
多尺度融合卷积的轻量化Transformer无人机地物识别模型
2024-02-17 10:39张恒宾刘宏伟张兴鹏
郑州大学学报(理学版) 2024年1期
肖 斌, 罗 浩, 张恒宾, 刘宏伟, 张兴鹏
(西南石油大学 计算机科学学院 四川 成都 610500)
0 引言
与高空卫星遥感影像相比,无人机航拍影像具有成像分辨率高、大气因素干扰少等优点[1],更易区分建筑、汽车、树木等细小物体。因此,无人机航拍影像在小区域遥感应用方面具有很大的前景。在遥感图像中,语义分割方法能够很好地确定土地类型,提取建筑和道路信息。随着深度学习的发展,基于卷积神经网络(convolutional neural network, CNN)的全卷积神经网络(fully convolution network, FCN)[2]实现了像素级分类。SegNet[3]、UNet[4]等一系列网络进一步提高了语义分割的精度。Zhao等[5]使用无人机在100 m高度采集图像,并使用UNet识别小麦倒伏。然而,同一类地物可能具有不同的形状和大小,不同类地物也可能具有相似的特征[6],只利用光谱信息的模型不足以有效区分地物,还需要通过多个尺度的上下文信息进行辅助识别。由于FCN的卷积核感受野大小固定,不能获取足够的上下文信息,导致语义分割网络的分割精度不足。吴兰等[7]通过多尺度融合的方式有效地获取了上下文信息。
Vision Transformer(ViT)[8]舍弃了卷积运算,采用纯Transformer[9]架构对全局语义信息进行建模,使得模型有更大的感受野。然而,ViT在处理高分辨率图像时往往会产生巨大的参数量。例如,利用SETR[10]处理像素大小256×256的图片,参数量达到惊人的317 M。基于此,本文提出一种用于无人机遥感图像的多尺度融合卷积的轻量化Transformer模型,旨在研究Transformer在无人机遥感图像语义分割上的潜力。主要贡献如下:① 设计了一种轻量级的多尺度融合卷积方法,使得Transformer在计算自注意力时丢失的块内空间信息能够通过CNN得到补偿。② 设计了多尺度缩减键值序列的方式,可以有效减少自注意力计算的参数量,同时捕获远程、小型孤立对象。③ 设计了轻量级的多尺度MLP解码器,丢弃了不必要的卷积操作。实验结果表明,所提模型在Vaihingen和Potsdam数据集上性能有所提升。
1 相关工作
1.1 无人机遥感图像语义分割
遥感图像被广泛应用于众多领域,如车道线检测[11]、自动化农业[12]等。传统的遥感图像语义分割方式大多依赖图像的光谱信息和纹理信息。然而,不同的地物可能具有相同的光谱特征或者纹理特征,相同的地物也可能具有不同的光谱特征或者纹理特征[7],这导致传统分割方法的精度不足。而基于深度学习的语义分割方式不仅会考虑地物的光谱信息和纹理信息,还会考虑地物间相互关系,这使得遥感图像地物识别在效率和精度上得到提升。
目前,已有许多深度学习语义分割方法应用在遥感图像上。例如,Chong等[13]提出CFEM和IEM模块,增强了卷积网络区分小尺度物体和细化小尺度物体边界的能力。Ding等[14]使用轻量级的PAM和AEM模块,平衡了模型的特征表示能力和空间定位精度。然而,通过这些模块收集的上下文信息仍然不够,导致一些较小目标的分割结果并不太理想。
现有的语义分割方法大多集中在扩大有效感受野或者通过上下文建模的方式来获取足够的上下文信息。文献[15]中Deeplabv3+引入空洞卷积,通过扩大卷积核来扩大感受野。文献[16]中PSPNet引入PPM模块,通过上下文建模来获取足够的上下文信息。近年来,利用注意力机制来捕获远程上下文信息的方式开始兴起。文献[17]中DANet引入通道和空间注意力,提升了模型性能。
1.2 用于图像的Transformer网络
相比CNN,ViT这种基于全局语义相关性构建的模型在远距离特征捕获能力上具有更大的优势[18]。SETR将ViT作为语义分割模型的编码器,ViT将图片划分成像素大小为16×16的图片块,再将其拉直为序列,送入Transformer进行注意力计算。然而,ViT存在以下问题:
1) 在拉直为序列的过程中,图片块内部的空间结构遭到了破坏。
2) 当ViT用于大图像时,由于划分的图片块数量增加以及自注意力计算具有二次复杂度,导致计算成本相当高。
3) ViT作为序列到序列的模型,无法获得与常规CNN类似的多尺度特征图,这意味着其不能很好地获取图片粗粒度与细粒度的特征信息。
1.3 Transformer在图像领域中的轻量化方法
SETR自注意力计算的复杂度为O(n2),表明模型的计算复杂度会随着图像尺寸的增大而快速增加,这对于资源受限的无人机遥感任务并不友好。降低自注意力计算的复杂度是当前的一个研究热点。文献[19]中PVT引入SRA模块,通过卷积的方式缩减键值序列,减少了自注意力计算的复杂度。PVTv2[20]在PVT的基础上,将原有的SRA模块的卷积操作换成平均池化操作,进一步减少了自注意力计算的复杂度。Swin Transformer[21]通过新颖的分窗以及移窗操作,将原本基于全局的自注意力计算变为局部自注意力计算,可以将二次方的复杂度降为线性复杂度。
2 问题描述和整体框架
2.1 问题描述
本文通过语义分割的方式进行地物识别,向网络中输入原图,利用训练后的模型进行推理,从而得到与标签接近的预测图。模型的输入为X∈RH×W×3,输出为Y∈RH×W×Ncls。其中:H代表图片的高;W代表图片的宽;Ncls代表类别数量。
2.2 整体框架
模型整体结构如图1所示。采用双分支端到端的网络结构,上、下分支同时进行计算。
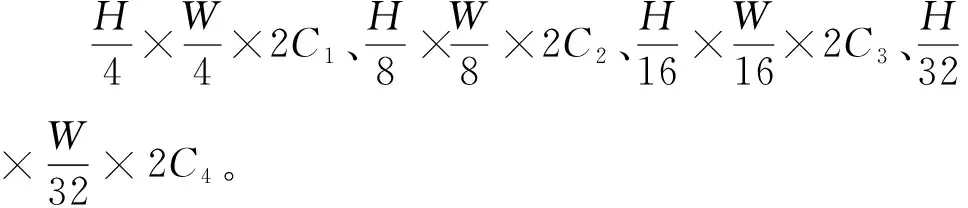
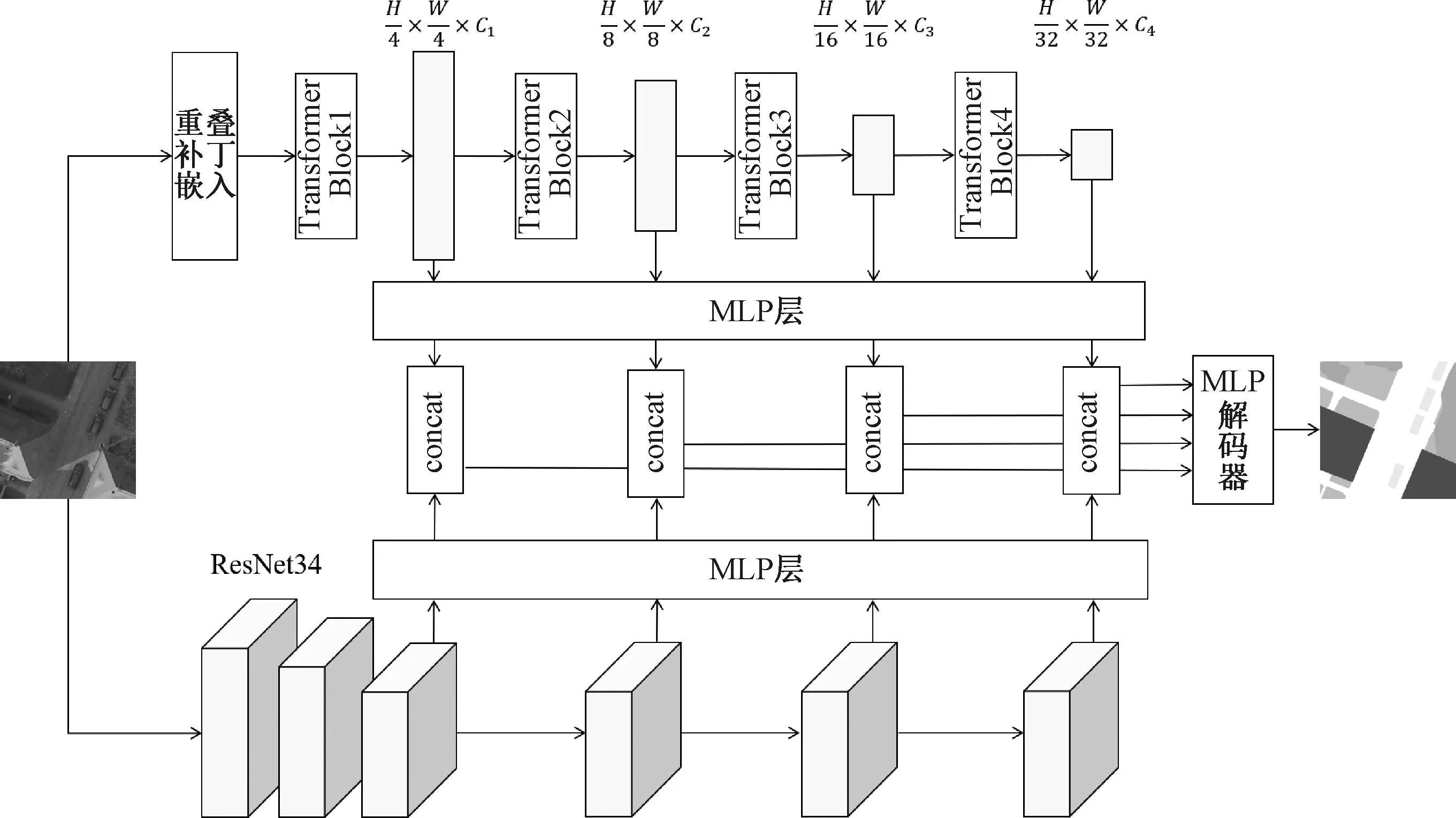
图1 模型整体结构Figure 1 Overall structure of the model
3 多尺度融合卷积的轻量化Transformer模型
3.1 多尺度融合卷积
由于只使用Transformer模块会丢失图片块原有的内部空间信息,使用预训练后的ResNet34来学习图片块丢失的内部空间结构信息。Transformer是直接基于全局语义相关性构建的模型,因此该模型能够获取足够大的有效感受野。为了减少模型参数以及尽可能保留Transformer获取的感受野,简单堆叠的MLP层被用来对特征图进行细微调整。同时,为了获取多尺度信息,模型融合了4个阶段的特征图。
3.2 缩减键值序列的自注意力Transformer
对于单个注意力模块,如图2所示,采用类似Segformer[23]的Transformer架构。
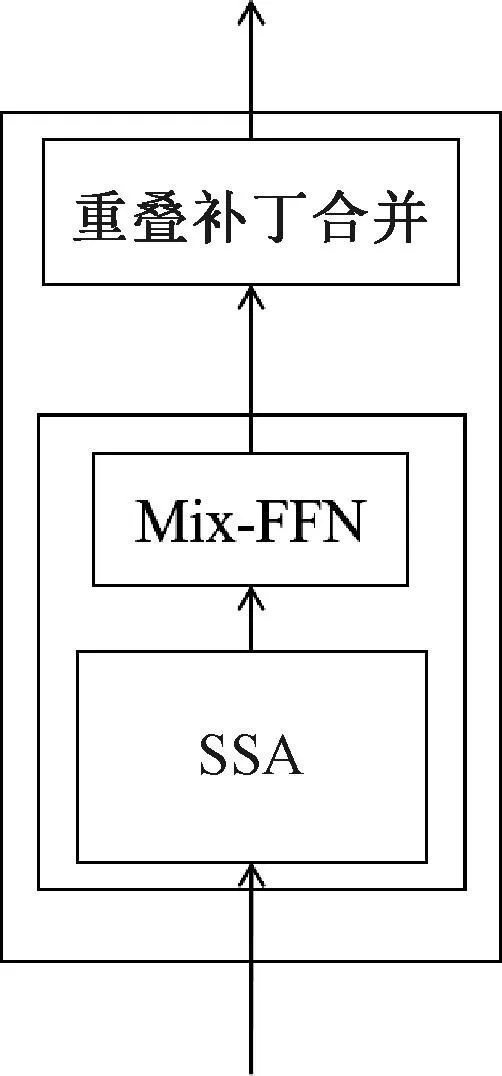
图2 Transformer模块Figure 2 Transformer module
由于原有SRA只在单一尺度上对键值序列进行缩减,这并不利于小物体的分割,使用分流的自注意力(shunted self-attention, SSA)[24]进行改进。SSA操作使用多尺度缩减键值序列的方式获取目标多个尺度的上下文相互关系,通过头部进行分组,不同的头部键值序列的缩减尺度不同。
假设头部索引为i,有
Vi=Vi+LE(Vi),
(1)
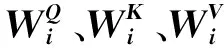
(2)
其中:dh表示维度。为了最大限度地轻量化模型,保留了Segformer原有的Mix-FFN设计。Transformer模块的整体计算过程为
XSSA=SSA(OverlapPatchEmbed(Xk)),
Xout1=MLP(XSSA),
Xout2=GELU(Conv3×3(Xout1)),
Xk+1=MLP(Xout2)+XSSA,
(3)
其中:Xk表示第k个输入特征图;XSSA表示经过SSA计算后的输出;Xk+1表示Transformer模块的输出;OverlapPatchEmbed(·)表示通过跨步卷积对图像进行分块;MLP(·)表示全连接层;Conv3×3(·)表示3×3的深度卷积;GELU(·)表示激活函数[25]。
3.3 多尺度MLP上采样模块
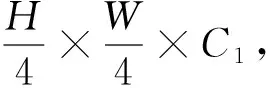
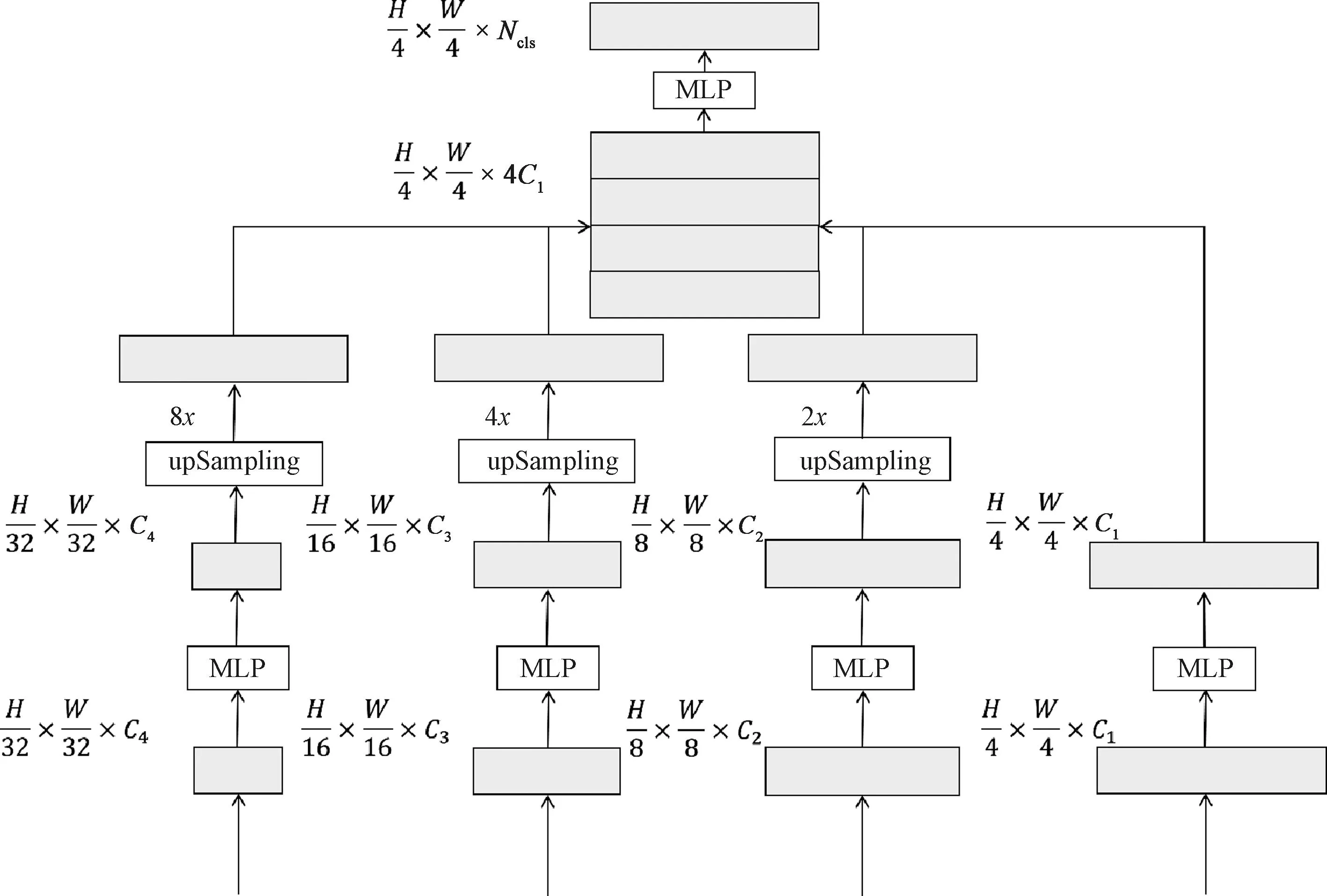
图3 MLP解码器Figure 3 MLP decoder
4 实验设置
4.1 数据集
实验使用国际摄影测量与遥感协会(ISPRS)的Vaihingen和Potsdam数据集,其数据都是由无人机在城市上空进行多次拍摄获得的,拍摄地点为德国的Vaihingen和Potsdam两个城市。数据集包含6种常见的土地覆盖类别,分别为树木、汽车、建筑物、低矮植被、不透水平面和其他。
Vaihingen数据集包含33张图片,其中16张图片具备标注信息,图片的平均像素大小为2 494×2 064,地面采样距离为9 cm。将12张图片作为训练集,4张图片作为测试集。此外,每幅图像包含近红外波段、红色波段、绿色波段三种波段。
Potsdam数据集包含38张图片,其中24张图片具备标注信息,每张图片的像素大小为6 000×6 000,地面采样距离为5 cm。将18张图片作为训练集,6张图片作为测试集。将所有图片切分为256×256像素大小,使用随机水平和垂直翻转数据增强操作。
4.2 评价指标
采用ISPRS的官方评估方法,所用评价指标为整体准确度(OA)、F1值以及交并比(IoU)。
OA的计算公式为
(4)
其中:TP、TN、FP、FN分别代表真阳性、真阴性、假阳性、假阴性。
F1值的计算公式为
(5)
(6)
(7)
IoU的计算公式为
(8)
其中:Np表示预测集;Ngt表示图像的标签。
4.3 训练设置
实验通过pytorch1.10.1、python3.8实现,所有实验通过一张NVIDIA RTX 3090显卡进行训练。网络使用AdamW优化器,学习率为6×10-5,权重衰减为0.01。同时,采用power为0.9的“poly”学习率策略,迭代次数为3.2×105。对比算法均采用相同的训练策略。
5 实验结果
将本文模型与近几年具有代表性的模型以及基于ViT进行分割的模型进行比较,不同模型在Vaihingen和Potsdam数据集上的对比实验结果分别如表1、表2所示。其中,对最优结果进行了加黑显示。
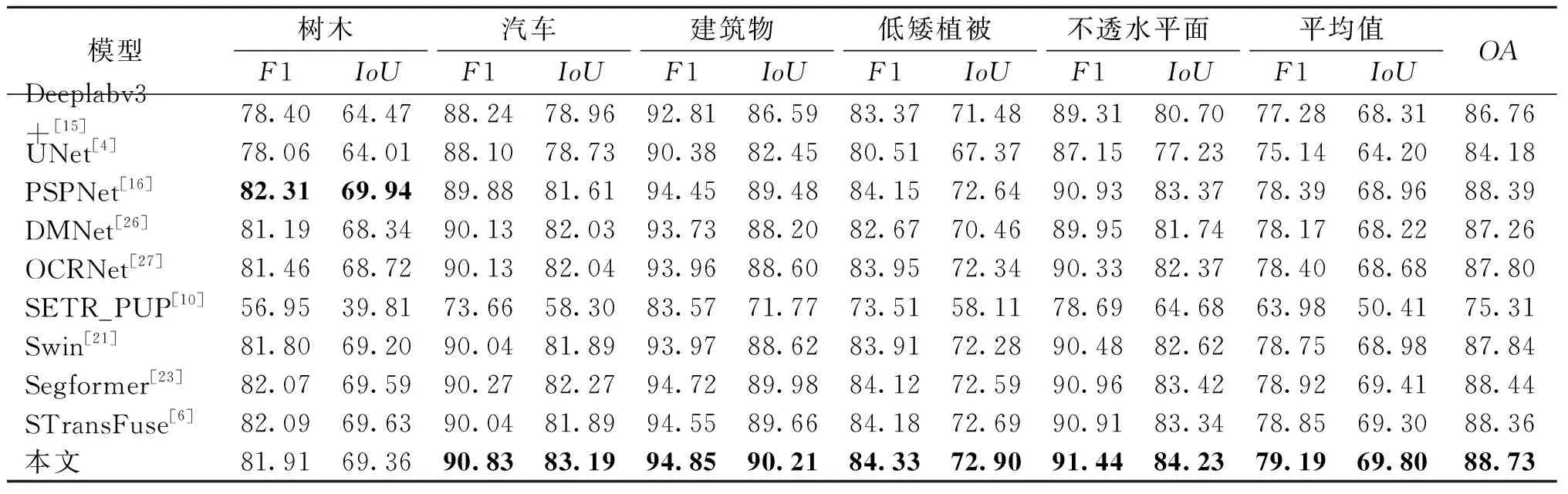
表2 不同模型在Potsdam数据集上的对比实验结果Table 2 Comparative experimental results of different models on Potsdam data set 单位:%
1) 定量比较
从表1、表2可以看出,在Vaihingen数据集上,本文模型的F1、IoU平均值分别比对比模型中的最优结果高出0.12%、0.02%。在Potsdam数据集上,本文模型的F1、IoU平均值以及OA值分别比对比模型中的最优结果高出0.27%、0.39%、0.29%。
如表1所示,除了SETR外,基于ViT的方法在OA值上普遍高于基于CNN的方法。这是由于通过Transformer的方式获取了足够的感受野,使得原来难以确定的边界通过其上下文信息能够进行较为精准的判断。同时,基于ViT的方法在类别数量较多时预测会更加准确。可以看到,在不平衡的数据集Vaihingen上,对于类别较多的建筑物,Swin Transformer达到了最好的效果;对于类别较少的汽车,反而是PSPNet达到了最好的效果。这是由于ViT将块拉直为序列的操作导致了这样的现象。建筑物类别具有数量多且尺度大等特点,拉直成序列后对于建筑物的影响并不是特别大。而汽车类别在划分的图像块中占比较小,尺度也较小,拉直成序列后块内结构信息损失严重,因此会更加难以判断。
主要有以下几个方面导致SETR的表现不佳:① SETR特征图大小没有发生变化,对于粗粒度和细粒度都以同一尺度特征图进行输出,难以获取粗粒度和细粒度的特征。② SETR未使用跨步卷积,而是直接切分成小块,切断了SETR中块之间的联系。③ SETR将切分好的图像块进行拉直操作,破坏了图像块的内部空间结构,对于小目标的识别十分不友好。
2) 定性比较
本文方法在类别较为平衡的数据集Postdam上取得了较为理想的结果,同时在不平衡的数据集Vaihingen上也取得了总体不错的效果。从表1可以看出,本文方法在一定程度上缓解了类别不均衡的问题。对于数量较多的建筑物类别,本文方法相较基于CNN的方法也有明显的优势,这是由于通过双分支的方法能够将Transformer和CNN的优点进行有机融合。
对Vaihingen和Potsdam数据集的部分实验结果进行了可视化,分别如图4、图5所示。可以看出,对于Vaihingen数据集,本文方法对阴影部分具有很好的处理能力,这得益于Transformer与CNN的有机结合获取了足够大的感受野;对于Potsdam数据集,在原图上光谱信息相似的地方(例如第2张图中的树木和低矮植被),由于能够有效获取上下文信息,模型能够较好地对这些地方进行分割。

图4 Vaihingen数据集实验结果可视化Figure 4 Visualization of experimental results on Vaihingen data set

图5 Potsdam数据集实验结果可视化Figure 5 Visualization of experimental results on Potsdam data set
不同模型在Vaihingen和Potsdam数据集上的参数量如图6所示。可以看出,本文模型是使用Transformer的网络模型中参数量最少且效果最好的。在Potsdam数据集上,与双分支网络STransFuse的参数量(86.99 M)相比,本文模型的参数量为71.24 M,减少18%,这得益于SSA以及MLP解码器。
6 结语
本文提出一种多尺度融合卷积的轻量化Transformer模型,实现了Transformer与卷积网络的有机融合。利用改进后的Transformer获取了足够大的

图6 不同模型在Vaihingen和Potsdam数据集上的参数量Figure 6 Parameters of different models on Vaihingen and Potsdam data sets
感受野,同时又能结合卷积网络的优点,这使得模型在语义分割任务上获得了较大的优势。为了进一步补充图像粗粒度和细粒度特征,设计了多尺度缩减键值序列的注意力计算方式,加强了网络对于小目标的识别能力。由于无人机遥感任务通常硬件资源受限,采用了轻量级的多尺度MLP解码器网络以及添加了轻量级的MLP层来帮助融合Transformer和卷积网络。通过对比实验可知,本文模型在精度上相比其他模型有较大的优势。并且,本文模型相比基于Transformer的模型有更少的参数量。Transformer在遥感任务上拥有很大的潜力,未来将专注于轻量化Transformer,使其能够更加适应无人机遥感任务。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
开放教育研究(2020年2期)2020-03-31
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
外语学刊(2011年1期)2011-01-22
