
一种多尺度特征关联网络的遥感影像场景分类方法
2024-01-05 11:10段烨陈国坤李佳田金维胡浩
遥感信息 2023年5期
段烨,陈国坤,李佳田,金维,胡浩
(昆明理工大学 国土资源工程学院,昆明 650093)
0 引言
在遥感技术快速发展的大背景下[1],对地观测卫星成为常用的数据源,遥感影像的应用变得日渐广泛。随着遥感影像的发展,影像解译作为解读遥感影像的方式也在不断地发展。遥感影像场景分类的目的是根据影像的关键特征内容,判断遥感影像上的地物类别。因遥感影像的分辨率不断提高,单张影像能涵盖的信息量变多,这一技术在地理学、生态学、城市规划等学科中受到关注和应用[2]。
在遥感影像的图像处理方面,单纯使用全局信息会错误地将背景当成关键特征,从而导致分类出现错误结果。因此,准确地获取局部特征信息至关重要,而融合多尺度图像信息和注意力机制可以很好地解决这一问题。多尺度图像信息提取是计算机视觉领域常用的方法,其中最有代表性的是特征金字塔。Lin等[3]提出特征金字塔网络(feature pyramid networks,FPN)用于目标检测,通过自顶向下和横向连接的过程,解决低层特征语义信息少的问题,实现图像中的多尺度融合。然而,FPN自顶向下的多尺度图像融合方式会将不同尺度的冗余信息和无关信息向下融合,无法更好地关注特征信息。注意力机制最早被引用于递归神经网络(recurrent neural network,RNN),直至Hu等[4]提出的SE-Net在卷积神经网络中使用了注意力机制。该网络将通道信息并入特征提取方法中,通过改变不同通道的权重指数来应用注意力机制。应用注意力机制后具有显著特征信息的通道被增强,使得卷积神经网络能够更好地关注特征信息。
2017年Transformer[5]模型在自然语言处理(natural language processing,NLP)领域的成效优于RNN与卷积神经网络(convolutional neural network,CNN)。该模型仅使用编解码结构和注意力机制就能取得很好的效果。Dosovitskiy等[6]将Transformer模型引用到计算机视觉领域,并提出了ViT (visual transformer)模型,所提模型在许多图像处理任务中表现出优异的性能。尽管ViT表现优异,但计算复杂度很高。为了解决这些问题,Liu等[7]提出Swin Transformer模型,将图像分为多个窗口,仅对每个窗口进行计算,从而限制了计算复杂度。通过滑动窗口的机制,使每个窗口的信息得到交互,既能实现多头自注意力的空间注意力效果,一定程度上也能减少网络的计算复杂度。
结合上述所表现出来的问题,本文提出一种新的多尺度特征关联网络。该网络结合了Swin Transformer中的滑动窗口多头自注意力(shifted window multi-head self attention,SW-MSA)模块、FPN结构和关联模块,采用空洞卷积进行影像特征提取,以扩大感受野来结合上文语义信息。此外,多头注意力模块中的滑动窗口方式可以提高局部信息的提取效率,其中借助FPN结构进行自上而下的融合,可实现更好地关注局部信息,减少多尺度影像直接融合的冗余信息,同时使用关联模块能进一步加强通道内的关键特征。实验结果表明,该方法能够提升MFC-Net网络的局部特征提取和背景抑制的能力,以提高遥感影像场景分类的精度。
1 研究方法
1.1 多尺度特征关联网络的遥感场景分类模型
本文提出的遥感场景分类模型由3个主要部分构成:多尺度影像提取部分、获取空间注意力与多尺度融合部分及多尺度特征关联与分类部分,具体如图1所示。
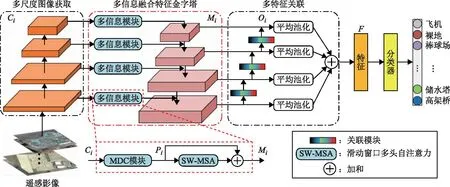
图1 MFC-Net结构
MFC-Net网络结构的核心思想为:将预处理影像输入ResNet-18架构,以获取多尺度图像Ci(i=1,2,3,4);将多尺度图像输入到多信息融合特征金字塔(multi-information fusion feature pyramid,MIF-FP)中,获取多尺度图像特征信息并进行融合输出Mi(i=1,2,3,4);将融合后的特征信息输入多特征关联部分,进行特征信息相互关联获取Oi(i=1,2,3,4),经平均池化后融合为特征F,再将F输入到softmax分类器中进行分类预测,输出预测类别。
1.2 多尺度图像提取
本文采用ResNet18作为多尺度图像提取的架构,其残差结构可以避免整个网络出现过拟合的情况,从而更好地提取所需的多尺度影像。
ResNet18的网络架构由5个Conv卷积层、1个全局平均池化层以及1个全连接层组成。本文使用ResNet18中前4个Conv卷积层来完成多尺度图像获取,输出结果如式(1)所示。
(1)
式中:Conv1、Conv2_x、Conv3_x、Conv4_x均为卷积层操作;I∈RH×W×C为预处理后输入的影像;H、W和C分别为输入影像的高、宽和通道数;Ci为多尺度特征图,分别为C1∈R(H/2)×(W/2)×64、C2∈R(H/2)×(W/2)×64、C3∈R(H/4)×(W/4)×128、C4∈R(H/8)×(W/8)×256分别为提取多尺度影像的结果。
本文未使用第5个卷积层进行多尺度图像提取,其原因为第5个卷积层输出的图像尺度较小,而小尺度图片在后面进行的获取空间注意力与多尺度融合部分中难以达到更优的效果。相比之下,大尺寸图像在使用空间注意力的效果更为明显。因此,选择特定的结构来进行多尺度图像提取,能够更好地提取所需的多尺度影像特征信息。
1.3 多信息融合特征金字塔
MIF-FP是基于FPN框架提出的一种融合多尺度图像特征信息的架构。较传统FPN结构,本文将空洞卷积与SW-MSA加入其中,提取的多尺度图像Ci经多信息模块后使其获得关注信息并进行上下层融合得到Mi,框架如图2所示。
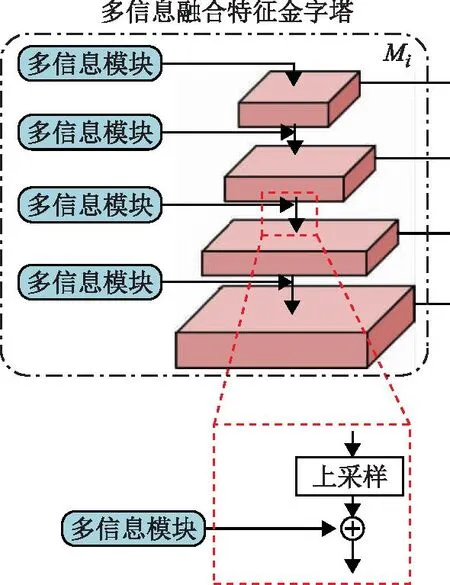
图2 MIF-FP结构
MI module如图3所示,其表达如式(2)至式(3)所示。
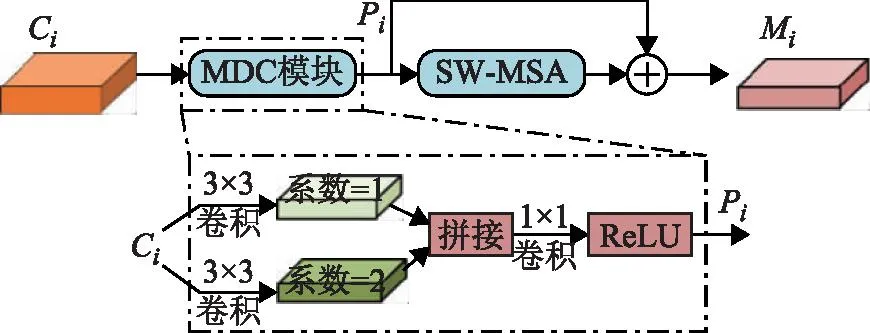
图3 MI module结构
Mi=attention{σ{Conv{Cat[MDC]}}}+Pi
(2)
MDC=DConv(Ci,1),DConv(Ci,2)
(3)
式中:Ci为ResNet18获取的多尺度影像;Pi为经过空洞卷积计算后得到的特征影像;DConv(Ci,r)表示对多尺度影像Ci进行扩张率为r的空洞卷积计算;Cat(·)为通道拼接操作;Conv(·)为1×1卷积操作;σ(·)为ReLU激活操作;attention(·)为滑动窗口注意力模块;Mi表示输出结果。
传统卷积局限于捕捉到特定位置的信息,忽略了上下文等密集语义信息。而空洞卷积通过调整扩张率,可以在不增加参数量的情况下获得更大感受野。这种方式在保证图像分辨率的基础上能提取较大范围的图像特征,可以有效地提取影像上下文信息[8]。在提取图像特征信息中,感受野越大所提取到的特征信息越接近于局部特征。不同于空洞空间卷积池化金字塔(atrous spatial pyramid pooling,ASPP)[9],本文仅使用较小扩张率的空洞卷积,这是因为在小尺度图像和分类任务中,主要关注小部分和小区域的特征以及其上下文信息,而过大的扩张率可能会获取到其他易混淆的特征。
SW-MSA是Swin Transformer中的滑动窗口自注意力模块,与传统的卷积空间注意力方式不同,SW-MSA通过将图片划分成M×M的窗口,这样的做法更加注重对局部信息的空间注意力计算,即将影像P∈RH×W×C划分为多个平面窗口,每一个窗口的训练参数为WQ、WK、Wv3个参数矩阵,对每个窗口进行多头自注意力计算,并且计算局部空间注意力时不会有过大的计算复杂度。同时加入滑动窗机制,使得每个窗口之间的信息能够相交互,其自注意力机制如式(4)所示。
(4)
式中:Q,K,V∈RM2×d表示为每个窗口的变量、关键字和关系值矩阵;KT为转置矩阵;B∈RM2×M2为相对位置偏置;d表示的是Q/K的维度大小;M2则表示为切分影像窗口的大小。
不同于传统FPN直接自上而下的融合,MIF-FP模块通过引入空洞卷积和SW-MSA空间注意力计算,获取更多有用的上下文语义信息,避免了直接融合的信息冗余问题。MIF-FP对每层获取的多尺度图像使用空洞卷积进行局部特征获取,经过空间注意力后能关注到各层图像的关键特征信息。MIF-FP结构能够对各层特征进行增强或抑制,以突出关键特征信息,如图4所示。传统FPN未添加特征增强或是抑制模块,容易融合周围无效信息,例如飞机类别图中无法准确关注到右上角的目标地物,且未能有效屏蔽周围无效信息;船类别图和储水罐类别图也存在类似问题,因影响特征的关注而导致分类错误。MIF-FP则能够有效抑制非关注特征,突出关键特征信息。
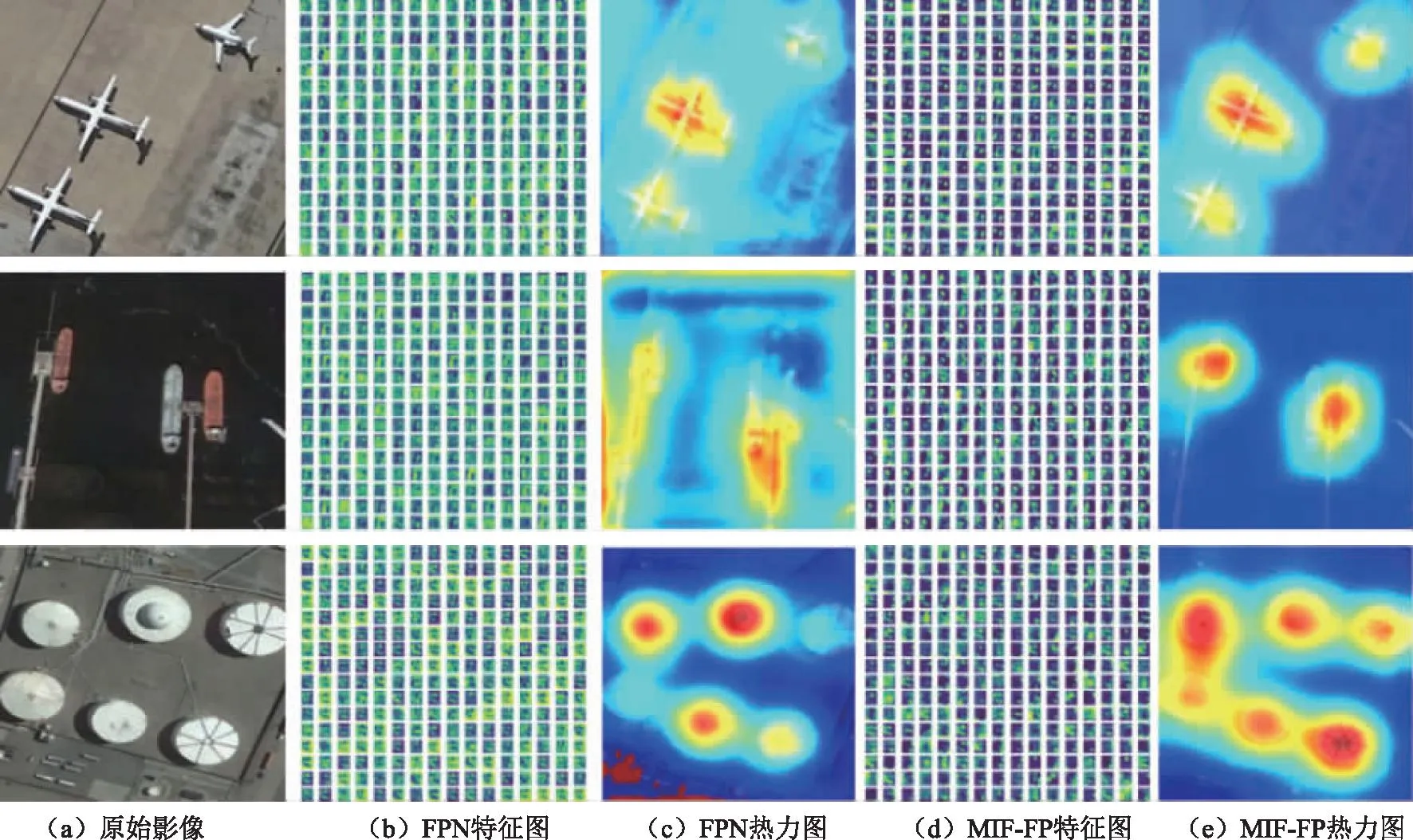
图4 热力图可视化
1.4 多尺度特征关联与分类
将MIF-FP输出的融合图像输入到多尺度特征关联部分进行最后的特征增强以及分类,主要架构如图5所示,具体过程见图6。
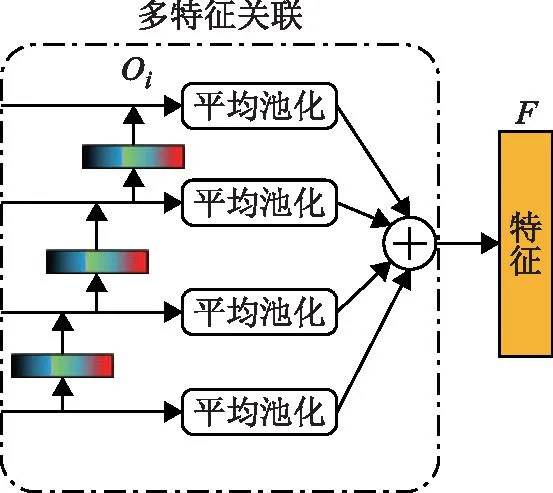
图5 多特征关联部分

图6 关联模块
关联是将Mi的相邻层进行相关联的操作。在多尺度图像中,底层图像通常包含着高层次图像的特征信息,并且Mi通过前一部分的空间注意力计算,高层图像的特征信息可以更好地融合到底层图像中。接着,经过MIF-FP后,各层多尺度图像的特征信息被提取到不同的通道中,使用关联模块将通道激活,与上一层的特征信息进行融合,加强关键特征的表现,抑制无效信息。因此,将底层特征与高层特征相融合,能够更好地突出分类中所关注的重要特征信息。其结构计算如式(5)所示。
Oi+1=FC(Gpool[Mi])⊗Mi+1=
δ(Conv2[σ{BN{Conv1{Gpool(Mi)}}}])⊗Mi+1
(5)
式中:FC表示卷积层运算;Mi(i=1,2,3)表示第i层的特征图;Oi+1(i=1,2,3)表示关联后的第i+1输出层;Gpool(·)为全局平均池化操作;Conv1(·)、Conv2(·)分别为降维1×1卷积和升维1×1卷积;BN(·)为批量标准化;σ(·)为ReLU激活操作;δ(·)为sigmoid激活操作;⊗为像素相乘操作。
最后将每层输出结果Oi(i=1,2,3,4)进行平均池化和加和操作,得到最后特征。通过网络计算最终得到F特征,输入分类器进行分类,使用交叉熵函数进行整体网络的损失计算。
2 实验方法
2.1 实验数据集
为验证所提网络架构的有效性,本文使用了两个公开数据集进行验证测试。
1)2017年武汉大学和华中科技大学共同发布AID(aerial image dataset)遥感场景影像数据集[10]。该数据集共包括30个场景类别,其中所有样本的图像均从世界上不同国家和地区采集获得,每个类别包含220~420张影像,每张图像为600像素×600像素,空间分辨率为0.5~8 m,总计有10 000张影像。
2)2016年西北工业大学发布的NWPU45(NWPU-RESISC45 dataset)数据集。NWPU45数据集包含飞机、教堂、沙漠等总计45个类别,每个类别有1 000张影像,影像空间分辨率为0.2~30 m,总计有31 500张影像,包含超过100个国家与地区的影像。
2.2 评价指标
本文所提方法的有效性通过使用总体分类准确率(overall accuracy,OA)、Kappa系数和F1值来评估。OA为经过计算后正确分类的样本数占测试集总样本数的比例,它反映了数据集总体的分类情况。Kappa系数是一个衡量分类效果和检验分类一致性的指标。分类一致性是指模型预测结果和实际分类结果是否一致。基于混淆矩阵计算得到Kappa系数,通常系数值落在0~1之间。F1值是精确率和召回率评估指标。
2.3 实验配置
本实验基于中国移动云服务器完成,操作系统为Ubuntu 18.04.3 LTS,GPU为Tesla V100。实验基于Pytorch V1.10.1框架进行,其中超参数设置迭代次数为100,批处理大小为32,学习率为0.000 1。优化器采用Adam优化器,权重衰减为0.001,使用交叉熵函数作为损失函数。
2.4 实验结果
在公共数据集上使用本文方法与现有已知相关分类方法进行对比实验,以确保本文方法的有效性。AID数据集和NWPU数据集的训练比例分别为50%和20%。首先,对两种不同多尺度影像输入方式进行比较;接着,进行不同扩张率的空洞卷积对比,并比较不同注意力机制的效果;最后,与其他方法进行对比。对比方法包括传统简单路线的VGG_VD16、传统路线网络的改进算法如VGG_VD16加入MSCP模块[11]、多分支网络DCCNN[12]、多分支注意力池化网络APDC-Net[13]、深度迁移可变形卷积神经网络DTDCNN[14]、注意力一致网络ACNet[15]以及基于自注意力融合特征的SAFF[16]。表1表示在AID和NWPU数据集上不同算法的精度结果。

表1 不同提取方式的分类精度
本文使用两种不同获取多尺度影像方式进行对比。第一种输入方式使用ResNet-18中后4个Conv卷积层的输出结果,第二种输入方式使用前4个Conv卷积层的输出结果。
从表1能够看出,在相同的网络架构下,本文使用的提取方式2在两个数据集的分类精度上提升1%左右。主要原因在于多尺度融合过程中,大尺寸的影像能够获得更多有效的特征。引入滑动窗口多头自注意力机制,能够将影像进行切割并获取各个小块的特征,而更大尺寸的影像能使影像切割进入更多的信息,有利于使用空间注意力。
本文对两个数据集使用了3种不同膨胀方式的卷积模块,并进行结果对比分析。由表2的实验结果可以看出,与不使用空洞卷积和使用较大膨胀系数的空洞卷积相比,本文使用的较小膨胀系数卷积模块分类总体精度提高1%左右。同时,使用较大膨胀系数的空洞卷积模块所用时间更长。因此,在时间效率方面,本文所使用的小膨胀系数的模块具有优势。

表2 不同膨胀系数的卷积模块
为探究注意力机制对于模型性能的影响,在多尺度特征关联网络中,使用SE(squeeze-and-excitation)和CBAM(convolutional block attention module)[17]两种注意力机制,分别在两个数据集上进行分类测试。结合表3给出的结果,可以看出在没有使用注意力机制的网络中,分类精度能达到93.82%和89.38%的分类效果,说明整体网络在框架上具有一定的优势。两个注意力机制在分类总体精度上较SW-MSA差1%左右。注意力机制在金字塔这种多层特征融合的框架上有一定的影响,注意力能力越强且复合的模块能更有效地利用这种特征融合框架。
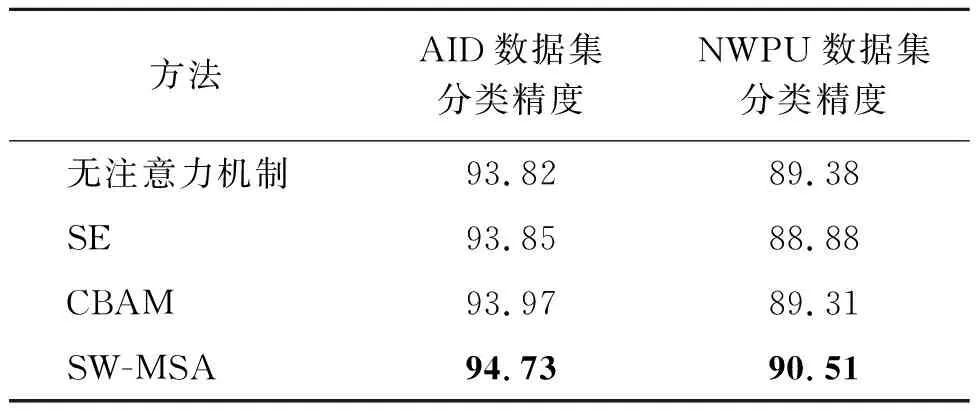
表3 不同注意力方法的分类精度 %
在AID数据集中,MFC-Net比经典单一路线网络VGG_VD16精度高5.09%;较经典网络中添加特征融合算法的AlexNet-MSCP提升2.37%,与网络层数更深的VGG_VD16-MSCP效果相当;较密集连接的特征增强网络DCCNN和多分支注意力池化网络APDC-Net分别提升3.24%和2.58%;较经典网络中添加自注意力机制的VGG_VD16-SAFF提升0.9%;相比于迁移可变形卷积网络DTDCNN提高5.47%;略低于使用约束注意力机制ACNet的95.38%。从上述结果可以看出,MFC-Net在特征提取、融合和增强方面与具有更深层次的特征提取层网络VGG_VD16-MSCP和ACNet相当。
AID数据集中主要的易混分的类别有旅游胜地、广场与公园。公园与旅游胜地存在相近地物,广场与旅游胜地存在相似形状的情况,如图(7)所示。这几类地物复杂且周围地物会对其分类产生影响,关键特征地物受到周围信息影响从而错误分类(图7)。

图7 在AID数据集上的易混分类别
NWPU数据集较AID数据集地物种类多,图像数量大且有部分地物易混分,因此在分类精度上不如AID,本文方法较多数对比方法可以取得更高的分类精度。较传统VGG_VD16提升10.72%;较VGG_VD16-MSCP提升1.58%,整体效果相当;较AlexNet- MSCP提升4.93%;较多分支网络的DCCNN和APDC-Net分别提升4.88%和2.67%;比VGG_VD16-SAFF的精度高2.65%,较AID的提升效果更大;AlexNet-SAFF与本文方法精度差距较VGG_VD16-SAFF更大;相较于DTDCNN提升6.39%;低于ACNet的92.42%。NWPU中,对于无易混分类别的地物,MFC-Net能准确提取并增强地物特征,但易混分地物中,金字塔和关联模块的特征获取能力还有待进一步提高。
NWPU数据集中最容易混分的是教堂和宫殿。宫殿的部分建筑物类型与教堂中的主要建筑物十分相似,多尺度融合以及注意力机制的运用不能很好地进行区分。另外,火车站分类成为铁路,如图8所示,二者类别中火车站通常包含着铁路的地物特征信息,但当图像内容复杂多样且火车站特征地物较小时,空洞卷积和多尺度融合会丢失掉火车站特征信息,无法正确找到此类的关键特征,因此错误分类为铁路。

图8 在NWPU数据集上的易混分类别
表5展示了不同方法的网络参数量。由表4和表5看出,MFC-Net在两个数据集的总体分类精度上均优于VGG_VD16、VGG_VD16-MSCP、AlexNet- MSCP、DCCNN、APDC-Net、VGG_VD16-SAFF以及DTDCNN,较ACNet稍低;网络参数量低于其余网络,稍高于DCCNN和APDC-Net。
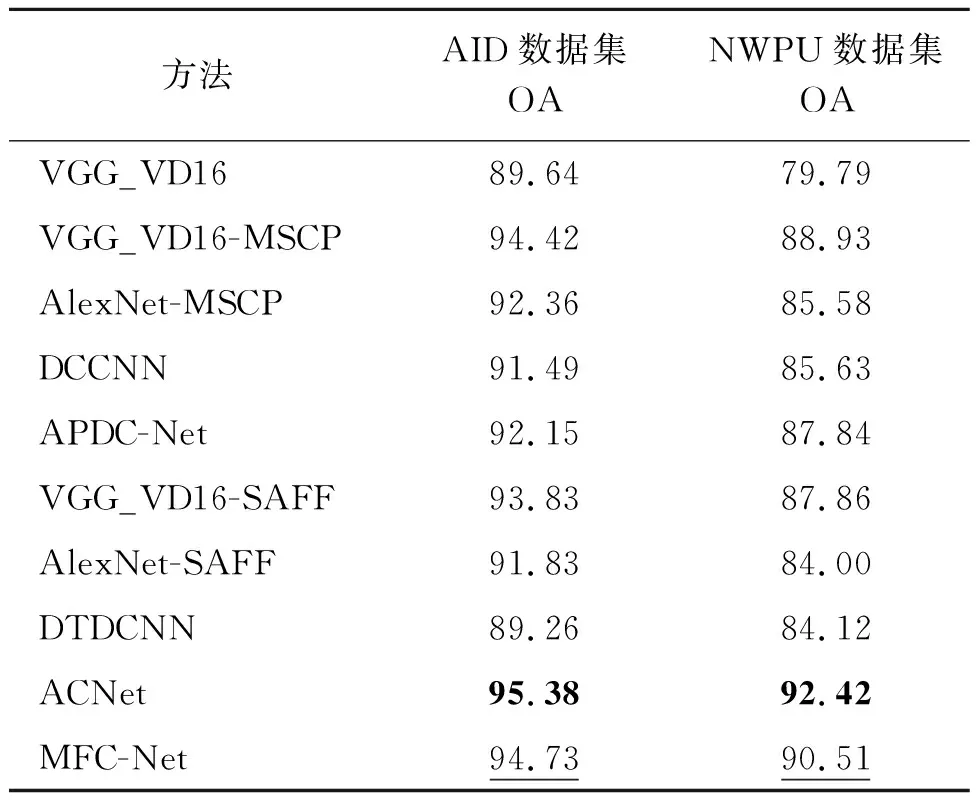
表4 不同方法在两个数据集上的分类精度 %
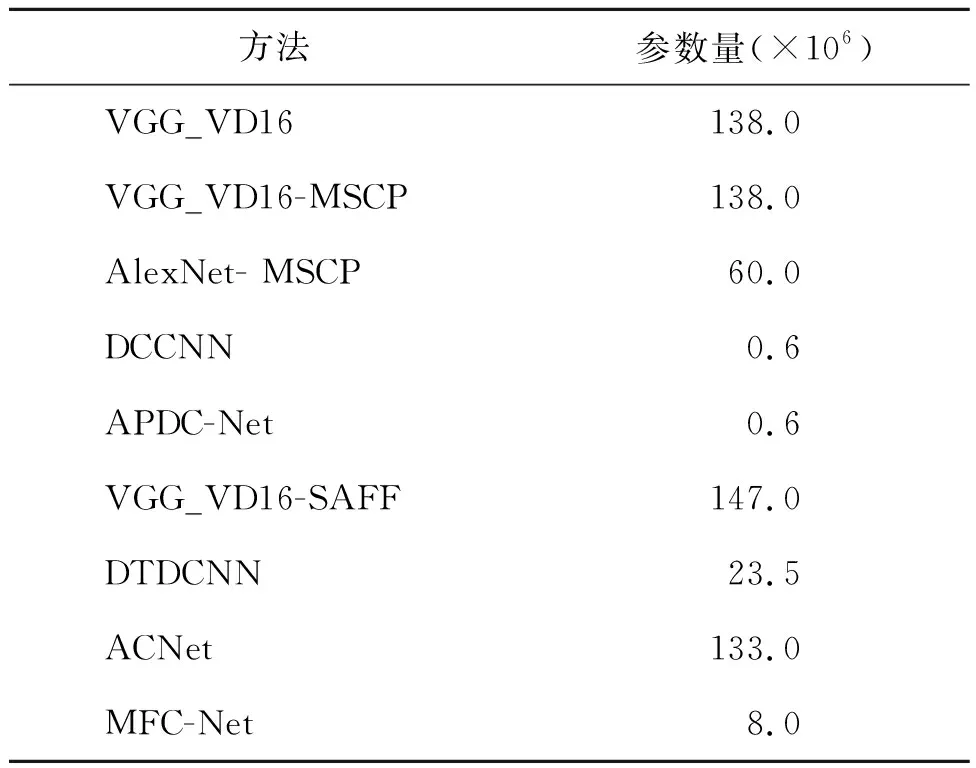
表5 不同方法的参数量
MFC-Net将空洞卷积和滑动窗口多头自注意力模块融入金字塔结构,使其在遥感影像的场景特征提取上较上述对比网络有更优的提取和抑制能力,且多特征关联部分能在提取准确的前提下更好地增强特征信息。
相较于总体分类精度相近的ACNet网络,虽然ACNet的分类精度略优于本文方法,但MFC-Net网络的参数量仅为其十六分之一,其他参数量较少的网络分类精度较低。因此,结合考虑精度和参数量的综合表现,MFC-Net网络具有一定的可用性。
2.5 消融实验
本文方法中添加空洞卷积模块、滑动窗口多头自注意力模块以及特征关联模块。本小节使用NWPU数据集对本文方法进行消融实验,验证各个模块的有效性。表6为消融实验的结果。
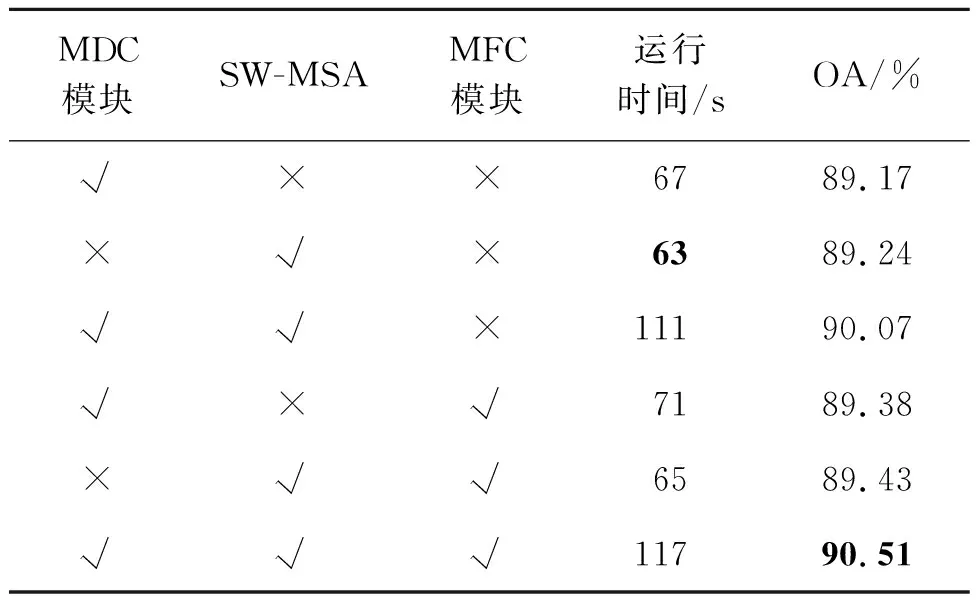
表6 消融实验
从表6结果看出,滑动窗口多头自注意力模块和空洞卷积模块对网络的提升效果相当。两个模块结合在一起能更有效地提高分类精度,结合多尺度特征关联模块能达到最优效果。主要原因是仅使用空洞卷积虽然能联系上下文语义信息,但却无法更多地关注关键特征。引入滑动窗口多头自注意力模块后,可以在空间域上增强通过空洞卷积所获得的特征,从而更好地关注关键特征,因此能有更好的效果。
3 结束语
MFC-Net以ResNet18为多尺度提取网络,使用特征金字塔结构多尺度融合的基础框架。此外,MFC-Net结合空洞卷积模块和滑动窗口多头自注意力机制模块,以获得图像多尺度特征信息、多尺度注意力获取以及多尺度特征图像有效融合的效果。同时,MFC-Net采用多尺度特征关联来增强提取特征之间的信息交互,通过多尺度特征加和的形式增强最终特征,最后进行有效的场景分类。实验结果表明,在两个大型且具有挑战性的数据集上,场景分类总体精度较高。MFC-Net在多尺度图像获取部分过滤小尺寸图像,使用大尺寸图像结合空洞卷积的方式来提取局部、小区域的特征信息。此外,MFC-Net网络内部使用Swin Transformer多头自注意力模块以增强特征提取效果。实验结果证明该方法能有效提高分类精度,较Transformer类网络,参数量更少、时间成本降低,表明了MFC-Net网络的优越性。后续将研究在多尺度图像融合部分中添加有效的判断机制,提高特征增强的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
