
基于情感分析和热度预测的网络舆情预测研究
2024-01-22 06:35赵嵩正李美彦高鹏飞顾王旬皓
西安石油大学学报(自然科学版) 2024年1期
赵嵩正,魏 娜,李美彦,高鹏飞,顾王旬皓,2
(1.西北工业大学 管理学院,陕西 西安 710129; 2.中兴通讯股份有限公司,江苏 南京 210012)
引言
中国互联网络中心(CNNIC)在2023年3月发布的第51次《中国互联网络发展状况统计报告》[1]中显示,到2022年12月为止,我国网民规模达10.67亿,较2021年底增长了3 549万,互联网普及率达75.6%。其中,即时通信用户、网络视频(含短视频)用户、网络支付用户、网络购物用户、网络新闻用户、线上办公用户、在线旅游预定用户和互联网医疗用户分别占网民整体的97.2%、96.5%、85.4%、79.2%、73.4%、50.6%、39.6%和34.0%。这表明互联网已对人们的学习、生活和娱乐方式产生了重要影响,且成为信息传递的重要载体。然而,由于互联网自身存在的虚构性、隐藏性、扩散性和随意性等特征[2],个别媒体和一些网民借助网络散播虚假的和未经证实的信息,有意引导舆论走向,从而增加了舆情事件的负面影响,对社会的安定团结造成了重要危害。因此,对网络上的社会热点事件的网民情感导向进行有效分析和监控,及时监测事件的舆论现状,预测未来的舆论走向,有利于提前制定相应的应对措施,防止舆论被他人刻意引导,对于控制舆论影响有重要意义[3]。
现有的网络舆情分析方法包括基于构建指标体系的方法[4]、基于传播过程的方法[5]和基于情感分析的方法[6]。其中,基于构建指标体系的方法存在时效性差和主观性强的缺点;基于传播过程的方法存在模型复杂度高、依赖假设和缺乏综合性等局限;基于情感分析的方法则由于有较多的数据支撑而具有较高准确率。因此,本研究基于情感分析方法,将其与热度预测相结合,用于网络舆情分析。
目前主要的情感分析方法包括3种:基于情感词典的方法[7-11]、基于传统机器学习的方法[12-15]和基于深度学习的方法[16-21]。其中,基于情感词典的方法通过与人工构建的情感词典库匹配确定评论文本的情感极性;基于传统机器学习的方法通过传统机器学习模型(例如,支持向量机和决策树模型)实现文本情感分类,这两种方法均需要耗费大量的人工成本和时间成本,且领域适应性较差;基于深度学习的方法可以通过深度学习模型(主要指神经网络模型)自动学习文本的语义特征,减少了人工特征工程的工作量,然而,不同的深度学习模型通常可以提取到的语义特征也是不同的,单一的深度学习模型不能提取到情感分析所需要的全部语义特征,且数据不均衡问题(当热点事件中的舆论被有意引导时,评论文本中某一情感极性的文本数量往往多于另一情感极性的文本数量)会对深度学习模型产生比较大的负面影响[22]。
目前主流的热度预测方法是基于定量模型的方法[23-25],包括:时间序列分析、灰色理论、logistic模型、马尔科夫链和指数平滑法。其中,时间序列分析具有考虑时间依赖性,适用于短期和长期预测,可解释性强等优势,被广泛应用于热度预测领域。
因此,本研究提出了基于情感分析和热度预测的舆情预测思路;基于卷积神经网络和双向长短期记忆网络,构建了多特征融合的情感分析模型,解决了同时提取评论文本中长期记忆信息和局部信息的问题;基于简单数据增强方法,降低了情感分析中的数据不均衡问题对深度学习模型的负面影响;构建了基于时间序列分析的热度预测模型,实现了热点事件的热度走向预测;基于真实数据集,验证了本研究提出的情感分析模型、热度预测模型和舆情分析思路的有效性。
1 多特征融合的情感分析模型构建
本研究基于卷积神经网络和双向长短期记忆网络,构建了融合长期记忆信息和局部信息的情感分析模型(图1),该模型主要包括6个部分:输入层、数据增强层、词嵌入生成层、文本特征提取层、情感分类层和输出层。
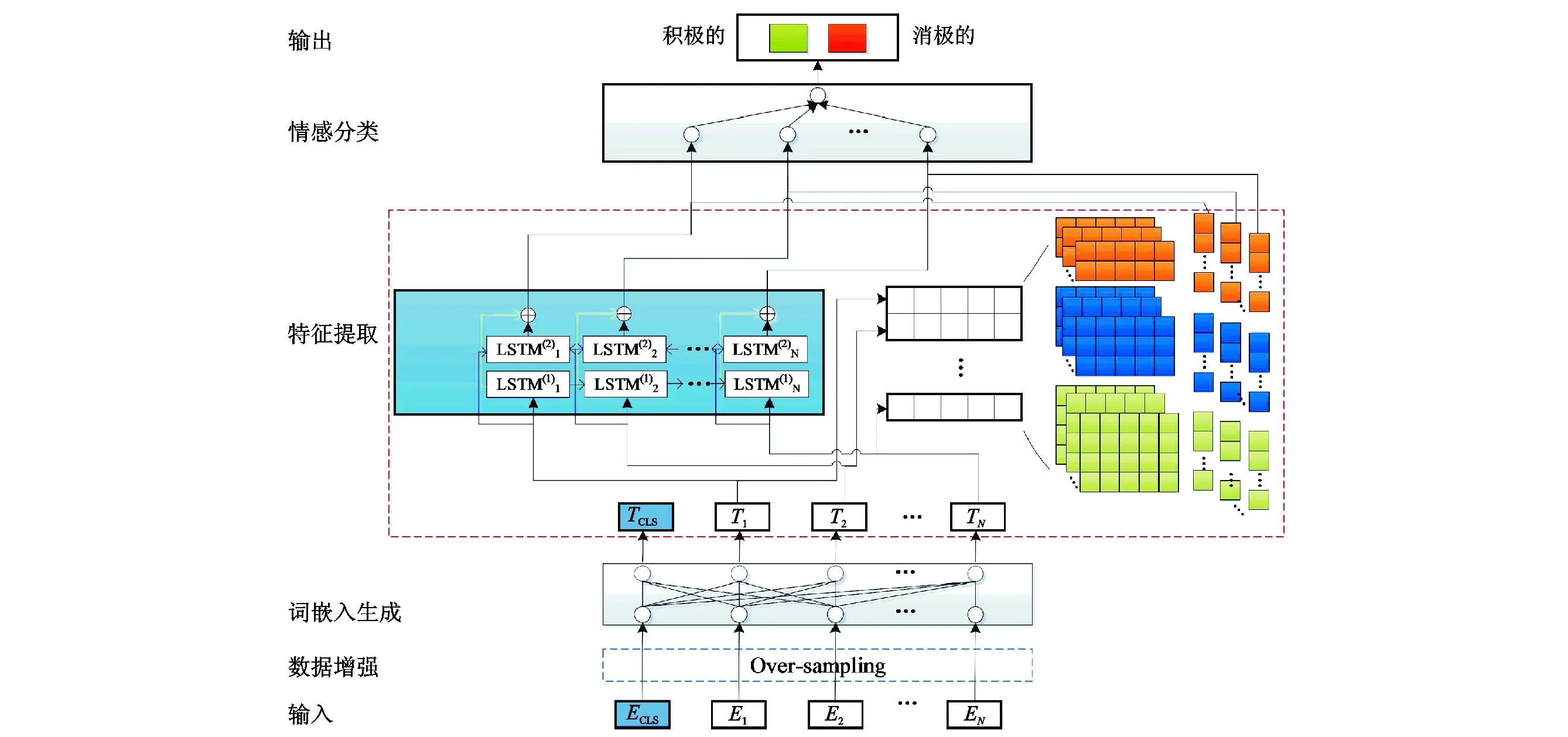
图1 基于多特征融合的情感分析模型
1.1 输入层
本研究构建的基于多特征融合的情感分析模型的输入是文本数据,每段文本按照字符或词汇切分,形成序列,最后将序列输入到整个模型。
1.2 数据增强层
为了降低数据不均衡问题对分类模型的负面影响,有研究者提出了用数据增强的方法自动增加训练数据中少数类的数据量[26],从而为分类模型构造出均衡的训练数据。由于数据增强方法不是本研究的主要内容,因此,本研究采用文本数据增强方法中最简单和易于实施的过抽样方法解决数据不均衡问题,即通过简单重复的方法,增加少数类的文本数量,得到均衡的训练数据集。
1.3 词嵌入生成层
BERT模型被广泛用于自然语言处理的各个领域(例如,文本分类[27]和关系抽取[28]),且均取得了不错的效果,因此,本研究采用BERT模型生成文本的词嵌入。
BERT模型由Transformer模型中的Encoder层堆叠而成,可以有效获取文本的上下文信息[29]。BERT模型的输入包括3部分:文本中的字符或词本身的表示向量、字或字符的位置表示向量和句子之间的分割表示向量。BERT模型的训练过程包括预训练和微调两部分,其中预训练基于遮蔽语言模型(Masked Language Model,MLM)和下一句预测任务实施,微调阶段则基于具体任务的文本数据进行训练。
1.4 文本特征提取层
采用Bi-LSTM和CNN提取文本的上下文信息和局部信息,如图1中的特征提取层所示。
Bi-LSTM模型由两层LSTM模型组成,一层学习正向的文本上文信息,一层学习反向的文本下文信息,通过两层得到的向量的拼接获取完整的文本上下文信息。Bi-LSTM模型通过门控机制可以有效解决梯度消失和梯度爆炸问题,从而保留文本的长期和短期序列信息。门控机制由3个门组成:输入门、遗忘门和输出门,分别用于决定上一时刻的信息可以输入到当前时刻的比例、当前时刻的信息需要被丢弃的比例和当前时刻的信息可以被输出到下一时刻的比例。
卷积神经网络(CNN)的模型框架包括卷积层和池化层两部分。卷积层通过卷积操作代替全连接神经网络中的全连接操作,实现参数共享,从而可以有效减少模型的参数数量,在一定程度上解决过拟合问题。同时,卷积神经网络可以通过卷积操作有效提取文本的局部信息,从而可以在情感分类任务中有效学习情感词汇所表达的局部语义特征。
1.5 情感分类层和输出层
通过全连接神经网络融合Bi-LSTM和CNN提取到的文本信息,实现文本情感分类。对于每一条文本,最终输出其情感极性:积极或消极。
2 基于时间序列的热度预测模型构建
为了评估社交媒体上某个话题的热度和未来走向,借鉴文献[30]提出的热度计算方法,本研究构建了社交媒体中某个话题的热度计算公式,并基于时间序列,构建了热度预测模型,预测某个话题的未来影响力大小。
2.1 热度计算方法设计
目前,用户在社交媒体上发表的关于某一事件的话题的影响度可以用3个主要指标来衡量,分别是:点赞数、评论数和转发数。通常,这3个指标在话题影响度评估中的重要性是不同的,本研究构建的热度计算式为
H=w1·R+w2·C+w3·L。
(1)
式中,w1,w2和w3分别表示不同的权重,可以通过专家访谈和文献分析等方法获取;R,C和L分别表示某个话题的转发数、评论数和点赞数。
由于不同话题的热度差异较大,因此,本文采用Min-Max标准化方法[31]对式(1)计算得到的热度值进行标准化处理,使最终得到的热度值取值范围为[0,1]。
2.2 热度预测模型构建
基于2.1节的话题热度计算方法,本小节通过时间序列分析方法,基于某个话题的历史和当前热度,预测该话题的未来热度走向,从而辅助重要话题的舆论控制策略制定。
现有的被广泛使用的时间序列模型包括:自回归模型(Auto-Regression,AR)、滑动平均模型(Moving-Average,MA)和自回归滑动平均模型 (Auto-Regression Moving Average,ARMA)。由于这3个模型都只能处理平稳时间序列,而本研究经过数据探索发现,话题热度序列属于非平稳时间序列,因此,采用文献[32]提出的求和自回归滑动平均模型(Auto-Regressive Integrated Moving-Average,ARIMA)执行话题热度预测任务,即采用差分运算将非平稳时间序列转化为平稳时间序列,再通过ARMA模型执行预测任务。ARIMA模型的数学表达式为
(2)
式中,p为自回归阶数;d为差分阶数;q为滑动平均阶数;φi为自回归系数;θi为滑动平均系数;φp、θq不为0;εt是零均值且固定方差为σ2的白噪声序列。
3 基于情感分析和热度预测的舆情预测
在获得某个话题的情感极性及未来热度走向后,可据此判断某个事件是否会引发网络舆情,以及可能引发的舆情等级,并制定相应的应对策略,使社交媒体上的舆论环境朝着良好的方向发展。例如,由于公众在面对某一事件时,对风险的感知程度越高,其消极恐惧情绪就会越明显,反之亦然[33]。因此,当某个话题的情感极性表现消极,且话题热度不断增加,则需根据话题讨论的事件,及时制定合理的应对措施,引导舆论导向,避免事件进一步恶化;如果话题情感极性表现积极,则话题热度无论如何演变,都可以任其自然发展。
同时,也可根据话题的热度变化是否符合预期,判断某个话题是否应被重点关注或判断制定的应对措施是否有效。例如,某个负面话题的热度在实时预测时,其真实热度总是远远高于预测值,则需要分析该话题的发展是否被人为控制,或向不可控的方向发展;当对某个话题实施了相应的应对措施后,如果话题的热度或情感极性向着预期方向发展,且变化范围大于预测值,则认为该措施发挥了积极正向的作用。
4 实验分析
本小节设计了3组实验用于评估本研究构建的情感分类模型、热度预测模型和舆情分析思路的有效性和合理性。
4.1 实验数据
本文选择微博平台作为数据的爬取来源,通过Scrapy爬虫框架获取相关内容。在情感分类模型的评估中,选择新浪微博中有关甲流话题的内容,共计得到相关数据30 101条;在热度预测模型的评估中,选择不同话题的881条博文,及其点赞数、转发数、评论数等相关数据;在舆情分析思路评估中,选择10个话题,对其进行具体分析。
4.2 评估指标
在情感分类模型的评估中,选择经典的准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F-measure (F1);在热度预测模型的评估中,选择平均绝对误差MAE、均方误差MSE、均方根误差RMSE和判定系数R2这4种经典的预测模型的评估指标;在舆情分析思路有效性评估中,采用专家访谈的方法对其进行评估。
4.3 实验过程及结果
4.3.1 情感分类模型有效性评估
在情感分类模型评估中,本研究设计了两部分实验,分别评估多特征融合模块的有效性和数据增强模块的有效性。
在多特征融合模块评估中,参与比较的基准模型包括传统的Bi-LSTM模型和CNN模型,比较结果见表1。

表1 情感分类模型中多特征融合模块评估
由表1可知,本文的情感分类模型在准确率、精确率和综合评价指标F1方面,均优于传统的Bi-LSTM和CNN模型。这是因为,传统的CNN模型只考虑了局部语义特征,没有考虑文本的上下文关系;Bi-LSTM模型充分考虑了上下文信息,但忽略了文本局部语义特征。本文构建的融合多特征的文本分类模型综合考虑文本上下文和局部语义特征,因此获得了优于其他两个模型的分类效果。
在数据增强模块的评估中,参与比较的方法包括不进行任何数据增强操作、简单的过抽样方法(Over-sampling)和欠抽样方法(Under-sampling),比较结果见表2。

表2 情感分类模型中数据增强模块评估
由表2可以看出,采用过抽样方法进行数据增强的情感分类模型在准确率、召回率和综合评价指标F1上,明显优于不增加任何数据增强策略的情感分类模型和采用欠抽样方法进行数据增强的情感分类模型。这表明,采用数据增强方法解决训练文本中的数据不均衡问题,可以有效提高分类模型的有效性。
4.3.2 热度预测模型有效性评估
在热度预测模型评估中,本研究设计了两部分实验,分别用于数据序列平稳性检验和预测模型效果评估。沿用文献[30]中的参数设置,将式(1)中的w1,w2和w3分别设定为0.45、0.35和0.20。
在数据平稳性检验中,选择某条博文(1)https://weibo.cn/comment/J9ogv2rZi?uid=2803301701&rl=0的热度序列,采用ADF单位根检验,评估数据序列的平稳性。检验假设H0:存在单位根;H1:时间序列不存在单位根。计算结果见表3。

表3 数据序列ADF单位根检验
从表3可以看到,3种类型的检验统计量基本都大于1%、5%、10%水平临界值,所以无法拒绝原假设,而且p-value均大于0.05,说明数据存在单位根,即数据是非平稳时间序列。
在热度预测模型的评估中,本研究基于BIC参数,确定了模型中的参数值:p=2,q=1。选择某一话题,基于平均绝对误差MAE、均方误差MSE、均方根误差RMSE和判定系数R2评估预测模型的有效性,评估结果见表4,预测结果可视化效果如图2所示。
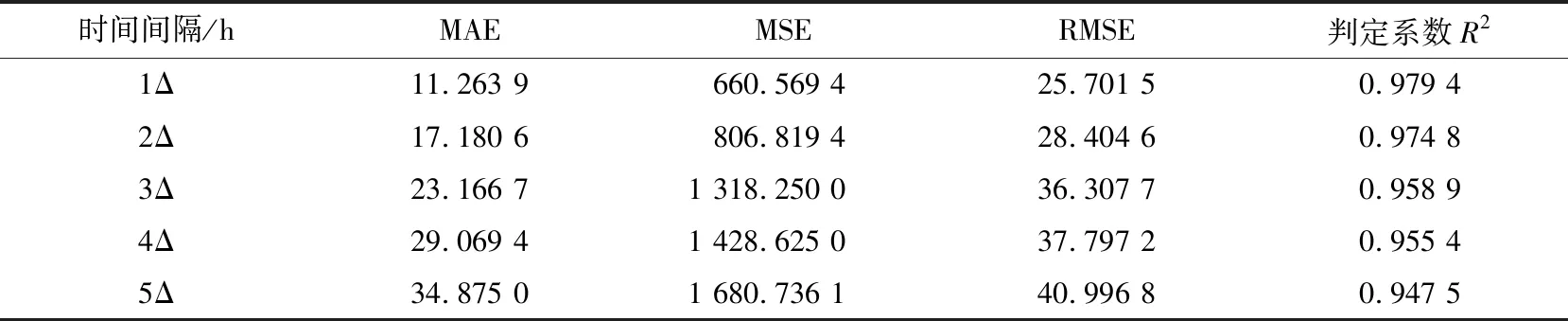
表4 不同时间间隔的预测模型效果评估

图2 实际数据序列与预测数据序列可视化
从图2和表4可以看到,随着预测时间间隔的增大,平均绝对误差、均方误差和均方根误差都在不断增大,判定系数在不断减小,表明模型的拟合程度在下降。判定系数表示自变量可解释因变量变化的比例,本研究中当自变量可解释因变量变化比例降低时,表示噪声所造成的影响增加。当判定系数低于0.95(噪声对预测热度造成的影响超过5%)时,预测热度不满足实际应用中对于准确度的需求。根据表4中的判定系数值,当预测时间间隔为1Δ、2Δ、3Δ和4Δ时,本研究构建的预测模型的预测效果可满足要求。
4.3.3 舆情预测思路有效性评估
为了评估本研究提出的基于情感分析和热度预测的舆情分析思路的有效性,收集10个不同话题,基于话题评论中负面评论的比率、话题最大热度和实际热度与预测热度发生较大偏差的次数(突变次数)筛选应该被重点关注的话题。实验结果见表5。

表5 不同话题舆情分析结果展示
从表5可以看出,话题6的负面评论率高达84.24%,热度突变次数高达3次且最大热度值也很高,因此,该话题的舆情预警等级最高,需要特别关注;话题2、4、9、10的负面评论率均超过50%,且最大热度值均超过1万,因此,这些话题的舆情预警等级较高,需要重点关注;话题1、5、7、8的负面评论率、热度突变次数、最大热度值3个指标中只有部分指标显示需要关注,因此给予其一般关注即可;相比较而言,话题3则无需过多关注。经评估,上述话题的评估结果与话题的后续发展基本吻合,这表明,本研究提出的基于情感分析和热度预测的舆情分析思路是有效的和可行的。
为了进一步分析热度预测结果对舆情分析结果的影响,本文对比了考虑和不考虑热度预测结果时的舆情分析结果。从表5可以看出, 在只考虑负面评论率的情况下,话题1和话题7的负面评论率均较低(分别为34.69%和29.63%),因此,预警等级应该设置为“无”,但由于在热度预测过程中,话题1和话题7的热度分别发生2次和3次突变,这说明这两个话题的受关注程度均在发酵过程中出现了一定程度的不可预测性,因此,这两个话题的预警等级应该被提高,这一结果也在话题的后续发展过程中得到了验证。这表明,在舆情分析中同时考虑情感分析结果和热度预测结果是有必要且合理的。
5 结 论
随着计算机技术的发展,社交媒体已成为人们信息交流的重要载体。对网络上的社会热点事件的网民情感导向进行有效分析和监控,预测未来的舆论走向,有利于提前制定相应的应对措施,对于控制舆论影响有重要意义。因此,本研究提出了基于情感分析和热度预测的舆情分析思路,构建了融合多特征的情感分类模型和基于时间序列的热度预测模型,用于分析社交媒体上热点话题的大众情感倾向及话题的受关注度趋势,并通过一系列实验验证了模型的有效性。本研究对于情感分类和时间序列数据的分析和预测相关研究有重要的理论意义;同时对于社交媒体上的舆论环境的分析和监管有重要实践意义。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
质量与标准化(2015年9期)2015-07-10
浙江人大(2014年5期)2014-03-20
传媒国际评论(2014年1期)2014-02-27
