
基于深度学习的非均质土壤条件下探地雷达反演方法
2024-01-17 01:14赵昀杰
工程地球物理学报 2023年6期
张 坤,程 曦,赵昀杰
(新疆农业大学 计算机与信息工程学院,新疆 乌鲁木齐 830052)
1 引言
探地雷达(Ground Penetrating Radar, GPR)是一种非侵入式的无损测试技术,用于探测和图像化地下结构、地层和物体的特征[1-7]。探地雷达反演是一种地球物理数据处理手段,利用电磁波与地下结构相互作用的原理,能够对地下介质进行成像和参数推断。该技术已经在地质勘探[8]、环境监测[9]、土壤科学[10]以及军事应用等领域展示出巨大的潜力,并广泛应用于实践中。
探地雷达反演研究自21世纪初以来经历了长足的发展。最早的研究集中在理解雷达信号与地下目标之间的相互作用,随后逐渐演化为开展地下目标的三维成像和参数估计。近年来,随着传感器技术和信号处理方法的不断进步,探地雷达反演研究取得了显著进展,包括高分辨率成像、多频段和多模式数据融合等方面的创新。然而,该领域仍然存在一些挑战,如地下介质复杂性、非均匀性、多目标问题、数据处理效率和实时性等方面的问题,这些问题需要进一步的研究和解决,以提高探地雷达反演技术的性能和应用范围。
探地雷达反演方案一般分为传统解决方案和基于深度学习的解决方案。其中常用的传统解决方案一般是全波反演方法( Full-Waveform Inversion,FWI)。但FWI需要大量的计算资源和时间,而且面对非均匀介质需要很好的先验信息。近年来,随着深度学习技术的迅猛发展,基于深度学习的探地雷达反演方法成为研究的热点。本论文旨在研究基于深度学习的探地雷达反演方法。深度学习模型具备强大的表达能力和自适应性,能够从大量数据中学习土壤质量的复杂特征表示,从而提高预测的准确性和效率。一种基于多感受野双U形卷积神经网络(Double U-shape Convolutional Neural Networks with Multiple Receptive Fields, DMRF-UNet)的反演方法[11]被学者们提出,用于解决探地雷达反演问题。该方法采用两阶段学习方案,在非均匀土壤下进行反演,并利用多尺度卷积提取图像特征,从而实现高精度的模型。然而,该模型的计算量和复杂性较高,同时两阶段学习也增加了训练的难度。
本文提出了一种名为多特征提取网络块编码器—解码器(Encoder-Decoder with Multiple Feature Extraction Blocks, EDMFEBs)的神经网络模型。该模型在提高精确度的同时,降低了复杂度。通过分析接收到的电磁波反射信号,从而推断地下结构和目标的性质、位置和几何形状。研究中还引入了一种名为贪婪通道—空间注意力 (Greedy Channel-Spatial attention, GCS attention)的新方法,旨在提高模型的准确性。研究对象是在非均匀土壤条件下的形状规则介质目标地下成像。通过EDMFEBs网络,能够以高精度重建地下物体的介电常数、形状、大小和位置。与现有方法的比较结果发现在非均质土壤条件下,该方法缩短了训练时间,能有效去除反演结果中的伪影。
2 图像反演网络在探地雷达反演中的应用
2.1 主体架构
EDMFEBs将卷积神经网络和注意力机制融合,包含编码器、特征提取器、解码器三个部分。如图1所示,其中编码器是采用3x3的小卷积核加上批量归一化(Batch Normalization, BN)[12]和ReLU(Rectified Linear Unit, ReLU)[13],将输入特征图进行编码。5个多尺度自适应特征提取网络块(Multiple Scale Adaptive Feature Extraction Block, MSAFE Block)组成特征提取器,实现特征提取。解码器的结构是3x3的小卷积核加上Sigmoid激活函数[9]。
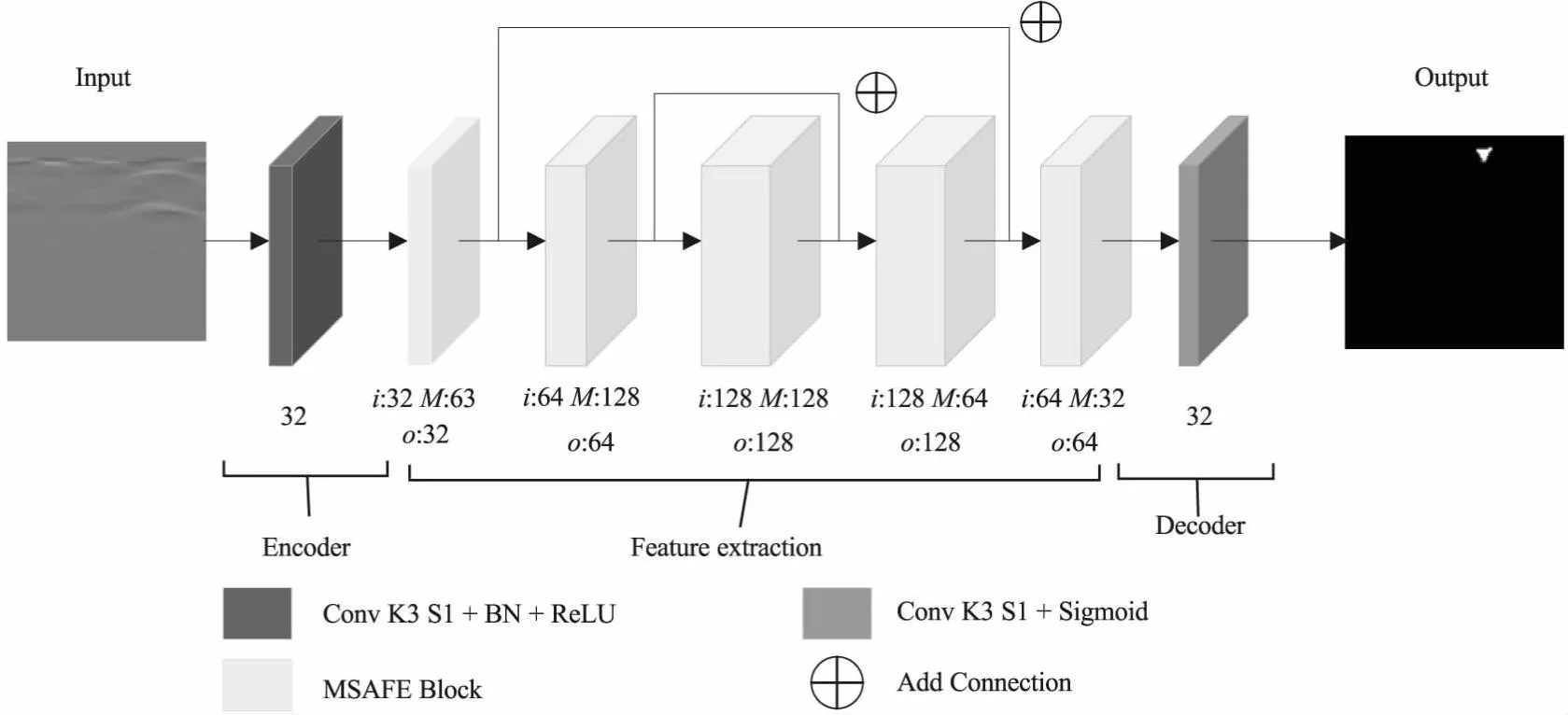
图1 含有多个特征提取网络块的编码器-解码器网络模型Fig.1 Encoder-decoder network model with multiple feature extraction blocks
2.2 MSAFE Block
图2为MSAFE Block的结构,特征图尺寸大小为128×128,通道数为32。主要由2个下采样网络块、1个上采样网络快和注意力网络块组成。
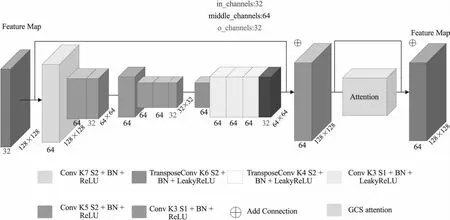
图2 多尺度自适应特征提取模块Fig.2 Multi-scale adaptive feature extraction module
第1个下采样网络块,包含一个核尺寸为7×7、步长为2、通道数为64的卷积层,特征图尺寸变为64×64,通道数为64。一个核尺寸为3×3、步长为1、通道数为64的卷积层,特征图尺寸和通道数不变。一个核尺寸为3×3、步长为1、通道数为32的卷积层,特征图的尺寸大小为64×64,通道数为32。
第2个下采样网络块,包含一个核尺寸为5×5、步长为2、通道数为64的卷积层,特征图尺寸变为32×32,通道数为64。两个核尺寸为3×3、步长为1、通道数为64的卷积层,特征图的尺寸和通道数不变。一个核尺寸为3×3、步长为1、通道数为32的卷积层,特征图大小为32×32,通道数为32。
上采样网络块,包含一个核尺寸为6×6、步长为2、通道数为64的转置卷积层,特征图尺寸为64×64,通道数为64。三个核尺寸为3×3、步长为1、通道数为64的卷积层,特征图尺寸和通道数不变。一个核尺寸为4×4、步长为2、通道数为32的转置卷积层,特征图尺寸为128×128,通道数为32。
在下采样网络块中,每个卷积层后面加上批归一化和ReLU。在上采样网络块中每个卷积层和转置卷积层后面加上批归一化和带泄露的ReLU(Leaky Rectified Linear Unit,LeakyReLU)[14]。此时特征图大小和输入时特征图大小相等,做一个相加操作。然后用一个核尺寸为3×3、步长为1、通道数为32的卷积层后面跟着BN和ReLU。在上采样和下采样中采用随机失活Dropout[15]。在实验中Dropout的值为0.3。
2.3 GCS注意力机制
注意力机制使得神经网络能够更加灵活地处理输入信息,将重要的信息集中聚焦,从而在任务中取得更好的性能和效果。如图3为贪婪通道—空间注意力 (Greedy Channel-Spatial attention, GCS attention) 网络块。它包含两种注意力网络块,通道注意力(Channel Attention)网络块[16]和空间注意力(Spatial Attention)网络块[17]。在通道注意力网络块中,首先对特征图X做全局最大池化和全局平均池化。然后用两个全连接网络分别对通道特征图进行压缩和激励,之后用SoftMax函数对特征图分别打分。采用2×C个可学习参数分别乘注意力分数,然后乘以原始特征图X,再把两个通道相加,这里做一个相加操作,提升模型的拟合速度。然后使用空间注意力,它通过对输入数据的不同位置进行加权,使模型能够更加关注重要的空间位置信息,并将其应用于卷积神经网络中的不同层次,以提升模型的表达能力和性能。它同样是将得到的输出和输入做相加操作,最终得到输出特征图。
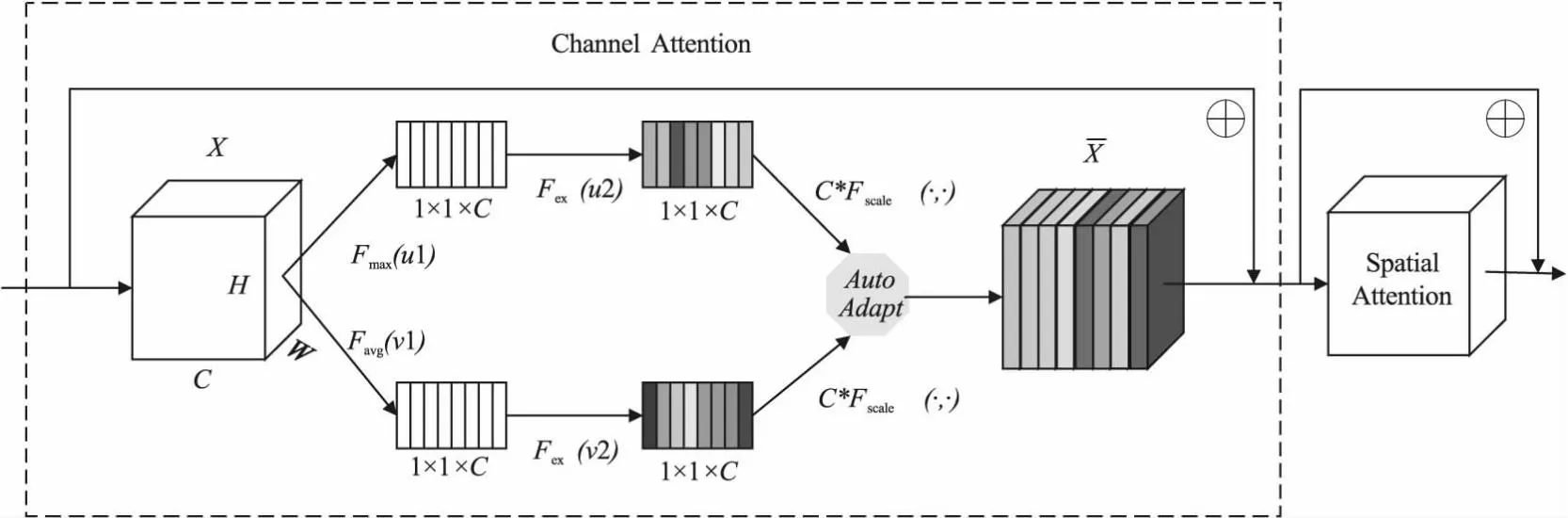
图3 贪婪通道-空间注意力网络块Fig.3 Greedy channel-spatial attention network block
其计算方式如下:
式(1)、式(2)分别为全局最大池化和全局平均池化。其中,H代表特征图的高;W代表特征图的宽;C代表特征图的通道数;xi,j,c代表第C通道上第i行第j列位置上的值。
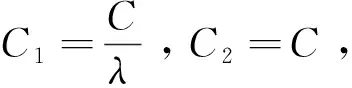
(5)
V2=σSoftmax(PX)
=Softmax(PC2*σ(XV2))
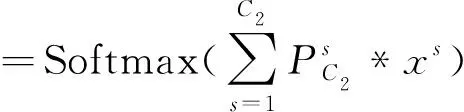
(6)
式(5)和式(6)中,Q=[q0,q1,…,qC2-1]和P=[p0,p1,…,pC2-1]是核的数量为C的滤波器,对X进行滤波操作,之后能得到输出U2=[u0,u1,…,uC2-1]和V2=[v0,v1,…,vC2-1]。
(7)
(8)
式(7)和式(8)为ReLU和Softmax激活函数,其中e为自然对数的底,近似值约为2.718 28。
(9)
式(9)为对U2和V2进行自适应操作。α和β是C个可学习参数,初始值为0,值域是[0,1]。最大池化层用于提取主要特征,而平均池化层则对特征进行平滑处理,有助于降低噪声的影响。在模型的学习过程中,贪婪的思想使得模型能够自动决定在通道中选择更多特征还是更多平滑处理。
2.4 损失函数
损失函数(Loss Function,Loss)是在机器学习和深度学习中用于衡量模型预测值与实际值之间差异的函数。结构相似性指数(Structural Similarity Index Measure, SSIM) 考虑了图像的亮度、对比度和结构等方面的信息。与传统的图像质量评估方法(如均方误差)相比,SSIM更能模拟人类感知图像的方式,因此在实际应用中具有更好的效果。SSIM通过比较两幅图像的局部区域来评估它们之间的相似性。将图像分为许多块,对每个块进行亮度、对比度和结构相似性的比较,并对比较结果进行加权平均。公式如下:
(10)
式(10)中,μx和μy表示图像x,y的平均值;σx,σy分别表示x,y的标准差;σx,y表示x和y的协方差;c1,c2为常数。返回一个介于0和1之间的值,其中1表示完全相似,0表示完全不相似。
均方误差(Mean Squared Error, MSE)是一种常用的图像质量评估指标,用于衡量两幅图像之间的差异程度。它计算了两幅图像中对应像素之间的平方差,并对所有差值求平均。平均绝对误差(Mean Absolute Error, MAE)是一种常用的评估指标,用于衡量预测值与真实值之间的差异程度。它计算了预测值和真实值之间的绝对差,并对所有差值求平均。平均相对误差(Mean Relative Error, MRE)是一种衡量预测值与真实值之间相对误差的指标,常用于回归问题的性能评估。
MSE的计算公式如下:
式(11)~式(13)中,x表示神经网络的输出;y表示训练数据中对应的真值;W,H代表图像的宽和高;N代表图像的像素总个数;xi,j,yi,j表示网路输出的图像和真值图像对应点的像素值。
模型在训练过程中,以MSE为损失函数,以SSIM、MSE、MAE、MRE作为评价指标。
3 实验
3.1 GPR模型
探地雷达一般包括一个发射器和一个接收器,它们分别用来发射电磁波和接收电磁波。图4为探地雷达模型,其中发射器用TX表示,接收器用RX表示,TX向地下发射电磁信号,RX接收到从地下反射回来的电磁波。形成A-Scan数据,TX和RX沿箭头方向移动,产生多道A-Scan数据,将其合并成B-Scan数据。
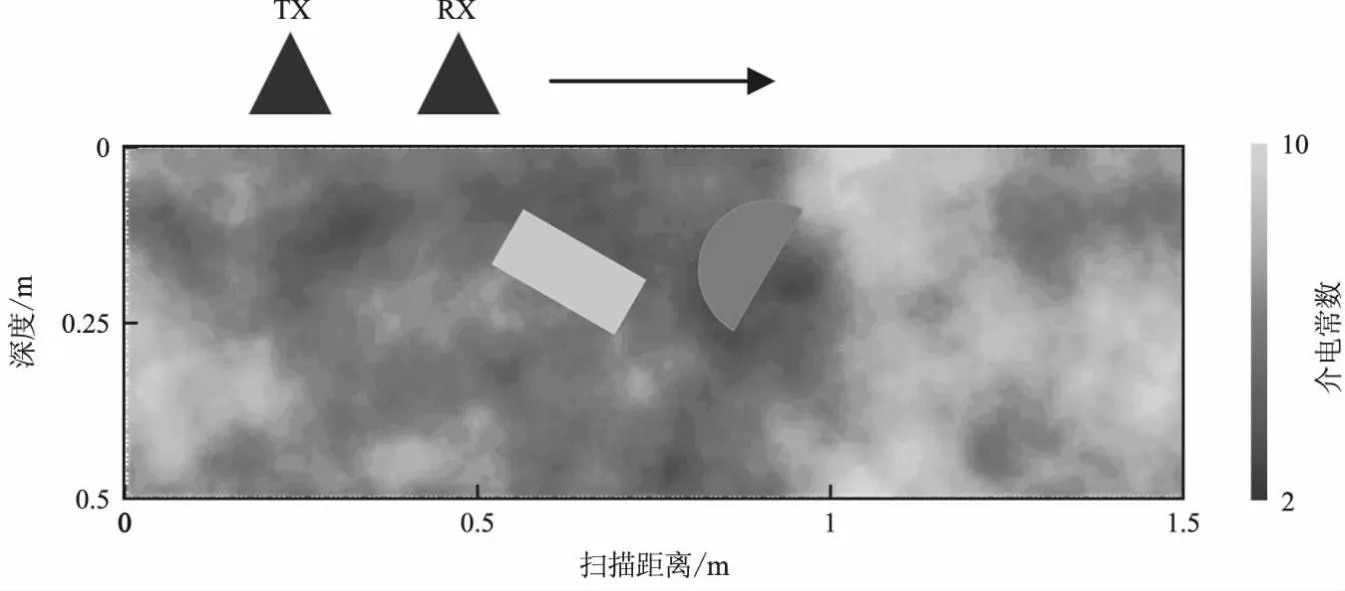
图4 探地雷达模型Fig.4 Ground penetrating radar model
地下是非均匀土壤环境,土壤大小为1.5×0.5 m2,使用Peplinski混合模型[18]。将土壤设置为砂粒分数为0.5,黏土分数为0.5,容重为2 g/cm3的土壤,砂粒密度为2.66 g/cm3,体积水分数范围为0.001~0.20。采用gprMax仿真生成非均匀土壤模型,土壤的介电常数在3~10。
在土壤中嵌入随机0°~360°旋转后的圆形、半圆形、方形、三角型物体,每个物体的介电常数在2~32之间随机取值。扫描方式为B-Scan,激发采用具有1A的振幅和1 GHz的中心频率的高斯波形。时间窗口设为20 ns。生成10种随机非均匀土壤环境,然后向土壤中插入随机目标物体。
发射天线和接收天线距离地面的距离为0.1 m,发射天线和接收天线之间的距离为0.2 m。发射天线从0.05 m处开始向右滑动并发射信号,此时接收天线的位置为0.25 m。发射天线和接收天线同时滑动。滑动到最右端的位置为1.25 m,此时接收天线的位置是1.45 m,每滑动0.025 m发射一次电磁信号,共有48道数据。
3.2 数据预处理
本文共采用两种预处理方式,第一种是采用简单平均减法[19]:
(14)
第二种预处理方式是去噪音预处理,使用B-Scan对无目标物体的土壤和有目标物体的土壤扫描后得到的数据格式是3 396×48,用扫描得到的土壤信号减去背景土壤信号:
(15)

将数据归一化:
(16)
式(16)中,xnorm表示xi归一化后的数据,值域为[0,1];xmin为xi中的最小值;xmax为xi中x最大值。之后再将数据的尺寸由3 396×48变为128×128。
图5为预处理后的效果。在图5中,将地下真实场景目标物体设为固定的像素值,背景介质的像素为0,目标物体的像素按照其介电常数大小将其从[0,255]平均切分:
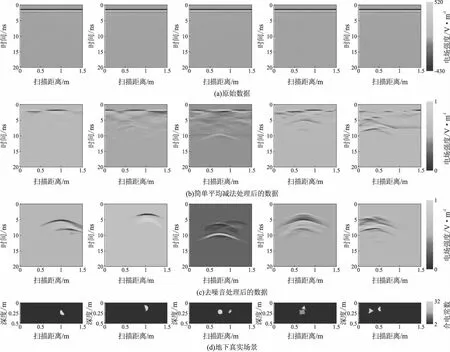
图5 预处理效果Fig.5 Preprocessed image
y=ceil((x-1)*(255/31))
(17)
式(17)中x代表目标物体的介电常数;y是对应的像素值;ceil是向上取整。比如,若目标物体的介电常数值是4,那它对应在图像中的像素应该是25。
3.3 实验环境与参数设置
在实验环境为Linux系统,基于Pytorch深度学习框架搭建EDMFEBs网络结构并进行实验,设置初始学习率为1 e-4,采用Adam优化器[20]进行网络训练,采用余弦退火策略通过在训练过程中逐渐降低学习率,并以余弦函数的形式调整学习率的变化,帮助模型更好地收敛到全局最优解。训练过程中使用Dropout以防止模型过拟合,BatchSize设置为100,共训练150个epoch,保证模型收敛。
3.4 实验比较
为了验证本文提出的EDMFEBs网络模型的有效性,在两种预处理数据上做实验,并与DMRF-UNet网络模型做对比。在DMRF-UNet网络模型原文中,采用双阶段训练方法,即采用图5中预处理结果图5(b)作为网络模型的输入,采用图5(c)为第一阶段网络训练的真值,采用图5(d)作为第二阶段训练网络的真值。而本文采用图5(b)作为网络模型的输入,图5(d)作为真值。
通过观察图6中的训练过程,可以得出以下结论:EBMFEBs网络在MSE损失的表征上优于DMRF-UNet网络。从图中的结果可以看出,EBMFEBs网络在训练过程中呈现出更快的收敛速度,并且在整个训练过程中能够维持较低的MSE损失值。相比之下,DMRF-UNet网络在训练初期出现了较高的MSE损失,并且在后续的训练过程中仍然存在一定的震荡和波动。

图7 反演结果比较Fig.7 Inversion results comparison
这些观察结果表明,EBMFEBs网络在损失函数的优化过程中具有更好的性能。它能够更快地学习到地下目标物体的特征和结构,并且更有效地减小预测结果与真实值之间的误差。相对而言,DMRF-UNet网络可能需要更长的训练时间和更多的迭代才能达到相似的性能水平。
在图7中,不同颜色代表不同的介电常数。图7(d)代表FWI预测结果,可以看出FWI可以粗略地反演出物体的介电常数结果,但预测物体的大小和形状偏离真实值。而且FWI迭代时间长,每个场景大约需要迭代2 h。图7(e)和图7(f)分别代表DMRF-UNet和EDMFBs预测结果,EDMFEBs改善了反演图像中出现“伪影”的情况,相比之下,EDMFEBs模型更接近真实介电常数数值,并且反演出的目标物体形状与地下目标物体更加吻合。
根据表1中展示的量化指标,可以观察到,EBMFEBs相较于DMRF-UNet在反演结果方面有明显的改进。具体来说,EBMFEBs相对于DMRF-UNet,SSIM指标提高了0.69 %,MSE降低了0.014 %,MAE降低了0.92 %,MRE降低了9.2 %。本文提出的EBMFEBs网络相较于DMRF-UNet在探地雷达反演效果上取得了显著的改进,这进一步验证了EBMFEBs网络结构的有效性和性能优势。

表1 模型精度对比Table 1 Model accuracy comparison table
根据表2的结果,可以观察到在GPU服务器上,EBMFEBs相对于DMRF-UNet具有更快的训练时间和预测时间。在实验中,训练集包含了14 400张图片,测试集包含了1 800张图片。表中的预测时间表示每张图片的预测时间。

表2 模型时间对比
在表3中,可以看到EDMFEBs相对于DMRF-UNet在模型规模方面有显著的优势。EDMFEBs模型具有更小的存储需求和更少的计算量,这意味着在部署和使用时,EDMFEBs模型更加高效。这一优势使得EDMFEBs成为一种更加轻量级和实用的选择,特别适合在资源有限的环境中进行部署和应用。

表3 模型效率对比
3.5 消融实验
为了评估EDMFEBs网络模型中各个组件对整体性能的影响,设计了消融实验。在EDMFEBs网络模型中去除了网络中的所有相加操作命名为EDMFEBs_v1。在EDMFEBs网络模型中删除了GCS attention机制命名为EDMFEBs_v2。在EDMFEBs网络模型中通道数减半,并将Dropout设置为0.15, 命名为EDMFEBs_v3。在实验过程中,保持了其他条件与EDMFEBs相同。
根据表4的结果可以看出,EBMFEBs网络中的相加操作对模型的收敛速度和精度都产生了正面影响。同时,引入GCS attention机制,在多尺度卷积层之后再次提取特征图的特征,进一步提高了模型的精度。此外,与EBMFEBs_v3相比,增加网络通道数进一步提升了模型的精度。
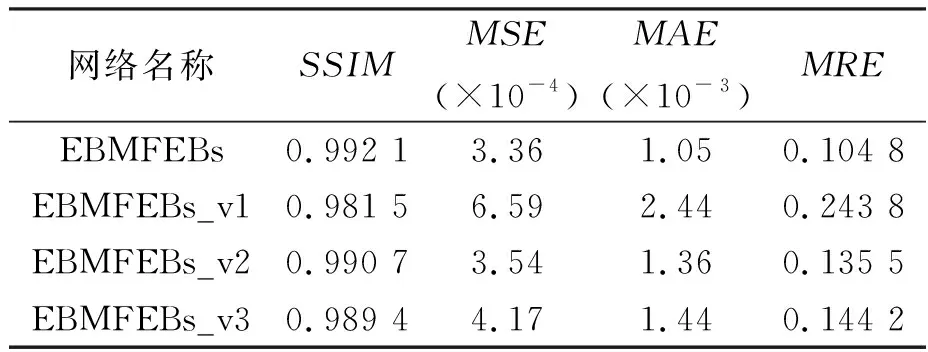
表4 模型精度对比
3.6 实测数据反演
如图8(a)~图8(c)[11]所示,在室外不均匀砂场上进行了商用GSSI效用扫描Pro GPR系统的测量。图8(a)显示了实验场景的示意图。如图8(b)所示,实验中使用 400 MHz 天线和控制单元的GPR系统来收集 B-Scan。沿 1 m 扫描轨迹获得的每个B-Scan由88个A扫描组成,每个A扫描中的采样点数为512。时间窗口为 20 ns。埋藏的物体被选为5个具有不同形状、大小和相对介电常数(εr)的木质物体。埋藏物体的特性如图8(c)所示。分别从[20,80] cm,[9,25] cm, [0°,60°]和[0°,60°]中选择物体的x坐标位置、深度、水平角和垂直角的范围。场表面的介电常数分布由Keysight N1501A介电探针测量。如图8(d)所示,由于湿度的差异,沿扫描迹线的相对介电常数为[2.64,6.48]。
采用DMFR-UNet[11]作者提供的开源数据集,验证模型的反演能力。共196张实测数据,按照8∶1∶1的比例划分数据集为训练数据、验证数据、测试数据。将DMRF-UNet和EBMFEBs网络在实测数据集上做迁移学习。
在实验环境为Linux系统,设置初始学习率为1e-5,采用Adam优化器进行网络训练,采用余弦退火策略通过在训练过程中逐渐降低学习率,并以余弦函数的形式调整学习率的变化,帮助模型更好地收敛到全局最优解。批次大小设置为10,共训练150个epoch,保证模型收敛。
在图9中,EBMFEBs在实测数据中仍可以反演出物体的形状、位置、大小及介电常数。预测介电常数与实际介电常数之间的差异,表明了EBMFEBs在实际应用中的有效性。
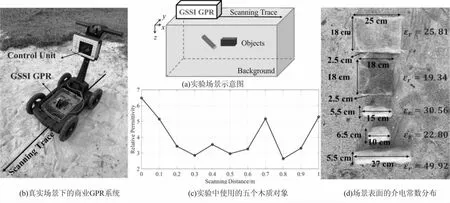
图8 真实测量数据的实验设置[11]Fig.8 Experiment setup for collecting real measurement data[11]
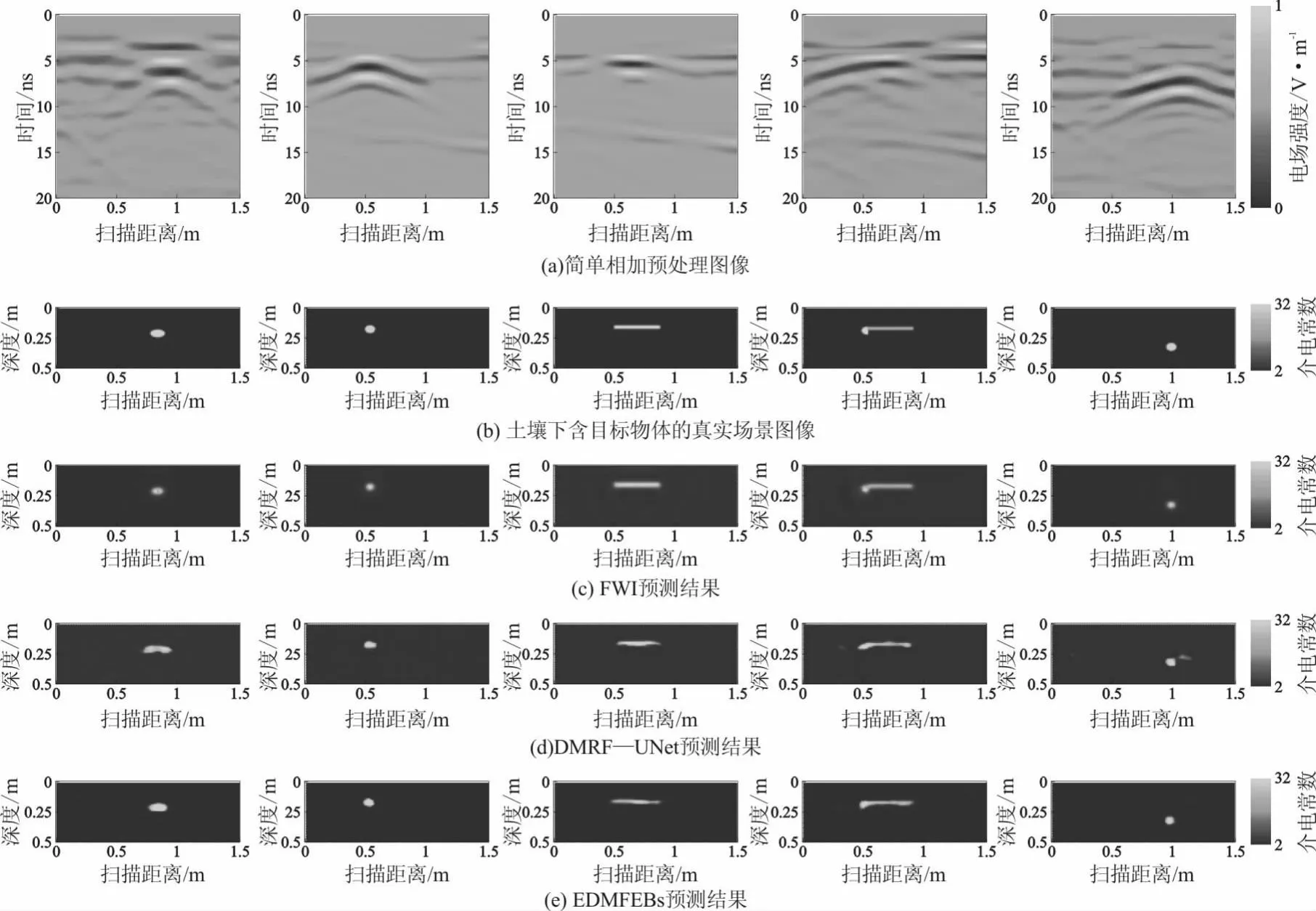
图9 实测数据反演结果比较Fig.9 Comparison of inverted results from real data
4 结论
经过研究和实验,提出了一种新的基于深度学习的探地雷达图像反演网络,名为EBMFEBs。该网络能够根据探地雷达图像反演出地下物体的介电模型图。EBMFEBs网络采用了U-Net模型结构的启发,但通过使用多个通道数较少的MSAFE Block来替代U-Net中通道数较多的情况。这种设计在保证模型精度提升的同时,减少了模型可学习参数的数量,降低了模型训练难度,并提升了模型的效率。
在EBMFEBs网络模型中,使用了5个MSAFE Block。前两个MSAFE Block的中间通道数是输入通道的两倍,第三个MSAFE Block的中间通道数保持不变,而后两个MSAFE Block的中间通道数减半。通过这样的设计,增加了模型的表示能力和非线性能力。此外,还采用了GCS 注意力机制,以进一步提升模型的精度。
本研究的实验环境是非均匀土壤,并且地下成像的目标是形状规则的介质。未来,计划在形状不规则的介质中进行进一步的研究,更好地了解探地雷达在这种复杂环境下的反演问题。同时,还将探索探地雷达在三维空间中的反演应用,这将进一步扩展研究领域并应对到更广泛的实际场景。
致谢
感谢新疆农业大学计算机与信息工程学院提供计算服务器支持。
猜你喜欢
中等数学(2022年5期)2022-08-29
科技研究·理论版(2021年20期)2021-04-20
雷达学报(2021年1期)2021-03-04
通信电源技术(2018年3期)2018-06-26
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年2期)2017-11-23
电子制作(2017年20期)2017-04-26
材料科学与工程学报(2016年5期)2016-02-27
中国塑料(2015年8期)2015-10-14
长江大学学报(自科版)(2014年2期)2014-03-20
