
LLM在工业品物料分类场景的应用
2024-01-11 10:23朱俊
宝钢技术 2023年6期
朱 俊
(欧冶工业品股份有限公司,上海 201900)
1 工业品领域物料分类技术现状及场景落地
1.1 工业品领域物料分类任务的概述
随着全球工业化进程的不断推进,工业品领域物料的种类与数量呈现出爆炸式增长。自21世纪初以来,全球制造业产值已经翻了一番多[1]。如何对这些物料进行有效的分类和管理,已经成为企业降低成本、提高生产效率和市场竞争力的关键问题。采用有效的物料管理系统可以帮助企业提高生产效率,同时降低库存成本。因此,研究工业品领域物料分类技术具有重要的实际意义和理论价值。
1.2 NLP技术在工业品领域物料分类中的应用及局限性
近年来,自然语言处理(NLP)技术在物料分类领域取得了显著的成果。主要可以概括为基于规则的分类方法和基于深度学习的分类方法。
基于规则的分类方法是物料分类技术的传统方法,通过人工设定一系列规则进行分类,例如基于专家经验制作关键词—物料类别对照表。这种方法在物料种类较少、规则明确的场景下具有一定的实用性。然而,随着物料种类的增多,规则的制定变得越来越复杂,人工设定的规则很难覆盖所有物料,导致分类效果不理想。
随着深度学习技术的不断发展,这类方法在物料分类上也得到了不少应用,并具有更好的泛化能力和更高的准确率[2]。例如DNN、LSTM、BERT等,可以有效地解决基于规则方法在物料种类繁多、规则复杂的情况下的局限性,可以随着数据集的增长和变化不断优化模型性能[3]。
然而,基于深度学习的物料分类方法仍然存在一定的局限性。首先,深度学习模型需要大量的标注数据进行训练,而在工业品实际场景中,大部分物料数据质量较差,存在物料属性数据缺失、型号规格书写不规范等问题,获取高质量的标注数据是一大难题。此外,深度学习模型的可解释性较差,由于工业领域对准确性的要求较高,这可能导致企业在实际应用中对模型输出的结果产生质疑,从而影响模型的推广应用。
综上所述,工业品领域物料分类技术已经取得了一定的成果,但仍然面临着诸多挑战。传统的基于规则的分类方法在应对复杂物料分类任务时显得力不从心,而基于深度学习的分类方法虽然具有一定的优势,但也存在数据需求高、可解释性差等问题。
近期,随着GPT模型的快速崛起,生成式大语言模型逐渐成为自然语言处理领域的新风向,大量任务引入生成式大语言模型并取得了显著的效果。因此,在未来的研究中,探讨如何将生成式大语言模型与物料分类技术相结合,实现对工业品领域物料的高效识别和分类,具有重要的研究价值。
2 生成式大语言模型在工业品物料分类上的应用
2.1 生成式大语言模型原理
大语言模型(LLM),如GPT-3和GPT-4(GPT即生成预训练 Transformer)是基于Transformer架构的NLP模型。大语言模型的训练过程基于一个被称为“自监督”的学习任务。在这个任务中,模型预测给定一个文本序列中的下一个词是什么。例如,如果输入的文本是“今天天气很好,我打算去公园”,那么模型的任务可能是预测“出行”这个意图。这个任务要求模型学习到大量的语言知识,包括语法、词汇、习语,甚至一些世界知识。LLM通过在大量的文本数据上进行训练来完成这个任务。训练数据可以包括各种类型的文本,比如书籍、文章、网页等。模型通过这种方式学习了大量的语言模式,从而可以生成流畅且自然的文本。
大语言模型可以应用于各种自然语言处理任务,包括但不限于以下几个方面:
(1) 文本生成:生成一篇文章,写一个故事,或者是创作一首诗。
(2) 机器翻译:将文本从一种语言翻译成另一种语言。
(3) 问答系统:在问答系统中,大语言模型可以用来生成问题的答案。
(4) 文本摘要:生成文本的摘要或者是概括。
(5) 情感分析:分析文本的情感倾向,是积极还是消极。
(6) 代码生成和代码理解:理解和生成编程代码,这对于开发者帮助和代码自动完成等场景非常有用。
(7) 聊天机器人:用于构建能够与人自然交流的聊天机器人。
2.2 工业品物料分类应用场景
在工业品采购过程中,基于采购需求的描述,对工业品询单物料进行分类,有助于精细化识别用户需求,推荐最优质的供应商。在该应用场景中,分类模型需要根据非结构化物料文本信息(可能包括物料名称、型规、技术属性及使用场景),将物料分类到一个具体的叶类,叶类来自于给定的物料叶类体系。本文用于训练的数据集是物料库中的物料数据,共1 081 488条,每条包括名称、品牌、型规、技术属性、叶类字段,其中叶类即为预测目标,共581个叶类。另外有来自于实际业务场景中的物料数据523 897条,不包括所属类别信息。
2.3 生成式大语言模型数据增强及效果
针对该场景,使用传统的规则方法或深度学习方法效果较差。本文提出一种使用大语言生成式模型增强工业品物料分类的方法,以提高分类的准确性和鲁棒性,并降低算力消耗。
首先,通过引入生成式大语言模型,分别对训练数据进行增强,以及对多个分类模型进行集成,以增强分类模型的表现。作为参考,本文首先设计了一个基于关键词—叶类表的TF-IDF统计学分类模型(每个关键词对每个叶类计算TF-IDF,形成关键词—叶类的权重表),一个基于Word2Vec+LGBM的分类模型[4],以及一个基于微调后的BERT的分类模型[5],各原始模型分别在测试集上的表现如表1所示。

表1 原始分类模型效果统计指标Table 1 Statistical metrics for the performance of the original classification model
本文以BELLE-7B-2M模型[6]为基础,通过物料数据库数据对BELLE进行微调,对原始数据进行增强。微调采用instruct-answer的形式,instruct为“有以下物料信息,{物料名称、型规、品牌、技术属性的拼接},请问它属于哪个叶类”。answer为“{叶类名称}”。微调数据采用平滑分布抽样[7]后的物料库数据2万条,并保证每个叶类至少有一条物料数据。
在第一阶段,使用生成式大语言模型对数据量较少的叶类进行数据增强。具体实施步骤见图1、2。
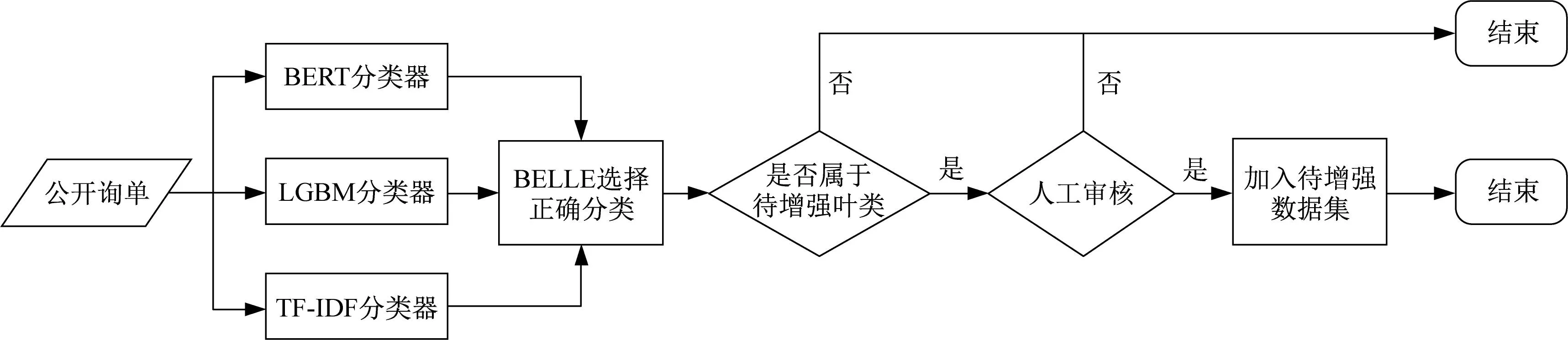
图1 使用原分类器结合人工审核找到分类效果较差叶类数据Fig.1 Finding poorly classified leaf data by the original classifier and manual review

图2 使用BELLE对数据集进行增强Fig.2 Data augmentation with BELLE applied to the dataset
(1) 在物料数据库中,采用分布平滑抽样的方法取15%的数据作为测试集[7],并确保每个叶类至少有一个测试数据。统计三个模型的测试集结果,分别统计结果中所有叶类的F1值,取在三个模型下F1值均处于后四分之一的叶类作为待增强叶类集合。
(2) 使用LGBM、BERT和TF-IDF这三个模型分别对物料数据进行分类,得到三个类别预测结果(可以重复)。使用微调后的BELLE在这三个结果中进行选择。取结果属于待增强叶类的物料并人工审核BELLE的选择是否正确,筛选后得到共1 362条物料数据,作为增强样本。
(3) 使用BELLE对增强样本进行数据增强,即通过prompt“生成类似{增强样本中的物料信息}的物料数据”使BELLE生成近似的物料数据,以1∶10的比例扩充增强样本以解决原数据分布不均及稀疏的问题[8]。
(4) 使用增强样本继续微调训练LGBM和BERT模型,使其在待增强叶类上的性能得到提升。
在一阶段融合后,LGBM和BERT在同样的测试集下表现如表2所示。

表2 一阶段加强后分类结果Table 2 Classification results after first-stage enhancement
在第二阶段,将增强后的LGBM模型、增强后的BERT模型,以及原始的TF-IDF模型在推理阶段进行集成,从而进一步提高工业品物料分类的准确性和鲁棒性。具体实施步骤如图3。

图3 使用BELLE对BERT、LGBM和TF-IDF分类进行集成Fig.3 Integration of BERT,LGBM,and TF-IDF classifiers using BELLE
(1) 分别使用增强后的LGBM模型、增强后的BERT模型和原始的TF-IDF模型对测试样本进行推理,得到各自的预测类别。这一步骤可以提供多种视角的预测结果,为后续的融合打下基础。在实际操作中,我们将各模型的输出结果进行归一化处理,以消除不同模型预测概率值之间的差异。
(2) 使用微调后的BELLE对这三个预测类别进行判断。具体而言,微调后的BELLE模型会将各模型的预测结果作为输入,输出一个综合评估后的类别预测。BELLE模型基于其自身与训练及微调的结果,对物料信息及三个模型的分类结果进行理解并选择,从而使集成后的模型性能更加优越。
通过BELLE进行集成学习后在同样的测试集下可以得到表3所示结果。

表3 二阶段加强后分类结果Table 3 Classification results after second-stage enhancement
2.4 试验结果与分析详述
本研究采用了三种模型:TF-IDF统计分类,LGBM及BERT模型进行分类,并采用微调后的BELLE-7B-2M模型进行两阶段的加强。实验结果显示,在使用微调后的BELLE模型一阶段加强,对LGBM和BERT进行样本增强和再次训练后,LGBM在精确率0.88、召回率0.87和F1值 0.87上有所提升,BERT在精确率0.87、召回率0.89和F1值 0.88上也有所进步。在微调后的BELLE模型二阶段加强后,通过对三个基础模型的预测结果进行选择完成对三个模型结果的集成,集成后的模型在精确率0.89、召回率0.90和F1值 0.89上相比三个模型独立工作取得了进一步提升。总体来说,通过BELLE加强原分类模型的方法在提升模型性能方面取得了成效。
3 结语
本文通过对工业品领域物料分类技术的分析,提出了一套结合生成式大型预训练模型(如BELLE)和深度学习分类器的物料分类方案,并经实验进行对比验证了生成式大型预训练模型能够为分类任务带来有效提升。这套方案充分利用了生成式模型在数据预处理和增强方面的优势,同时结合领域知识和先进的深度学习技术,实现了高准确率的物料分类。
猜你喜欢
农业开发与装备(2021年2期)2021-12-27
四川农业与农机(2021年4期)2021-12-05
消费导刊(2021年7期)2021-07-12
中国特种设备安全(2019年11期)2020-01-16
中国蔬菜(2019年1期)2019-01-21
电线电缆(2018年2期)2018-05-19
现代工业经济和信息化(2018年13期)2018-02-21
甘肃农业科技(2018年1期)2018-02-02
家庭影院技术(2017年10期)2017-11-23
教育科学论坛(2014年8期)2014-03-01
