
基于投影奖励机制的多机器人协同编队与避障
2024-02-18 13:46沙灜
应用科学学报 2024年1期
葛 星,秦 丽,沙灜
1.华中农业大学信息学院,湖北 武汉 430070
2.湖北省农业大数据工程技术研究中心,湖北 武汉 430070
将简单机器人组成模块化的多机器人系统以探索未知环境,并将其应用于重复性、危险性领域已成为研究热点[1]。其中多机器人的协同编队与避障任务是完成各项任务的基础[2]。
根据通信方式的不同,传统的多机器人编队方式可以分为集中式和分布式两种[3]。集中式架构依靠主控单元获取所有机器人的状态信息后发布运动指令。文献[4] 在集中式体系结构中引入图结构,将机器人看作图中的顶点,通过边的关系运算得出多机系统中所有机器人的位置信息。集中架构形成的编队稳定性较好,但对主控单元的依赖性太强,一旦主控单元出错,则多机编队会溃散。另外集中式方式要求主控单元具备较高的计算力,若计算力不足也会出现编队系统效率低下的问题。因此文献[5] 提出了一种新的分布式体系结构。在分布式体系结构下,编队系统内各机器人间可互相通信,共享邻居机器人的速度和位置信息,并基于此来决定自身的策略选择。分布式结构不受主控单元的影响,且对各机器人的计算力要求不高。但由于机器人的位置变化较快,各机器人因受通信延迟的影响而无法及时接收到其他机器人的位置信息,容易造成编队混乱。为此研究人员提出了分层体系结构[6],设置主控单元负责统筹全局信息,各机器人通过互相通信和主控单元信息共同确定自身运动。基于以上3 种通信方式衍生出多种控制方法,如跟随领航法[7]、虚拟结构法[8]、基于行为法[9]、人工势场法[10]、遗传算法[11]等。
随着强化学习[12]和深度学习[13]的不断发展,深度强化学习技术在多机器人领域应用越来越广泛。从分布式体系结构出发,文献[14] 实现了基于深度强化学习多机器人协同避碰策略,但由于深度强化学习需要处理大量数据,对机器人的配置要求较高,因此大多适用于大型机器人。综合考虑机器人性能及成本等因素,分层式体系结构更为适用。相较于传统方法,基于分层式的深度强化学习方法提高了机器人感知外界环境的能力[15],仿真环境下训练的模型可以迁移到其他多种未知环境,且具备更强的适应性与可探索性。多机器人中包含自身位置、速度、传感器、其他机器人以及障碍物等多种信息,当深度强化学习技术应用于该任务时,如何从多机器人系统中提取有效信息来定义当前的状态就成了基础。在状态定义的基础上设计高效的奖赏机制,实现状态与动作之间的映射关系是深度强化学习的关键[16]。聚焦于此,文献[17] 将深度强化学习方法与跟随领航方法相结合,利用机器人与目标位置的距离实现状态与动作之间的映射,但由于编队设置了中心点作为基准,对其中的跟随机器人和领航机器人的状态定义进行了区分,仅领航者使用深度强化学习方法完成自身决策,而跟随者依赖于领航者的决策采用了传统的速度控制方法,因此编队系统中心化程度较高,鲁棒性较低。
基于深度强化学习实现多机器人协同编队与避障任务中各机器人策略选择的关键问题在于:1)状态表征是深度强化学习方法的基础,多机器人系统内包含位置、速度、传感器等多种状态信息,且处于动态变化中,如何精确定义各机器人当前状态是首先要面临的问题;2)如何设计更为高效的奖励机制,准确定义状态与动作之间的映射关系;3)如何通过深度强化学习方法实现多机器人系统内各机器人自主决策,实现去中心化的多机器人系统。
针对以上问题,本文提出了一种基于投影奖励机制的多机器人协同编队与避障(projected reward for multi-robot formation and obstacle avoidance,PRMFO)模型。设计了统一状态表征方法,将机器人状态分为可观测状态和预测状态;在统一状态表征基础上设计矢量化的投影奖励机制判断当前动作的优劣;最后通过自主决策层为各机器人独立决策提供方法,并基于机器人操作系统(robot operating system,ROS)进行仿真实验,结果表明PRMFO 方法在单机器人平均回报值、成功率以及时间指标上分别提高42%、8%、9%,多机器人编队误差控制于0~0.06 范围内,实现了较高精度的多机器人编队。
1 理论基础
当深度强化学习技术应用于多机器人系统时,首先要解决的是以适当的数据形式表征当前环境状态,例如机器人自身状态、多机器人编队信息、机器人与障碍物以及机器人间的碰撞信息等。根据各机器人间有无信息交互,状态表征方法有所不同。在无信息交互的情况下,文献[18] 从图像角度出发,获取多机器人系统所处环境的图像,得到栅格化的环境状态,其中每格代表一个像素点,用像素信息作为当前价值评估的状态表征。此种表征方法虽较精准,但图像处理维度过高,计算量太大。
文献[19] 针对该问题,将每个机器人的状态信息分为自身的状态信息和其他信息,其他信息包括环境信息和多机器人系统中其他机器人信息,将其中的不变特征按一定顺序提取,再根据值函数选择最优动作指引其到达目标位置,避免每个机器人与环境中障碍物或其他机器人发生碰撞。为了进一步将其他机器人与环境中障碍物统一化处理,文献[14] 提出传感器级分散式碰撞策略,通过机载传感器获取原始数据,将传感器数据和其他机器人位置信息统一定义为障碍物信息,并将其映射为无碰撞的动作指令,从而学习到最优策略。为了减少各机器人的计算压力,文献[20] 开发了一个完全分散的避碰框架,每个机器人的导航策略均以自身机载传感器收集的测距数据作为输入,输出相应的速度命令,而在编队系统内不进行任何通信。
以上无信息交互的深度强化学习方法大多采用图像信息或机器人传感器信息来表征当前机器人状态或环境状态,在避障方面效果较好,但由于机器人间缺少交互,协同能力较差。为了增强多机器人系统的协同能力,文献[21] 通过增加机器人间的信息交互,将编队系统内除自身外其他机器人看作动态障碍物,各机器人发送自身位置和速度,并将其作为状态信息,采用速度障碍法预测碰撞区域,进而选择最优动作,完成路径规划。此种方法加强了机器人间的信息交流,达到了协同避碰的效果,但在移动过程中仍将其他机器人看作障碍物,并未涉及路径规划过程中的协同编队任务。为此,文献[22] 引入跟随领航法形成协同编队,同时采用深度强化学习的方法融合传感器数据进行编队避障,但针对领航者和跟随者的表征方法进行了区分,且跟随者完全依赖于领航者的策略选择,若领航者发生碰撞或计算错误,则编队失败。因此如何统筹处理多机器人系统内各机器人信息、传感器信息以及环境信息并准确定义机器人当前状态亟待解决。
奖赏函数实现了状态与动作之间的映射,是指导机器人学习的关键。在状态定义的基础上,制定高效的奖赏机制是关键。早期研究主要设置离散化奖励指导机器人躲避障碍物并抵达目标位置。文献[23] 根据机器人与障碍物的距离范围给予负奖励值,使得机器人具备避障能力。文献[24] 通过设定不同状态下的奖赏值,鼓励其不断完成目标任务。此种方法实现起来简单有效,但对于距离范围的设定和给定奖励数值的大小较为敏感且缺乏相应的规则。
为了解决上述问题,文献[25] 直接将机器人与障碍物的距离设置为奖励值,形成连续化奖励。为了进一步扩大机器人执行动作的奖惩差距,文献[26] 引入奖励参数,优化连续性奖惩函数,鼓励机器人更接近目标位置,并使其躲避环境中的障碍物。以上基于距离的方法较为直观,但不足在于:该方法的表现效果与环境大小和机器人动作的距离大小息息相关;奖赏参数的设定同样缺乏相应的规则。
2 PRMFO 模型
PRMFO 模型框架如图1 所示,包括以下3 部分:统一状态表征、投影奖励机制和自主决策层。在当前多机器人系统内编队信息、各机器人位置信息、速度信息以及雷达信息的基础上,统一状态表征将各机器人状态分为可观测状态和预测状态;投影奖励机制根据机器人实际状态变化与预测状态变化之间的差异衡量当前动作的效果;最后通过自主决策层各机器人判断自身状态下的最优动作,完成决策过程,从而实现多机器人自主决策的协同编队任务。

图1 PRMFO 模型框架图Figure 1 Framework of PRMFO
在多机器人协同任务中,若将所有机器人的状态组合成状态向量会使深度强化学习的过程计算量过大,且收敛速度过慢[27]。为了实现多机器人与复杂环境交互过程的一致性,PRMFO 设计了统一的状态表征方法,将机器人状态分为可观测状态和预测状态,其中可观测状态包括t和t+1 时刻各机器人自身状态与目标状态的相对关系、各机器人速度信息以及雷达信息;预测状态为t时刻预估机器人t+1 时刻与目标状态之间的相对关系、速度信息。可观测状态和预测状态统筹处理机器人自身信息、环境信息、编队信息以及雷达信息,为多机器人系统提供了统一的状态度量。
为了进一步加大各状态下不同动作的奖惩力度,为状态动作之间的映射关系提供更为准确的衡量方法,PRMFO 在统一状态表征方法的基础上,设计了投影奖励机制,将传统基于标量的奖励过程矢量化。具体实现过程是:将机器人动作前后实际状态变化的表征向量投影到预估机器人状态变化的表征向量上,得到的投影向量用以衡量当前动作实际产生的作用效果与预期产生的变化之间的差距。因此投影奖励机制旨在将机器人实际状态变化与预估状态变化向量化,进而为函数奖励机制提供了矢量化方法。
为了解决多机器人协同编队中的过度中心化问题,设计了自主决策层。自主决策层融合了统一状态表征与投影奖励机制,以软演员评论家(soft actor-critic,SAC)算法为基线方法,实现编队系统内各机器人独立决策,从而实现去中心化的多机器人协同编队。
2.1 统一状态表征
现有的跟随领航者方法与深度强化学习相结合的方法应用于编队协同的编队任务时,仅领航者采用深度强化学习方法进行目标导航,跟随者采用速度控制方法与领航者保持相对位置关系[22]。使用此种方法的主要原因在于,若跟随者机器人参与目标导航任务,则需将各机器人的状态与动作组合起来拼接为状态向量与动作向量,维度过高,训练效率低下。为此,本文提出适用于多机器人系统中各机器人的统一状态表征方法,实现各机器人针对自身状态的自主策略选择。
采用单元机器人turtlebot3 系统,结构如图2 所示。机器人在二维平面中运动。机器人顶部中心位置设置激光雷达扫描仪,扫描半径为[0.15 m,3.50 m],扫描范围为360°。机器人在t时刻的位置信息用pposition(t)=[xt,yt] 来表示,机器人在t时刻的速度表示为vt=[v,w],其中v表示线速度,ω表示角速度。因此机器人的速度向量vt可以表征为

图2 机器人模型图Figure 2 Robot model diagram
式中:vx为机器人在该时刻X轴方向的速度大小;vy为机器人在该时刻Y轴方向的速度大小;φ为机器人在该时刻的角速度大小。
PRMFO 将状态分为可观测状态和预测状态。设编队参数Fformation=(f0,f1,f2,···,fn),其中f0=(x0,y0) 为目标位置;fi=(Δxi,Δyi),i∈[1,n) 为多机器人协同编队内部的相对位置关系;n为机器人数目。将多机器人系统中各机器人的状态表征统一化,具体表示为
2.2 投影奖励机制
奖励机制是指导机器人策略选择的关键。传统的奖励机制依据机器人自身所处位置与目标位置之间的标量距离来定义反馈奖赏,但由于机器人同时存在角速度和线速度,在角度和距离两个方面均存在变化。所以PRMFO 设计了投影奖励机制,从两个维度上将该奖励过程矢量化,提供了更为精确的奖赏机制。
将传统标量方法的奖励机制转化为矢量投影的过程,具体实现如图3 所示,主要通过统一状态中的可观测状态和预测状态获取当前时刻的奖赏值。Rrobot(t)代表机器人的初始位置,为预测到达的位置,Rrobot(t+1)为机器人实际下一时刻位置。Ggoal(t)=(Δxt,Δyt) 和Ggoal(t+1)=(Δxt+1,Δyt+1) 分别为t时刻和t+1 时刻机器人与目标位置之间相对位置的向量表示,分别为蓝色向量和黄色向量。为在t时刻预估机器人下一时刻与目标位置之间相对位置的向量表示,为绿色向量。以上表示均由统一状态表征得到,据此得到该动作的实际状态变化与预估的状态变化,在图3 中分别为黑色向量和紫色向量。公式为

图3 投影奖励机制Figure 3 Projected reward mechanism
式中:Δpposition(t)代表了机器人采取动作前后的变化情况,可以用来表征该状态下某动作的作用效果;则代表预估机器人在当前状态下采用最优动作的状态变化情况。可见实际状态变化与预估状态变化之间的差异程度即为当前动作与最优动作之间的区别。采用向量投影的方法将Δpposition(t)投影到方向上,得到向量,在图3 中由橙色向量表示,并将其作为t时刻采取动作得到的奖励值,公式为
因此得到机器人各时刻奖赏值为
式中:α和β用以表征两部分奖赏值的权重。本文给予避障部分奖赏值更大的权重,即在协同编队中优先考虑避障问题,保证机器人安全。
2.3 自主决策层
自主决策层旨在为多机器人系统中各机器人独立完成自身策略选择提供方法。SAC 网络算法[28]是一种稳定高效的深度强化学习算法,适用于机器人与环境交互的实验要求。本文将统一状态表征与投影奖励机制融入SAC 算法中,设计了自主决策层,进而实现去中心化的多机器人协同编队与避障模型PRMFO。
——日前,德国《法兰克福汇报》网站以此为题报道称,中国年轻男性很难找到生活伴侣,主要原因是女性在择偶过程中首先要看的是男性的经济条件和职业
统一状态表征是PRME 模型应用于多机器人协同编队与避障任务的基础,各机器人自身均搭载SAC 网络,其输入与输出如图4 所示,各机器人获取当前编队信息,通过当前编队信息和自身位置信息得到自身与目标的相对位置关系,将雷达数据、相对位置以及速度等状态信息传入SAC 网络进行决策,输出该状态下应采取的最优线速度与角速度。

图4 SAC 网络输入与输出示意图Figure 4 Schematic diagram of SAC network input and output
在统一状态表征的基础上,根据机器人同质动力学原理,一台机器人训练的模型可以部署到相同结构的其他机器人上,各机器人均通过自身搭载的网络选择最优策略。在该过程中给予避障任务更高的优先级,即在躲避障碍物的前提下考虑编队协同任务。如图5 所示,以三角形队形为例,灰色框线为多机器人系统初始位置,红色框线为多机器人系统目标位置。在机器人前往目标位置的过程中,存在如灰色圆形所示障碍物,若其中某机器人遇到障碍物,则该机器人可躲避障碍物暂时脱离原队形抵达目标位置。
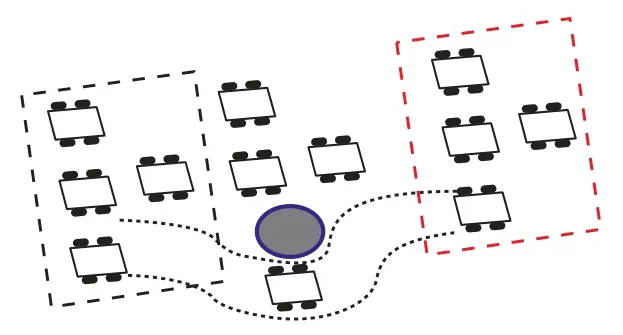
图5 多机器人协同编队示意图Figure 5 Schematic diagram of multi-robot cooperative formation
最优策略π:→a,指在不同状态下选取当前的最优动作,从而在无碰撞的情况下保持指定队形前往目标位置。各状态下的最优动作取决于动作的奖赏值r。最优策略的形成需综合考虑避障与目标位置,即
式(7) 为SAC 的优化目标函数,即在最大化回报值的同时最大化策略的熵。式(8) 为该任务的约束条件,分别表示多机器人满足协同编队要求和避障要求,即在雷达检测数据的安全范围内,各机器人保持编队要求抵达目标位置。在满足约束的基础上获取最优策略完成协同编队与避障任务并抵达目标位置。

3 仿真实验与结果分析
本文基于ROS 建立不同环境,进行仿真实验。网络模型采用Pytorch[29]实现,处理器为Intel®Xeon(R) Silver 4214R CPU@2.40 GHz × 48,显卡为llvmpipe (LLVM 12.0.0,256 bits)/llvmpipe (LLVM 12.0.0,256 bits),RAM 大小是31.0 GB。
3.1 单机器人仿真实验
3.1.1 评价指标和对比实验
模型训练参数如表1 所示,为了验证PRMFO 方法的优越性,将所提模型与基础SAC 网络算法进行对比。在环境配置相同的情况下,通过平均回报值、成功率、时间3 个指标进行实验对比。

表1 训练参数Table 1 Training parameters
1)平均回报值 当前训练回合内的平均奖赏值,即累积奖赏值/回合数;
2)成功率 将相同训练时间的模型置于仿真环境中测试其在相同步数下成功到达目标位置的次数。本文在当前环境中测试机器人100 回合内到达目标位置的次数,以成功次数/回合数表示成功率;
3)时间 在100 回合内,机器人平均每次到达目标位置所用的步数。所用步数越少,耗费时间就越短,效率也就越高。
使用Gazebo 创建10 m×10 m 多障碍物环境,如图6 所示。其中长方体和圆柱体为随机分布的障碍物,移动机器人模型为Turtlebot3 系列移动机器人。机器人初始位置为中心位置(0,0),雷达安全距离设置为0.2 m。为了增强模型的泛化能力,提高机器人对外界环境的感知能力,在当前环境的非障碍物区域随机初始化目标位置,机器人到达该目标位置后无需返回初始位置,即规划路径至下一目标位置。
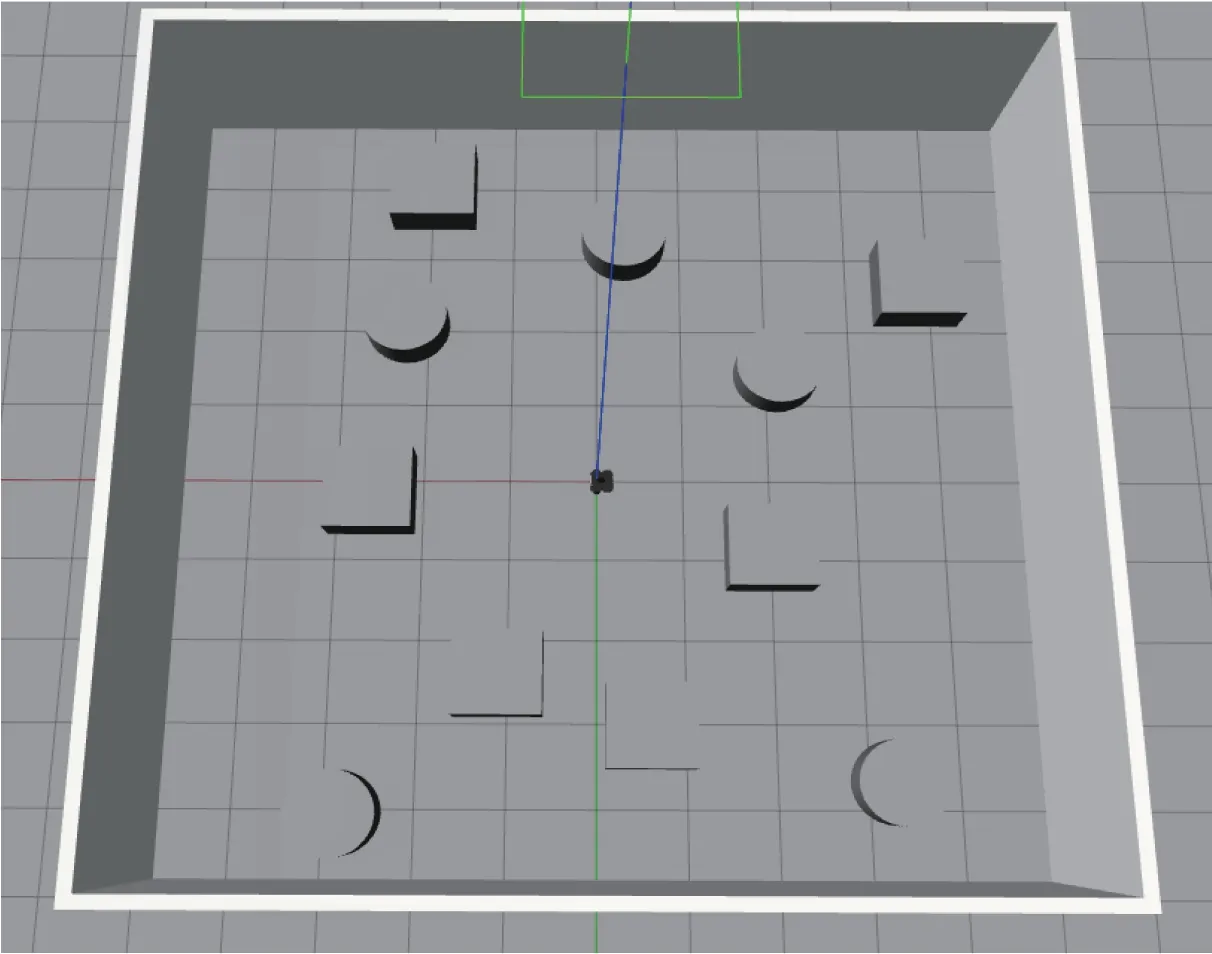
图6 仿真场景图Figure 6 Simulation scenery diagram
机器人根据指定参数进行训练,训练过程中平均回报值如图7 所示。训练初期机器人通过与环境交互收集信息,动作选择随机性较高,平均回报值存在一定的波动,模型达到一定训练次数后,平均回报值不断上升且上升幅度逐渐缩小直至趋于稳定。由图7 可以看出:初期PRMFO 算法较SAC 算法的每轮平均回报值波动较小,处于稳步上升的状态,且上升速度较快。
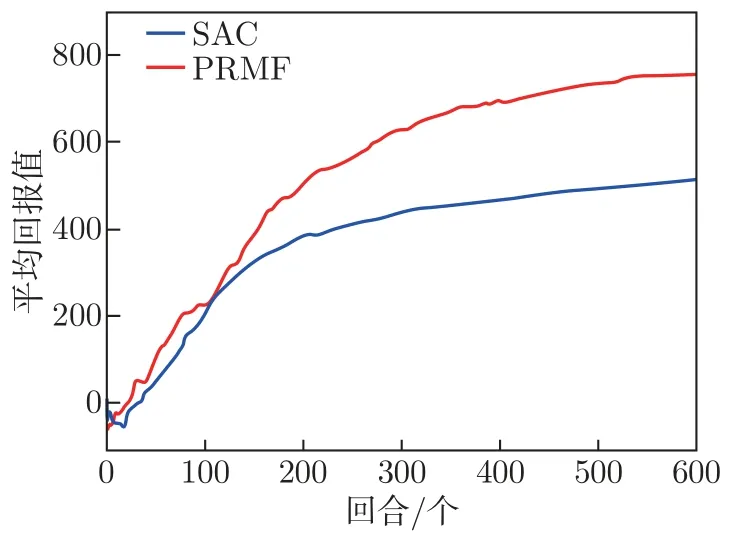
图7 每回合内平均回报值Figure 7 Averaged returns within each epoch
为了进一步验证PRMFO 算法的优越性,在每回合内平均回报值的基础上取每步的平均回报值进行比较,如图8 所示,PRMFO 算法呈现出稳步上升的趋势,在训练步数达到1 200时,平均每步回报值位于2.0 附近。而基础SAC 算法初期稳定性较差,且最终收敛于1.0 附近。因此从每回合的平均回报值与平均每步的回报值指标看,PRMFO 算法均取得更优的效果。两种算法的实验结果对比如表2 所示,由实验数据可知PRMFO 算法在平均回报值、成功率以及时间指标上均优于SAC 算法。
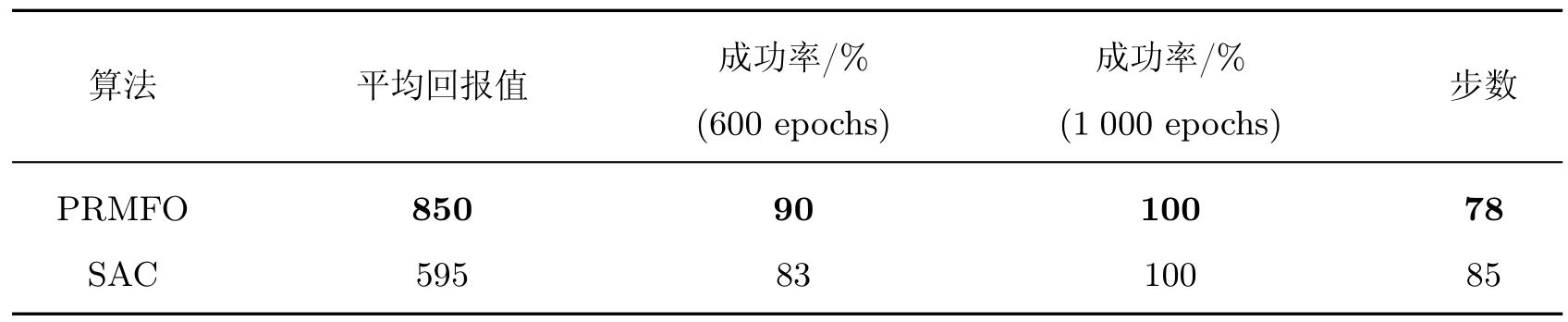
表2 实验结果对比Table 2 Comparison of experimental results
3.1.2 泛化性分析
将PRMFO 模型置于图6 仿真环境中,随机初始化目标位置,使用Rviz 工具绘制路径规划的轨迹图。图9 为路径规划俯视图,机器人初始位置为(0,0),目标位置为(4,0),机器人自主决策到达该目标位置后,在(4,0) 随机初始化目标位置为(3,-4),进而到达该目标位置。机器人可以在当前环境内到达任意非障碍物位置。

图9 路径规划图Figure 9 Path planning diagram
在验证当前方法可行性的基础上对其泛化能力进行测试。改变当前环境,构建仿真环境如图10 所示。将在图6 仿真环境中训练好的模型迁移到当前环境中,测试该模型的泛化能力。为了进一步验证当前方法在其他复杂环境下的泛化能力,将机器人置于如图10 所示仿真环境Env1 中,机器人需在狭窄空间中穿过障碍物抵达目标位置。机器人的初始位置为(0,0),目标位置为(5,0),两点之间的路径规划效果如图11 所示。

图10 环境仿真图Figure 10 Environment simulation diagram

图11 在狭窄环境中的路径规划图Figure 11 Path planning diagram in narrow environment
为了进一步验证在无障碍物环境Env2 中的导航能力,机器人的初始位置为(0,0),目标位置为(3,4),两点之间的路径规划如图12 所示。由此可见PRMFO 在多障碍物、狭窄空间以及无障碍物环境中都具备很好的路径规划能力,验证了该模型的泛化能力。对比在狭窄环境中PRMFO 模型与基础SAC 模型的效果,如表3 所示,PRMFO 模型到达目标位置及避障能力均优于基础SAC。

表3 泛化实验结果对比Table 3 Comparison of generalization experimental results

图12 在无障碍物环境中的路径规划图Figure 12 Path planning diagram in accessible environment
3.2 多机器人协同编队仿真实验
多机器人协同编队与避障任务需要综合考虑机器人间的约束问题与各机器人自身的避障问题。根据多机器人同质动力学原则,各机器人可共享网络参数训练。在保证安全的前提下形成编队,即在多机器人协同编队与避障任务过程中允许部分机器人优先考虑躲避障碍物任务,多机器人系统灵活性较高。
以“一”字型编队为例,在无障碍物环境中设定编队参数f0=(4,0),f1=(0,-1),其中f0=(4,0) 为目标位置,f1=(0,-1) 为两机器人相对位置关系,移动轨迹如图13 所示,其中红色线代表机器人F0,蓝色线代表机器人F1。F0初始位置为(0,0),F1初始位置为(0,-1),可见两机器人保持稳定的编队参数并到达了目标位置。

图13 “一”字型编队机器人移动轨迹Figure 13 Robot movement trajectory with “one-line” formation
在以“一”字型编队抵达目标位置的过程中产生的误差如图14 所示。实际运动过程中两机器人间的相对位置与目标编队参数的距离差在(-0.02,0.04) 范围内,且在运动初期与目标编队参数几乎完全相符。由于PRMFO 具备指引机器人到达目标位置的能力,因此在多机器人中表现出较高的编队精准度。

图14 “一”字型编队误差Figure 14 “One-line” formation error
在无障碍物环境中测试三角形编队,以F0、F1、F2为例,设置编队参数为f0=(3,-2),f1=(-1,-1),f2=(-1,1)。如图15 所示,f0=(3,-2) 为目标位置,f1=(-1,-1),f2=(-1,1) 为机器人间的相对位置关系。机器人移动轨迹如图15 所示,其中红色线代表机器人F0,蓝色线代表机器人F1,黑色线代表机器人F2。F0初始位置为(0,0),F1初始位置为(-1,-1),F2初始位置为(-1,1),可见3 个机器人保持编队到达目标位置。

图15 三角形编队机器人移动轨迹Figure 15 Robot movement trajectory with triangle formation
在以三角形编队抵达目标位置的过程中产生的编队误差如图16 所示。实际运动过程中以F0为三角形顶点为例,F1、F2分别与F0之间的相对位置关系与目标编队参数之间的距离差分别处于(-0.04,0.04) 和(-0.06,0.05) 范围内。因此PRMFO 在三角形队形中也具备较高的编队精度。

图16 三角形编队误差Figure 16 Triangle formation error
为了验证模型在有障碍物环境中的协同效果,设置编队参数f0=(-4,2),f1=(0,-1),其中f0=(-4,2) 为目标位置,f1=(0,-1) 为两机器人间相对位置关系。将F0与F1两机器人置于图6 仿真仿真环境中,两机器人移动轨迹如图17 所示,红色线为F0,蓝色线为F1。在(-1,1.5) 附近区域,为了躲避障碍物,队形发生了变化。机器人通过障碍物后,依据编队要求抵达目标位置,完成多机器人协同编队与避障任务。

图17 有障碍物环境多机器人移动轨迹Figure 17 Robot movement trajectory with obstacle environment
因此该模型在有障碍物环境与无障碍物环境中均具备一定的多机器人协同编队与避障能力,且各机器人自主决策,实现了去中心化编队,提高了多机器人系统的鲁棒性。
4 结语
深度强化学习方法与跟随领航法相结合应用于多机器人协同编队与避障任务中实现了未知环境中的多机协作,但其受领航者机器人决策的影响较大。针对该问题,本文提出了一种基于投影奖励机制的多机器人协同编队与避障模型,为多机器人系统提供了统一的状态表征方法;设计了基于投影的奖赏机制,并以SAC 网络为基础,实现了去中心化的多机器人协同编队。通过仿真实验验证了PRMFO 方法在平均奖赏值、成功率以及时间指标的优越性,及其在不同环境的泛化能力,显示出该方法能够实现去中心化编队。
下一步可针对PRMFO 模型中的网络部分进行优化,提升算法性能,使机器人在更加复杂环境中完成协同编队任务。
猜你喜欢
军事文摘(2023年5期)2023-03-27
科学大众(2020年23期)2021-01-18
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
汽车观察(2019年2期)2019-03-15
北京航空航天大学学报(2017年3期)2017-11-23
中国卫生(2016年5期)2016-11-12
海军航空大学学报(2015年4期)2015-02-27
导航定位与授时(2014年2期)2014-04-27
生物进化(2014年2期)2014-04-16
