
基于网络流量分析的自适应用户行为识别技术
2024-01-06 04:03李国军
浙江警察学院学报 2023年6期
杨 雪 李国军 徐 博
随着网络技术的发展,Web应用随之普及,电子商务、电子政务等相关网站给人们的生活带来极大的便利。然而,Web技术也为社会带来一些负面影响,不法分子常利用网站开展色情传播、赌博或电信诈骗等违法犯罪活动。从网络流量中自动关联相应的Web应用已成为网络管理员必备的一项技能。SSL/TLS等端到端加密协议能够保护通信的具体内容但并未隐藏网络流量中报文的长度、方向、时序等边信息,因此仍会遭受利用。目前,网站指纹识别领域的研究人员通常利用机器学习算法分析加密网络流量,识别用户访问的网页/网站,(1)See FAIK A &JASLEEN K. Can Android Applications be Identified Using Only TCP/IP Headers of Their Launch Time Traffic. The 9th ACM Conference on Security and Privacy in Wireless and Mobile Networks, Darmstadt,2016:61-66. See Wang T, Cai X &Nithyanand R. Effective Attacks and Provable Defenses for Website Fingerprinting. The 23rd USENIX Security Symposium, California,2014:143-157.然而这些研究方法大都关注单个网页(如网站主页)的指纹识别,忽略页面间的跳转。而在现实场景中,用户大都通过点击超链接访问Web应用各模块,且触发的网络报文序列较长。本文利用网页间跳转信息构建“用户—Web应用交互模式”,在未知网络流量中识别用户的行为,并应用于一种基于用户角色和行为模式的Web应用程序识别框架。
国际权威调研机构Gartner的调查显示,互联网信息安全攻击有75%发生在应用层而非网络层上,即Web应用是黑客攻击的主要目标。(2)See Gartner. Predicts 2022: Cyber-Physical Systems Security Critical Infrastructure in Focus.2022-01-26.https://www.gartner.com/en/doc/757423-predictive-analytics-cyber-security.2022-02-23.因此,从掌握网络安全态势的角度出发,网络管理员或网络审查机构也需具备从网络流量自动关联出用户访问的Web服务的能力。近年来,部分学者在这一研究领域提出解决方案。Ionescu和Keirstead提出一个识别框架,通过扫描用户、Web应用之间的交互行为以及用户访问的网络资源识别关联的应用程序。(3)See Ionescu P, Keirstead J &Onut I. Automatic Traffic Classification of Web Applications and Services based on Dynamic Analysis. United States Patent,2019.与这些针对用户是否访问某一具体网页或网站的方法相比,公安机关更需要一种能够识别逻辑相似的Web应用的方法。
从页面跳转触发的网络流量中构建交互模式在Web应用识别领域具有现实意义。近年来,服务商提供的模板使网站的创建变得越来越简单。(4)参见柏志安、廖健、曾剑平:《基于DOM树与模板的自适应网络信息抽取方法》,《计算机应用与软件》2022年第8期。模板化建站加大了执法机关对不法网站的打击难度,犯罪分子在网站被取缔后仍可将其“改头换面”(修改域名、标题、网页图片等),保留原来的业务继续运营。例如,有新闻报道网警程某利用工作之便,在打击赌博网站后将查获的源代码交给他人重新开设赌场获利。因此,本文认为由同一模板派生出的Web应用即使具有不同的标题或图片等外观元素,但它们仍具有相似的底层功能逻辑,这些相对固定的功能逻辑可被视为该类Web应用的“基因”。
Web应用的功能逻辑通常以用户和应用间的交互模式呈现,各类型的用户具有不同的权限,可执行不同类型的操作。用户在Web应用上执行的各类操作可用有向连接图U=(V,E)表示。其中,顶点集合V表示用户可执行的一系列动作,边集合E则代表各动作间的跳转。如图1所示,一个Web应用可描述为不同用户类型及其可执行的操作,图中顶点vi代表用户的某种行为,Pij则表示用户行为由vi转变为vj的概率。例如:某社交论坛包括注册用户和访客两种角色的用户,同一角色的用户往往呈现一定的行为模式(如注册用户通常会执行登录、浏览、发帖等操作)。因此,从网络流量中挖掘用户与Web应用的交互模式,并在未知流量中识别用户行为在Web应用识别领域具有应用价值。
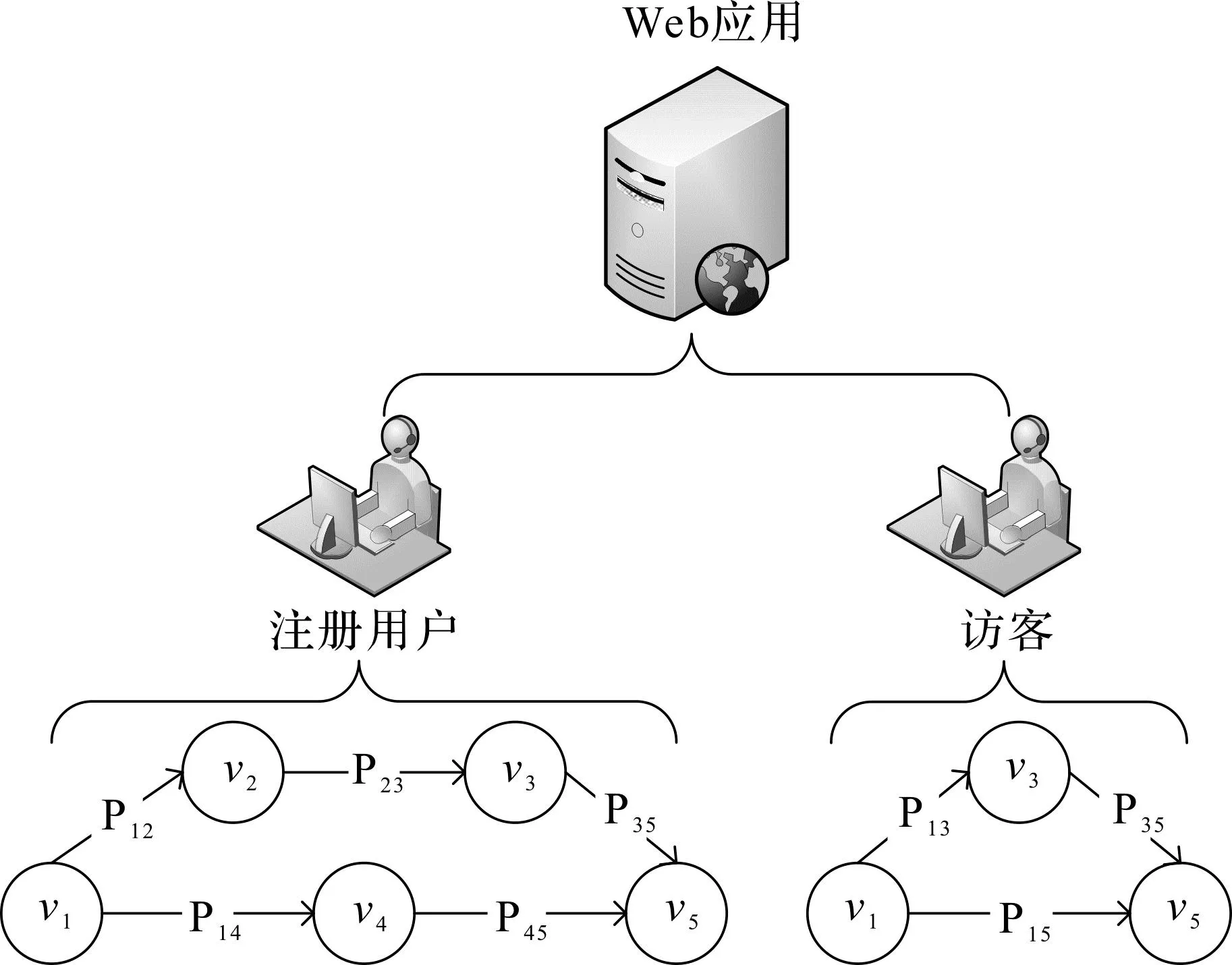
图1 Web应用模型
针对目前通过识别用户访问某个Web页面(通常为网站主页)判断其是否访问某Web应用,而实际的用户行为往往涉及多个页面间跳转的问题,论文提出一种利用网络流量报文分布信息的自适应用户行为识别方法,借助生物信息学中广泛使用的Profile Hidden Markov Model(5)See Eddy S R. Profile Hidden Markov Models. Bioinformatics,1998,14(9):755-763.模型从网页跳转触发的网络流量中挖掘用户与Web应用间的交互模式,从未知网络流量中识别用户行为,并应用于一种基于用户角色和行为模式的Web应用程序识别框架。
一、相关工作
功能各异的Web应用使得越来越多的用户通过网络使用金融、在线游戏和网络购物等高级场景。网络流量是用户与Web应用间交互的重要载体,用户执行的各类操作会触发相应的网络流量,同时可能泄露一些隐私数据(如联系人、照片、位置等)。近年来,网络流量分析技术越来越受到研究人员的关注。一方面,网络管理人员可以通过网络流量分析重构用户的行为序列(6)See Xie G, Liofotou M &Karagiiannis T. ReSurf: Reconstructing Web-surfing Activity from Network Traffic. IFIP Networking Conference, New York,2013:1-9. See Neasbitt C, Perdisci R &Li K. ClickMiner: Towards Forensic Reconstruction of User-Behavior Interactions from Network Traces. The 2014 ACM SIGSAC Conference on Computer and Communications Security, Arizona,2014:1244-1255.、识别恶意软件(7)参见高峰、鲍旭丹、刘敬:《WEID:一种基于信息量差加权集成的Android恶意软件检测方法》,《计算机应用与软件》2022年第9期。See Wang W, Sun C S &Ye J N. A Method for TLS Malicious Traffic Identification based on Machine Learning. Advances in Science and Technology,2021,105:291-301.、提升网络服务质量等(8)参见孙明玮、司维超、董琪:《基于多维度数据的网络服务质量的综合评估研究》,《计算机科学》2021年第6A期。。另一方面,攻击者通过网络流量分析能够获取目标网络中用户访问的Web应用(9)See Wang Y B, Xu H T &Guo Z H. snWF: Website Fingerprinting Attack by Ensembling the Snapshot of Deep Learning. IEEE Transactions on Information Forensics and Security,2022,17:1214-1226.、挖掘用户网络行为习惯(10)See Dai S, Tongaonkar A &Wang X. NetworkProfiler: Towards Automatic Fingerprinting of Android Apps. IEEE INFOCOM, Turin,2013:809-817.等隐私信息。国内外与本文相关的研究主要集中在网站指纹攻击、网络行为分析等领域。
(一)网站指纹攻击
网站指纹攻击(Website Fingerprinting Attack)能够判断用户访问了哪些网站或网页,通过分析探知用户隐私(如:兴趣爱好、政治倾向等)。1998年,Cheng和Avnur(11)See Cheng H &Avnur R. Traffic Analysis of SSL Encrypted Web Browsing.1998-01-01.http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.3.1201. 2021-11-05.证实SSL无法抵御网络流量分析,第一次提出网站指纹攻击的概念。近年来,网站指纹攻击得到研究者的广泛关注,各种机器学习算法被应用到这一领域且取得了不错的成果。
Cai等人(12)See Cai X, Zhang X &Joshi B. Touching from a Distance: Website Fingerprinting Attacks and Defenses. The 2012 ACM SIGSAC Conference on Computer and Communications Security, Raleigh,2012:605-616.使用隐马尔可夫模型(Hidden Markov Model,HMM)对网站建模,HMM的各状态对应网站的页面或页面类目。Hayes和Danezis(13)See Hayes J &Danezis G. K-fingerprinting: a Robust Scalable Website Fingerprinting Technique. The 25th USENIX Security Symposium, Austin,2016:1187-1203.提出从加密或匿名网络流量中识别用户访问网页的K-fingerprinting方法。Sirinam等人(14)See Sirinam P, Mathews N &Rahman M. Triplet Fingerprinting: More Practical and Portable Website Fingerprinting with N-Shot Learning. The 2019 ACM SIGSAC Conference on Computer and Communications Security, Colorado,2019:1131-1148.提出Triplet Fingerprinting方法,采用N-shot算法在减少收集、训练网站指纹训练集工作量的同时,降低不同网络环境对攻击效果的影响。FineWP(15)See Shen M, Liu Y &Zhu L. Fine-Grained Webpage Fingerprinting Using Only Packet Length Information of Encrypted Traffic. IEEE Transactions on Information Forensics and Security,2021,16:2046-2059.是一种细粒度网页指纹提取工具,通过提取客户与服务器交互时双向网络流量中报文长度作为特征向量训练随机森林、决策树和KNN等机器学习分类器,在控制训练开销的同时获得高识别率。以上研究大多考虑单一网页,忽略用户行为触发的网页间跳转。Zhuo等人(16)See Zhuo Z, Zhang Y &Zhang Z. Website Fingerprinting Attack on Anonymity Networks Based on Profile Hidden Markov Model. IEEE Transactions on Information Forensics and Security,2018,13(5):1081-1095.验证了PHMM能够有效利用Web页面间的跳转信息提高网站识别的准确率。本文同样借助PHMM能够有效使用页面跳转信息这一特点构建“用户—Web应用交互模式”,并提出一种利用网络流量统计特征的自适应符号化算法。
(二)网络行为分析
用户访问Web应用时触发的网络数据呈现不同模式,这使得在网络流量中识别用户行为成为可能。网络行为分析可用于提升网络服务质量或挖掘用户隐私。
Conti等人(17)See Conti M, Mancini L &Spolaor R. Analyzing Android Encrypted Network Traffic to Identify User Actions. IEEE Transactions on Information Forensics and Security,2016,11(1):114-125.提出一个移动APP内的行为检测框架,利用IP地址、TCP报文头部等信息识别用户在应用内的操作。他们使用动态时间规整(Dynamic Time Warping,DTW)和随机森林算法挖掘行为模式。然而,动态时间规整算法在序列长度较长、两段时间序列长度相当时计算效率低。Fu等(18)See Fu Y J, Xiong H &Lu X J. Service Usage Classification with Encrypted Internet Traffic in Mobile Messaging Apps. IEEE Transactions on Mobile Computing,2016,15(11):2851-2864.研究如何利用加密网络流量对移动APP内的用户行为进行分类。他们使用报文长度、时延以及时序依赖性等特征,将收集到的流量划分为Session和Dialog两个层次,再以Dialog为基本单位选择报文长度序列和时间间隔序列开展用户行为分类。
目前,网络行为分析技术已从传统网络应用场景扩展到移动智能家居设备研究领域。PINGPONG(19)See Trimananda R, Varmaken J &Markopoulou A. Packet-Level Signatures for Smart Home Devices. The Network and Distributed System Security Symposium, California,2020:1-18.能够自动从网络流量中提取智能家居设备的指纹,识别各类动作(如开灯或关灯)。HoMonit(20)See Zhang W, Meng Y &Liu Y. HoMonit: Monitoring Smart Home Apps from Encrypted Traffic. The 2018 ACM SIGSAC Conference on Computer and Communications, Toronto,2018:1074-1088.通过分析智能家居设备产生的网络流量判断用户在设备上的操作。Li和Feng等(21)See Li Q, Feng X &Wang R. Towards Fine-Grained Fingerprinting of Firmware in Online Embedded Devices. IEEE Conferences on Computer Communications, Hawaii,2018:2537-2545.采用自然语言处理技术和文档对象模型分析固件镜像文件系统的细微差别,进而提取指纹识别互联网上的固件。他们的方法必须主动与固件交互,因而容易被感知。本文采用被动监听的方法在网络流量中识别用户访问Web应用的行为。
二、问题定义
定义1 用户行为(UserAction)用户为实现某一目的与Web应用间的某次交互活动。例如:用户点击某社交网站的登录框,输入账号和密码,点击“登录”按钮登入该网站。
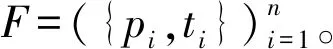
定义3 流量序列(TrafficSequence)用户执行某一行为触发的报文序列,流量序列TS是网络流量F的子集,即:TS⊆F。
本文拟解决的问题:给定捕获到的流量序列TS,判断触发该流量序列的用户行为,即识别目标网络内的用户访问某Web应用时执行的操作。
例如,某社交论坛允许用户执行若干操作(注册用户通常会执行登录、浏览、发布新帖、发表评论等操作),由于不同的用户行为触发的网络流量具有不同的特点,可收集用户与该论坛交互时产生的网络流量,针对不同用户操作分别训练行为模型,并利用这些模型从未知网络流量中识别用户行为,进而判断该未知网络流量是否由用户与某个特定Web应用之间的交互产生,即判断目标网络内的用户是否访问了某Web应用。
三、用户行为识别框架
本节介绍从网络流量中构建用户行为模型的方法。首先收集用户与目标Web应用交互时产生的网络流量,按一定规则过滤冗余信息。然后,提取报文长度、方向、时间戳等边信息构造流量序列特征向量,挖掘用户与Web应用的交互行为模型。本文提出的用户行为建模及识别框架如图2所示。
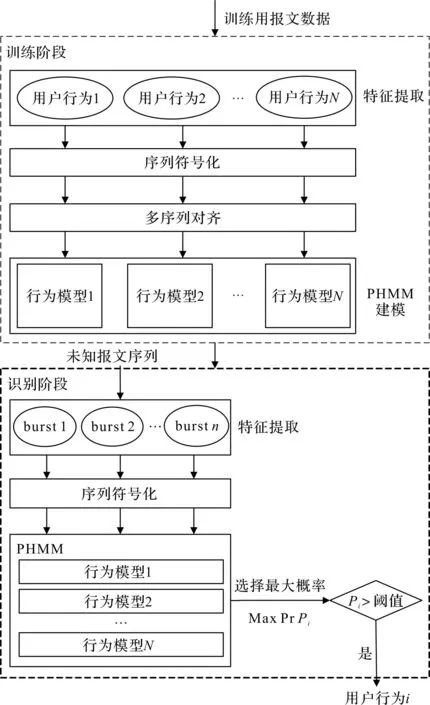
图2 用户行为建模及识别框架
(一)网络流量收集与预处理
在可控小规模网络中利用计算机作为AP记录用户访问Web应用触发的网络流量,图3展示了网络流量收集方式。在流量收集的过程中,除了屏蔽用户访问目标Web应用以外的其他上网行为产生的流量,还记录了用户与Web应用交互时每种行为的开始时间与结束时间,以便尽可能过滤掉异常流量。
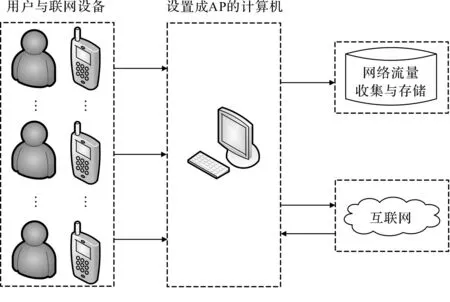
图3 网络流量收集
网络流量预处理阶段包括三个步骤:流量过滤、流量序列化以及流量切分。首先要过滤非必需的网络流量,其次是将流量数据转为序列化的特征数据以便后续处理,最后将流量切分以区分不同行为对应的不同网络流量。
1.流量过滤。捕获到的网络流量中不可避免存在不相关流量,例如,数据传输过程中丢失、损坏的重传数据包;不携带负载仅在数据传输过程中起到确认作用的ACK数据报文、用于TCP握手过程中建立连接和断开连接的数据报文等。在收集网络流量时,还不可避免地会存在操作系统产生的背景流量、网络通讯过程中所需要的网络流量以及一些非关键性网络流量,如ARP、DHCP等报文。此外,为防止其他用户连接至相同Wi-Fi访问点,利用IP地址过滤非目标用户产生的流量。
2.流量序列化。流量序列化指将收集到的网络流量转化为便于计算机处理的数字序列。本文提取网络流量中各报文的长度、方向、时间戳等边信息将流量数据转化为数字序列。时间戳是切分网络流量的依据,可用来计算流量中报文间的时间间隔,从网络流量中切分出不同的网络行为子序列。
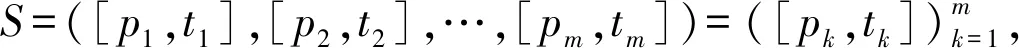
3.流量切分。利用IP地址、cookies等信息区分不同用户的网络流量,对于部署了网络地址转换(Network Address Translation,NAT)的网络,可使用文献(23)See Verde N, Ateniese G &Gabrielli E. No NAT’d User Left Behind: Fingerprinting Users Behind NAT from NetFlow Records Alone. The 34th IEEE International Conference on Distributed Computing Systems, Madrid,2014:218-227.提出的方法从流量中区分不同的用户。为方便描述用户操作触发的网络报文序列,给出“会话”和“交互流量”的定义。
网络流量是用户与Web应用交互时产生的,收集到的网络流量中混合了用户的多种行为,流量切分的目的就是要从中切分出用户行为子序列。通常的做法是先去除一整段网络流量中的背景流量,然后按固定时间间隔阈值将流量切分成多个会话,再将每个会话切分成若干段子序列,每段子序列代表用户的一种行为。
首先将序列化后的报文序列以固定时间间隔切分为多个会话,每个会话记为Session。然后将每个Session切分为固定时长的片段,即为Burst。由于每个Session可能包含若干连续的Burst,而每个用户动作产生的网络报文量及持续时间不同,时间阈值的选取非常重要。本文在后续的实验中将固定时长阈值设置为4.5秒,以期获得最佳分类效果。
经过流量预处理操作后,能够得到不同用户行为触发的报文序列,可建立模型从中识别这些报文序列对应的“用户—Web应用”交互类型。
(二)用户行为模式挖掘
1.PHMM模型。PHMM模型在计算生物学领域被广泛应用于识别基因序列的家族关系。研究者发现,同一家族的基因序列间虽然存在一些差异,但序列中某些位置的基因表达与其他位置相比更加固定。与基因序列类似,同一用户动作(如多次登录同一Web应用)触发的网络流量虽然会随着网络环境变化而发生波动,但其携带的关键信息不会改变。例如,Web应用的页面往往包含CSS文件、图片等元素,点击页面触发的网络流量中包含唯一标识这些元素的信息。图4展示PHMM模型,插入(Ii)和删除(Di)状态使模型对序列的波动不敏感且能有效利用序列的位置信息。本文采用PHMM模型训练用户与Web应用间的交互模式。

图4 PHMM模型示例
2.序列符号化。由于各类用户行为通常涉及页面间的跳转,生成的报文序列较长。为尽可能在保留原始流量信息的条件下降低模型的复杂度,需要在构建用户行为模型之前对流量序列执行符号化操作。符号化的目标是用有限的符号集尽可能多保留原序列的有效信息。符号化操作将流量序列由数字序列转换为符号序列,如“QRJPQNNNCBBBB…”。流量序列转换为符号序列的算法实现过程如下:
输入:流量序列s
输出:符号序列seq
1.l←0,sign←0,seq←null;
2.fors中单个报文pdo
3.l←报文p的长度len(p);
4.ifp是出站报文then
5.sign←-1;
6.else
7.sign←1;
8.endif
9.l←l×sign;
10.seq←seq+l对应的符号
11.endfor
12.returnseq
符号化是重要的时间序列分析方法,如何选择合适的符号化策略一直以来都是一个难题。符号化指把实数序列转换成符号序列,依据序列的数值特征对该序列做粗糙化处理,再将获得的符号序列做各种推理计算,理解系统特征,因此符号化强调“先划分、后理解”(25)参见向馗、蒋静坪:《时间序列的符号化方法研究》,《模式识别与人工智能》2007年第2期。。符号化方法大致可分为直接法和小波空间法两种。直接法包括对数值序列不进行预处理、直接根据序列数值特征进行符号划分的静态法、动态法及综合法等。小波空间法则先对序列做适当变换,然后再进行划分。
在网络流量分析领域,为实现流量序列符号化,有研究(26)See Zhuo Z, Zhang Y &Zhang Z. Website Fingerprinting Attack on Anonymity Networks Based on Profile Hidden Markov Model. IEEE Transactions on Information Forensics and Security,2018,13(5):1081-1095.采用等间距符号化算法将报文长度序列划分为若干等长的区间,为每个区间分配不同的符号。等间距符号化算法属于直接法的一种,该算法简单、易于实现,时间复杂度为O(N),其中N为待处理的网络流量数据集中的报文数量。等间距符号化算法不考虑报文分布,为报文聚集和稀疏的区间分配同样多的符号。例如,图5展示了用户浏览某社交论坛时触发的网络流量报文长度分布情况,其中的数值符号表示报文方向(出站/入站)。由图可见,[0,600]和[900,1500]区间内报文数量与其他区间相比明显较少。等间距算法在分配符号时忽略各区间内报文的数量,因此无法更细致地表示报文密集的区间。
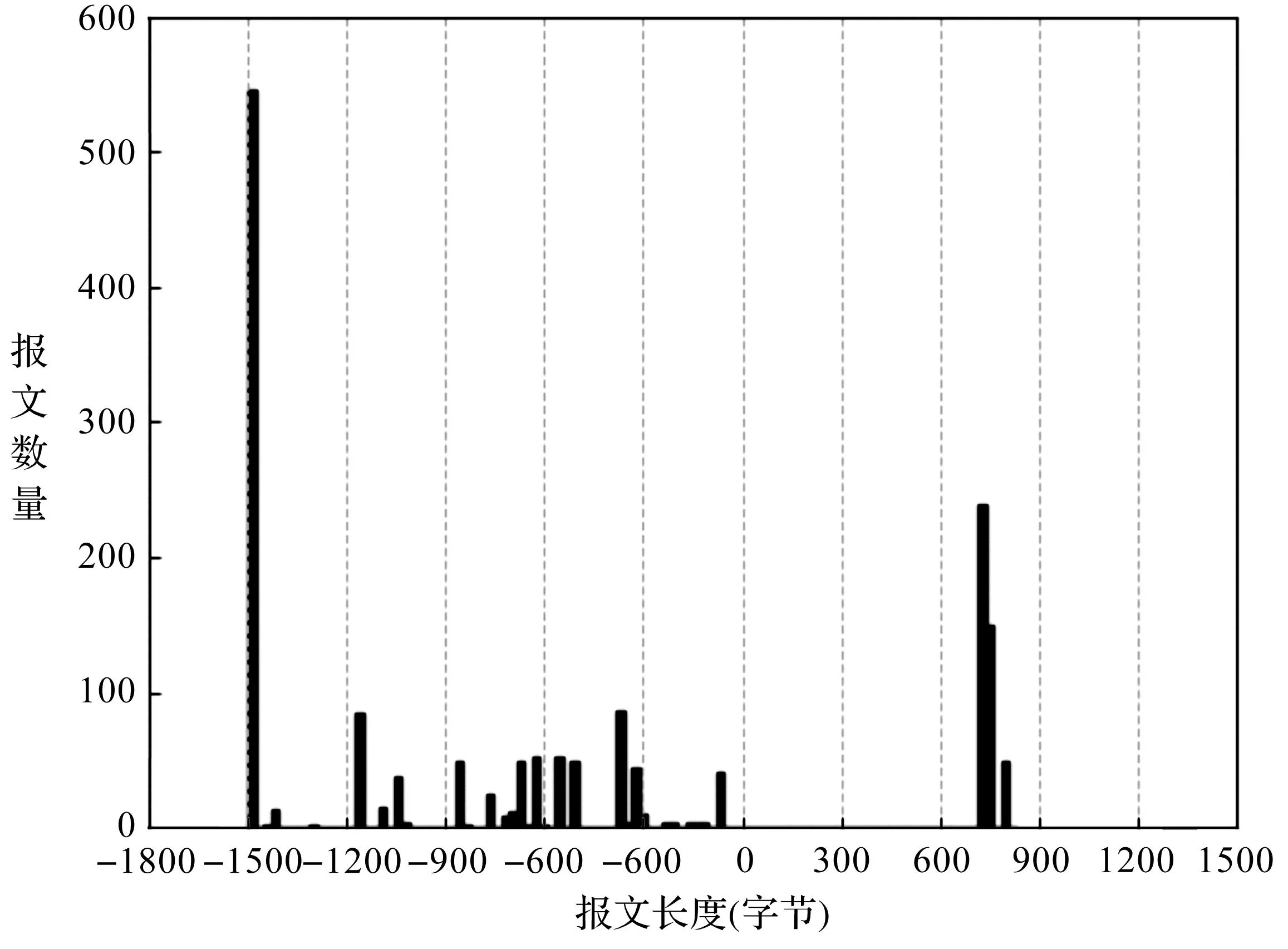
图5 等间距符号化算法忽略网络报文长度分布信息
除等间距符号化算法外,有研究(27)See He G, Yang M &Luo J. A Novel Application Classification Attack Against Tor. Concurrency and Computation: Practice and Experience,2015,27(18):5640-5661.采用K-means聚类算法实现流量序列符号化,该算法的时间复杂度为O(NKt),其中N代表待处理的网络流量数据集中的报文数量,K为聚类个数,t是聚类的迭代次数。K-means算法能够利用报文序列的分布信息,但在处理大量数据时耗费时间较长。
由此可见,无论是等间距符号化算法还是K-means聚类方法都存在明显的缺陷。在前一种方法中,区间长度的划分由用户随机指定,极端情况下长度落在某些区间内的报文数量可能会很少甚至没有,但算法仍需为这些“稀疏”区间分配符号。而对于那些报文比较密集的区间,算法也无法为它们分配更多的符号以体现序列的统计分布特征。同样,K-means算法虽然是对报文长度序列进行聚类,但用户无法控制聚类过程,也无法确定该算法将原序列划分K个类别后生成的符号序列是否能最大限度地描述原始序列。
因此,针对现有符号化算法存在的问题,本文提出一种在限定符号集大小的前提下考虑网络流量报文分布的自适应符号化方法。
(1)自适应符号化算法。本节提出一种自适应符号化算法,在符号集大小固定的情况下,寻找原始流量序列符号化后精度损失最少的区间划分方法。由于流量序列中各元素的取值范围是[-1500,1500],待解决的问题可转换为在符号集合大小为K的条件下,即将流量序列划分为K个区间时,确定合适的区间长度τ1,τ2,…,τK。
由于原序列中任意一个元素值xi都有对应的出现概率pi,符号化前后序列间的距离D可由公式(1)表示。
(1)
其中E(X)是原流量序列的期望值,E(Iτi)是流量序列在第i个区间上的期望值,与区间长度τi有关。假设共有Nτi个报文落在该区间,则可用公式(2)计算E(Iτi)。
(2)
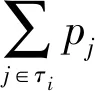
(3)
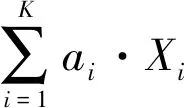
(4)
(5)
对该条件极值函数求偏导,得式(6)。
(6)
解该联立方程可得式(7)。
(7)
输入:流量序列集合S
符号集大小K
输出:区间集合Ψ={τ1,τ2,…,τK}
1.S’ ←S中的数据从小到大排序;
2.N←sizeof(S’)
3.i ← 1, j ← 1, prev ← 0, sum ← 0, p ← 1/N,Ψ← null;
4.forxiinS’do
5.prev←sum;
6.sum←sum+p;
7.ifprev<= 1/Kandsum>1/Kthen//划分K个区间
8.if|prev-1/K| <|sum-1/K|then
9.xτj=xi-1
10.i←i-1;
11.else
12.xτj=xi
13.endif
14.sum← 0,prev← 0;
15.τj←Range(xτj-1,xτj); //区间包含相邻间隔点间所有元素
16.j←j+ 1;
17.endif
18.endfor
19.Ψ←Ψ+τj
20.returnΨ
(2)多序列对齐。受网络环境的影响,同一用户行为触发的网络流量存在波动,因此符号化后的序列长度也并不完全一致。Baum-Welch算法(28)See Rabiner L. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE,1989,77(2):257-286.可以从长度不一的多条序列中构建PHMM模式,但非常耗时且容易陷入局部最优。(29)See Bhargava A &Kondrak G. Multiple Word Alignment with Profile Hidden Markov Model. The NAACL HLT Student Research Workshop and Doctoral Consortium, Colorado,2009:43-48.因此,本节先利用多序列对齐算法(Multiple Sequence Alignment,MSA)将每类用户行为对应的符号序列对齐。
使用Clustal Omega工具(30)See Clustal Omega. 2016-07-01. http://www.clustal.org/omega/.2021-12-01.对符号化后的字符序列执行对齐操作。图6展示了一个符号序列对齐的样例。经对齐操作后,每条序列包含115个字符,各序列缺失的位置用短横线“-”填充。对齐后的符号序列可用来训练不同用户行为的模型。

图6 多序列对齐结果示例
(三)用户行为识别
如前所述,开展用户行为识别时,首先从待测网络流量中切分出单次交互触发的流量,提取报文长度、方向等特征,生成待检测的数字序列。接着,使用与训练阶段相同的符号化方式将待测交互流量中的报文特征序列映射为符号序列。依次计算该符号序列在此前构建的N个模型{M1,M2,…,MN}下的观测概率Pr(i)。若Max(Pr(i))>μ,则判定待测序列由模型Mj关联的用户行为触发,j由公式(8)确定。
j=argmax(Pr(j))
(8)
若Max(Pr(i))<μ,则将该待测序列判定为未知类型的流量。其中,阈值μ是经验值参数,可从训练数据中习得。
用户行为识别是Web应用识别的基础,在完成同一用户触发的网络流量中的多个动作识别后,可构造该用户的网络行为序列,进而识别用户是否访问了目标Web应用。图7展示了本文采用的Web应用识别框架。
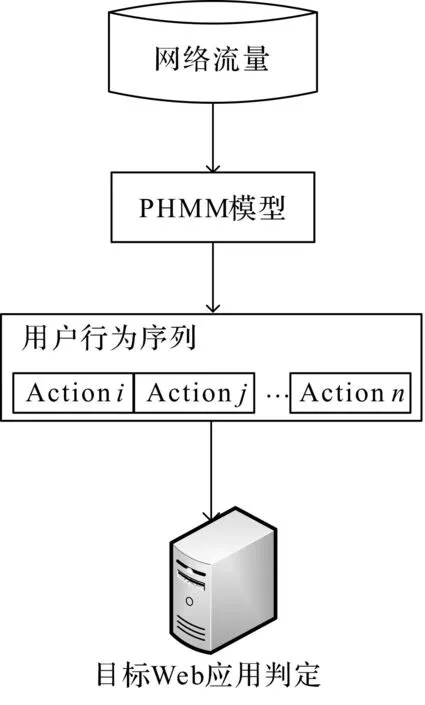
图7 Web应用识别框架
四、实验与分析
(一)数据集和评判指标
利用PHPWind Version 8.7在阿里云服务器上搭建论坛,邀请志愿者访问并使用Wireshark软件记录触发的网络流量。表1展示志愿者们在该社交论坛上执行的操作。执行以下行为各50次,收集触发的网络流量。流量收集完毕后进行过滤、切分、提取特征值和符号化等处理。将收集到网络流量转化为多条代表用户行为的符号序列,构建用户行为模型。接着,重复执行表1中的动作各100次生成测试数据集。

表1 用户操作
采用机器学习常用的准确率(Precision)、召回率(Recall)、F1值(F1-Score)以及混淆矩阵评估用户行为分类结果。
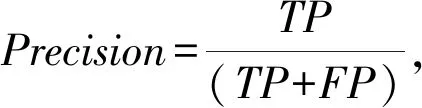
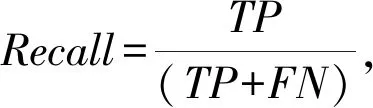
F1值(F1-Score)是准确率和召回率的调和平均值,计算方式如公式(9)所示。
(9)
TP、FP、TN和FN在本实验的定义如下。TP:PHMM模型将用户各类访问论坛的行为触发的网络流量正确分类到对应行为的数量。FP:PHMM模型将用户各类访问论坛的行为触发的网络流量错误地分类到其他访问行为的数量。TN:PHMM模型将用户访问其他应用触发的网络流量正确分类为无关行为的数量。FN:PHMM模型将用户访问论坛的行为触发的网络流量错误分类为无关行为的数量。
混淆矩阵,又名误差矩阵、错误矩阵,是表示精度评价的一种标准格式。矩阵中的行表示样本的实际类别,列则表示样本的预测类别。混淆矩阵中的点颜色越深表示被正确分类的样本占比越大。
(二)实验设置
Wireshark收集到的网络流量经流量过滤、切分、特征提取转化为报文长度序列,再进行符号化和多序列对齐处理。将符号化序列划分为训练集和测试集,训练集用于构建用户行为模型,测试集用于评估各行为模型判断流量对应的用户行为的有效性。
在经过与训练阶段相同的符号化处理之后,本文使用HMMER工具提供的hmmsearch指令寻找与测试流量序列匹配的PHMM模型(31)See Eddy S &The HMMER Development Team. HMMER User’s Guide: Biological Sequence Analysis Using Profile Hidden Markov Models. 2020-11-01. http://eddylab.org/software/hmmer/Userguide.pdf.2022-02-05.。由于执行hmmsearch指令后输出的bitscore数值仅体现某一PHMM模型和目标序列间的关系(bitscore值越大说明待测序列与该PHMM模型的匹配度越高),与序列数据库的规模无关。因此,本文依据bitscore值对测试数据进行分类,依次将待测序列与多个PHMM用户行为模型相匹配,并将其判定为匹配度最高的PHMM模型所表示的用户行为。
(三)用户行为识别实验
1.与其他符号化算法对比实验。为评估本文提出的符号化算法的有效性,在Ede等人的公开数据集上(32)参见Alexa Top 1000网站流量数据集,2020年5月21日,https://github.com/Thijsvanede/FlowPrint/tree/master/datasets,2022年3月20日访问。比较自适应符号化算法和等间距算法、K-means聚类算法。图8分别展示了三种符号化算法在符号化序列与原序列间距以及运行时长两方面的对比结果。自适应符号化算法在降低符号化序列与原序列间距方面的表现显著优于等间距和K-means聚类算法,因此能够最大限度保留流量序列原始信息。在运行效率方面自适应算法优于K-means,与等间距符号化算法用时相近。
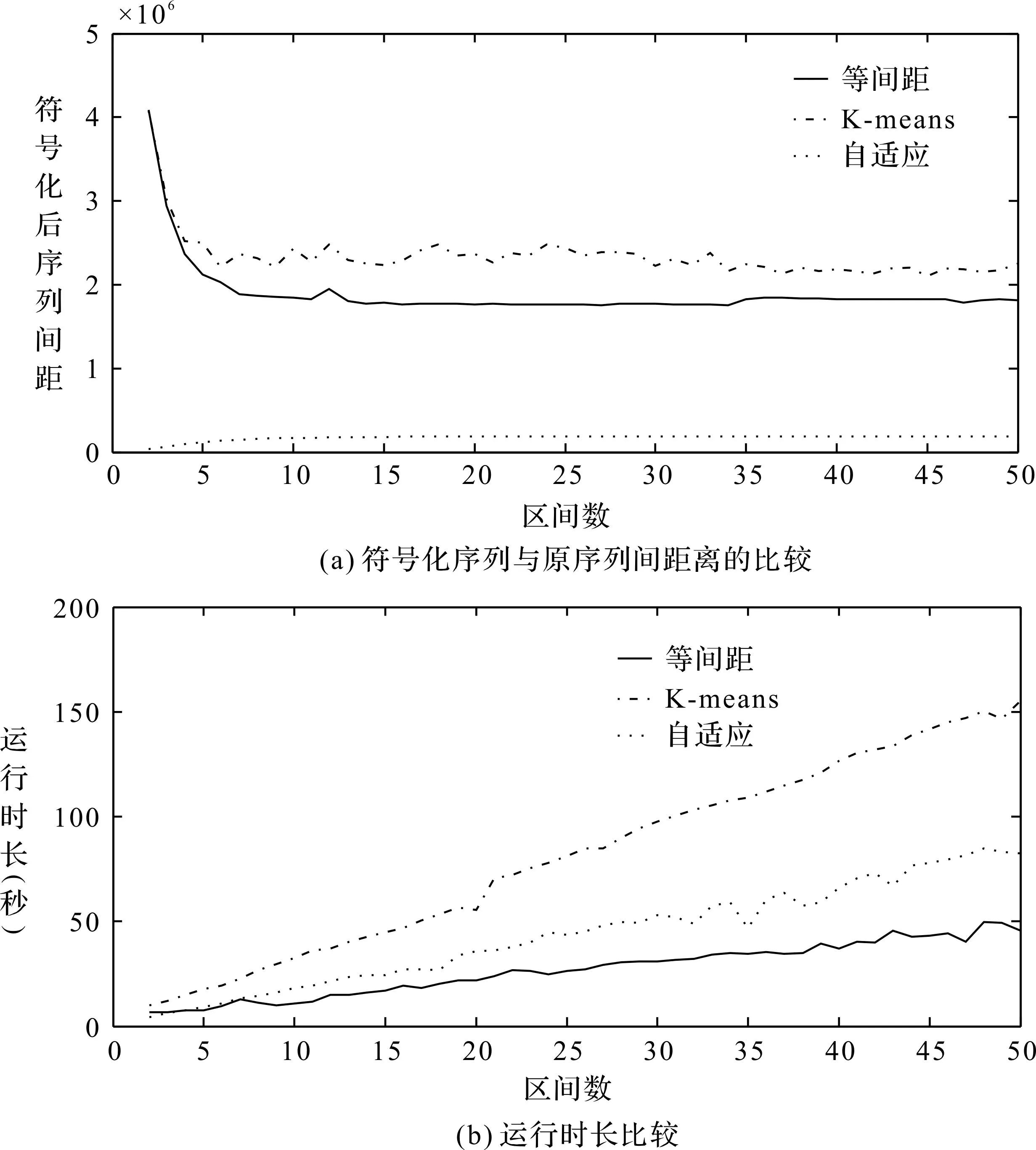
图8 等间距、K-means、自适应符号化算法的对比
由图8(a)可知,随着区间数K的增大,符号化序列与原序列间的距离逐渐收敛。为确定K的最优值,采用启发式方法根据公式(10)和(11)分别计算符号化序列各区间内部距离intraK和外部距离interK。
(10)
interK=min|centeri-centerj|i,j∈{1,2,…,K}
(11)
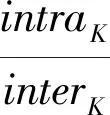
(12)
由于自适应符号化算法在保留流量序列原始信息方面具有显著优越性,本文采用自适应符号化算法预处理网络流量,并根据公式(12)的计算结果取K值为23。
2.基于PHMM的用户行为识别实验。表2描述基于PHMM的用户行为识别方法的准确率、召回率和F1值。从结果可以看出,绝大部分的用户行为识别准确率都在95%以上,但“回帖”动作的准确率为58%,且“发帖”这一动作的召回率仅为27%。通过人工分析发现大量的发帖行为被误判为回帖行为,影响了这两类用户行为的识别率。图9展示用户行为识别混淆矩阵,可见有70%的“发帖”行为被误判为“回帖”。
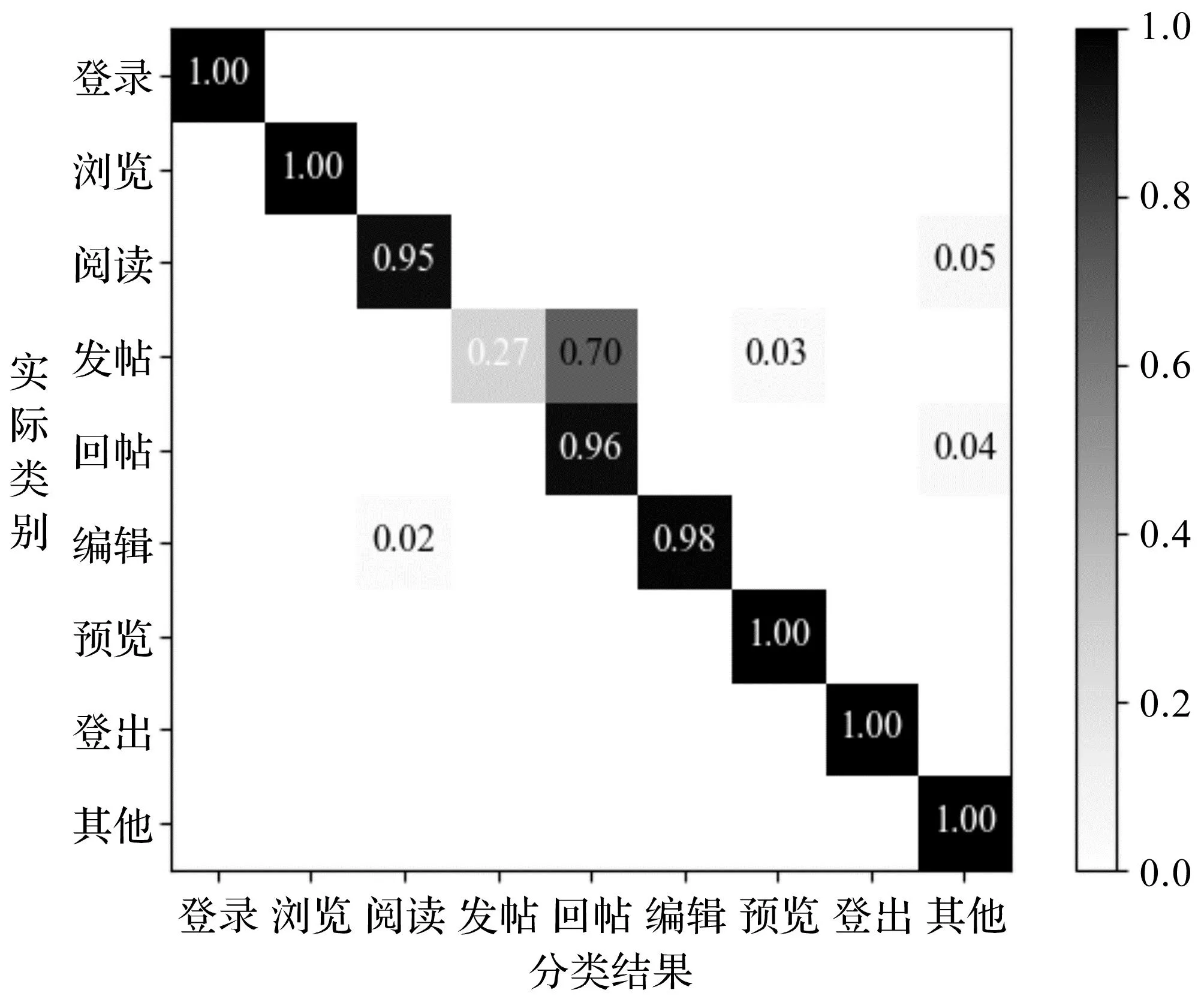
图9 用户行为识别混淆矩阵
事实上,无论“发帖”或“回帖”,其实质都是向Web应用递交数据。通过观察发现,用户执行发帖和回帖操作访问的URL路径一致,参数部分略有不同。例如:某用户发布新帖时访问的URL是post.php?fid=2,而其他用户回复该帖时访问的URL是post.php?action=reply&fid=2。此外,用户发帖和回帖的行为都会引起网页刷新,而这些网页具有同样的文档结构。基于以上观察,本文认为“发帖”与“回帖”差异性较小,从而在后续实验中合并这两类行为。重新使用此前收集到的发帖和回帖行为触发的网络流量共同训练出新的“发帖”行为模型,在测试数据集中识别用户的发帖或回帖动作。图10展示调整后的用户行为识别混淆矩阵。
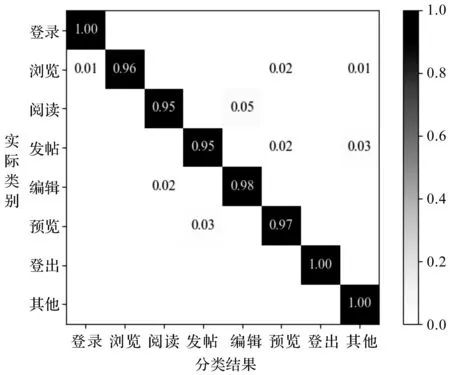
图10 调整后的混淆矩阵
由图可见,实验中每类用户行为的识别率都在95%以上,仅有部分流量被错误分类至其他类型。其中,“登录”和“登出”两类行为的识别率达到100%。此外,用户访其他Web应用触发的流量会被识别为“其他”行为类别,不存在误判的情况。用户行为识别实验的平均召回率、准确率和F1值分别为97.3%,97.6%和97.4%。
3.与其他方法对比实验。由于用户行为识别使用的网络流量样本集多由研究者各自收集整理,因此通过复现文献的方法进行对比分析,以进一步评估本文提出方法的有效性。有研究(33)参见燕飞鹏:《基于网络流量的微信用户行为识别技术》,硕士学位论文,杭州电子科技大学,2019年。采用在大多数分类场景下表现优秀的随机森林算法(Random Forest,RF)识别用户行为。提取流量序列中报文的最大值、最小值、均值、绝对中位差、标准差、方差、偏度和峰度等统计特征构建特征向量。此外,为反映报文长度分布信息,将长度落在[0-300][301-600][601-900][901-1200]和[1201-1500]等5个区间的报文数量选作特征值。图11展示本文(PHMM)与文献(RF)提出的用户行为识别方法的准确率对比,证实了本文方法的有效性。
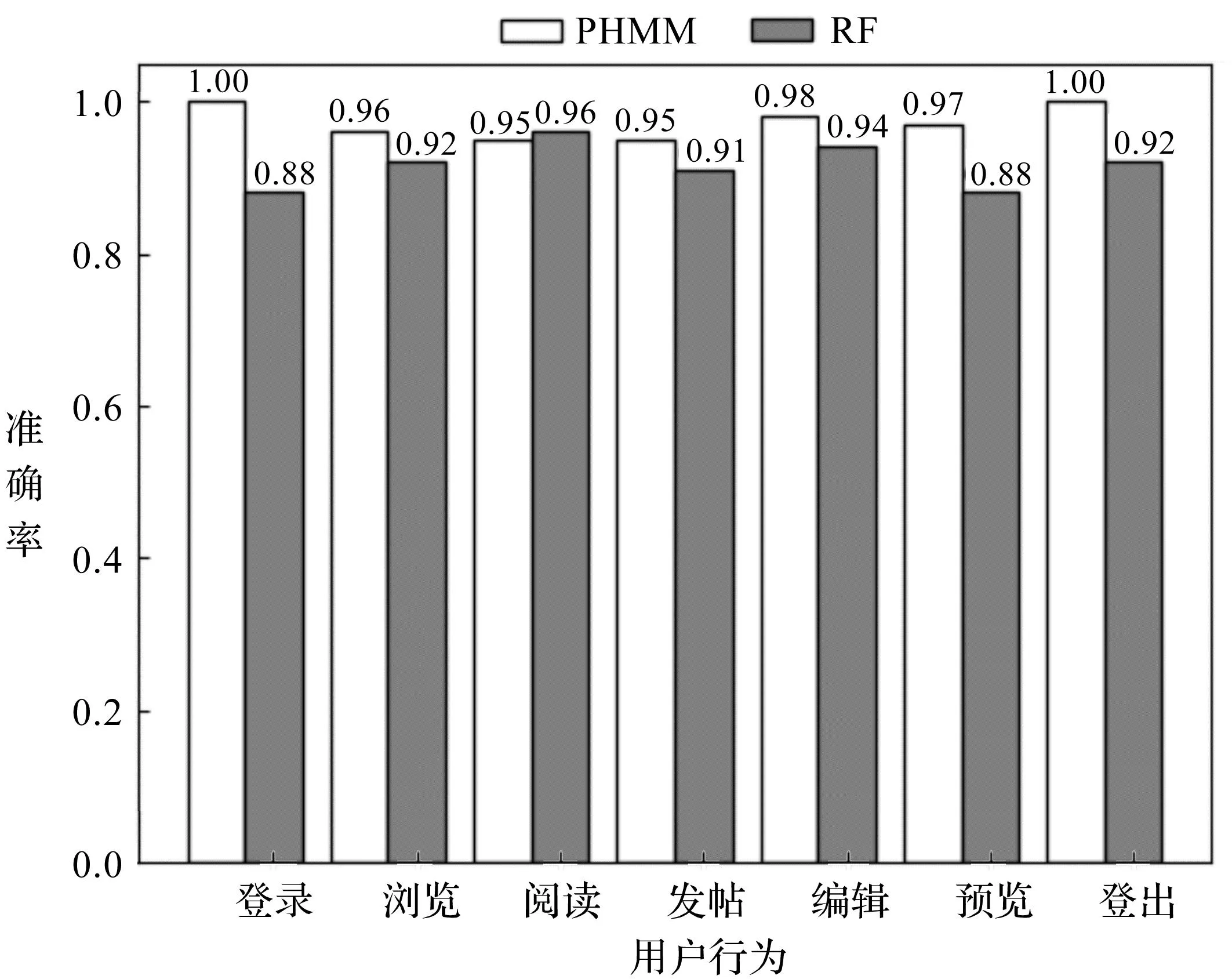
图11 PHMM与随机森林分类方法对比实验结果
五、诈骗类网站识别
随着互联网经济和电信产业的迅猛发展,涉信息网络犯罪的案件逐年上升。以电信网络诈骗为代表的新型犯罪持续高发,已成为上升最快、群众反映最为强烈的一类案件。据最高人民法院《涉信息网络犯罪特点和趋势司法大数据专题报告》披露,过去五年涉信息网络犯罪案件呈逐年上升趋势,其中近四成涉信息网络犯罪案件涉及诈骗罪。(34)参见《涉信息网络犯罪特点和趋势(2017.1—2021.12)司法大数据专题报告》,2022年8月1日,载中国司法大数据研究院网,https://file.chinacourt.org/f.php?id=c9b92b185f359c81&class=enclosure,2023年6月8日访问。2021年4月,习近平总书记对打击治理电信网络诈骗犯罪工作作出重要指示,要求“坚持以人民为中心全面落实打防管控措施,坚决遏制电信网络诈骗犯罪多发高发态势”。2022年9月2日通过的《中华人民共和国反电信网络诈骗法》体现了国家对于网络空间安全的重视及打击电信网络诈骗犯罪的决心,同时为公安机关牵头负责反电信网络诈骗工作提供有力的法律支持。在上述背景下,本文以用户访问诈骗类网站触发的网络流量为研究对象,从网络流量中构建诈骗类网站的特征模型,进而开展涉诈类网站的识别,对公安机关打击涉信息网络犯罪具有积极作用。
为验证本文所提出算法的可迁移性,将其应用于诈骗类网站识别。诈骗类网站是犯罪分子实施网络诈骗的重要平台,这些网站通过发布虚假信息和非法交易等手段诱导用户提供个人财务或其他敏感信息,导致用户财产损失或隐私泄露。公安机关检测并打击此类网站有助于保护公民财产安全及个人隐私,削弱犯罪网络组织的运作能力,对减少涉信息网络犯罪的发生具有重要意义。
本实验采用从公安部门获取的诈骗网站地址与非诈骗网站地址,(35)参见周胜利、徐啸炀:《基于网络流量的用户网络行为被害性分析模型》,《电信科学》2021年第2期。手动模拟用户对这些网站的访问,并利用Wireshark捕获访问过程中产生的网络流量。实验数据集中共包含诈骗网站访问流量2051条,非诈骗网站访问流量1143条。表3列出数据集中诈骗网站的类型和数量。

表3 实验数据集中诈骗类网站的类型及数量
将本文提出的基于PHMM的用户行为识别算法与经典的随机森林算法分别应用于该数据集,对比两种算法在诈骗网站识别方面的有效性。表4展示了两种算法识别结果的混淆矩阵,矩阵中的行表示样本的实际类别,列则表示样本的预测类别。由混淆矩阵可得,基于PHMM的模型在诈骗网站识别方面的精确率为0.974,召回率为0.978;随机森林模型的精确率分别为0.902和0.911。基于PHMM模型的算法优于经典的随机森林算法,实验证实本文提出的方法具备良好的迁移性。
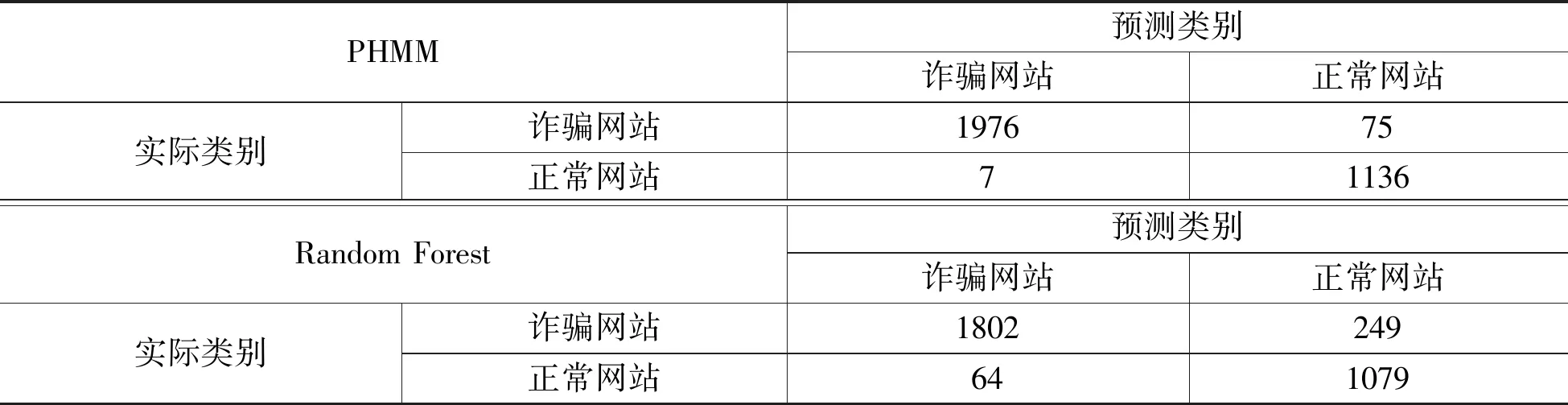
表4 混淆矩阵对比结果
六、结语
针对用户与Web应用交互时往往涉及页面跳转且网络流量序列较长的问题,提出一种自适应的符号化算法,并利用计算生物学中广泛应用的PHMM模型挖掘用户和Web应用间的交互模式,从网络流量中识别用户行为。与前人工作相比,本文提出的自适应符号化算法能在最大限度保留原序列信息的同时降低PHMM模型的复杂度,且耗时较少。与经典的随机森林分类算法的对比实验表明,基于PHMM的用户行为识别方法具有良好的准确率。诈骗类网站识别验证了本文提出的算法具备可迁移性,能够为公安机关打击涉信息网络犯罪提供一定的技术支持。下一步研究将考虑在用户行为模式挖掘的基础上开展行为预测,实现对用户异常网络行为的实时监控,并应用于涉信息网络犯罪的预测及防治。
猜你喜欢
汽车电器(2022年9期)2022-11-07
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
数学教学通讯·小学版(2022年4期)2022-05-29
微型电脑应用(2021年3期)2021-03-31
铁道通信信号(2020年4期)2020-09-21
中国外汇(2019年11期)2019-08-27
新校园·上旬刊(2017年10期)2017-12-08
北京航空航天大学学报(2017年7期)2017-11-24
纺织科技进展(2016年3期)2016-11-29
铁道通信信号(2016年8期)2016-06-01
