
基于多层次深度模型的社交网络核心谣言传播节点识别*
2024-01-19 11:18李元张栖朱建明焦建彬
中国科学院大学学报 2024年1期
李元,张栖,朱建明,焦建彬†
(1 中国科学院大学电子电气与通信工程学院, 北京 100049; 2 中国科学院大学应急管理科学与工程学院, 北京 100049) (2022年3月18日收稿; 2022年6月6日收修改稿)
数字时代的到来使世界各地人们的联系变得更加紧密和容易。在众多的协作、分享和交流渠道中,社交网络已成为人们生活中离不开的一种重要社交工具。公众能用社交平台关注当下热点事件、表达对热门话题的观点并分享自己的兴趣和生活,这种信息快速共享和转发的方式大大加快了信息融合的速度和规模。但是,信息的传播并不总是可靠的。为了赚取流量或其他某种目的,不断有人在社交平台中散布大量谣言。谣言是一种未经证实的信息,可能会带来伤害或威胁[1]。大量事实证明社交网络已成为谣言滋长的温床[2]。不仅如此,Vosoughi等[3]研究表明,利用谣言的吸引力和在线社交网络的广泛影响力,谣言比事实信息传播得更快、更广。这势必会给社会带来恐慌和直接或间接的经济损失。因此,在谣言扩散前,识别是否存在核心谣言传播节点以及谁是核心谣言传播节点,对于预防和控制谣言传播具有重要的理论和现实意义。
谣言控制已成为社交网络研究领域的一个重要分支。过去的研究多数是基于影响最大化的思想,从阻塞点[4-6]、阻塞边[7-8]以及寻找关键节点传播正面信息[9-11]这3个方面进行谣言事后控制。无论是哪种控制策略,其核心目的是通过某种算法寻找或识别关键的、有影响力的节点或边。其中贪婪算法是一种重要的方法,其核心思想是计算每个节点的影响力,并依次选择边际影响力最大的,直到选出K个最有影响力的节点[12-15];虽然贪婪算法有效性较高,但特别耗时。因此具有较低时间复杂度的启发式算法得到了学者的广泛研究[16-18]。此外,也有学者通过分析用户档案信息[19]、观察用户在特定时间窗口的活动模式[20]等方法识别网络中的恶意用户;还有不少学者从图论结构中心性的角度[21-23]描述了节点的重要性;随着人工智能的发展,有的学者利用特征工程[24]的方法在特定场景中寻找重要节点[25-27];此外,逐渐有学者开始尝试深度学习方法,例如图卷积网络(graph convolutional network,GCN)[28],可将关键节点识别问题转换为分类、聚类或预测问题[29-32]。
相比事后控制,对谣言的事先控制,能在尽可能早的时间实现从源头上进行谣言阻断,指数级地缩小全网监控范围,从而降低系统运行和维护成本,进一步推进实现人防和机防的联合响应,更好地阻止谣言传播。而实现事先控制的关键是识别核心谣言传播节点。因为核心谣言传播节点可能是谣言传播的潜在来源或引爆节点。这里,我们将谣言传播节点定义为那些可能参与传播谣言的用户。“核心”是指一种影响力,“核心谣言传播节点”是指传播谣言的用户中影响力较大的用户。实验中将谣言传播节点影响力前10%的用户视为核心谣言传播节点。在社交平台中,识别核心谣言传播节点具有4大难点:一是传播谣言的用户与众多没有参与传播谣言的用户建立了许多紧密的联系,这种联系加强了谣言传播者的网络融合性与隐蔽性;二是谣言话题具有复杂性和高维性;三是由于谣言事件发生的时间较短、随机性大、删除率高,因此无法有效地进行重要数据提取,导致现有公开数据集普遍面临数据样本稀疏、正负样本分布不均衡的问题;四是识别核心谣言传播节点这一问题目前还没有得到足够的重视,这主要是因为缺乏关于谣言传播节点的标注数据集。
基于此,提出一种多特征多层图卷积网络(MSF-GCN)模型的核心谣言传播节点识别方法。模型主要基于GCN,将特征工程和网络工程的方法结合起来,将节点静态属性和动态属性、谣言传播的时序信息、节点的关系网络整合起来一并纳入神经网络中进行学习。为解决谣言数据样本分布不均,样本数量缺乏这一问题,在进行量化计算时,设计了两阶段学习框架:第1阶段是GCN的预训练模型,它能针对特定下游任务,实现对整个场景的大概认知和知识提取;第2阶段是特征增强的GCN学习模型,它通过高斯采样技术,很好地扩展了样本集的特征,提升了小样本空间的致密性,促使神经网络的多层局部响应机制更好地发挥出来。通过与支持向量机(support vector machine,SVM)、K近邻(K-nearest neighbor,KNN)和逻辑回归(logistic regression,LR)3种基线方法的对比可知,MSF-GCN学习框架在基本没有增加计算量的情况下,不仅提高了识别类,而且实现了学习精度的显著提升。
综上所述,这项研究的创新性有以下3点:
1)通过对社交网络中用户动态和静态特征进行挖掘和提取,利用多层神经网的局部响应机制,有效地识别出核心谣言节点,从而实现谣言的事先控制。
2)提出一个多维特征下图卷积网络的双层学习框架,它将用户特征表示与网络结构特征相结合,既能处理节点静态/动态属性特征、语义特征和时序特征,又能处理节点的网络结构特征。
3)在MSF-GCN模型的双层学习结构中,通过预训练学习,对基本数据集进行特征提取。然后利用特征增强技术,对特征空间进行高斯采样,显著增加了特征样本数。这不仅解决了小样本分布不均、样本数量缺乏的问题,而且使过拟合问题得到了缓解。
1 数据及特征提取
首先对实验选用的数据集进行简要说明,接着详细解释如何将原始微博数据集转化为识别核心谣言传播节点的实验数据集。然后给出核心谣言传播节点的定义,并从实验数据集中提取3种不同类型的特征集,作为所提模型算法的原始输入。最后介绍所提MSF-GCN学习模型的关键技术。
1.1 实验数据集的获取
实验所用的数据集来源于清华大学Aminer团队编写的新浪微博公开数据集[33]。这个公开数据集是随机选择100个用户作为种子用户,然后依次收集他们的关注者及关注者的关注者。总共收集170万用户和他们之间的40亿个关注关系,平均每个用户有200个关注者。对于每个用户,同时收集他们的相关人物属性及最近1 000条微博(发布+转发)。
为将原始数据转化为所需的谣言数据,实验采用关键字筛选的方式,选出2类不同的谣言微博(原微博+转发微博)作为实验数据集。它们分别是“温州动车事故”(话题A)和“中国儿童尝试吃转基因大米”(话题B)。将参与这2个话题发布或转发的用户分为2大类,一类是支持谣言并继续发布和转发不实言论的谣言用户uR,一类是不相信谣言并发布和转发反谣言微博的反谣言用户uAR。在数据提取过程中,对抽取数据做了细致的人工标注。各话题具体统计信息见表1。

表1 实验数据集的统计量Table 1 The statistics of the experimental data set
抽取出的用户属性用UP={ui,Pi}表示,其中Pi表示谣言话题中用户ui的静态属性和行为
属性。静态属性包括节点的性别Gen(ui)、认证情况Ver(ui),及注册时间Reg(ui);行为属性包括节点的微博转发数Ret(ui)、微博原创数Pos(ui)、关注数Fol(ui)及粉丝数Deg(ui)。因此Pi=[Gen(ui),Ver(ui),Reg(ui),Deg(ui),Fol(ui),Ret(ui),Pos(ui)]。需要指出的是,由于一些用户被系统封禁,原数据集中无法获取到该类用户属性特征,因此将这类用户视为异常节点,将其删除。
另外,用户的历史微博内容用HC={ui,Ci}表示,其中Ci表示单个用户ui在社交平台上的微博历史文本信息,包括原始微博内容和转发微博内容。
1.2 核心谣言传播节点的定义
基于以上实验数据集,进一步对谣言用户进行细分。同时,给出以下2个定义。

决定谣言用户影响力的2个因素是扩散范围(粉丝数)的大小和参与谣言(发布或转发)的时间。越早参与谣言话题的传播,对谣言的扩散更有助力。先在同类谣言微博中,对谣言用户的参与时间进行时序化处理,对应得到谣言用户的时序数(见定义2)。再将用户粉丝数量乘以时序数的衰减因子,即用下式来衡量每个谣言用户的综合影响力
(1)

定义2时序s:指在同一谣言话题下,用户参与转发谣言的时间序列。
对同一类谣言微博按发布时间的先后进行排序,将其持续时间的取值范围分为k+1个等宽的区间,从0开始依次标记,落在第i个区间的用户的时序值用si表示,过程如图1所示。没有参与的用户时序值设为+∞。

图1 谣言微博时序处理过程Fig.1 Timing sequence process of rumor microblogs
根据上述定义,利用公式(1)可将实验数据集中谣言用户分为核心谣言传播节点与非核心谣言传播节点。最终得到3类用户,如表2所示。这也是实验的最终预测分类值。

表2 3类用户的数据统计Table 2 Data statistics of three types of users
1.3 模型特征集的提取
1.3.1 节点属性特征矩阵的构建
大量研究表明个体的异质性在谣言传播中起着关键作用,所以在构建模型的过程中,特别考虑了节点属性的作用。用户属性中包含节点的静态属性和行为属性,从中提取出模型能够识别的数据特征,并用于表示学习。
节点的粉丝数Deg(ui)可用于刻画度中心性Deg_Cen(ui),它反映该用户信息扩散的能力以及在网络拓扑中的重要性。关注数Fol(ui)可用于表示节点获取信息的范围。认证情况和性别是节点身份的一种象征,文中分别用认证用户和性别在原始数据集中的比例表示节点的认证特征Ratio_Ver(ui)与性别特征Ratio_Gen(ui)。另外,微博转发数Ret(ui)、微博原创数Pos(ui)和时间3个维度的组合可用来构造用户的活跃程度Act(ui),反映节点在一定时长内参与话题讨论的多少,其计算方式如下
(2)
T(ui)=Text-Reg(ui).
(3)
其中:T(ui)代表一个时间跨度,即用户注册时间到数据获取时间中间的时长;Text指获取数据的时间。
最后,通过上述分析,可以得到每个用户的静态及动态属性的特征向量:Fa=[Ratio_Gen(ui),Ratio_Ver(ui),Deg_Cen(ui),Fol(ui),Act(ui)],其中a为用户属性特性向量的维度5。整个网络系统中用户的特征表示可设为X=n×Fa,其中n为网络中的节点数。
1.3.2 节点的历史内容特征矩阵的构建
用户发布的微博内容在一定程度上可以反映出用户在某个时间段的兴趣和观点。因此在构造用户的历史内容特征矩阵时,选取节点的历史微博信息HC={ui,Ci}来提取相应的内容特征。将用户所有历史微博内容以文本形式存储后,经过文本向量化Doc2vec算法,可输出用户历史文本的特征矩阵D=n×Fb,其中n表示网络中节点数,Fb表示每个节点的历史文本内容Ci特征向量,b为历史内容特征向量的维度。
1.3.3 节点的局部时序邻域网络矩阵的构建
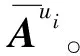
qi=-si+c,
(4)
(5)
(6)
例如图2,若要为节点a(da=3)提取一个规模为S=6的邻域矩阵,则需先提取a的所有1阶邻居b(1-hop,db=1)、c(1-hop,dc=2)和d(1-hop,dd=3),由于1阶邻居数为3,达不到S-1的规模,则继续提取a的2阶邻居e(2-hop,de=1)、f(2-hop,df=0)和g(2-hop,dg=2)。从2阶邻居中寻找出度更大的邻居e和g,就能得到节点a规模为6的邻接矩阵Aa。假设目标节点

图2 时序邻接矩阵的生成Fig.2 Generation of timing sequential adjacency matrix

2 模型方法
MSF-GCN模型是将识别核心谣言节点的问题转化为一个三分类的预测模型,3类分别是核心谣言传播节点、非核心谣言传播节点和反谣言传播节点。整个预测模型主要由输入层、隐藏层、全连接层、输出层及损失函数构成。
2.1 输入层

由于节点属性特征值存在量纲的不同,为提升模型的卷积速度和精度、避免过拟合,实验中采用下式max-min标准化方法对节点的每个属性特征值进行归一化处理
(7)
从而得到标准化后的节点属性特征矩阵X′。
这样每个目标节点的表示可以用属性特征矩阵与历史行为特征矩阵拼接而成,因此,输入层特征矩阵可表示为F(a,b)=(X′,D),其维度是a+b。
(8)

2.2 隐藏层
隐藏层也称图卷积层,它是一种利用图结构和特征向量学习节点表示向量的半监督算法。该层定义如下
(9)
其中:Hi为GCN第i层的节点特征表示,Wi和bi表示第i层的训练权重和偏差参数,σ为非线性激活函数。在实验中,模型设置了2层GCN,选择ReLu(x)=max(0,x)作为这2层的激活函数,H0为节点的特征矩阵F(a,b)。与此同时,为避免过度拟合,在这层还应用了Dropout[34]技术。
2.3 全连接层
模型中设计了3个全连接层(fully connected layers,FC)用于进行GCN下游任务学习。每个全连接层利用ReLu非线性函数激活。同样,在前2个全连接层采用了Dropout技术,以避免过拟合。
2.4 输出层和损失函数
全连接层的输出被送入LogSoftMax分类器。整个模型的输出为Z=In(P(uk,k,uAR)),将输出的分类结果与真实数据集中的标签进行比较,利用下式优化似然损失
(10)
综上所述,模型整体框架图如图3所示。

图3 模型框架图Fig.3 Model frame
3 实验与实验结果
实验使用的是Window64位系统,处理器为Intel(R) Core(TM) i7-9700 CPU@3.00 GHz,内存32 GB。在对比实验中,选取SVM、KNN和LR 3个基线方法。
3.1 超参数设置
在模型框架中,训练集和测试集比例为8∶2。用户历史文本特征维度设为300,即Fb中b=300;实验中对目标节点采样了S=50的邻域网络。由于用户属性特征维度a=5,因此,输入层中特征矩阵F(a,b)=(X′,D)中每个节点的特征维度为305维。
模型的前2层是图卷积层,后3层是全连接层,所有参数使用Adam优化器[35]训练得到,各层具体参数见表3。初始学习率设置为0.001,权值衰减为5e-4。当训练算法迭代到第10个epoch时,将学习率调为0.000 1。最终运行训练算法20个epoch时,通过early stopping方法[36]选出效果最好的模型。最终输出经过Logsoftmax处理,完成核心谣言传播节点、非核心谣言传播节点及反谣言传播节点的预测任务。
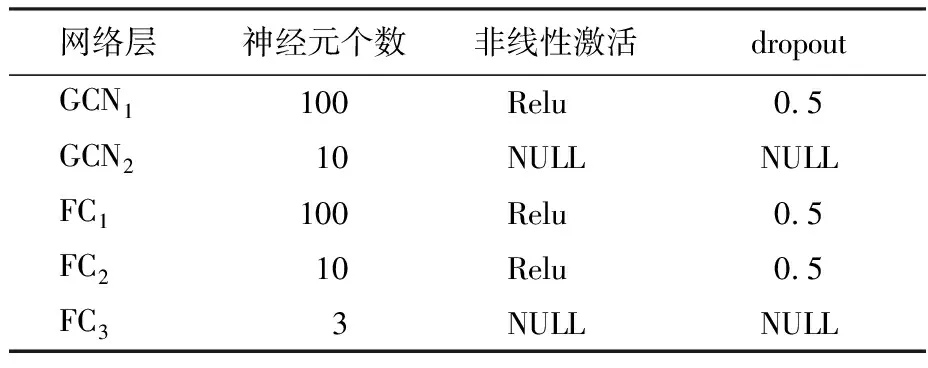
表3 模型参数Table 3 Model parameters
3.2 实验过程
3.2.1 预训练
由于小样本问题(样本不足和样本不平衡)的存在,模型会产生过拟合且缺乏泛化能力,因此在实验中对模型做了预训练,以完成对已有知识的抽取。将训练数据集放入模型,通过BP算法[37]得到模型参数,并且在预训练结束后得到数据通过GCN层后的特征表示,作为下一步高斯采样的输入。3类训练样本数分别为509、4 592和2 053,3类样本特征表示个数也依次对应。需注意的是,若预训练的epoch设置太低,模型还未充分学习,抽取到的知识自然是有限的;若epoch设置太高,模型虽然在训练集表现会越来越好,但是测试集上会表现得很差,这时候抽取到的知识是偏颇的,缺乏泛化能力。根据未做预训练之前模型在数据集上的拟合情况,实验将epoch设为3。
3.2.2 高斯采样

3.2.3 训练过程

3.3 实验结果
实验首先对MSF-GCN模型中加入预训练和高斯采样这2项技术带来的影响和效果做了验证。在MSF-GCN模型和传统GCN模型(不加入预训练和高斯采样)下,训练集、测试集的准确率和损失值随着epoch数的增加,变化趋势如图4所示。2组实验的模型参数一致。图4(a)和4(b)显示,随着训练的进行,传统GCN模型在训练集上准确率上升,但在测试集上,准确率会逐步降低。但损失值在训练集和测试集的变化趋势却呈相反情况,这种情况说明了过拟合的出现。而图4(c)和4(d)显示,MSF-GCN模型虽然前3个epoch在测试集上准确率比原始GCN低,损失值比原始GCN高,但是随着训练次数的增加,准确率在训练集和测试集都有所提高,且最终模型在测试集上的准确率超过传统GCN模型20%左右。MSF-GCN模型之所以在最开始表现得不如传统GCN,是因为它降低了模型对某些特征的依赖,更复杂的特征空间使得最开始学习稍微困难。但是随着学习的进行,模型从训练集提取到更丰富的知识后,在测试集中面对未知的特征,也能做出更合适的判断。最终,实验结果证明预训练和高斯采样能够有效解决小样本带来的过拟合和缺乏泛化性的问题。

图4 MSF-GCN与传统GCN模型对比Fig.4 Comparison between MSF-GCN and traditional GCN models
此外,还对MSF-GCN模型的有效性做了实验验证。这里选用SVM[38]、KNN[39]、LR[40]3种方法作为基准对比方法,并采用4种度量指标,分别是Precision、Accuracy、Recall以及F1-score。MSF-GCN模型与3种基准方法在4种度量指标下的差异如表4所示。结果显示MSF-GCN模型的有效性最好。在3种基准方法中,SVM效果最好,LR稍差,KNN效果最差。主要原因是KNN在预测时,需要考虑训练集中的每一个点,而当预测到稀有类别时,大量无关类别的点也会被考虑进去计算距离;LR和SVM都会增加与分类关系较大的数据权重,降低与分类关系较小的点的权重,但SVM通过支持向量来影响决策面,具有一定的稀疏性,因此效果较好。然而,MSF-GCN模型不仅考虑用户的个人属性特征,还考虑用户之间的关系,同时对小样本特征进行了补充,因此表现出最好的效果。
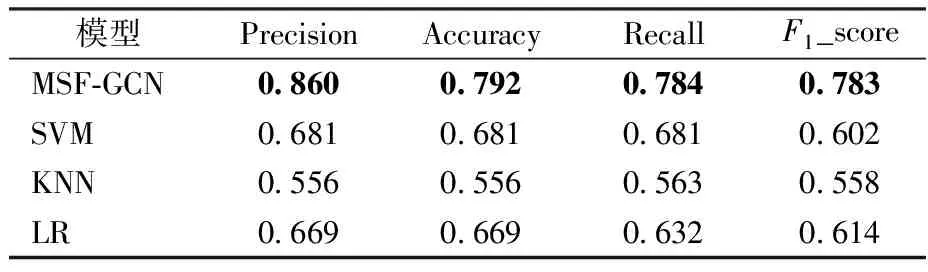
表4 不同模型下的预测效果评价指标Table 4 The evaluation statistics of different models
4 总结与未来工作
本文基于特征学习、节点的网络结构、历史文本特征和时间特性,构造了一个识别核心谣言传播节点的三分类预测模型。目标是提前锁定谣言传播中会发挥关键作用的节点,以实现有效识别、侦测、防控谣言传播,达到事先控制的目的。在这项工作中,提出MSF-GCN模型,通过模型预训练和特征增强的技术,使模型比基线模型能更好地识别核心谣言传播节点。同时,MSF-GCN模型的整体性能表明了该方法的有效性。在未来的研究中,计划构造新的模型算法扩展这项研究,例如图注意网络、残差网络等。另外,由于谣言话题的复杂性和高维性,在谣言分类下研究群体行为也将成为未来研究的一个重要方向。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
环球时报(2022-04-13)2022-04-13
国际眼科杂志(2021年9期)2021-09-15
装备制造技术(2020年2期)2020-12-14
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
中国盐业(2018年17期)2018-12-23
数学小灵通·3-4年级(2017年9期)2017-10-13
民间文化论坛(2016年2期)2016-12-01
学生天地(2016年32期)2016-04-16
