
面向抽水蓄能电站智能巡检系统的联邦学习隐私保护方法
2023-12-29 12:21黄建德罗远林吴鹏浩
重庆邮电大学学报(自然科学版) 2023年6期
黄建德,何 秋,宗 悦,王 斌,罗远林,吴鹏浩,于 尧,郭 磊
(1.华东桐柏抽水蓄能发电有限责任公司,浙江 台州 317200;2.中国电建集团华东勘测设计研究院有限公司,杭州 311122;3.东北大学 计算机科学与工程学院,沈阳 110819;4.重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
随着物联网通信技术的快速发展,智能异构传感器被广泛部署于抽水蓄能电站巡检系统中,以辅助人工对发电机组设备进行多方位、全天候的巡视监控与数据采集[1]。在对巡检数据进行处理的过程中,由于人工介入通常伴有不确定性,基于人眼和经验识别异常情况的准确率有限,很难发现数据细微变化,面对海量行为数据不能及时地进行分析并对设备异常做出快速响应与调整,可能导致延误设备维护最佳时机,对电站运营安全造成严重威胁。
利用机器学习处理和分析抽水蓄能电站中的海量巡检数据是一种极具前景的思路。在机器学习范畴内,联邦学习作为一种多设备与中央服务器协同组成的分布式学习技术,更适合抽水蓄能电站智能巡检系统的实际部署[2]。然而,在面向抽水蓄能电站智能巡检系统的联邦学习架构中,针对设备本地模型参数的攻击仍会造成设备个体与群体隐私泄露,严重威胁电站运行安全。一方面,恶意服务器可以将指定的巡检设备与其上传的模型参数进行匹配,发起成员推理攻击,推断出各巡检设备身份、分工与工作状态等隐私信息;另一方面,外部攻击者可以通过窃听各巡检设备上传的模型参数,发起重构攻击,推理出设备本地训练数据,进而获知设备部署位置及其所监测的环境、电机机组运行状态等信息,通过发起有针对性的网络或物理攻击破坏电站安全[3-5]。针对以上问题,本文提出了一种面向抽水蓄能电站智能巡检系统的联邦学习隐私保护方法,在服务器端和传输过程中增强对设备本地模型参数的隐私保护。本文主要贡献总结如下。
1)针对恶意服务器匹配巡检设备及其上传参数所造成的隐私泄露问题,本文提出了一种基于随机响应的巡检设备选择机制,各巡检设备通过随机响应参与联邦学习训练,使服务器无法掌握具体某个设备参与训练的情况,避免服务器推理获得与设备身份相关的隐私信息。
2)针对设备本地模型参数在上传过程中的隐私安全问题,本文提出了一种自适应差分隐私方法,在给上传参数提供差分隐私保护的同时,根据参数梯度各元素特征为其自适应添加噪声,以提高差分隐私保护下的联邦学习模型准确率,并减少参数上传过程中的通信开销。
3)安全性分析与仿真结果表明,本文所提出的方法可以在服务器端和传输过程中增强对巡检设备本地模型参数隐私保护的能力,有效抵御来自服务器端的成员推理攻击和来自外部攻击者的重构攻击。与现有方法相比,本文方法可以有效提升差分隐私保护下的联邦学习全局模型准确率,并且能够减少训练过程中参数上传产生的通信开销。
1 相关工作
目前,国内外针对联邦学习隐私保护方法的研究已经取得了一定的进展,尤其是在利用差分技术赋能联邦学习隐私保护方面。
为防止攻击者通过分析客户端上传参数泄露隐私信息,文献[6]提出了一种基于差分隐私概念的联邦学习新框架,通过聚合前在客户端侧给本地模型参数加入人工噪声的方式,为本地模型参数在上传过程中提供差分隐私保护。文献[7]指出,在对联邦学习的差分攻击中,攻击者可以通过分析分布式模型来揭示客户端在训练期间的贡献以及与其数据集相关的信息。文献[8]提出将联邦学习和本地差分隐私相结合,以增强车联网众包应用中机器学习模型的隐私保护能力并降低通信成本。文献[9]研究了在本地差分隐私约束下,针对高斯多址信道为模型的无线信道上的联邦学习问题,提出了一种隐私无线梯度聚合方案,并对无线资源、收敛和隐私之间的权衡进行了研究。文献[10]考虑到参与者的异构性,提出了一种具有差分隐私的个性化联邦学习算法,在为每个参与者提供高效的个性化机器学习模型的同时保证其本地数据的差分隐私安全,并探讨了该方法在准确性和隐私间的权衡。
2 系统模型
为确保巡检设备本地数据的隐私性,本文提出了一个基于隐私保护联邦学习的智能巡检系统架构,如图1所示。整个智能巡检系统由多个巡检设备和一个联邦学习中央服务器组成。为保护本地模型参数在上传过程中的差分隐私安全,巡检设备在上传本地模型参数之前按照差分隐私保护要求为其添加噪声,并将加噪后的本地模型参数上传至联邦学习中央服务器。服务器使用参数平均算法对收集到的参数进行聚合并更新全局模型参数,并返回给参与联邦学习的巡检设备,至此完成一轮联邦学习训练。经多轮训练直至联邦学习全局模型收敛后,对其进行测试,并在确认各指标符合电站实际应用需求后将其部署于智能巡检系统中。
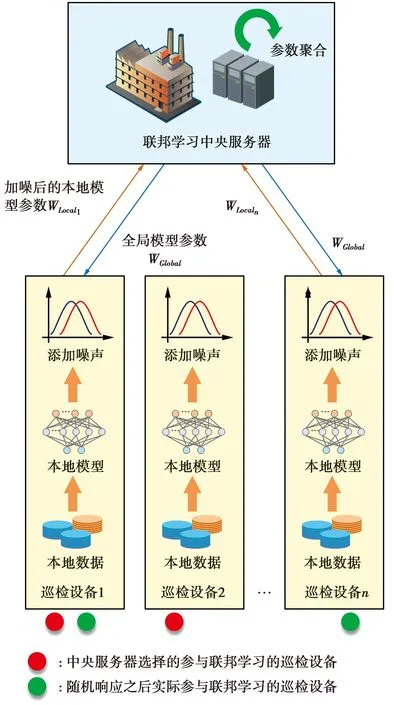
图1 基于隐私保护联邦学习的智能巡检系统架构Fig.1 Intelligent inspection system architecture based on privacy-preserving federal learning
考虑到电站巡检任务多样化、巡检设备密集部署以及算力有限的问题,在一次针对特定巡检任务的联邦学习过程中,只需要部分巡检设备参与即可。因此,在执行上述联邦学习过程之前,服务器需要选择参与联邦学习的巡检设备。为避免恶意服务器发起成员推理攻击获取设备隐私,各巡检设备先执行随机响应策略,服务器选择的设备与实际参与联邦学习的设备存在差异,故服务器无法根据自己的选择匹配其实际收集到的设备本地模型参数。
3 联邦学习隐私保护方法
3.1 基于随机响应的巡检设备选择机制
在大多数联邦学习应用中,客户端身份对服务器来说是默认已知的,因此,恶意服务器可以将指定客户端的身份与其上传的模型参数信息进行匹配,从而对指定客户端发起成员推理攻击或重构攻击,泄露其个体隐私。为阻止恶意服务的匹配行为,本文提出了一种基于随机响应的巡检设备选择机制。在联邦学习进程开始前,各巡检设备在本地执行随机响应判断自己是否被选中,而非由服务器直接指定,使服务器无法知晓实际参与联邦学习的设备身份。具体过程如下。
第1步:初始化各巡检设备设置状态参数θ=0。注意,θ=1和θ=0分别表示该巡检设备参与和不参与接下来的联邦学习训练,初始化时各巡检设备的θ均为0。
第2步:服务器根据本次巡检任务的执行要求和对联邦学习参与设备数量的要求,选择参与联邦学习训练的巡检设备,并将选中的巡检设备状态参数θ设置为1,没有选中的巡检设备状态参数θ仍保持为0。
第3步:所有满足本次巡检任务执行要求的巡检设备进行随机响应,即以概率p保持当前状态参数不变,以概率1-p改变当前状态参数。经过随机响应后,状态参数θ=1的巡检设备被选中参与接下来的联邦学习训练过程。
第4步:如果随机响应后巡检设备数量不满足联邦学习训练数量要求,则重新进行随机响应。
3.2 自适应差分隐私技术
传统差分隐私技术为训练中的机器学习模型参数(即梯度向量)添加固定强度噪声以为其提供差分隐私保护。噪声的添加会影响模型准确率,而要提升模型准确率通常是以削弱差分隐私保护能力为代价的。
研究发现,梯度向量的不同维度之间取值存在差异,不同维度对添加的噪声表现出不同的敏感性。如果将强度较高的噪声添加到取值较小的梯度向量维度中,过量的噪声会显著影响梯度下降速度甚至是方向,造成模型参数精度损失,模型准确率下降;如果将强度较低的噪声添加到取值较大的梯度向量维度中,则会降低整个梯度的差分隐私保护级别。本文提出一种自适应差分技术,即根据巡检设备本地模型梯度向量中各维度的取值大小自适应地为各维度添加强度不同的噪声,在不降低隐私保护级别的前提下避免过量噪声所造成的模型参数精度损失,提高模型准确率。自适应差分隐私技术的执行过程如下。
第1步:计算梯度向量每个维度敏感度Si为
(1)
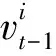
第2步:计算梯度向量每个维度所需添加的噪声标准差σi为
(2)
(2)式中:σ*为噪声标准差;m为梯度向量维数。
(3)
根据文献[11]中的差分隐私定理可知,若某种技术满足(4)式,则该技术一定是差分隐私技术。
Pr[lM,D,D′≥ε]-Pr[lM,D′,D≤-ε]≤δ
(4)
(4)式中:lM,D,D′表示隐私损失变量;D和D′表示只差一条数据的相邻数据集;ε表示隐私预算。隐私预算可以用来衡量差分隐私技术,可以为巡检设备本地模型参数提供隐私保护级别,一般来说,隐私预算值越小,隐私保护级别越高。ε满足的条件为

(5)
(5)式中:C1和C2为常量;q为采样概率;T为本地模型迭代次数;δ为差分隐私失败的概率。
下面证明本文所提出的自适应差分隐私技术满足差分隐私定理,即证明对梯度向量各维度分别添加噪声后的隐私损失变量满足(4)式。
证明隐私损失变量表示为
(6)
令S=(s1,s2,…,sm)=‖f(D)-f(D′)‖2,(r1,r2,…,rm)=y-f(D),其中m表示维度,可得
(7)
(8)
故有
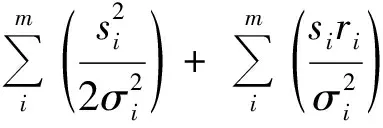
(9)
(9)式中,lM,D,D′服从N(η,2η)高斯分布,且
(10)
故有
(11)
同理可得
Pr[lM,D′,D≤-ε]=Pr[N(η,2η)≤-ε]=
(12)
故有
Pr[lM,D,D′≥ε]-eε·Pr[lM,D′,D≤-ε]=
(13)
(13)式对η求导可得
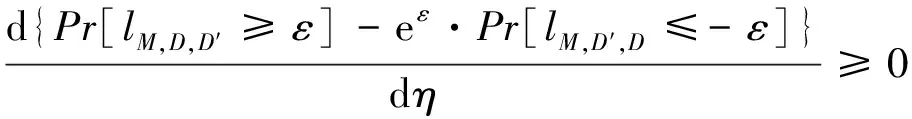
(14)
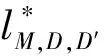
综上所述,可将基于随机响应的巡检设备选择机制与自适应差分隐私技术整合到智能巡检系统联邦学习架构中。本文提出的面向抽水蓄能电站智能巡检系统的联邦学习隐私保护算法流程如算法1所示。
算法1面向抽水蓄能电站智能巡检系统的联邦学习隐私保护算法
1.服务器初始化全局模型参数WGlobal,并将其分发给所有巡检设备;
2.巡检设备随机响应阶段:
3.服务器指定参与联邦学习的巡检设备;
4.全部巡检设备执行随机响应机制,以概率1-p改变其状态参数;
5.状态参数θ=1的巡检设备参与联邦学习训练,数量表示为N;
6.巡检设备自适应噪声添加阶段:
7.for联邦学习训练轮t=1,2,…,Tdo
8.各巡检设备本地执行:
9.for batchb∈Bdo
11.end for
12.为梯度向量各维度添加噪声:
13.fori-th梯度向量维度 do
17.else
19.end if
22.end for
23.服务器参数聚合与分发阶段:
服务器收集各参与设备上传的梯度并将这些梯度进行聚合,其中Mn代表第n个设备数据集的大小,M代表所有设备数据集总和的大小;
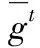
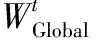
28.end for
4 仿真与结果分析
4.1 参数设置
为使本文提出的联邦学习隐私保护算法具有良好的稳定性和快速收敛能力,仿真中使用的参数设置如表1所示。考虑到国家电力系统相关数据安全规定,针对抽水蓄能电站巡检数据的敏感性,根据生产单位建议,本文使用公开数据集MNIST来验证算法的有效性。每个设备的本地模型采用多层感知机实现,输入层、两个隐藏层和输出层的神经元数量分别为784、15、15和10,隐藏层激活函数为ReLU。本文采用最先进的FedAdam算法训练模型。

表1 仿真参数设置Tab.1 Simulation parameter settings
在差分隐私算法设计中,利用上一时刻累计梯度平方值近似估计当前梯度值的方式存在一定误差,故使用裁剪因素β来对当前误差进行矫正。本文将传统差分隐私技术中的梯度向量全局敏感度计算优化为梯度向量各维度局部敏感度计算,而在局部敏感度计算中,β的取值不同会影响联邦学习全局模型准确度。为此,本文进行了多轮实验测试不同β值下的模型准确率,实验结果如图2所示。
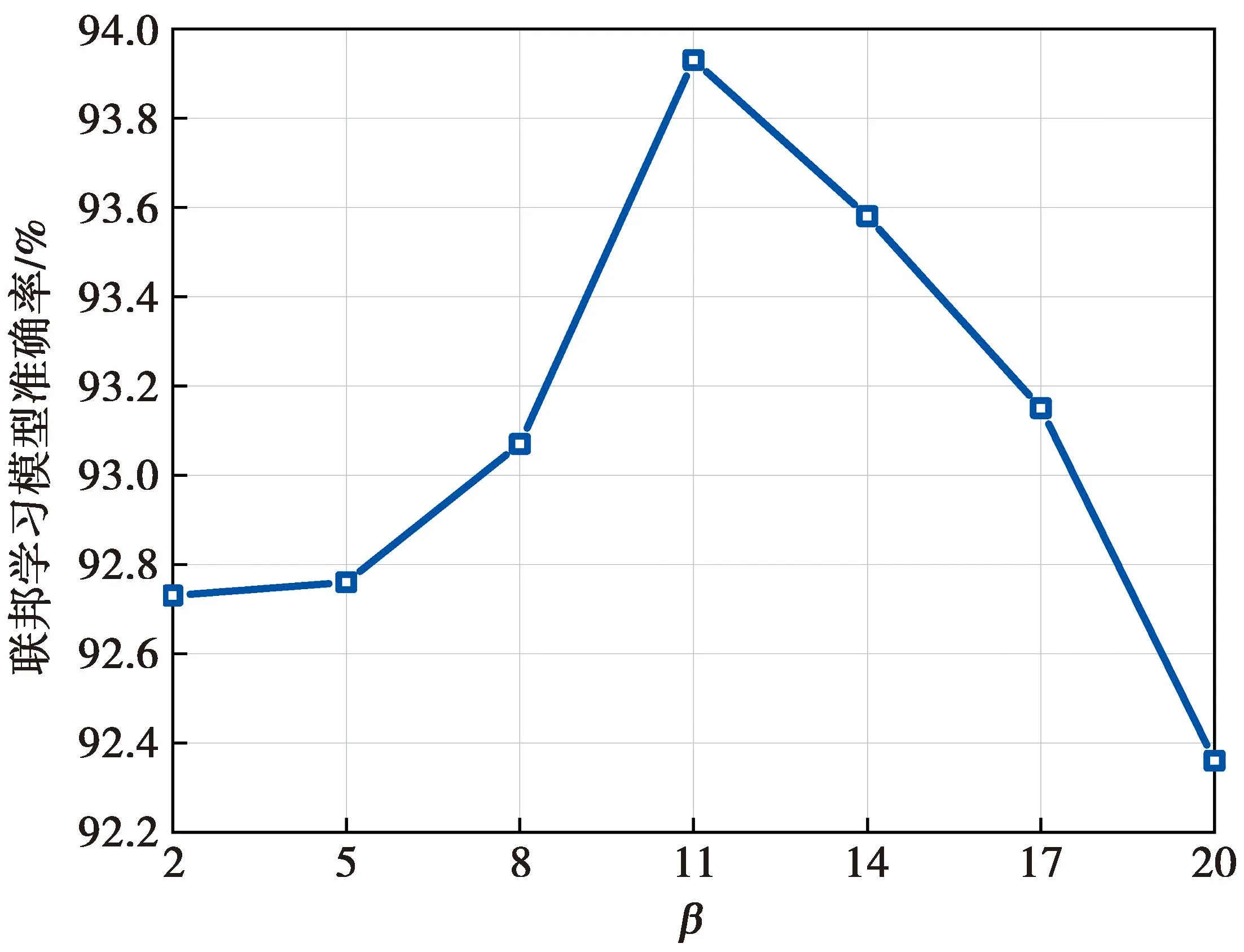
图2 不同β取值对联邦学习模型准确率的影响Fig.2 Federated learning model accuracy under different values of β
从图2可以看出,当β=11时,联邦学习模型准确率达到峰值93.48%。为保证模型具有较高的准确率,本文后续仿真实验中β值取11。
为验证提出模型的性能优势,本文选择传统差分隐私技术作用下的联邦学习(简称传统差分隐私方法)和无隐私保护技术作用下的联邦学习(简称无隐私保护方法)作为对比方案,其中,传统差分隐私技术给巡检设备本地模型参数梯度各维度添加相同强度的噪声。
4.2 模型准确率对比分析
为验证本文方法在联邦学习模型准确率方面的性能优势,本节对比了3种方法在不同隐私预算下的准确率,如图3所示。从图3可以看出,在不同隐私预算下,本文方法准确率高于传统差分隐私方法,但与无隐私保护方法的准确率相比略有损失。这是因为在本文方法中,自适应差分隐私技术根据梯度向量各维度取值大小自适应地为各维度添加不同分布的噪声,从而避免噪声添加过量而导致的模型参数精度损失,提高了准确率。而传统差分隐私技术忽略了巡检设备本地模型梯度各维度之间的差异,为各维度添加同分布高强度噪声,导致模型参数精度损失严重,模型准确率下降。此外,为确保模型参数隐私性,添加适量噪声将模型准确率降幅控制在可以接受的范围内是值得的。对于抽水蓄能电站巡检系统来说,本文方法可以为巡检设备本地数据提供差分隐私保护,同时提供更高准确率的数据分析全局模型。

图3 不同隐私预算下3种方法联邦学习模型 准确率对比Fig.3 Federated learning model accuracy of the tree methods under different privacy budgets
4.3 通信开销对比分析
为验证本文方法在联邦学习通信开销方面的性能优势,本节将本文方法作用下与传统差分隐私方法作用下的联邦学习通信轮数进行了比较,结果如图4所示。由于每个参与训练的设备数据量、批次大小、迭代次数均相同,所以每个参与训练的设备上传的数据总量也相同,本文通信开销只与通信轮次有关。在不同隐私预算下,本文方法作用下的联邦学习通信轮数明显小于使用传统差分隐私方法作用下的通信轮数。以隐私预算ε=45、δ=10-5为例,本文方法相较于对比方法减少了通信轮数。原因在于,本文方法减少了梯度参数精度损失,提升了联邦学习全局模型收敛速度,从而节省了服务器与巡检设备间的通信开销。

图4 不同隐私预算下通信轮数对比Fig.4 Federated learning communication rounds under different privacy budgets
4.4 多用户场景性能对比分析
考虑到联邦学习是一种多用户参与的分布式机器学习技术,因此,本节重点讨论了联邦学习参与设备数量对本文方法作用下模型性能的影响,并与传统差分隐私方法作用下联邦学习模型性能进行了对比分析。为满足抽水蓄能电站智能巡检系统整体对高水平隐私保护的需求,本节为两种联邦学习隐私保护方法设置了一个固定且取值较小的隐私预算。不同参与设备数量下模型性能对比如图5所示。在隐私预算固定的情况下,随着联邦学习参与设备数量的增加,本文方法中的联邦学习模型准确率有所下降,通信轮数有所上升,但仍优于传统差分隐私方法。原因在于,当联邦学习系统隐私预算固定不变时,随着参与设备数量的增多,分配给每个参与设备的隐私预算减少,需要给各参与设备本地模型参数添加更多的噪声以使系统整体保持高水平的隐私保护,导致联邦学习模型参数精度损失加剧,收敛所需的通信轮数增加,通信开销增加。尽管如此,本文自适应添加噪声的方式仍可以减少不必要的噪声添加,在与传统差分隐私技术提供相同级别隐私保护水平的前提下,本文方法可以实现更高准确率、更低通信开销。

图5 不同参与设备数量下模型性能对比Fig.5 Federated learning model performances of the two methods under different numbers of participating devices
4.5 安全性分析
根据随机响应与自适应差分隐私技术分析,本文方法具有以下安全特征。
1)恶意服务器无法成功实施对特定设备的成员推理攻击以泄露其隐私。在基于随机响应的巡检设备选择机制作用下,服务器无法获知或推理出实际参与联邦学习的设备身份,无法将设备身份与其上传的本地模型参数进行匹配。恶意服务器不能通过指定联邦学习参与设备并根据模型参数差异推理出与特定设备身份相关隐私信息,导致成员推理攻击失败。
2)恶意服务器或外部攻击者无法成功实施对联邦学习参与设备的重构攻击导致泄露其隐私。在自适应差分隐私技术作用下,对于任一设备的本地数据库,添加或删除一条或几条本地数据不可通过其本地模型参数直观地反映出数据库的差异。恶意服务器或者外部攻击者不能根据已获取的模型参数通过模型重构逆向推理出具体的设备本地数据,导致重构攻击失败。
5 结束语
本文受国网新源公司科技项目支持,提出了一种联邦学习隐私保护方法以解决抽水蓄能电站智能巡检系统联邦学习过程中的隐私泄露问题。具体来说,基于随机响应的巡检设备选择机制,各巡检设备通过随机响应参与联邦学习训练过程,使服务器无法通过匹配设备身份及其上传模型参数推理出设备隐私信息,确保模型参数在服务器端的隐私安全;自适应差分隐私技术,在传输过程中为设备本地模型参数提供高级别的差分隐私保护。安全性分析和仿真结果表明,本文方法可以有效防止恶意设备和外部攻击者通过发起成员推理攻击与重构攻击泄露设备隐私,与现有经典方法相比,本文方法在保证模型参数差分隐私安全的同时可以使联邦学习模型具有更高的准确率和更低的通信开销。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
新世纪智能(数学备考)(2021年5期)2021-07-28
家庭影院技术(2020年10期)2020-12-14
应用数学(2020年2期)2020-06-24
家庭影院技术(2019年7期)2019-08-27
数学年刊A辑(中文版)(2018年2期)2019-01-08
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
四川生理科学杂志(2014年2期)2014-02-28
河南科技(2014年3期)2014-02-27
