
一种改进的变权科莫多优化算法及其应用
2024-01-29 10:04梁少华李林轩叶青
长江大学学报(自科版) 2024年1期
梁少华,李林轩,叶青
长江大学计算机科学学院,湖北 荆州 434023
自然一直是许多元启发式算法的灵感来源,如进化论中的自然选择是遗传算法[1](genetic algorithm,GA)灵感来源,鸟群觅食过程是粒子群算法[2](particle swarm optimization,PSO)灵感来源等。智能算法已经成功地解决各个领域的问题,包括旅行商问题[3]、最优控制理论[4]、医学图像处理技术[5]等。为解决更加棘手的问题,相关学者相继提出鹰栖息算法[6](eagle perching optimization,EPO)、灰狼算法[7](grey wolf optimization,GWO)、科莫多算法[8](komodo mlipir mlgorithm,KMA)以及各种改进算法和方法,如加入PSO的混合鹰栖息算法[9]、混沌理论[10]、莱维(Levy)飞行[11-12]和动态权值[13]等方法应用于智能算法中。
KMA是2022年1月由SUYANTO等提出的新颖的元启发优化算法,该算法有着遗传算法和粒子群优化算法的诸多优点,可以通过不同阶级个体的运动和繁殖寻找最优值,还提出通过种群自适应[14]来控制局部和全局寻优的平衡,使得KMA收敛速度较快和精度较高,并且在高维函数中具有延展性。但是KMA在复杂函数中仍存在局部收敛的问题。
为了进一步提高KMA的性能,改进KMA在收敛过程中存在的问题,笔者提出了一种改进的变权科莫多优化算法(VWCKMA)。主要创新和意义如下:①引入可变惯性权重因子[15],将科莫多巨蜥的社会阶级都赋予一个随着迭代次数而改变的惯性权重,提升了种群的收敛速度和全局探索的能力;②引入了Tent混沌映射[16]初始化科莫多种群,提高初始化种群位置的质量,丰富了种群的多样性,提高了收敛速度;③利用Tent混沌映射[17]有效调节种群的多样性,帮助算法动态跳出局部最优,提高了收敛精度。
1 科莫多算法
在KMA中,随机生成科莫多种群,根据适应度划分种群为3种不同的社会阶级。通过3种阶级的不同运动,完成最后寻优的过程。其中大型雄性的运动行为用数学模型描述如下:
(1)
(2)

小型雄性的运动通过特定的概率随机选择一部分去靠近大型雄性,用数学模型描述如下:
(3)
(4)
2 改进科莫多算法以及算法流程
2.1 Tent混沌映射初始化粒子位置
目前大多数算法采用随机初始化粒子的方式来表示,但是这容易造成个体集中在某一区域,分布不均衡。混沌序列具有内在随机性和空间遍历性,能够在一定的空间范围内不重复的无规律遍历,能有效地避免局部最优解,实现全局优化。李兵等[18]将混沌理论应用于群智能算法的优化中,发现其优化效率高于一般随机算法。
Tent混沌映射具有简单的结构,同时迭代过程更加适合计算机的运行,并且Tent混沌映射的遍历性更加均匀。单梁等[16]表明了Tent混沌映射的遍历性要比logistic混沌映射[19]更好,因此,采用Tent混沌映射对种群进行初始化,式(5)是Tent混沌映射,其数学表达式为:
(5)
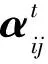
2.2 新增惯性权重策略及雌性运动
为了避免KMA在搜索过程中陷入局部最优值,在KMA中引入了一种新的参数称为惯性权重,用于控制全局探索和局部搜索。对于大型雄性、雌性、小型雄性的运动分别引入不同的惯性权重w1、w2、w3,所有的权重都应该是变化的,并且相加时和为1。即:
w1+w2+w3=1
(6)

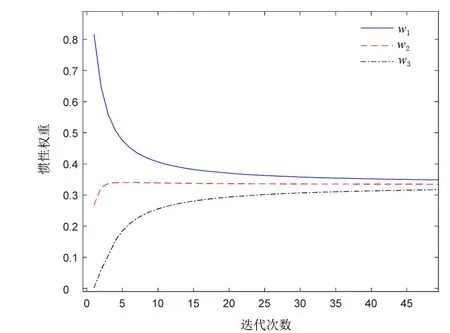
图1 可变权值的迭代图Fig.1 Iterative graph of time-varying weights

(7)

(8)
基于以上这些假设和因素,提出了一种新的可变惯性权重更新方法,定义为:
w1=cosθ
w3=1-w1-w2
(9)
可变惯性权重曲线如图1所示。
将大型雄性运动的数学表达式(1)改进为:
(10)
KMA中雌性只存在有性繁殖或者无性繁殖的行为,根据自然界正常生理活动,新增雌性向大型雄性移动的新运动,其运动的数学表达式为:
(11)

最后,同样对小型雄性的运动增加惯性权重w3,即对式(3)进行改进。则其数学表达式为:
(12)
2.3 新增Tent混沌映射扰动策略
在完成科莫多3种阶级运动后,进行混沌扰动实现局部搜索。使用Tent混沌映射进行扰动,在科莫多个体周围产生一些局部解,然后再与之前的最优解进行比较。具体的Tent混沌映射扰动步骤如下:
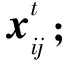
2.4 VWCKMA整体流程
VWCKMA的具体算法流程如图2所示。
步骤1 初始化参数,初始化种群和维度大小,最小和最大的自适应种群规模的大小,最大迭代次数,最大混沌次数,大型雄性的个数;
步骤2 初始化种群,利用Tent混沌映射初始化科莫多个体群的位置;
步骤3 计算科莫多个体的适应度值,利用式(6)~式(9)计算不同社会阶级科莫多的惯性权值;
步骤4 更新位置,根据式(2)和式(10)更新大型雄性的位置,式(11)更新雌性的位置,式(4)和式(12)更新小型雄性的位置;
步骤5 使用式(5)进行Tent混沌映射扰动,进行局部搜索。
步骤6 判断是否得到最优解或达到最大的迭代次数,如果是算法搜索结束执行步骤7;否则返回到步骤3;
步骤7 输出最优值信息。

图2 VWCKMA的执行框架Fig.2 Implementation framework of VWCKMA
2.5 改进算法复杂度分析
KMA的时间复杂度为O(n×m×Max_iteration+f(n)+α1)(其中n,m,f(n),α1和Max_iteration分别代表种群中个体的数量,维度,目标函数计算时间,适应度值排序过程的时间和最大迭代次数)VWCKMA时间复杂度分析如下:
1)Tent混沌映射初始化种群的时间复杂化为O(n×m),则引入Tent混沌映射初始化种群的算法时间复杂度为O(n×m×Max_iteration+f(n)+α1+n×m)=O(n×m×Max_iteration+f(n)+α1)。 2)假设更新时变惯性权重的所需时间为t1,引入时变惯性权重后算法的时间复杂度为O(n×m×Max_iteration+f(n)+α1+t1)=O(n×m×Max_iteration+f(n)+α1)。
3)Tent混沌映射进行扰动的时间复杂度为O(n×m),引用Tent混沌映射进行扰动的算法时间复杂度为O(n×m×Max_iteration+f(n)+α1+n×m)=O(n×m×Max_iteration+f(n)+α1)。
VWCKMA空间复杂度分析如下:加入Tent混沌映射初始化种群和惯性权重的优化策略均在KMA基础上改进,未新增存储空间。加入Tent混沌映射扰动策略后新增的空间复杂度为O(logk)(其中k为最大混沌次数)。与KMA相比略微增加了O(logk),但是在现有计算机硬件水平中O(1)≈O(logk)。
综上所述,相比KMA,笔者提出的VWCKMA没有增加复杂度。
3 仿真实验及分析
3.1 测试函数集
为了综合检验VWCKMA具有效性和优越性,将VWCKMA同时与KMA,GWO算法和PSO算法对8个基准函数进行求解,单峰函数f1(x)~f3(x),多峰函数f4(x)~f8(x),函数信息如表1所示。

表1 基准函数
3.2 实验数据及分析
参数设置相同,VWCKMA与KMA,GWO和PSO算法的迭代次数为200次,最大种群规模为200。在该条件下对30维度、100维度和500维度的8个基准函数独立运行30次,进行寻优计算。计算出各个算法的均值和标准差(见表2)。其中最优者用黑体加下划线标注。为了更加直观地体现VWCKMA的优越性能,在30维度的测试函数中,绘制出部分测试基准函数的收敛曲线图,如图3所示。所涉代码采用MATLAB R2020a软件编写,仿真实验环境为:64位Windows操作系统,CPU型号为Intel Core i7-12700 F,机带RAM为32 GB。

表2 4种算法在8个基准函数上的测试结果

图3 基准函数的收敛曲线Fig.3 Convergence curve of benchmark functions
在同维度和迭代次数的情况下,表2的结果表明:VWCKMA在单峰函数f1(x)~f3(x)中能收敛到函数的理论最优值,其他算法都无法收敛到0。VWCKMA在多峰函数中,f4(x)~f6(x)函数均表现出收敛到函数理论最优值,在f7(x)和f8(x)函数中收敛精度最高。对比结果说明VWCKMA的精度高于KMA、GWO算法和PSO算法。对比500维度情况,f1(x)~f6(x)函数均收敛到函数理论最优值,f7(x)和f8(x)函数收敛精度仍最高,表明VWCKMA在高维情况下仍具有收敛的精准性。图3表明:VWCKMA在f4(x)~f7(x)函数中平均迭代5次便能够快速准确地收敛到最佳值,在f7(x)函数中KMA陷入局部最优值时VWCKMA能有效跳出局部最优值。无论从收敛精度还是速度上都远远高于PSO,GWO和KMA。说明该算法较其他3种元启发算法具有收敛精度更高、速度更快的突出优势。
综上分析所得,VWCKMA与PSO、GWO和KMA比较,无论是在低维度还是高维度,无论在收敛精度还是收敛速度方面,无论是在单峰函数还是多峰函数情况下的寻优计算,VWCKMA都具有明显的优势。同时VWCKMA有较强的全局探索与局部搜索的能力和较快的收敛速度,且对于局部最优解有很强的抵抗性,能够轻易地跳出局部最优解,找到函数的最优值。
4 应用
4.1 对象与方法
将VWCKMA应用在成都市空气污染物PM2.5预测的实际问题中。通过MATLAB进行仿真实验,选择传统的BP神经网络[20]、粒子群优化神经网络[21](PSO-BP)、科莫多优化神经网络(KMA-BP),以及改进科莫多优化神经网络(VWCKMA-BP)4种模型分别对成都市空气污染物PM2.5进行预测。为了公平性,4种预测模型的参数设定一致,参数设定如下:BP神经网络的结构为5-10-5-1,输入层到隐藏层之间的传递函数为Tansig函数,隐藏层到输出层之间的传递函数为Poslin函数,学习率设置为0.4。样本数据的选取来自于中国空气质量在线监测分析平台(https://www.aqistudy.cn),选取成都市2020年1月1日至2022年6月30日一共912条数据进行实验。具体数据包括日期、AQI、质量等级、PM2.5、PM10、CO、NO2、SO2、O3。数据简况见表3,由于篇幅有限列举一部分数据。
评价指标在选取PM2.5的实际值和真实值的比较基础上,再引入了平均相对误差(EMR),平均相对误差均方误差EMS,平均绝对误差EMA,均方根误差ERMS和预测准确率Pacc进行全方位的比较预测精度。预测模型都采用均方误差函数作为算法的适应度函数,5个指标的数学定义分为:
(16)
(17)
(18)
(19)
(20)
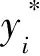

表3 原始数据样本
4.2 结果分析
在2020年1月1日至2022年6月30日的912条数据中选择70%为训练集,30%为测试集。4种预测模型的预测值与真实值的对比结果如图4所示。VWCKMA-BP模型的预测值与真实值的比较结果如图5所示。从图5可清晰看出,VWCKMA-BP模型更加接近真实值,通过VWCKMA使得寻优精度得到有效提升。
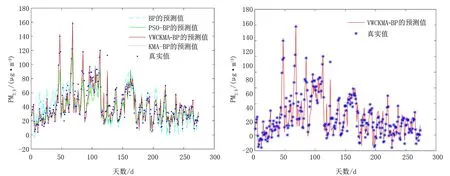
图4 PM2.5的预测值和真实值对比图5 VWCKMA-BP的预测值和真实值对比Fig.4 Comparison of predicted and true Fig.5 Comparison of predicted and true values PM2.5 values of VWCKMA-BP
表4为4种预测模型在测试集上的EMR、EMS、EMA、ERMS和Pacc这5个指标的统计结果。从表4中可以看出不同优化策略对BP神经网络的预测有较大的影响,VWCKMA-BP模型准确率达到85.085%。4种模型只有VWCKMA-BP模型使得平均绝对误差低于6 μg/m3,均方根误差低于60 μg/m3,均方误差低于15%。改进算法在迭代次数上也有进一步的提升,KMA、PSO和VWCKMA的对比收敛曲线如图6所示,VWCKMA的初始适应度值均优于其他两种算法,这是Tent混沌映射初始化种群的结果。在迭代30次左右时,VWCKMA的函数适应度接近收敛值,其他算法适应度值均大于VWCKMA。以上结果表明VWCKMA-BP模型在预测空气污染物PM2.5指标上有效可行。

表4 不同模型的指标统计结果对比
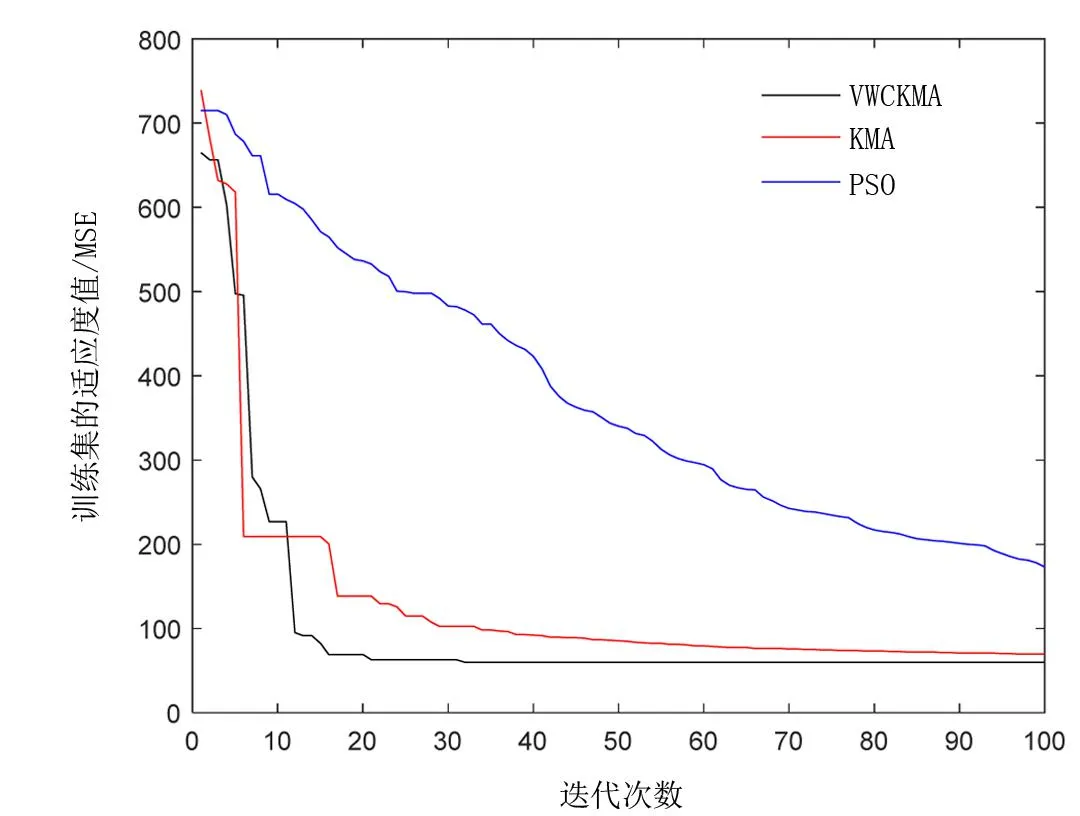
图6 不同算法迭代收敛曲线对比Fig.6 Comparison of iterative convergence curves of different algorithms
5 结论
1)为进一步提高KMA性能,改进KMA在收敛过程中存在的问题,笔者提出根据随迭代次数变化的惯性权值策略,提高收敛速度;利用Tent混沌映射初始化种群,保证种群多样性,提高收敛速度;针对KMA易陷入局部最优解的问题,采用Tent混沌映射能够有效跳出局部最优解,更加精确地对最优解进行搜索。
2)在仿真实验中,将VWCKMA与PSO、GWO、KMA进行比较,选择了8个不同性质的基准函数进行函数优化的实验。实验表明VWCKMA在函数寻优的收敛精度与速度方面具有突出优势。
3)在实际应用中,使用VWCKMA-BP、PSO-BP、KMA-BP和BP神经网络进行空气污染物PM2.5的实际预测,实验表明VWCKMA-BP模型预测准确率在4种模型中最高,达到85.085%,相比BP神经网络预测准确率提高19.85个百分点。说明VWCKMA在函数优化以及实际优化问题方面的性能得到了显著提高。后续可将VWCKMA尝试应用于多目标优化解析中。
猜你喜欢
中学生数理化·八年级物理人教版(2023年3期)2023-03-21
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
小学生(看图说画)(2020年11期)2020-11-11
小哥白尼(野生动物)(2020年4期)2020-07-27
中国惯性技术学报(2019年6期)2019-03-04
故事作文·高年级(2018年10期)2018-10-25
小哥白尼(野生动物)(2018年5期)2018-06-15
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
小学科学(学生版)(2016年1期)2016-10-09
