
不同分级方法对区域滑坡易发性区划的影响
2024-02-02 09:29黄发明张崟琅郭子正范宣梅周创兵
工程科学与技术 2024年1期
黄发明,张崟琅,郭子正,范宣梅,周创兵
(1.南昌大学工程建设学院,江西南昌 330031;2.中国瑞林工程技术股份有限公司,江西南昌 330031;3.河北工业大学土木与交通学院,天津 300401;4.成都理工大学地质灾害防治与地质环境保护国家重点实验室,四川成都 610059)
作为中国最为严重的地质灾害类型之一,滑坡会给人民生命财产安全造成巨大威胁[1–2]。在常规的滑坡风险普查和分区工作中,区域易发性预测的结果能够揭示空间中潜在滑坡发育的地带,已经成为目前减少和缓解滑坡风险过程中的一个重要步骤[3]。
大量学者关注区域尺度的滑坡易发性预测,但现有研究大多集中于预测模型的开发和对比,主要包括启发式、确定性和数据驱动模型3类[4–6]。其中,因启发式模型需要丰富的专家经验,这些经验是基于其在野外对地形等地质条件的观察和主观判断[7];确定性模型通常需要多个岩土力学和水文参数,但这些参数在区域尺度上不易获得且存在空间变异性[8–9]。因此,前两种模型都具有较明显的局限性,与之相比,数据驱动模型在理论基础和实际应用中都具有优势,这类模型通常基于假设,即未来的滑坡将会发生在与过去的滑坡发生条件类似的地质环境中[5,10]。机器学习是数据驱动模型中的一个重要分支,近年模型对比研究[11–13]表明,机器学习模型能够很好地识别评价因子和滑坡之间的非线性关系,从而获得较为精确的区域滑坡易发性分区图。
基于机器学习的滑坡易发性建模包括如下步骤:选取环境因子,分析滑坡与各因子间的统计规律,模型训练和测试,预测滑坡易发性,采用合理的分级方法进行易发性制图,建模结果评价和验证[14]。选择正确的模型能确保预测出较为准确的滑坡易发性指数,并需要合理的分级方法,实现滑坡易发性分级制图。现有分级主要采用GIS平台的自然断点法、等间隔法、分位数法和几何间隔法等[15–16]。这些方法由于能够在GIS软件中轻松实现而被广泛使用,但也存在一定局限性,如自然断点法在易发性指数集存在明显突变时才更有效,易发性制图会随着断点的主观变化而发生较大变化[17];等间隔法具有截止依赖性;分位数法受易发性指数分布影响较大,如果易发性指数分布不均匀,将导致分析结果产生偏差。针对这些问题,有学者提出了其他的分级方法。如Pradhan[11]认为可将全部滑坡易发性指数按照一定的面积比例分为极高(10%)、高(20%)、中(40%)、低(20%)和极低(10%)易发区,类似的分级思想也体现在了郭子正等[18]的研究工作。Cantrino等[19]提出了一种基于ROC曲线的方法来确定易发性等级的阈值,该方法可从地形特征中提取信息且包含了“错误分级”概念,能够产生更具同质性和稳定性的易发性分级结果。杨永刚等[20]提出使用聚类方法进行易发性指数级别的划分,该方法不基于GIS而使用自动聚类算法且取得了良好的实际应用效果[21]。总体而言,目前缺乏滑坡易发性分级方法的系统性研究,并且几乎所有分级方法都仅仅是从滑坡易发性指数分布特征出发,而没有综合考虑已知滑坡空间分布特征及其与滑坡易发性指数之间的非线性相关。
鉴于此,本文以陕西省延长县作为研究区,选取3种机器学习模型预测滑坡易发性,使用4种基于GIS的常规易发性分级方法(自然断点法、等间隔法、分位数法、几何间隔)以及频率比阈值法进行滑坡易发性分级制图。具体研究目标包括:1) 揭示3种基于不同软件的机器学习模型预测滑坡易发性的优缺点;2)探明4种常规分级法以及频率比阈值法对滑坡易发性分级的准确性,以揭示分级方法对易发性制图的影响规律。
1 滑坡易发性预测及其分级方法
1.1 滑坡易发性建模
本文分别基于SPSS Modeler构建分类和回归树(C&RT)模型、基于SPSS软件构建RBF模型并用R语言编程实现随机森林(RF)模型。整个易发性建模中除模型外的其余步骤均一致,具体建模流程如图1所示。
1)选取合适的滑坡—非滑坡样本。用全部滑坡样本以及在剔除滑坡样本后的全区样本中随机选取等量的非滑坡样本作为模型输出变量,以便为机器学习建模提供历史滑坡及其分布特征的学习样本。
2)提取滑坡相关的12个环境因子。计算每个因子频率比(FR),作为机器学习模型的输入变量,这样不仅能降低模型复杂度,且FR反映的因子对滑坡的影响也会被包含进模型。
3)将步骤1)、2)的模型输入-输出变量导入机器学习中进行训练和测试,因子对应的FR为输入数据,将该点的滑坡状态(滑坡点为1,非滑坡点为0)作为输出值。输入–输出变量集中的80%被随机划分以用作模型训练,另外20%用作模型测试。
4)使用RF模型分析环境因子的重要性,主要的指标是均值降低精度和平均降低基尼指数。
5)将全区环境因子数据导入训练好的模型中,以预测得到滑坡易发性指数。该值一般处于0~1,值越大,则滑坡的易发性越高。
6)依据不同的分级方法,划分滑坡易发性指数等级,以绘制全区易发性预测图。
7)分别采用ROC曲线法和统计方法评价建模性能,定量计算易发性分区的精度,并揭示不同易发性等级的分布模式及历史滑坡在各等级中的分布特点。将滑坡面转化为栅格单元,栅格的位置组合起来就是滑坡实际发生的位置。滑坡的面积不同,其包含的栅格数也不同。
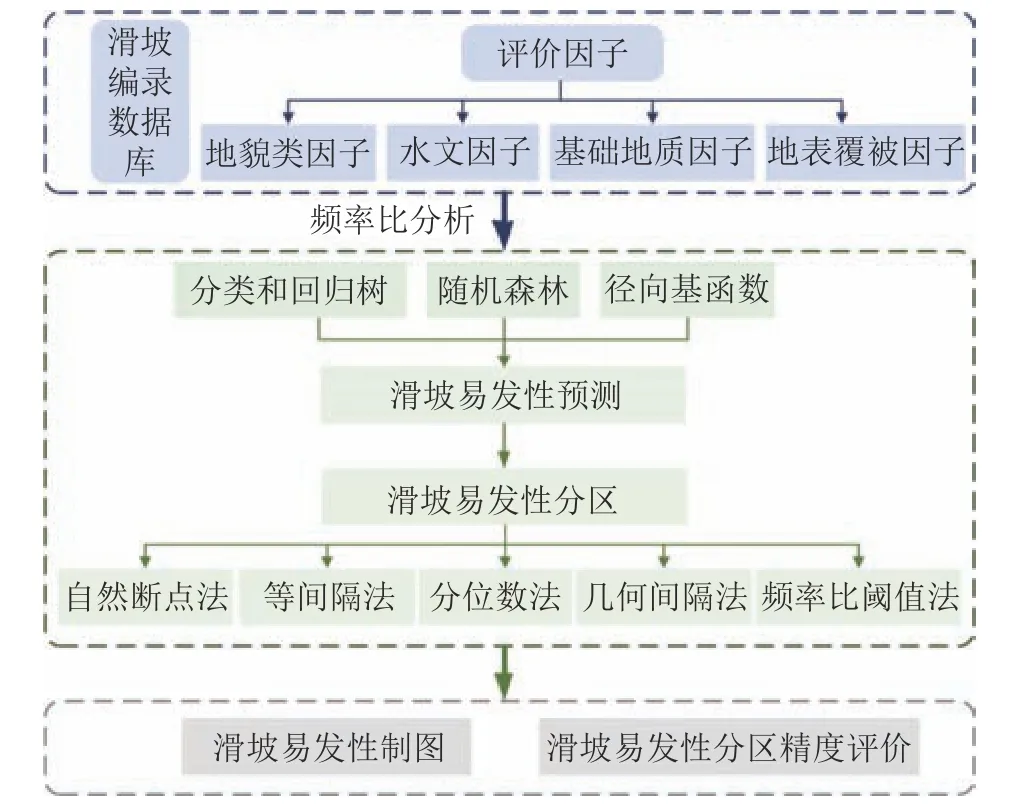
图1 滑坡易发性分级建模流程Fig.1 Modelling flow chat of landslide susceptibility prediction
1.2 环境因子及其与滑坡的非线性关系
基于机器学习模型进行环境因子与历史滑坡的非线性关系分析,统计各环境因子范围值内的滑坡孕育。环境因子频率比方法是实现环境因子与历史滑坡的非线性关系链接最常见的手段之一[18],定义某一环境因子分类区间内滑坡面积占滑坡总面积百分比与该区间面积占研究区总面积百分比的比为环境因子频率比FR:
式中,Ni为某个环境因子第i个类别内的滑坡总面积,TN为全区滑坡总面积,Ai为i个类别的总面积,TA为研究区总面积。若FR大于1,说明该区间利于滑坡孕育,而且FR越高对滑坡孕育越有利;反之,不利于滑坡孕育。
1.3 机器学习模型简介
1.3.1分类和回归树(C&RT)模型
分类和回归树算法是决策树的一种,可生成分类树或回归树,C&RT算法递归地二分每个样本集为两个子样本集,使得生成的每个非叶子节点都有两个分支。非叶子节点的特征取值为“是”和“否”,因此C&RT算法生成的决策树是结构简洁的二叉树。其适合对多特征变量的复杂数据进行建模,具有抽取规则简单、准确度高、可解释性强的优势。
1.3.2随机森林(RF)模型
RF算法生成的众多决策树形成森林,可以改变干扰目标的因素并生成聚合以提供精确的输出,因此,已经被广泛应用于数据分类及预测。随机森林中的每棵树都是使用CART技术对数据进行引导的样本开发的,该技术在单个节点中随机选择变量子集,使用所有决策树的多数票确定模型的最终预测。与其他方法相比,RF的主要优势在于不需要调节过多的模型参数,只需要调节树的数量,而且树的数量越多则模型性能一般就越好。
1.3.3径向基函数(RBF)神经网络模型
RBF神经网络是一种性能良好的前馈式网络,具有最佳逼近、训练简洁、学习收敛速度快等优点。目前其已经被广泛用于模式识别、非线性控制和图像处理等领域。RBF神经网络是一种包括输入层、隐含层、输出层等3层的神经网络。从输出空间到隐含层空间的变换是非线性的,而从隐含层空间到输出层空间是线性的。
1.4 环境因子的重要性排序
在用RF模型建模预测易发性过程中,可以获得均值降低精度和平均降低基尼指数这两个参数,来评价各环境因子对模型预测效果的影响程度。均值降低精度体现为把一个变量变为随机数,RF预测准确率的降低程度,均值降低精度越大,表明该变量的重要性越高。平均降低基尼指数是通过计算每个变量对分类树各节点上观测值的异质性的影响,从而比较各环境因子的重要性;平均降低基尼指数是变量的节点杂质总减少量的平均值,通过RF中每个单独决策树中到达该节点的样本比例进行加权而得,平均降低基尼指数越大,表明该变量的重要性越高。
1.5 滑坡易发性分级方法
1.5.1自然断点法
自然断点法是基于数据中固有的自然分组,对分类间隔加以识别,将相似值进行恰当的分组并最大化各个类之间的差异[21]。将特征划分为类,在数据值差异较大的地方设置类边界。自然断点法寻求类内平均值的偏差最小化,同时使与其他类平均值的偏差最大化。该方法减少了类内部的方差,最大化了类之间的方差,所以不适用于数据方差很小的情况。寻求类内平均值的偏差最小化,同时使与其他类平均值的偏差最大化方法也被称为方差拟合优度,等于数组均值的偏差平方和减去类均值的偏差平方和。由于自然断点法将聚集的值放在同一个类中,因此该方法适合于映射非均匀分布的数据值。
1.5.2等间隔、分位数和几何间隔法
等间隔法是将属性值的范围根据需求划分为若干个大小相等的子范围,强调一个类别相对于其他类别,其优点是能快速实现分类,缺点是没有考虑数据分布的结构。分位数法为每个类分配数量相等的数据值,适用于呈线性分布的数据,不存在空类也不存在值过多或过少的类。几何间隔法基于具有几何级数的类区间创建分类间隔,该方法通过最小化每个类中元素数量的平方和来创建区间,确保每个类范围内的值数量大致相同并且间隔之间的变化一致。几何间隔法是等间隔、自然断点和分位数法的折中方法,其在突出显示中间值变化和极值变化之间达成了一种平衡,尤其是对于显示非正态分布的数据或者数据的分布及其倾斜时非常有用。
1.5.3频率比阈值法
频率比阈值法将连续型因子划分为若干个离散型因子,再分析各离散型因子与滑坡发生的非线性相关的频率比因子:1)将预测得到的滑坡易发性指数按从大到小的顺序依次划分为50~100等份,计算每一等份内的滑坡栅格数量及其占总滑坡栅格数量的比例;2)用频率比法计算每等份易发性指数区间的滑坡频率比值,以频率比值的转折处为主,同时以频率比值分布特征作为参考来划分易发性级别。频率比阈值法将滑坡易发性指数和滑坡分布结合起来做考虑,展现了工程地质类比的思想。该方法避免了单纯从滑坡易发性指数出发来进行易发性分级,实现了滑坡易发性指数与滑坡分布之间的紧密结合。
1.6 建模评价
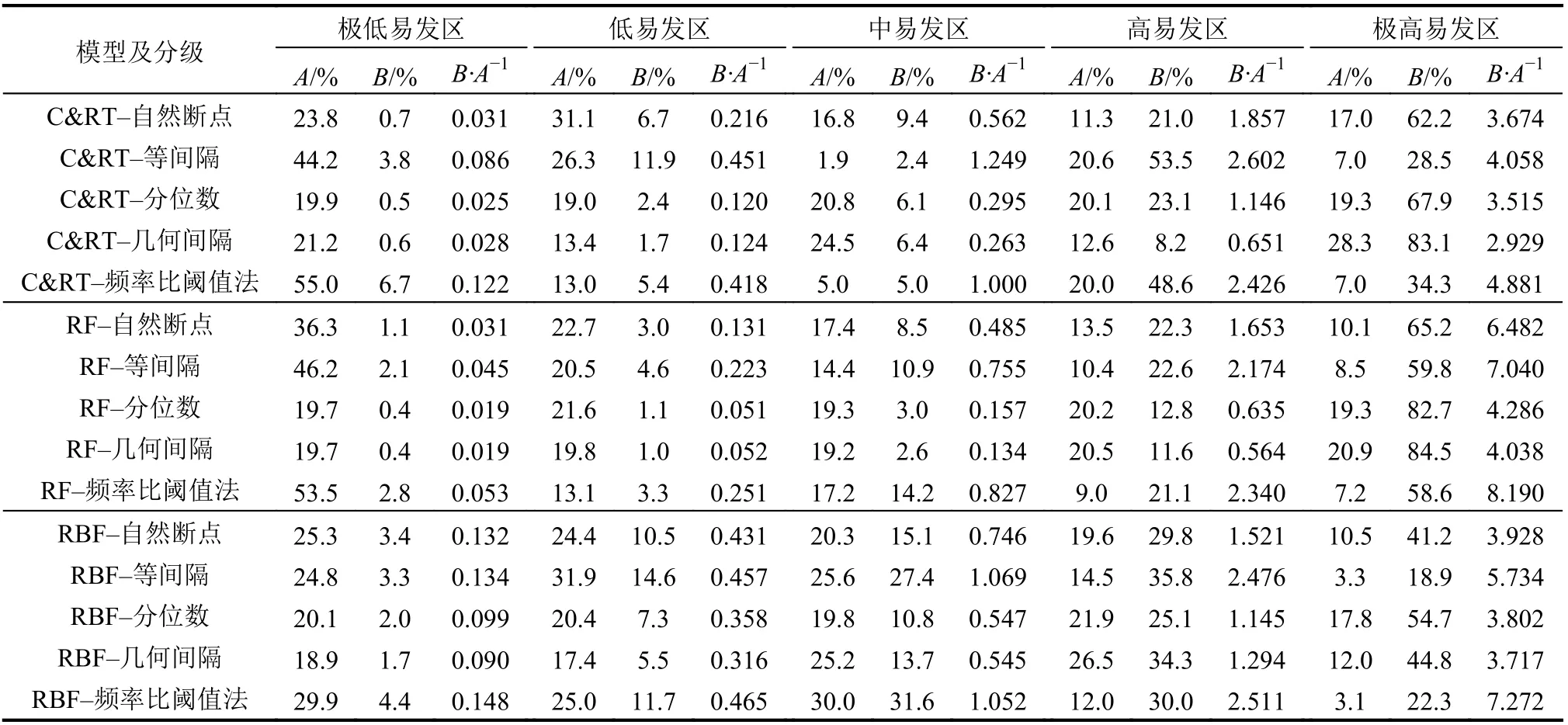
统计不同易发性图中各易发性等级的面积比例(A)、各等级滑坡占全部滑坡的比例(B)、各易发性等级中的滑坡比率(B/A)[15,22],根据各等级中这3个指标的具体值定量比较不同易发性图的效果。高/极高易发区的面积比例越小、区内滑坡占全部滑坡的比例越大,表明被准确预测的滑坡点越多;极低/低易发区的面积比例越大、区内滑坡占全部滑坡的比例越小,表明被误判的滑坡点越少;滑坡比例(B/A)越大,说明该等级中滑坡分布越集中。能够以越少的高/极高易发区预测越多的滑坡点,说明模型预测效果越优。
2 研究区概况及环境因子
2.1 研究区概况
图2为研究区位置及滑坡编录图。由图2可见,延长县位于陕西北部,全区面积共2 368 km2,属于黄土高原中部的多山地带。地势由西北向东南倾斜,呈现中间低而南北高的特征。属于大陆性季风气候,较干燥,年均降雨约500 mm。但由于不同区域间高程起伏较大,降雨和温度也呈现出了较为明显的空间差异性。降雨集中在夏季,约占全年75%。主要出露岩层为三叠纪和第四纪地层,共有5组沉积岩,其中砂泥岩互层和黄土最常见。另外区内地表水系较为发达,黄河及数条支流组成了较为复杂的径流网络,主要的城镇和居民区也多集中在河流附近。
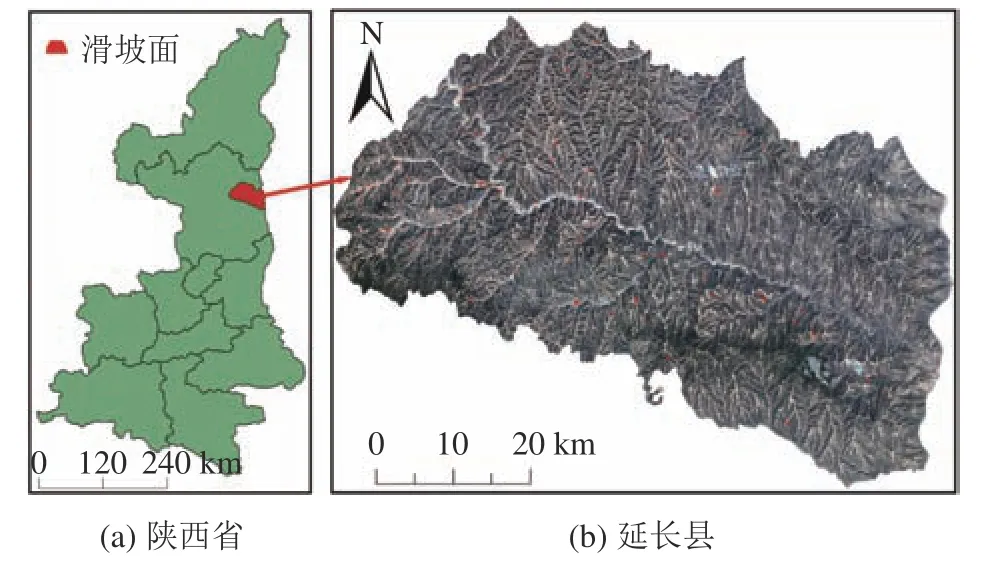
图2 研究区位置及滑坡编录图Fig.2 Location of the study area and the spatial distribution of landslides in the region
2.2 滑坡数据库
延长县地处陕北黄土高原,全县都有一定的黄土覆盖现象,地貌方面则有丘陵以及沟壑相对较多的特征,同时地质状态偏差,水土流失现象严重,加上黄土的大孔隙和对水的敏感性,在强降雨条件下容易湿陷,使得延长县成为滑坡高发区,因此选择该区域作为研究区。为对其进行滑坡易发性预测,需先制备可靠的滑坡编录数据库;通过地灾监测部门提供的项目报告,将区内滑坡地理位置导入到ArcGIS 10.2软件中,并通过Google Earth影像探查每一处滑坡的变形情况以确保滑坡的准确性。需要说明的是,报告中都有明确的滑坡边界信息,但由于本研究使用栅格单元作为评价单元,因此,在分析过程中将滑坡面转变为栅格进行分析。研究区数据见表1。
在属性表中链接各单体滑坡的编录信息,包括面积、体积、发生时间等,建立区域滑坡编录数据库。图2中:该区共有滑坡82处,其中,大型滑坡37个,巨型滑坡1个,其余为中小型滑坡,累计体积达到了5.2×107m3;滑坡面积介于7.4×103~1.3×103m2,滑坡总面积为3.1 km2,约占据全县面积的0.13%;从物质组成来看绝大部分为黄土滑坡,少数由砂岩或泥岩构成;这些滑坡大多发生在雨季,即每年的6~8月份,极少数几个为人为工程活动所诱发,如斜坡开挖和道路修建等。

表1 研究区数据列表Tab.1 List of study area data
2.3 滑坡易发性预测的环境因子
环境因子的选取是易发性预测中重要的一步,其涉及影响滑坡发育。目前,常用环境因子主要包括地貌类因子、基础地质类因子、水文因子和地表覆被因子等[23–24]。黄土地区地形破碎、山地沟壑和垂直节理发育,第四系碎屑沉积物较厚、孔隙大、强度低且易被侵蚀。对于西北黄土边坡,其发育形成滑坡的过程主要受一定坡度的山地和沟谷、易于风化的岩层及其松散堆积物、地表径流和地下水入渗等水文条件,以及土壤裸露和人类工程活动等地表覆被因素的影响。同时,黄土边坡在短时间内失稳的重要诱发因素主要是强降雨和工程切坡等问题。常见黄土滑坡致灾条件因子包括地层岩性、地质构造、坡度、高程、坡形、地形起伏、降雨、沟壑网络、植被覆盖和人类工程活动等。实时降雨量等短时诱发因素一般用于滑坡危险性预警建模,易发性建模不考虑此类的时间效应。同时,由于研究区内只有极少数滑坡由人类活动直接诱发,且工程活动的地点及施工强度具有随机性,因此人类活动因子也未被考虑在内。对于这一点,地表植被覆盖率也能间接反映人类活动的影响,归一化植被指数(KNDVI)高的区域人类活动相对弱一些,且有研究表明,土地利用类型因子与KNDVI因子之间存在较强的相关性,因此主要采用KNDVI来间接表征人类活动特征。
结合以往研究[9,13],构建4大类共12个因子的指标体系。其中,地貌类因子包括高程、坡度、坡向、平面曲率、剖面曲率、地形起伏度、地表粗糙度和地表切割深度等;基础地质因子为岩性;水文因子包括地形湿度指数(KTWI)和距离河流的距离;地表覆被因子为KNDVI。图3为滑坡易发性预测因子,由图3可见:
高程(图3(a))是影响滑坡空间分布的重要指标,地质和环境条件会随高程而改变,如岩石风化程度,地表植被覆盖等;同时山区小气候差异显著,降雨、日照等在不同高程分布也是不均的。全区的高程在470~1370 m之间,且西北高,东南低。本文数字高程模型(DEM)来自开源数据集地理空间数据云平台(http://www.gscloud.cn/home),分辨率为30 m。
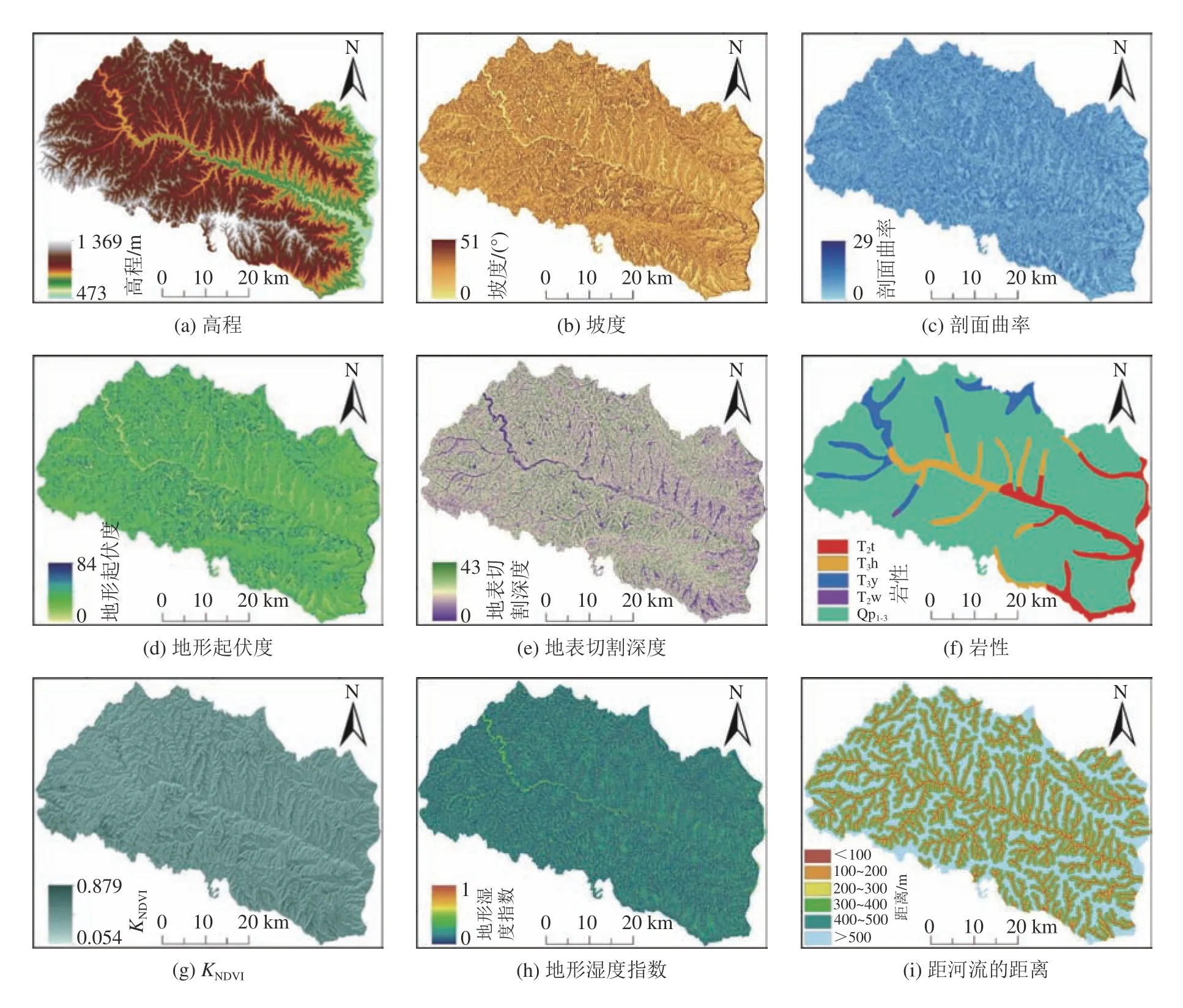
图3 滑坡易发性预测因子Fig. 3 Influencing factors for landslide susceptibility
坡度(图3(b))能够直接影响坡体的稳定性系数,还能通过影响坡体内部的应力分布、地表径流等来影响滑坡演化,全区坡度在0~51°之间。需要说明的是,这里的坡度因子并非原始地形数据,而是提取出的坡度,原因如下:首先大部分滑坡的变形破坏特征以蠕变形式为主,并未发生长距离滑移破坏,滑动前后坡度变化不大;对于小部分发生长距离滑移破坏的滑坡,在圈定滑坡边界时会把滑坡周界都绘制到滑坡范围内,并能通过适当扩大滑坡周界来降低前后坡度变化造成的误差;此外,30m分辨率栅格单元表征坡度时本身就会造成“坡度平均”的效应,也会降低滑坡前后造成的坡度变化。因此坡度值的误差在一定程度上是可容忍的。
不同的坡向会影响坡体所受的太阳辐射的程度,并导致坡体产生的水热比差异,从而影响坡体上的植被覆盖与水体蒸腾。坡向的值在–1~360°,其中–1表示平地。
平面曲率反映的是山体曲率在水平面上的投影,可以影响斜坡坡面上的水流。研究区的平面曲率图是由DEM得出的,在0~81之间。
剖面曲率(图3(c))反映的是山体曲率在剖面上的投影,影响着坡体物质加速或减速的运动形态,同样来自DEM。
地形起伏度(图3(d))反映地貌特征,从整体揭示某地区的地势。在GIS中计算每个栅格邻域内高程的最大和最小值,两者的极差为地形起伏度。
地形粗糙度反映陆地表面的起伏程度和侵蚀强度的指标,可定义为特定区域内坡度角的变化,并计算为坡度的标准偏差:
式中,S是坡度。延长县的地形粗糙度在1.00~1.57。
地表切割深度(图3(e))为地图中某点周围区域的最低海拔和平均海拔之间的差异,可以用来表示地表侵蚀程度。首先利用ArcGIS10.2中的邻域统计工具计算特定像元周围的区域形状,然后使用统计类型工具来获取邻域内具有3×3像元大小的高程的平均值和最小值,最后从栅格计算器获得的平均值和最小值的差即为地表切割深度。
大部分滑坡分布在黄土所在的第四纪地层,因此有必要将岩性作为区分滑坡是否容易发生的一个指标,这也与“易滑地层”的概念一致(图3(f))。岩性单元不同,对应的岩土体参数也不同,从根本上影响坡体的稳定性,因此该因子已被广泛应用于滑坡易发性评估研究[4,14–15]。不同岩性单元说明出露的地层年代不同。全区主要包括第四纪(Qp1-3)和三叠纪的地层,其中三叠纪的地层又可划分为4个不同组(T2t、T3h、T3y、T2w),因此共出露5套沉积地层。
KNDVI反映了地区植被覆盖程度,其可影响并改变斜坡上土壤和水文过程的分布(图3(g))。KNDVI通常是从遥感影像中得出的:
式中,PNIR和PRed分别代表近红和红波。本文选择Landsat8遥感影像作为KNDVI数据源,结果显示该地区的KNDVI值在0.054~0.879范围内。
地形湿度指数(KTWI)作为一个水文参数,可描述水文过程的地形属性,因为该因子考虑了坡度和坡体上部贡献面积(图3(h))。
式中,a为从特定栅格流出的坡上部面积,tanβ为该栅格的倾斜角。为生成KTWI图,使用GIS的水文统计工具来计算各栅格的流向和累积径流量,最后将KTWI值归一化为无量纲单位。
距河流距离(图3(i))为河流侵蚀并冲刷坡体,从而制造边坡临空面;同时河流影响坡体地下水位,改变岩土体的渗透状态。对河流以100m为单位进行了缓冲分析,后期分析各个类别的频率比值,再将频率比值相近的间隔归为一个类别。
2.4 环境因子分类及频率比分析
离散型变量的类别是固定的(如岩性),而连续型变量,需首先使用一个较小的间隔将该因子等分成多个属性区间,然后用式(1)计算不同区间的FR值,将FR值相近的区间合并成一个类别。一般而言,具有4~10个类别的因子对于机器学习的应用是较为合理的[12],本文所有因子的二级区间数为4~9。归类后各因子类别及其相应的FR值见表2。
3 延长县滑坡易发性预测及其分级研究
3.1 环境因子重要性
使用SPSS Statistics22软件中的Pearson相关性方法对各因子进行相关性分析,结果表明所有因子之间的相关性系数都小于0.5,说明因素之间均呈弱相关,因此每个因子都可用于本次易发性评价计算。然后使用RF模型中的均值降低精度和平均降低基尼指数分析因子重要性,结果如图4所示。虽然评价指标不同,但是可以发现高程和距河流的距离始终是最重要的两个因子,这与表2中FR相吻合。对于高程因子,其在800~1000m海拔内的FR大于1,说明该高程区间利于滑坡发育;对于距河流距离因子,0~400m范围内的FR均大于1,说明研究区的滑坡大部分集中沟壑等的附近。总体而言,岩性类别、坡向和地形起伏度对滑坡发育具有较为重要的影响,而剖面曲率、地形粗糙度、KTWI和KNDVI对研究区滑坡的影响相对较小。
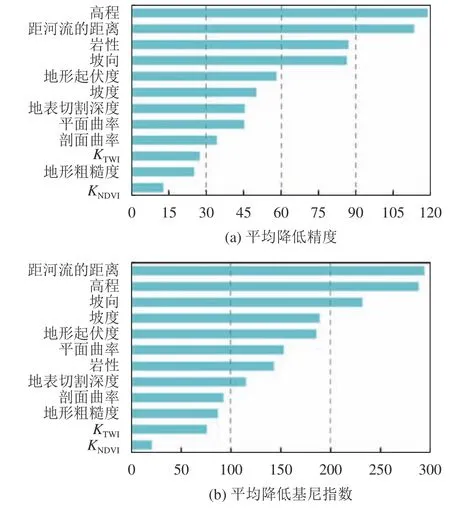
图4 各环境因子的重要性排序Fig. 4 Ranking of the importance of the factors
3.2 滑坡易发性指数分布及其精度评价
3.2.1延长县滑坡易发性预测结果
分别利用3种机器学习模型预测延长县的滑坡易发性指数,结果如图5所示。由图5可见,3个易发性指数的结果均是从0到1分布,表示滑坡发生概率从低到高。研究区东部的滑坡易发性指数整体上明显小于西部地区,滑坡编录的分布情况与易发性指数分布特征相吻合,即西部地区滑坡多而东部少。虽然3种模型预测的滑坡易发性图分布规律总体相似,但在很多细节上仍然存在差异。比如在研究区东部,C&RT和RF模型预测的滑坡易发性指数要低于(颜色更深)RBF模型的预测结果。
3.2.2滑坡易发性预测的精度
采用测试集ROC曲线下面积(SAUC)作为评价不同模型性能的指标。C&RT、RF、RBF等3种模型的ROC曲线如图6所示。从图6中可知,RF模型的SAUC(0.866)最大,其次是C&RT模型(0.852),而RBF模型的SAUC(0.780)相对较小。可见RF模型预测性能最好,依次优于C&RT和RBF模型。
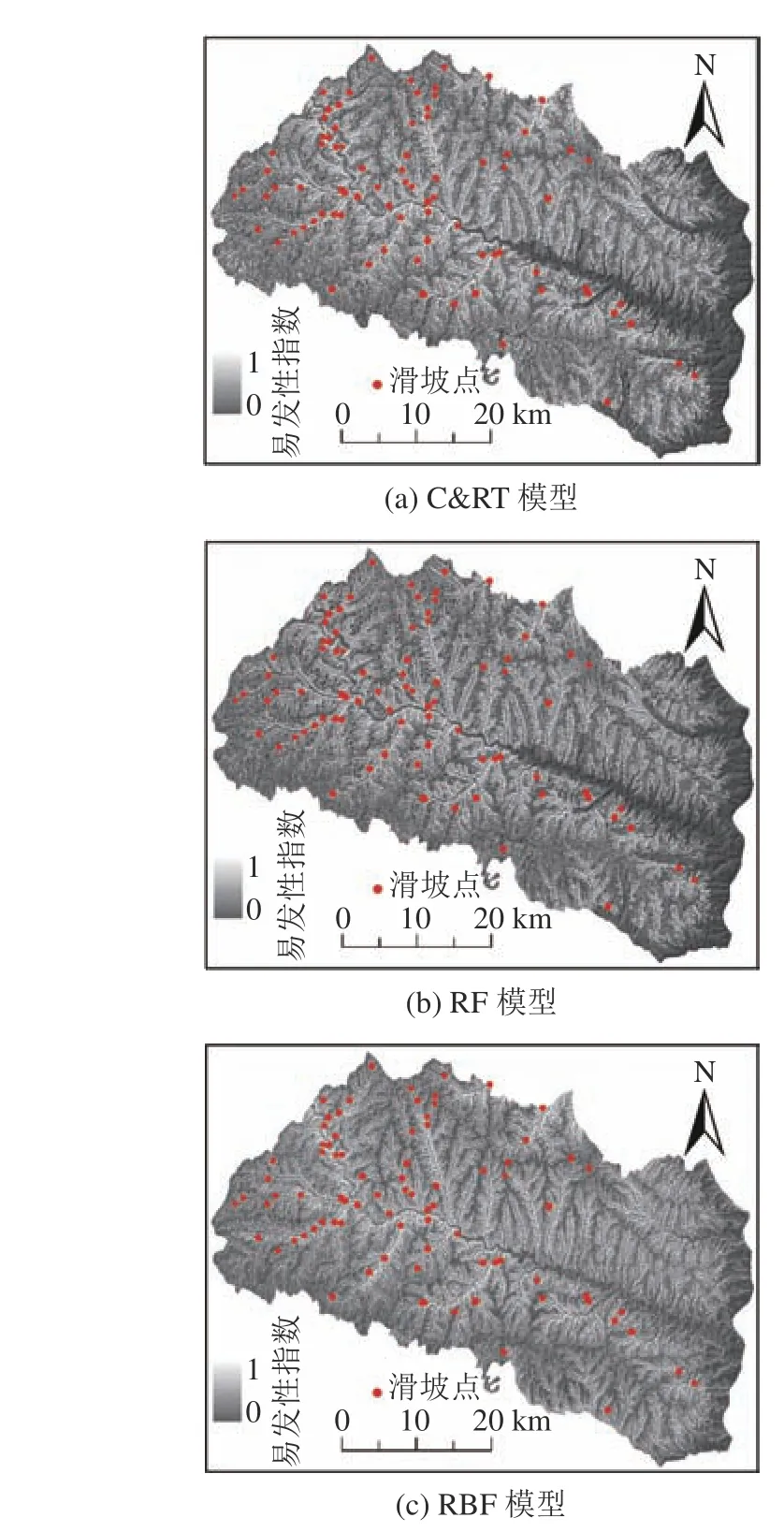
图5 各模型易发性指数的空间分布图及接收者操作特征曲线精度Fig. 5 Distribution of landslide susceptibility index from different models
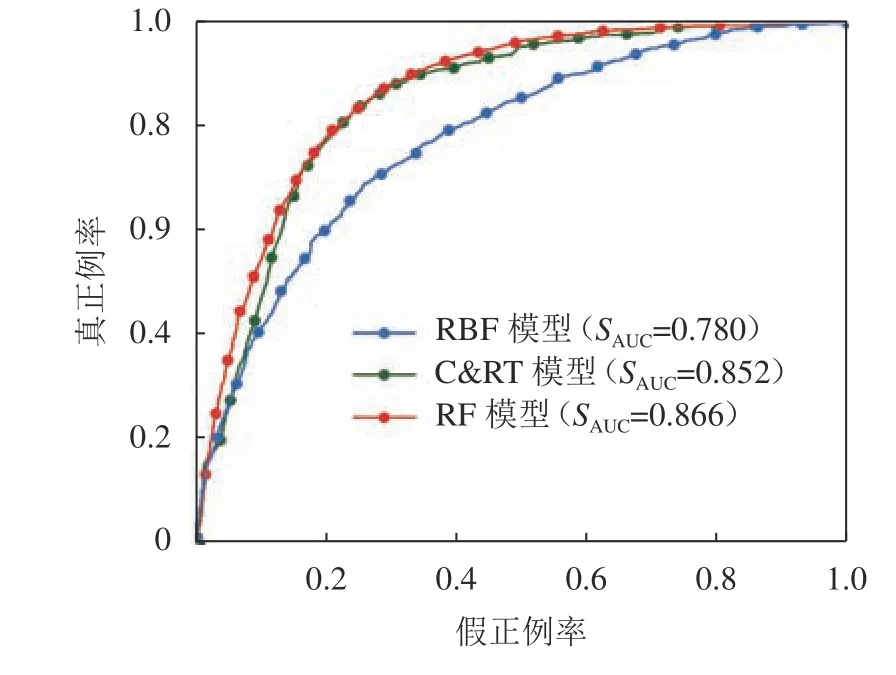
图6 模型易发性指数的接收者操作特征曲线精度Fig. 6 Receiver operating characteristic curve of all the models
3.2.3滑坡易发性指数的均值和标准差
进一步采用均值和标准差分别反映滑坡易发性指数分布的平均水平和离散程度,以此分析不同模型预测滑坡易发性指数的不确定性。图7为各模型获得易发性指数与对应的栅格个数和概率密度函数,由图7可知,3种模型预测的滑坡易发性指数分布存在较大差异:C&RT模型预测的易发性指数呈现“中间低两头高”的总体趋势,且主要集中分布在0~0.4及0.6~0.9之间;RF模型预测的易发性指数,总体上呈现为“递减型指数函数”的分布模式;而RBF模型预测得到的易发性指数分布相对较为均匀,中间栅格数较多但在两级分布较少,且模型的拟合和预测能力相对较差。
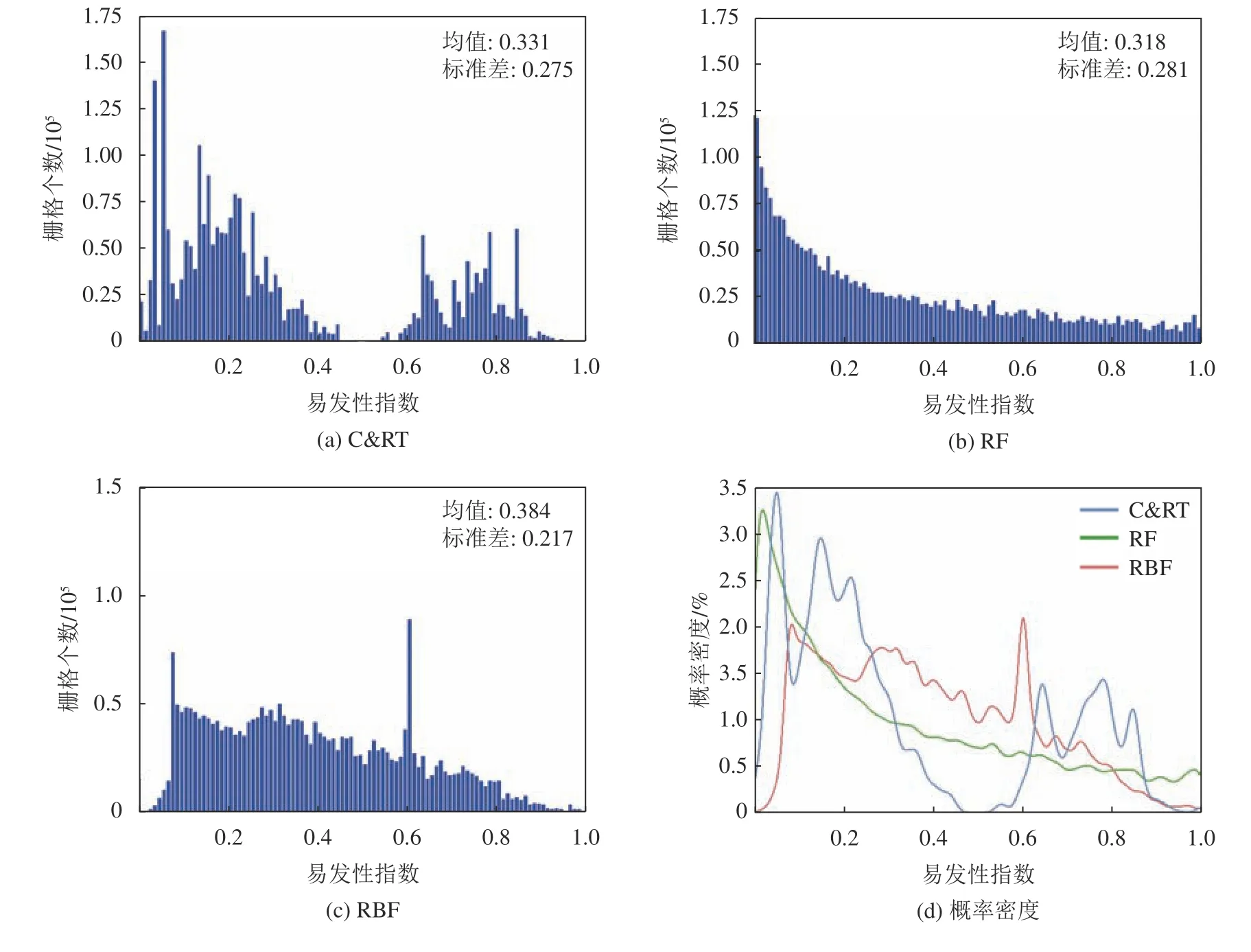
图7 各模型获得易发性指数与对应的栅格个数和概率密度函数Fig. 7 Relationship between landslide susceptibility indexes and corresponding number of cells and probability density function
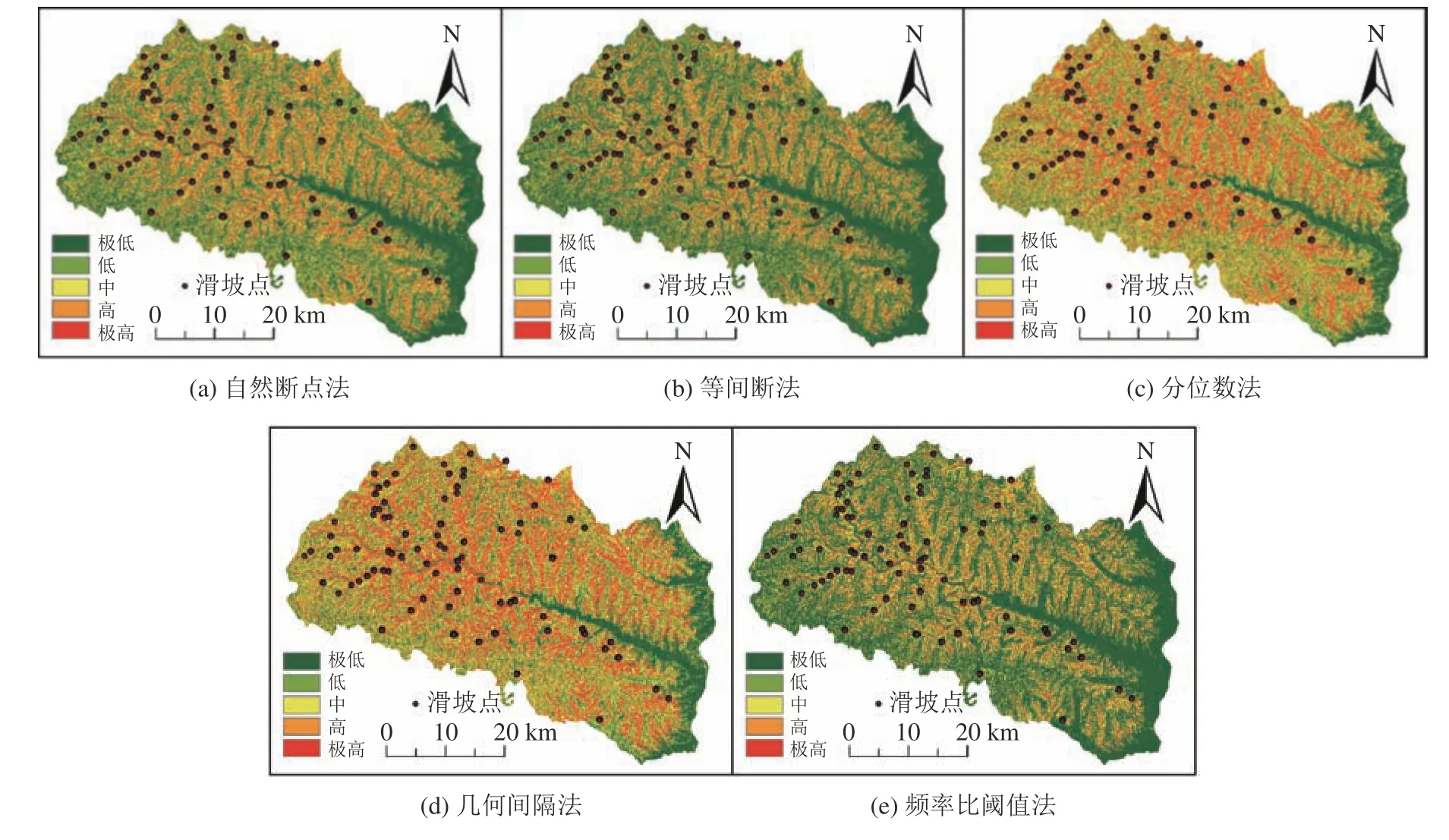
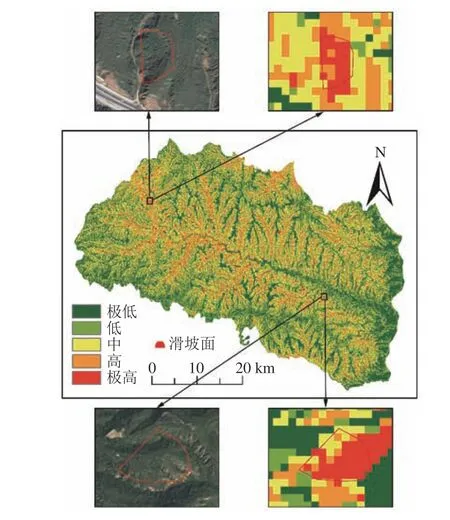
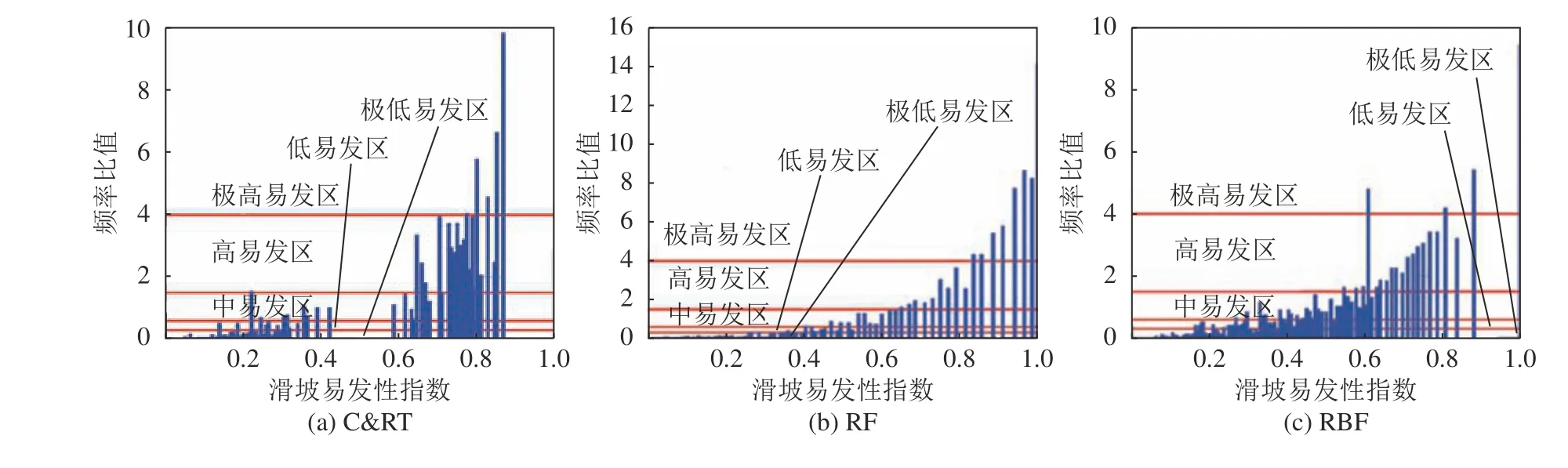
3种模型预测的易发性指数均值排序为:RF(0.318) 3.3.1不同分级方法和机器学习的滑坡易发性制图 根据各模型预测的滑坡易发性指数的结果(图5),使用GIS平台中的自然断点、等间隔、分位数和几何间隔法4种分级方法以及本文提出的频率比阈值法,分别将各易发性指数划分成5个等级,即极高、高、中、低和极低易发区,从而获得延长县滑坡易发性分级图,基于RF模型和5种分级方法下绘制的易发性分区图如图8所示。由图8可见,不同分级方法下绘制的滑坡易发性制图结果具有显著差异。几何间隔分级方法和RF机器学习模型下的极高和高易发区较多,等间隔分级方法和C&RT机器学习模型下的极低和低易发区较多。 3.3.2滑坡易发性分级结果的不确定性分析 不同工况下的滑坡易发性图中各易发性等级的面积比例(A)和各等级滑坡占全部滑坡的比例(B),以及滑坡比率(B/A)的统计结果见表3。根据表3中极高、高易发区和极低、低易发区A和B值,定量分析不同分级方法下的滑坡易发性分区图的异同。对于C&RT模型,分位数和几何间隔法的分级结果表明,极高和高易发区分别识别出91%和91.3%的滑坡,而等间隔法、自然断点法和频率比阈值法分别识别出82.0%、83.2%、82.9%;等间隔法在极高易发区只识别出28.5%的滑坡,大幅度低于高易发区,并不合理。RF与C&RT模型中的易发性分级结果表现出类似趋势,分位数和几何间隔方法中极高和高易发性区的滑坡比例最高,分别达到了95.5%和96.1%。这两种方法在极高易发区的滑坡点百分比要比其他3种分级方法高17.5%~25.7%。但是RF的等间隔分级法结果在极高易发区能识别大部分滑坡(59.8%),这与C&RT模型有所区别。 图8 基于RF模型的滑坡易发性分区图Fig. 8 Landslide susceptibility map by using the RF model 表3 各易发性制图中的历史滑坡统计结果Tab.3 Satistical results of historical landslides in each landslide susceptibility map 与RF和C&RT模型相比,RBF模型中极高和高易发区对历史滑坡的识别性能较差。尤其在极高易发区,5种分级方法中最高(分位数法)也只能识别出54.7%的滑坡数,而最低的等间隔法仅能识别出18.9%的滑坡。进一步分析各易发性等级中的滑坡比率(B/A),该值越大说明该等级中滑坡分布越集中,间接说明了对应分级方法的有效性。由表3可知,每种计算工况中滑坡比率值都是从极低到极高易发区逐渐增大,显示在高/极高易发区间内的滑坡分布更为集中。在各种预测模型和分级方法组合工况下,频率比阈值法的极高/高易发区的滑坡识别比率普遍大于其他4种方法,可见频率比阈值的分级效果较优。 3.3.3 滑坡易发性分级结果验证分析 利用Google Earth中的遥感影像数据对部分滑坡点进行验证,如图9所示。由图9可见,大部分栅格均处于极高易发区,这也说明频率比阈值法得到的结果与实际情况较为一致。 图9 使用遥感影像对于频率比阈值法进行验证Fig.9 Verification for the frequency ratio threshold method by using the historical remote sensing images 总体而言,分级方法的选择对于滑坡易发性制图的影响较为显著,同一预测模型和不同分级方法工况下的滑坡易发性分区图的滑坡分布模式存在较大差异。基于RF模型和几何间隔法的滑坡易发性分区图的效果最好,其在极高易发区和高易发区中识别出了96.1%的滑坡点,且仅有0.4%的滑坡点被错误地划分到了低易发区中,这种情况中极高和高易发区的总面积为全区面积的41.4%。基于RF模型和频率比阈值法在极高易发区具有最大的滑坡比率(8.190)。因此,对于特定模型,应该根据研究目的和易发性图的用途来确定分级方法:如果地灾管理部门想尽可能识别出多的滑坡用于隐患点的识别与预警,就选择分位数和几何间隔分级法,但需要注意,不能因为想尽可能识别出多的滑坡数而提高研究区滑坡易发性等级。本文中41.4%的极高和高易发区面积是可以接受的;如果易发性图被用于应急管理工作,如在某次极端降雨之后确定最可能发生滑坡灾害的地区,使用较少的极高和高易发区识别出尽可能多的滑坡,从而提高滑坡易发性分区图的效率,此时应选择频率比阈值法。 3.3.4 频率比阈值法的其他不确定性问题 频率比阈值法在确定频率比值转折点时存在一定的不确定性,图10为频率比阈值法划分易发性级别。由图10(a)可见,在频率比值出现较明显转折点时,比较容易确定其具体的频率比阈值;但是,在相邻等级频率比变化不明显时,由图10(c)可见,想要确定极低和低易发区的频率比阈值还有一定困难。如果想要获得一个较好的分级阈值,需要依靠科研人员的主观经验判断。针对频率比阈值法在确定分级阈值时存在的主观性问题,在下一步研究中考虑以自然间断点法划分的滑坡易发性分级标准为基础;再结合滑坡频率比阈值的分布特征,对自然间断点法的易发性分级结果进行调整;最后,形成自然间断点—频率比阈值法实现主客观有机结合改进滑坡易发性分级方案。在频率比值变化不明显时,以自然间断点法的分级阈值作为参考基础,再结合该阈值处的频率比值对易发性分级阈值进行综合确定。频率比值在某段易发性值范围内都变化较大,导致难以确定频率比划分的阈值时,就可以参考自然间断点法的阈值划分结果,确定频率比阈值。 图10 频率比阈值法划分易发性级别Fig.10 Frequency ratio threshold method to classify susceptibility levels 本文使用C&RT、RF和RBF等3种经典机器学习模型预测延长县滑坡易发性,三者预测精度均高于0.75。进一步采用4种基于GIS的分级方法以及本文新提出的频率比阈值法,对3种滑坡易发性预测结果进行级别划分,结果显示,不同机器学习模型中效果最好的易发性分级方法也有差异:几何间隔法和分位数法划分出的极高和高滑坡易发区面积显著大于自然断点法、等间隔分级法和频率比阈值法;然而自然断点法、等间隔分级法和频率比阈值法的极高和高易发区的滑坡比率更大,尤其是频率比阈值法的滑坡比率普遍大于其余4种基于GIS的分级方法。从历史滑坡识别数量的角度出发,基于RF模型和几何间隔法的滑坡易发性图的性能最好,极高和高易发性区中共识别出了96.1%的滑坡,而极低和低易发性区中仅有1.4%的滑坡,并存在明显的极高/高易发区比例过高;若从滑坡点的分布密度来看,基于RF模型和频率比阈值分级法的滑坡易发性图的性能最好,极高和高易发区只占全区面积的16.2%,却能识别出79.7%的滑坡。本文提出的频率比阈值法的定量精度与已知的基于GIS的分类方法相类似,且极高和高易发区中的滑坡密度更大,达到了用较少的高和极高易发区来表征尽可能多的已知滑坡的目的,且在极低和低易发区中被错误分类的滑坡很少,说明其是一种适用于防灾减灾实际工作的新型易发性等级分区方法。3.3 不同易发性等级中的滑坡分布模式
4 结 论
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
今日农业(2021年10期)2021-11-27
河北地质(2021年1期)2021-07-21
今日农业(2021年1期)2021-03-19
数学小灵通(1-2年级)(2020年11期)2020-12-28
小学生学习指导(低年级)(2019年3期)2019-04-22
北方交通(2016年12期)2017-01-15
水利科技与经济(2016年6期)2016-04-22
山东青年(2016年3期)2016-02-28
