
改进DeepLabV3+网络的指针轨迹图像识别
2024-01-10 17:05袁帅,蒋强,饶兵
沈阳理工大学学报 2024年1期
袁 帅,蒋 强,饶 兵
(1.沈阳理工大学自动化与电气工程学院,沈阳 110159;2.沈阳天眼智云智能技术研究院有限公司,沈阳 110179)
在精密仪器运输过程中,通常采用指针式机械记录仪记录震动轨迹图像数据,若采用人工检定方法,检定结果不精准,工作量巨大且效率很低。 通过机器学习相关技术,可实现高效率高精度自动检测指针式机械记录仪震动轨迹图像,极大地减少人工工作量[1]。
2014 年开始,谷歌团队推出并发展了具有良好分割性能的DeepLab 系列分割网络,其中DeepLabV3+网络[2]在语义分割领域表现更为突出,准确度更高。 以DeepLabV3+为基础,学者们进行了深入研究,将其应用于诸多领域。 2019 年,Liu 等[3]通过添加更多的跳跃连接和卷积层来设计DeepLabV3+解码器,改善了遥感图像中建筑物轮廓的检测结果,但对细微边界分割效果不理想。 2022 年,Zhang 等[4]在DeepLabV3 + 中加入一种基于边缘信息的损失函数,提高了网络对舌边的分离效果,但对错误分类处理能力不高。 同年,刘慧等[5]使用轻量化MobileNetV2 作为Deep-LabV3+骨干网络,减少了模型参数,并使用Re-LU6 激活函数减少部署在移动端设备上的精度损失,但对小像素目标识别效果较差。 2023 年,周迅等[6]在DeepLabV3+中使用三点注意力模块提高了对坝面裂缝像素的提取能力,但存在漏检情况。
本文将DeepLabV3+网络模型应用于指针式机械记录仪轨迹图像的识别。 使用轻量化网络MobileNetV3 替换原骨干网络Xception,实现模型轻量化;在解码器中使用2 个连续的2 倍上采样替换原网络中的4 倍上采样,将提取到的特征图逐步放大,使得还原出的边界更加细化。
1 DeepLabV3+网络及其改进
1.1 DeepLabV3+网络介绍
DeepLabV3+网络使用编码器-解码器(Encoder-Decoder)结构[7-8],在提升分割效果的同时关注边界信息。 模型采用Xception 作为骨干网络,使用空洞空间卷积金字塔池化(atrous spatial pyramid pooling,ASPP)融合特征图多尺度信息,并将深度卷积和逐点卷积[9]应用于ASPP 和Encoder 模块中, 使网络训练速度更快。DeepLabV3+网络结构如图1 所示。 图中:Conv表示卷积;rate 表示膨胀率;Upsample 表示上采样;DCNN 表示深度卷积神经网络;Atrous Conv表示空洞卷积;Pooling 表示池化;Low-level Feature 表示低级特征;Concat 表示数据拼接。
DeepLabV3+网络通过Encoder 结构得到两部分图片特征,在Decoder 中使用卷积调整通道,融合两部分特征,再使用线性插值上采样使得输出层和原图片尺寸一致,获得预测结果[10-11]。
1.2 改进的DeeplabV3+网络
1.2.1 改进DeepLabV3+骨干网络
由于本文检测对象是设备运输过程中的指针震动轨迹,为满足实时检测和移动检测的要求,需将训练好的模型部署在移动端硬件平台上。 因此,在进行图像特征提取时要尽量保证全局信息的准确性,同时简化参数和计算量,保证识别效率。
为解决上述问题,可采用轻量化网络模型。DeepLabV3+骨干网络为Xception,该网络结构比较复杂,参数量较多,消耗大量的显存。 本文对DeepLabV3+结构的骨干网络实现轻量化,采用MobileNetV3 代替Xception[12],轻量化网络MobileNetV3 的参数量较少,更易于部署到移动设备上。 MobilenetV3 的瓶颈(bneck)结构如图2 所示。 图中:NL 表示非线性激活函数;Pool 表示平均池化;Dwise 表示深度可分离卷积;FC 表示全连接层;ReLU、hard-σ 表示激活函数;⊗表示乘法操作。
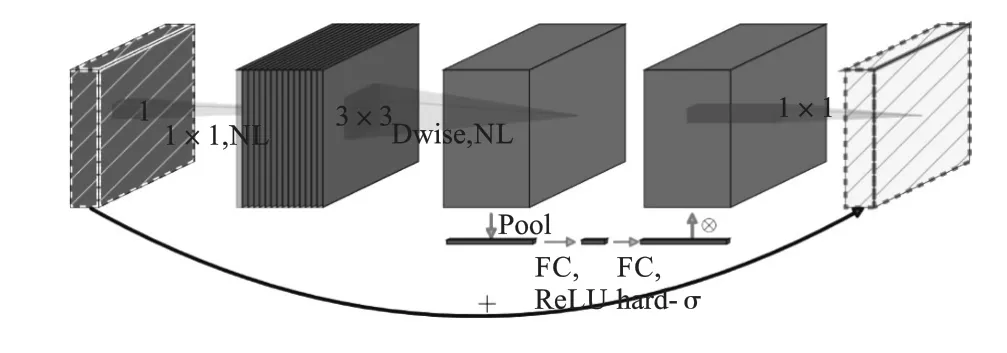
图2 MobileNetV3 网络的bneck 结构Fig.2 Bneck structure of MobileNetV3 network
MobilNetV3 在MobilNetV2 的结构基础上增加了注意力机制(squeeze-and-excitation,SE),并使用h-swish 激活函数替换swish 函数,相比于MobilNetV2,MobilNetV3 模型更加轻量化,降低了计算成本,识别精度更高,计算速度更快。
1.2.2 改进DeepLabV3 +模型解码器设计
经Encoder 得到的特征图由大量的像素矩阵构成, 各像素之间均存在密切的联系,DeepLabV3+网络中Decoder 将传入的特征图直接使用一次双线性4 倍上采样恢复目标边界信息,会使图像的像素不连续,导致网络预测边界不精确[13]。 本文将传入Decoder 中的特征信息先进行一次2 倍上采样,还原边界信息,然后再进行一次2 倍上采样,即使用2 个连续的2 倍上采样替换原始DeepLabV3+网络中的4 倍上采样,增强图像中像素的连续性,还原出的边界信息更接近原始标注图像,从而获得更清晰的目标边界。 改进的DeepLabV3+网络模型在Decoder 中仅添加了1 次上采样操作,相比DeepLabV3+网络模型,参数增加极少。 改进前后的Decoder 部分如图3所示。

图3 改进前后的Decoder 部分Fig.3 Decoder part before and after improvement
改进后的DeepLabV3 + 网络结构如图4所示。

图4 改进后的DeepLabV3+网络结构Fig.4 Improved DeepLabV3+ Network Structure
2 实验与分析
2.1 实验环境
本文基于百度飞桨(PaddlePaddle)深度学习框架进行实验。 模型训练过程中使用随机梯度下降法,最大训练轮次为10 000 轮。 单次训练样本数设置为2,初始学习率设置为0.01,之后通过多项式衰减策略减少学习率。
实验数据来自设备运输过程中采集的指针式机械记录仪震动轨迹图像,以此自制数据集,该数据集包含精细标注影像873 张,标注内容包括轨迹和背景。 由于总体样本数据较少,采用图像反转、水平和垂直镜像等处理方法进行数据增强,丰富实验数据集。
为解决网络模型在不同工作场景的算法适用性问题,使用图像分割套件PaddleSeg 中的预训练模型,加快模型训练速度并保证特征提取效果,提高模型对指针轨迹图像识别的准确性和泛化性。
2.2 评价指标
本文选用平均交并比(MIoU)作为实验结果评价指标,MIoU 是语义分割领域的标准度量指标。 分别对每个类计算交并比(IoU),再对所有类别的IoU 求均值,即为MIoU。 其计算式为
式中:k+1 表示图像中所有分割类别数目;pij表示标签为i被预测为j的样本数量;pji表示标签为j被预测为i的样本数量;pii表示标签为i被预测为i的样本数量。
采用单位时间内模型检测图片的数量(FPS)作为另一个评价指标,该评价指标越大,表示检测的速度越快,其值为待检测的图片总数与模型预测所需的时间之比。
2.3 实验对比
对改进前后的DeepLabV3+模型进行训练测试,两组实验均使用PaddleSeg 套件中自带的预训练模型,训练过程中其他条件相同,得到的可视化参数如图5 和图6 所示。

图5 原始DeepLabV3+网络训练参数Fig.5 Original DeepLabV3+ network training parameters
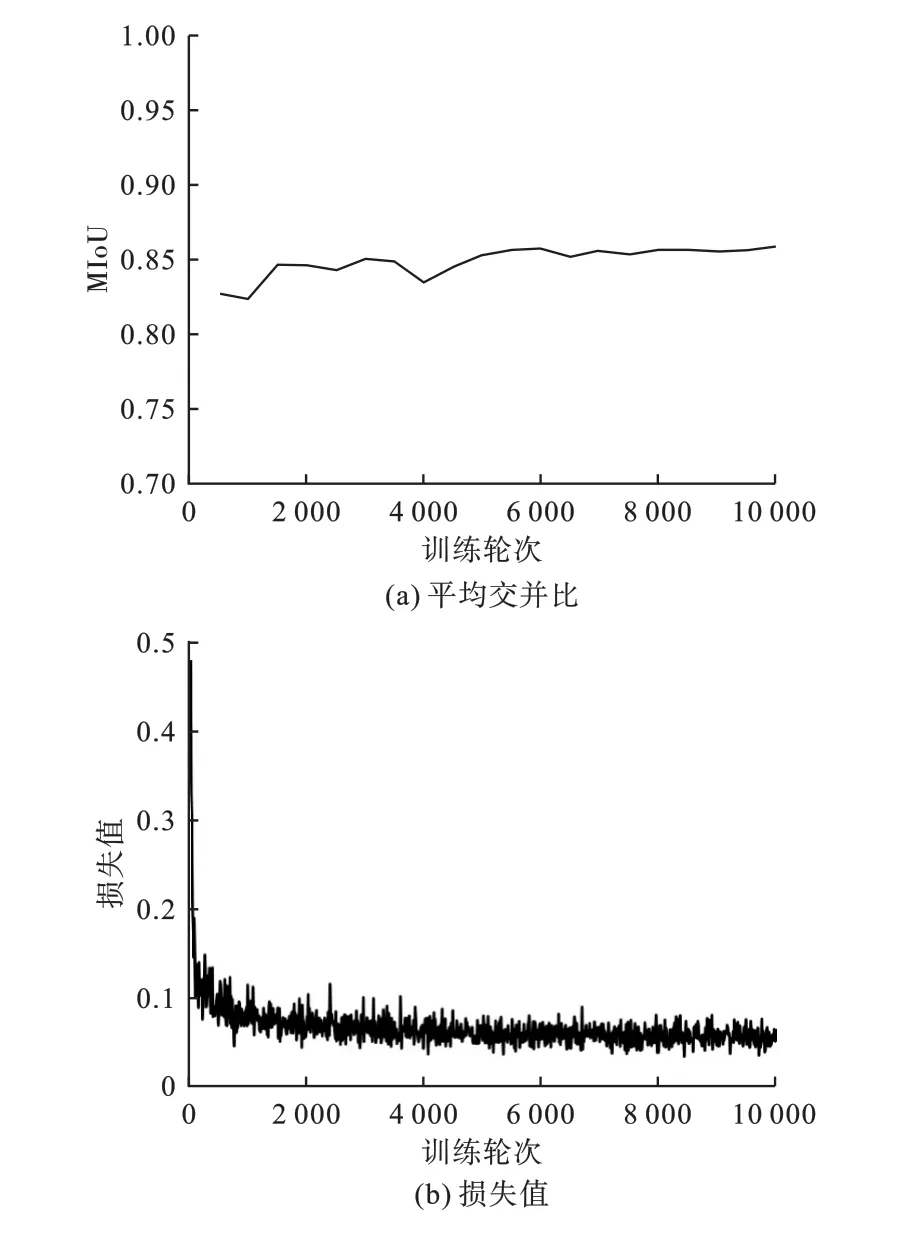
图6 改进DeepLabV3+网络训练参数Fig.6 Improved DeepLabV3+ network training parameters
由图5 和图6 可见,改进DeepLabV3+网络的MIoU 更高,模型识别指针轨迹图像的能力更好,损失函数能够更快地收敛且下降程度更大,模型的性能更优。
训练完成后,将测试集中图片统一调整为相同的分辨率,分别使用网络改进前后两组实验中的最好模型进行预测,以图片1 和图片2 为例,两个图片的预测结果如图7 和图8 所示。

图7 对比实验预测结果(图片1)Fig.7 Comparisons of experimental prediction results(image 1)

图8 对比实验预测结果(图片2)Fig.8 Comparisons of experimental prediction results(image 2)
由图7 和图8 可见,本文提出的改进Deep-LabV3 + 网络模型可以更好地获取轨迹语义信息,漏检和误检的比例更小,对轨迹特征提取能力更强,能够更好地完成轨迹图像识别任务。
模型预测参数及模型大小如表1 所示。

表1 模型参数对比Table 1 Comparisons of model parameters
由表1 可知,本文提出的改进DeepLabV3+网络模型检测结果更精细、检测速度更快、模型体积更小,体现了该算法的可行性和优越性。
3 结论
为解决运输过程中车辆颠簸是否导致仪器设备损坏的检测问题,以DeepLabV3+作为语义分割模型,将其骨干网络替换为轻量化网络Mobile-NetV3,减少了参数量,解决了模型部署到移动端硬件平台的问题;针对Decoder 结构中4 倍上采样操作导致图像中的边界像素不连续、丢失某些重要像素信息问题,采用2 次2 倍上采样增强图像中像素的连续性,还原出的边界信息更接近原始标注图像,获得了更清晰的目标边界。 改进后的DeepLabV3+模型体积减少了129.64 MB;检测结果更精细,MIoU 达到85. 84%,提高了3.57%;检测速度更快,FPS 提升了3.58 s-1。 本文提出的改进DeepLabV3+网络降低了模型的参数量、加快了检测速度、提高了模型对轨迹图像识别的泛化能力,更宜于实际应用。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
儿童时代·幸福宝宝(2021年11期)2021-12-21
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
证券法律评论(2018年0期)2018-08-31
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
专用汽车(2016年1期)2016-03-01
