
多视图融合DJ-TextRCNN的古籍文本主题推荐研究
2024-02-04 09:45杨秀璋
情报学报 2024年1期
武 帅,杨秀璋,何 琳
(1. 南京农业大学信息管理学院,南京 211800;2. 武汉大学国家网络安全学院,武汉 430072;3. 贵州财经大学信息学院,贵阳 550025)
0 引 言
随着数字人文研究纵深化拓展,计算社会科学跨学科融合,推动着以大数据[1]、人工智能[2]、知识图谱[3]等为代表的互联网3.0 技术拓宽新文科背景下的人文社科领域寻找新的研究范畴[4],以进一步提升传统社会科学领域下的计算人文标准。随着计算人文研究的深入,数字人文研究不再局限于单部古籍文本,而是针对某一特定研究主题的古籍文本进行细粒度文本挖掘[5]。古籍研究者如何快速精确定位目标主题的古籍文本,智能化实现古籍文本的主题内容的推荐,已成为数字人文研究领域迫切需要解决的难题。因此,面向古籍研究者的古籍文本事件类型的主题自动推荐算法研究变得尤为重要。推荐算法(recommended algorithm)[6]作为一种结合用户历史行为、兴趣和社交网络等信息,为用户推荐个性化的技术,随深度学习技术的发展已成为当下文本挖掘领域的一个研究热点和难点。如何结合古籍文本语料特征、提供古籍文本的主题自动化推荐服务,对数字人文领域研究发展具有重要的意义。随着我国于2007 年起实施“中华古籍保护计划”[7],海量珍贵古籍实现了数字化保护,为人文计算提供了重要的语料研究对象。由于古籍文本时间跨度大,不同时期编目主题划分标准不一,古籍研究者面对海量数字化古籍文献的领域主题划分变得尤为困难,在数字人文研究过程中查询和分析同一主题的古籍文本难度加大,短时间内无法实现精准获取古籍文献知识库中同一主题的古籍文本[8]。为保障研究者短时间内获取古籍文本主题的准确性,推荐符合其研究主题需求的古籍文本,本文参考并深入分析推荐算法,结合古籍文本特征,提出一种多视图融合DJ-TextRCNN(DianJi - recurrent convo‐lutional neural networks for text classification)[9]的古籍文本主题推荐算法,有效实现古籍文本的自动分类,为古籍研究者提供更精准的主题推荐服务。
面对古籍知识库中大规模的数字化古籍文献,传统编目分类和规则匹配方法工作效能低,过度依赖专家知识,花费大量人力和物力成本,缺乏对古籍文本自身语义的深层次挖掘,随着古籍知识库的扩充,编目主题边界模糊,较难实现对古籍文本主题的精准推荐。同时,随着人工智能的兴起,以机器学习和深度学习为代表的自动分类算法越来越多,但该类方法仅从实体视图尝试对文本自动分类,缺乏考虑古籍文本的实体位置与触发词之间的关联性[10],缺乏考虑古籍文本在语言表达、文字风格和文字形式与现代文本的差异性,缺乏考虑古籍文本以双句、叠句为主,缺乏考虑古籍文本侧重于将情感渗透在文字中等具体情况。
针对上述现有推荐算法存在的不足,本文结合古籍文本语料实体识别后的触发词、实体的互补性,利用预训练模型、深度学习模型和自注意力机制构建适用于古籍文本特征的主题推荐模型,将其命名为DJ-TextRCNN,以实现对古籍文本不同主题的自动分类和推荐。本文主要贡献如下。
(1)相较于仅从实体视图进行古籍文本挖掘研究,本文考虑到触发词对实体的互补,尝试融合主体(位于触发词前的实体)、客体(位于触发词后的实体)和关系(触发词)三个视图,从更多维度挖掘文本语义。
(2)传统深度学习模型处理文本的优势相对单一,而DJ-TextRCNN 模型综合考虑了各模型的特点,包括卷积神经网络侧重于细粒度的文本特征提取、循环神经网络侧重于突出文本语序、双向长短时记忆网络侧重于上下文语义关联性、注意力机制侧重于目标语义加权,以及预训练模型侧重于词向量加权,实现了对古籍文本的更细粒度、更深层次的语义挖掘。
(3)本文尝试融合多视图语料知识元和上下文语义信息,通过DJ-TextRCNN 模型实现对古籍文本更细粒度、更深层次、更多维度的语义挖掘,一定程度上提升了主题推荐的准确性,可以缓解现有主题推荐研究过于依赖专家知识的现状,进而节约古籍研究者获取目标主题的古籍文本所花费的时间和精力,推动数字人文研究的进一步发展。
1 相关研究工作
随着新一轮科技革命的发展,推动人类社会朝着崭新的“智慧城市”时代发展,以第三轮科技革命为代表的大数据、人工智能、云计算等高性能技术逐步融入日常生活中,随之衍生出的是日常行为方式的转变。数智赋能[11]理念的提出为利用高性能计算实现主题推荐服务提供了理论支撑。本文旨在利用更细粒度、更深层次、更多维度的文本挖掘技术实现对古籍文本的主题推荐,节约古籍研究者获取目标主题的古籍文本所花费的时间和精力。相关研究工作将从传统古籍目录的主题推荐、基于浅层语义挖掘的主题推荐、基于深层语义挖掘的主题推荐和主题推荐的研究现状评述四个方面进行阐述。
1.1 传统古籍目录的主题推荐
现阶段,古籍目录的古籍分类研究较少,主要集中于古籍目录和古籍数据库的主题分类研究。
古籍目录是指将古籍的书名和叙录依次编列的总聚,是我国自西汉《七略》以来两千余年古籍整理工作留下的重要学术遗产。古籍书目的四部分类法虽自《隋书·艺文志》后趋于稳定,但四部分类借下划分并不严谨,各部分类范围过于庞大,不利于精细研究[12]。姚名达[13]系统梳理了十三种书目的类目增删变化,罗列了书目内涵的对照关系。万彩红[14]认为史志目录中易学文献的分类是跨列多类、纷繁复杂的,虽能体现中国传统学术文化不同流派间的融合、演化出历史研究轨迹,但并不利于现有古籍研究者的梳理。上述研究仅从类目层进行定性分析,缺乏考虑类目下具体收录的古籍内容,存在一定的片面性。
古籍数据库的主题分类是由现有古籍数据库收录的古籍资源主题决定的。随着数据驱动的第四研究范式的兴起,古籍整理和编目从最初的数字化转向以数据和知识为对象的深度挖掘。夏翠娟等[15]设计一种能够融合不同来源、格式的古籍目录模型,搭建了“中文古籍联合目录及循证平台”。李惠等[16]构建“人物-古籍-摘要”的文本特征提取模型,结合元数据信息和三种常用的文献推荐算法,实现了古籍提要的知识发现。李文琦等[17]依据领域专家的需求,利用人机交互技术构建历代古籍目录可视化分析系统,较好地实现了类目分合转化的模式识别。
总体而言,古籍目录和数据库的主题分类研究主要采用扁平化的方式,过于依赖专家知识。随着所收录古籍的涉及面增加,该方式因难度极大而难以普及,缺乏依托文本挖掘技术实现自动化分类的研究,不能提升基础分类效率;且研究对象侧重于四部分类法的类目层或类目层下具体收录的古籍名称,缺乏考虑古籍内容的研究。上述不足在一定程度上制约了传统古籍文本的主题推荐方法在信息化时代的推广,不适合更深语义的主题推荐。
1.2 基于浅层语义挖掘的主题推荐
随着计算机技术的发展,计算机的计算力逐步满足日常数据的统计归纳,浅层语义挖掘模型逐步登上历史舞台。浅层语义挖掘模型的规模化运用为主题推荐提供了新的方法,主要包括基于统计规则的主题推荐和基于主题模型的主题推荐。
常见的统计规则方法包括基于无监督学习的聚类、降维和自编码器,以及基于监督学习的支持向量机(support vector machine,SVM)、朴素贝叶斯、决策树等。常娥[18]运用聚类算法设计农史专题资料自动编纂系统,实现对“稻、麦、豆、棉、麻”五个主题的分类。Sinclair 等[19]考虑到古籍主题分类涉及历史、社会等人文方面的因素影响,分别从定量和定性两种视角交互式呈现数据规模和时间跨度的主题分类效果。北京大学与北京爱如生数字化技术研究中心合作研发中国基本古籍库[20],构建自编码器实现对分类、条目和全文三个方面的古籍检索。张力元等[21]运用机器学习的方式实现对古籍《荀子》和《管子》目录中互著与别裁映射的文本分类任务,为古籍在多类目记载提供了新思路,推动了主题推荐研究的发展。
Blei 等[22]在Hofmann[23]提出的潜在语义分析模型(probabilistic latent semantic analysis,pLSA) 的基础上引入“先验分布”的概念,提出潜在狄利克雷分配模型(latent Dirichlet allocation, LDA),在一定程度上推进了主题推荐研究进程。颜端武等[24]基于HDP(hierarchy Dirichlet processing)模型结合内容、时间相似度实现了对主题文献的自动推荐。房小可等[25]综合考虑标签主题和主题概念空间因素,提出标签推荐算法(LDA-concept),提升了单一模型主题推荐效果。基于此,祝婷等[26]引入本体的概念,张亮[27]引入社会化标签,秦贺然等[28]在互信息计算特征词的基础上加入命名实体特征,崔金栋等[29]引入微型本体概念,均通过提升语义来进一步提升LDA 模型的主题推荐效果。
总体而言,基于浅层语义挖掘的主题推荐方法在LDA 模型提出后,通过增强语义的方法不断提升主题推荐效果。上述方法虽然在一定程度上提升了LDA 主题推荐算法的效果和精度,但核心研究模型依旧是以LDA 模型为主体,未考虑长距离文本上下语义的依赖程度,忽略了深层次语义知识对主题推荐结果的影响。同时,LDA 模型以“词-主题-文档”的词频概率统计假设,忽略了构建词向量计算的优势,对规模以上级语料进行主题推荐时效果不佳,监督学习过程容易造成语义损失、重复无效计算、面对新语料存在冷启动[30]等缺陷,不适合深层次的主题推荐,需尝试使用深度学习模型进行深层语义挖掘,提升主题推荐效果。
1.3 基于深层语义挖掘的主题推荐
Web 3.0 带来了以GPU(graphics processing unit)为核心计算的强大计算能力,推动着人工智能技术不断发展,一定程度上促进了主题推荐方法的改进,主要包括基于知识图谱的主题推荐和基于深度学习的主题推荐。
基于知识图谱的主题推荐是指通过构建知识库,运用知识图谱所具备的强大语义处理和开放互联能力,从而实现对目标人群的知识推荐。翟姗姗等[31]针对不同场景分别构建知识库,计算知识元间的相似度实现主题推荐,但缺乏深层次语义挖掘。彭博[32]构建主题-知识关联模型实现对信息资源的知识推荐,虽然在一定程度上提升了语义挖掘效果,但数据维度会影响推荐效果。李锴君等[33]考虑到推荐算法在学习高维度特征时出现的反向传播路径过长的问题,提出一种基于知识嵌入的编码-解码模型(knowledge embedding-based encoding-decod‐ing model,KE-EDM),在一定程度上提升了推荐准确性,但无法计算实体在现实环境下的权重。
基于深度学习的主题推荐是指通过运用神经网络对信息资源深层次挖掘,发现潜在语义关联性,从而实现对目标内容的主题推荐。常用于推荐算法的神经网络以卷积神经网络(convolutional neural networks,CNN)和循环神经网络(recurrent neural network,RNN)为主。卷积神经网络结构层主要由卷积层和池化层构成,能较好地实现对文本语料的潜在语义特征的提取。王杰等[34]融合LDA 主题模型和卷积神经网络实现对目标用户的主题推荐。严凡等[35]使用两段卷积神经网络实现主题推荐。李治等[36]融合树状与循环CNN 网络实现实时主题推荐。相较于CNN 模型侧重于细粒度的特征提取,RNN 侧重于突出文本语序,但其在处理长文本语料时,易造成梯度爆炸或消失的现象,后常用效果更佳的长短时记忆网络(long short-term memory,LSTM)[37]或双向长短时记忆网络(bi-directional long short-term memory,BiLSTM)[38]处理长文本语料。卢春华等[39]提出了一种基于本体和循环神经网络的资源模型,虽然解决了电子数据存在信息过载的现象,但耗时较长。倪维健等[40]在传统LSTM 模型基础上引入多头自注意力机制,提升了模型推荐效果。赵雪峰等[41]在传统LSTM 模型基础上引入预训练模型(bidirectional encoder representation from transformers,BERT)[42],有效提升了模型提取能力。
总体而言,基于深层语义挖掘的主题推荐模型是现阶段主要研究方法,随着注意力机制、预训练模型等新深度学习方法的不断提出,通过细粒度、深层次挖掘语料信息来增强语义,实现精准的主题推荐。
1.4 主题推荐的研究现状评述
现阶段的主题推荐算法主要集中于对现代文本的研究,而针对古籍文本的主题推荐研究较少。现有主题推荐方法研究中传统古籍目录、浅层语义挖掘、深层语义挖掘的方法均取得了一定的研究成果,一定程度上实现了细粒度、深层次的文本挖掘。但上述方法均仅从单一实体视图角度进行细粒度文本挖掘,缺乏考虑不同视图语义知识的特征互补性以及长文本数据间的上下文语义关联性,会产生文本噪声现象,易导致文本重复计算,较难实现对深层次文本特征的挖掘,一定程度上限制了主题推荐的准确性。
2 古籍文本主题推荐算法框架构建
针对古籍主题推荐模型仅从单一视图实体进行文本语义挖掘、缺乏考虑其他视图对语义特征词的影响、准确率相对较低的问题,本文结合主体、关系和客体三个视图的互补性和协调性,提出一种多视图融合DJ-TextRCNN 的古籍主题推荐模型,实现对不同主题的古籍文本自动分类和推荐。
2.1 主题推荐算法整体框架
多视图融合DJ-TextRCNN 的主题推荐算法模型整体框架如图1 所示。该框架包含四个模块:古籍文本语料处理模块、多视图融合特征提取模块、DJ-TextRCNN 模型、主题推荐模型评估模块。

图1 多视图融合DJ-TextRCNN的古籍文本事件类型主题推荐算法整体框架
(1)古籍文本语料处理模块:系统处理古籍文本语料,主要包括中文分词、词性标注、命名实体识别、命名实体消歧、触发词识别。
(2)多视图融合特征提取模块:首先,将处理好的古籍文本语料数据分别从主体视图、客体视图和关系视图进行文本特征提取;其次,将提取后的特征属性结合权重进行赋值;最后,将多视图融合后的文本特征进行词向量化处理。
(3)DJ-TextRCNN 模型:先通过BERT 预训练模型对处理好的古籍文本语料进行二次预处理,提升部分词的特征权重;再通过TextRCNN 的卷积神经网络(CNN) 实现对局部文本语料的细粒度处理;然后通过TextRCNN 的循环神经网络(RNN)和双向长短时记忆网络(BiLSTM)捕获长文本语料中的局部特征及其上下文语义关联性;最后,利用多头注意力(multihead attention,MHA)机制[43]实现对关键特征的权重加权,提升模型整体主题分类识别效果,最终实现对古籍文本的主题分类推荐任务。
(4)主题推荐模型评估模块:将处理好的古籍文本语料按照8∶1∶1 分为训练集、测试集和验证集。通过详细的对比实验,计算各个模型的精确率(precision)、召回率(recall)、F1 值(F1-score)和准确率(accuracy),判断各模型主题分类推荐效果。最后,运用混淆矩阵(confusion matrix)判断本文模型在识别古籍文献各事件类型主题间的效果。
2.2 多视图融合
深度学习中的多视图融合(multi-view fusion)是指对同一研究对象从不同视图(视角)通过引入函数来模拟特定的视图,利用相同冗余视角来优化函数本身,结合不同视图间的互补性和协调性[44],对其实现信息补充,完成在分析或预测任务时处理不同类型(特征)的过程,从而提升模型整体的准确性。传统文本主题推荐仅从实体视图进行主题分类推荐研究,具有一定的局限性。由于实体词属性通常以人物、地点、事件等名词为主,仅能浅层次表达文本语义,缺乏考虑关系(触发词)与实体词间的位置关系对深层语义的描述。
为此,本文增设前提条件:古籍文本数据经过文本预处理和特征提取后所形成的特征向量V(d)符合
的计算方式。其中,文档d包含n个特征词和对应权重;ti表示文档d中第i个特征词;wi(d)表示特征词ti在文档d中的权重大小。
本文是对古籍文本进行主题分类推荐研究,结合古籍文本语料特征,选择主体、客体和关系三个核心视图进行多视图融合研究,其融合原理如图2所示。

图2 古籍文本语义特征多视图融合原理
以古籍文本《左传》(隐公四年)中“故/c 宋公/nr、/w 陳侯/nr、/w 蔡人/n、/w 衞人/n 伐/v 鄭/ns。/w”为例,主体视图特征提取为“宋公/nr、/w 陳侯/nr、/w 蔡人/n、/w 衞人/n”,客体视图特征提取为“鄭/ns”,关系视图特征提取为“伐/v”。由图2 可以发现,多视图融合算法将原本的主体视图(F1)、客体视图(F2)、关系视图(F3)有效关联融合为U1、U2、U3、U4、U5、U6和U7区域,其划分原理为
在本文所使用的多视图融合算法中,由于图2所示的7 个区域中,每个区域迭代次数不同,因此,需对不同区域设置不同权重系数进行区分。整个多视图融合区域划分为单层视图(U1、U2、U3)、双重交叉视图(U4、U5、U6) 和多重交叉视图(U7),其权重加权原理为
其中,S表示经过多视图融合后的特征向量;wi表示所处区域的权重系数;Vi表示进入不同区域的特征词向量。
2.3 预训练模型
古籍文本相较于传统自然语言,存在命名规则复杂化、语义歧义多样化等复杂性问题,且存在大量省略语句,大大加深了上下文之间语义的关联性。因此,需要对古籍文本进行领域数据夯实,构建契合语料需求的预训练模型,提升模型主题推荐效果。本文选择谷歌自然语言处理实验室2018 年提出的通过双向Transformer 捕获目标语句中双向关系的预训练语言模型[42]作为预训练模型。
古籍文本中的实体词在不同位置包含的语义不同,而BERT 模型的网络结构[42](图3)能够充分考虑词嵌入、句嵌入和位置嵌入的关系特征,较好补全分词后语义的完整性,增强字向量的语义表示,能够更好地保留原古籍文本所含的文本信息。其中,W1,W2,…,WN为BERT 模型的输入向量,V1,V2,…,VN为BERT模型的输出向量,Trm 表示Transformer编译器。本文通过BERT 模型预训练古籍文本语料知识,结合多个Transformer 双向编译器对古籍文本字符进行位置编码和语义编码,并对分词做注意力机制加权赋值以获取词间关联性、捕获上下文语义。Trans‐former 编码器结构[42]如图4 所示,其由N组自注意力机制(self-attention)和前馈神经网络(feed for‐ward)构成,通过计算输入BERT 模型的字向量矩阵的值矩阵(value,V)、键矩阵(key,K)和查询矩阵(query,Q)捕获古籍文本不同词间存在的关联性和重要性,其计算公式为
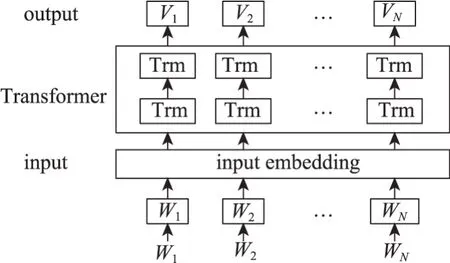
图3 BERT模型的网络架构[42]
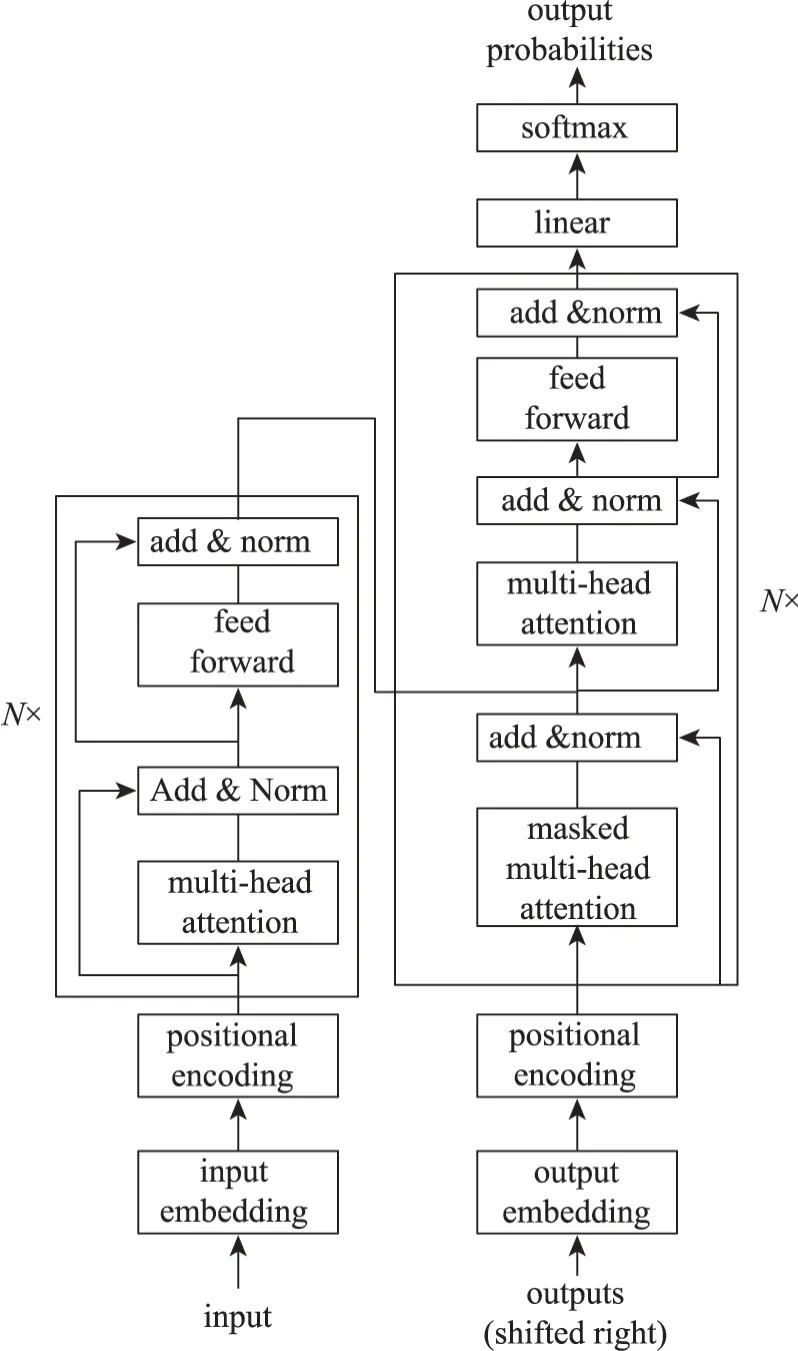
图4 Transformer编码器结构[42]
考虑到《左传》文本多为短语句,在此设定输入向量dk的维度为5。
2.4 DJ-TextRCNN模型
卷积神经网络(CNN)通常被认为属于计算机视觉领域,直至2014 年,Kim[45]对CNN 模型的输入层进行变形,将原本需要输入二维图像数据变形为输入一维自然语言, 提出了文本分类模型TextCNN。TextCNN 模型旨在通过降低神经网络的模型参数、简化任务烦琐度,实现对局部文本数据的特征提取,并根据卷积核大小实现不同细粒程度的文本分类任务。由于TextCNN 模型是依据CNN模型变形而成的,因此,存在全局池化层易造成结构信息丢失的问题,且无法获取长文本中上下文语义间的关联性和特征词的强度分布。2016 年,Liu等[46]在循环神经网络(RNN)基础上提出TextRNN模型,旨在运用RNN 捕获文本语料的时序特征,解决捕获长序列上下文语义依赖关系的问题。由于TextRNN 模型是依据RNN 模型变形而成的,需进行大量参数调整,并行效果较差且运行速度慢。针对TextCNN和TextRNN的局限性,Lai等[9]提出TextRCNN模型,结合TextRNN 捕获文本时间序列的特征,构建双循环神经网络实现对上下文语义特征的提取;结合TextCNN 利用最大池化层,实现对目标语料的细粒度特征提取,从而实现文本分类任务。
但古籍文本中的主体、关系和客体中存在大量的词性兼类现象,以古籍文本《左传》中关系(触发词)“朝”为例。
(1)“朝”的一般用法,主卑宾尊,后接宾语、受事宾语(“王,公”或者某个政治团体),译为“朝见,拜见”[47],在《左传》中,多指以卑见尊,共计出现146 次,其中后接受事宾语28 次(郑伯如周,始朝桓王也。[隐公六年])[48];后接代词“之”1 次(凡诸侯即位,小国朝之,大国聘焉。[襄公元年])[45];后接“于”补宾语23 次(而随蔡侯以朝于执事。[文公十七年])[47];后接修饰语“焉”3 次(吴将伐齐,越子率其众以朝焉。[哀公十一年])[47];宾语省略85 次(七人执郑詹,郑不朝也。[庄公十七年])[48]。
(2)“朝”的使动用法,主尊宾卑,译为“使……朝见”[44],共计出现10次(卫侯以国让父兄子弟,及朝众。[僖公十八年])[48]。
以关系(触发词)“朝”为例,使动用法(谓+宾)形式上与一般用法(谓+宾)很难区分,须在具体语境下才能识别。虽然两者都带宾语,但一般用法为受事宾语(“朝”的承受者),使动用法为使动宾语(“朝”的发出者)。无论受事宾语还是使动宾语,它们都为实体词(名词或名词性词组),需进行更深层次的语义挖掘。本文结合古籍文本的特点对TextRCNN 模型进行改进,构建如图5 所示的DJ-TextRCNN 模型。①利用多视图融合算法构建主体、关系和客体的特征融合,运用BERT 预训练模型进行特征向量转换;②构建TextCNN 模型并设置三类不同卷积核(2、3、4)和最大池化层实现对长文本典籍语料的初步语义局部特征提取;③结合BiLSTM 模型实现不同方向对同一特征词的长距离依赖关系和上下语义知识识别,加深对局部特征词的关联语义挖掘;④结合多头注意力(MHA)机制实现对主题分类推荐任务贡献度大的特征词聚焦,弱化常用词和无意义词造成语义歧义的影响,进一步提高整体模型的运行效率;⑤连接全连接层调用softmax 函数实现对古籍文本的智能主题分类推荐。下文将详细阐述DJ-TextRCNN 模型的优化原理。
考虑到模型全程对局部关键特征的加权处理和对关键特征词上下文语义信息的捕获,DJ-TextRCNN 模型的真实处理过程采用n-gram 分词进行古籍文本分词处理,可以较好地保存关键特征词的上下文语义信息和局部关键特征。通过将原本为单层的TextCNN 模型改进为卷积核分别为2、3、4 的三层卷积核(图5),实现通过三层不同卷积层的卷积滑动来提取古籍文本的局部特征。
在此做出前提假设:一个n维长度的古籍文本经过多视图特征融合后,可以表示为n阶k维词向量,即
其中,⊕表示向量拼接;xi表示第i个特征词对应的k维词向量。
CNN 模型通过设置卷积核分别为2、3、4 的卷积层对多视图融合的n阶k维词向量进行特征向量过滤,以实现局部特征提取。通过构建三层卷积核对上一阶段输入的n阶k维词向量矩阵进行卷积操作,滤波器根据多视图融合划分的不同区域进行关键特征提取,输出的新特征向量记作卷积层的计算过程为
由图5 可知,多视图特征融合后的古籍语料的特征词i对应的词向量为Vi,d表示卷积核的大小,wd表示对应大小的卷积核,bd表示偏置项。DJTextRCNN 模型选择的激活函数f为常用函数ReLU。
三层卷积处理后的新特征向量,通过映射得到古籍语料的局部特征集合Hd,映射过程计算公式为
DJ-TextRCNN 模型选择MaxPooling 技术实现对局部特征集合Hd的最大池化处理,将经过三层卷积层输出的古籍文本主题特征集通过最大池化层进行采样处理,并结合
实现对古籍文本特征集的局部特征最优解Mi的计算,降低数据维度,缩减特征向量和网络参数大小,减少无关计算量。
池化层提取局部特征最优解Mi后,为了方便后续BiLSTM 层进行更深层次的细粒度文本挖掘,将所得的局部特征最优解Mi组合形成输出向量X,输出方式为
通过公式(5)~公式(9)的三层CNN 模型处理,即可实现对古籍文本向量的深层次细粒度的特征提取,将其输出向量X作为后续BiLSTM 层的输入向量,完成对古籍文本主题语义特征的识别。
双向长短时记忆网络(BiLSTM)是由两条不同方向的循环神经网络(RNN)的变体长短时记忆网络(LSTM)组成的,其网络结构[38]如图6 所示。该模型通过记忆状态单元保留输入向量X的重要信息,遗忘次要信息,能够有效降低信息维度,较好地避免梯度爆炸(消失)现象的发生。

图6 BiLSTM模型网络结构[38]
以《左传》(文公十五年)为例,“曹伯来朝,礼也。诸侯五年再相朝,以修王命,古之制也”[47],触发词“朝”因为“来朝”[9]结构用法,隐含宾语,需要结合具体语境才能得知隐含宾语“晋”。考虑到上述语料情况在古籍文本中经常出现,DJ-TextRCNN 模型经过三层卷积核处理后的特征向量通过BiLSTM 模型能够更好地捕获典籍文本相同时间段的特征词的长距离依赖关系,还能较好地获取上下文语义特征和共现特征。
从图6 可知,BiLSTM 模型分别从前后两个方向对古籍文本语料的特征词进行深度训练,捕获各特征词的时序特征,结合上下文语境进行细粒度的古籍主题分类推荐。语义提取过程为
DJ-TextRCNN 模型的BiLSTM 层的最终输出结果yt所用激活函数f选择的是sigmoid,激活函数g选择tanh。以t时刻输入图6 模型的古籍文本的向量St为例,上层LSTM 层获取输入上文序列信息(Lh0,下层LSTM 层获取输入下文序列信息wn表示各位置的权重参数。
古籍文本的文本挖掘对模型具有较高的语义理解要求,需全局语义理解。但BiLSTM 层输出的结果yt存在些许冗余信息和噪声数据,需引入注意力(attention)机制进行特征精调,减少无关参数,降低模型整体计算压力。传统注意力机制侧重于归一化处理当前位置的注意力权重,以权重和的形式表示整个句子的隐含向量,无法考虑上下文语义对当前位置的语义影响,不适合古籍文本的语义挖掘。针对古籍文本侧重于对上下文语义信息关联性和局部关键特征的高要求,DJ-TextRCNN 模型在BiLSTM 层后引入多头注意力(MHA)机制,网络结构[43]如图7 所示。
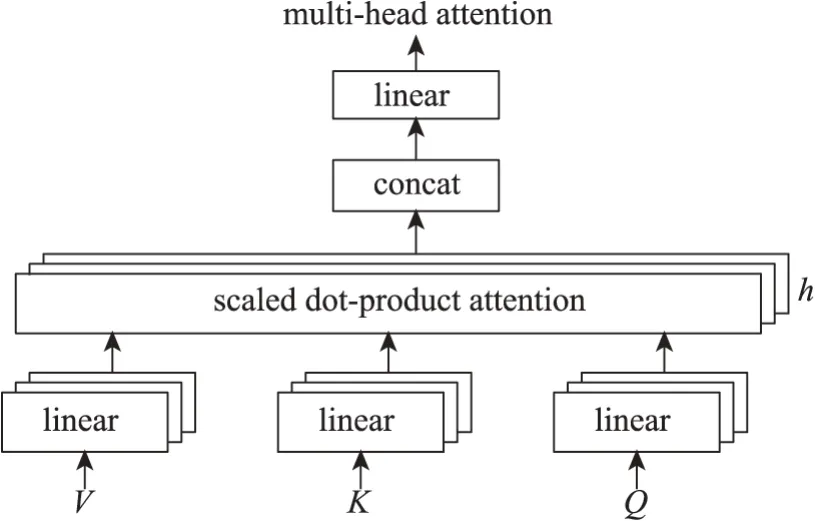
图7 多头注意力机制网络结构[43]
多头注意力机制将先前处理好的结果矩阵yt作为输入,通过线性变换转化为三个维度相同的矩阵:值矩阵(V)、键矩阵(K)、查询矩阵(Q)。第i个线性变化下Qi、Ki、Vi对应的转移矩阵分别是即
对Qi、Ki、Vi进行缩放点积注意力计算,将三个矩阵融合为单个注意力矩阵hi,计算过程为
其中,dk为三个矩阵的维度,能够防止出现梯度爆炸或超负荷计算。
最后,将计算出的多个注意力矩阵hi进行拼接,通过
对其实现线性变化,得出t时刻下典籍文本特征矩阵Mt(Q,K.V)。其中,C表示连接操作;WO为变换矩阵。
3 实验分析
本文采用Keras 和TensorFlow 深度学习框架构建神经网络模型,编程语言为Python 3.9。对本文提出的DJ-TextRCNN 模型能否实现更细粒度、更深层次、更多维度的古籍文本语义挖掘并提升主题推荐的准确性进行详细对比实验,以验证DJ-Text RCNN 模型的优势。
3.1 实验环境及数据集
为提高整体算力,本文采用GPU 加速器满足深度模型对算力的需求。实验环境方面,采用Win‐dow11 64 位操作系统,CPU 为Inter(R) Core i9-12900H,内存为64 GB,GPU 为NVIDIA GeForce RTX 3070 Ti Laptop,深度学习参数设置如表1所示。

表1 DJ-TextRCNN模型超参数设置
古籍文本作为中华传统文化传承的重要载体,是中华五千年文化智慧的结晶,能较好地反映我国源远流长的文化底蕴。然而,现代文本与古籍文本在语言表达、文字风格和文字形式上的差异,在一定程度上制约了古籍数字人文研究的发展。相比于现代文本风格平实、表达简洁、语句精练的特点,古籍文本侧重于将情感渗透在文字中,更注重风格古雅、表达抒情、语句押韵,需结合古籍文本的文字格式、表达方式、文字风格进行与之对应的特征提取。
《左传》原名《左氏春秋》,也被称为《春秋左氏传》,是先秦六十部典籍中我国首部叙事详尽的编年体史书,与《公羊传》《谷梁传》并称“春秋三传”,其在典籍中的历史价值和地位是被普遍认可的。其始于鲁隐公元年(公元前722 年),止于鲁哀公二十七年(公元前468 年),详细记录了期间两百余年百家诸侯国所发生的真实事件,可作为研究春秋期间历史发展和社会发展的重要语料数据[10]。因此,选取《左传》作为实验的语料文本,对本文提出的多视图融合DJ-TextRCNN 的古籍文本主题推荐模型进行效果检验。
本课题组前期对古籍《左传》语料数据进行了系统的数据处理,包括自动分词、词性标注、语义标注、事件抽取、命名实体识别、实体消歧、语义关系抽取和触发词识别;尝试通过构建中华文化知识表达体系实现面向大众的查询应用、面向学者的人文议题助力以及面向产业的古籍内容活化[49]。前期大量的语料预处理研究保障了本文所使用的数据语料的精准性,中华文化知识表达体系的构建也为本文的研究思路提供了理论支撑。
本文使用本课题组前期标注的《左传》语料数据[46]进行对比实验论证,按照8∶1∶1 分为训练集、验证集和测试集,如表2 所示。

表2 典籍文本数据集主题类型分布
但在本课题组前期的面向大众的查询应用中,仅以实体(人物、地点、事件)为中心,缺乏尝试不同视图相融合的、更为全面的查询应用;前期的面向学者的人文议题助力,分别从人物合作网络、团体对抗网络、人口流动路线、事件空间分布四个角度进行分析研究,缺乏考虑事件背后潜在的深层次真实原因的探究;前期的面向产业的典籍内容活化利用,分别从宴请饮食、兵器考述、事件重现、社会画像的单维度事件叙述进行活化,重现典籍所记录的历史事件,但仍欠缺一种对事件本身潜在主题推荐的活化应用[49]。针对上述不足之处,本文在前期研究的基础上尝试融合“主体、关系、客体”三个视图,对其语义潜在信息进行更深层次、更细粒度、更多维度的主题推荐应用研究。本文的研究成果有效解决了科研工作者筛选领域研究主题时面临的困难,为古籍文本的领域主题研究提供了数据支撑,对中华文化深层次挖掘起到了一定的指导作用。
3.2 评价指标
古籍文本主题分类推荐实验采用四个常用于文本分类的评价指标评价本文提出的DJ-TextRCNN 模型的鲁棒性,分别是精确率(precision)、召回率(recall)、F1 值(F1-score) 和准确率(accuracy),各评价指标计算公式为
其中,TP(true positive)表示正确识别的正确样本数量;FP(false positive)表示错误识别的错误样本数量;TN(true negative)表示正确识别的错误样本数量;FN(false negative)表示错误识别的正确样本数量;accuracy 表示预测正确的数量占总预测量的比值,能直观地评价所使用模型判断《左传》语料主题的准确性。
3.3 无视图的主题推荐结果分析
为提升各模型对比实验的真实性和说服力,本文采用10 次交叉实验结果的平均值作为模型效果的评价结果,从而避免单次实验产生的噪声对实验结果的误判。
本文提出的DJ-TextRCNN 模型的《左传》主题分类效果与机器学习(decision tree、random forest、logistic regression、SVM、multinomial navie Bayes)、深度学习(LSTM、GRU、TextCNN、TextBiRNN、Tex‐tRCNN、TextAttRCNN)、Transformer 模型(BERT‐CNN、 BERTLSTM、 BERTRCNN、 BERTattRCNN)的对比结果如表3 所示。

表3 非多视图下各模型实验效果对比
由表3 可以发现,本文提出的DJ-TextRCNN 模型在《左传》主题分类推荐任务中能够取得较好效果,其精确率、召回率、F1 值和准确率分别是76.15%、75.96%、75.92%和75.96%,比现有主流模型均有一定程度的提升。相比于机器学习模型中效果最佳的SVM,DJ-TextRCNN 模型的准确率提升了50.02 个百分点;相比于深度学习模型中效果最佳的TextCNN,DJ-TextRCNN 模型的准确率提升了7.56 个百分点;相比于Transformer 模型中效果最佳的BERTAttRCNN,DJ-TextRCNN 模型的准确率提升了1.06 个百分点。实验结果表明,融合BERT 的Transformer 模型效果普遍优于机器学习和深度学习模型,其主要原因是BERT 预训练模型拥有大量参数,能够更好地表示《左传》知识。相较于其他Transformer 模型,DJ-TextRCNN 模型中的三层CNN能实现更细粒度的文本特征提取,BiLSTM 网络能实现上下语义知识识别,多头注意力(MHA)机制能聚焦对主题推荐任务贡献度大的特征词。
3.4 多视图融合的主题推荐结果分析
为进一步分析Transformer 模型在不同视图下对《左传》主题分类的效果,本文分别从单视图(主体、关系、客体)、双视图(主体-关系、主体-客体、关系-客体)和多视图融合(主体-关系-客体)进行对比分析,结果如表4 所示。

表4 多视图融合下transformer模型实验效果对比(单位:%)
由表4 可知,本文提出的多视图融合算法对融合BERT 预训练模型的Transformer 模型有着较好的提升效果,列举的五种模型的《左传》主题分类准确率平均提升了13.01 个百分点。单视图中,“关系”视图(触发词)提升最为明显,准确率平均提升了8.46 个百分点;“客体”视图(位于触发词后的实体)次之,准确率平均提升了7.01 个百分点;最后是“主体”视图(位于触发词前的实体),准确率平均提升了4.07 个百分点。双视图中,“关系-客体”视图提升最为明显,准确率平均提升了11.60 个百分点;“主体-关系”视图次之,准确率平均提升了10.89 个百分点;最后是“主体-客体”视图,准确率平均提升了8.56 个百分点。
本文提出的DJ-TextRCNN 模型的《左传》主题分类推荐任务在各视图下均取得最好的准确性,在“主体”单视图下的准确率为78.94%(效果提升了2.98 个百分点),在“关系”单视图下的准确率为83.38%(效果提升了7.42 个百分点),在“客体”单视图下的准确率为81.99%(效果提升了6.03 个百分点),在“主体-关系”双视图下的准确率为85.43%(效果提升了9.47 个百分点),在“主体-客体”双视图下的准确率为83.64%(效果提升了7.68个百分点),在“关系-客体”双视图下的准确率为86.23%(效果提升了10.27 个百分点),在“主体-关系-客体”多视图融合下的准确率为88.54%(效果提升了12.58 个百分点)。
综上所述,通过进一步对比分析《左传》主题分类结果样本,发现多视图融合算法对单位词位置特征的权重加权有助于BERT 预训练模型更好地捕获上下文语义信息,生成更为优质的向量特征,提升后续主题分类器对《左传》文本的主题分类推荐任务的准确率。本文提出的DJ-TextRCNN 模型在多视图融合的语义增强基础上,能有效学习“主体”“关系”“实体”视图的特点,实现对《左传》文本语义知识的深层次挖掘,进一步提升整体模型效果,且优于其他Transformer 模型,能较好地实现古籍文本主题分类任务,完成主题推荐。
3.5 多视图融合的不同主题推荐结果分析
本文以F1 值详细对比DJ-TextRCNN 模型在《左传》文本的政治、人物、地理、从属、军事、风俗、经济、外交八个主题下的分类推荐结果,如表5 所示。其中,多视图融合视图下的人物、地理、从属、军事、风俗、经济、外交主题推荐效果最佳, F1 值分别是 91.13%、 92.77%、 81.59%、89.71%、84.85%、87.85%、92.79%;“关系-客体”视图下的政治主题效果优于多视图融合视图效果,F1 值是82.05%。结合《左传》语料发现,政治类主题的语料多为省略句。例如,“將/d 墮/v 三/m 都/n,/w 於是/c 叔孫氏/nr 墮/v 郈/ns。/w”中“关系”视图为“墮/v”,“客体”视图为“三/m 都/n”和“郈/ns”,而“主体”视图的前半句为“空集”,后半句为“叔孫氏/nr”;但在语料中,前半句真实“主体”应为“仲由”,一定程度上造成了相比于“关系-客体”视图的语义缺失。后期再对省略句语料标注时,应结合文本内容补充省略知识,以提升模型准确性。
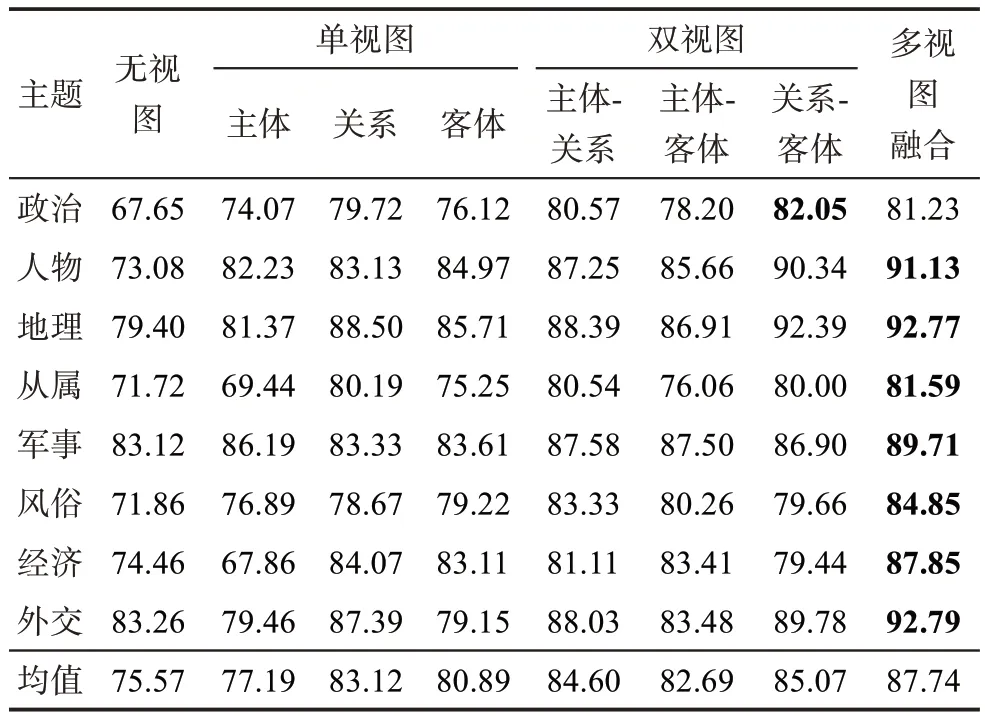
表5 《左传》不同主题下推荐效果评估(单位:%)
由表5 可以发现,本文提出的DJ-TextRCNN 模型能较好地实现对《左传》文本主题的预测和推荐,具有较好的鲁棒性和准确性。但后期需对文本实验语料中的省略句语料进行信息补充,减少视图信息空缺现象的发生,进一步提升多视图融合视图下模型预测的准确性。
本文根据《左传》文本主题方向的分类结果绘制了如图8 所示的混淆矩阵,其横轴为真实的主题类别,纵轴为预测的主题类别。其中,主题类别预测正确数最多的是地理主题,共预测正确263 句;从属主题次之,共预测正确262 句。预测错误最少的主题类别是外交,共错误预测9 句;地理主题次之,预测错误17 句。预测错误最多的主题类别是风俗,共错误预测38 句,其中14 句风俗主题被错误预测为政治主题,10 句从属主题被错误预测为人物。内容分析发现,标注为政治主题的内容分为四类,分别是“衝突殺戮”“築城”“叛亂”和“冊立即位”;标注为风俗主题的内容分为九类,分别是“見面遇見”“生養”“人物關係-態度”“婚姻”“宴請|飲食”“祭祀”“蔔筮”“製作”和“休閒”;标注为人物主题的内容分为六类,分别是“死亡”“人物特征”“疾病”“人物動作”“聽說告訴詢問”和“等待”。由于风俗类主题中包含的“見面遇見”与政治类的“衝突殺戮”中部分“衝突”类信息的语义接近,易造成模型误判;人物主题中包含的“人物特征”与风俗类的“人物關係-態度”类信息的语义接近,易造成模型误判。

图8 各主题方向混淆矩阵对比
综上所述,实验结果充分证明了本文提出的DJ-TextRCNN 模型在古籍文本主题分类与推荐任务中能进行更细粒度、更深层次、更多维度的语义挖掘,模型整体具有较好的鲁棒性和准确性;同时,体现了本文提出的基于“主体-关系-客体”的多视图融合的语义增强模型对典籍文本特征的权重加权,以及对模型整体精度提升的显著性。
4 结束语
面对古籍知识库中大规模的数字化古籍文献,依托传统编目分类和规则匹配的主题推荐方法不足以支撑当下数字人文研究的需求。为保障古籍科研工作者短时间内获取古籍文本主题的准确性,推荐符合其研究领域主题需求的古籍文本,本文参考并深入分析推荐算法,针对传统主题推荐方法仅从单一实体视图角度实现主题推荐,缺乏考虑古籍文本在语言表达、文字风格和文字形式上与现代文本的差异性,古籍文本的实体位置与触发词之间的关联性,古籍长文本数据间的上下文语义关联性,一定程度上会造成文本噪声现象的产生,以及较难实现对深层次文本特征的提取的问题,提出一种多视图融合DJ-TextRCNN 的古籍文本主题推荐算法,有效实现了古籍文本的自动分类,可为古籍研究者提供更精准的主题推荐服务。具体贡献如下。
(1)面对古籍知识库中大规模的数字化古籍文献,传统编目分类和规则匹配方法存在工作效能低、过度依赖专家知识、花费大量人力和物力成本、缺乏对古籍文本自身语义的深层次挖掘的问题。首先,本文通过BERT 预训练模型对处理好的典籍语料进行二次预处理,提升部分词的特征权重;其次,通过TextRCNN 的卷积神经网络(CNN)实现对局部文本语料的细粒度处理;再其次,通过TextRCNN 的循环神经网络(RNN)和双向长短时记忆网络(BiLSTM)捕获长文本语料中的局部特征及其上下文语义关联性;最后,利用多头注意力(MHA)机制实现对关键特征的权重加权,提升模型整体主题分类识别效果,最终实现对典籍文本的主题分类推荐任务。研究结果表明,本文构建的DJ-TextRCNN 模型在古籍文本的主题推荐任务中能够取得较好效果,其精确率、召回率、F1 值和准确率分别是76.15%、75.96%、75.92% 和75.96%,比现有主流模型均有一定程度提升。相比于机器学习模型中效果最佳的SVM,DJ-TextRCNN 模型的准确率提升了50.02 个百分点;相比于深度学习模型中效果最佳的TextCNN,DJ-TextRCNN 模型的准确率提升了7.56 个百分点;相比于Transformer 模型中效果最佳的BERTattRCNN,DJ-TextRCNN 模型的准确率提升了1.06 个百分点。因此,本文构建的DJTextRCNN 模型能较好地完成对古籍文本的更细粒度、更深层次的语义挖掘。
(2)传统古籍文本研究仅从实体视图进行数字人文研究,具有一定的局限性。由于实体词属性以人物、地点、事件等名词为主,仅能浅层次表达文本语义,缺乏考虑关系(触发词)与实体间的位置关系对深层语义描述的影响。本文考虑到触发词与实体的互补,尝试融合主体(位于触发词前的实体)、客体(位于触发词后的实体)和关系(触发词)三个视图,更多维度地挖掘文本语义。研究结果表明,多视图融合下本文设计的DJ-TextRCNN 模型在各视图下均取得了最好的准确性。在“主体”单视图下的准确率为78.94%,效果提升了2.98 个百分点;在“关系”单视图下的准确率为83.38%,效果提升了7.42 个百分点;在“客体”单视图下的准确率为81.99%,效果提升了6.03 个百分点;在“主体-关系”双视图下的准确率为85.43%,效果提升了9.47 个百分点;在“主体-客体”双视图下的准确率为83.64%,效果提升了7.68 个百分点;在“关系-客体”双视图下的准确率为86.23%,效果提升了10.27 个百分点;在“主体-关系-客体”多视图融合下的准确率为88.54%,效果提升了12.58 个百分点。同时,DJ-TextRCNN 模型多视图融合视图下在人物、地理、从属、军事、风俗、经济、外交主题推荐效果最佳,F1 值分别是91.13%、92.77%、81.59%、89.71%、84.95%、87.85%、92.79%;“关系-客体”视图下的政治主题推荐效果优于多视图融合视图效果,F1 值是82.05%。因此,本文提出的“主体-关系-客体”多视图的特征融合算法能够辅助DJ-TextRCNN 模型实现更多维度的语义挖掘,进一步提升模型的准确性。
总体而言,DJ-TextRCNN 模型中的三层CNN 能够实现更细粒度的文本特征提取,BiLSTM 网络能实现上下语义知识识别,多头注意力机制能聚焦对主题分类任务贡献度大的特征词,通过多视图融合权重加权,DJ-TextRCNN 模型能够实现对古籍文本更为全面、更细粒度、更深层次的语义挖掘,在一定程度上提升主题推荐的准确性,加快古籍研究者对单一主题的语料采集速率,缓解研究压力。考虑到本文在实验过程中发现主题子分类下存在语义相似主题以及文本语料中存在省略句现象,未来,一方面,本文将补全省略句缺失的主体语料信息,提升模型整体精度;另一方面,将结合部分语义相似内容增设新主题,提出更精确的主题特征分类。
猜你喜欢
汉字汉语研究(2021年3期)2021-11-24
天一阁文丛(2020年0期)2020-11-05
天一阁文丛(2018年0期)2018-11-29
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
金桥(2017年5期)2017-07-05
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
