
基于联邦深度强化学习的多无人机轨迹规划算法
2024-01-02 07:53王鉴威李学华陈硕
北京信息科技大学学报(自然科学版) 2023年6期
王鉴威,李学华,陈硕
(北京信息科技大学 现代测控技术教育部重点实验室,北京 100101)
0 引言
随着物联网技术不断发展以及第五代移动通信技术大规模商用,越来越多的计算密集型应用对时延具有较强的敏感度,对设备的计算能力提出了较高的要求。移动边缘计算(mobile edge computing,MEC)通过在移动网络边缘部署计算和存储资源,可以有效地给予用户超低延时和高带宽的网络服务解决方案[1]。
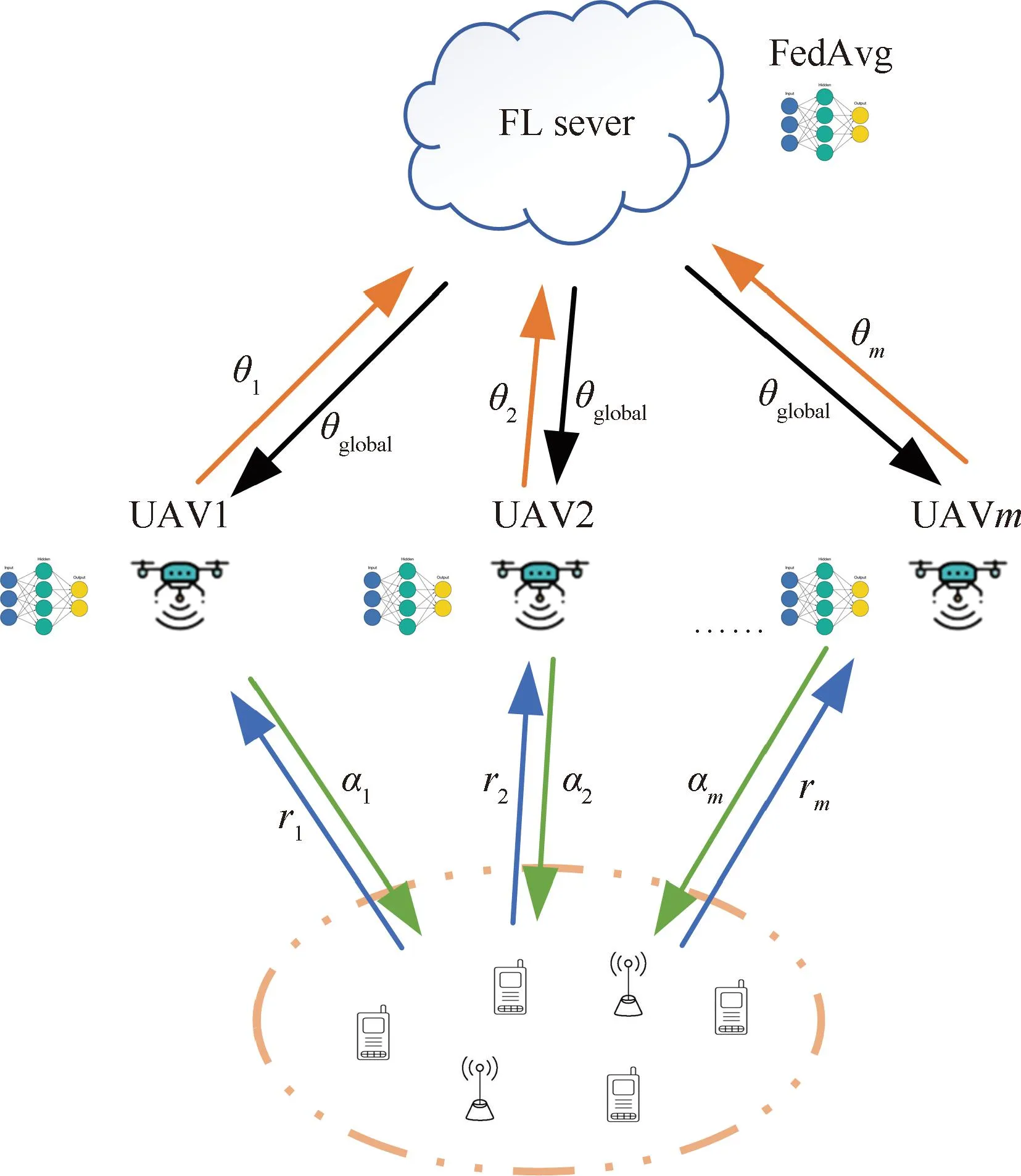
然而,现有MEC服务器部署往往依赖地面通信基础服务设施。在偏远区域或紧急情况下,难以满足移动用户的通信需求。无人机(unmanned aerial vehicle,UAV)因其灵活度高、移动性强和部署成本低等特点[2],可以在空中建立移动通信基站为地面移动设备提供通信服务,依靠视距(light of sight,LoS)传输信道[3]以及灵活部署位置获取最佳信道条件等优势,构筑空-地一体的通信网络。
虽然无人机能够通过自身移动性,灵活规划无人机轨迹进行MEC服务,但是无人机辅助移动边缘计算仍存在诸多挑战。一方面,传统计算卸载方案,将计算任务全部卸载到边缘服务器上执行,舍弃了地面设备端的计算资源,没有充分利用场景内的算力;另一方面,传统研究采用单个无人机对地面用户进行移动边缘计算服务,相比于多个无人机对地面用户服务的效率较低。如今,多无人机轨迹规划算法已有大量的研究。如文献[4],为最小化平均相应时间,采用粒子群优化算法与遗传算法算子相结合的方式来优化无人机部署。文献[5]在资源分配凸优化和组合无人机分组优化方案的耦合步骤中,通过调控优化无人机发射功率、计算资源分配,在最大化资源利用率的同时最大限度减少无人机传输能量和计算能量消耗。
然而,上述方法难以真正应用于实际场景[6]。一方面,用户位置、无人机-用户信道状况等用户侧信息常常无法获得或提前预测;另一方面,实际通信环境通常较复杂,无法准确建模。因此,在无法提前掌握环境信息的场景下进行无人机轨迹规划是亟需解决的关键技术。
近年来,多智能体强化学习(multi-agent reinforcement learning,MARL)已成为热门研究课题。多智能体强化学习可以基于分布式架构的无人机通信网络,提供一种有效的智能资源管理解决方案,特别是在一些无人机只能获取局部本地信息的真实场景下。如文献[7],当环境动态和部分可观察时,基于多智能体强化学习设计多无人机在多重约束下学习最优轨迹规划策略。文献[8]采用多智能体强化学习框架,每个智能体根据局部观察学习,所有智能体独立地执行决策算法。分布式架构有效地降低了计算的复杂性。然而,在经典的分布式学习方法中,大多数智能体的决策都是局部的。这些代理之间相互独立、缺乏信息共享,难以实现全局最优结果。此外,即使有些方案在智能体间进行了信息交互,但此类方法没有考虑用户数据的隐私性,会对用户通信数据的安全构成威胁。
联邦学习(federated learning,FL)作为一种分布式机器学习算法,将训练数据保存在本地设备,通过汇总本地模型更新到云服务器,学习得到全局模型,可同时实现隐私保护和信息共享。Wang等[9]在多无人机网络采用联邦学习框架,无需将原始敏感数据传至服务器,在保护用户设备隐私的同时节省无人机有限的计算和通信资源。余雪勇等[10]面对感知数据隐私安全问题,采用联邦学习与强化学习的激励机制相结合的方式促进高质量模型共享,提高了无人机的实用性并保障了隐私保护。从上述文献能够看出,联邦学习既能够实现用户间的信息共享,又很好地弥补了传统分布式架构在隐私安全方面的缺陷。
因此,本文提出了一种移动边缘计算场景下基于联邦深度强化学习的多无人机轨迹规划算法,有效地解决了无人机辅助移动边缘计算场景中地面用户设备时延敏感、无人机卸载服务不均衡的情况。本算法结合了联邦学习与双延迟深度确定性策略梯度(twin delayed deep deterministic policy gradient,TD3)算法,既实现了在环境信息无法预知的情况下进行路径规划,又确保了信息共享以实现全局最优,同时保护了无人机的数据隐私。
1 系统模型与问题描述
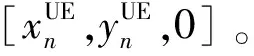
1.1 无人机飞行模型
将无人机的飞行时间划分为T个时隙,每个时隙长度为τ。无人机以固定安全高度H在目标区域上空飞行,第m(m=1,2,…,M)架无人机的飞行坐标为[Xm(t),Ym(t),H],其中Xm(t)、Ym(t)分别为无人机m在第t(t=1,2,…,T)时隙的横、纵坐标。令dm,t和θm,t分别为无人机在t时隙的飞行距离和水平方向角度,且满足dmax为无人机单位时隙内最大飞行距离。因此第m架无人机在第t时隙的横纵坐标分别为
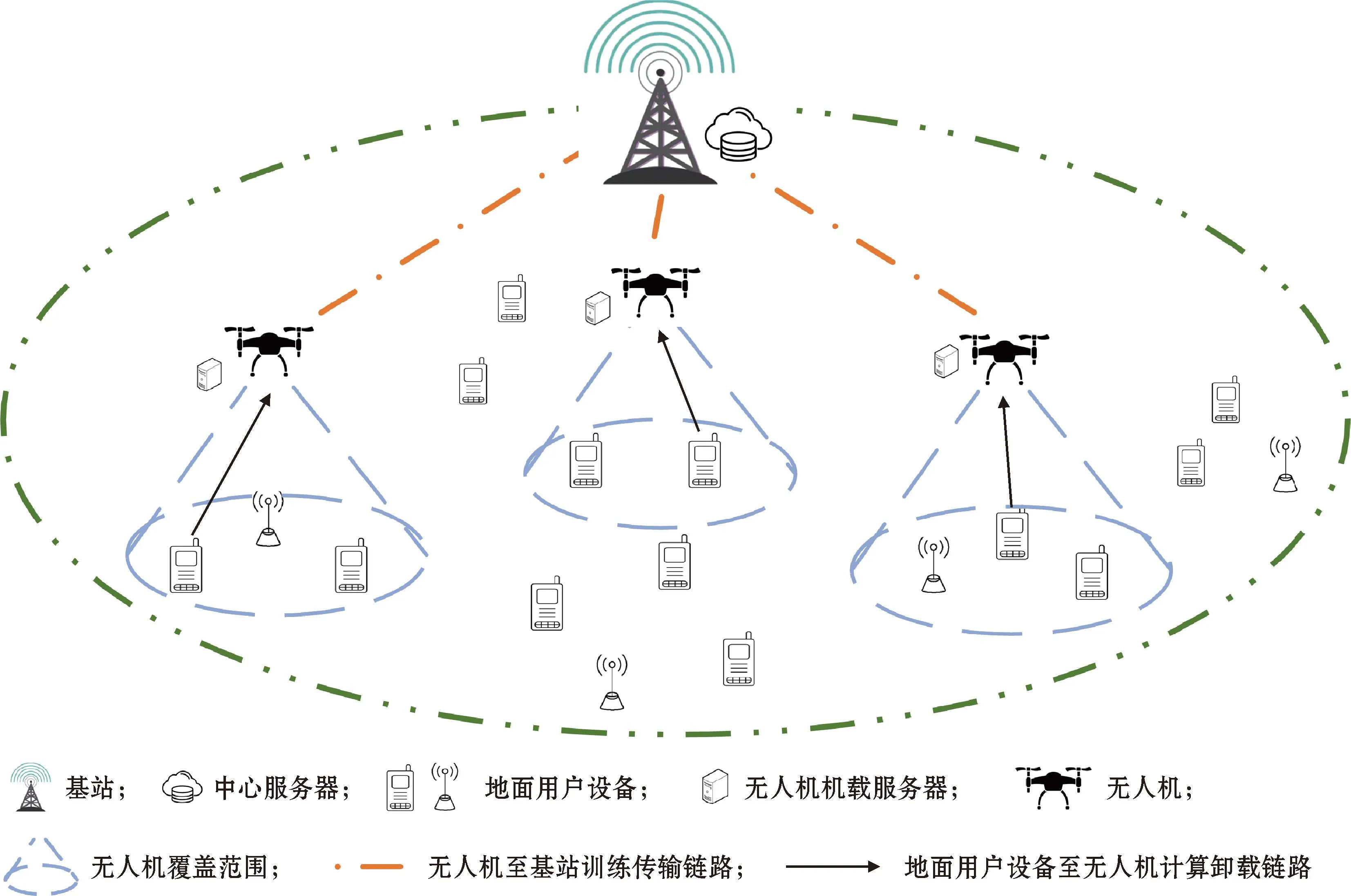
图1 无人机辅助移动边缘计算系统模型Fig.1 UAV aided mobile edge computing system model
(1)
为保证无人机在飞行过程中的安全,限定边界,防止无人机飞出任务区域,即0≤Xm(t)≤Xmax和0≤Ym(t)≤Ymax,其中Xmax和Ymax为该区域的长度和宽度。多无人机协同工作时,为避免无人机之间出现碰撞造成损失,需得到无人机m与无人机m′之间的距离,表示如下:
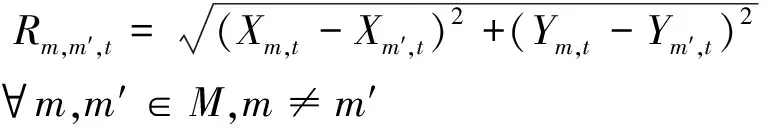
(2)
设置无人机m与无人机m′之间的最小距离为Rm,并满足:
Rm,m′,t≥Rm
(3)
1.2 信道模型
对于空对地信道,当无人机在一定高度上时,地面用户n与无人机m之间的传播条件可以近似为由视距链路[12]主导的自由空间路径损耗模型[13]。因此,无人机m和地面用户设备n之间的信道功率增益可以被量化为
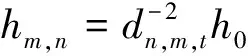
(4)
式中:h0为参考距离d0=1 m时无线信道内的信道增益大小;dn,m,t为第n个地面用户与第m架无人机之间的距离。利用欧几里得坐标系表示为
(5)

因此,第n个地面用户与第m架无人机之间的数据传输速率[14]可以进一步表示为
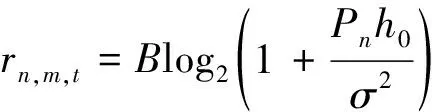
(6)
式中:B为信道的带宽,本文设定所有无人机通过频分多址(frequency division multiple access,FDMA)的方式为所有地面用户提供同等带宽分配的服务;Pn为用户设备n的传输功率;σ2为信道中的背景噪声功率。
同时考虑到传输距离损耗和不同信道之间的干扰,设定无人机可为地面用户提供计算卸载的最大传输距离,即覆盖范围为Rmax,并满足如下覆盖范围约束:
dn,m,t≤Rmax
(7)
1.3 计算卸载模型
本文假定,每个地面用户均可选择本地计算或部分卸载至无人机进行辅助计算。同时,无人机可为覆盖范围内的任意地面用户提供比例卸载服务。卸载比例αn,m,t∈[0,1],αn,m,t=0表示完全卸载至无人机m进行计算,αn,m,t=1表示由地面用户进行计算。为简化数据分割难度,同一时隙内单个地面用户设备规定只能与一架无人机关联进行计算卸载。
在任意时隙t,各地面用户设备均会产生一个待处理的计算密集型任务Sn,t,并假设终端设备产生的任务数据均可逐位独立并可按任意比例进行划分,定义为
Sn,t={Dn,t,Fn,t}
(8)
式中:Dn,t为待处理的数据量;Fn,t为执行此任务所需的CPU周期总数。
1.3.1 地面用户本地计算
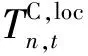
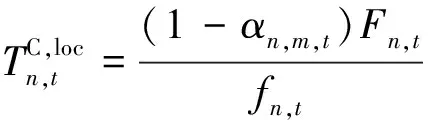
(9)
式中:fn,t为用户设备处理器的CPU计算频率。
1.3.2 地面用户设备卸载到无人机
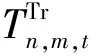
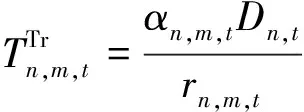
(10)
在无人机端任务的执行时间可以表示为
(11)
式中:fm,t为无人机服务器的CPU计算频率。
由于无人机端计算处理结束后产生的数据结果通常较小,因此忽略数据回传时延。
1.3.3 对于单个地面用户设备的总时延
虽然终端设备可以同时将任务卸载到无人机,但各终端设备卸载的任务在无人机上为串行执行,故需要排队处理,采用先进先出(first input first output,FIFO)方式对终端设备卸载到无人机的数据进行处理。无人机计算卸载时延由传输时延、等待和计算时延构成。
因为采取了部分卸载的方式,充分利用了无人机端和地面用户设备端的计算资源。因此,对于单个地面用户,在计算总时延时需要并行考虑这两端的时延。对每一个地面用户设备所产生的待计算任务工作时延Tn,t为
(12)
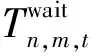
最后,为了保障所有地面用户设备的计算能够在规定时间内完成,还规定了每个时隙内的最大任务时间Tmax,并满足:
Tn,t (13) (14) 为了同时兼顾地面用户任务处理时延以及无人机服务地面用户的公平性,本文提出了多无人机辅助移动边缘计算系统中的联合优化问题,通过联合优化无人机的轨迹和计算卸载决策,使服务公平性和任务计算时延的加权和最大化。用β代表权重系数,最终优化问题可以描述如下: (15) 在本节中,提出一种融合联邦学习和双延迟深度确定性策略梯度(FL-TD3)的算法,解决移动边缘计算中多无人机轨迹规划问题。由于在环境中没有可以获取全局信息的中央控制器,每架无人机只能根据自身传感器获取环境中的相关信息,而无法得知其他无人机的相关信息。各无人机分别与环境交互,依据自身观察到的局部信息获取动作奖励值,得到相应策略。这种训练方式使无人机获取信息不够全面,根据这些局部信息学习得到的策略容易陷入局部最优。因此,为了保证不陷入局部最优解,需要对无人机进行一定的协作来实现信息共享,从而达到全局最优。 为保证训练效果,本文用联邦深度强化学习的方式对无人机辅助移动边缘计算进行训练,如图2所示。 图2 基于联邦深度强化学习算法框架Fig.2 Framework of federated deep reinforcement learning algorithm 首先,无人机根据自身情况与环境进行交互,训练得到局部最优策略;然后,为保证多无人机决策不陷入局部最优解,定期将无人机训练所得局部模型传输至云服务器进行联邦学习中心聚合,之后再将聚合所得模型下发回各无人机。与集中式架构的中央控制器决策方案相比,云服务器不进行全局模型训练,仅通过更新模型参数的方式实现无人机之间的信息共享。无人机重复上述学习方式,直至收敛完成训练。这样,无人机就可以直接根据环境信息生成相应的部署和资源分配决策,无需将大量数据传输至云服务器在云端集中训练,极大缩减数据传输量以及训练复杂度。 在此算法中,每架无人机作为一个智能体,每个智能体可以进行独立学习,根据当前环境状态确定下一步的动作。无人机的轨迹位置状态和计算卸载服务状态都具有马尔可夫性质,即下一个时刻的状态只与当前状态有关,与之前的状态均无关。因此,这样的优化问题可以被建立为离散时间马尔可夫决策过程(Markov decision process,MDP)。在数学上,将MDP重新定义为三元组(sm,am,rm)。其中,sm和am分别代表无人机m的状态空间和动作空间,rm代表无人机m在当前状态sm做出动作am的奖励函数。 因此可以定义每个智能体在t时隙的状态、动作、奖励函数如下: 2)动作am(t)。定义在t时隙无人机m的飞行位移和卸载比例am(t)={dm,t,θm,t,αn,m,t} 。 3)奖励函数rm(t)。定义奖励函数为 (16) 式中:pr为无人机m飞出限定范围的惩罚;pm为无人机m与其他无人机相撞的惩罚。 综上所述,每架无人机都可以根据当前的环境状态信息做出相应的执行策略。根据多架无人机的联合动作将环境更新到下一状态,同时每架无人机得到相应的奖励。每架无人机通过试错的方法不断地与环境交互,最终学习到一个最优的策略π(s),使其能够做出最优决策,得到长期奖励最大化,可以将长期奖励定义为 (17) 式中:r(·)为奖励函数;γ为奖励的折扣因子,γ∈(0,1)。 深度强化学习因其加强了神经网络的层级,可用于处理无人机更加复杂的的控制问题。使用深度神经网络的输出近似拟合未来奖励的期望值Q(s,a),Q(s,a)是在状态s中执行动作a,以取得奖励的预期收益。连续性动作控制算法包括深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法和TD3算法,通过最小化损失函数更新神经网络的参数θ获得更准确的Q值,提升智能体的性能。 TD3作为一种连续动作控制算法,在智能控制领域拥有良好的效果。与同为连续动作空间控制算法的DDPG相比,这一经典算法解决了高估误差问题。TD3使用3种技术对这个问题进行优化。 首先,TD3算法采用两套Critic网络及Critic Target网络,对于每次更新,选取较小的Q值。 其次,采用延迟更新策略,当模型的价值函数产生较大变化时,才会更新其策略;否则,不会更新。这样可降低价值估计的差异,产生更好的策略,在更新时可以获得更稳定的性能。 最后,采用目标策略正则化减少方差增加,因为在更新Critic网络时,确定性策略的学习目标容易受到函数近似值误差的影响,导致目标的方差增加。此外,TD3的动作输出会受到噪声影响,我们通过平均训练批次中的噪声平滑估计值。所添加的噪声服从正态分布,并且对采样的噪声进行适当裁剪,使动作更接近原始动作。 从以上所述可以看到,在每架无人机上分别部署了基于TD3的无人机辅助移动边缘计算轨迹规划算法。每架无人机分别根据自身所处环境学得局部最优策略。然而,本文的场景设置为多无人机协作共同服务地面用户,如果单架无人机只追求自身的奖励最大化,会影响其他无人机的训练结果。而在此项任务当中无人机相互之间处于合作关系而非独立或者竞争的关系,那么应当设计出一种能够在全局的角度下最优结果,而非单架无人机局部最优。因此,本文引入联邦学习框架,从而达到多无人机协同过程中的全局最优。 采用联邦平均(federated averaging,FedAvg)的方式对深度强化学习模型进行平均聚合,按式(18)更新: (18) 式中:θglobal为全局网络模型参数;θm为无人机上部署的局部模型参数。 在联邦深度强化学习框架下,模型训练仅在各无人机端利用私有数据进行训练,而中心服务器只进行模型聚合。与传统的集中式学习相比,本方案并没有将所有数据传至中心服务器进行集中式训练,既降低了训练复杂度又保护了数据隐私。 在本文提出的移动边缘计算中基于联邦深度强化学习的无人机辅助轨迹规划方案中,无人机是联邦学习框架中客户端学习与训练的主体,基站配属的服务器是联邦学习框架中的云端。每架无人机都被建模为一个智能体,可以进行独立的探索和学习。算法将联邦学习和深度强化学习相结合,组成多智能体协作通信网络。具体过程如算法1所示。 该算法分为3个部分。首先,初始化整个多无人机通信环境和每架无人机的网络参数。之后,每架无人机通过与环境交互获得状态信息。无人机根据神经网络的输出结果执行动作,获得相应的奖励和下一个状态。重复无人机与环境交互达到一定次数后,将学习所得网络模型参数传输至FL云服务器。最后,FL云服务器在特定周期得到各无人机上传的网络模型参数。云服务器聚合各局部模型参数并生成新的全局模型参数,再下发回各无人机继续训练。重复上述训练过程,直到达到迭代次数为止。 算法1:移动边缘计算中基于联邦深度强化学习的多无人机轨迹规划算法1.建立环境和算法参数;2.for all UAV m,m∈Mdo3. 初始化回放缓存 m。4. 初始化Critic网络Qmθ1、Qmθ2和Actor网络πmϕ,以及随机参数θm1、θm2、ϕm。5.初始化Critic Target网络Qm,Targetθ1、Qm,Targetθ2和Ac-tor Target网络θm,Targetπϕ,以及模型参数:θm,Target1θm1、θm,Target2θm2、ϕm,Target1ϕm。6.end for7.forp=1 to emaxdo8. 初始化环境以及全局状态S(t);9. fort=1 to Tdo10. for all UAV m,m∈M do11. 从FL中心服务器获取全局权重θglobal;12. 获取状态sm(t)同时依据模型策略选 取动作; 13. end for14. 根据所有无人机的联合动作A(t)更新最新 的全局状态S(t+1);15. for all UAV m,m∈Mdo16. 获取新的状态值sm(t)以及相应的奖励 rm(t);17. 存储(sm(t),am(t),rm(t),sm(t+1))到 回放缓存 m中;18. 从回放缓存 m中随机采样过渡的小批 量样本(sj,aji,rji,s′j);19. 通过目标值ym计算最小化损失函数,更 新Critic网络的权重θm1、θm2: θmi←argminθmiN-1∑(ym-Qmθi(s,a))2 ∀i∈1,220. Ift mod 3 then21. 更新Actor网络的权重 ϕm: ΔϕmJ(ϕm)=N-1∑ΔaQmθmi(s,a)a=πmϕ(s)Δϕmπϕm(s)22. 更新Actor Target网络和Critic Target 网络的权重: θm,Targeti←τθmi+(1-τ)θm,Target ∀i∈1,2 ϕm,Target←τϕm+(1-τ)ϕm,Target∀i∈1,223. End if24. 发送模型权重θm1、θm2、ϕm到联邦学习中心 服务器;25. end for26. 联邦学习云服务器对所有无人机的权重进 行平均,以更新全局权重θglobal;27. end for28.end for 本节通过实验仿真说明移动边缘计算中基于联邦深度强化学习的多无人机轨迹规划算法的性能。首先,描述系统模型参数设置。其次,分析仿真结果以及性能,并与其他算法进行性能比较。 设定150 m×150 m的任务区域,部署3架无人机以及20个地面用户随机分布在任务区域内,如果无人机飞出限定区域将被强制返回。为了简化无人机飞行环境,设置无人机飞行高度为15 m。3架无人机的起始位置分别为[20,20]、[20,120]、[120,120] m。在此区域内部署随机分布的20个地面用户,每个地面用户在各时隙开始时均会产生一个数据大小为D以及每比特需要CPU轮数为F的待处理计算密集型任务Sn,t。具体相关参数见表1。 表1 系统模型与优化模型参数Table 1 System model and optimization model parameters 为分析本文算法性能,与其他3种算法进行对比: 1)分布式双延迟深度确定性策略梯度(distributed twin delayed deep deterministic policy gradient,DIS-TD3)[15]多无人机辅助移动边缘计算算法:部署多架无人机,采用分布式架构,TD3算法独立部署在各无人机上仅依靠自身局部信息训练学习,最终做出决策。 2)双延迟深度确定性策略梯度单无人机辅助移动边缘计算(single UAV twin delayed deep deterministic policy gradient,SINGLE-TD3)[16]算法:仅使用单个无人机,利用双延迟深度确定性策略梯度算法对无人机进行轨迹规划。 3)在地面用户设备本地执行所有计算任务,简称为LOCAL-ONLY:无人机不参与计算任务,仅依靠地面用户自身对产生的计算任务进行处理。 首先,描述多无人机辅助移动边缘计算的轨迹,如图3。在150 m×150 m的规定范围内部署了3架无人机以及20个地面用户随机分布在任务区域内,圆点代表地面用户的位置,菱形、三角形、十字形分别为3架无人机的轨迹。 图3 各地面用户位置分布及无人机轨迹Fig.3 Location distribution of ground users and drone trajectories 从图3可以看出,因计算卸载覆盖范围有限,无人机必须移动位置以保证服务更多地面用户,从而提高服务地面用户公平性。同时为减小卸载到无人机计算任务的传输时延,无人机尽可能贴近地面用户以减小传输距离。所有无人机都在一定区域内飞行,无人机1聚集在左下,贴近地面用户聚集处。无人机3从右上逐渐迁移至右下,以服务更多用户。 图4为FL-TD3的收敛性能。本文共部署了3架无人机协同对地面用户设备进行计算卸载服务。收敛性能描述了训练过程中3架无人机的总奖励值变化。刚开始总奖励持续增加,到1 000次左右逐渐趋于平缓,经过约2 800次训练后趋于收敛。 图4 FL-TD3算法收敛情况Fig.4 Convergence of FL-TD3 algorithm 图5为系统中服务公平性和时延累计随时隙变化的仿真结果。在整个多无人机辅助计算卸载过程中,共设置了10个时隙为地面用户提供服务。其中,为了对比优化问题中权重系数β对性能的影响,在本文提出的FL-TD3上设立权重系数为β=0.3的对比算法,即图中的FL-TD3-0.3算法,对比权重系数对公平性和时延性能的影响。在图5(a)中,所有算法的公平性均随着时隙的增长而升高。这是因为随着时隙的增长无人机不断增加对地面用户的计算卸载数量,从而使服务公平性不断增高。图5(b)为时延的累计,它随着时隙的增长不断升高。首先,FL-TD3-0.3相比FL-TD3的公平性较差而时延较好,这是因为当权重系数β变小时,算法将更重视对时延的优化而减轻对公平性的注重。因此FL-TD3-0.3的时延优于其他所有算法。还可以看出,因为FL-TD3-0.3权重系数β较小,随着时隙的增长,FL-TD3-0.3的公平性相比于另两个多无人机算法的差距越来越大。其次,本文提出的FL-TD3算法优于DIS-TD3算法,这是因为本研究将联邦学习融入了多智能体深度强化学习框架中,联邦学习的加入让无人机之间能够信息共享,因此性能更优。最后,分析无人机数量对服务性能的影响,单无人机与多无人机相对比,仅依靠单个无人机对地面用户进行计算卸载任务服务,能够看出其性能低于多无人机算法。LOCAL-ONLY算法不能充分利用整个系统的计算资源,性能在所有算法中最差。 图5 公平性和时延累计随时隙变化Fig.5 Fairness and delay accumulation vary with time slots 图6展示了在无人机不同覆盖范围Rmax下,各算法的服务公平性和时延对比。其中地面用户数量恒定为20个。同样,本文为了对比优化问题中权重系数β对性能的影响,设置了对比算法FL-TD3-0.3。 图6 公平性与总时延随无人机覆盖范围变化Fig.6 Fairness and total latency vary with drone coverage 由图6可以看出,当无人机的覆盖范围增大时,所有算法的性能随之更优。具体来说,公平性均随覆盖范围的增大而变好;FL-TD3算法、FL-TD3-0.3、DIS-TD3的时延均随覆盖范围的增大而减短。这是因为随着无人机覆盖范围的增大,无人机能够在单个时隙内覆盖更多地面用户,从而丰富了无人机部署位置的多样性,最终提高了无人机服务地面用户的整体性能。相比本文提出的算法FL-TD3,随着覆盖范围变化,FL-TD3-0.3始终保持着公平性较差而时延较好的趋势,这是因为其权重系数β较小,使公平性的权重降低而时延的权重更高。本文提出的FL-TD3算法因其融入了联邦学习框架,使无人机之间能够实现信息共享。随着覆盖范围的增大,FL-TD3性能始终优于DIS-TD3算法。SINGLE-TD3算法覆盖范围在15~25 m区间时,可以看到时延能够随覆盖范围增大而降低。然而在30~45 m之间,时延几乎不变,只有微弱的降低,这是因为单个无人机无法在一个时隙内卸载过多地面用户,这会造成计算任务大量排队,使计算时延超过本地计算时间,无人机不再拓展更多计算卸载任务,所以在此区间内时延变化不大。对比其他算法,SINGLE-TD3的公平性、时延性能虽然能够随着覆盖范围的增大而变优,但是由于其无人机数量局限性,其性能差于所有多无人机算法。LOCAL-ONLY算法不能充分利用整个系统的计算资源,性能在所有算法中最差。 本文研究了多无人机辅助移动边缘计算的轨迹规划问题。针对计算密集型应用对时延具有较强的敏感性,采取将地面用户部分任务卸载到无人机上进行辅助计算。本文采用了一种联合优化策略,将无人机轨迹和任务卸载比例作为优化目标,旨在最大化任务时延和服务公平性的加权和,以确保在服务地面用户的过程中,最小化时延的同时兼顾无人机服务地面公平性。为实现多无人机能够协同对地面用户进行计算卸载服务,本文将联邦学习融入多智能体深度强化学习算法中,达到信息交互的目的。通过联邦学习非隐私数据共享的机制,既实现了多无人机间的信息共享使学习效果达到全局最优,又保障了数据隐私。仿真结果表明,与无信息交互的多智能体深度强化学习相比,本文提出的算法在无人机服务公平性和时延上具有更好的性能。1.4 问题描述
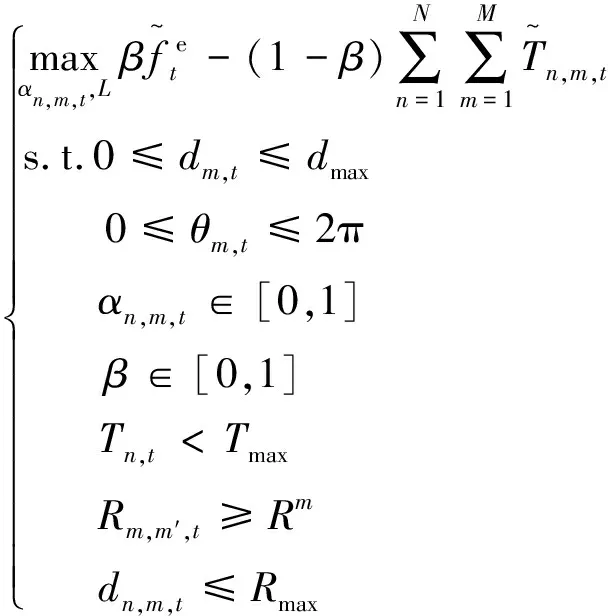
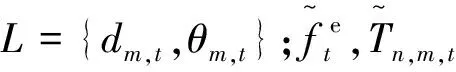
2 算法设计
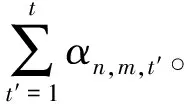


3 仿真结果和分析
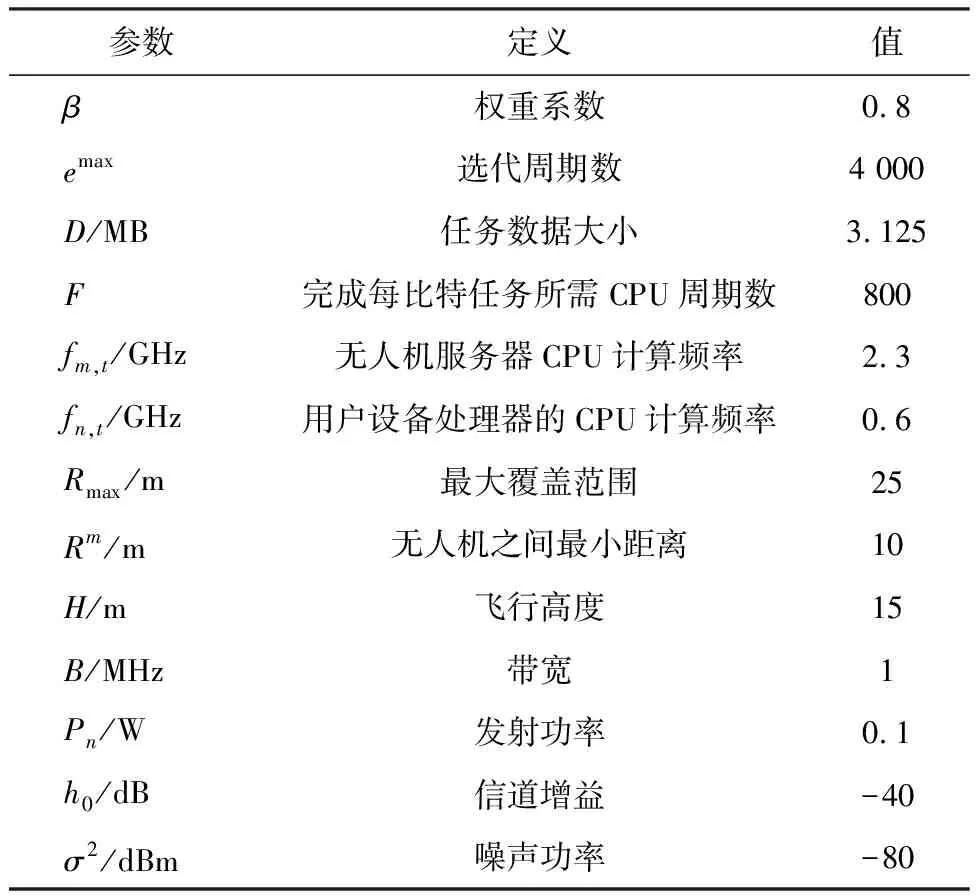
3.1 仿真设计环境参数和算法超参数设置
3.2 仿真性能分析
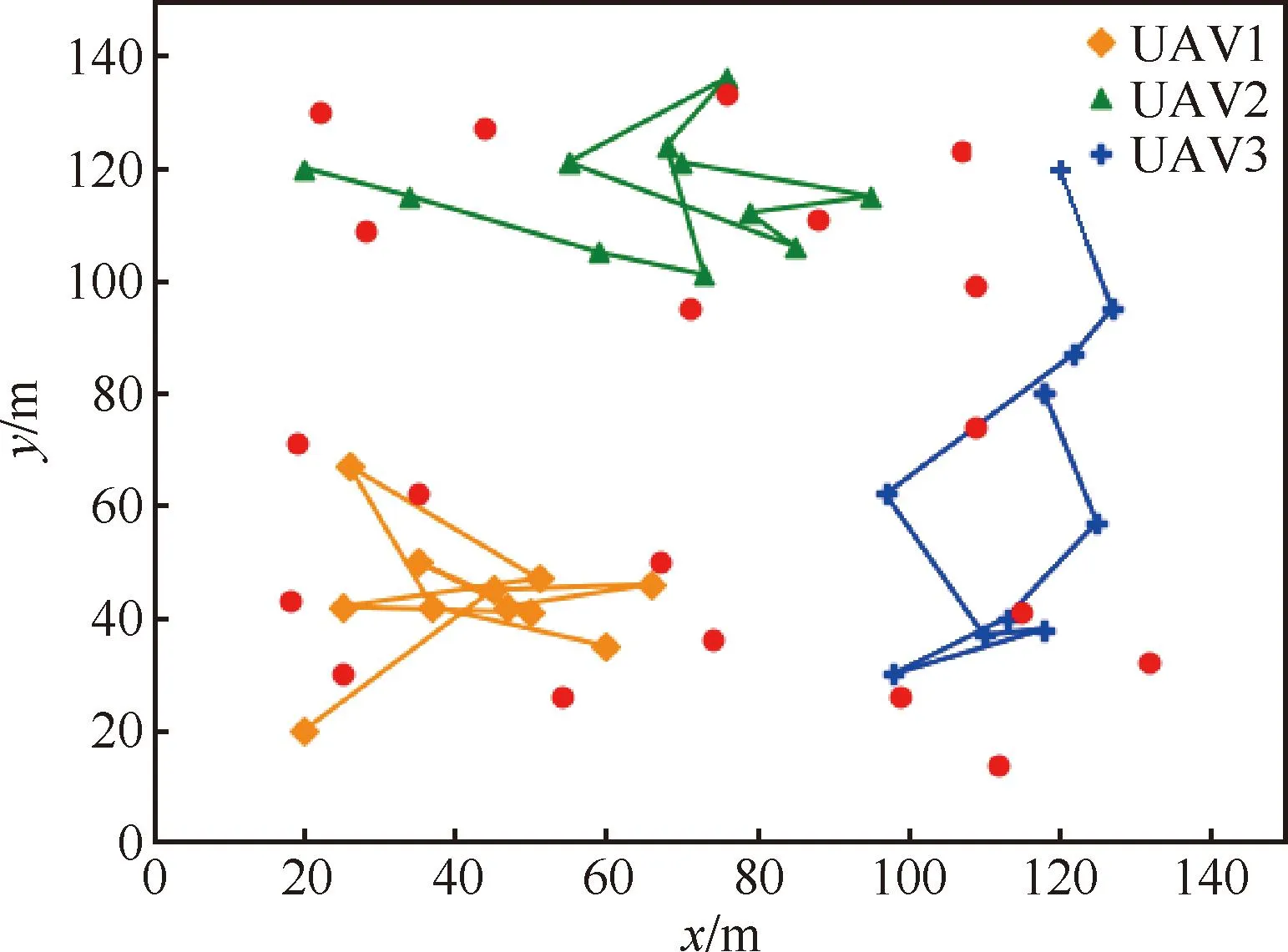
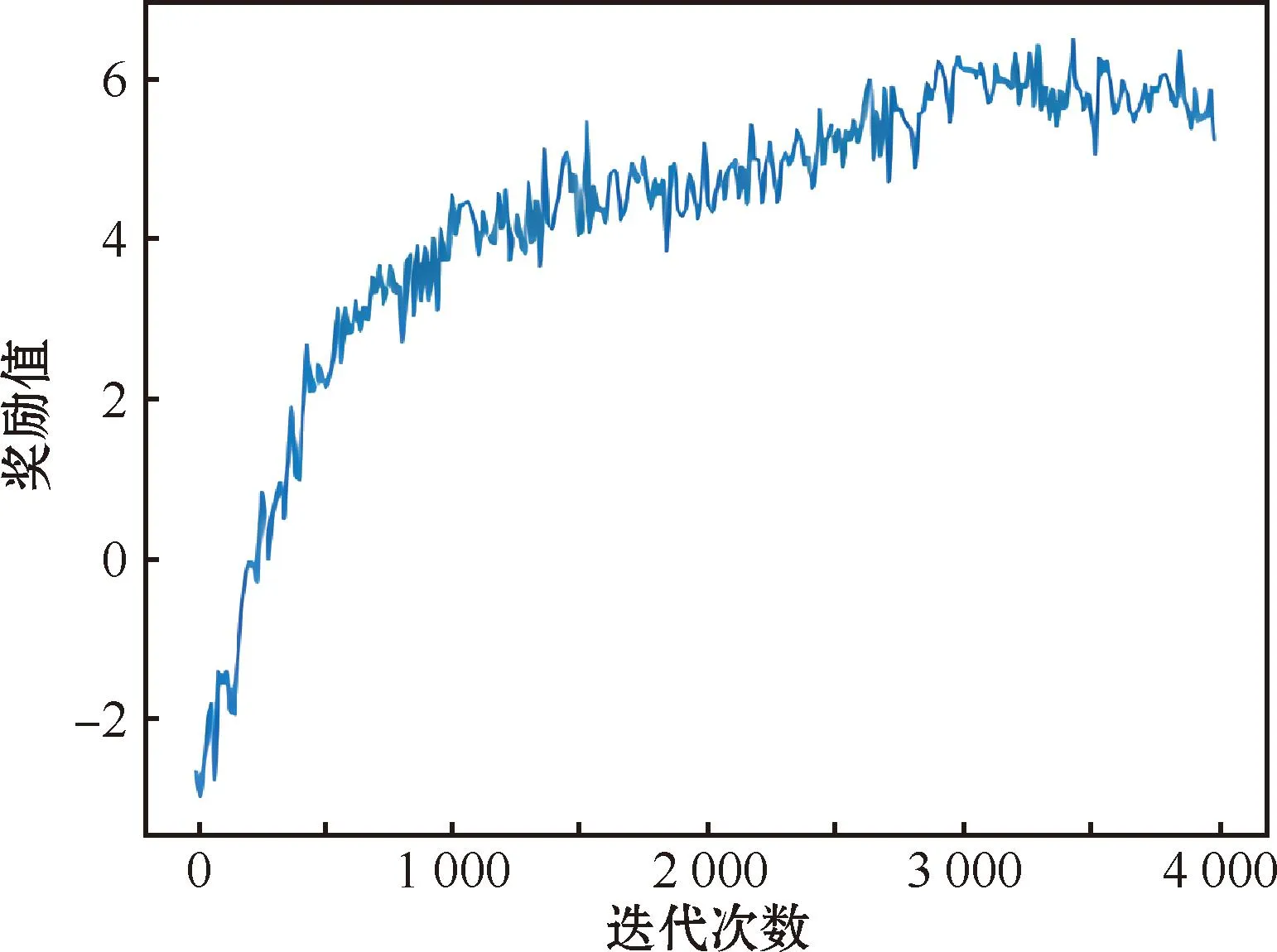

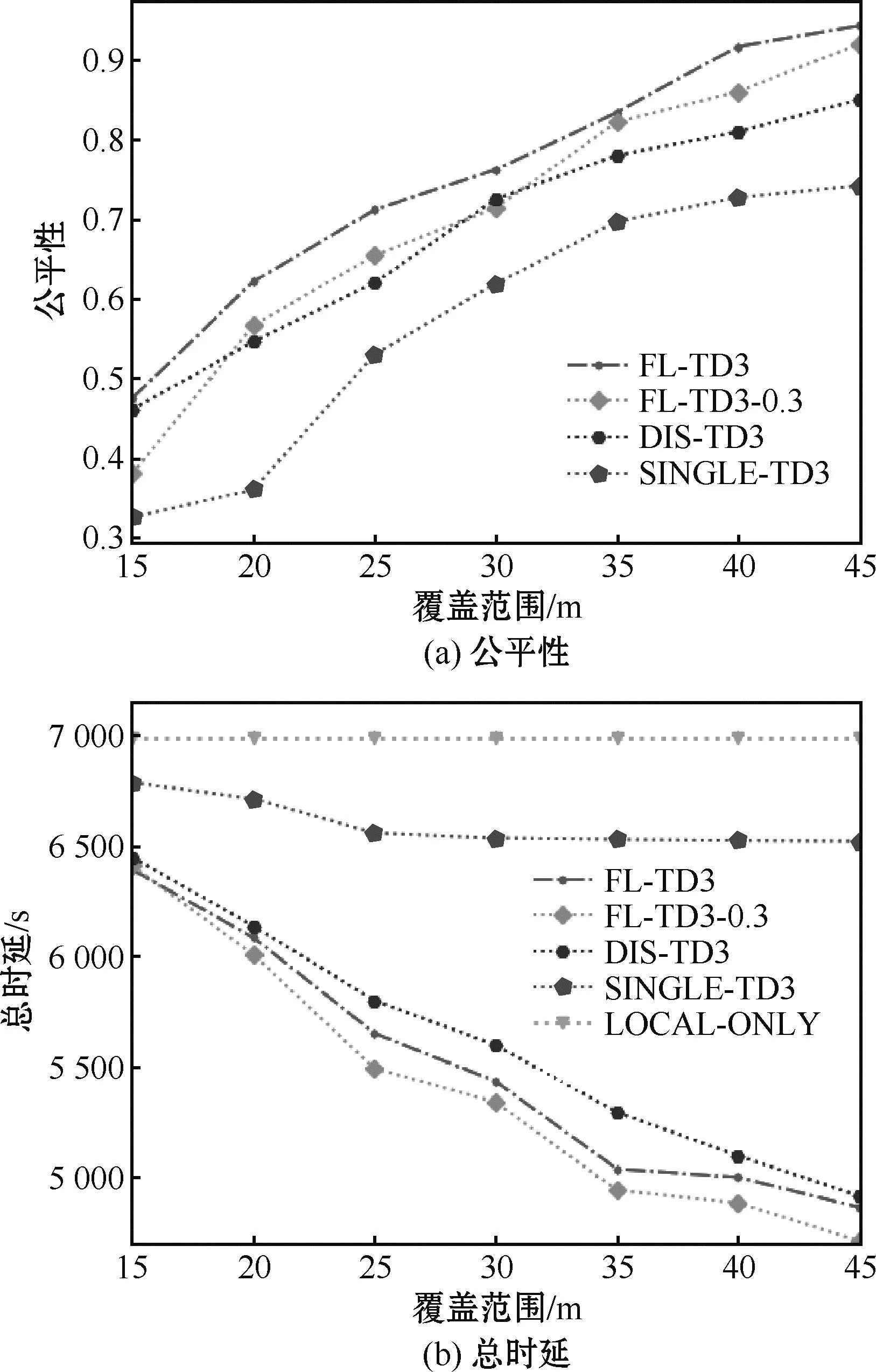
4 结束语
猜你喜欢
铁道通信信号(2018年9期)2018-11-10
电脑与电信(2018年12期)2018-03-23
电脑与电信(2018年11期)2018-02-16
舰船电子对抗(2016年3期)2016-12-13
高中生学习·高二版(2016年11期)2016-12-01
广西大学学报(自然科学版)(2016年5期)2016-11-12
电子制作(2016年23期)2016-05-17
科技视界(2016年9期)2016-04-26
中国卫生(2015年3期)2015-11-19
计算机工程(2014年10期)2014-06-07
