
水下无线传感网的自适应时域压缩方法
2024-01-10 01:35应蓓华王子聪
浙江工商职业技术学院学报 2023年4期
应蓓华 王子聪
(浙江工商职业技术学院,浙江 宁波 315012)
1 研究背景
覆盖地球表面70%多的海洋对人类的生存与发展具有重要而深远的意义。随着科学技术的进步和海洋经济的兴起,世界各国对海洋权益及其蕴含的巨大能源和多种资源愈发重视,人类对海洋勘测和开发等相关领域的技术需求亦日显迫切[1]。在此背景下,水下无线传感网(Underwater Wireless Sensor Network,简称UWSN)正成为兴起的新的研究热点[2]。
UWSN 是指将低能耗、具备短距离通信能力的水下传感器节点以固定在海底或悬浮于海中的形式部署在指定海域中,节点内部集成用于测量温度、盐度、深度、压力、波高、剖面流量等海洋环境参数的传感器,且能通过声学网络通信的方式将采集的数据传递至漂浮于水面的基站或船舶,并通过无线网络通信,经由卫星或互联网最终达到用户端[3]。图1、图2 所示分别为水下无线传感网的系统示意图及其基本架构。在海洋勘探与开发、环境监测、溢油检测、潜艇探测、灾害预警预报等众多军用和民用领域,UWSN 有着广阔的应用前景和发展潜力。不管是理论探索还是技术实践,对高可靠性、高使用寿命的UWSN 进行研究都具有深刻而重大的意义。

图1 水下传感网的系统示意图
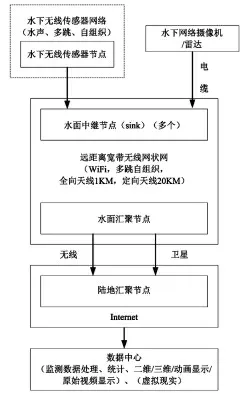
图2 水下传感网的系统架构
然而,水下无线传感网的传输能力弱和传输能耗大是其区别于其他无线网络的最大不同。在低通信带宽、低传输速率、高误码率和高发射功率的共同影响下,相对于目前再生能源供给技术并不成熟的高制造成本和高部署成本来说,水下节点仅靠有限的电池供电,其能量的高效使用无疑是亟待解决的重要问题之一。而水下网络的特性及其对能耗提出的严格要求,将深刻影响UWSN 四层体系结构的设计,同时也给水下网络的进一步研究带来了更多的挑战。
2 研究现状及存在的问题
2.1 国内外研究现状
在WSN 的早期研究中,网内信息处理是数据传输协议中较为重要的研究分支之一。鉴于节点计算资源和存储资源受限,适用于WSN 的数据处理大多为轻量级算法,即在引入少量额外计算能耗的前提下,降低节点的总能耗。根据数据相关性的不同处理角度,现有WSN 数据压缩算法可分为以下三种:时域压缩、空域压缩和时空域压缩。
在时域压缩中,得益于较低的计算复杂度,以分段常数逼近(PMC-MR 和PMC-MEAN)[4]、滑动窗口平均[5]、类似旋转门趋势压缩的轻量级时域压缩机制LTC(Lightweight Temporal Compression)[6]为代表的线性回归算法,与预测编码[7]、小波变换[8]等成为该领域的主流技术。考虑到处理器的计算能力和存储能力,预测编码多采用一阶自回归和一次移动平均作为预测模型,而小波变换则以基于提升格式(lifting scheme)的二代小波为主,最常用的是5/3 小波和2/6 小波。
2.2 存在的问题
可以看出,作为最贴近UWSN 的无线网络,WSN在网内信息处理方面已有一定程度的研究积累,但由于这些方法的适用性受限于WSN 的自身特点,无法直接拓展至水下,分析其原因,大致有以下几点:
一是轻量级的算法制约了信息处理的效果。考虑到WSN 节点的计算和存储能力有限,且处理器的工作功率和节点通信功率基本处于同一数量级,算法的轻量级是设计的基本要求。大多数压缩方法在降低复杂度的同时也损失了大部分的压缩效果。从近几年研发的水下节点来看,在MCU 的选择上已从2006 年USC 节点[9]的ATMEGA 128L、UCI 节点[10]的MSP430 发展为2012 年GaWoNU[11]节点的ARMCortex-M3。可以看出,处理器性能的提升令执行压缩有了更多的选择。更重要的是,由于发射功率远远高于处理功率,水下节点可以通过适当增加计算复杂度来获取更好的压缩效果,进一步凸显网内信息处理在水下网络通信中的节能优势。
二是水下数据的类型和特点有别于陆上WSN应用。在UWSN 应用场景中,大部分原始数据采集于水下。水下环境复杂多变,存在很多随机的不确定性。以最常见的温度数据为例,图3 所示为传感器在相同时间、不同海拔高度下测得的温度变化曲线,此实测数据取自热带太平洋观测系统[12](Tropical Atmosphere Ocean project)。可以看到,即便是同一种数据类型,在不同环境下也会表现出不同的变化特性,这将直接影响陆上WSN 的信息处理方法对水下数据的适应程度。另一方面,陆上WSN 并未对水下测量特有的物理量如水深、波高、波向、盐度、导电率、溶解氧、浊度、剖面流速、剖面流向、潮汐水位高度等的变化特性进行深入研究,进而无法获知适合各个数据类型的信息处理方法。

图3 相同时刻、不同监测位的温度变化曲线
三是UWSN 的稀疏部署弱化了原始数据的空间相关性,影响着水下节点的工作模式。由于WSN 属于密集部署型网络,节点密度高、距离近,通常情况下,原始数据间存在着较大的空间冗余。因此,WSN研究大多侧重于节点的空间相关性。而对于高节点成本的UWSN 来说,节点间的距离通常达到几百米,稀疏型部署使节点的空域相关度明显减少,基于空间冗余而提出的信息处理方法大多不再适用,而时域相关的方法研究则仍待加强。此外,由于原有方法涉及的信息频繁交互方式将带来大量通信损耗,水下节点需要尽可能地减少交互的次数,更多地采用自学习的方式和预测机制来实现节点的协同工作。
鉴于以上几方面原因,WSN 的信息处理方法不适宜直接移植并应用于水下,而目前针对UWSN 提出的信息处理及其相关算法的研究则仍处于起步阶段,不少文献仅仅提及要在UWSN 中使用数据压缩,但并未深入展开[13]。在已发表的应用于UWSN的信息处理方法中,有研究提出将传统的网络编码延伸到水下,运用水下模拟测试平台,验证了简单网络拓扑下(菱形拓扑),利用数据相关性对其进行网络编码,能有效弥补水下环境带来的信号损失,提高差错恢复率[14]。还有研究提出,可在多跳传输机制中使用随机线性网络编码,提高信道吞吐量[15]。
3 适用于水下网络的自适应时域压缩
能量的高效使用是UWSN 的首要设计目标。数据压缩(Data Compression)技术被引入UWSN 中,得益于其在去除数据冗余方面的能力。在满足应用需求的前提下,对原始数据进行适当的网内处理,减少数据传输量,进而有效地节省能耗,延长网络生存寿命,是数据压缩的基本功能。
3.1 背景技术
通过对现有时域压缩算法的节能效益进行评估后发现,数据压缩算法不能保证在任何情况下都能获得节能效果。在某些应用场合中,节点的密集部署使得通信的射频功率降低,而数据的精度要求较高则直接影响压缩的执行效果。在这种情况下,执行网内数据压缩未必能够实现预期的节能目的,反而会因为额外增加的计算能耗超过节省的通信能耗,使执行压缩算法得不偿失。由此,一种针对单一时域压缩算法进行节能优化的节点级压缩判决机制被提出,并用来在执行压缩前,对压缩是否节能进行预判[16]。
将 “压缩判决方法” 应用于传感器节点,能够有效避免压缩可能带来的不必要的能量损失,但此方法仍然存在着一定的不足:压缩判决仅针对单个节点进行能量优化,并未考虑网络全局和无线通信的信道质量。该方法从节点自身的能量损失来判断压缩是否节能,通过将节点执行压缩的计算能耗与节点发送压缩后数据能够节省的发射能耗进行比较,得到判决结果。由此可见,此方法只实现了节点级的能量优化,并未涉及网络中普遍存在的多跳传输情况以及实际信道的多变性。在多跳传输中,压缩带来的通信数据量的减少,不仅能够节省本地节点的发射能耗,而且也能降低后续中继节点的通信能耗,与此同时,无线信道的不确定性带来了数据重传的可能。因此,在压缩与否的判定中,需要进一步考虑网络中的其他节点和实际信道质量,实现全网级别的能量优化。
3.2 具体实现
图4 为传感器节点的硬件框架。该基本架构以微处理器为主要控制单元,兼备一定的存储功能。其余各个模块的功能如下:传感器(或称为执行器)负责实现数据采集;射频收发器进行数据的无线传输;能量供应单元分别给射频收发器、微处理器以及传感器提供能量;用户接口负责节点与上层管理终端的通信连接,包括应用参数的设置以及相关信息的读取。

图4 传感器节点的硬件框架
图5 为软件架构体系,该体系位于节点微处理器的处理单元内,该体系在数据处理层中添加了压缩决策的模块,以此实现自适应压缩控制。整个软件体系共分五个层次,与互联网所使用的五层协议类似,从顶至下依次为:应用层、数据处理层、网络传输层、数据链路层以及物理层。其中,数据处理层包括两个子功能模块:数据压缩和压缩决策,压缩决策执行本研究所阐述的压缩判决过程,数据压缩执行数据压缩过程。所需的预知信息均读取自微处理器的存储单元,分别由与微处理器连接的各个模块提供。通过压缩决策可以得到最佳的压缩执行策略: 执行备选压缩算法中的一种或是不执行任何压缩操作。

图5 传感器节点的软件架构体系
本设计中,整个自适应压缩方法包括两个部分:建模和决策执行。由于压缩决策需要预测出各种备选压缩策略的总能耗并加以比较,因此在执行决策前要建立相应的预测模型。本研究涉及到的预测模型包括:压缩比的预测模型和压缩执行时间的预测模型。通过数据库技术建立的这两种预测模型,采用不同种类的备选压缩算法,基于同一种原始数据,以不同精度要求下获得的压缩比和执行时间作为建模输入,在MCU 中对数据进行统计分析及插值计算,进而构筑预测所需的二维表格,当压缩比的预测模型和压缩执行时间的预测模型建立后,通过查表的方式,由压缩比的预测模型得到CR,由压缩执行时间的预测模型得到TMCU。本研究所需的预测模型,是基于精度要求e 的二维表,其属性分别为:
压缩比预测表={(精度要求),(平均压缩比)}压缩执行时间预测表={(精度要求),(平均压缩时间)}
不同的压缩算法均构筑对应的两张预测二维表,并通过查表完成压缩比和压缩执行时间的预测。若应用提出的精度要求无法直接在表中查得,则采用插值运算获得所需值。本设计采用分段多项式插值中的分段线性插值,当然,其他低复杂度量的插值运算也可用于本研究,不限上述几种。
分段线性插值的基本原理是:设函数y=f(x)在节点:a≤x0<x1<…xn≤b 上的函数值为: f(x0),f(x1),…,f(xn)则在区间上[xk,xk+1],对应节点x 的插值I(x)可由下式计算得到:
以上建模过程称为自适应压缩方法的机器学习,由节点在线完成。机器学习程序使用所记录的样本数据,通过统计分析和插值计算,得到两种预测模型的二维表格,以此取代人工输入参数的离线建模方式。
在网络运行初期,节点执行各种备选压缩算法,记录不同精度要求下各种算法的压缩比和压缩执行时间,以此作为样本输入,构筑两种预测模型的二维表,并将其存储于微处理器中,完成首次建模。为了保证预测的准确性,在之后的网络运行过程中,节点将随机选取若干新样本进行模型验证,若其预测误差超过设定的阈值将触发节点再次进入机器学习,对模型予以修正和调整。机器学习过程中,节点将不执行任何压缩算法,直接传输原始数据。
自适应压缩方法的决策执行部分即为实际执行压缩判决的过程。图6 为本设计提出的压缩决策的工作流程。整个工作流程包括以下几个步骤:
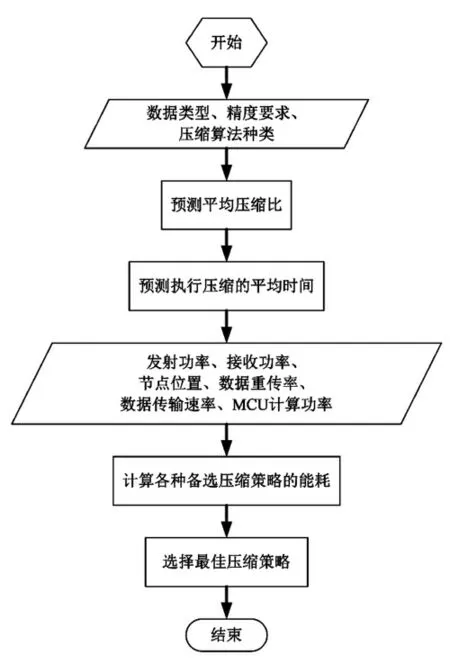
图6 传感器节点的软件架构体系
步骤1: 如果压缩决策所需的任一预知信息发生改变,则压缩决策启动。预知信息中,发射功率、精度要求、节点位置(跳数)和数据重传率的变化相对频繁,故而成为启动压缩决策的主要因素。
步骤2: 压缩决策模块从应用层中获取相关信息。所涉及的信息包括:数据类型、精度要求以及压缩算法种类,相应地保存于微处理器的存储单元内,可以通过用户接口预先设置(节点部署前),也可以取自射频模块提供的控制帧信息(节点部署后)。
步骤3:根据应用层提供的相关信息,预测各种备选压缩算法(本文为一次移动平均预测、LAA、PMC-MR 和LTC)所能获得的平均压缩比CR。预测过程需要借助自适应压缩方法在机器学习阶段建立的预测模型。本文涉及到的压缩比,其定义为压缩后的数据总量与原始数据量之比。经由样本统计所获得的压缩比预测模型,通过查表或插值运算,可以预测出确定类型的原始数据,在特定的压缩算法和不同的精度要求下,能够达到的平均压缩比CR。本文的精度要求也可表示为应用背景给出的数据误差容限。
步骤4:根据应用层提供的相关信息,预测执行各种备选压缩算法(本文为一次移动平均预测、LAA、PMC-MR 和LTC) 所需的平均时间作为TMCU。该预测过程与步骤3 中所述的过程相类似,即预测过程需要借助自适应压缩方法在机器学习阶段建立的预测模型。经由样本统计获得压缩执行时间的预测模型,通过查表或插值运算,预测出确定类型的原始数据,在特定的压缩算法和不同的精度要求下,能够达到的平均压缩时间TMCU。
步骤5: 压缩决策模块从网络传输层中获取相关信息,包括:发射功率、节点位置(跳数)、数据重传率、接收功率、数据传输速率以及MCU 计算功率等。
步骤6: 计算各种备选压缩算法的总能耗Ecomp以及不执行压缩时的总能耗Euncomp。压缩算法的总能耗Ecomp和不执行压缩时的总能耗Euncomp经由以下推导给出:
压缩算法的总能耗由两部分组成: 微处理器(MCU)执行压缩的能耗和射频(RF)模块的通信能耗;不执行压缩时的总能耗则仅有射频模块的通信能耗。考虑到射频模块的唤醒能耗是所有情况共有的(无论是否执行压缩算法,或是执行哪种压缩算法),因此不会对能耗比较结果产生影响;同时,数据帧的帧头部分长度相比于数据部分而言微乎其微,也是可以忽略的,因此,总能耗Ecomp和Euncomp可以简化为:
其中,PMCU为微处理器MCU 的功率;L 为原始数据总长度;TMCU为在已知精度要求e 下,节点压缩1 个字节数据的时间开销,由压缩执行时间的预测模型计算得到(步骤4);PTX为节点间通信距离d 下,射频模块的发射功率;CR 为在已知精度要求e 下,算法的平均压缩比,根据压缩比预测模型计算得到(步骤3);Ttran为节点发送1 个字节数据所需的时间,由数据传输速率决定;PRX为射频模块的接收功率;节点位置即跳数h=1 表示的是汇Ttran聚节点的邻居节点,由于汇聚节点是能量不受限的超级节点,因此这种情况下的总能耗仅考虑发射部分,而无需包含接收部分;数据重传率g 反映出节点多跳路由中通信信道质量,数值越大,表示接收误码率越高,通信信道越恶劣。
步骤7: 比较各种备选压缩算法的总能耗Ecomp和不执行压缩时的总能耗Euncomp,选择其中能耗最低的一种压缩策略,并予以执行。能耗最低即表示策略的节能效果最佳,其比较结果可能为备选压缩算法中的一种,也可能是不执行任何压缩,直接发送原始数据。
步骤8:节点结束一次压缩决策过程。
4 实验结果
为了检验自适应压缩方法对网络能耗的优化作用,我们首先选取采自于实际物理环境下的传感器数据及适用于该数据特性的压缩算法,以此建立所需的两种预测模型,即完成自适应压缩方法的机器学习阶段;然后通过仿真来比较传统的数据压缩算法与结合了压缩决策的自适应压缩方法,在等同条件下的能耗差异。此外,为了验证预测模型的在线建模方式对数据特性变化的跟踪能力,我们选择两种不同变化特性的数据样本,比较其与离线建模方式的预测准确性,并同时对本课题采用数据库建模技术取代数据拟合方式的可行性进行了验证。
这里选取的原始数据来自于太平洋海洋环境实验室的热带大气海洋计划。此外,我们选择的4种备选压缩算法分别代表了复杂度和压缩效果的不同折中,包括复杂度较低、但压缩效果较差的LAA 和一次移动平均预测,以及复杂度较高、但压缩效果较好的PMC-MR 和LTC。需要特别指出的是,根据我们对大量数据类型和压缩算法的仿真,本课题提出的自适应压缩方法并不局限于特定的数据类型和备选压缩算法,这里选择特定的数据类型和备选压缩算法只是为了更好地说明这一方法所能获得的效果。
表1 给出了TAO 中原始数据海水温度在一次移动平均预测算法作用下获得的平均压缩比二维表。同理可以获得压缩算法执行时间的预测模型。为了比较数据拟合与本课题所述的数据库关系模型在预测精度上的差异,我们选取实际数据的真实压缩比进行对比,如表2 所示。其中,“查表值” 即为关系模型建立后得到的二维表中的数值。可以看出,基于数据库技术的压缩比预测并未引入太多的误差,反而大大简化了预测过程,降低了预测的计算量和复杂度。

表1 一次移动平均预测的平均压缩比表

表2 数据拟合和关系模型对比
若二维表中无法查到所需的预测值,本课题提出可通过插值计算得到。表3 所示为插值得到的压缩比预测,作为对比,同时给出数据拟合下的压缩比预测值和真值。从表3 的对比结果可以看到,通过插值计算得到的压缩比预测并未损失太多的准确度。

表3 数据拟合和插值计算对比
为了验证预测模型的修正特性,测试采用两种不同特性的原始数据作为样本,以此模拟数据特性发生变化,进而触发机器学习的情况。表4 给出的是启动新一轮机器学习后,一次移动平均预测的平均压缩比表。表5 所示则为更进一步的修正前后两张二维表的压缩预测值对比。由此可见,本研究提出的基于机器学习的在线建模方式和结合插值计算的关系模型构筑能够很好地实现对压缩比和压缩执行时间的预测,为后续的压缩决策提供准确的参考指标。

表4 一次移动平均预测的平均压缩比表
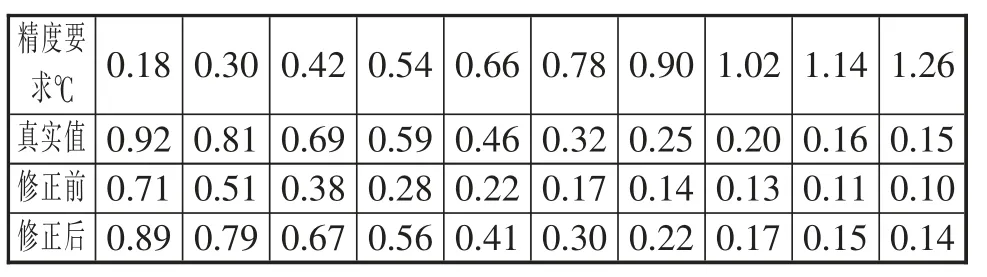
表5 修正前后二维表的预测对比
鉴于水下无线传感器节点与WSN 节点仅在通信信道参数方面存在差异,且由于本课题未能顺利采购水下无线传感器节点,能量优化的验证实验采用加州大学伯克利分校开发的MicaZ 试验节点作为替代的硬件平台,后期若能获取水下无线传感器节点的实际参数,则将本研究涉及的参量进行替换即可。本试验节点的处理器平台参考ATMEGA 128L。以50 个数据为单位(组)执行压缩,共选取100 组。为了确保验证的准确性,所用的原始数据不同于机器学习阶段使用的统计样本。实验中的网络拓扑采用等密度分布的栅格(grid)结构。网络规模为25*25,共625 个节点,其中,汇聚节点位于全网中心,其余为同构的传感器节点。源节点以最短路径树(Shortest Path Tree,简称SPT)的形式路由到汇聚节点。由于源节点的分布密度相等,因此假定节点采用统一级别的发射功率进行数据传送,且各无线信道设定为相同的数据重传率。随着网络节点的失效,网络密度将会降低,射频发射功率和数据重传率则相应增大。
事实上,如果节点的每组数据都能采用能耗最低的策略完成数据传送任务,则可认为是网络节能的最理想情况。实验即以该理想情况作为参照,将各种情况下节点总能耗的统计结果与之相比,给出各种实现方式相对于理想情况的最大偏差(用百分比表示),如表6 所示。表中 “E” 代表所设精度要求级别,“RF” 代表发射功率级别,“γ” 代表数据重传率,即 “E2_RF7_γ0.1” 表示所设精度要求的级别为2,发射功率级别为7,数据重传率为10%。从表6 中的统计结果可以看到,加入了压缩决策的自适应压缩方法,针对不同的精度要求、发射功率和数据重传率,全网节点都能以接近能耗最优的情况完成数据传送任务。当精度要求较高时(如 “E2”),压缩算法未能达到理想的数据压缩效果,反而增加了额外的计算损耗,由此,节点的总能量损失背离理想情况较多,此时,不执行压缩或是执行复杂度较低的算法反而会使能耗逼近最优值。随着精度要求的降低,压缩算法逐级显露出在节能上的优势,尤其是压缩效果好且执行复杂度低算法,将被越来越多的节点所采用,而此时,不执行压缩却逐渐增大了其与理想情况的偏离程度。

表6 各种实现方式与理想情况的最大能耗偏差
由于受到压缩比及压缩时间预测精度的限制,在实现节能优化机制过程中,不可避免地会有误判产生,这也导致了某些情况下,单一执行压缩策略的能耗更接近最优情况(如 “E10_R7_γ0.1”)。但从总体而言,自适应压缩方法能够为节点提供较为准确的节能策略,使其能以能耗接近最优的情况完成数据传送,最高的偏离度不超过5%。
5 结论
作为UWSN 体系结构中应用层的实现功能,对原始数据的信息冗余进行网内信息处理,在保留应用所需信息量的前提下,将需要传输的数据量最小化,这样,不仅能够有效应对水下传输能力弱的问题,提高数据传输速率和带宽利用率,避免网络拥塞,更重要的是,通过压缩来减少通信量,有利于降低水下节点的通信能耗,延长节点乃至整个网络的使用寿命,提高有限能源的使用效率。本研究尝试在节点的软件框架中增加网络级的节能优化机制,提出了一种符合海洋数据特性的自适应压缩方法,保证了各个位置上的节点均能根据自身的实际情况以能耗接近最优的效果完成数据传送任务。
猜你喜欢
China Report Asean(2022年8期)2022-09-02
物联网技术(2020年12期)2021-01-27
软件(2020年3期)2020-04-20
铁道通信信号(2019年9期)2019-11-25
汽车零部件(2017年4期)2017-07-12
电讯技术(2017年4期)2017-04-16
电测与仪表(2015年14期)2015-04-09
汽车与新动力(2014年6期)2014-02-27
汽车与新动力(2014年5期)2014-02-27
汽车与新动力(2014年4期)2014-02-27
