
基于多层注意力机制的口罩佩戴检测算法改进∗
2024-01-29 02:23陈冠宇钟海莲
电子器件 2023年6期
周 蕾,陈冠宇,钟海莲
(1.淮阴工学院计算机与软件工程学院,江苏 淮安 223003;2.淮阴工学院化学工程学院,江苏 淮安 223003)
当今全球传染病流行趋势上升,人们佩戴口罩已经成为一种常见的行为,人们自觉佩戴好口罩可以有效保护自身健康安全,减少被病毒感染机会。目前,用于口罩自动检测的方法主要是浅层学习算法(如支持向量机和浅层神经网络)和深度学习算法,浅层学习算法特征提取能力有限,对小目标检测精度低[1]。基于深度学习的目标检测方法是当前研究的主流方法,主要分为一阶段(one-stage)算法和两阶段(twostage)算法[2]。两阶段算法典型代表有R-CNN、Fast R-CNN、Faster R-CNN,具有准确率高,检测时间长的特点;一阶段算法的典型代表有YOLO 系列和SSD 算法,相比两阶段算法,虽然精度会受一点影响,但运行速度快,可以满足实际应用需求。
目前口罩佩戴检测算法在公共卫生、安全、出行等方面应用广泛,且取得了较好的检测效果。比如在公共场所、交通枢纽等人员聚集的地方,通过口罩检测算法检测出未佩戴口罩的人员,有助于加强疫情防控;在企事业单位、学校等场所,通过口罩检测算法检测出未佩戴口罩的人员,有助于管理人员进出;在公共交通工具上,通过口罩检测算法检测出未佩戴口罩的乘客,有助于加强交通出行的安全保障。
1 相关工作
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,它利用卷积运算对输入数据进行过滤,可以提取与识别视觉特征,常用于计算机视觉和自然语言处理等领域。目标检测是计算机视觉的一个重要任务,代表算法有:①R-CNN(Region-based Convolutional Neural Networks)系列算法[3],通过先提取候选区域,然后对每个候选区域进行分类和回归来检测图像中的目标;②SSD(Single Shot MultiBox Detector)算法[4],使用一个单独的深度神经网络模型来直接预测目标的类别和位置,通过多层特征融合来检测不同大小的目标;③RetinaNet:通过引入Focal Loss 和ResNet 等技术,解决了在大规模目标检测任务中正负样本不平衡的问题,提高了检测性能;④YOLO(You Only Look Once)系列算法[5],使用一个单独的深度神经网络模型来直接预测目标的类别和位置。
目前有很多学者对口罩识别目标检测算法开展了相关研究工作。Singh 等[6]使用了两种不同的网络,即YOLOv3 和Faster R-CNN,进行人脸口罩佩戴检测,该模型使用计算机视觉技术实现自动化检测,无需人工干预,但对于不同的场景和光照条件,模型的鲁棒性有待进一步提高;Nagrath 等[7]提出了一种名为SSDMNV2 的模型用来实现人脸口罩佩戴检测,该模型实验了不同卷积神经网络作为主干网络的SSD 模型的性能,同时用轻量级网络MobileNetV2进行分类预测,使得模型具有较小的体积和内存占用,适合移动设备上的实时应用,可以在保持高准确率的情况下具有较快的检测速度,但是在一些复杂场景下可能会存在漏检和误检的情况,需要进行进一步优化和改进;Jiang 等[8]提出了SE-YOLOv3 人脸口罩佩戴检测器,通过在DarkNet53 中引入SE 模块整合通道之间的关系,使网络关注更重要的特征,同时采用更能描述预测框与真实框差异的GIOU 损失,以提高边框回归的稳定性。相对于一些轻量级算法,SE-YOLOv3 的计算量和参数量较大,需要更高的计算资源和更大的存储空间;Yu 等[9]提出了一种基于改进YOLOv4 的人脸口罩佩戴检测算法,该算法使用改进的CSPDarkNet53 网络来降低网络计算成本,提高网络学习能力,使用自适应图片缩放算法减少计算量,引入改进的PANet 结构使网络获得更多的语义特征信息;Wu 等[10]提出了一种新的口罩检测框架FMD-YOLO,采用Im-ResNet-101 网络作为主干特征提取网络,该网络包含了层次卷积结构,变形卷积和非局部机制,能够最大化地提取特征,使用增强的路径聚合网络En-PAN 使高层语义信息和低层细节信息充分融合,提高网络的鲁棒性,同时在推理阶段采用Matric NMS 方法提高了检测效率和准确性。
以上研究者提出的算法在一般场景下已经有了较好的检测效果,但对于小目标检测场景下的精度还有待提高。针对上述问题,本文提出了一种改进YOLOX 的口罩佩戴检测方法,该方法通过在算法中添加多层注意力机制,采用DIoU(Distance-IoU)损失函数和DW 卷积使模型达到更好的效果。
2 YOLOX 目标检测算法
YOLOX 是一个基于YOLOv3 改进的目标检测算法,由Megvii AI 团队于2021 年提出。YOLOX 通过改进网络结构、损失函数和数据增强等方面来提升检测精度和速度,并实现了高效的多尺度特征融合,从而适用于多种复杂场景下的目标检测任务。
YOLOX 使用的主干特征提取网络为CSPDarknet[11]。CSPDarkNet 网络在YOLOV4 中首先提出,整个网络由残差卷积构成,通过增加深度,使用跳跃连接,来提高准确率,缓解深度增加带来的梯度消失问题。
CSPDarkNet 使用CSPNet 网络结构将原来的残差块(如图1(a)所示)拆分成两部分,一部分继续进行原来残差块的堆叠,另一部分则像一个残差边一样,经过少量处理直接连接到最后,如图1(b)所示。
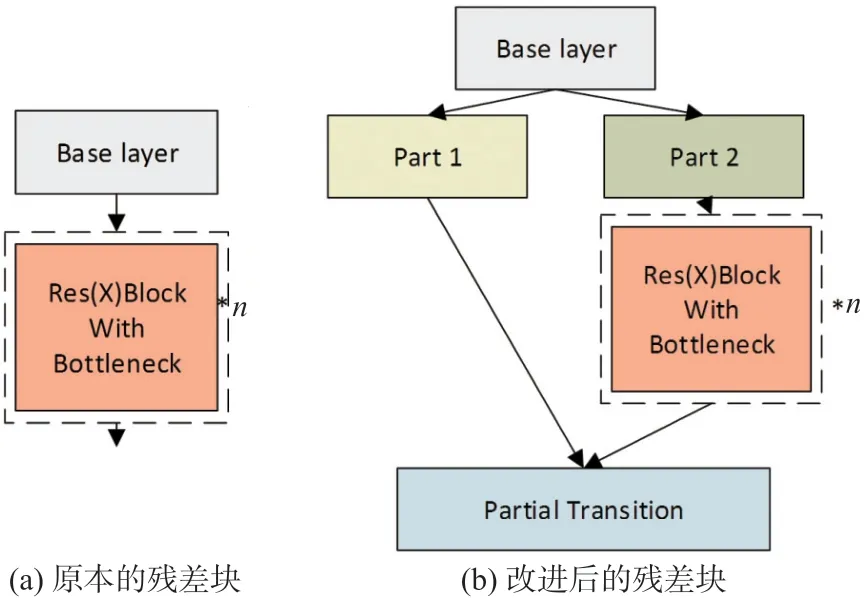
图1 CSPnet 网络结构
CSPNet 网络结构的引入可以在减少模型计算量和提高运行速度的同时,不降低模型的精度。
CSPDarkNet 使用Focus 结构对检测图片进行切片操作来减少参数,提高速度。具体操作为:在一张图片中每隔一个像素取一个值,从而获得了四个独立的特征层,然后进行拼接,这样通道数就扩充为原来的四倍,原图片从原来的RGB 三通道数变为十二通道数,然后将新图片用于接下来的卷积操作,具体结构如图2 所示。
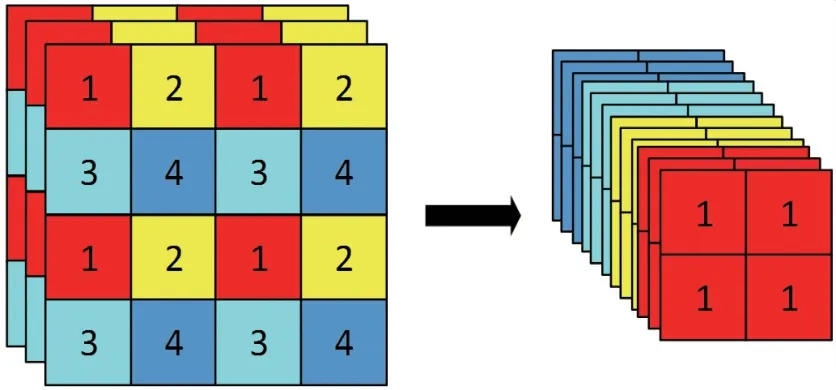
图2 Focus 网络结构
为了提高网络的感受野,在主干网络中还用到了SPP 模块,主要通过不同大小的卷积核进行最大池化操作。另外,该网络的激活函数选取了SiLU 激活函数,该激活函数具有平滑和非单调的特点,具体公式为:
YOLOX 的主干网络结构如图3 所示,可以看出,网络从CSPDarkNet 的中间层、中下层、底层的各个位置提取到了三个有效特征层作为构建特征加强网络FPN 的输入。在FPN 部分,为了进一步加强提取有效特征,YOLOX 算法从结合不同尺度的特征层入手,通过使用PANet 结构,将前面获得的有效特征层通过上采样和下采样来实现特征融合,最终得到特征加强网络输出的三个有效特征层。

图3 YOLOX 网络结构图
YOLOX 在速度和精度上都表现优异,在实际应用中得到了广泛的应用。在COCO 数据集上,其mAP 在YOLOv5 的基础上提升了3 个点以上,同时运行速度也比较快,可以达到实时检测的要求。
3 多层注意力机制
Swin Transformer[12]是一种基于注意力机制的神经网络模型,它在计算机视觉任务中取得了很好的性能表现,特别是在图像分类、目标检测和语义分割等方面。Swin Transformer 中的注意力机制与传统的注意力机制有些不同,但是仍然属于注意力机制的范畴。
3.1 传统注意力机制
传统的注意力机制通过将输入的Query、Key、Value 向量分别进行矩阵乘法,并使用softmax 函数将乘积矩阵进行归一化,得到每个Query 向量对所有Key 向量的加权和作为输出,本质是通过计算一个关注度得分,来决定每个位置对于整体的重要性。
传统注意力机制可以实现对输入序列的全局建模,但计算复杂度较高,每个Query 向量需要计算与所有Key 向量的相似度,并根据相似度权重对Value向量进行加权汇聚。这种方法的计算复杂度为O(N2),其中N为输入向量的长度。当输入向量很长时,计算复杂度将非常高,导致模型运算速度缓慢。
3.2 Swin Transformer 中的注意力机制
Swin Transformer 中同时使用了窗口多头注意力模块(Windows Multi-head Self-Attention,W-MSA)和移动窗口多头力模块(Shift Windows Multi-head Self-Attention,SW-MSA),图4 为两个连续的Swin Transformer 模块结构。

图4 两个连续的Swin Transformer 模块结构
由图4 可知,Swin Transformer 模块由正则化层、多头自注意力、前馈网络层和残差连接组成。其中左边使用的是W-MSA,右边使用SW-MSA。模块首先将输入的图片进行Layer Normalization(LN)正则化,主要作用是进行批量正则化处理,对输入数据进行归一化处理,从而保证输入层数据分布的规则性,随后进入W-MSA 模块,将输入图片拆分成多个窗口,在每个窗口内进行注意力计算,最后将不同窗口的注意力矩阵拼接在一起,形成最终的注意力矩阵;接下来再经过LN 正则化之后进入SW-MSA 模块,采用移动窗口的方式进行注意力计算。
W-MSA 模块和SW-MSA 模块对于注意力计算的方式比较如图5 所示。

图5 W-MSA 和SW-MSA 计算注意力方式对比
图5 左边为W-MSA 模块,该模块相较于传统MSA 而言,是将所有的像素划分为多个窗口,然后在窗口内部计算每个像素与其他像素的相关性,每个窗口内的特征仅能与该窗口内的其他特征进行相似度计算并进行加权,这种方法的优点是可以显著降低计算量,但缺点也很明显,缺少窗口间的信息交互,使得仅使用窗口自注意力层来构建网络时,特征提取能力较差,导致最终的特征提取效果下降。为了克服这一限制,Swin Transformer 提出了SW-MSA。图5 右侧图片是左图向右向下移动两个单位后的结果,这时窗口之间具有重叠部分,基于移动后的窗口可以重新计算注意力,使相邻特征可以计算相似度并完成信息关联,从而实现了窗口与窗口之间的交互[13]。SW-MSA 的窗口移动机制能够帮助网络更好地捕捉局部信息和全局信息的关联性,从而提高特征的表达能力。
4 口罩佩戴检测改进算法YOLO-l-sd
YOLOX 算法目前有多个版本,它们的区别主要在于模型大小和检测精度之间的权衡。本文在YOLOX-l 算法上进行改进,相较其他版本,YOLOX-l的参数量多,因此精度也更高。具体改进包括:①在CSPDarkNet 主干网络中加入Swin Transformer 网络结构,利用注意力机制优化网络结构,提高特征提取效果。②将BN(Batch Normal)修改为LN(Layer Normal),优化计算量,提升了数据处理效果。③替换普通卷积为DW 卷积,DW 卷积所使用的参数量相对较少,可以有效提升网络的计算速度。
改进后的网络图如图6 所示。

图6 特征网络改进
4.1 骨干网络修改
YOLOX 所使用的主干特征提取网络为CSPDarkNet53,通过在骨干网络多个stage 中使用残差连接以及通道分割来提高网络的效率和准确性。CSPDarkNet53 的骨干网络包含5 个stage,每个stage 包含若干个CSPBlock。每个CSPBlock 又包含基础卷积层、空间金字塔池化(Spatial Pyramid Pooling,SPP)层以及残差连接。SPP 层可以在不增加计算量的情况下提取多尺度的特征,可以从不同尺度的特征图中提取特征,通过不同池化核大小的最大池化进行特征提取,来提高网络的感受野。由于检测任务需要利用多尺度信息,因此对SPP 结构进行了保留。
本文使用Swin Transformer 的有效特征层对YOLOX 的主干网络进行修改,将YOLOX 中的CSPBlock 替换为Swin Transformer Block,进一步提升网络的提取效果。Swin Transformer Block 利用自注意力机制在特征之间进行关联和交互,能够更好地捕捉特征之间的关系,进而提高特征表达能力,从而提高检测的准确性。此外,还在SPP 之后加入SW-MSA注意力机制来提升特征的表达能力和区分度。具体改进如图7 所示。
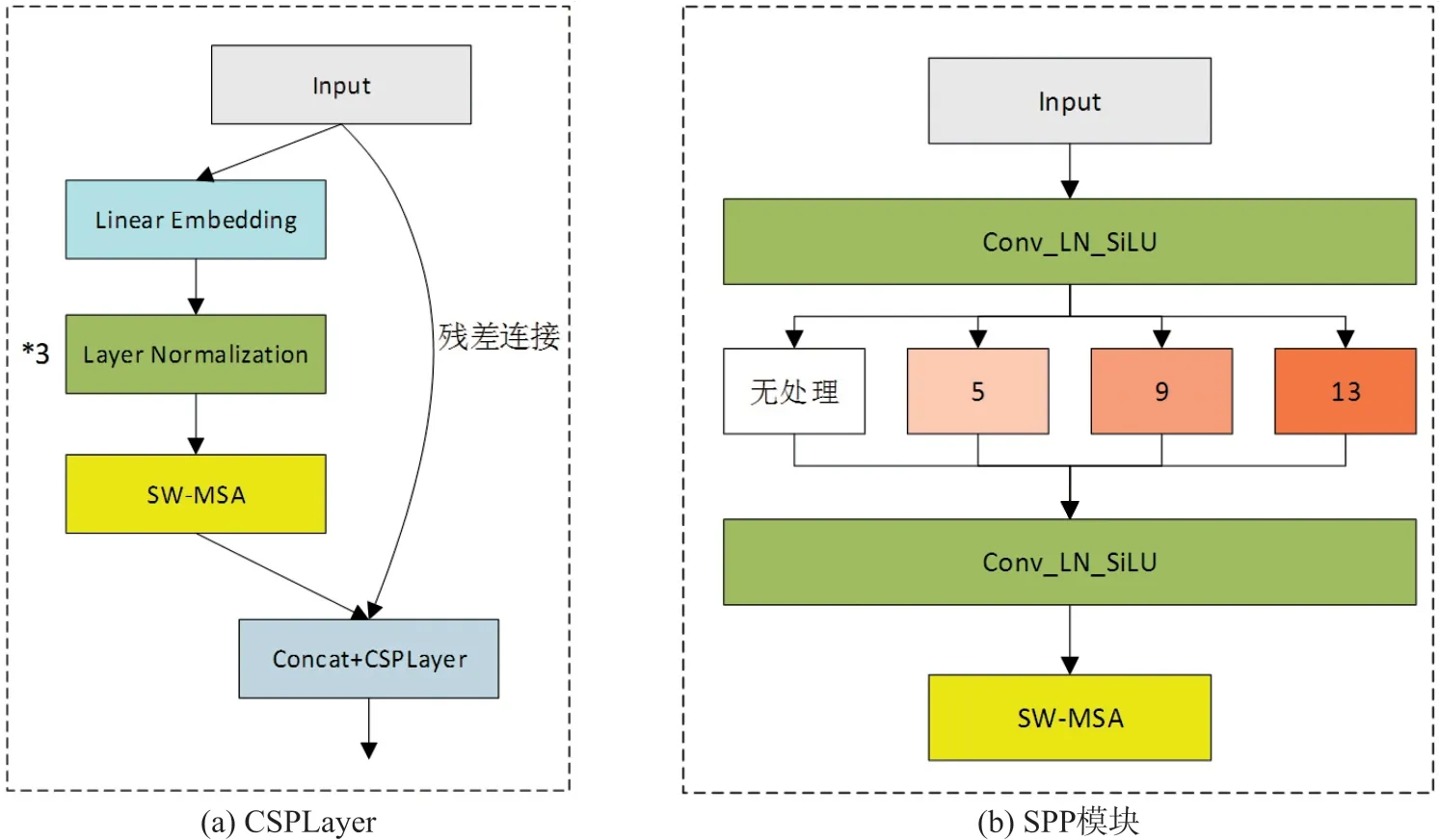
图7 对骨干网络的主要改进图
①图7(a)是CSPLayer 结构,其将输入的特征图分为两个分支,左边的分支经过LN 正则化进行标准化处理,再通过SW-MSA 注意力机制更好地提取特征,最后将两个分支合并输出到下一分支网络。②图7(b)为SPP 模块,用来增加网络的感受野,结构中同样增加了SW-MSA 注意力模块。首先将输入的特征层进行基础卷积,然后分别通过5×5,9×9,13×13 全局平均池化三个分支和一个不变分支,再将四个分支的结果相加后进行卷积,在SPP 与特征融合最后结果的特征层后面加上SW-MSA 注意力机制,提高特征提取效果,减少计算量。
4.2 修改正则化方法
BN 是一种在深度学习中常用的技术,主要用于神经网络的训练,可以将输入数据的分布进行归一化,从而加速训练过程并提高模型的泛化能力。BN 是对神经网络的每一层输入数据分布的均值和方差进行归一化处理。具体来说,对于一个输入数据,先计算该batch 的均值和方差,再用这些统计值对数据进行归一化。这样可以使数据分布更加平均,从而提高训练速度和模型的稳定性,避免梯度爆炸和梯度消失的问题。但BN 存在一些缺点,例如对小批量数据的效果不好,因为小批量数据的均值和方差统计可能会出现偏差。此外,BN 会增加计算量,特别是在大型神经网络中,计算代价可能会很高。
LN 是一种用于深度学习中的正则化方法,它类似于BN,但不是在小批量上进行归一化,而是对每个样本单独进行归一化。在LN 中,假设一个张量x∈Rm×n,包括m个样本,每个样本n个特征,对于每个样本xi,LN 将它的所有特征维度按照均值和方差进行归一化,公式如下:
式中:μi和σi分别表示样本xi在所有特征维度上的均值和方差,ε是一个很小的常数,用于避免分母为0。
由于BN 的一个缺点是需要较大的batch size才能合理预估训练数据的均值和方差,本文选用参数量较大的YOLOX-l 模型,采用BN 可能会导致内存不足,而LN 不依赖于batch 的大小和输入sequence 的深度,更为适合该模型。
4.3 采用DW 卷积
DW 卷积(Depthwise Convolution)是一种深度可分离卷积的变种卷积操作,通常用于深度学习模型的轻量化或加速,在减少模型参数和计算量的同时,提高模型的感受野和学习能力。DW 卷积的计算过程可以分为深度卷积和逐点卷积两个部分。在深度卷积中,DW 卷积首先对输入数据的每个通道分别进行卷积,即针对每个通道都使用一个卷积核进行卷积操作。因此,如果输入数据共有C个通道,那么深度卷积部分会使用C个卷积核进行卷积。这个过程可以看做是对每个通道进行一维卷积操作。在逐点卷积中,DW 卷积使用一个1×1 的卷积核对每个通道的结果进行融合,即将所有通道的结果按元素相加并得到一个新的输出结果。这个过程可以看做是对每个通道进行一维逐点卷积操作。
与普通卷积相比,DW 卷积的卷积核只在每个输入通道上进行卷积操作,因此参数数量远远少于普通卷积;DW 卷积具有更少的卷积核数量和更小的卷积核大小,因此需要更少的计算量。将普通卷积替换为DW 卷积,可以在保持参数和计算量较少的情况下,达到与普通卷积相似或更好的准确率。
4.4 损失函数的选择
损失函数主要用于度量预测框与真实框之间的差异,以此优化模型的参数。选择不同的损失函数会影响网络模型预测框的精度,以下介绍两种改良的损失函数。
①完全交并比(Complete Intersection Over Union,CIOU)
CIOU 是一种改进的IOU。IOU 用于计算预测框和真实框的交叠率,即它们的交集和并集的比值,最理想情况是完全重叠,这时比值为1。IOU 的计算公式为:
式中:A表示预测框,B表示真实框,A∩B表示A和B的交集,A∪B表示A和B的并集。
CIOU 还考虑了目标框的长宽比例和中心点之间的距离,在某些情况下比IOU 更加准确。CIOU的计算公式为:
式中:IOU 表示两个边界框的交并比,ρ是一个惩罚项,用于惩罚边界框中心点之间的距离,C1和C2分别表示两个边界框的对角线长度,¯C表示这两个对角线长度的平均值。
②距离交并比(Distance Intersection Over Union,DIOU)
DIOU 也是一种改进的IOU 方法,它在CIOU 的基础上增加了重叠部分的面积惩罚项,以进一步提高预测框与真实框之间重叠度的准确性。DIOU 的计算公式为:
式中:d代表预测框和真实框两个中心点距离的平方,c代表两个框的最小外接矩形对角线长度。如果两个框完美重叠,d=0,IOU =1,DIOU =1-0 =1。如果两个框相距很远,趋近于1,IOU =0,DIOU =0-1 =-1。
5 实验与结论
5.1 实验环境
本文所述实验均在Windows10 操作系统下进行。环境配置为python3.6.13,torch1.2.0,torchvision0.4.0,硬件环境为RTX 2080 Ti(11GB)×1,4 vCPU Intel(R)Xeon(R)Silver 4110 CPU@2.10GHz,16GB 内存。
5.2 数据集
数据集的质量是保证深度学习模型训练结果的重要因素。本文数据集为自制数据集,通过网络爬虫等方法收集网络公开的图片,一共收集了4 050张图片,数据集按照8 ∶1 ∶1 的比例分为训练集、测试集和验证集。数据集包含了多个场景下佩戴口罩的人脸图片,数据集中人脸分辨率最大为1 536×1 876,最小为20×40,涵盖了人脸出现在摄像头拍摄图像中的大多数可能尺寸,保证了网络对小尺度人脸的识别需求。
5.3 评价指标
目标检测的评价指标主要包括精度(Precision),召回率(Recall),平均精度(AP),平均精度均值(mAP)。
①精度
精度是指检测结果中正确检测的目标框数量与所有检测到的目标框数量的比例。即,算法检测出来的所有目标框中,正确框的数量占总检测框数量的比例。精度计算公式为:
式中:TP 为被模型预测为正类的正样本;TN 为被模型预测为负类的负样本;FP 为被模型预测为正类的负样本;FN 为被模型预测为负类的正样本。精度越高,表示算法检测出的目标框中正确率越高,具有更好的检测准确性。
②召回率
召回率是指在所有真实目标框中,被算法正确检测出的目标框的比例。在目标检测任务中,召回率衡量的是算法对于真实目标框的检测能力,即算法能够检测到多少真实目标框。召回率计算公式为:
式中:TP 为被模型预测为正类的正样本;FN 为被模型预测为负类的正样本。召回率越高,表示算法能够检测到更多的真实目标框,具有更好的检测能力。
③平均精度AP
平均精度是评价模型检测能力的主要指标之一。AP 是通过计算不同召回率下的精度值,再将这些精度值在召回率的范围内进行平均得到的一个指标。一般来说,平均精度越高,表示模型的检测效果越好。
平均精度均值是不同类别的平均精度的平均值。对于一个具有n个类别的目标检测模型,其mAP 可以表示为所有类别AP 的平均值:
式中:N表示所有类别数量。
④F1
F1 是精确率和召回率的调和平均值,计算公式如下:
式中:FN 表示预测错误的样本数量;TP 为被模型预测为正类的正样本;FN 为被模型预测为负类的正样本;FP 为被模型预测为正类的负样本。
5.4 损失函数对比分析
CIOU 是一种改进的IOU 损失函数,它通过综合考虑预测框和真实框的中心点、宽度、高度和长宽比等因素来计算损失;DIOU 也是一种改进的IOU损失函数,它通过综合考虑预测框和真实框之间的距离、中心点、宽度、高度和长宽比等因素来计算损失。
为比较使用不同损失函数的模型效果,实验对CIOU 和DIOU 进行了实验,最终的Loss 曲线如图8所示。

图8 不同损失函数Loss 曲线图
图8 中,(a)为CIOU 损失函数图像,(b)为DIOU损失函数图像。由图可知,两种损失函数数值下降速度相仿,(b)图的训练损失与验证损失曲线相比(a)图更加贴合,曲线更加平滑,收敛效果更好,因此选取DIOU 作为本文提出的YOLO-l-sd 模型的损失函数。
5.5 消融实现结果分析
为了验证各个注意力模块对YOLOX-l 检测效果的影响,在数据集上进行消融实验。在损失函数都采用DIOU 的基础上,模型加入SW-MSA 注意力和DW 卷积模块的消融实验,结果如表1 所示。

表1 消融实验结果
对比发现,经过加入DW 卷积后,AP 降低了0.68%,但召回率提升了0.99%,精度提升了1.05%。而加入SW-MSA 注意力机制以后算法相较于原本的算法,AP 提升了0.36%,召回率提升了5.24%,精度提升了0.93%;在SW-MSA 基础上加入DW 卷积后,AP 提高了0.32%,召回率提高了0.22%,精度提升了1.52%。经过综合对比,相较于原始的YOLOX-l,YOLO-l-sd 的AP 提升了0.68%,召回率提升了5.46%,精度提升了2.45%。
①遮挡目标检测效果对比
图9(a)为YOLOX-l 的检测结果,图9(b)为YOLOX-l-sd 的检测结果,可以看出,在遮挡目标检测中,YOLOX-l 出现了漏检,而YOLOX-l-sd 可以正常检出。

图9 遮挡目标检测结果对比
②小目标检测效果对比
图10(a)为YOLOX-l 的检测结果,图10(b)为YOLOX-l-sd 的检测结果,YOLOX-l-sd 算法的检测精度要比原始算法平均提高了3%左右。

图10 小目标检测结果对比
通过对比实验可以看出,文章提出的YOLOX-lsd 算法在召回率、精确率、F1 和mAP 等指标上相比原始算法均有不同程度的提高,对小目标与遮挡目标的检测效果也有了明显的提升。
6 结论
为了提高小目标和遮挡目标场景下口罩佩戴目标检测的效果,文章对YOLOX 算法进行了改进,替换普通卷积为DW 卷积,在CSPDarkNet 主干网络中引入 Swin Transformer 多 层注意力机制,在CSPLayer、SPP 模块中添加SW-MSA 注意力模块,将SPP 模块BN 正则化方法修改为LN,同时采用DIOU 损失函数来提高网络精确度。实验结果表明,文章提出的YOLOX-l-sd 算法有效提升了佩戴口罩目标检测算法的性能,与原始算法相比,模型的检测精度提高了2.45%。在未来的工作中,将继续优化模型,研究佩戴口罩的人脸分类网络,进一步研究密集人群中佩戴口罩人脸识别问题。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
电子制作(2019年11期)2019-07-04
作文大王·笑话大王(2019年3期)2019-04-22
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
