
基于机器学习算法的森林生物量多源遥感估测
2024-01-20 03:32黄天宝欧光龙徐熊伟王振会蔺如喜
西北林学院学报 2024年1期
黄天宝,欧光龙,吴 勇,徐熊伟,王振会,蔺如喜,徐 灿*
(1.西南林业大学,云南 昆明 650244;2.中国地质调查局 昆明自然资源调查中心,云南 昆明 650111;3.自然资源部 自然生态系统碳汇工程技术创新中心,云南 昆明 650111)
森林生物量是森林生态系统的重要数量、质量指标,对其精准监测是提高森林生态系统碳汇效益的重要保障[1]。传统野外调查方法获取森林生物量信息存在诸多局限性,利用遥感手段对森林生物量估测已然成为当前的热点[2]。被动遥感系统的光学遥感数据不仅具有覆盖范围广、获取容易、时间、空间分辨率高、技术成熟等优点,而且多光谱光学遥感具有红色、近红外(NIR)或红边波段,对植被具有较好敏感性等,被泛应用于森林生物量研究估测领域[3-5]。在光学遥感森林生物量遥感估测中,空间分辨率和光谱特征在很大程度上影响着森林生物量遥感估测精度[7],不同空间分辨率影像对地物的光谱特征及与样地尺度不匹配产生的混合像元都会造成估测差异[7-8]。随着遥感技术的不断发展,多源遥感数据协同估测森林生物量成为热点,多源遥感数据协同估测可以克服单一影像对地物特征描述的片面性,因此具有较好的估测精度[9-10],此外,环境因子也被广泛用于协同遥感估测,且在一定程度上可以提高森林生物量遥感估测精度[11-12]。然而,在整合多源数据估测森林生物量中,信息冗余无疑是面临的一个问题,在众多变量中选择最优特征变量参与建模是影响估测效果的关键一步[13-15]。在变量选择方法中Boruta是一种基于随机森林学习器的启发式算法,是通过变量与学习器结合的包装式变量选择方法,具有从复杂数据中挑选出与模型适应性较强特征变量的能力[16-18]。
在森林生物量遥感估测中的模型按结构通常可分为参数模型和非参数模型,非参数模型大多统称为机器学习模型,机器学习算法在森林生物量遥感估测中具有能充分捕捉复杂遥感变量与森林生物量之间的非线性复杂关系的能力,相较于参数模型,往往具有更好的估测效果[19]。常见的经典机器学习算法随机森林、k-近邻、支持向量机、BP神经网络等算法被广泛运用于森林生物量遥感估测[19-21]。Stacking集成算法作为经典的集成算法之一,相较于单一模型,Stacking集成模型能对特征数据充分学习,集各基础模型优点于一身、具有较强的泛化能力,可以克服单一模型结果的偶然性和片面性,具有较好的学习效果[22-23]。
森林生物量分为地上生物量和地下生物量,大多研究都是基于地上生物量遥感估测,全株树木生物量估测的研究相对较少。Landsat 8 OLI、sentinel 2A、GF2(国产高分2号)影像分别具有30、10、4 m不同的空间分辨率及不同波段,然而很少有研究在样地大小为10 m×10 m尺度上比较3种影像及影像整合的估测性能,为进一步探索基于机器学习算法的3种空间分辨率影像及整合3种影像在10 m×10 m样地下的森林生物量(地上+地下)估测性能,以及协同机器学习算法(RF、SVM、DT、GBM、k-NN、Stacking)的估测效果,本研究引入地形因子、气候因子、林分因子为辅助因子对GF2、sentinel 2A、Landsat 8 OLI影像、整合3种影像4种情况下基于Boruta算法变量选择方法,对楚雄州元谋县乔木林森林生物量遥感估测展开探索,可为森林生物量遥感估测提供参考和借鉴。
1 研究区概况
元谋县位于云南省楚雄州(25°33′44″-25°36′50″N,101°51′21″-101°53′32″E),为干热河谷典型区(图1),属于生态脆弱区,该地区旱湿季节分明,年平均降水量<800 mm,年平均气温21.9 ℃,最高温达40°以上,年积温7 791.6 ℃。年平均蒸发量为3 847.8 mm,年平均降水量634 mm,年平均蒸发量远大于年降水量。全年降水量大多集中在6-10月。由于地形和降水导致植被在垂直方向的分布差异明显,1 600 m以下主要以灌木为主,1 600 m以上主要乔木为主[24-25]。
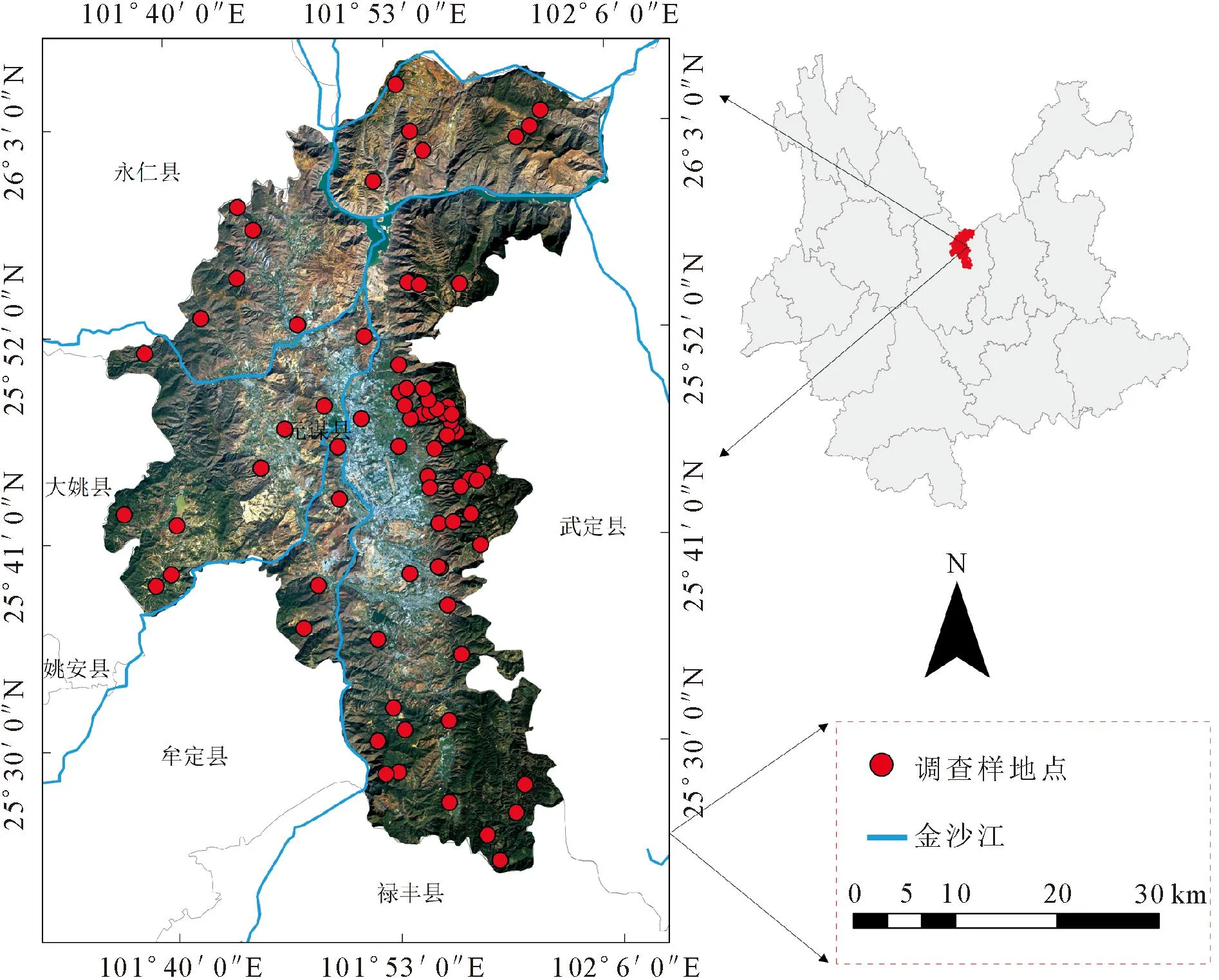
地图审图号:GS(2019)1822号
2 研究方法
2.1 样地数据处理
样地数据为2022年按树种分布、地理位置特征等调查的元谋县77块乔木树种,样地大小为10 m×10 m,用RTK记录样地质心点坐标,其样地分布见图1,涵盖了元谋地区主要乔木树种分布区域。树种主要包括云南松(Pinusyunnanensis)、锥链栎(Quercusfranchetii)、余甘子(Phyllanthusemblica)、旱冬瓜(Alnusnepalensis)、油杉(Keteleeriafortunei)、桉树(Eucalyptusrobusta)、华山松(P.armandii)、厚皮香(Ternstroemiagymnanthera)、黄檀(Dalbergiahupeana)等。参考tang等[26]、Luo等[27]、胥辉等[28]的云南省优势树种生长异速生长方程,计算单株树木的森林生物量,各公式见表1,没有生长异速方程的树种采用相近树种或按常绿落叶林、落叶阔叶林选取生长异速方程。

表1 单木生物量计算Table 1 Biomass calculation of individual trees
样地单位面积生物量(Q)计算公式为
(1)
式中:n为样地树种株树;W为单木生物量(t);S为样地面积(hm2)。
图2为样地单位面积生物量按优势树种、森林类型分布基本情况,其中阔叶林的样地较多,针叶林和混交林样地相对较少,所调查样地中针叶林的平均生物量大于混交林,大于阔叶林;松属、栎属为优势树种的样地单位面积生物量值分布差异较大;样地单位面积生物量最小值为1.86 t·hm-2,最大值为184.11 t·hm-2,平均值为60.53 t·hm-2。
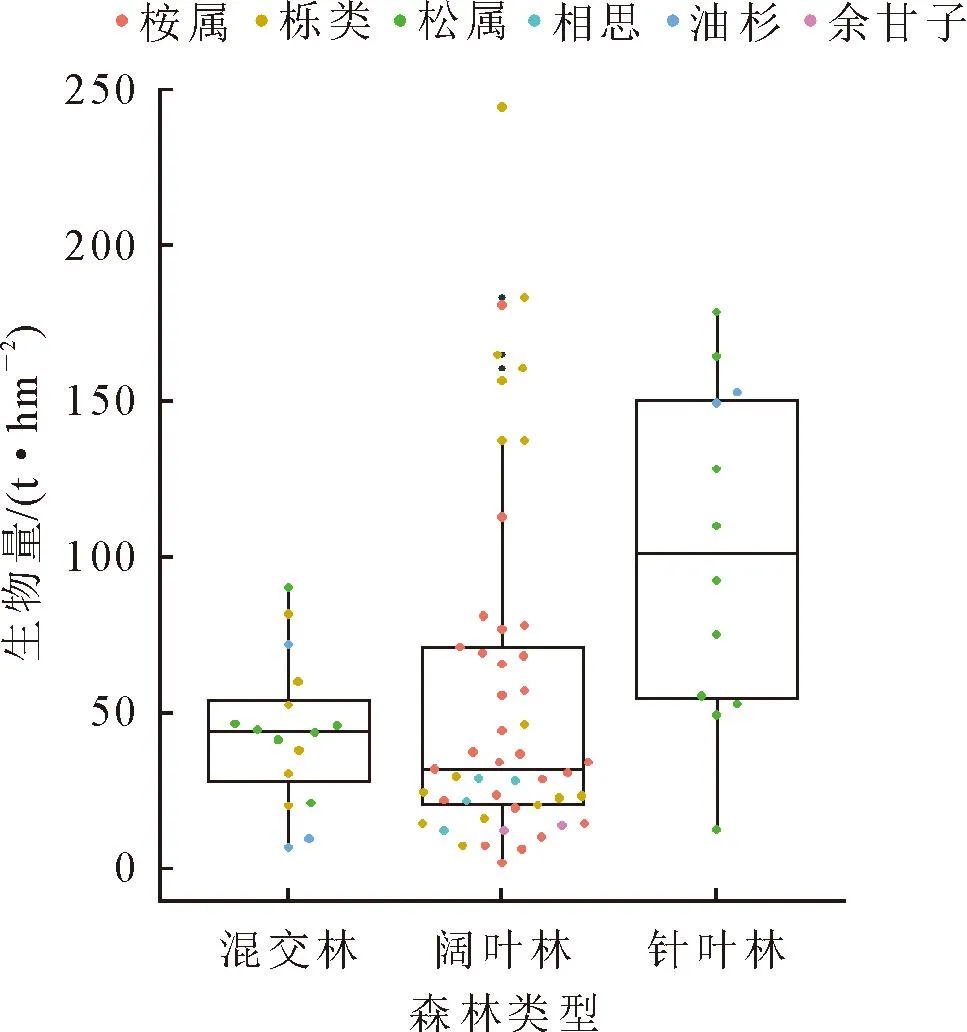
图2 样地生物量基本情况Fig.2 Basic situation of biomass in sample plots
2.2 数据获取及预处理
Landsat 8 OLI为地理空间数据云(http://www.gscloud.cn/)下载得到,分辨率30 m×30 m,本研究用了b1-b7波段;GF2为云南巡天卫星科技有限公司购买,分辨率4 m×4 m,共4个波段,将获得的Landsat 8 OLI、GF2在ENVI 5.3中经过大气校正、辐射定标、裁剪等预处理工作,最终得到地表反射率产品;sentinel 2A为GEE(google earth engine)云计算平台下载得到元谋地区2A级地表反射率产品,sentinel 2A分辨率10 m×10 m,共12个波段;环境因子来源于http://www.worldclim.org/,包括年均降水(MAP)和年均气温(MAT);DEM高程数据来源于地理空间数据云(http://www.gscloud.cn/)。
2.3 特征变量提取
参考Miura等[29]、Schlerf等[30]、Hashemi等[31]的研究在ENVI 5.3中完成对植被指数的计算,包括GF2、Sentinel 2A、Landsat 8 OLI 的单波段、植被指数、纹理特征。林分因子包括优势树种、森林类型(针叶林、阔叶林、针阔混交林),样地坐标与影像坐标均为高斯-克吕格投影坐标(CGCS2000_3_Degree_GK_Zone_34),并在Arcgis 10.7中以“多值提取至点”功能完成各样地遥感变量统计值提取,DEM数据(坡向、坡面、海拔)的提取,以及环境因子统计值提取,变量见表2。

表2 变量名称Table 2 Variables
2.4 特征变量选择
Boruta是一种基于随机森林学习器的启发式算法,其核心思想是通过对原始真实特征进行训练,构造阴影特征,并将原始特征与阴影特征聚合为特征矩阵进行训练,然后以阴影特征的特征重要性分数为参考,从原始真实特征中选择与因变量相关的特征集[32]。Boruta算法除了生成特征排序外还将特征分为3种类型(confirmed、tentative、rejected)对变量重要性进行定性评价[16-18]。在R语言中利用boruta程序包,分别对GF2、sentinel 2A、Landsat 8 OLI及三者变量整合情况下进行变量选择。
2.5 模型构建
利用R语言的caret包实现随机森林模型(RF)[33]、支持向量机(SVM)[34]、决策树(DT)[35-36]和梯度提升机(GBM)[37-38]模型的构建。堆叠集成算法(Stacking)一般由两层学习器组成,第1层为初级学习器,第2层称为元学习器,其基本思想是利用训练数据集训练模型构造基学习器,将所有基学习器的预测结果与响应变量真值组合为一个新的数据集,最后基于元学习器对新数据集进行训练和预测,也逐渐被应用于森林生物量遥感估[22-23]。在本研究中,以RF、k-NN、SVM、DT、GBM作为基础模型,最终以RF算法进行Stacking集成。77块均为建模样本,并采用K折交叉验证对模型评价。利用R语言的caret包实现RF、k-NN、SVM、GBM、DT模型的构建,采用网格化模型参数调优。
2.6 评价指标
K折交叉验证能有效避免过学习和欠学习状态的发生,尤其针对小样本数据建模具有较好的适用性,其模型评价结果也比较具有说服性[39],因此,本研究所有机器学习算法均采用K折交叉验证对模型检验评价,K取10。采用决定系数(R2)和均方根误差(RMSE)对模型评价。
3 结果与分析
3.1 boruta算法选择
经过boruta算法分别对基于sentinel 2A条件下、Landsat 8 OLI条件下、GF2条件下及整合多源遥感条件下进行森林生物量遥感测进行变量选择,boruta算法结果见图3,结果皆为Confirmed下的特征变量,在基于sentinel 2A估测森林生物量中,选择的变量为林分因子中的森林类型(forests_types)、植被指数和纹理因子,其中植被指数PEIP的得分最高;在Landsat 8 OLI下,纹理因子b2_ME_9×9的得分最高;在GF2下,植被指数GNDVI的得分最高;在SUM下GF2的GNDVI得分最高,但环境因子和地形因子特征没有被捕获。
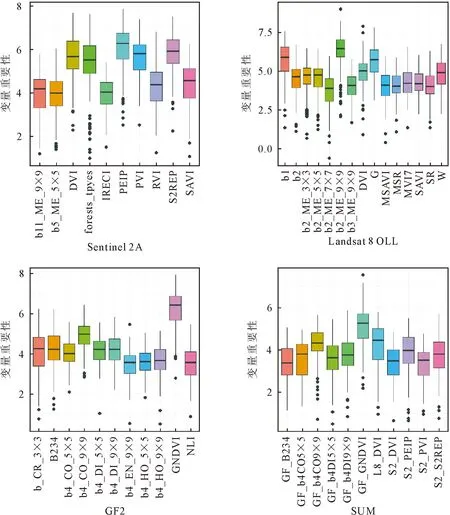
图3 变量选择Fig.3 Variable selection
3.2 模型评价
在基于boruta算法变量选择下,分别在sentinel 2A、Landsat 8 OLI、GF2及SUM条件下完成RF、DT、k-NN、GBM、SVM模型、Stacking集成算法模型构建,经过K折交叉验证,K=10,取其R2和RMSE的平均值作为评价指标,建模结果见图4。集成算法相较于单模型均有较好的估测性能,从集成算法的结果看,SUM估测森林生物量相较于单一遥感具有较好的估测效果,此外,GF2在元谋地区遥感估测森林生物量中相较于sentinel 2A、Landsat 8 OLI具有较好的估测性能,sentinel 2A的估测性能优于Landsat 8 OLI,SUM下的Stacking模型R2为 0.73,RMSE为28.46 t·hm-2,为本研究的最优模型形式。此外在单一算法中RF具有较好的估测效果。
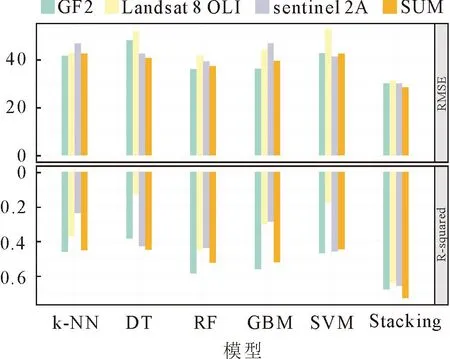
图4 建模结果Fig.4 Modeling results
3.3 反演估算
图5为基于sentinel 2A、Landsat 8 OLI、GF2、及SUM下Stacking集成算法的元谋地区森林生物量遥感估测反演结果,由图5可以看出,4种情况下的反演结果均有较好的异质性,其中基于Landsat 8 OLI的估测结果相较于sentinel 2A、GF2、SUM位于60~90 t·hm-2的图斑居多,sentinel 2A为影像源下,低值的图斑居多,基于GF2和SUM的估算结果较为相似,从模型评价效果来看整合多源遥感和GF2模型性能优于sentinel 2A和Landsat OLI,在高值估测能力方面SUM优于GF2,具有较宽的估测范围,基于SUM的估测结果更具参考意义。
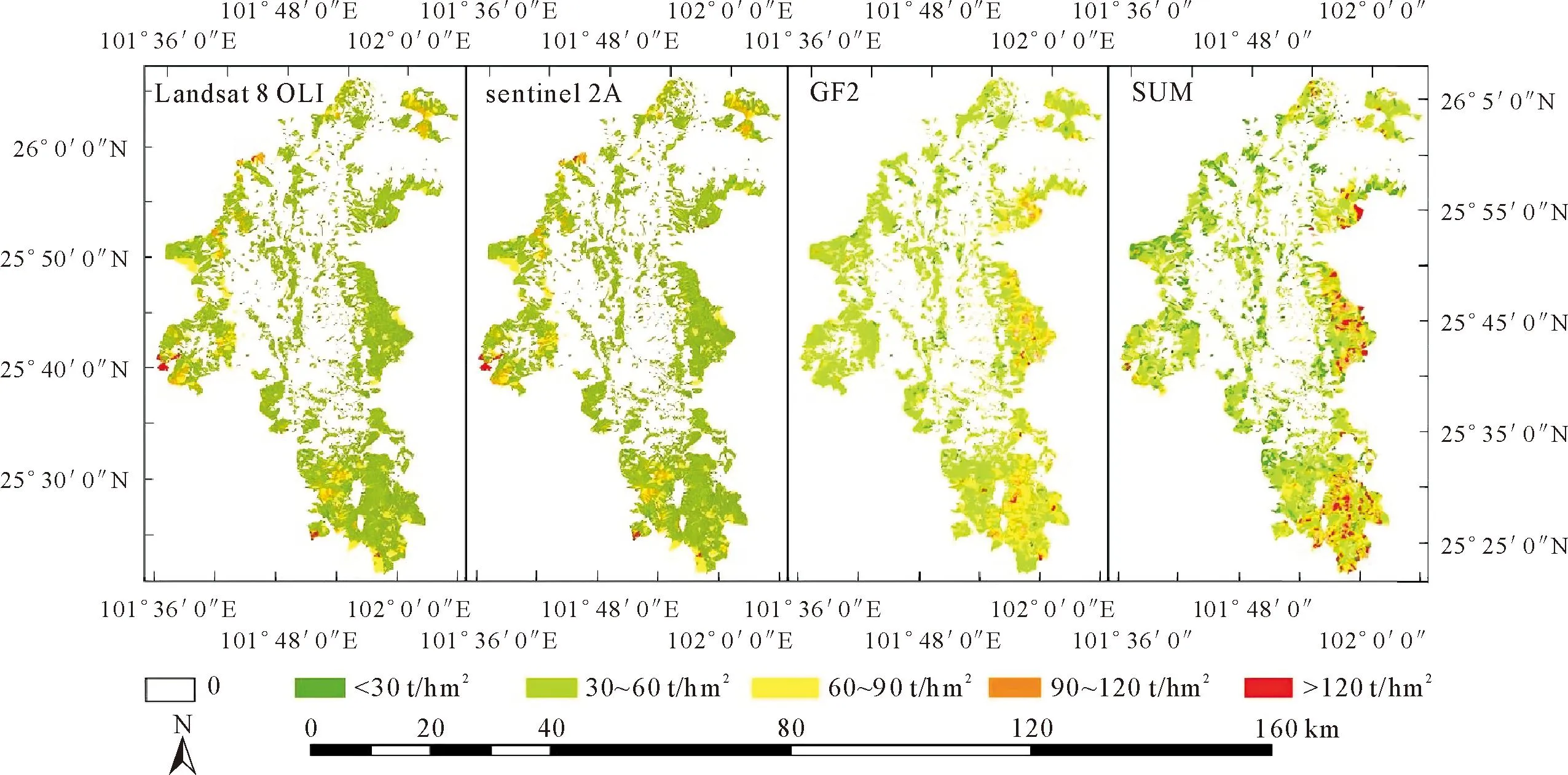
图5 元谋地区森林生物量遥感估算结果Fig.5 Estimation results of forest biomass remote sensing in Yuanmou area
4 讨论
基于Boruta算法在单一影像变量重要性得分中sentinel 2A影像的植被指数PEIP(红边感染点指数)、GF2的GNDVI得分最高,具红边波段的植被指数具有较好的得分,这与光学影像的红边波段对植被敏感的特征相呼应,此外在高分辨率影像GF2中,相对较多纹理特征与较高的得分,这与高分辨率影像估测森林生物量中纹理特征具有较好的估测效果相呼应[8]。基于sentinel 2A感测森林生物量中,林分因子森林类型也有较好的贡献率,若能有更多容易获取的林分因子协同森林生物量遥感估测[40-41],将会获得更好的估测效果。此外,光学遥感对针叶林、阔叶林、针阔混交林的光谱特征存在差异,由于受样本量限制,本研究仅将森林类型作为一个变量,若能分森林类型进行遥感估测,在一定程度上可以提高估测精度[41]。本研究引入年平均降水、年平均气温作为变量,但效果稍逊于遥感因子,在特征变量选择时没有被捕获,可能是由于区域尺度较小,气候因子的变化梯度不够明显,往往在大区域森林生物量遥感估测中,气候因子能发挥较好的效果[42]。
在本研究中,GF2相较于sentinel 2A、Landsat 8 OLI具有较好的估测效果,这与高分辨率遥感影像更具区分光谱特征变化能力、空间信息更加丰富、纹理和细节等信息更加突出等优点相呼应,相较于粗分辨率往往具有更好的估测效果相呼应[43],sentinel 2A估测效果优于Landsat 8 OLI,这与sentinel 2A与10 m×10 m样地尺度匹配,在理论上不存在混合像元,且与Landsat 8 OLI相比具有更高的空间分辨率相呼应。整合多源遥感往往比单一遥感具有较好的估测性能[44-45],本研究也如此,但在单一模型层面基于GF2构建的k-NN模型R2为0.46,整合3种影像后k-NN模型R2为0.39,GF2的RF模型R2为0.58,而整合3种影像后的RF模型R2为0.52,存在整合后反而模型效果比单一影像差的情况,本研究的解释为在变量选择方面只用了Boruta算法进行特征选择,在一定程度上可能存在偶然性和片面性、存在有用信息遗漏的情况以及针对所选择的同一份数据集对不同的学习器普适性会存在差异所导致,恰好集成算法在一定程度可以弥补这种缺陷,克服单一模型结果的偶然性和片面性,综合各模型对数据集进行客观评价,在一定程度上更具说服力[22-23],若能综合多种变量选择方法或许可以弥补单一变量选择手段的不足[46-48]。Stacking集成算法可以提高估测精度[22,43,49],通过降低生物量估计偏差的形式来提高估测精度[49],本研究最优集成模型的R2为0.73,RMSE为28.46 t·hm-2,在光学遥感估测森林生物量中,与Lin[22]、岳彩荣[50]和孙雪莲[51]基于光学遥感估测森林生物量相比较,其精度偏中上,主动遥感机载传感器系列在小区域往往有更好的估测效果[53-54]。
此外,在森林生物量遥感估测中,影像像元大小与样地尺寸的匹配问题导致产生大量混合像元也会影响森林生物量遥感估测精度,本研究比较了3种空间分辨率影像尺度在10 m×10 m样地尺度的估测效果,但没有体现混合像元带来的具体误差,Yu等[7]提出了一种熵加权指数的尺度转换方法,以修正粗分辨率遥感图像估计的生物量结果的尺度误差,改善了尺度不匹配带来的误差,值得参考和借鉴。在融合高、中低分辨率森林生物量遥感估测中,若能用高分辨率影像提取林分结构信息结合中低分辨率影像的多波段、光谱信息,应该可以很好地改善森林生物量遥感估测效果,有待进一步探索。
5 结论
通过机器学习算法用GF2、sentinel 2A、Landsat 8 OLI、SUM影像及辅助因子对元谋地区乔木林森林生物量展开估测,研究表明,在10 m×10 m样地尺度下SUM的估测效果最佳,其余依次为GF2、sentinel 2A和Landsat 8 OLI,SUM下的Stacking集成算法为最终估测模型,模型的R2为0.73,RMSE为28.46 t·hm-2。Boruta算法进行特征选择下,单一影像中sentinel 2A的植被指数PEIP、Landsat 8 OLI的纹理因子b2_ME_9×9、GF2的GNDVI分别具有最高的得分,GF2的GNDVI为SUM下的最高得分变量。在构建RF、SVM、DT、GBM、k-NN及对5个模型的Stacking集成算法中,Stacking集成算法均优于单一基础模型,在单一算法层面RF具有较好的估测性能。进一步说明高分辨率影像在10 m×10 m样地尺度下具有较好的估测效果,整合多源遥感和集成算法相较于单一遥感源和单一算法具有较好的估测精度,可为森林生物量遥感估测提供一定的参考和借鉴。
猜你喜欢
现代园艺(2021年23期)2021-12-01
林业勘查设计(2020年1期)2021-01-18
新农业(2020年18期)2021-01-07
今日农业(2020年19期)2020-12-14
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24
中国科技信息(2015年2期)2015-11-16
植物营养与肥料学报(2014年1期)2014-03-11
