
应用无人机可见光影像和面向对象的随机森林模型对城市树种分类1)
2024-01-12 10:15陈逊龙孙一铭郭仕杰段煜柯唐桉琦叶章熙张厚喜
东北林业大学学报 2024年3期
陈逊龙 孙一铭 郭仕杰 段煜柯 唐桉琦 叶章熙 张厚喜
(福建农林大学,福州,350002)
城市树木作为城市的重要组成部分是评估城市生态环境的重要指标之一,具有重要的生态、经济和社会效益[1]。随着城市化进程的不断深化,城市树木的生态效益也日渐凸显。然而,不同种类、种植结构和种植区域的城市树木会产生不同的生态环境效益[2]。因此,及时准确地获取城市树种的类别和空间分布信息对城市规划、城市树木的管理与维护具有重要意义[3]。
传统的城市树种分类主要依靠地面调查,然而该方法存在成本高、耗时长且难以获取大尺度数据等不足[4]。近年来,遥感技术飞速发展,为城市树种的准确快速识别提供了新的途径。然而,传统的高分辨率卫星遥感影像易受天气和环境因素干扰、时效性较差且费用昂贵。此外,免费提供的卫星遥感影像空间分辨率低,难以适用于树种层面的识别研究[5]。相比传统的遥感平台,近地无人机(UAV)能在较小空间尺度上提供高分辨率的遥感影像和地理数据,具有更高的适用性,是遥感数据获取的重要手段之一[6]。然而,目前有关树种信息提取的无人机遥感研究多集中于多光谱、高光谱影像的分类领域,但由于搭载多光谱、高光谱传感器的无人机普遍价格昂贵,极大地限制了其在实际生产中的推广应用。随着数码技术的发展,通过搭载可见光传感器的无人机获取包含树种信息的遥感影像,具有获取方便、成本低、空间分辨率高等优点,已成为遥感影像识别树种研究方向上重要的数据源之一[7]。
根据遥感影像分类单元的不同,可将分类方法归为基于像元和面向对象两类。基于像元的方法主要关注局部像素的光谱信息,在处理高分辨率遥感影像时对噪声比较敏感、稳健性差,极易出现错分、漏分现象[8]。为弥补基于像元方法的不足,面向对象的影像分析技术(OBIA)逐渐被用于处理高分辨率遥感影像[9]。OBIA方法综合考虑区域相邻像素的纹理、形态以及空间结构等多维特征,减少了“椒盐噪声”的同时,通常具有更高的准确率[10]。然而,随着特征维数的增加,数据处理的难度呈几何倍数增长,使得传统分类算法的应用受到一定限制。随机森林(RF)是一种基于集成学习思想集成多颗决策树的机器学习算法,通过对样本的决策树建模以及组合多棵决策树的预测,最终由分类树投票决定数据的分类[11]。随机森林算法不仅具有模型简单、分类精度更高、校正参数更少的特点,而且鲁棒性强,不易过拟合,在遥感领域高维特征分类中得到广泛应用[12]。
面向对象方法可以有效减少“同物异谱”现象,而随机森林算法在处理高维数据时有其独特的性能优势,二者的结合在一定程度上提高了分类精度。宗影等[13]将面向对象方法和随机森林算法的有机结合,有效提高了滨海湿地植被的分类精度,总体精度达87.07%;赵士肄等[14]将面向对象方法和随机森林算法应用于耕地领域,并与其他机器学习分类算法进行对比验证,结果表明基于面向对象的随机森林模型取得了最高的耕地提取精度,并减弱了“椒盐”噪声,优化了分类结果;耿仁方等[15]研究结果表明,基于面向对象结合随机森林算法对岩溶湿地植被具有较高的识别能力,在95%置信区间内的总体精度为86.75%。虽然该方法的研究已经取得了一定的成功,但不同类型的特征对城市树种信息提取效果的影响尚不明确。因此,面向对象结合随机森林的方法对于城市树种分类的效果有待进一步探讨。此外,目前主流的数据源是大尺度的卫星影像和航空影像,或者是特征信息更加丰富的多光谱和激光雷达影像,而消费级无人机可见光影像在城市树种的精细分类方面还鲜有报道。因此,本文以福州市仓山区无人机可见光影像为研究对象,基于OBIA-RF模型,通过特征优选,构建最佳子集并比较不同机器学习算法的分类精度,并分析不同特征对城市树种分类的影响,构建该研究区城市行道树的最佳特征子集,比较不同分类算法对城市树种的分类效果,进一步评估OBIA-RF模型的分类性能和适用性,为城市生态系统保护及生态环境治理提供技术支持。
1 研究区概况
研究区位于福建省福州市仓山区(见图1),该区域属于南亚热带海洋性季风气候温暖湿润,冬季无严寒,夏季无酷暑。年日照时间1 700~1 980 h,年降水量900~2 100 mm,气温20~25 ℃。福州市仓山区典型树种包括白兰(Michelia×alba)、荔枝(Litchichinensis)、芒果(Mangiferaindica)、南洋楹(Falcatariafalcata)、榕树(Ficusmicrocarpa)、棕榈(Trachycarpusfortunei)、樟(Cinnamomumcamphora)等。研究区地势平坦,自然环境相对复杂,具备城市的基本特征,对研究城市树种分类具有一定的代表性。
2 研究方法
2.1 无人机数据采集与预处理
实验数据于2020年2月8日采集,采用搭载FC6310S可见光镜头的大疆精灵4Pro(DJI Phantom 4Pro)无人机进行航拍获取研究区影像,为削弱阴影对分类过程的干扰,选择天气状况良好无风有云的时间段进行作业。飞行相关参数设置如下:航高设置为60 m,航向与旁向重叠率均为70%,镜头角度-90°,光圈值f/5,曝光时间1/200 s,IOS速度为IOS-400。本次飞行共获得450张航拍影像,照片分辨率为5 472×3 078。通过瑞士Pix4Dmapper专业摄影测量软件对所采集的原始数据进行空中三角测量、点云重建、裁切以及镶嵌等操作,得到研究区的正射影像(DOM)和数字地表模型(DSM)。
为了精确获得研究区的道路信息,采用天地图在线矢量影像作为辅助信息,并通过手绘的方式提取道路矢量数据。根据实际调查情况,利用缓冲分析,将缓冲距离设置为5 m,得到了行道树的矢量分布图,然后,将矢量布图与原始影像叠加,最终裁剪出了研究区影像。
2.2 地形特征提取
归一化数字表面模型(nDSM)是一种反映地物绝对高度的高程模型[16],可为地物判别提供可靠依据。使用ArcMap10.2软件进行地形特征提取。首先,通过人工目视解译方法从DSM中选取950个地面点,并批量提取栅格的高程信息,其中100个样本点的高程数据用以验证精度。其次采用插值的方法生成数字高程模型(DEM)。为获取更加精确的地面高程信息,比较常见的插值方法(克里金插值法、反距离权重法、样条插值法以及自然邻域法)生成的数字高程模型(DEM),以均方根误差、平均绝对值误差和决定系数(R2)作为评分指标(见表1)。4种插值方法均可得到较高精度的DEM数据,综合考虑决定系数(R2)、平均绝对值误差以及均方根误差,最终确定采用克里金插值法生成连续的DEM数据。最后,根据已生成的DEM数据,利用ArcMap10.2软件中的栅格计算器,将DSM数据与DEM数据相减得到nDSM数据[17]。
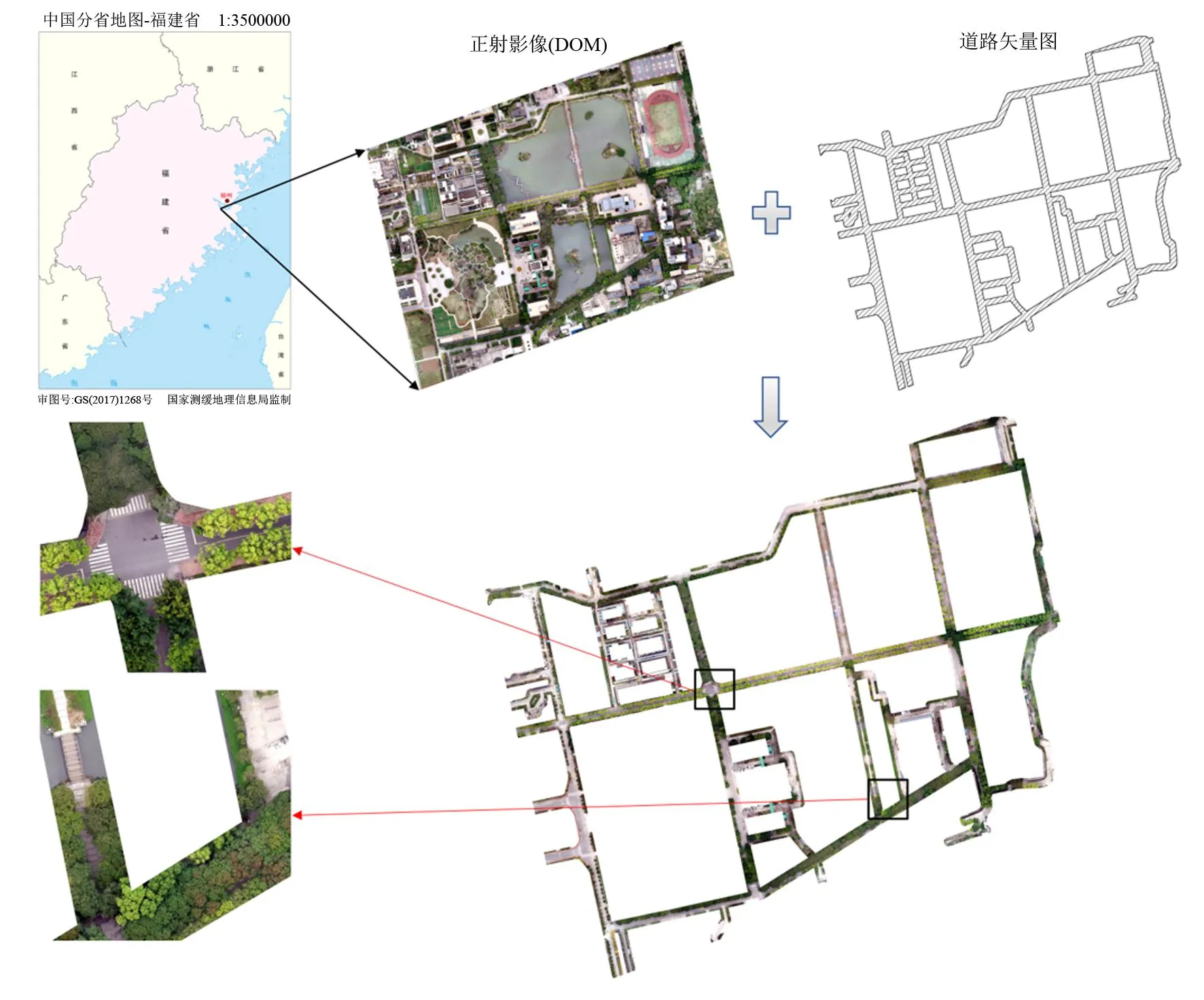
图1 研究区概况图

表1 不同插值方法精度评价
2.3 最佳分割尺度确定
影像分割是面向对象方法中至关重要的初始环节,分割结果将直接影响分类精度[18]。本研究采用尺度参数评价工具(ESP2),结合目视解译的方法确定最佳分割尺度,所有图像分割过程均在eCognition9.0 Developer 9.0软件完成。ESP2是用以评价不同尺度影像整体最大差异性的工具,通过计算整体局部方差均值随尺度变化率评估不同地物所对应的最佳尺度参数[19]。而ESP2计算出的尺度参数往往是多个值,需要结合人工目视才能确定最佳分割尺度。形状参数和紧致度参数是准确表示不同树种轮廓,使得对象内部同质性高的关键。综合考虑无人机影像的特点以及影像对象形状和紧致度因子的相互关系,将形状参数设置为0.5,紧致度参数设置为0.3。其他必要参数为:各波段的权重值设置为1、起始分割尺度为40、分割步长为1、迭代80次。随着尺度的增大,局部方差均值整体呈现上升的趋势,而尺度变化率呈现下降的趋势(见图2)。为了获得图像的过分割和欠分割之间的临界值,选取尺度变化率峰值为51、57、76、80、89、104、109和118作为相对最佳分割尺度参数,采用多尺度分割算法得到分割结果(见图3)。当分割尺度参数设置较大(分割尺度参数大于104)时,白兰、榕树和背景多处被划分为同一个对象,不同树种存在混淆现象难以被区分。当分割尺度参数设置较小(分割尺度小于76)时,不同地物内部出现了过分割现象,增加了数据冗余。当分割尺度参数设置76~89时,植被与背景区分相对明显,不同的树种之间能够被分割成独立的对象,整体分割效果较为理想。权衡分割效果与实际情况的吻合度,最终确定研究区无人机影像最佳分割尺度参数为76,并利用该分割尺度参数进行城市行道树提取。
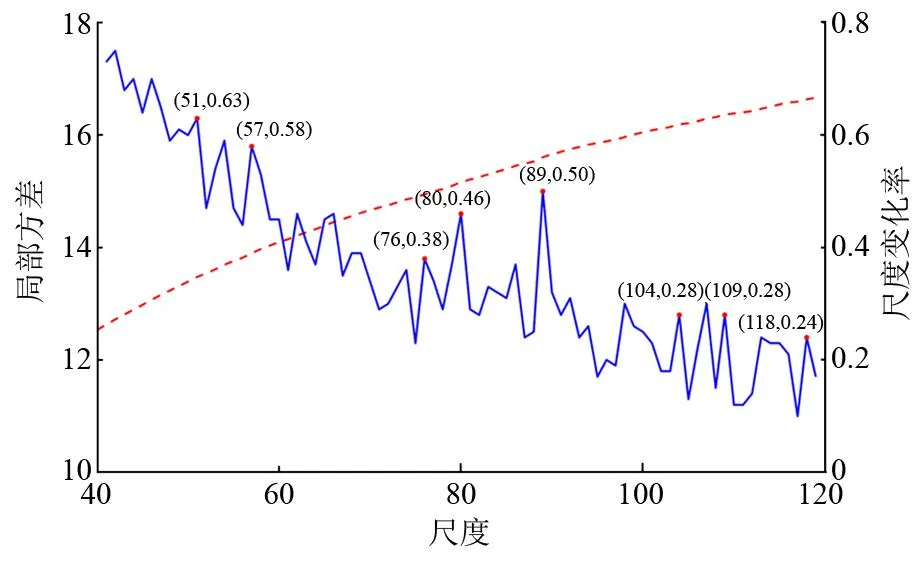
图2 ESP2最佳分割尺度估计图

图3 不同尺度参数分割效果图
2.4 对象光谱特征提取
光谱特征是遥感影像的重要特征之一,地物通常具有不同的光谱特征,因此根据可见光影像中的地物光谱信息的差异可以用来区分不同的地物类型[20]。植被指数利用植被在不同波段下反射和吸收的特性,增强植被信息的同时使非植被信息最小化[21],被广泛应用于林业病虫害防治、农作物生长量估计、生态环境监测等领域[22]。在遥感图像中,不同地物通常具有复杂程度不同的边缘特征,因此,形状特征可以作为快速准确识别地物类型的有效手段[23]。纹理特征是遥感影像的底层特征,不受图像亮度的影响,能够综合反映像素的灰度分布和结构信息,利用纹理特征可以有效弥补可见光影像光谱信息的不足[6]。在面向对象的分类过程中,结合纹理特征对于提升分类精度效果显著[24]。地形特征能真实反映不同地物的高程信息,在影像分类过程中对于区分不同类型的地物具有重要意义。因此,本研究共选取光谱、指数、纹理、几何以及地形5大特征,剔除无效特征筛选出40个子特征,具体如下:
(1)光谱特征(SPEC):主要包括:红色(R)波段的像元亮度的均值(MR)、绿色(G)波段的像元亮度的均值(MG)、蓝色(B)波段像元亮度的均值(MB)、最大差异值(Md)、亮度值(Br)。
(2)指数特征(INDE):包括植被颜色指数(ICIVE)、可见光波段差异植被指数(IVDVI)、联合指数2(ICOM2)、超绿指数(IEXG)、超绿超红差分指数(IEXGR)、植被指数(IVGE)、归一化红绿差异指数(INGRDI)以及归一化绿蓝差异指数(INGBDI)(见表2)。
(3)几何特征(GEOM):包括面积、边界长、宽度、长度、不对称性、长宽比、边界指数、圆度、像素个数、紧致度、体积、密度、椭圆拟合、主方向、形状指数、最大封闭椭圆半径、最小封闭椭圆半径以及矩形拟合。
(4)纹理特征(GLCM):基于灰度共生矩阵(GLCM)提取影像的纹理特征,包括对比度(TCON)、相关性(TCOR)、相异性(TDIS)、熵(TENT)、同质度(THOM)、均值(TMEA)、角二阶矩(TASM)和标准差(TSD)等特征值[6](见表3)。
(5)地形特征:归一化数字表面模型(nDSM)。

表2 植被指数及表达式

表3 纹理特征及表达式
2.5 试验样本选取
本实验通过实地调查获取样本数据。调查者沿着研究区的主要道路记录了绿化树种,并排除了数量较少或被其他冠层遮挡的树种,最终确定了7类树种(白兰(Michelia×alba)、荔枝(Litchichinensis)、芒果(Mangiferaindica)、南洋楹(Falcatariafalcata)、榕树(Ficusmicrocarpa)、棕榈(Trachycarpusfortunei)、樟(Cinnamomumcamphora))以及草地、灌木作为研究对象。根据遥感影像中不同地物类型的分布位置与大致面积比例,共选取了1100个样本点。为了避免较小的样本数量影响模型分类精度,将最小样本数量设置为60。采用Scikit-learn中内置的train_test_split函数进行分层抽样,按7:3的比例将数据划分为训练集和测试集(见表4),使各类别样本点数量大致与该类别的总面积成比例。训练集用于构建分类模型,测试集用于验证分类精度。
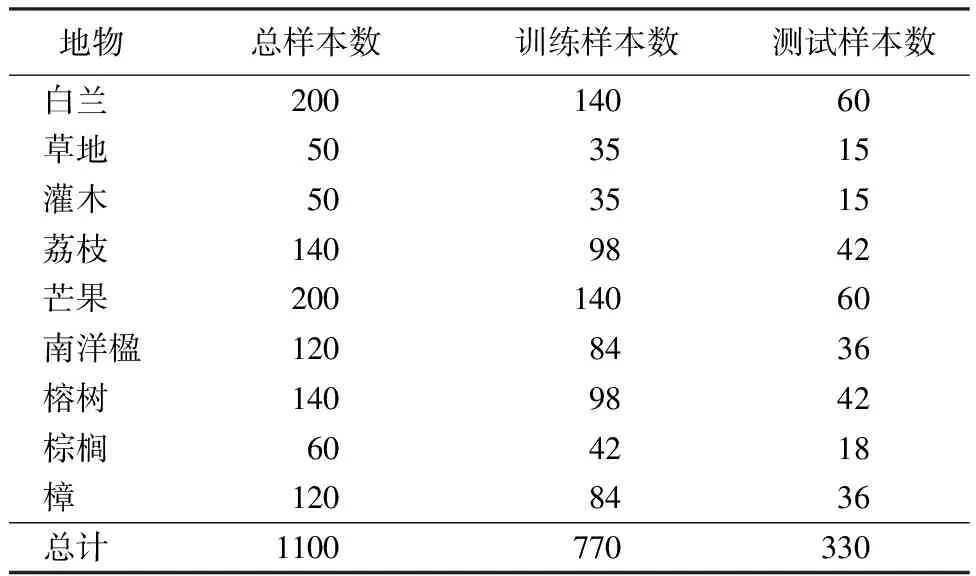
表4 训练和验证样本
2.6 分类模型与参数优化
2.6.1 随机森林算法
随机森林算法(RF)是一种通过集成学习的装袋思想将多棵决策树集合起来的算法,每棵决策树都充当预测目标类别的分类器。随机森林模型在样本数据和分类特征选择方面具有随机性,不容易过拟合,并且表现出良好的稳健性,即使在处理具有缺失值的高维数据时,仍能保持较高的分类精度。因此,它被认为是当今最好的算法之一[32]。目前,随机森林算法已经广泛集成在各种软件包中,使用Stata数据管理统计绘图软件、R语言统计软件可以轻松实现。在模型构造的过程中,通常只需要确定每个树节点包含的特征数量(M)以及决策树数量(N),就足以保证模型的性能[33]。
本文采取递归特征消除法(RFE)[34]结合交叉验证(Cross-Validation)确定最佳特征数(见图4)。随着特征维数的增加,整体分类精度曲线经历“几何增长”、“缓慢上升”这个两个阶段后趋于平稳。当特征数为20时,各分类精度曲线均处于相对最高点,因此最终将特征数量的参数设置为20。
在使用装袋方法生成训练集的过程中,随机森林算法会导致原始数据集中大约37%的数据未被抽到,这部分数据被称为袋外(OOB)数据。利用袋外数据对随机森林模型进行评估是一种无偏估计方法,且在一定程度上能减少计算量,提高算法的运行效率[35]。因此,本文采取遍历不同数量(1~1 000)决策树的方法,通过比较袋外误差的大小,确定最佳的决策树数量(见图5)。当决策树数量小于85时,不同子集的袋外数据误差均随着决策树数量的增加而急剧下降,而后随着决策树数量的增加袋外数据误差的下降速度逐渐迟缓,当决策树数量为200时,袋外数据误差处于相对最低点。因此,选择决策树的最佳数量为200。

图4 模型分类精度与特征数的关系曲线

图5 袋外误差与决策树数量的关系曲线
2.6.2 其他分类模型
为充分探索随机森林算法对城市树种信息提取的适用性,引入当下流行的机器学习算法作为对照,包括极致梯度提升(XGBoost)、轻量级梯度提升机(LightGBM)以及k最近邻算法(KNN)。XGBoost是一种基于增强学习(Boosting)的集成算法,它通过在梯度下降方向上将弱分类器集成到强分类器中,并迭代生成新树以拟合先前树的残差。XGBoost能够自动利用中央处理器(CPU)的多线程进行分布式学习和多核计算,在保证分类准确度的前提下提高计算效率,尤其适用于处理大规模数据[36-37]。LightGBM也属于增强学习方法,基本原理与XGBoost相似。但LightGBM使用基于直方图的决策树算法来减少存储与计算成本,并优化模型训练速度[38]。KNN算法是一种近似自变量与连续结果之间的关系的非参数方法[39],其基本思路是通过计算待分类样本与临近样本的距离(欧氏距离、曼哈顿距离)来确定所属类别,是一种简单而有效的分类算法。为了防止过拟合,本研究在Jupyter Notebook平台上利用Scikit-learn库中的GridSearchCV包对这3种分类器参数进行了调优(见表5)。

表5 不同分类器的超参数
2.7 试验方案构建
不同树种之间单一特征的差异有限,难以满足树种分类的要求。因此,本研究采取增加特征数量的方式来提高分类精度,并探究不同特征组合对分类结果的影响(见表6)。
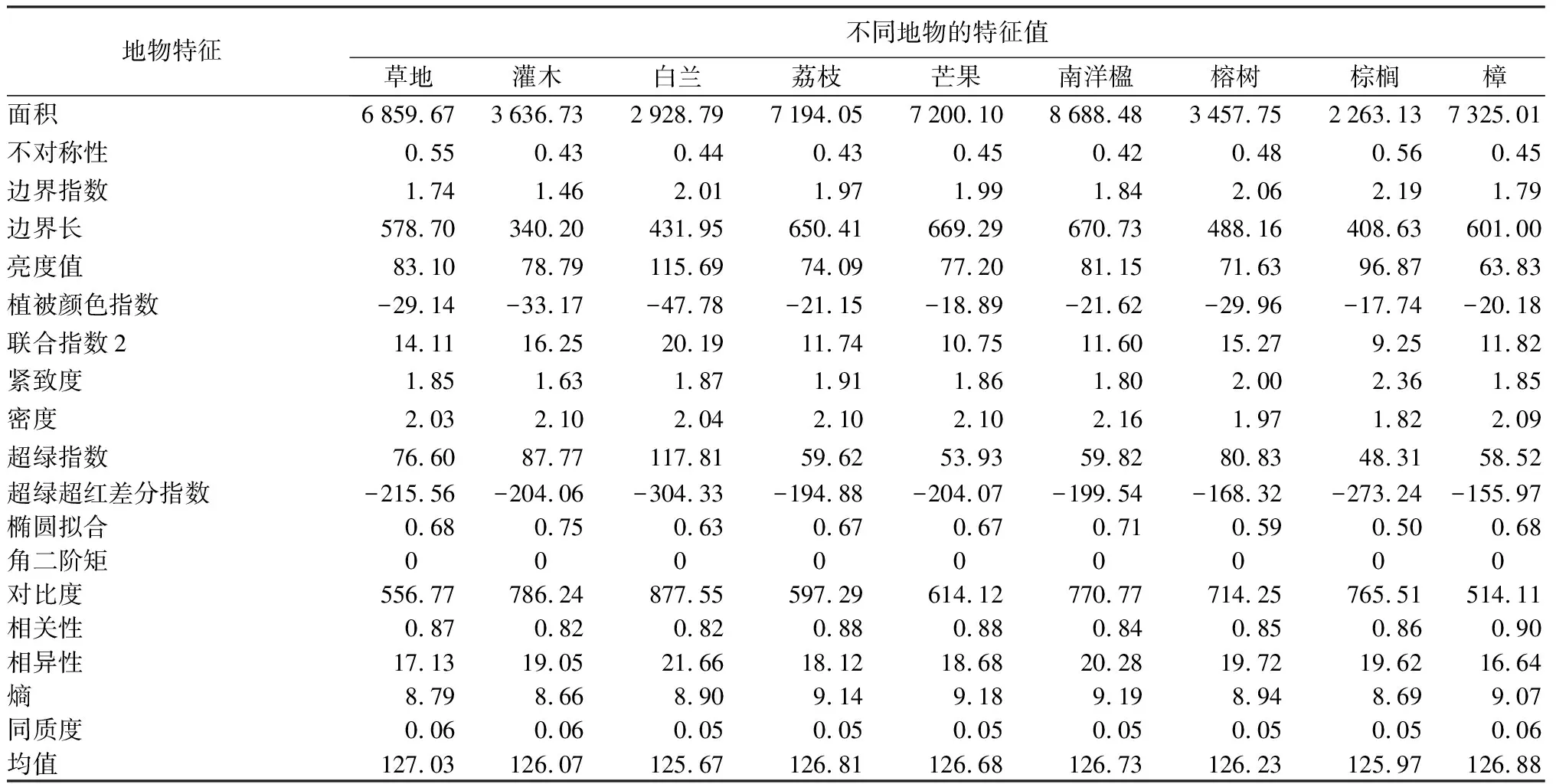
表6 研究区各地物特征值
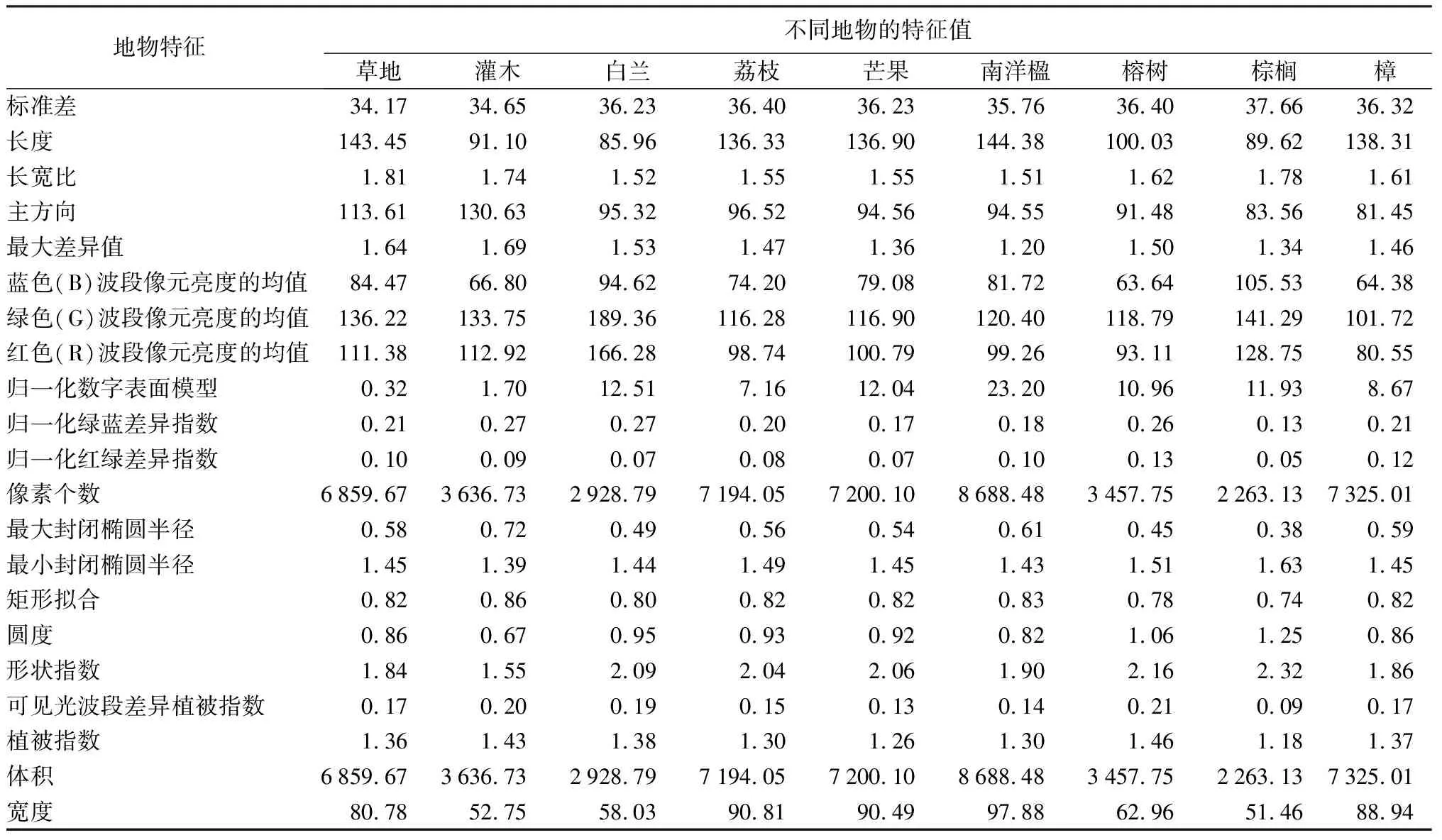
续(表6)
根据优选特征贡献率(见表7),将所选取的5大特征组合形成了10种试验方案(S1~S10)。光谱特征作为每幅遥感影像的基本特征,作为基础被纳入到这10种方案的构建中。其中,S1仅包含光谱特征;为了全面探究其他特征对分类结果的影响,在S1基础上引入了地形、指数、纹理等3个总体特征贡献率较高的特征,通过遍历这3个特征的各种组合得到了S2~S8;S9包含了所有的特征;根据20个优选特征组合建立S10,具体的分类方案见表8。

表7 优选特征重要性

表8 分类方案
2.8 精度评价
本文根据混淆矩阵对模型的分类精度进行定量评价。混淆矩阵也称为误差矩阵,是遥感影像二分类问题上的一种评价方法,反映了分类结果与真实地物类别之间的相关性[40]。混淆矩阵的评价指标包括总体精度(OA)、Kappa系数(Kp)、生产者精度(PA)以及用户精度(UA)。其中,总体精度指正确分类样本与总体样本的比值;生产者精度指分类结果与参考分类相符合的程度;用户精度指样本分类正确的可能性;Kappa系数是用于检验遥感影像分类结果的一致性,也可以用以均衡分类效果[41]。各指标计算公式如下:
PA=xii/x+i;
UA=xii/xi+。
式中:N为参与评价的样本总数;n为混淆矩阵的行列数;xii为混淆矩阵第i行、第i列上的样本数;xi+和x+i分别为第i行和第i列的样本总数。
3 结果与分析
3.1 随机森林算法的不同分类方案精度
由表9可知,随着不同特征类型数量的增加,总体分类精度和kappa系数整体呈上升趋势。其中,仅利用光谱特征作为分类依据的方案S1精度最低,总体精度和kappa系数分别为82.12%和0.79,说明光谱特征是遥感影像最重要的特征之一,但仅利用光谱特征难以达到所需的分类精度。方案S2~S4是在S1的基础上分别加上地形、指数和纹理特征,相比方案S1,这3个方案的总体分类精度分别提高了5.15%、4.55%、1.82%,kappa系数分别提高了0.06、0.06、0.03。在分类过程中,地形特征相较于指数和纹理特征扮演着更重要的角色,大幅提高了分类精度。方案S5~S7是在光谱特征的基础上加入地形、指数和纹理特征的两两组合,旨在研究它们之间的相互作用对分类精度的影响。整体而言,与S2~S4相比,这3个方案的总体分类精度呈上升趋势。其中,S6具有最高的总体精度和kappa系数,分别达到90%和0.88;其次是S7,和S1相比,总体精度和kappa系数分别提高了7.27%和0.09;而S5总体精度和kappa系数只增长了6.36%和0.08。表明地形与指数特征交互作用在分类过程中提供了更大的贡献度。方案S8是由特征重要性靠前的光谱、地形、指数以及纹理特征构成。与包含所有特征的方案S9相比,S8反而具有更高的总体分类精度和kappa系数,分别达到92.12%和0.91。表明几何特征对分类精度具有负向影响,它的加入降低了分类精度。方案S10由优选特征组成,其获得了所有子集中最高的分类精度和kappa系数,分别为92.42%和0.91。与S9相比,分类精度提高了0.60%。说明特征优选方法能消除高维复杂特征间的信息冗余,使模型仅利用较少特征数量并获得更高的运行效率和分类精度。

表9 不同分类方案分类精度
由表10可知,虽然S1方案的用户精度与生产者精度整体上处于最低水平,但棕榈树的用户精度达到了100%,表明棕榈与其他树种存在明显的光谱差异。方案S2加入地形指数后,各类地物的用户精度与生产者精度相比S1都有不同程度的提高,用户精度提升幅度1.88%~8.18%,生产者精度提升幅度2.78%~11.11%,因为地形特征的加入更好的反映了不同地物之间的空间关系,从而大幅提高了分类精度。方案S3在S1的基础上加入了指数特征,荔枝、榕树以及樟的用户精度分别提升了10.95%、9.18%和8.72%,说明植被指数对荔枝、榕树以及樟分类效果显著,但对于其他树种的区分能力有限。方案S4加入纹理特征,芒果和樟的用户精度提升了8.85%和9.00%,而棕榈和榕树的生产者精度分别提升了22.22%和11.9%,说明这些树种的纹理结构特异性强与其他地物的差异显著,因此纹理特征的加入对分类精度有正向影响。方案S5与S2相比,荔枝和榕树的用户精度提升了7.05%和5.12%,而草地的精度下降了5.88%;与S3相比,灌木的用户精度提升了4.47%。总体而言,地形特征与指数特征的组合对分类精度的提升不显著,并且在某些树种的分类上精度出现不同程度的下降,说明这二者的组合产生了冗余信息影响了分类精度。方案S6与S2相比,芒果与樟的用户精度分别提升了6.44%和7.66%,而棕榈树和榕树的生产者精度分别提升了27.78%和11.90%,这个结果与方案S4类似,说明地形特征和纹理特征的组合与树种的分类精度呈正相关。方案S7与S6相比,除个别树种外,整体精度出现了不同程度的降低,波动范围为-6.21%~4.04%。然而,与方案S5相比,总体分类精度有一定的提升,波动范围是-0.58%~7.55%。方案S8与表现最好的方案S7相比,荔枝和榕树的总体分类精度分别提升了9.42%和6.67%,其他树种的总体分类精度保持稳定,这表明高维度的特征组合带来了更多的信息,在一定程度上提高了分类精度。综合所有特征的方案S9与S8相比,总体分类精度呈现出不升反降的现象,波动范围为-10.23%~4.74%,说明高纬度的特征产生了冗余信息,影响了随机森林模型的分类性能。优选特征子集S10与S9相比,总体分类精度有所提升,其中灌木、草地以及荔枝的用户精度分别提升了10.23%、5.88%和3.55%。由此可见,特征优选通过对高维数据集的降维和优化,使模型仅利用较少的特征仍能保证良好的分类效果。
3.2 应用优选特征子集对不同分类模型的精度评价
由表11可知,随机森林模型的分类精度最高,总体精度为92.42%,比k最近邻算法(KNN)、极致梯度提升(XGBoost)和轻量级梯度提升机(LightGBM)算法分别提高了15.15%、1.51%和1.81%;随机森林模型的kappa系数为0.91,比KNN、XGBoost和LightGBM算法的kappa系数分别提高了0.17、0.01和0.02。表明随机森林模型具有更高的分类精度。
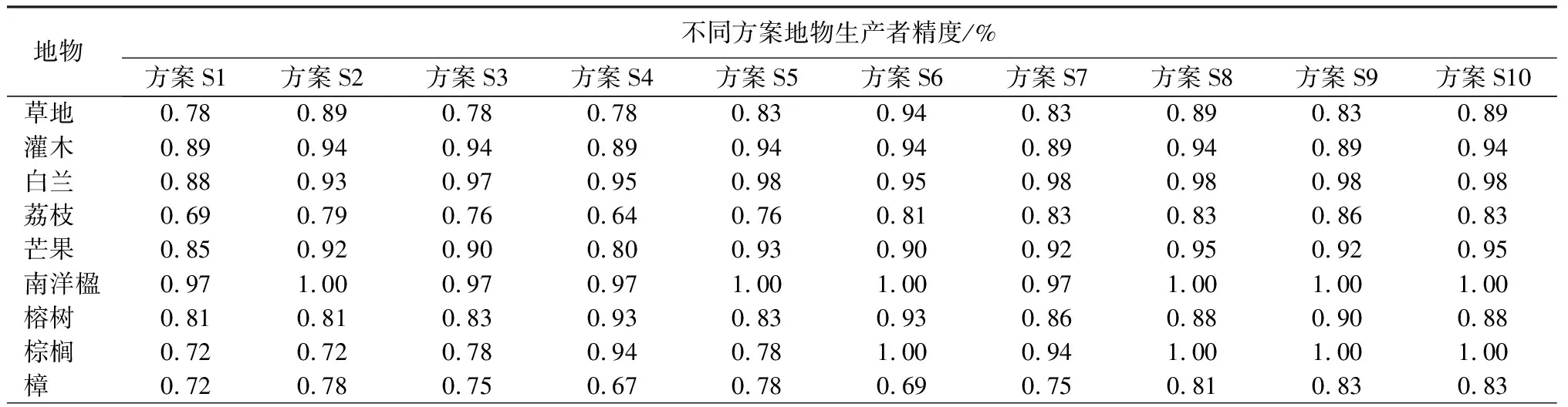
表10 不同分类方案地物生产者精度和用户精度

地物不同方案地物用户精度/%方案S1方案S2方案S3方案S4方案S5方案S6方案S7方案S8方案S9方案S10草地87.5094.1287.5093.3388.2494.4488.2494.1288.2494.12灌木84.2189.4785.0080.0089.4794.4488.8994.4484.2194.44白兰96.3698.2596.6798.2896.7298.2896.7296.7298.3396.72荔枝69.0575.0080.0062.7982.0573.9174.4783.3381.8285.37芒果73.9182.0977.1482.7681.1688.5288.7189.0690.1689.06南洋楹94.59100.00100.0092.11100.00100.00100.00100.00100.00100.00榕树82.9389.4792.1181.2594.5990.7094.7497.3797.4497.37棕榈100.0086.6787.5089.4787.5090.0089.4790.0094.7490.00樟68.4275.6877.1477.4277.7883.3381.8285.2985.7185.71

表11 不同分类模型分类精度比较
由图4可知,使用最佳特征组合子集作为样本数据,结合随机森林(RF)、k最近邻算法(KNN)、极致梯度提升(XGBoost)和轻量级梯度提升机(LightGBM)算法对整个研究区的行道树进行分类提取。随机森林(RF)算法的分类效果相对理想,大部分地物边缘较为清晰,整体与研究区域实际情况较为一致。XGBoost算法容易将白兰误分为榕树(见图4b)和将榕树误分为樟(见图4c)。LightGBM算法容易将荔枝、白兰和榕树混淆(见图4a和图4c)。KNN算法的分类效果最差,破碎化情况明显,出现了大量的错分(见4a和4b图中南洋楹误分为芒果)。综合来看,RF模型在进行城市树种精细分类时,具有最强的适用性和最佳的提取效果。
4 讨论
本研究应用随机森林模型的特征重要性排序构建了不同特征组合的方案,充分考虑特征对分类模型的影响,表明优选特征方案(S10)具有最高的分类精度。由于本研究采用了递归式特征消除法,通过定量分析特征贡献率,在尽可能保留重要特征的同时降低数据冗余,从而提高模型整体运行效率与精度。其中,光谱特征起到了最重要的作用,仅利用光谱特征分类的总体精度达到82.12%。虽然不同树种间组织细胞中叶绿素、类胡萝卜素、花青素、叶黄素的含量和绿色波段的反射率有紧密联系[6],但芒果、榕树、南洋楹和樟的光谱信息比较相似,因此利用光谱特征难以实现更精细的树种分类。地形特征对分类效果具有重要作用,随着地形特征的加入,总体分类精度得到了大幅度的提升,其贡献度达14.96%。研究区树种之间存在天然的高差,南洋楹属于高大乔木,平均树高达20 m以上,而荔枝的平均高度只有7~8 m,精确的冠层高度信息可以弥补光谱信息的不足,进一步提高了分类精度。本研究所选取的植被指数对分类结果均产生了一定的影响,其中比较重要的是联合指数和植被颜色指数,这两种指数在反映典型地物的像元特征时具有更低的变动绝对差值[42]。但纹理特征的引入并未显著提高分类精度,由于无人机影像不规则和较小的分割尺度以及几何特征的加入产生了数据冗余,从而降低了随机森林模型的分类精度[43]。
为进一步验证RF模型在城市树种信息提取上的适用性,本试验将其与其它常见的机器学习算法(XGBoost、LightGBM和KNN)进行了比较。随机森林算法取得了最高的分类精度和Kappa系数,并具有最佳的分类效果。杨红艳等[44]应用无人机高光谱遥感影像研究了荒漠草原草地植被分类,结果表明随机森林分类算法优于其他传统机器学习分类算法,说明随机森林算法在处理高维特征数据和有限训练样本时具有更好的适用性和稳定性。其原因在于随机森林模型通过随机选择样本和特征构成决策树,同时利用递归特征消除法排除非必要特征数据带来的冗余信息。随机森林在处理复杂数据和有限训练样本时能最大程度降低误差值对其分类性能的影响,仍然保持强大的稳健性。与随机森林模型相比,KNN算法只有77%的分类精度,并且存在大量的错分和漏分现象。KNN算法本质是一种基于实际样本的学习算法,通过计算未知样本和已知样本之间的距离来判断所属类别,由于本研究区地物丰富(乔木、灌木、道路以及建筑物等),在一定程度上导致了错分和漏分的现象;显著的样本数量差异(芒果为200个,草地为60个)也会影响模型的性能,降低分类精度,从某种程度上说明KNN算法不适用于复杂地物的精细分类[45]。而XGBoost和LightGBM的核心思想是通过迭代地添加新的模型来纠正前一个模型的错误,从而不断提高模型的准确性。由于样本数据中包含大量的噪声,且样本量过少,这在一定程度上会导致模型的性能下降,出现过拟合的现象。然而,这两种算法的分类精度均达到了90%以上,说明它们仍具有巨大的潜力[46-47]。在后续的研究中,可以采用基于卫星影像与激光雷达点云数据的结合,并通过数据预处理(去除缺失值、进行标准化等)、增加样本数据量以及合理调整参数的方式,充分发挥这两种算法的特点,以提高分类精度,实现大尺度城市植被信息的提取与反演。

图4 不同分类模型树种信息提取效果
尽管本研究根据最佳特征组合方案所构建的随机森林模型能有效识别城市树种,但仍存在一定的局限性。首先,尺度参数缺乏客观性,采用的ESP2插件,通过计算局部方差均值与尺度的变化率的关系,得出相对最佳尺度的备选值,但这种方法仍需要通过人工目视解译比较分割效果确定最终的尺度。由于受人为主观因素的影响,缺乏足够的客观性,无法得出适用于特定类型地物的最优分割尺度。刘金丽等[48]在ESP2插件的基础上提出了基于地物样本点的评价方法,提高了操作的简易性和评价因素的全面性。其次,分类模型难以推广,研究对象是根据某一时段的无人机可见光影像的植被信息提取,未充分考虑到植被物候差异的时间变化,导致OBIA-RF模型在全天候城市树种信息精确提取方面存在一定的局限性。刘灵等[49]基于Sentinel时序影像成功实现了香格里拉针叶林优势树种的精细识别。说明根据多时序的无人机可见光数据,计算不同树种物候特征与时序特征的回归关系,构建具有时间尺度的分类模型,可以提高模型的适用性。最后,尽管利用消费级无人机可见光影像实现了城市行道树的精细分类取得了一定的成果(分类精度为92.42%,kappa系数为0.91),但仅依赖可见光影像的三通道数据难以实现更高精度的分类。因此,在今后的研究中,可以考虑结合多光谱和激光雷达数据,充分利用多光谱影像的多通道数据和更精确的激光雷达点云信息(特别是多光谱影像中对植被信息敏感的近红外波段和激光雷达点云中的点云大小、点云密度、点云强度等特征)进行地物分类。
5 结论
本研究根据城市树种信息精细分类的需求,提出了一种基于消费级无人机高分辨可见光影像的城市行道树信息提取方法。应用OBIA-RF模型和植被的光谱、指数、几何、纹理以及地形特征,通过递归式特征消除法构建最佳特征子集的方式,实现城市行道树信息的提取,并探究了不同的特征组合对分类结果的影响,并引入XGBoost、LightGBM以及KNN等3类机器学习算法与随机森林模型在城市树种分类上的适用性进行对比。递归式特征消除是一种减少数据冗余提高模型运行效率的有效方法,经过优选特征变量组合(S10)取得了较高的分类精度。不同的特征对分类结果的影响不同,光谱特征、地形特征、指数特征以及纹理特征对分类结果起正向作用,光谱特征最为重要,仅利用光谱特征就能达到较高的分类精度;几何特征对分类精度有负向影响,高维几何特征的加入降低了分类精度;地形特征通过提供精确的冠层高度数据弥补了可见光影像光谱信息的不足,在分类过程具有最高的贡献度。而指数特征和纹理特征特征通过数学运算提取树种对象内部更深层次的光谱、纹理信息,对提高分类精度也具有重要作用。随机森林(RF)算法与当前流行机器学习算法(XGBoost、LightGBM以及KNN)相比,总体精度最高,提取效果最好,说明OBIA-RF模型在处理高维特征数据和有限训练样本时具有更好的适用性和稳定性。该方法为准确的获取城市树种空间分布信息提供了一种新思路,有助于提升城市居民生活水平和城市生态系统可持续发展。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2018年11期)2018-08-04
现代园艺(2018年2期)2018-03-15
太空探索(2016年5期)2016-07-12
测绘科学与工程(2016年5期)2016-04-17
中国林业产业(2016年5期)2016-04-03
中国林业产业(2016年5期)2016-04-03
电子设计工程(2015年3期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
武夷学院学报(2014年5期)2014-07-19
