
地铁车站PM2.5 浓度自注意力混合预测方法研究
2024-02-04 03:19陈定宇高国飞
现代交通与冶金材料 2024年1期
陈定宇,高国飞,袁 泉
(1.北京城建设计发展集团股份有限公司,北京,100037;2.广州地铁设计研究院有限公司,广东 广州 510010)
引言
空气和人类的生活息息相关。随着工业化和城市化的不断发展,其过程中排放的空气污染物包括颗粒物、二氧化硫、氮氧化物等,这些物质可引发呼吸系统疾病。长期暴露于污染空气中,人们容易患上呼吸道疾病,如慢性支气管炎、哮喘等[1]。
作为发展中国家,我国当前空气污染较严重。我国正在经历由传统产业向新型产业结构转化。在这个过程中,对空气污染的控制和治理十分重要。
对PM2.5 浓度进行预测,考虑其对我国地铁车站的影响是一项重要的环境管理工作。首先,PM2.5 是细小颗粒物,可以进入呼吸道并深入肺部,对人体健康造成潜在威胁。通过预测PM2.5浓度,车站管理者可以提前警示旅客,尤其是老年人、儿童和患有呼吸系统疾病的人,采取措施来降低暴露风险。其次,高浓度的PM2.5 可能影响交通运营的正常进行。对PM2.5 浓度的预测可以帮助交通管理者调整列车时刻和提前发布警报信息,以减缓交通系统的运营受到的影响。然而,由于PM2.5 的不规则特性和复杂的影响因素,难以实现PM2.5 浓度的精确预测。近年来,研究人员已经提出了一系列PM2.5浓度预测模型。
长期以来对空气污染物浓度的预测,相关研究主要在于提高模型预测的精确性和稳定性,随着人工智能的发展,出现了许多预测空气污染物浓度的模型[2]。这些模型可以分为三类:化学模型、统计模型、人工智能模型。化学模型包括CAMx[3]、CMAQ模型[4]和LOTOS-EUROS[5]等。这些方法能够考虑许多化学动力学条件、反应指数和化学产物,实现污染物预测。空气污染预测的传统统计模型包括自回归综合移动平均(ARIMA)[6]、灰色模型(GM)[7]、逐步回归[8]、主成分回归(PCR)[9]、多元线性回归(MLR)[10]和其他回归模型,例如孟凡强等[11]用ARIMA 对我国五个城市的空气污染物指数进行预测,李颖若等[12]用MLR 实现对北京空气质量的评估。
基于人工智能的预测模型中包括单一的预测模型和混合预测模型,单一预测模型包括深度信念网络(DBN)[13]、卷积神经网络(CNN)[14]和长短期记忆网络(LSTM)[15]等模型,例如王洪彬等[16]将CNN 用于空气中苯浓度的预测。
考虑到单一模型预测的局限性,混合模型在空气质量预测中变得越来越重要。混合模型主要包括以下两种类型:一是简单混合模型,即将两个或者多个模型堆叠在一起进行预测,省略了数据前处理和优化,例如杨雨佳等[17]采用CNN-GRU 模型对臭氧浓度进行预测,刘媛媛等[18]采用了CNN-LSTM 对空气质量指数进行预测。二类是智能混合模型,此类模型结合了数据处理和优化算法,例如王菲等[19]使用ELM 和灰狼优化算法结合,实现了对空气质量的预测,刘炳春等[20]采用Wavelet-LSTM 模型对北京空气污染进行预测。目前PM2.5 浓度的预测的相关文献存在以下不足:第一,PM2.5 浓度时间序列通常包含长期依赖关系,其中当前时刻的浓度受前几个时刻的浓度和外部因素的影响,相关文献的模型可能会受到滞后特征的限制[21];第二,PM2.5 时间序列数据存在固有的随机性,难以预测,在模型预测完后仍会出现较大误差。
为了克服以上不足,本文提出了一种基于智能混合预测方法的集成和预测误差校正模型,旨在提高模型预测的精确性和稳定性,本文的主要工作如下:
(1)自注意力机制可以有效地捕捉时间序列的长期依赖关系,可以有效改善时间序列的滞后性。因此首先采用自注意力机制对时间序列中的关键信息进行捕捉,再用GRU 进行预测 。
(2)采用误差修正可以帮助提高预测的准确性,通过对预测结果进行修正,可以减少误差,使模型更加可靠。因此本文设计了DBN 模型用来校正带自注意力机制的GRU 的误差,并且将误差预测结果和原预测结果相加得到最终预测结果,实验结果表明,基于自注意力机制的GRU-DBN 误差修正模型提高了模型预测的稳定性和精度。
1 模型及方法介绍
1.1 本文模型结构
模型结构框图如图1 所示。
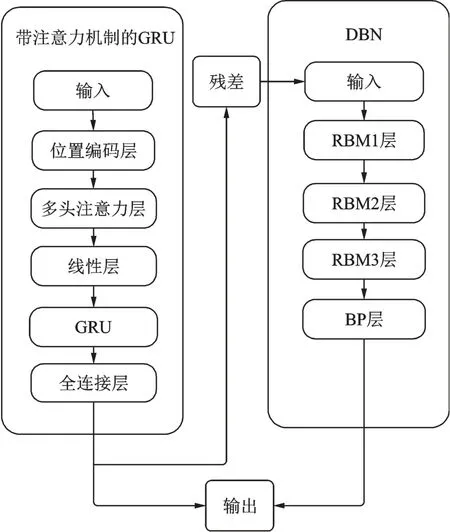
图1 模型框图Fig.1 Block diagram of the model
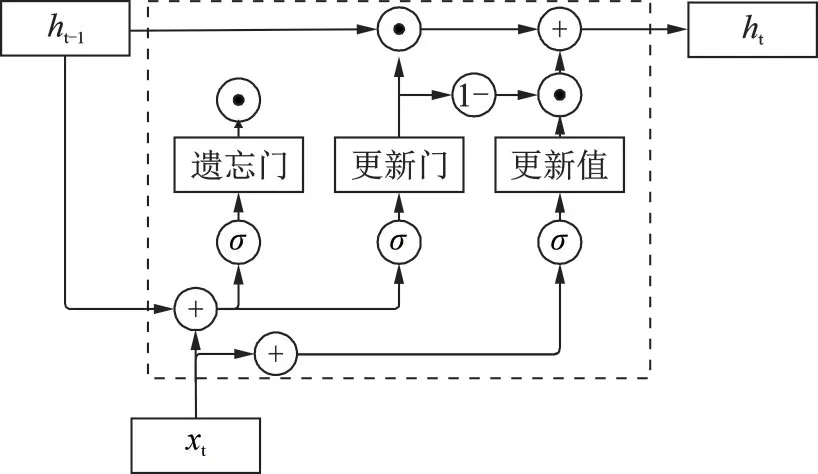
图2 GRU 网络结构Fig.2 Network structure of GRU

图3 DBN 网络结构Fig.3 Network structure of DBN
1.2 自注意力机制
注意力机制(Self-attention)可以通过计算注意力权重然后给输出向量动态生成权重,具体描述为将询问向量Q(query)、键值向量K(Key)和值向量V(value)映射到输出向量过程,输出向量是由Q和K计算过程产生的权重分配到值上产生的加权和。自注意力机制的点积模型公式如下:
由于模型在对当前信息进行编码时,会过度地将注意力集中于自身的位置,因此需要多头注意力机制解决这一问题,具体公式如下:
1.3 GRU
门控循环单元(Gate Recurrent Unit,GRU)[21]是RNN 的变种,解决了LSTM 不能长期记忆和反向传播中的梯度问题。GRU 比LSTM 的结构简单,GRU 包含两个门分别是更新门和重置门。
GRU 结构图如2 所示。
1.4 DBN
深度置信网络(Deep Belief Network,DBN)深度信念网络是一个概率生成模型,与传统的判别模型的神经网络相比,DBN 能够建立一个观察数据和标签之间的联合分布,拥有强大的无监督特征提取能力,DBN 由多个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)构成,最后一层为传统BP 神经网络。与传统BP 神经网络相比,DBN 学习速度更快,对数据的输入要求更低,精确性和稳定性更高。
DBN 网络结构和传统神经网络不同前面几层由RBM 构成,层内神经元无连接关系,结构图如3所示。
DBN 理论推导:
(1)输入层中,输入污染物数据至观察层v1,计算观察层神经元激活概率P(hj=1|v),从计算概率分布中利用 Gibbs 抽样法抽取样本hj~P(hj=1|v)。
(2)用隐藏层h1重新构建观察层并反推。计算隐藏层神经元激活概率P(vi=1|h),从计算概率分布中利用 Gibbs 抽样法抽取样本vi~P(vi=1|h)由v2再次计算隐藏层神经元激活概率并更新权重,并重复多次训练。
(3)利用 BP 算法用来进行有监督反向微调,目标函数为最小化重构输入与最初输入的均方误差:
式中n为样本个数,Yi为真实标准结果,为DBN 网络实际输出结果。
1.5 评价指标
论文使用统计学中常用的三个误差评估指标来定量评估模型的预测精度,即平均绝对误差(MAE)、RMSE 和平均绝对百分比误差(MAPE)。这三个评估指标如表1 所示。
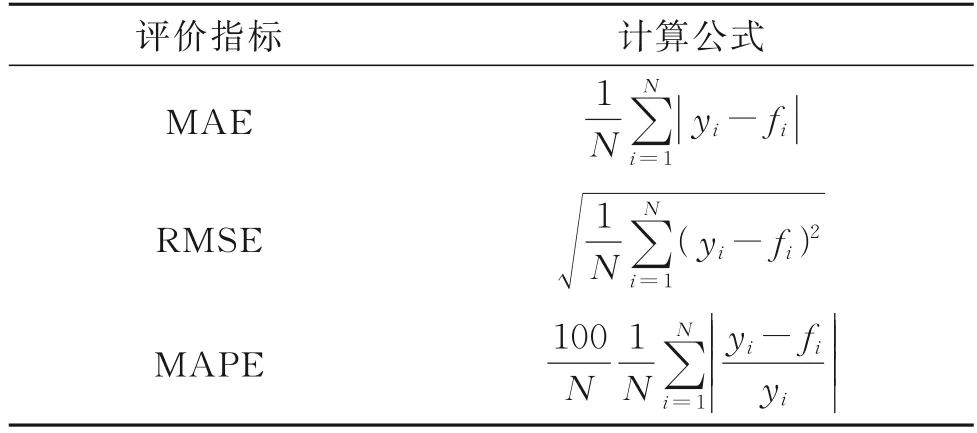
表1 评价指标表Tab.1 Table of evaluation indicators
2 实验步骤
因为PM2.5 时间序列受到多个因素的综合影响,包括但不限于温度、气压和风速等,仅仅依赖于复杂参数的单一预测模型很难有效拟合其变化趋势,导致预测精度不容易达到要求。因此,本文采用混合预测模型的方法,以更全面、综合的方式对序列进行预测。通过考虑多个影响因素的综合作用,本文混合模型有望提高预测的精确性,更好地捕捉PM2.5 浓度变化的复杂模式,满足更高的预测精度要求。该模型主要包括数据预处理,预测模型和模型评价:
步骤一:数据预处理,通过随机森林算法填补缺失值,用四组数据集分别来验证本文模型的性能,将数据集以8:2 的比例划分训练集{y1,y2,…,yt}和测试集{yt+1,yt+2,…,yt+n}。
步骤二:首先采用自注意力机制来捕捉合时间序列的关键信息。
步骤三:获得关键信息后,用GRU 对污染物时间序列进行预测。
步骤四:综合上述预测结果和原始序列得到残差e=y-,最后将残差用DBN 得到预测后的残差e',进行误差修正后形成最终的预测序列y*=+e',预测精度更高。
步骤五:用评价函数对模型进行评价,并且和现有的模型进行比较。
3 实验及模型评价
3.1 数据描述
本文以我国的四个交通枢纽(北京、天津、上海、广州)的污染物数据集作为研究对象。近年来我国交通枢纽的发展越来越快,研究其空气污染物预测模型对污染防治有着重大的意义。此次实验的数据来源于2022 年1 月 1 日~12 月 31 日24 小时PM2.5 数据,该PM2.5 数据均来自国家城市空气质量实时发布平台https://air.cnemccn:18007/中国环境监测中心。本文将数据分为四组来评价本文模型的性能,数据集均为8700 h(日期为2022.01.01~2022.12.31)的PM2.5 污染物数据,其中北京的污染物数据集为数据集1,天津的污染物数据集为数据集2,上海的污染物数据集为数据集3,广州的污染物数据集为数据集4。每一组按照8∶2 比例划分训练集与测试集,所有实验在Windows10 上的Python(3.9)四组数据集如图4 所示。

图4 四组原始数据图Fig.4 Plot of four sets of raw data
从图4 可以明显观察到PM2.5 浓度在特定时间段内变化较为显著,尤其是出现了较大的波动。这种复杂的时序变化使得单一模型的预测难以准确捕捉其真实趋势,导致预测的不精确性。因此,为了更有效地应对这种时序数据的多变性,需要采用混合模型来进行预测。
3.2 带自注意力机制的GRU 预测
在本节中研究了带自注意力机制的GRU 对PM2.5 浓度预测的影响,比较了带或不带自注意力机制的预测效果,四组数据集预测的平均MAE,RMSE、和MAPE 如图5 所示。
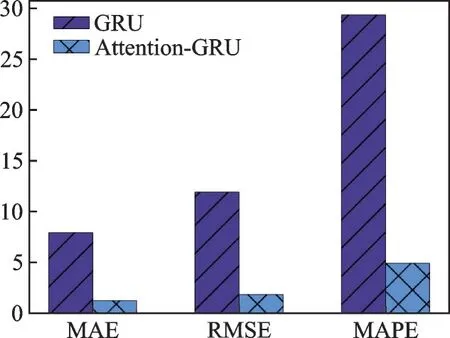
图5 有无注意力机制的预测效果比较Fig.5 Comparison of prediction effects with and without self-attention mechanism
由图5 可知,由于自注意力机制能够允许模型在处理序列数据时更灵活地关注不同位置的信息,而不受固定窗口大小的限制,这使得GRU 能够更好地捕捉序列中的长距离依赖关系,提高了GRU 时间序列预测的能力。
3.3 DBN 误差修正
在本节中,研究了DBN 误差修正对PM2.5 小时浓度预测的影响,误差预测结果如图6 所示。然后比较了四组数据,带或不带DBN 误差修正的模型之间取四组数据的MAE 比较如图6 所示,四组数据使用DBN 误差修正的改善百分比如表2 所示。从图6和表2 可以看出,在选定的四组数据集中,DBN 误差修正的使用可以提高整个模型的PM2.5 预测精度。
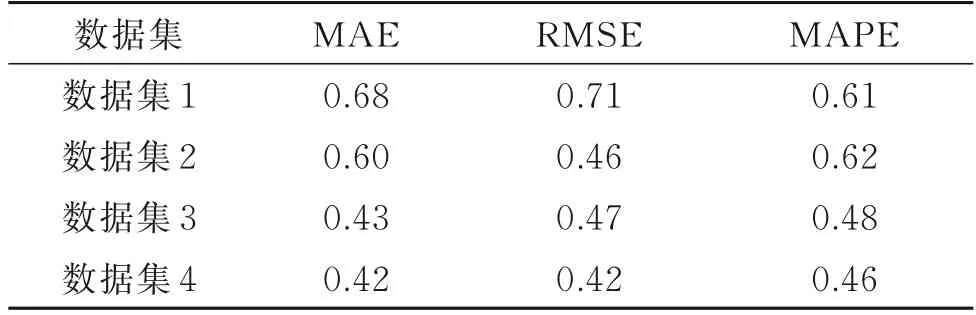
表2 使用误差修正的精度提升百分比Tab.2 Percentage improvement in accuracy using error correction
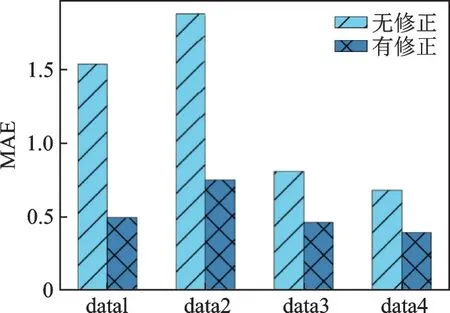
图6 有无误差修正MAE 比较图Fig.6 Comparison of MAE with and without error correction
由图6 可知,带有误差修正的模型比没带有误差修正的模型的预测精度高很多,说明用DBN 对模型预测结果进行误差修正是十分重要的。
由表2 可知,由于DBN 能够通过层级学习和特征提取,对输入数据进行有效地表征,这使得DBN在误差修正中具有优势,所以使用DBN 误差修正对前面的模型进度提升显著。使用DBN 误差修正后MAE 最高提升都达到了68%,RMSE 的最高提升达到了71%,MAPE 的最高提升达到了62%以上。
3.4 模型比较及误差分析
为了证明本文的预测方法的优势,将现有的五个空气污染预测模型与所提出的模型进行了比较。它们是DBN,GRU,Attention-GRU,极限学习机(ELM),回声状态网络(ESN)。为了更直观地显示本文的使用对预测结果的影响,图7~10 是选取平均精度最高的四个模型预测结果的散点图,当散射点的分布更集中于y=x线时,表明相应模型的预测结果更准确、更稳定。

图7 数据集1 的散点图Fig.7 Scatterplot of dataset 1
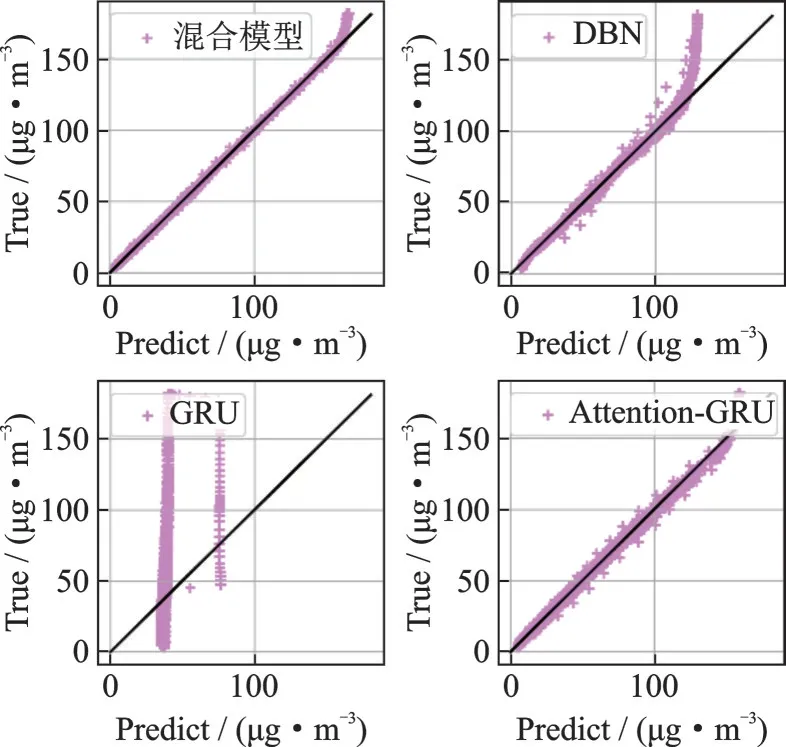
图8 数据集2 的散点图Fig.8 Scatterplot of dataset 2

图9 数据集3 的散点图Fig.9 Scatterplot of dataset 3

图10 数据集4 的散点图Fig.10 Scatterplot of dataset 4
由图中可以直观地看出本文模型图像的散射点比其他模型的散射点更集中于y=x线,带自注意力机制和DBN 的误差修正的模型对预测的精度有很大的提升,即本文提出的模型比现有的参照模型具有更好的预测效果。
本节还列出了各模型预测评价指标比较,如表3 所示。

表3 各模型预测评价指标比较Tab.3 Comparison of model prediction evaluation indicators
根据表3 可知:
(1)ELM 和ESN 都是相对简单的模型,通常在处理长时序列依赖关系时效果较差。对于复杂的时间序列,它们可能难以捕捉到足够复杂的关系,所以在本实验中更复杂的模型(深度学习模型)表现更好。ELM 和ESN 在上述四个数据集中表现不佳。
(2)由于DBN 逐层学习数据的层级特征,有助于捕捉数据的复杂模式,这使得DBN 在某些情况下能够更好地适应数据的复杂性,在本实验中的四个数据集中DBN 展现出比GRU 更好的效果。
(3)由于带有自注意力机制的GRU 在时间序列预测中的优势主要在于能够更好地处理长距离依赖关系,更灵活地调整对不同时间步的关注程度,以及更全面地捕捉序列中的特征和动态关系。这些特性使得它相对于普通的GRU 在PM2.5 时间序列预测任务上表现更好。在本实验中带自注意力机制的GRU 在四个数据集中的表现均优于GRU。
(4)本文的混合模型具有稳定且优异的性能,对于选定的四组PM2.5 数据的预测结果,与现有的五个模型相比,做出的预测精度都高于另外五个模型。这证明采用自注意力机制后和DBN 误差修正可以有效地提高模型的预测精度。
4 结语
本文提出了一种基于自注意力机制的GRUDBN 误差修正的PM2.5 浓度预测方法。选取中国的四个交通枢纽为研究对象,分为四组进行相关实验。本文提出的预测方法结合了自注意力机制、GRU 和DBN 误差修正。自注意力机制用来提取关键信息,GRU 用来PM2.5 时间序列预测,DBN 可以校正上一步的预测误差,以获得更准确的PM2.5 浓度预测结果。
实验结果表明:(1)本文提出的预测方法可以实现对每小时PM2.5 的较好的预测效果,四组数据的预测结果表明本文的预测方法优于相关文献中已有的五个模型,证明了本文建立的模型的优越性。(2)采自注意力机制有助于提取PM2.5 浓度时间序列的关键信息,达到更高的预测精度。(3)DBN 对预测误差进行修正可以提高模型对PM2.5 的预测精度,四组实验数据结果表明DBN 对预测误差进行修正对预测结果的改善显著。
本文建立的PM2.5 预测模型可以实现准确的预测效果,实现空气污染预警,帮助人们提前采取措施减少损失。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
Journal of Palaeogeography(2022年1期)2022-03-25
快乐语文(2021年35期)2022-01-18
今日农业(2021年11期)2021-11-27
环境科学研究(2021年6期)2021-06-23
环境科学研究(2021年4期)2021-04-25
少儿科学周刊·儿童版(2021年23期)2021-03-24
法律方法(2019年4期)2019-11-16
摄影之友(影像视觉)(2017年1期)2017-07-18
传媒评论(2017年3期)2017-06-13
