
基于车辆外观特征和帧间光流的目标跟踪算法
2024-02-18 13:46李绍骞周经美赵祥模
应用科学学报 2024年1期
李绍骞,程 鑫,周经美,赵祥模
1.长安大学信息工程学院,陕西 西安 710064
2.长安大学电子与控制工程学院,陕西 西安 710064
目标跟踪算法在机器人视觉、视频监控和无人驾驶等领域有着广泛的应用[1],实现高精度和实时的目标跟踪是一项具有挑战性的任务。目标跟踪主要利用目标检测算法、数据关联[2]与运动估计算法[3-4]进行处理,首先,通过目标检测算法得到图像中目标的位置信息,之后通过数据关联与运动估计算法预测并更新目标整个运动过程的轨迹信息。在理想情况下,整个运动过程中目标ID 的变换周期与目标出现到消失的周期相同,并且在这一周期内ID 不发生变换[5]。但是道路环境复杂、车辆目标之间的频繁遮挡和相似的外观导致跟踪算法的准确率降低[6],并且多数目标跟踪算法仅采用预设参数作为目标整个运动过程的运动状态参数,因此,寻找一个更具有普适性的参数来描述目标运动的状态,对提升目标跟踪算法的准确率具有重要意义。
1 相关工作
为解决上述提到的频繁遮挡以及相似外观带来的跟踪算法准确率降低等问题,目前常用的方法是通过深度学习模型来提取目标外观特征,然后计算目标的外观相似性。例如,可以将卷积神经网络(convolutional neural network,CNN)集成到经典的目标跟踪算法中提取目标的外观特征,在后续的跟踪过程中利用不同目标之间的外观特征计算两者间的外观相似性来重新识别对象[7],进而完成相同目标之间匹配的任务。常见的跟踪算法DeepSORT(simple online and realtime tracking with a deep association metric)采用检测和Re-ID 模型分离的策略实现跟踪,相较于联合检测和Re-ID 模型[8-10]的跟踪算法,分离策略的模型更加简单,且耦合性更低,因此本文选择检测和Re-ID 模型分离的DeepSORT 作为跟踪的基础算法。
光流描述的是连续两帧之间的运动信息。在深度学习未应用于计算机视觉领域之前,通常利用Horn-Schunck 和金字塔LK(Lucas-Kanada)计算图像间的光流信息,之后可以通过光流图进行展示,光流图中不同的颜色以及颜色的深浅代表像素速度大小和方向信息。文献[11-12] 通过CNN 直接对两帧之间的光流进行预测,避开了传统算法需要优化的问题。文献[13]提出的PWC-Net(CNNs for optical flow using pyramid,warping and cost volume)通过卷积神经网络得到图像特征,从低分辨率开始估计光流,之后上采样到高分辨率,同时构建成本代价矩阵预测当前分辨率的光流,逐步得到最终分辨率的光流,后续很多光流算法基于此框架实现。文献[14] 提出的RAFT(recurrent all-pairs field transforms for optical flow)通过卷积神经网络逐像素点提取特征,构建4D 像素点关联性金字塔,通过像素点的4D 关联信息,利用门控循环神经网络迭代更新光流场。RAFT 通过不同尺度的光流相关性特征,解决了不同尺度光流估计不准确的问题。
随着CNN 的发展,研究人员首先将孪生网络应用于目标跟踪领域,通过基于端到端的全卷积孪生网络计算后续图像帧与第1 帧模板之间的相似度特征,进而解决目标遮挡的问题,但当图像出现多个目标交替遮挡时跟踪性能会大幅下降。文献[6] 提出的新型多目标跟踪网络,首先利用孪生网络提取待检测目标的外观信息,再通过光流和卡尔曼滤波计算得到运动信息,最后将目标与现有轨迹关联起来得到跟踪结果。近年来,Tracking-by-detection[7]已成为主要的跟踪范式,这得益于深度学习和目标检测技术的成熟。Tracking-by-detection主要分为检测和关联匹配两步。首先对象检测器独立发现视频流中每一帧的潜在目标,然后与上一步中得到的检测进行关联。Tracking-by-detection 根据位置或身份特征维护每个轨迹的状态,并根据其最后可见状态将当前帧检测与每个轨迹相关联[15]。文献[16] 提出的目标跟踪算法SORT(simple online and realtime tracking)首次在多目标跟踪问题上应用Tracking-by-detection 架构,该算法更加注重于实时在线跟踪,以Faster RCNN 作为目标检测算法,向跟踪器中输入前一帧和当前帧的检测信息,通过卡尔曼滤波算法和匈牙利算法关联前后两帧的数据,进而实现目标的跟踪,但这种方法的数据关联度量信息有限,无法满足遮挡情况下的目标跟踪需求。基于Tracking-by-detection 架构的方法需要两个模块都进行特征提取,实时性较差,为此文献[10] 提出的检测和跟踪联合(joint detection and embedding,JDE)算法将检测和跟踪模块集成到单一网络中进行训练,该方法能够通过单一网络实现分类、定位与跟踪任务,但较易产生误检。文献[17] 提出了一种基于卡尔曼滤波器和匈牙利算法的跟踪方法。该方法首先利用卡尔曼滤波器建立运动模型,然后利用匈牙利算法对目标间的关联进行优化求解。该算法在实时速度上具有明显优势,但当目标运动复杂且当前帧中目标检测丢失时,卡尔曼滤波器预测的边界框与输入不匹配,不可避免地会漏掉一些轨迹。
受上述文献启发,针对车辆目标跟踪任务,本文充分考虑目标跟踪算法静态预设参数的不确定性,设计了基于相邻帧光流变化的运动状态信息更新算法;考虑车辆目标运动过程中发生的遮挡和相似外观问题,设计了车辆外观特征提取模型,提出了基于车辆外观特征和帧间光流的目标跟踪算法。
2 跟踪算法流程
跟踪算法流程如图1 所示。选择相邻两帧图像作为RAFT 算法的输入,计算光流场变化并生成光流场变化图;通过YOLOv5 算法中的YOLOv5x 网络模型获得车辆目标框的位置信息;利用车辆目标框的位置信息对光流场变化图进行裁剪得到光流小图,即帧间光流;在卡尔曼滤波更新运动状态信息时利用帧间光流进行补偿进而得到更精确的运动状态信息,并利用车辆外观特征和交并比(intersection over union,IOU)完成轨迹匹配,实现目标跟踪任务。图2 为跟踪算法的详细流程图。

图1 算法流程图Figure 1 Algorithm flow chart

图2 跟踪算法详细流程图Figure 2 Detailed flow chart of tracking algorithm
2.1 关联帧间光流
光流法是计算相邻帧之间像素运动信息的方法,计算出的光流表示像素在时间域x和y方向上的运动变化。假设图像上的一个像素点(x,y) 在t时刻的亮度为I(x,y,t),根据亮度恒定假设,在t+dt时刻的亮度I(x+dx,y+dy,t+dt) 与t时刻的亮度相等,即
将上式右侧通过Taylor 展开可得光流基本方程
式中:u=dx/dt;v=dy/dt。u和v分别为图像像素在x和y方向的瞬时速度。
传统光流计算方法约束条件多、计算复杂,本文采取基于深度学习的RAFT 算法计算连续帧的光流。RAFT 使用共享权重的特征提取模块提取相邻图像特征,通过语义特征提取模块提取第1 帧图像特征用于后续光流更新迭代;同时,计算连续特征图对的内积,构建4D 关联矩阵和不同尺度的图像相似度特征,通过不同尺度的特征描述大位移和小位移信息;最后,通过门控循环单元(gated recurrent unit,GRU)对光流迭代更新,直至得到最终的光流。RAFT 算法流程如图3 所示。

图3 RAFT 光流提取算法流程图Figure 3 RAFT optical flow extraction algorithm flow chart
基于RAFT 算法得到的相邻帧间光流,设计了如图4 所示的运动状态信息更新模块,模块将卡尔曼滤波的状态更新参数修改为相邻帧的光流信息。为得到交通场景下目标的精确光流信息,降低检测框中杂乱背景的干扰,本文将生成的光流场变化图进行裁剪得到目标中心位置1/4 区域的光流小图,根据光流小图计算x、y两个通道的均值,得到每个目标的水平、竖直方向的瞬时速度,最终得到的8 维特征(包括目标检测框的位置特征和目标检测框的光流信息)。通过实时帧间光流信息替代目标跟踪算法中的静态预设参数的方式,得到了更加精细的目标运动状态信息,从而使目标跟踪算法能够满足不同的场景需求。

图4 运动状态信息更新模块Figure 4 Motion status information update module
2.2 车辆外观特征提取
DeepSORT 通过外观模型提取连续图像帧中目标外观特征作为目标匹配的度量单位,文献[17] 的实验证明,将外观特征与Mahalanobis 距离特征联合作为目标匹配的度量单位,能够有效提升目标跟踪的准确率和精度。但是,DeepSORT 训练的ReID 模型无法满足交通场景下的车辆目标跟踪需求,其采用的特征提取网络的CNN 结构如表1 所示。

表1 车辆外观特征提取网络结构Table 1 Network structure of vehicle appearance feature extraction
针对交通场景中不同的车辆目标,本文将CNN 结构中的最大池化层改为自适应平均池化层,以此来适应各种尺寸的车辆目标,同时,将原始的6 层残差网络修改为16 层残差网络,对应网络的输出特征维度从128 变为256。通过实验对比分析可知,加深卷积层的深度虽然能够强化外观模型的特征识别能力,但是模型也会增大。本文结合模型大小以及模型检测精度选择较为适中的16 层残差网络。
在训练车辆外观特征模型的过程中使用随机梯度下降(stochastic gradient descent,SGD)算法作为优化器不断调整梯度求解损失函数的全局最优解,即损失函数的最小值。一般情况下,若设置训练过程中的步长恒定不变则会导致随机梯度下降算法在函数具有多处局部最优解时陷入局部最优的情况,如图5 所示。

图5 SGD 算法寻优过程Figure 5 SGD algorithm optimization process
余弦退火调整学习率算法CosineAnnealingLR 可以解决随机梯度下降算法易陷入局部最优的问题。训练模型的过程中通过CosineAnnealingLR 算法中的Restart 机制,使得学习率降低到较低点时Restart 返回到原点,通过这种增大步长的方式跳出局部最小点,CosineAnnealingLR 算法的计算公式为
式中:i为运行的次数;分别为学习率的最大值和最小值,从而定义了学习率的范围;Tcur为当前执行的epoch 的次数;Ti为第i次运行时总的epoch 次数。
图6 为CosineAnnealingLR 算法的优化过程,当求解过程陷入局部最优时,CosineAnnealingLR 算法的Restart 机制会使得学习率跳出局部最优点。为了避免模型训练权重的随机性导致学习率震荡的问题,在训练过程中加入WarmUp 机制,训练初始阶段将学习率设置为0 并逐渐增大,即模型在训练过程中先预热,直到达到设定的阈值后开始正式训练。通过WarmUp 机制能够确保在权重达到稳定后再开始训练,进而使得模型的收敛效果更好。

图6 CosineAnnealingLR 寻优过程Figure 6 CosineAnnexingLR optimization process
2.3 关联帧间光流的目标跟踪算法
DeepSORT 相比于SORT 提出更加可信的关联度量和关联方法,其利用CNN 提取外观特征解决遮挡问题,并利用级联匹配为不同的目标分配优先级,对频繁出现的目标赋予高优先级来解决长时间追踪的问题。但是,DeepSORT 算法中描述目标运动状态信息的速度值是通过速度权重估计得出的,这可能使跟踪算法在不同场景下的表现差别较大,不具有普适性,本文算法在DeepSORT 基础上进行改进以解决该问题。DeepSORT 算法主要分为4 个步骤:
步骤1基于原始的图像帧序列,利用检测器获得目标的检测框信息和置信度信息;
步骤2通过卡尔曼滤波算法得到预测框,对检测框和预测框进行IOU 匹配并计算cost matrix;
步骤3使用匈牙利算法对所得的cost matrix 进行最优匹配;
步骤4输出跟踪结果,更新卡尔曼滤波的参数。
卡尔曼滤波预测目标下一帧的状态信息表示为(x,y,a,h,u,v,a′,h′),其中(x,y) 为目标检测框的中心坐标;a为检测框的长宽比;h为检测框的高;(u,v,a′,h′) 分别表示(x,y,a,h)对应的瞬时速度。得到上述状态信息后,通过马氏距离对检测框和预测框进行匹配,公式为
式中:yi为第i条轨迹的预测框;dj为第j个目标检测框;Si为通过卡尔曼滤波得到的协方差矩阵。通过χ2设置阈值判断预测框和检测框的相似性,公式为
式中:t(1)为χ2对应95% 置信度阈值,本文取9.487 7;当d(1)(i,j) 小于阈值时,取1,表示预测框和检测框关联成功,否则为0。为解决当被遮挡目标重新出现在图像中时ID 的变换问题,需要对一部分帧中的特征进行保存,由集合Fk表示,公式为
式中:Lk为存储特征的长度,本文设置为100。DeepSORT 选择最小余弦距离对外观特征进行度量,公式为
式中:d(2)(i,j) 为第i个关联轨迹与第j个检测框的外观特征最小余弦距离。为最小余弦距离的归一化结果,与利用马氏距离判断两者相似的方法类似,通过χ2设置阈值t(2),再根据d(2)(i,j) 判断是否关联,表示为
通过运动特征和外观特征构造关联度量函数,公式为
式中:λ为两种特征的比例系数。计算出来的ci,j越小表示第i条轨迹和第j个检测框相似性越大。算法中关联度量还涉及外观特征,通过使用WarmUp 结合CosineAnnealingLR 的方法在VERI-Wild 数据集训练车辆外观特征模型,保证外观特征的检测精度,为外观特征的度量提供了更加准确的外观特征提取模型。综合考虑运动状态特征和外观特征来判断第i条轨迹和第j个检测框是否关联成功,公式为
基于关联度量的结果利用匈牙利算法进行最优匹配。
运动状态信息是后续运动状态度量的重中之重,其中,状态信息中的x、y方向的速度由控制位置的方差权重和控制速度的方差权重估计得到。算法引入帧间光流,光流即相邻图像帧间像素在x、y方向的速度,通过实时计算连续帧间光流替换卡尔曼滤波过程状态信息中的速度量,融合光流后的运动状态信息相对于使用速度估计值的原始DeepSORT 算法所采用的运动状态信息,能够对算法的预测过程提供更有利的支撑。引入光流后状态信息转变为:(x,y,a,h,flowx,flowy,a′,h′),其中flowx和flowy分别为检测框中心坐标在x和y方向上的瞬时速度,a′为检测框长宽比的瞬时速度,h′为检测框高的瞬时速度。
3 实验分析
3.1 实验平台与数据集
实验均基于python 语言和pytorch 1.7.0 框架进行实现,实验操作系统为Windows 10,实验平台内存为32 G,CPU 为Intel Coffeelake I9-9900 CPU,GPU 为GeForce RTX 3090,显存24 G,CUDA 版本为11.0。
训练目标检测模型选择BDD100K 自动驾驶数据集,此数据集是目前规模最大、最多样化的开源数据集,由100 000 个视频组成,每个视频大约40 s,清晰度为720 P,视频刷新率为30 帧/s,总时间超过1 100 h,涵盖了交通场景中多种类的目标,并对道路上常见的目标标注边界框,与此同时,BDD100K 涵盖了道路上出现频次最高的Bus、Truck、Car 的3 种数据,能够满足模型应用于交通场景的需求。
训练车辆外观特征模型选择VERI-Wild 数据集,此数据集包含由174 个摄像头捕获的监控网络,覆盖区域超过200 km2,是第1 个无约束条件收集的车辆数据集,该数据集涵盖了4 万辆汽车构成的40 万幅图像,并且为每辆汽车分配了ID。同时,此数据集相对于VeRI-776数据集和VehicleID 数据集在视角、光照、背景和遮挡4 个方面更加复杂。
选择目标跟踪领域中最常用的MOT Challenge 数据集中的MOT16[18]验证跟踪算法的有效性,MOT16 共有14 个视频,训练集和测试集各有7 个,视频中的场景采用固定场景的摄像头和移动摄像头进行拍摄,不同视频的拍摄角度、天气、时间均不同,并且待跟踪目标群体密度较高。数据集提供了训练集的标注、训练集和测试集的检测结果,为目标跟踪任务提供了便利。另外,MOT Challenge 数据集主要侧重行人跟踪,本文主要利用该数据集验证所提出跟踪算法的有效性。
3.2 实验评价指标
为评估检测模型的性能,使用目标检测领域典型的评价指标平均精度(average precision,AP)和平均精度均值(mean average precision,mAP),同时,为评估目标跟踪算法的性能,使用目标跟踪领域典型的评价指标,包括多目标跟踪准确度(multiple object tracking accuracy,MOTA)、多目标跟踪精度(multiple object tracking precision,MOTP)、多数被跟踪轨迹MT(mostly tracked trajectories)、识别F1 值(Identification F1-Score,IDF1)和高阶跟踪精度(higher order tracking accuracy,HOTA)。
AP 指目标检测过程中准确率Pprecision和召回率Rrecall绘制的PR 曲线与x轴围成区域的面积,Pprecision和Rrecall的公式分别为
式中:TP 为正确检测到目标的数量;FN 为未正确检测到目标的数量;FP 为检测错误的目标数量。mAP 表示所有检测类别AP 的平均值,公式为
目标跟踪的指标主要有MT(mostly tracked),常用来指80% 时间内成功匹配成功的次数,另外本文还选用了MOTP,MOTA、IDF1 和HOTA,公式分别为
式中:mt为第t帧漏检的数量;fpt为第t帧误报数量;mmet表示第t帧匹配错误的数量;MOTA 是衡量跟踪算法性能最主要的指标,其值越接近1 表示算法性能越好。
IDF1 综合了目标重识别和位置两个方面的性能,能够更全面地衡量跟踪算法的综合性能,不仅考虑正确的匹配,还考虑了漏检和误检的情况。公式为
式中:IDTP 为真正的ID 数;IDFP 为假阳的ID 数;IDFN 为假阴的ID 数。
HOTA 综合了多个指标,包括误检率、漏检率、ID 混淆率、轨迹错误率以及目标重识别的准确率;HOTA 指标引入了目标重识别的准确率,能够更好地评估目标的外观变化问题。相关公式为
式中:prID(k)表示预测身份为k的目标;gtID(k)表示真实身份为k的目标;TPA(c)、FNA(c)和FPA(c) 分别表示身份为c的匹配目标、漏检目标和虚检目标。可以看到HOTA 指标不仅考虑了跟踪的准确性还关注了匹配目标的身份正确性,因此更能反映跟踪算法的综合性能。
3.3 车辆检测模型分析
综合考虑检测速度、精确度等多方面因素,选择整体检测性能较好的YOLO 系列算法,其中YOLOv5 具有检测准确率较高、算法运行速度快、应用成熟等优势,因此本文选择YOLOv5 算法作为目标跟踪中的检测器。YOLOv5 系列包含了4 种不同的网络模型,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,且这4 种网络模型的体积逐渐扩大,检测准确率逐渐升高。在BDD100K 的基础上,采用不同的网络模型进行训练,训练使用的数据集中包含100 000 万幅图像,训练集、测试集、验证集比例为7∶2∶1,网络训练超参数如表2 所示。

表2 网络训练超参数Table 2 Network training hyperparameters
主要关注Bus、Truck、Car 这3 个种类的平均精度、所有类别的mAP 和不同交并比阈值下的mAP。由表3 可知,在4 种网络模型训练得到的结果中,YOLOv5x 在Car、Bus、Truck这3 个类别上的AP 均高于其他3 种网络模型,同时mAP 也高于其他3 种检测模型。为进一步对比网络模型在真实场景中的检测能力,选取检测精度相对较高的YOLOv5l、YOLOv5x进行实际应用场景的测试。

表3 网络模型检测性能Table 3 Network model checking performance %
为直观展示检测模型的有效性,选取某高速隧道数据进行分析,图7~11 为不同场景下模型检测效果图,各图(a)~(c) 分别展示交通场景原图、YOLOv5l 网络模型检测结果图、YOLOv5x 网络模型检测结果图。在图7 所示的红色矩形选中区域内,YOLOv5l 将远处的car 检测为truck,YOLOv5x 模型正确检测;在图8 所示的红色矩形选中区域内,YOLOv5l检测模型相较于YOLOv5x 检测模型对car 检测的置信度更低,此外,YOLOv5l 检测模型误将墙壁上背景检测为目标;在图9 所示的红色矩形选中区域内,YOLOv5l 检测模型将truck检测为train 并且检测置信度较低;在图10 所示的红色矩形选中区域内,YOLOv5l 检测模型未检测出驶入图像范围内目标车辆,YOLOv5x 模型正确检测;在如图11 所示的红色矩形选中区域内,YOLOv5l 检测模型将路障检测为目标车辆,YOLOv5x 模型未发生此类问题。

图7 模型误检效果对比Figure 7 Comparison of model false detection effects

图8 模型误检效果对比Figure 8 Comparison of model false detection effects

图9 模型误检效果对比Figure 9 Comparison of model false detection effects

图10 模型漏检效果对比Figure 10 Comparison of model missing detection effect

图11 模型误检效果对比Figure 11 Comparison of model false detection effects
文献[17] 研究表明,检测模型作为“Tracking-by-detection”二阶段目标跟踪策略中的关键要素,对目标跟踪性能有18.9% 的影响。于是本文在BDD100K 的基础上,采用不同的网络模型进行训练,通过对比不同网络模型在检测指标、真实应用场景的表现,选择高准确率、强鲁棒性的目标检测模型。从定量和定性两个方面对不同网络模型的效果进行分析,得出YOLOv5x 检测模型能够解决误检、漏检、置信度低3 大问题,能够为目标跟踪算法提供精准稳定的检测基础。
3.4 车辆外观特征模型分析
采用WarmUp 结合CosineAnnealingLR 方法在VERI-Wild 数据集上训练车辆外观特征模型,表4 分别展示了采用DeepSORT 中的Deep 特征提取网络训练的车辆外观特征模型与经本文算法改进后的车辆外观特征模型在训练集和验证集上的精度,改进方法的准确率在训练集上提升了1.7%,在验证集上提升了6.3%。图12(a) 和(b) 分别展示了原方法和改进方法训练过程中Loss 的变化情况和Top1err 的变化情况,从图中能够看出原方法训练到第150 轮时收敛,改进方法训练到第120 轮时Loss 达到最小值,两种方法在训练集和验证集的准确率如表4 所示,Top1err 整体趋势与Loss 趋势相同,分别在第150 轮时和第120 轮时收敛,表明模型达到最好状态。

表4 车辆外观模型训练结果Table 4 Vehicle appearance model training results %
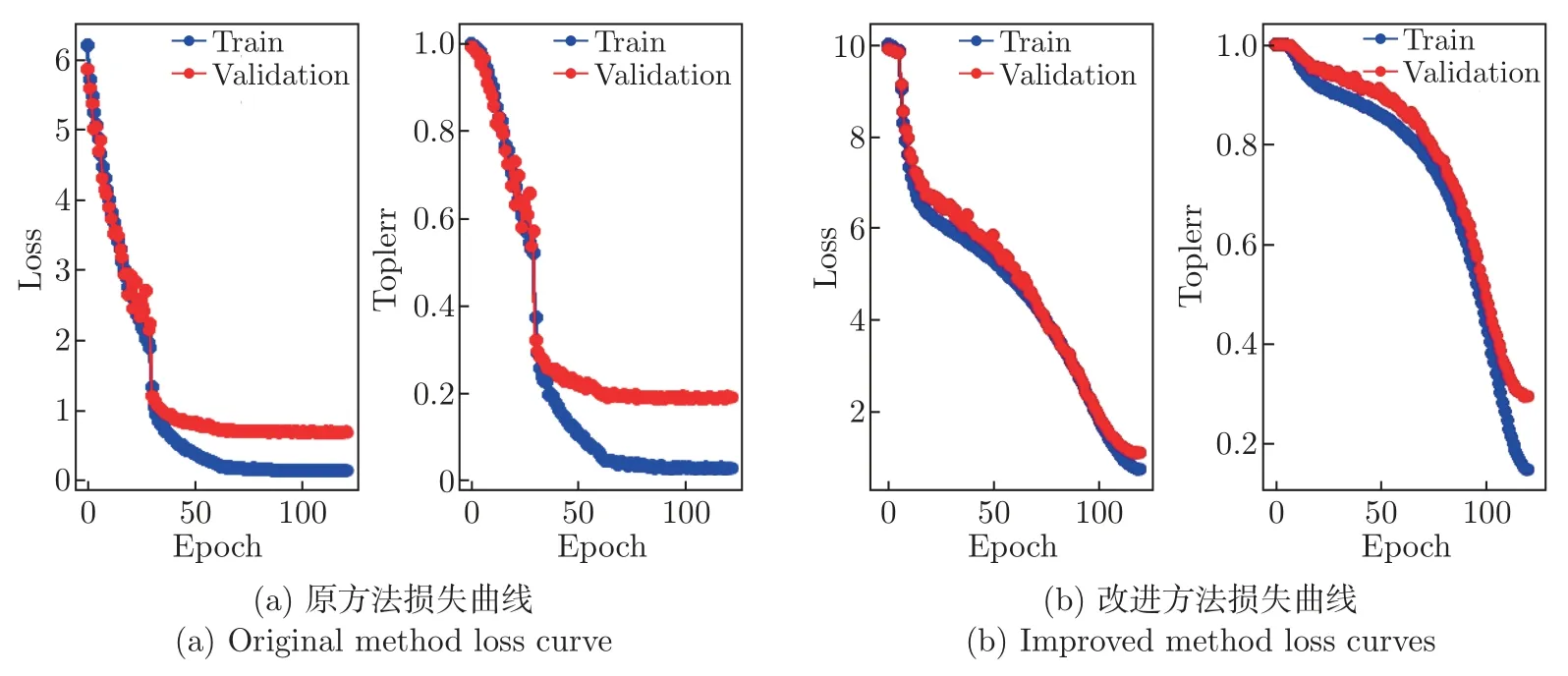
图12 损失曲线Figure 12 Loss curves
DeepSORT 采用外观特征与Mahalanobis 距离特征联合作为目标匹配的度量单位,其在一定程度上提高了匹配的精度,减少了ID 变换的次数,因此外观特征是决定目标能否匹配成功的关键度量单位之一。为此,修改特征提取网络结构来获得更加精确的车辆外观特征,同时,采用WarmUp 结合CosineAnnealingLR 方法训练得到准确率更高的车辆外观特征模型来提取跟踪过程中的车辆外观特征,可以提高目标跟踪算法的精度。
3.5 跟踪算法分析
通过MOT16 数据集验证算法在添加帧间光流模块后的有效性,如表5 所示,相较于DeepSORT 算法,在DeepSORT 算法的基础上添加帧间光流模块后,MT 提升了1.6%,MOTA 提升了1.3%,MOTP 提升了0.6%,IDF1 提升了2.6%,HOTA 提升了1.6%,相较表中其他方法,5 项指标结果仍表现较好。

表5 目标跟踪算法性能指标Table 5 Target tracking algorithm performance indicators %
为直观展示添加关联帧间光流模块后的跟踪效果,实验选取某高速道路数据进行应用分析,同时为验证算法的鲁棒性,在视频中人工添加黑色遮挡,比较目标在遮挡前后的ID 变化,图13~16 分别展示了跟踪算法对不同车道目标的跟踪效果,其中每幅图的(a) 和(b) 分别展示车辆目标未经过遮挡前的ID 情况和车辆经过遮挡后的ID 情况。在图13 所示的红色矩形选中区域内,车辆未经过遮挡前ID 为4,经过遮挡后ID 仍为4;在图14 所示的红色矩形选中区域内,车辆未经过遮挡前ID 为49,经过遮挡后ID 仍为49;在图15 所示的红色矩形选中区域内,车辆未经过遮挡前ID 为98,经过遮挡后ID 仍为98;在图16 所示的红色矩形选中区域内,车辆未经过遮挡前ID 为419,经过遮挡后ID 仍为419。

图13 逆向1 车道Figure 13 Reverse lane 1

图14 逆向2 车道Figure 14 Reverse lane 2

图16 同向2 车道Figure 16 Lane in the same direction 2
目标跟踪可以通过检验目标首次被检测器检测到的ID 和目标消失时的ID 的一致性判断跟踪算法的性能。本文从两个方面对目标跟踪效果分析,在性能指标方面,提出的目标跟踪算法各项性能指标均优于DeepSORT 及其他跟踪算法,在实际道路测试方面,提出的目标跟踪算法在人工添加黑色遮挡的条件下仍能保证被遮挡前后的ID 的一致性。从定量和定性两个方面分析可得,跟踪算法在精准度、鲁棒性等方面均呈现较好的效果。
4 结论
在复杂道路场景下,车辆目标之间的频繁遮挡、车辆目标之间相似的外观、目标整个运动过程中采用的静态预设参数都会导致跟踪准确率下降的问题。本文提出了一种基于车辆外观特征和帧间光流的目标跟踪算法,并通过实验验证了算法的有效性。研究结论如下:
1)在BDD100K 的基础上,采用不同的网络模型进行训练,通过对比不同网络模型在检测指标、真实应用场景的表现,选择高准确率、强鲁棒性的目标检测模型YOLOv5x,能够克服真实应用场景中存在的误检、漏检、置信度低等问题,为目标跟踪算法提供精准稳定的检测基础;
2)在修改车辆外观特征提取网络的基础上采用WarmUp 结合CosineAnnealingLR 方法训练得到准确率更高的车辆外观特征模型来提取跟踪过程中的车辆外观特征,进一步提高了目标跟踪算法的精度;
3)在卡尔曼滤波更新运动状态信息时关联帧间光流得到更精确的运动状态信息,实验结果表明,改进算法显著提升了目标跟踪的准确率和精度。
引入了光流计算模块能够为我们提供一种动态更新运动状态信息的方式,但是由于相邻帧间的光流计算对系统的要求较高,因此在后续研究中将针对引入关联帧间光流模块后导致的跟踪算法计算量变大的问题进行优化,进而实现高精度、实时性的目标跟踪算法。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2022年8期)2022-08-31
阅读(快乐英语高年级)(2022年6期)2022-06-17
家庭影院技术(2021年10期)2021-11-20
电光与控制(2018年10期)2018-10-13
小太阳画报(2018年3期)2018-05-14
紫禁城(2017年6期)2017-08-07
阅读与作文(小学低年级版)(2016年12期)2016-12-22
少年博览·小学低年级(2016年9期)2016-11-24
汽车文摘(2015年11期)2015-12-02
