
基于BERT 的BiGRU-Attention-CNN 混合模型的中文情感分析∗
2024-01-23 13:37张吴波
计算机与数字工程 2023年10期
邹 旺 张吴波
(湖北汽车工业学院电气与信息工程学院 十堰 442000)
1 引言
随着互联网的快速发展,抖音、微博、微信、美团外卖等各种网络平台正在逐渐地改变着人们的生活方式。越来越多的人在网络平台上发表自己的观点和态度,使得互联网用户逐渐由信息接收者转变为信息的生产者,并由此诞生出大量的蕴含用户主观情感色彩的文本数据。对这些文本信息的分析挖掘,能够更好地对产品和服务进行提升和改进,进一步改善人们的生活水平。
利用文本情感分析技术[1]能自动挖掘出各类评论文本中的情感倾向信息。传统的文本情感分析方法主要是基于词典,该方法是根据情感词典统计语料中出现情感词的数目以及权重来判断语料的情感类别[2]。但其准确率直接受到词典质量影响,不同领域需要制定不同词典,且构建和维护工作量较大[3]。近年来,随着机器学习与深度学习的广泛应用,各种学习策略与CNN、RNN 等神经网络模型逐渐被应用到情感分析任务中。CNN 模型具有较强的特征提取能力,广泛应用于图像领域。由于文本数据属于序列信息并存在上下文之间的联系,RNN 模型以及其变体LSTM、GRU 等模型被研究者广泛使用于文本信息中。对于情感分类任务,提取文本中的情感词至关重要,而这些常用的模型缺少对关键词的重点关注。在词嵌入方面,传统的词嵌入方法不能很好地解决一词多义的问题。因此,本文提出一种基于BERT 的BiGRU-Attention-CNN 混合模型的情感分析方法,在词嵌入方面采用BERT 模型产生包含丰富信息的动态词向量;在特征提取方面引入Attention 机制,为每个词分配不同大小的权重值,提高特征提取的精度。
2 相关工作
目前,对文本情感分析技术的研究主要是基于传统机器学习的算法[4]和深度学习方法。基于传统机器学习的方法是通过一定的学习策略和损失函数逐步迭代来进行特征学习,利用朴素贝叶斯[5]、支持向量机[6]、随机森林[7]等分类器进行有监督学习,然后采用训练好的分类器进行文本情感极性的分类。基于传统机器学习的算法在小规模数据集上效果较好,但随着数据量的不断增加各种复杂的特征出现,传统的机器学习的准确率也在逐渐下降。
近年来研究者逐渐采用深度学习算法来解决情感分析任务,其中CNN、RNN 等神经网络模型被广泛使用。Kim 等[8]在2014 年基于CNN的结构上对其调整提出TextCNN 模型,在文本分类上相比与传统的机器学习算法有明显的提升。但CNN 只能对文本进行局部特征的提取,无法捕获文本中上下文的依赖。Mikolov 等[9]首次将RNN 算法引入到文本的情感分类任务。但随着输入句子信息的增加,RNN 同时也会出现梯度爆炸或梯度消失的问题。随着研究者不断的优化和改进,长短期记忆网络(LSTM)[10]和循环门控单元(GRU)[11]等RNN 的变体逐渐被提出。杨青等[12]提出一种注意力机制和门控单元GRU 融合的情感分析模型,并验证其能有效提高情感分析的性能。
传统的深度学习模型对文本数据进行特征学习,无法对文本中关键词重点关注,且结构单一[13]。Attention 机制能对文本中的信息分配不同的权重值,很好地解决这一问题。徐菲菲等[14]结合卷积神经网络和最小门控单元MGU,并融入注意力机制提出C_MGU 模型,实验表明该模型能有效地提高情感分类的准确率。采用CNN 与RNN 以及融入Attention 机制相结合的混合模型虽然取得不错的效果,但是大多采用one-hot编码或Word2Vec 的词嵌入方法进行文本词向量表示。one-hot 编码方式容易导致向量维度过高,Word2Vec 方法无法解决一词多义的问题。BERT 模型是由Devlin 等[15]在2018 年提出的预训练模型,其目标是采用大量无标注语料来训练模型从而获得语料的完整向量表示。该模型采用多层能捕捉语句中的双向关系的Transformer 编码器对大量的语料进行预训练[16],能对不同语境中的词义产生不同的向量表征,有效地解决一词多义的问题。
综上,本文首先使用BERT 预训练模型将文本数据转化为包含丰富的动态词向量,然后采用BiGRU-Attention-CNN 混合模型进行数据的特征提取,其中BiGRU 模型能获取每个词更深层次的语义向量表达;Attention 机制能对关键信息加强;CNN 模型能对关键信息进行提取,最后采用Softmax函数计算情感极性的概率分布。
3 模型结构
为了实现中文文本的情感分析的目标,本文在基于BERT预训练模型下,结合BiGRU和CNN各自的优势并引入注意力机制构建混合的神经网络模型。如图1 所示,基于BERT 的BiGRU-Attention-CNN模型结构由六个部分组成:

图1 基于BERT的BiGRU-Attention-CNN模型结构
1)输入层:输入中文评论语料。
2)BERT 层:将文本转化为包含量丰富语义信息的动态词向量。
3)BIGRU层:获取每个动态词向量的更深层次的语义表达。
4)Attention层:计算每个词的注意力权重。
5)CNN层:对权重较大的词进行特征提取。
6)输出层:计算情感极性的概率分布。
3.1 BERT层
BERT 模型的基础是建立在Transformer 编码器的基础之上,拥有强大的语言表征能力和特征提取能力。Transfromer 模型[17]是由谷歌公司设计的Seq2Seq 模型,其中采用编码器-解码器的模型结构。Transformer Encoder 模型结构如图2 所示,Transformer 模型中重要的核心是采用多头注意力机制计算,实质通过线性映射来初始化不同的权重矩阵,将每个权重矩阵进行self-Attention 操作,从不同的角度去学习文本信息,从而实现丰富语义的目的。该功能类似于一个人从不同的角度去观测事物将会产生不同的观测结果。同时还加入Feed-Forward(前馈神经网络)与Add&Norm(残差连接&层归一化)对动态词向量的优化,前馈神经网络实质是两层线性映射并使用Relu 激活函数运算,Add&Norm 中的残差连接能减少传递信息中出现的偏差,层归一化将隐藏层归一为标准正态分布,可以起到加快训练速度、加速收敛的作用。

图2 Transformer Encoder模型结构
1)词嵌入向量与位置编码的计算如式(1)~(3)所示。
其中Xembedding是输入的词向量主要包括字向量和句向量,位置嵌入PE使用sin 和cos 函数的线性变换来提供给模型的位置信息,2i为偶数位置,2i+1为奇数位置。
2)多头注意力机制的计算如式(4)~(9)所示。
对WQ、Wk、Wv三个权重矩阵分别进行线性映射运算,从而达到多头的目的,然后对Q、K、V进行自注意力机制的运算得到,其中QKT是求注意力矩阵,然后用其给V加权,是为了让注意力矩阵更好的服从标准正态分布,使得归一化之后的结果更加稳定。为相应的初始权重矩阵;h为头数;Concat为拼接函数。
3)残差连接与层归一化的计算如式(10)~(14)所示。
残差连接将注意力得到的结果与X相加;层归一化是对向量矩阵中每行的每个元素减均值再除以标准差来实现归一化的目的;其中α、β是为了弥补归一化过程中损失掉的信息;ω防止除零。
4)前馈神经网络的计算如式(15)所示。
其中Linear为线性函数;Relu为激活函数。
BERT模型采用设计了两种方法来进行模型的预训练,第一种方法是采用MaskLM 的方式来训练模型,即以一定的概率随机选取字采用[MASK]替换,之后编码器根据语料的上下文来学习和预测被MASK 的字来训练模型。第二种方法是采用Next Sentence Prediction 的方法,即输入两个完整的句子,通过提取句中的信息来判断两个句子之间的逻辑关系,从而训练模型。
3.2 BiGRU层
GRU与LSTM一样属于RNN的变体形式,为了解决RNN 不具有长期依赖与梯度爆炸或消失的问题。GRU 的功能与LSTM 类似,其优点在于具有更少的参数和简单的结构。GRU 最重要的结构包括重置门r,更新门z,其内部的计算更新过程如式(16)~(20)所示。
其中xt表示当前节点的输入;ht-1表示上一节点的隐藏状态;h'表示候选隐藏状态;σ表示Sigmoid激活函数;ht表示传递给下一节点的隐藏状态;yt表示当前节点的输出。w1-7表示权重矩阵;b表示偏置项。重置门r用于控制上一节点的隐藏状态被遗忘的程度,产生候选隐藏状态h'。更新门z同时具有遗忘和记忆的功能,(1-z)*ht-1用于对上一节点状态选择性遗忘,z*h'用于对候选隐藏状态进行选择性记忆。
3.3 Attention层
Attention 机制的原理是对每个词分配不同大小的权重值,然后通过对权重进行加权和。其能对神经网络的隐层中的关键信息分配较大的权重,对无关的信息分配较小的权重,实现更好的特征提取。注意力机制是模拟人类大脑中的注意力功,专注重要的信息和忽略无关重要的信息。注意力机制的计算过程如式(21)~(23)所示。
其中hi表示BiGRU在i时刻输出的隐层状态;ei是预测与目标匹配的score 函数,表示对hi分配不同的初始权重值;V、W表示权重矩阵;ai表示对ei进行softmax 计算注意力的概率值;y为包含注意力值的语义向量。
3.4 CNN层
CNN 层采用的是文本卷积神经网TextCNN。相比于图像卷积神经网络,最大的区别在于TextCNN 采用不同大小的一维卷积核在文本序列上滑动,对文本进行特征提取。一般卷积核的大小kernel_size 设置为2、3、4 三种卷积核,其能对较长和较短的文本信息同时进行卷积。卷积网络的内部计算过程如式(24)~(25)所示。
其中yi:i+h-1表示第yi个向量到第yi+h-1个向量;b为偏置项;W为卷积核;式(24)表示卷积核W与yi:i+h-1进行卷积运算,得到相应的特征输出值Ci。式(25)是对卷积后的结果采用最大值法进行池化运算。
3.5 输出层
全连接层将池化运算的结果Pi传入输出层,采用softmax 函数计算预测概率实现对情感的分类,输出层的计算如式(26)所示。
其中w为权重矩阵;b为偏置项;p(y|Pi,w,b)为计算出的所属情感类别的概率分布。
4 实验
实验在Windows10 上进行,CPU 为Intel(R)Core(TM)i9,3.10GHz,GPU 为RTX3060 12G,编程语言为Python3.7,深度学习框架为Tensorflow 2.4.1。
4.1 数据集
本次实验数据集选用的是公开的中文数据集,分别为酒店评论数据集ChSentiCorp_htl_all、外卖评论数据集waimai_10k、网上购物评论数据集online_shopping_10_cats、微博评论数据集weibo_senti_100k。按照8∶2 将数据集分为训练集和测试集,4种中文数据集详情和样例如表1、表2所示。

表1 中文数据集详情

表2 中文数据集样例
4.2 实验设置
实验的模型参数设置较多,其中BERT 层采用谷歌公司已经训练好的中文BERT 模型,该模型采用12 层Transformer 编码器,隐层的维度为768,多头注意机制的的头数为12,总参数大小约为110MB。BiGRU 层中隐藏单元数为64,CNN 层中每种卷积核的数量为60,共180个卷积核。模型训练的参数设置,迭代次数为10 次,批次大小设置为32,学习率为1e-5,优化器Adam,为防止过拟合dropout设置为0.5,序列长度设置为100。
4.3 结果及分析
实验采用准确率、F1 值作为模型的评价标准,并设置了3 组对比实验来验证本文模型的有效性。准确率和F1值的计算如下:
其中m为预测正确样本数目;M为参加预测的样本总数目;precision为精度;recall为召回率。
4.3.1 词嵌入方法对比实验
为了验证BERT 模型具有更好的向量表征能力,实验将本文模型Word2Vec-BiGRU-Attention-CNN 模型在相同的实验环境下对4 种中文数据集进行对比实验。实验迭代10 次的训练过程如图3所示。

图3 词嵌入方法对比实验
从图3 可以看出,在使用相同的BiGRU-Attention-CNN 模型进行特征提取的情况下,在四种数据集上迭代的结果BERT 明显优于Word2Vec。BERT 在前6 次迭代准确率属于上升趋势,后四次迭代逐渐达到平滑,而Word2Vec 在迭代10 次下整体趋近于平滑。分析原因,Word2Vec 是将词典中所有的词映射到空间向量来表示,对模型训练准确率达到稳定较快;而BERT 是采用双向的Transformer 编码器对输入的文本进行预训练,动态词向量的表征是逐渐变丰富。
4.3.2 注意力机制影响实验
为了说明引入注意力机制对本文模型的有效性和优化作用,将本文模型与不引入注意力机制的模型在相同的实验环境下对四种中文数据集进行分析对比实验,实验结果如图4所示。
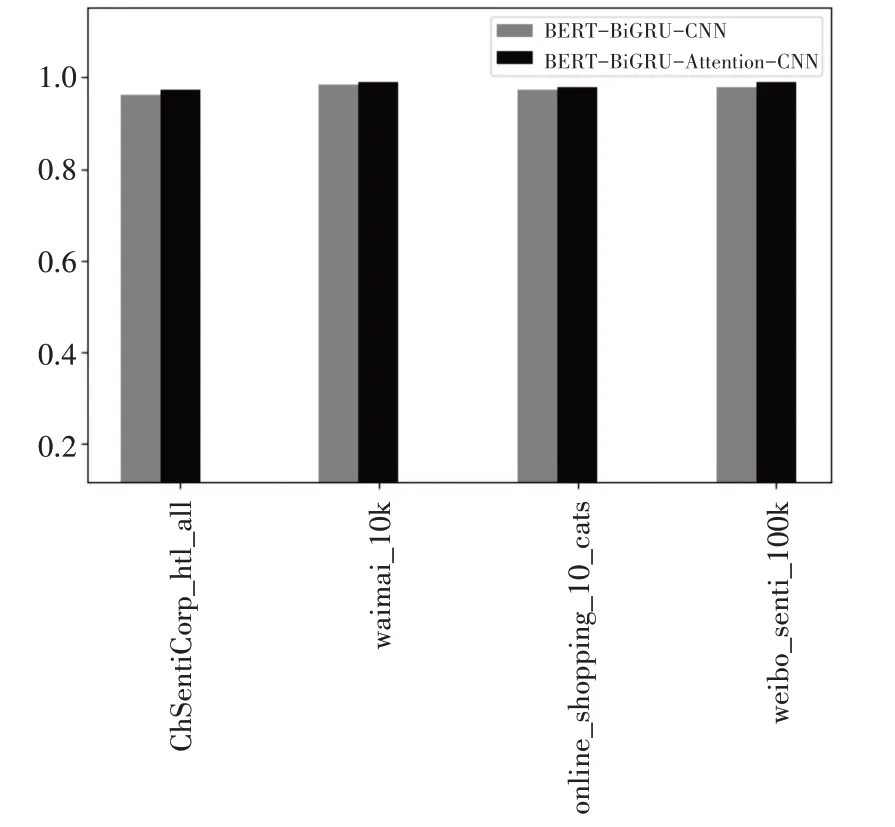
图4 注意力机制影响实验
从图4 中对比可以看出,相比没采用Attention机制的模型,引入Attention机制后模型的准确率有不错的提升。在ChSentiCorp_htl_all、waimai_10k、online_shopping_10_cats 和weibo_senti_100k 在 四种中文数据集上准确率分别提升0.95%、0.37%、0.49%、1%,验证融入Attention机制的有效性。
4.3.3 有效性对比实验
通过对四种中文数据集进行情感分析,将本文模型与基于BERT 下的几种常见模型在相同的实验环境下进行对比分析,采用Accuracy 和F1 值作为评价指标,来验证本文模型的有效性,实验结果如表3、表4所示。

表3 不同模型的准确率对比(单位%)
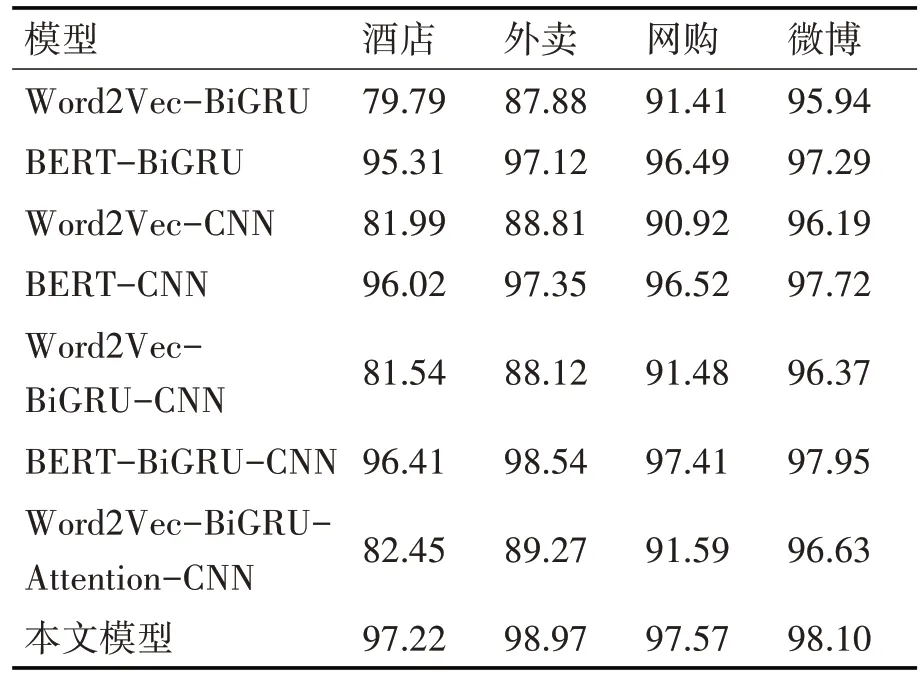
表4 不同模型的F1值对比(单位%)
由表3、表4可以看出,本文模型在四种数据集上准确率和F1 值的表现均优于其他模型。对比BERT-BiGRU-CNN 与BERT-BiGRU 可以看出,准确率平均提高0.85%,说明CNN 层有较好的特征提取能力,能在一定程度上提高模型的特征提取。对比BERT-BiGRU-CNN 与BERT-CNN 可以看出,准确率平均提高0.67%,说明BiGRU 层能提升模型对上下文的依赖,获取向量更深层次的表达。对比本文模型与BERT-BiGRU-CNN 可以看出,准确率平均提高0.45%,说明Attention 层能强化重要的特征信息,促进模型特征提取能力。综上,本文模型正是融合各层的优点所提出,对比各模型的性能,本文所提出的BERT-BiGRU-Attention-CNN 混合模型性能更优。
5 结语
针对现有中文情感分析普遍采用one-hot编码或Word2Vec 方法生成词向量,无法解决一词多义的问题,且未能考虑文本中的关键信息权重的问题。本文提出一种基于BERT 的BiGRU-Attention-CNN 的中文情感分析方法。该模型首选使用BERT 生成丰富信息的动态词向量,然后通过BiGRU层结合上下文信息获取动态词向量的更深层次的表示,融合Attention 机制强化重要的词向量,再采用CNN 层进行特征提取,最后通过Softmax 进行情感极性分类。实验结果表明,相比Word2Vec 方法,BERT 模型具有更好的表征能力,且引入Attention 机制的混合模型相比传统深度学习模型准确率更优。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2018年19期)2018-11-14
中国交通信息化(2018年5期)2018-08-21
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
噪声与振动控制(2015年4期)2015-01-01
