
基于分割网络的海滩泡沫浮球遥感影像自动识别应用研究
2024-01-16 13:37黄德华
福建地质 2023年4期
黄德华
(福建省地质测绘院,福州,350011)
海滩塑料垃圾的监测已成为海洋垃圾监测议题的重中之重[1-2]。海滩塑料垃圾监测以前主要以人工现场采样调查为主[3],该方法费时费力,于是诞生一系列更高效的技术手段,如视频监测[4]、高分辨率遥感影像监测[5]、无人机遥感影像监测[6-7]、人工智能监测[8-9]等技术。前二者监测范围小、成本高,精度低,而后二者结合监测方法具备前二者的优势,越来越受青睐。近年来,已有不少研究项目基于无人机影像,利用深度学习图像分类[10-11]、目标检测[8-9]领域的模型算法对海滩塑料垃圾进行智能识别。其识别尺度为图像级、对象级,无法达到像素级别,对于垃圾面积估算有天然劣势,并不能满足对面积统计有较高精度的应用需求。基于无人机影像,利用语义分割网络识别塑料垃圾类型多为塑料大类,所用网络为简单的U-net 网络及其变种[12-14]。语义分割网络从2015 年的FCN[15]、U-net[16]发展至今,已从最初的CNN 结构,发展到如今的Transformer 结构以及CNN+Transformer 混合结构,其分割精度也随着不同网络结构的发展不断提高。Transformer 结构相较于传统的CNN 结构,具有更好的并行性和可扩展性,能够处理更大规模的数据集,并且还能够在不同尺度下进行语义分割。同时,基于Transformer结构的语义分割网络还具有更好地捕获全局信息的能力,能够更好地处理长距离依赖关系,从而提高模型的精度和鲁棒性。而CNN 结构则更擅长处理局部信息,其优势在于参数共享,比Transformer 结构更加轻量。在实际应用场景中,需对塑料大类中的小类进行更细致的分类与统计,需要更为有效的语义分割二分类网络,除经典的CNN 结构语义分割网络外,语义分割领域出现了一系列Transformer及CNN+Transformer 结构的网络,如Transunet、Swin-unet 等[17-18],这些网络的出现无疑为实现更有效地分割提供了更为强大的技术支持。以福建沿海海滩塑料泡沫浮球为例进行智能识别,研究设计实验,对比了现有3 种主流结构(CNN、CNN+Transformer、Transformer)的语义分割网络在海滩塑料泡沫浮球分割的识别效果,为语义分割网络在海滩塑料垃圾智能识别的实际应用中提供借鉴与技术参考。
1 研究方法
1.1 数据源获取
研究采用DJI Matrice M300 RTK 无人机,搭载DJI ZENMUSE P1 相机,有效像素为4 500 万,具有POS 惯导系统,地面基站用的是fjCors。于2022 年8—10 月利用上述型号无人机载具对福建沿海不同区域的23 个岸段进行航测,航测地点远离人口密集区,航高180 m,收集到1 ~3 cm 分辨率的无人机航拍影像数据(图1)。
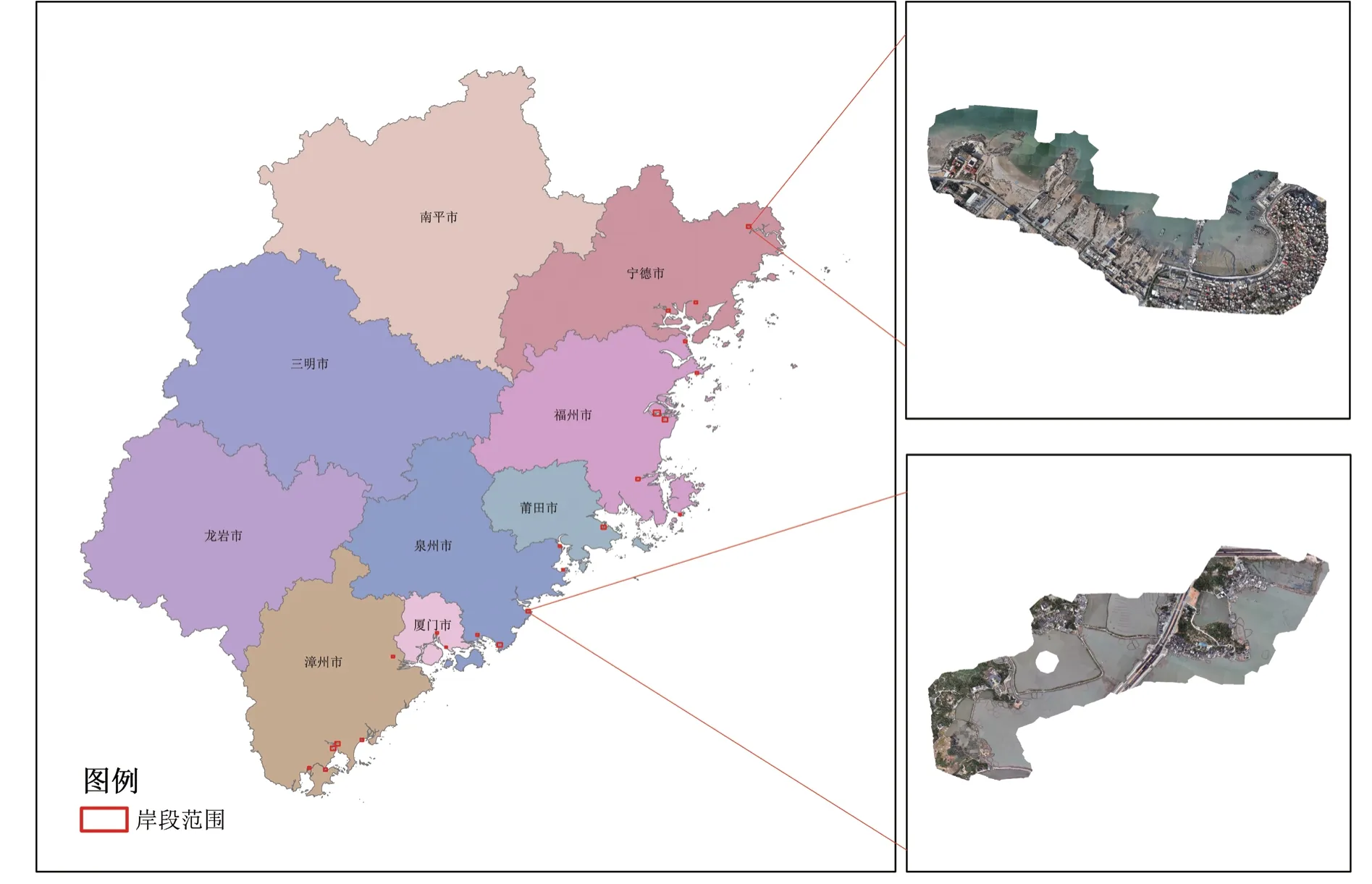
图1 研究区岸段区域及对应无人机影像Fig 1 Regional scope of the study area and corresponding UAV image
1.2 样本制作
根据前期对福建沿海不同区域岸段塑料垃圾的调查研究,发现泡沫浮球占塑料垃圾总数的50%以上,且该类型垃圾形态多样,呈不均匀散落分布,若能用较高精度的自动解译代替人工目视解译,将大幅度减少内业人员的工作量。此次研究选取泡沫浮球这一类型塑料垃圾进行语义分割智能识别。采用自然资源部办公厅下发的“全国海岸线修测技术规程”所规定岸线界定方法,将海岸线分为3 大类12 小类。
首先,利用Arcmap 软件,以各个岸段无人机影像为底图,以海岸线缓冲区200 m 为解译范围,对泡沫浮球进行目视解译,解译规则在影像上呈现柱状(表1)。

表1 研究区泡沫浮球目视解译规则示例Table 1 Rules for visual interpretation of foam float in the study area
选择硬件所支持的最大位移窗口为256×256 pixels(相当于地面分辨率7.68 m×7.68 m),重叠率为0.2,分别对各岸段无人机影像及所对应的泡沫浮球解译图斑进行裁剪,得到泡沫浮球语义分割样本总共47 775 对,其中正样本12 012 对,负样本35 763 对。最后,以8 ∶1 ∶1 的比例,随机种子为10 101,将正负样本分别划分为训练集、验证集、测试集,其中训练集和验证集用于模型训练,测试集用于精度评价。
1.3 语义分割模型
研究从3 种语义分割网络结构中,选择4个语义分割网络进行训练,网络分别为U-net、DeepLabv3+、Transunet、Swin-unet,其中U-net、DeepLabv3+为CNN 结构,Transunet 为CNN+Trans former 结构,Swin-unet 为Transformer 结构。
U-net 网络:由对称的Encoder、Decoder 组成,通过cov+relu 的组合进行特征提取,利用maxpooling 进行下采样,利用最近邻插值进行上采样,整个网络先进行4 个阶段下采样,再进行4个阶段的上采样,每个阶段上采样结束后,利用concat 将encoder 对应的特征图与上采样后的特征图进行拼接(图2)。研究所用U-net 结构,输入图像尺寸改为256×256 pixels。

图2 研究区U-net 网络结构图Fig.2 U-net network structure diagram of the study area
DeepLabv3+网络:由Encoder、Decoder 2 部分组成。Encoder 部分先通过一个DCNN 网络提取特征,再利用ASPP 模块提取长距离特征,之后利用1×1 卷积将得到的特征图降维,并上采样到原输入图像的1/4(记为b3),Decoder 部分将DCNN 低维度特征图(原输入图像的1/4)与b3 进行concat 连接,最后进行一次卷积一次上采样(图3)。研究所用DeepLabv3+网络,其DCNN 为ResNet50,输入尺寸为256×256 pixels。
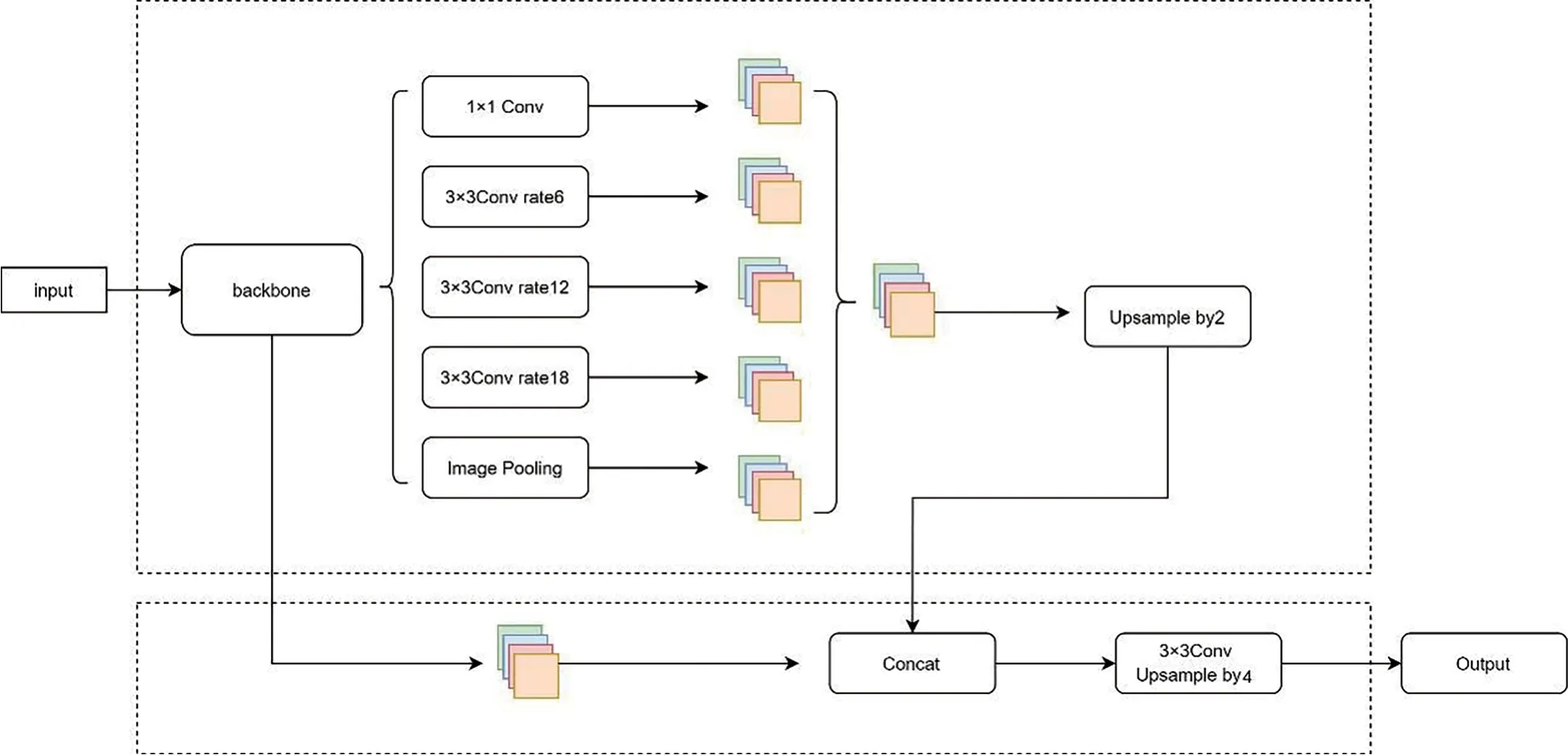
图3 研究区DeepLabv3+网络结构图(据参考文献[19])Fig.3 DeepLabv3+ network structure diagram of the study area
Transunet 网络:是基于U-net 网络改动而来,在U-net 网络3 次下采样后,第4 次下采样部分替换为12 个Transformer 模块,输入Transformer模块前, 需要对特征图做块嵌入(Patch Embedding)和位置嵌入(Position Embedding)(图4)。研究所用Transunet,输入图像尺寸改为256×256 pixels。
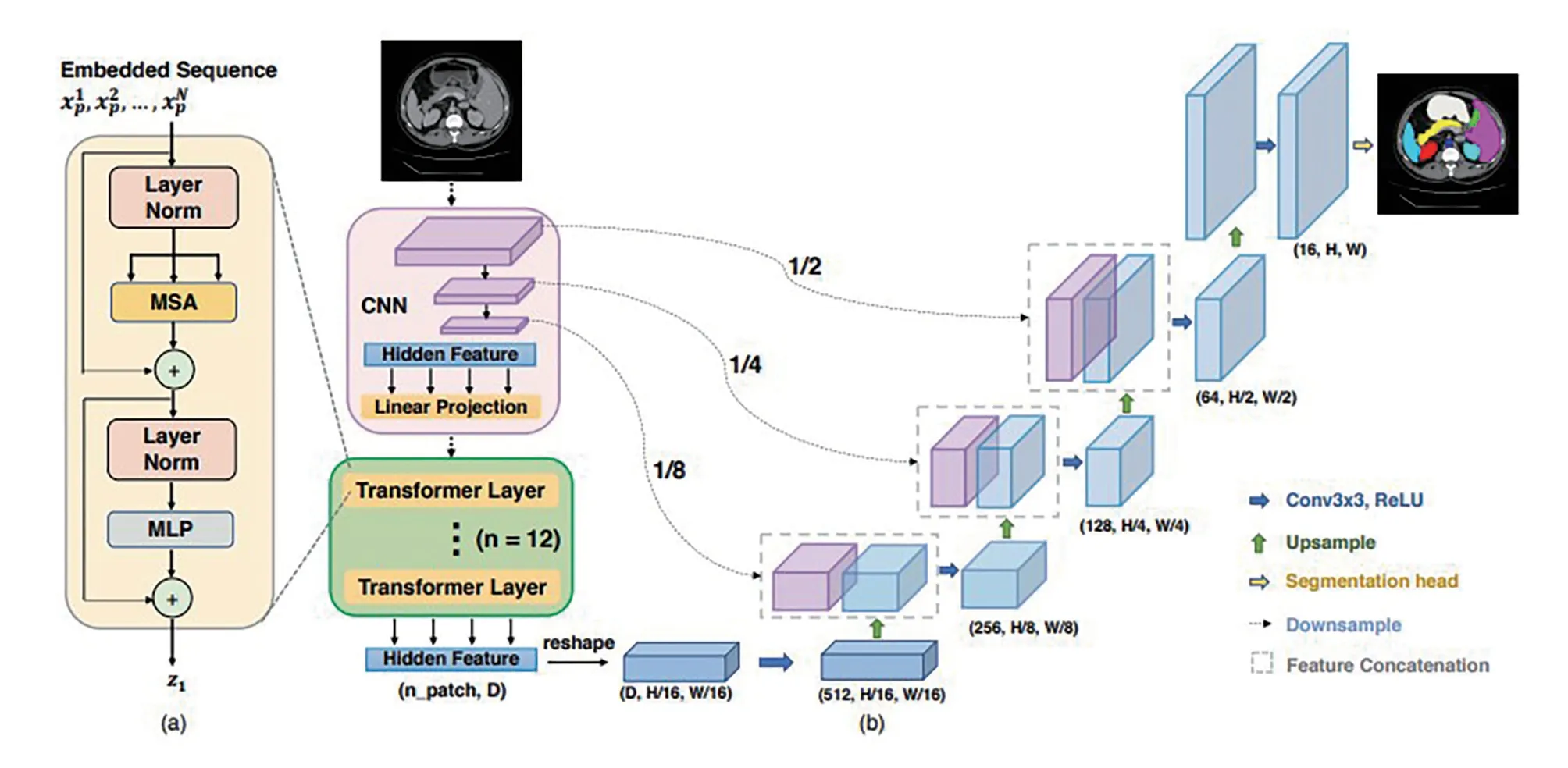
图4 研究区Transunet 网络结构图(据参考文献[17])Fig.4 Transunet network structure diagram of the study area
Transunet:使用可训练线性投影,将向量化的patch Xp 映射到潜在的d 维嵌入空间。为编码块空间信息,学习特定的位置嵌入,网络采用与块嵌入相加的方式,保留位置信息。
式中:E是块嵌入,Epos代表位置嵌入。
Swin-Unet 网络基于U-net 网络改动而来,其做法是将U-net 中conv+relu 的基本单元替换成Swin transformer block,再配合块扩张(Patch Expanding)进行上采样与下采样(图5)。输入图像尺寸为256×256 pixels。
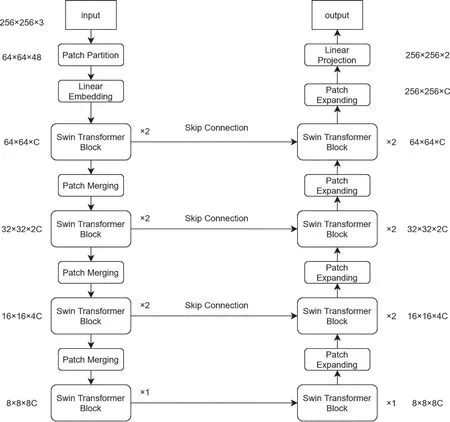
图5 研究区Swin-Unet 网络结构图Fig.5 Swin-Unet network structure diagram of the study area
与传统的多头自注意力(MSA)模块不同,Swin Transformer 块是基于平移窗口构造的。Swin Transformer 块由层标准化层、多头自注意力模块、剩余连接和具有GELU 非线性的2 层MLP 组成。在2 个连续的Transformer 模块中分别采用了基于窗口的多头自注意力(W-MSA)模块和基于移动窗口的多头自注意力(SW-MSA)模块。基于这种窗口划分机制,连续Swin Transformer 块可表示为:
1.4 训练环境及策略
训练实验采用Windows10 系统,5 块英伟达RTX 3080GPU,4 块Intel 至强XeonE3 CPU,采用Tensorflow 2.4.1 进行模型搭建。
由于泡沫浮球图斑面积较小,对于样品为256×256 pixels 的图斑面积对比非泡沫浮球图斑面积平均而言要小得多,如果采用传统的正负样均衡(正负样本比例为1 ∶1),网络也会因为泡沫浮球图斑面积过小而难以训练,为解决这一问题,将模型训练分为3 个阶段。
第一阶段:取训练集、验证集中的所有正样本进行模型训练。Epoch 范围为100 ~500,初始学习率为10-3。
第二阶段:取训练集、验证集中的所有正样本及相同数量的随机负样本,以1 ∶3 的比例进行随机数据增强,增强方式包括随机翻转、随机HSV 增强、随机缩放,其中随机缩放长宽比例为0.56 ∶1.56,随机HSV 增强,色调变化范围在原色调基础上加减0.2,明度和饱和度以1 ∶1.2 的比例进行增减。Epoch 范围为300 ~500,初始学习率为10-5。
第三阶段:取测试集所有正样本和相同数量随机负样本对模型进行精度评价。
1.5 精度评价参数
为了有效评价语义分割结果的分类精度,采用以下3 个指标参数:F1 分数、精确率、召回率。
F1 分数:综合了精确率和召回率的指标,可以反映出模型的综合性能。
精确率:模型判定为正样本的样本中,真正为正样本的比例。
召回率:真正为正样本的样本中,被模型正确判定为正样本的比例。
通过这3 个指标的综合评价,可全面了解模型的性能,并验证模型是否达到了预期的效果。
式中:P为精确率;R为召回率;TP为真正为正样本的样本中,被模型正确判定为正样本的数量;FP为模型错误地将负样本判定为正样本的数量;TN为真正为负样本的样本中,被模型正确判定为负样本的数量;FN为模型错误地将正样本判定为负样本的数量。
2 识别精度分析
研究采用4 种语义分割网络对泡沫浮球进行训练,有4 种不同网络的性能。
U-net 模型是一种常用的语义分割模型,基本结构是卷积神经网络(CNN)。U-net 模型的F1 得分为90.35%,精确率为90.78%,召回率为89.92%。这意味着U-net 模型在分割任务上表现良好。
DeepLabv3+模型与U-net 模型是基于CNN 结构的。同样是CNN 结构,DeepLabv3+ 模型的性能却低于U-net 模型,其F1 得分为85.33%,精确率为85.65%,召回率为85.01%。这是由于DeepLabv3+模型使用的是空洞卷积(dilated convolution) 和全局池化(global pooling) 等技术,这些技术虽然可以增加感受野(Receptive Field),但也会降低分辨率,从而影响分割性能,此外DeepLabv3+在只取了2 个特征图层进行concat 后上采样,导致中间不同尺度的特征层信息丢失,从而导致性能下降。
Transunet 模型使用了CNN 和Transformer 结构,可以更好地捕获图像中的长距离依赖关系。Transunet 模型在所有指标上均优于其他模型,其F1 得分为93.76%,精确率为93.47%,召回率为94.05%。这表明Transunet 模型在语义分割任务上表现出色,认为Transunet 在浅层使用了CNN 结构,关注局部信息,在深层使用Transformer 结构,关注全局信息,二者结合,使得图像特征信息丢失的较少。
Swin-unet 模型使用了Transformer 结构,但其性能低于其他模型,其F1 得分为86.36%,精确率(P)为85.87%,召回率(R)为86.85%。由于纯Transformer 结构虽然更关注全局信息,但其展开成一维向量,因此少了空间信息,基于此点,图像Transformer 结构都需要加入地理编码,而地理编码方式本身会影响其精度,加之,Transformer 结构参数量大,在训练时,需要更多的样本支撑,由于训练样本偏少,Swin-unet 的精度并不理想。
不同密集程度、不同图斑大小、不同语义分割网络的泡沫浮球自动识别效果对比(图6)。U-net 在不同密度和不同图斑大小的场景中表现比较出色,但它存在一些问题,如细微孔洞、碎片化和小面积错误图斑等。DeepLabv3+的整体表现不理想,尤其是在密集小图斑的分割中存在漏提现象。Transunet 在所有场景中都表现最佳,其分割效果与U-net 相似,但在处理密集小图斑时也稍显逊色。Swin-unet 的分割效果相对较差,但在处理密集小图斑时要优于DeepLabv3+,主要是因为它基于U-net 结构,在Decoder 部分使用了concat 连接encoder 所有阶段特征层的设计。总体而言,4种网络对于大图斑的识别效果要优于小图斑,而对于稀疏区域的识别效果则要优于密集区域。今后研究可以考虑进一步优化这些网络结构,以提高密集小图斑场景自动识别的准确性和效率。
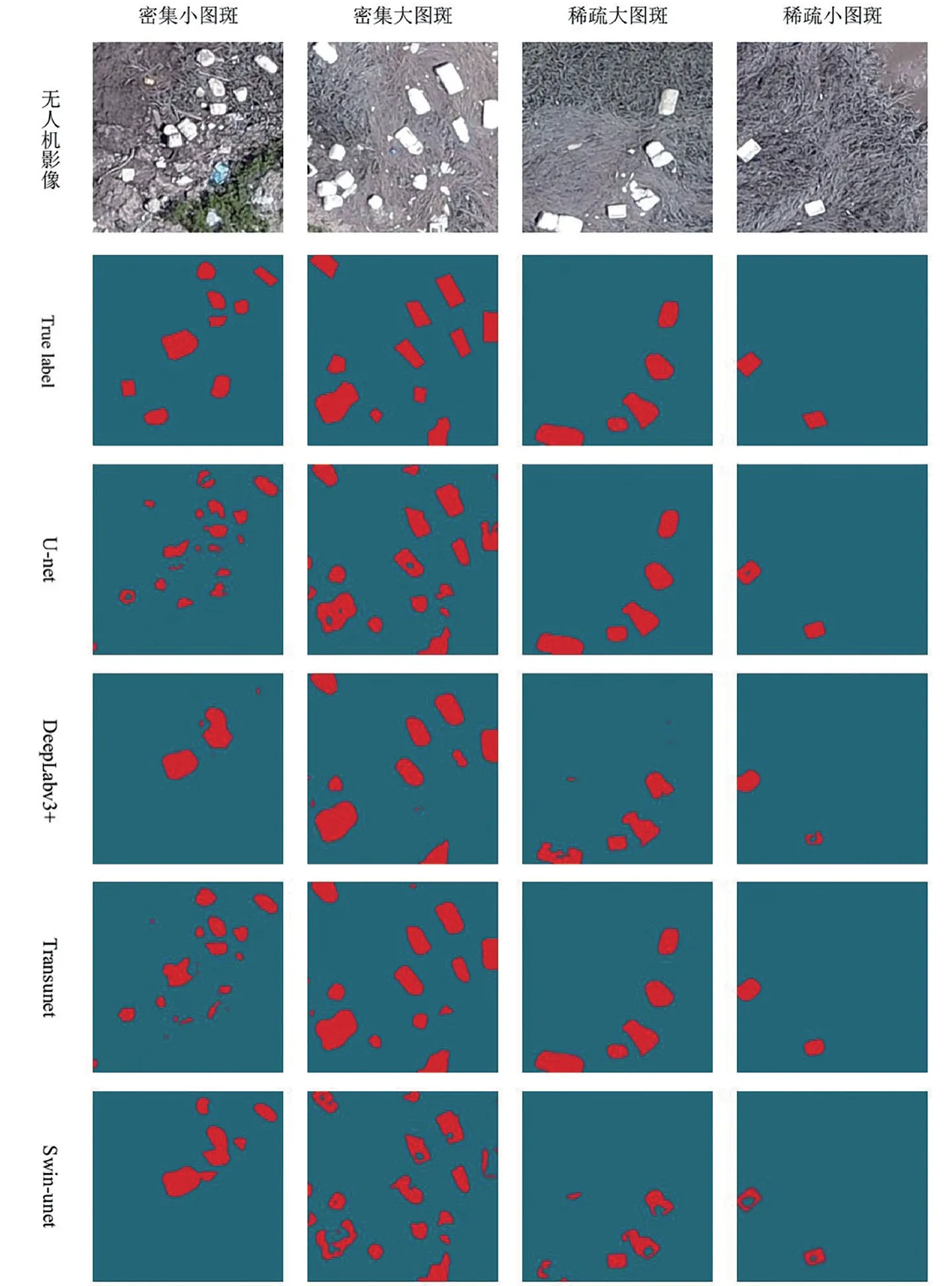
图6 分割效果对比Fig.6 Comparison of segmentation results
4 个模型计算耗时统计,测试区域以泉州市金井镇为例,影像大小为20 GB,裁切后测试图片数量为82 410 张,图片为256×256 pixels。测试所用GPU 型号为英伟达RTX 3080,数量3 块,内存为64 GB。在测试过程中,内存利用在11 GB 左右浮动,内存利用率为17%。Transunet 虽然精度更高,但由于其网络中有12 个Transformer layer,相比U-net 结构更为复杂,且参数也更多,实际使用中,Swin-unet 耗时4.72 h,Transunet 耗时3.58 h,DeepLabv3+耗时2.19 h,U-net耗时1.16 h,Transformer 结构的模型耗时更高。
3 结论
利用4 种不同语义分割网络对样本进行训练,成功地实现了对海滩塑料泡沫浮球的智能识别。实验结果表明,Transunet 网络具有较高的识别精度和鲁棒性,其F1、P、R精度指标均为最高,这得益于其CNN 与Transformer 串联的结构设计,能够有效地识别不同大小、不同密集程度的海滩塑料泡沫浮球。与其他网络相比,CNN+Transformer 结构具有更高的识别精度,可以更好地应对复杂的海滩环境,在实际应用中具有很大的潜力。
猜你喜欢
环球时报(2023-03-22)2023-03-22
北京测绘(2022年9期)2022-10-11
作文周刊·小学一年级版(2022年20期)2022-05-07
绿色科技(2021年5期)2021-11-28
趣味(数学)(2021年4期)2021-08-05
探索科学(学术版)(2020年7期)2021-01-13
计算机技术与发展(2020年4期)2020-04-30
科技视界(2019年26期)2019-11-26
长江科学院院报(2017年5期)2017-05-18
发明与创新·中学生(2015年8期)2015-07-21
