
基于钻录测数据驱动的储层可压性无监督聚类模型及其压裂布缝优化
2024-01-06 03:08胡诗梦盛茂秦世勇任登峰彭芬冯觉勇
石油科学通报 2023年6期
胡诗梦 ,盛茂 *,秦世勇,任登峰,彭芬,冯觉勇
1 中国石油大学(北京)人工智能学院,北京 102249
2 中国石油大学(北京)油气资源与工程全国重点实验室,北京 102249
3 中国石油天然气股份有限公司塔里木油田分公司,库尔勒市 841000
0 引言
储层可压性评价是提高非常规油气压裂均衡改造效果的先决条件之一,特别是针对岩石非均质性强的储层,客观上易造成裂缝无序起裂、扩展不均的非均衡改造难题,亟需定量评价储层可压性沿井筒非均匀分布特征,优选布缝位置在可压性相近的井段,实现多簇裂缝间同步起裂、均衡扩展。
目前储层可压性评价按照原理分类,可分为基于矿物组分的可压性评价和基于岩石力学性质的可压性评价。后者通常是基于测井资料中的纵波速度、横波速度和密度测井值[1-7],根据理论公式,计算目的层段的岩石力学参数;基于岩石断裂力学理论推导组合测井解释的力学参数,获得储层可压性数值[8-11]。然而对于岩石各向异性强的储层,常规测井理论公式难以适用并修正,应用效果不均衡,单纯依靠测井数据间接表征储层可压性难以满足精细评价需求。近年来,钻井机械比能被用于表征储层岩石抗压强度,定量评价储层可压性沿井眼轴向分布,将压裂裂缝布置在机械比能数值相近的井段,应用区块平均提产27%[12-13]。该方法依赖钻录井数据,需去除钻杆与井壁摩擦、钻头磨损等因素对井底机械比能的影响,获得纯钻头破岩所需的机械比能,其有效性取决于模型的准确性。
为此本文利用钻头破岩数据直接反映岩石力学参数的特点,融合钻录井数据和测井数据,不依赖于机理模型,通过相关性分析优选特征参数,采用主成分降维,建立了基于SOM无监督聚类算法的储层可压性聚类模型,手肘法确定储层可压性最优聚类数,形成了压裂布缝位置参数优化方法。针对塔里木盆地超深巨厚储层典型井分层压裂,聚类得到了储层可压性沿井轴方向分布情况,优化设计了布缝位置,有望实现均衡压裂改造。
1 特征参数选取及数据预处理
1.1 特征参数选取
以钻录井数据和测井数据为基础,如表1 所示,选取与储层可压性具有潜在相关性的特征参数。其中,钻录井数据是钻头—岩石相互作用的综合结果,可直接反映原始地应力和天然裂缝原位状态下岩石力学参数[14-15]。选取钻头钻压、转盘转速、扭矩、钻时、dc指数、钻头尺寸等6 类钻井特征参数。测井数据可间接反映岩性变化和岩石动态弹性模量、泊松比等岩石力学参数[16-17],选取井径、中子、密度、声波时差、自然伽马、地层电阻率等6 类测井特征参数。同时,选取钻井机械比能[18],如式(1),其数值反映岩石抗压强度[19],已被用于储层可压性评价。

表1 特征数据类型统计Table 1 Statistics of characteristic data
式中,WOB为钻压,KN;RPM为钻头转速,r/min;Tor为钻头扭矩,KN·m;Ab为钻头横截面积,mm2;ROP为机械钻速,m/min。
采用皮尔逊系数的相关性分析[20]筛选出与储层可压性相关的特征参数。皮尔逊相关系数的变化范围:-1~1,两个变量关联程度越强则该系数绝对值越大,即接近于1 或-1,两个变量关联程度越弱则该系数越接近0。通常按照皮尔逊关联系数取值划分参数间相关性:极强关联0.8~1.0,强关联0.6~0.8,中等强度关联0.4~0.6,弱关联0.2~0.4,极弱关联或无关联0.0~0.2。选取钻井机械比能作为储层可压性目标参数,皮尔逊相关系数绝对值如图1 所示,筛选去除极弱相关性与无关联的井深、钻头尺寸、井径、自然伽马等特征参数,最终筛选出7 个特征参数:钻时、dc指数、钻压、扭矩、地层电阻率、声波时差和中子测井,作为无监督聚类模型输入参数。
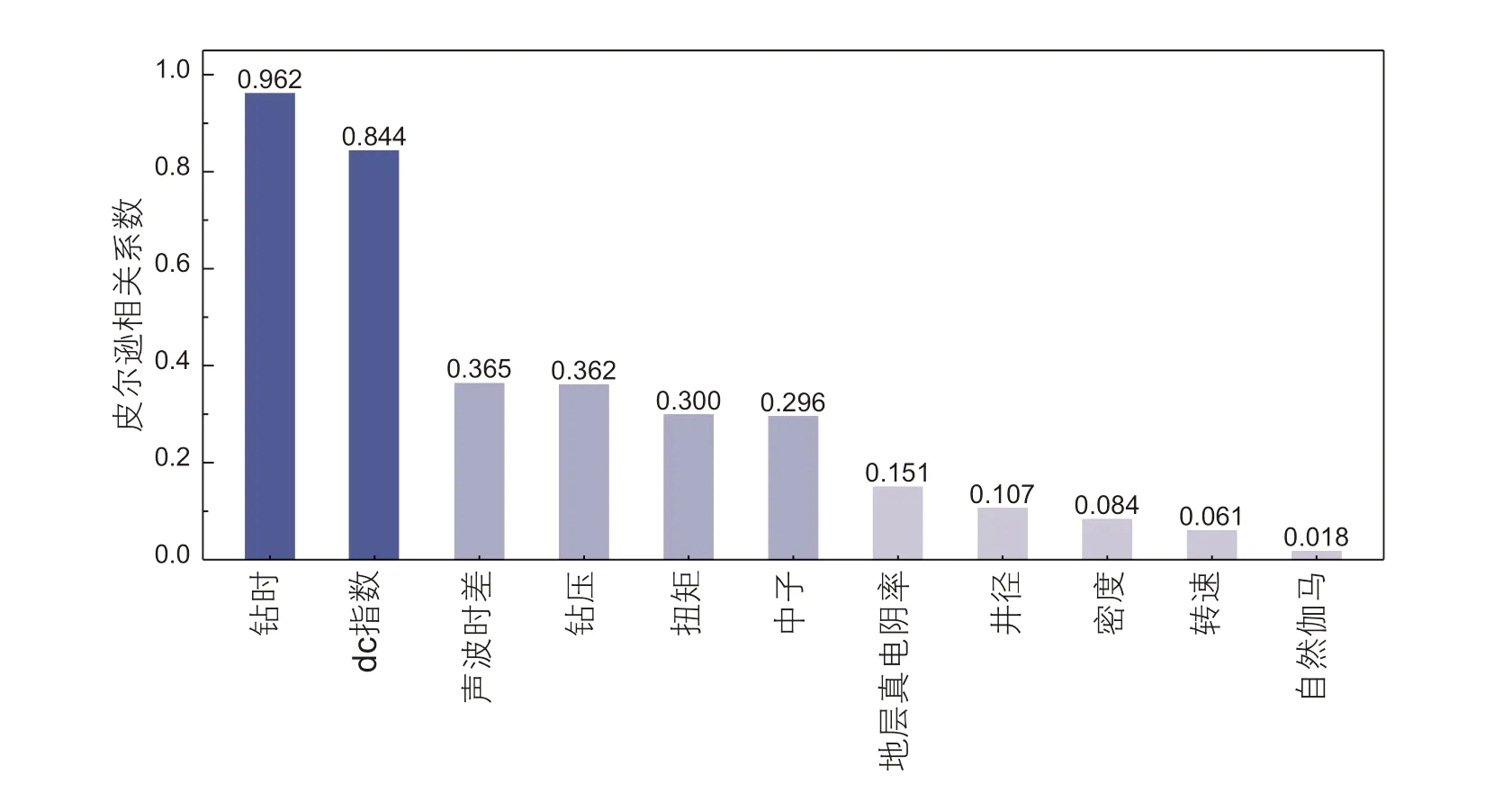
图1 皮尔逊相关系数柱状图Fig. 1 Histogram of Pearson correlation coefficient
1.2 数据完整性和标准化处理
原始数据完整性处理包括统一不同来源的数据、统一数据格式、补充遗漏缺失数据。针对钻井和测井数据尺度差异性,对应至同一单位尺度。选取KNN近邻算法填补缺失值,基于欧式距离最短的点来识别空间相似或相近的K个样本,获得距离矩阵,然后使用这些“K”样本来估计缺失数据点的值[21]。该方法因考虑高维空间中的多维数据样本间的相关性,其填补缺失值更加精确。本文所使用样本数据集来源于塔里木盆地一口深部巨厚储层直井的钻录井和测井数据,共149 个数据样本点,每个样本点分别包含7 维特征参数。
由于数据类型、计量方式及单位不同,将样本特征值转为无量纲数值,让不同维度之间的特征在数值上具有可比较性。采用Z-Score标准化方法,如式(2)所示,将数据按属性通过减去均值然后除以标准差,经处理后的数据符合标准正态分布,即均值为0,标准差为1。
式中,xnew为处理后数据值;x为原始数据值;μ为数据均值;σ为数据标准差。
2 模型建立与压裂布缝优化
2.1 自组织特征映射神经网络无监督聚类原理与模型建立
储层可压性无监督聚类建模流程如图2 所示,采用无监督学习方式对7 个特征参数进行无监督多维聚类,无需额外标签发掘样本间的内在联系和区别。常规无监督学习算法包括K均值聚类和层次聚类等基于欧式几何距离的算法,均需人为设定聚类类别数,人为因素不可避免。为此,优选自组织特征映射神经网络(Self-Organizing Map, SOM)算法[22],该算法无需人为设定聚类类别数,即可识别特征参数的内在关联性。

图2 储层可压性无监督聚类模型建立流程图Fig. 2 Flow chart of unsupervised cluster model of reservoir fracability
本文构建的SOM神经网络模型为二维平面阵,如图3 所示,包含输入层和输出层,该结构是SOM经典组织方式,具有大脑皮层形象,融入了人脑神经元信号处理机制,基于“竞争学习”方式,依靠神经元之间互相竞争逐步优选网络。输入层是由钻头钻压、扭矩、钻时、dc指数4 种钻井数据和声波时差、自然伽马、中子3 种测井数据模拟成的7×1 维矩阵,输入层神经元通过权向量将样本信息汇集至输出层神经元,通过迭代训练调整网络权向量的值,使得训练结束时输出层神经元可以反映样本内在联系,最终实现不同储层可压性聚类。训练模型前,预先设置合适的神经元竞争节点数,最大迭代次数,neighborhood函数和学习率,以实现较好的模型收敛性。在后续迭代过程中,权向量按照式(3)更新:
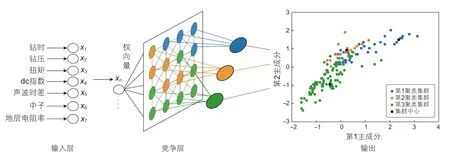
图3 自组织映射神经网络模型示意图Fig. 3 Schematic diagram of self-organizing mapping neural network model
式中,η(t)为t时刻神经网络学习率;wij(t)为t时刻输入层第i个神经元和竞争层第j个神经元之间连接的权向量;t∈[1,500]。
每次迭代后,模型将计算竞争层的第j个神经元与输入层X之间的欧式几何距离,公式如(4):
模型按预设条件迭代训练,未达到要求则继续,否则结束训练。样本将在输出层中找到最匹配的节点,得到各样本所属类别。后续通过主成分分析(Principal Component Analysis,PCA)方法,基于特征值分解方法计算各样本点与聚类中心点距离,将原始高维特征映射到二维上,达到样本聚类结果可视化目的,并绘制如图3 所示的储层可压性聚类结果。
2.2 压裂布缝优化方法
根据储层可压性无监督聚类模型所得结果,如图4 所示,沿井深划分若干压裂段,布缝位置参数优化考虑3 个条件:(1)选择同一类别的储层可压性位置布缝;(2)同一压裂段内优先选择占比多的可压性集群区域布缝;(3)同一压裂段内,簇间裂缝间距考虑应力干扰作用。
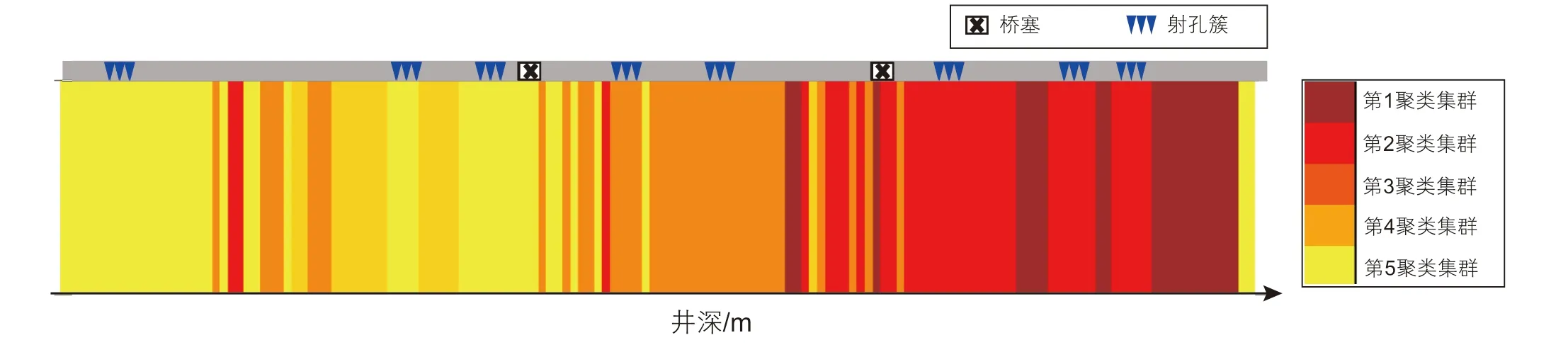
图4 布缝位置优选方法Fig. 4 Optimization method of fracture placement
3 模型应用与分析
K13 井是塔里木盆地一口深部巨厚储层直井,设计井深7465 m,压裂目标井段为白垩系巴什基奇克组7306.0~7455.0 m,改造储层厚度达149.0 m,岩性以褐色中砂岩、细砂岩为主,夹薄层褐色含砾砂岩、泥质粉砂岩、粉砂岩及少量泥岩,储层非均质性强。
收集该井钻压、扭矩、钻时、dc指数、中子、声波时差、地层电阻率等7 个特征参数,建立自组织特征映射神经网络模型,实例中将SOM网络竞争节点数字设置成8×8,最大迭代次数设置为500,neighborhood函数设置为gaussian函数,学习率设置为0.5,该训练条件下所得聚类结果具有较好的收敛性。通过主成分分析(PCA)方法,将原始7 维特征映射到2 维上,实现样本聚类结果可视化,如图5 所示,第一聚类集群的第一主成分主要介于-1.8~1.9,第二主成分主要介于-2.5~0.8;第二聚类集群的第一主成分主要介于0.1~3.3,第二主成分主要介于0.1~2.0;第三聚类集群的第一主成分主要介于-1.8~0.4,第二主成分主要介于-2~0.9;第四聚类集群的第一主成分主要介于-0.5~1.3,第二主成分主要分布在0~1.5;第五聚类集群的第一主成分主要介于-0.6~0.4,第二主成分主要介于-0.5~1.2。各类储层可压性聚类集群中心点之间有较为明显差异,说明SOM模型聚类结果是有效的。
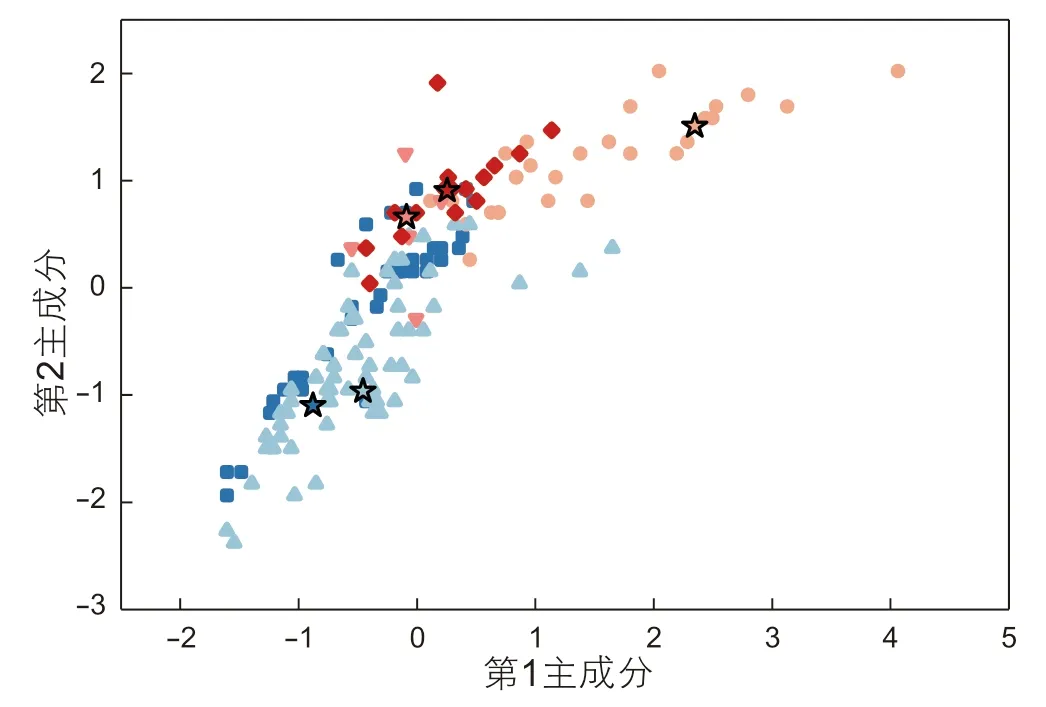
图5 基于PCA的聚类结果可视化Fig. 5 Visualization of clustering results based on PCA
沿井深的储层可压性聚类结果如图6(a)所示,图中不同颜色代表不同可压性等级,利用钻井数据计算机械比能值,绘制其沿井深剖面的折线图,如图6(b)所示。对比可知,由机械比能计算得到的岩石强度分布情况与所建立的基于自组织映射神经网络的储层可压性聚类结果有相似的分布趋势,验证了本文模型聚类的有效性。
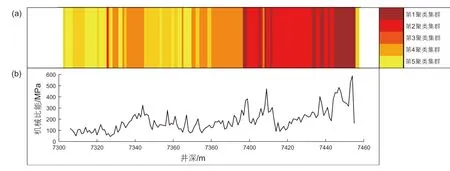
图6 聚类结果与机械比能的对比Fig. 6 Comparison of clustering results with mechanical specific energy
压裂布缝位置优化结果如图7 所示,目标井段7306.0~7455.0 m划分为3 个压裂层段,每层段多簇射孔3~5 簇。根据储层可压性聚类结果,每层段的射孔簇布置在同类储层可压性井段。结果表明,储层可压性沿井筒轴向差异性显著,本模型融合钻头破岩录井数据,可综合体现地应力、天然裂缝分布、岩石力学参数等对储层可压性的影响;不依赖于机理模型,而是数据驱动分类评价储层可压性。然而,本模型仍无法定量刻画不同类别储层可压性的数值差异性,同时在布缝位置优化中未定量评价缝间应力干扰作用。
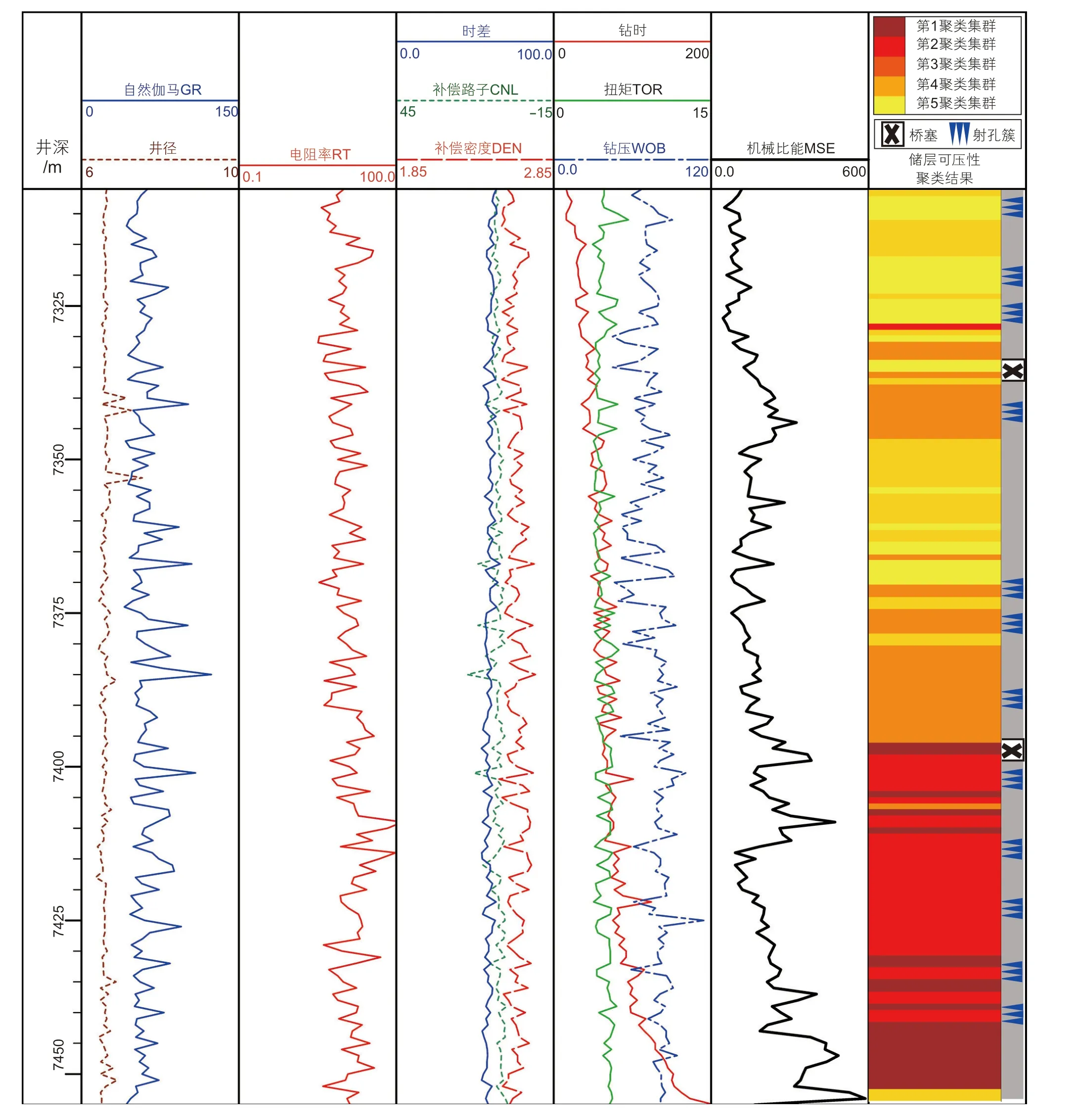
图7 K13 井沿井深压裂布缝位置优化设计Fig. 7 Optimal design of fracture placement along well depth for K13 well
4 结论
本文利用钻头破岩数据直接反映岩石原位状态下力学参数的特点,融合钻录井数据和测井数据,不依赖于机理模型,通过相关性分析优选特征参数和主成分降维,建立了基于SOM无监督聚类算法的储层可压性聚类模型。聚类结果综合体现了地应力、天然裂缝分布、岩石力学参数等对储层可压性的影响。相关性分析表明,钻井钻时、dc指数、钻压、扭矩和测井地层电阻率、声波时差和中子等参数与储层可压性显著相关;模型可有效区分储层可压性沿井筒轴向的差异性,优选同类别储层可压性井段布置裂缝,有望提高均衡压裂改造效果。
猜你喜欢
西南石油大学学报(自然科学版)(2022年2期)2022-04-23
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
制造技术与机床(2017年11期)2017-12-18
断块油气田(2017年3期)2017-06-07
中南大学学报(自然科学版)(2016年2期)2017-01-19
浙江中医杂志(2017年4期)2017-01-14
潍坊学院学报(2016年6期)2016-04-18
石油知识(2016年2期)2016-02-28
江西煤炭科技(2015年1期)2015-11-07
