
合成语声的声学分析及识别特征算法∗
2024-02-29 10:58周峻林胡晓光黄子旭付哲宇
应用声学 2024年1期
周峻林 胡晓光 黄子旭 汪 旭 付哲宇
(中国人民公安大学 北京 100038)
0 引言
随着人工智能技术的发展,合成语声的能力日益提高。通过技术手段合成得到的语声开始变得越来越逼真,甚至可以达到通过模仿目标说话人,生成即使是人类也很难区分的语声。基于深度学习的最新语声合成研究成果包括Tacotron和Tacotron2框架、百度AI 研发的Deep Voice、谷歌Deepmind 提出的Wavenet 技术、科大讯飞语声合成系统等。嫌疑人利用这些技术合成语声开展电信诈骗等违法犯罪活动的比例逐年上升,对人民财产安全、社会稳定构成了严重威胁。现有的传统司法语声鉴定技术在开展合成语声检验时难度较大,难以出具鉴定意见。但由于人对语声的感知是非常多样化的,考虑到计算机受限于目前人工智能技术和硬件运算能力,只能通过部分参数在一定程度上对人类真实语声的声学特性进行感知,使得通过语声合成技术生成的语声在声学特性上仍与真实语声存在着一定距离。因此,研究合成语声识别的技术存在可行性。目前的主流研究趋势[1]是通过设计和改进语声特征,以找到能够较好表征出合成语声和真实语声间差异性的参数,实现有效识别合成语声的目的。
现有的语声特征研究成果丰富[2],主要可分为倒谱系数特征、相位特征、幅度值特征、长时特征、子带特征,分别是根据在语声合成的过程中短时内频率变化、相位、幅度特性差异,长时内语声信息差异和频带中的部分特性差异所提出的一系列特征,主要如下。
Davis 等[3]提出,在以人对频率的听觉感知曲线梅尔刻度的基础上,设计得到梅尔频率倒谱系数(Mel-frequency cepstral coefficients,MFCC)。在此基础上,不同的研究人员设计了不同的MFCC改进特征,如Chettri 等[4]提出的逆梅尔频率倒谱系数(Inverted Mel-frequency cepstral coefficients,IMFCC)等。类似于MFCC,还有利用线性的三角滤波器组对语声做出处理后,再求取对数的倒谱系数,得到线性频率倒谱系数特征(Linear frequency cepstral coefficients,LFCC),由于LFCC在语声高频区域可能具有更好的分辨率,其已被证实拥有较好性能。Hanilci[5]提出从线性预测残差分析信号中提取出幅值和相位,得到线性预测残差相位函数(Linear prediction residual phase,LPResPhase)、线性预测残余希尔伯特包络倒谱系数(Linear prediction residual Hilbert envelope cepstral coefficients,LPRHEC)以及线性预测残余相位层系数(Linear prediction residual phase cepstral coefficients,LPRPC)特征,用于合成语声识别,在ASVspoof2015 数据集上取得了较好性能。Sanchez等[6]提出利用相位信息开展对合成语声的检测工作,使用相对相位偏移(Relative phase shift,RPS)特征实现了合成语声的检测。除此之外,相位特征还包括群延迟特征(Group delay,GD)、修正群延迟倒谱系数(Modified group delay cepstral coefficients,MGDCC)、基带相位差(Baseband phase difference,BPD)等。Tian 等[7]综合比对了这些相位特征在合成语声识别任务中的性能,证实了相位特征的有效性。Todisco 等[8]提出利用基于长时常数Q 变换的倒谱系数(Constant-Q cepstral coefficients,CQCC)特征,该特征是研究者针对伪造语声识别领域所专门设计的特征,其能更密切地反映出人对声音感知程度,提取过程是通过对语声信号采样恒Q变换(Constant-Q transform,CQT)后,再求对数得到倒谱系数所得到的。在CQCC 特征的基础上,Yang 等[9]研究提出倒倍频常数Q 系数和倒倍频常数Q 倒倍频系数来进一步优化CQCC特征。Das 等[10]验证了基于CQT 的扩展恒Q 倒谱系数(extended constant-Q cepstral coefficients,eCQCC)、常数Q 统计量加主信息系数(Constant-Q statistics-plus-principal information coefficients,CQSPIC)特征的性能优于CQCC 特征。子带特征指的是通过对频带中的一部分展开变换所得到的特征。主要包括子带频谱质心幅度系数(Spectral centroid magnitude coefficients,SCMC)、子带质心频率系数(Subband centroid frequency coefficients,SCFC)等。2020 年,Yang 等[11]提出的恒Q 等子带变换(Constant-Q equal subband transform,CQEST)、恒Q 倍频程子带变换(CQ-OST)和离散傅里叶梅尔子带变换(Discrete Fourier Mel subband transform,DF-MST),并在ASVspoof2019 LA数据集上取得了较好的效果,这证明了子带特征也适用于合成语声识别领域。Laskowski 等[12]提出基频变化率(Fundamental frequency variation,FFV)特征用于说话人识别领域。Monisankha等[13]将其应用于合成语声识别上,取得了较好的效果。
上述为目前研究领域主流特征,大部分是针对合成语声短时内频率、幅度、相位和长时内语声信息、部分频带特性5 个方面进行设计和持续改进的。但是由于目前计算机对于人类语声的感知学习能力是有限的,现有成果针对合成语声的声学特性表现研究较少,针对合成语声同真实语声在听感上存在的韵律平淡、自然度欠缺的特点所设计的特征较少,且不同特征间的融合探索还可以进一步加强。
1 合成与真实语声的声学差异分析
本节通过剖析比对合成语声同真实语声在声学特性上的差异,开展声学分析,从而证实两者差异是可通过声学特性进行体现的。
1.1 声学研究过程
本文通过使用语声学分析软件Praat 对比计算机合成的语声、人类真实语声的各项声学特性,生成相关图表,分析数据上的差异,从而找到可用以区分合成语声和真实语声的依据。其中真实语声来自于TESS数据集[14],合成语声来自于利用Jia等[15]提出的说话人风格迁移的方法和SV2TTS 模型在真实语声的基础上进行合成。两者在语义信息、说话人声音特点上保持了一致。
研究具体过程如图1 所示。首先在语声数据集中选取出真实语声;随后提取出真实语声的文本信息与说话人声音特点,融入至用于语声合成的神经网络模型中,得到满足比对条件的合成语声和真实语声样本;再依次通过不同的软件进行语声标注、数据提取、绘制图表,得到声学特性的数据统计结果;最后经过分析,得到结论。

图1 声学研究流程Fig.1 The process of acoustic research
1.2 声学研究结果
对合成语声与真实语声的基频、声强、窄带频谱图3 类声学特性进行比对以及结果分析,其中真实语声包含中性、愤怒、恐惧、开心、悲伤5 种情感。这是因为人类往往是在不同情感状态下进行发声的,使用不同的情感语声将能更全面地代表人类语声的真实发声情况。分别提取90 条合成语声与90条真实语声中的基频和声强数据,求取均值和方差值的总体均值,统计结果如图2、图3所示。

图2 合成与真实语声的基频、声强均值及方差数据统计图Fig.2 The statistical graph of the mean and variance data of the fundamental frequency and speech intensity of the synthetic and real speech

图3 合成语声与真实语声窄带频谱比对图Fig.3 The comparison of narrowband spectrogram of synthetic and real speech
总结合成语声与真实语声在声学特性中的表现差异如下:
(1) 基频。由图2(a)可见:合成语声的基频均值约为170.75 Hz,而真实语声的基频均值约为257.98 Hz;合成语声基频方差值约为44.57,真实语声基频方差值却为1849.83。对比之下,可见真实语声基频均值和方差值均大于合成语声,其中方差值要远大于合成语声。这是因为人类真实语声往往会受多方面影响而起伏波动,比如在某些激烈的情绪条件下,声调变化程度也会加剧,使得基频方差要明显大于合成语声。因此,可利用声调的变化程度作为区分合成语声与真实语声的可靠依据之一。
(2) 声强。由图2(b)可见:合成语声的声强均值约为83.06 dB,真实语声的声强均值约为83.06 dB。对比之下,可见真实语声声强均值小于合成语声,声强方差值要大于合成语声。这是因为真实语声往往节奏多变,致使语声能量起伏输出、方差较大。但是语声的强度大小可受到声源设备等非语声自身因素决定,并非合成语声与真实语声的根本性差异。由此可知,可利用语声声强的变化程度作为区分合成语声与真实语声的可靠依据之一。
(3) 窄带频谱图。由文献[16]以及图3 可见:合成语声3000 Hz 以上频率的谐波存在着明显缺失,谐波总体形态平直无倾斜,韵头走向仅存在微小的弯曲,韵尾走向平直,音节过渡区域几乎没有抖动,见图3(a)中蓝色方框中无黑色实线;中性语声谐波整体形态近乎平直,韵头、韵尾均有微小的弯曲,倾角较小,在音节过渡区域可见明显但幅度较小的抖动,见图3(b)蓝色方框中线条弯曲;悲伤语声整体形态呈直线下降趋势,韵头、韵尾走向有些许弯曲,过渡区域的抖动较小,见图3(d)蓝色方框中线条起伏弯曲;恐惧、开心、愤怒语声可见整体形态存在着明显的、不同程度的倾斜和弯曲,呈下降趋势,韵头韵尾弯曲明显且程度大,音节过渡区域存在明显较大抖动,见图3(c)、图3(e)、图3(f)蓝色方框中线条为曲线,且弯曲程度大。
由上述比对结果可知:在窄带频谱图谐波形态方面,真实语声较合成语声的整体弯曲、倾斜程度更大,韵头韵尾弯曲程度明显更大,过渡区域的抖动范围更大。因此,频谱图中反映的谐波形态、频谱分布宽泛程度可作为区分合成语声与真实语声的可靠依据之一。
2 合成语声识别特征研究
表征声学特性的数据需进一步量化为声学特征输入至构造的深度学习模型中,才能让机器实现自动化识别合成语声。本节针对声学比对结果,对不同的声学特性差异开展了特征量化,设计选用不同的声学特征及其结合开展实验,以验证性能。
2.1 特征化声学特性
特征化声学特性的步骤是:(1) 依据声学实验结果得到所需数据;(2) 依据数据特点,设计特定算法;(3) 利用特定算法处理声学数据;(4) 对数据进行变换,突出高价值部分。最终表征出对合成语声识别任务具有针对性的特征。
本文设计了均方根角(Root mean square angle,RMSA)特征,一种能够反映声强变化程度的声学特征。选取能够反映出基频变化程度、语声频谱特性的声学特征,分别为FFV 特征、语声窄带频谱图(Speech narrowband spectrogram,SNS)特征。其中RMSA与FFV特征为时域特征,包含时序信息;SNS 特征为频域特征,包含频谱信息。进一步结合3种特征,将能更加适用于合成语声识别任务。
2.1.1 RMSA特征
本文提出RMSA特征的具体过程如下:
(1) 语声数据获取。输入语声,经过16000 Hz采样和8位量化提取语声数字信号。
(2)计算语声均方根(Root mean square,RMS)能量。首先对语声信号进行分帧处理,其中每帧包含2048 个采样点,帧与帧间的重叠部分包含512 个采样点,再计算每帧语声信号RMS能量,如公式(1)所示:
(3) 向量化输入数据。为使一维时序型数据变换为二维数据,向原数据中加入时间点数据作为维度一,维度二为该点的数值。
(4) 计算相邻向量间的余弦距离,如公式(2)所示:
(5) 最后根据计算的余弦距离d,得出夹角余弦值,利用反余弦函数计算对应的夹角度数,得到RMSA 特征,计算过程表示如公式(3)所示:
本文通过利用RMS 能量的计算方式作为特定处理算法表征声强,能够更为准确地表征出语声信号的真实强度大小,有利于提取出周期性变化的语声信号的每一帧能量,而每一帧的语声能量有效值则能够较好地表征出信号在较短时间段内的能量大小。图4为语声信号的RMS能量可视化。可见经过计算RMS 能量值大小,将语声信号的起伏程度以数值上变化的形式有效表征出来,为下一步提取声强变化率提供了计算条件。
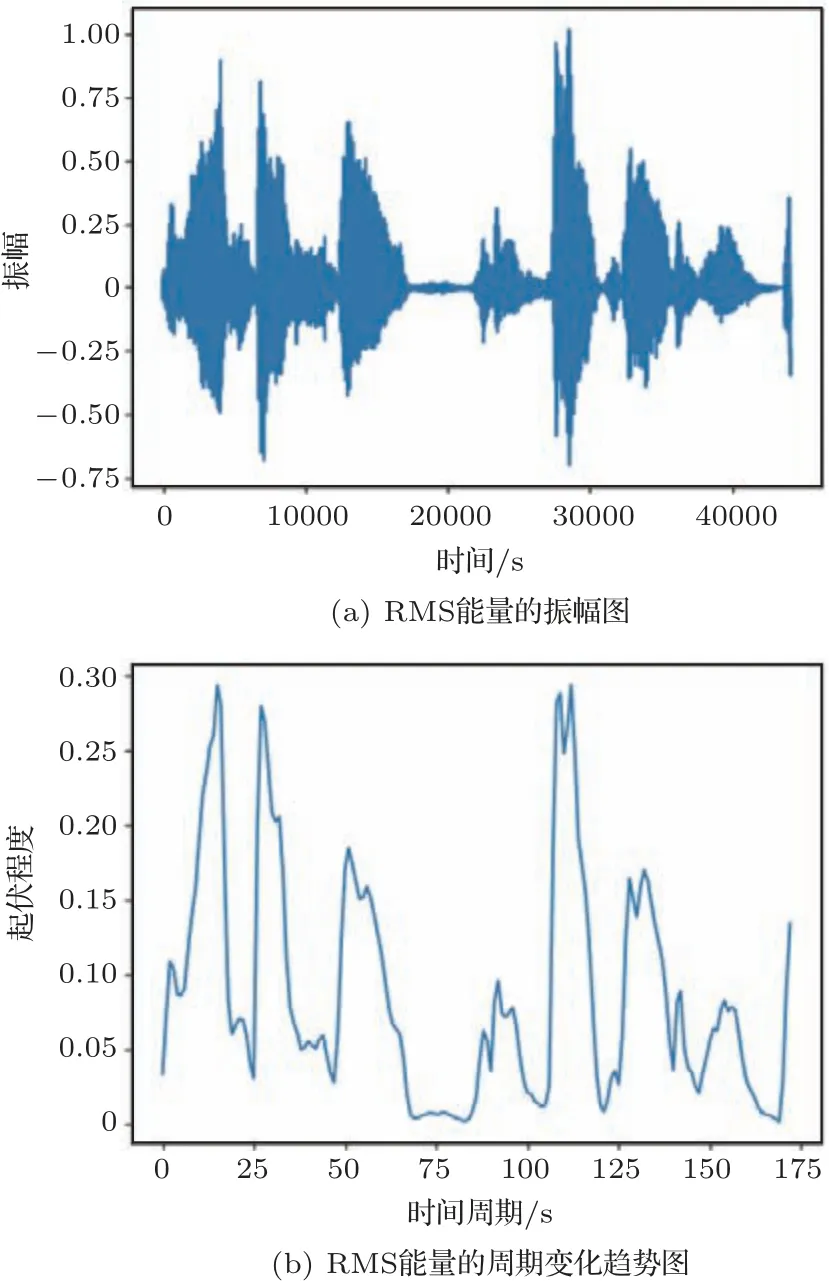
图4 RMS 能量可视化Fig.4 RMS energy visualization
为量化合成语声与真实语声的声强的变化程度不同,本文进一步计算了相邻RMS 能量数据间的余弦夹角,如图5 所示。这样做可以提高数据精细度,放大相邻数据差异大的部分,缩小差异小的部分,降低数据的平滑度,从而增强数据的特点。这是因为自然语声在发声过程中,往往是起伏较大、律感十足的,剧烈波动对声强的影响往往较大,相邻向量间的夹角度数扩大的程度较大,而合成语声的声强则会偏于平稳发声,这使得两个相邻向量之间的夹角变化较小。因此经过计算得到两个相邻向量间的夹角大小,可以用以衡量数据点之间的差值大小,可以量化语声在声强声学特性上体现的起伏程度。由图5 可见,下个时间点的数值较当前时间点的增加得越多,则两者夹角α越大,并且夹角的增幅越大。
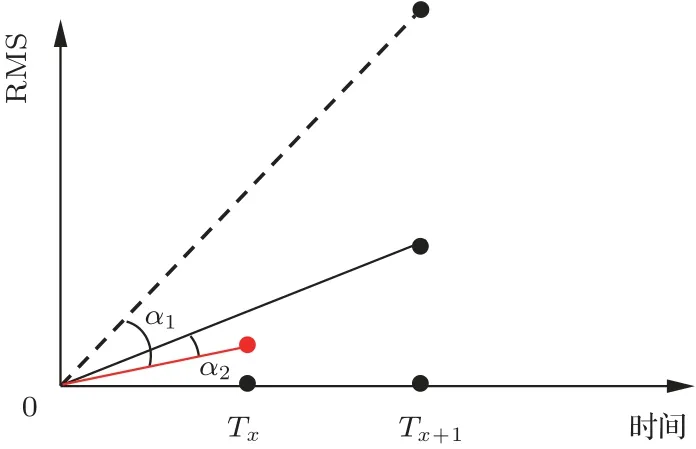
图5 RMSA 特征余弦夹角示意图Fig.5 Diagram of RMSA feature cosine angle
通过提取语声信号能量有效值,并量化相邻两帧的差异,在一定程度上可以反映出语声的声学特性情况和说话人发音时的状态。因此提取语声的RMSA 特征表征声强变化程度可以从语声声学特性的角度,提取出声强的即时变化情况,进而有利于区分合成语声和真实语声,有助于提高合成语声自动化识别的准确率。
2.1.2 FFV和SNS特征
(1) FFV特征。使用韵律学特征中的FFV特征表示了逐帧间的基音频率瞬时变化的情况,能够较好体现声学上的声调起伏程度,又能较好地适用于合成语声识别任务,将有助于区分合成语声和真实语声。
(2) SNS特征。SNS在频率上的分辨能力高,相比宽带频谱图,其包含的谐波结构及形态走向更加清晰明了。两者本质上是同种变换不同参数下的结果。因此,本文直接提取SNS特征,利用机器直接学习和识别输入的窄带频谱图像,将能比较直观地学习到合成语声与真实语声的频谱特性差异情况,相较于宽带频谱有着更为高效、直观的优点。
3 合成语声识别特征验证实验
通过比对目前合成语声识别领域前沿特征,开展合成语声识别实验和消融实验,通过设置对照实验特征及模型,与本文所提和使用的特征在同一模型下的表现性能进行比对,从而得出特征化声学特性得到的声学特征在区分合成语声任务中的表现情况,用以证明声学特征的有效性,进一步验证特征的针对合成语声识别任务的性能。
3.1 数据集及实验环境
本实验使用的数据集为FoR[17]:Fake or Real合成语声数据集的2 s 语声标准版。该数据集使用了最新的开源语声合成(Text-to-speech,TTS)系统包括百度的Deep voice3、谷歌云Wavenet、亚马逊AWS Polly、微软Azure TTS 系统等,对选取的特殊短语文本生成声频文件;收集了来自Arctic、LJSpeech、VoxForge三个开源数据集和Youtube 视频播放平台上的语声作为数据集中真实语声的来源。训练集包含的合成语声、真实语声均为8391 条语句,总共16782 条语句,验证集包含2826 条语句,测试集中包含1088 条语句并且增加了一种训练和验证集中没有的语声合成方法,用以测试实验模型和特征的泛化性能。
本实验使用的评价指标为等错误率(Equal error rate,EER)[18],即错误接受率(False accept rate,FAR)和错误拒绝率(False rejection rate,FRR)相等时的数值。其数值越小,代表性能越好,分类错误出现得更少。
实验工具包括Keras、tensorflow 深度学习框架、sklearn 机器学习工具库、librosa 声频数据处理库、spafe 语声特征提取库、numba 开源编译器工具库。实验运行环境:操作系统为windows 10专业版,图形运算显卡为Nvidia Tesla V100-SXM2 32 GB。
3.2 实验模型及参数设置
为保证能够在相同的变量条件下开展对照实验,在实验模型上根据特征的类型选择不同的深度神经网络模型,以保证声学特征和对比特征在同一模型中开展的同时,保证识别模型的性能。
(1) 时序型特征识别模型。针对以时间序列上排序为重要特性的RMSA 特征、FFV 特征,将使用适用于合成语声识别任务的包含5 层隐藏层、每层2048 个神经元的深度神经网络(Deep neural network,DNN)模型。
(2) 谱图型特征识别模型。针对主要以频谱图像为形式的SNS 特征,将使用包含两层64 个3×3的卷积核、两层汇聚层的卷积神经网络(Convolutional neural network,CNN)模型,对特征分类学习。使用该模型连接全连接层,实现二分类输出为合成或者真实标签。
(3) 融合特征识别模型。特征融合的方法是通过使用DNN、CNN 模型对声学特征数据进行深度向量表示后,利用Concat 层融合,一同输入至全连接层进行二分类输出。融合特征识别模型结构如图6所示。

图6 融合特征识别模型结构图Fig.6 Structure diagram of fusion feature recognition model
模型的训练具体参数设置为:使用Adam 优化器,学习率初始化为3×10-4,损失函数使用二值交叉熵函数。为避免过拟合,当训练过程中损失不再下降超过5 轮时,学习率缩小10 倍。训练批次大小为128,训练周期为60轮。
3.3 实验结果与分析
3.3.1 RMSA、FFV特征有效性验证实验
为验证本文设计的特征在合成语声识别任务上的有效性以及优化性能,开展消融实验,进一步对比本文所选用和设计的声学特征在合成语声识别领域的适用性,将提取RMS特征、RMS 差分特征比对本文设计的RMSA 特征识别性能;提取Pitch(基频)特征、Pitch 差分特征比对FFV 特征识别性能,在相同的DNN 模型下进行测试,EER 指标如表1所示。
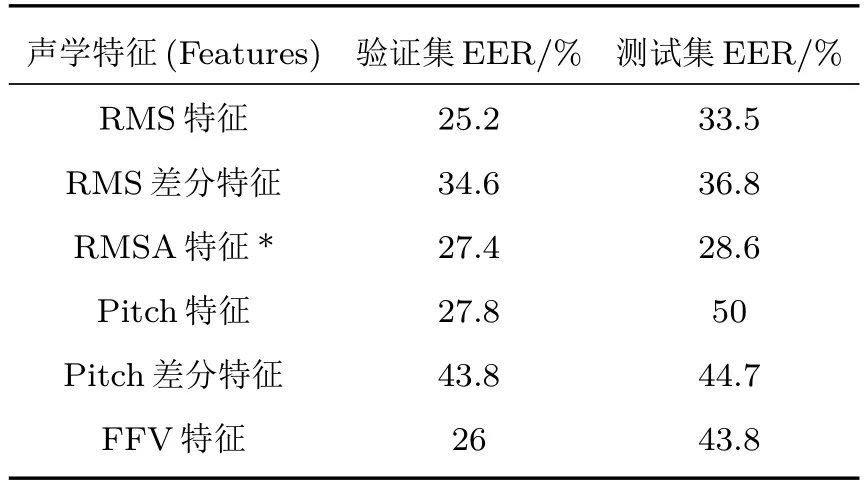
表1 RMSA、FFV 和对比特征的实验结果Table 1 Experimental results of RMSA,FFV and comparison features
由验证集实验结果可见,6 种特征都能实现在一定程度上识别合成语声,其中对照设置的RMS、Pitch 特征在模型中的识别效果则分别为25.2%、27.8%。这表明提取出语声的声强、基频声学特性,并且利用其开展区分合成语声与真实语声是可行的。差分特征能够实现一定程度的识别效果,改进的RMSA和FFV特征优于差分特征。
由测试集实验结果可见,RMSA 特征、FFV 特征的EER 为28.6%、43.8%,识别效果最佳。这表明本文使用的RMSA特征、FFV特征分别能在一定程度上对合成语声进行识别的基础上,对于训练集中没有学习过的语声合成算法的泛化识别性能更好。
通过对比上述实验结果可以发现:RMSA 特征在验证集中的性能略差于RMS 特征,优于RMS 差分特征,在测试集中的性能却同时好于RMS特征和RMS差分特征。这是因为模型通过学习RMS特征,学习到了声强的数值大小,利用声强数值上的差异也能够区分部分合成语声与真实语声,但是表征声强变化程度的RMSA 特征更为根本性地反映了合成语声在声学特性上与真实语声的差异,并进一步增强了差异性表现程度,因此模型通过学习RMSA特征将能拥有更好的鲁棒性和泛化性能。
FFV 特征则在验证集、测试集上均优于Pitch特征及差分特征,但可以发现在测试集中Pitch 特征识别合成语声失败,且Pitch 差分特征和FFV 特征的EER 也明显提高,证明在面对新算法的干扰时,利用基频特性开展合成语声识别的鲁棒性要差于声强特性。因此,可见通过提取RMSA特征、FFV特征实现合成语声的识别,反映出本文所设计的算法能较好地表征出语声声学特性的特点的同时,也证明利用声强、基频的变化程度差异,区分合成语声与真实语声是可行的且性能较好。
3.3.2 SNS特征有效性验证实验
为对比SNS 特征,选择基于语声频谱数据为基础进行变换得到的特征,分别为MFCC、Mel-Spectrogram、CQT、LFCC 特征。以上4 种对比特征均是在语声频谱数据的基础上设计应用不同的算法得到的特征,是目前合成语声识别领域性能较好、应用较多、设计较为前沿的特征,在欺骗性语声识别大赛上均能取得较好的实验效果。同时提取了宽带频谱图中的Formants(共振峰)特征来对比SNS特征。
通过采用相同的CNN 模型分别对SNS 特征以及Formants、MFCC、Mel-spectrogram、CQT、LFCC 特征进行对比实验,以发现本文使用的SNS特征化频谱声学特性的方法对合成语声识别任务的适用性,验证所设计语声的特征的有效性。根据结果计算的EER指标如表2所示。
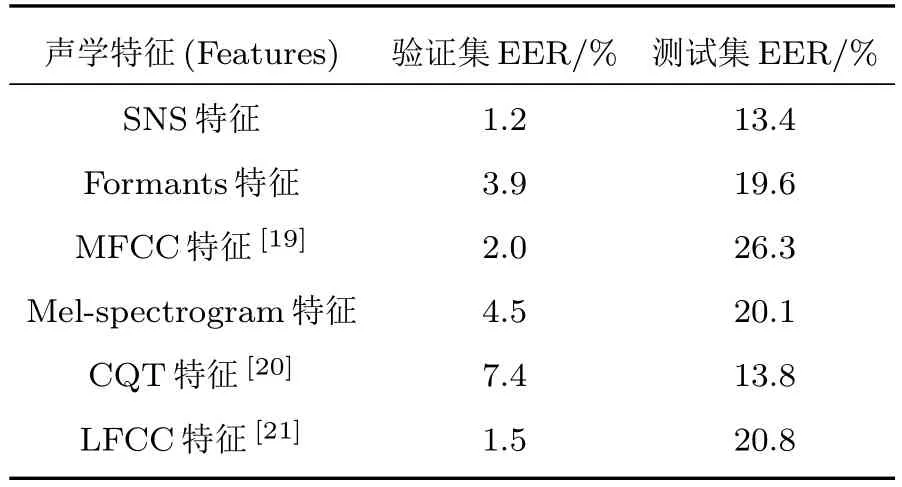
表2 SNS 和对比特征的实验结果Table 2 Experimental results of SNS and comparison features
由验证集实验结果可见,SNS 特征与对比特征都能识别合成语声。其中SNS 特征、Formants特征、MFCC特征、Mel-spectrogram特征、CQT特征、LFCC 特征的EER 分别达到了1.2%、3.9%、2.0%、4.5%、7.4%、1.5%。这表明利用频谱特性为基础的声学特征能够使模型学习到合成语声与真实语声之间的差异,并且SNS特征在验证集中的性能最优。
由测试集实验结果可见,同为频谱变换得到的SNS 特征和对比特征在相同的网络模型下,得到的EER 分别为13.4%、19.6%、26.3%、20.1%、13.8%、20.8%,其中SNS 特征EER 明显最低。这表明本文使用的SNS 特征对于训练集中没有学习过的语声合成算法同样保持着较好的识别性能,泛化性能更好。
通过对比上述实验结果可以发现:SNS 特征在验证集和测试集当中的识别性能是最佳的。这是因为SNS 特征表征的SNS 中包含了大量语声频谱声学特性,当CNN 模型利用该特性开展合成语声识别时,能更加直观地学习到谐波形态与分布宽泛程度的差异,优于宽带频谱图中Formants(共振峰)以及其他特征对于频谱特性的表达方法。因此,可见通过提取SNS 特征能够实现合成语声的识别,在表征出合成语声与真实语声频谱声学特性差异的同时,也证明利用该差异区分合成语声与真实语声是可行的且性能较好。
3.3.3 RMSA、FFV、SNS融合特征消融实验
通过采用DNN 模型分别对RMSA、FFV 特征进行深度向量表征,采用CNN 模型对SNS 特征进行深度向量表示,以融合特征化声学特性的声学特征。将三者的融合特征与消融后的单个特征进行对比,分析融合过程对最终的合成语声识别所带来的影响,验证融合特征的有效性。根据结果计算的EER指标如表3所示。

表3 RMSA、FFV、SNS 融合特征的消融实验结果Table 3 Results of ablation experiments of RMSA,FFV and SNS fusion features
通过对比可以发现:3 类特征融合后在验证集和测试集上表现最佳。这是因为不同的声学特征之间,存在着同质和异质之差的部分。特征数据内部不同部分对目标任务的价值高低也不尽相同。通过模型深度表示的方法对特征进行融合,可以相互补足异质有价值的数据、强化共有的同质关键数据以及弱化异质冗余数据。同时,证明了本文使用的3种声学特征之间的信息冗余较少,不同特征之间可以相互补充,使得融合后的数据信息价值更高。因此,通过利用RMSA、FFV、SNS 的融合特征开展合成语声识别是有效的,3 种特征之间包含着异质高价值数据,可以进一步降低EER,提升模型的识别性能。
3.3.4 RMSA、FFV、SNS 以及融合特征的损失变化曲线对比分析
在验证集下的特征损失曲线变化如图7 所示。可以发现,图7(a)中训练曲线和验证损失曲线在前10 个周期时下降速度较快,10∼30 个周期内缓慢下降,最后大约于第35 个周期逐渐收敛于平稳;图7(b)中训练损失曲线和验证测试曲线在前10 个周期内下降速度快,10∼20 个周期内缓慢下降,验证损失曲线存在波动,在大约第20 和第22 个周期时,训练曲线和验证损失曲线开始收敛于稳定值;由图7(c)可见,训练损失曲线在小于5 个周期内就收敛平稳,验证损失曲线在经过2∼3 次微小波动后于大约第12个周期就开始收敛于平稳;由图7(d)可见,训练曲线和验证损失曲线均在小于5 个周期内就开始收敛于平稳值,验证曲线仅经过一次骤升剧降,便趋于稳定下降。
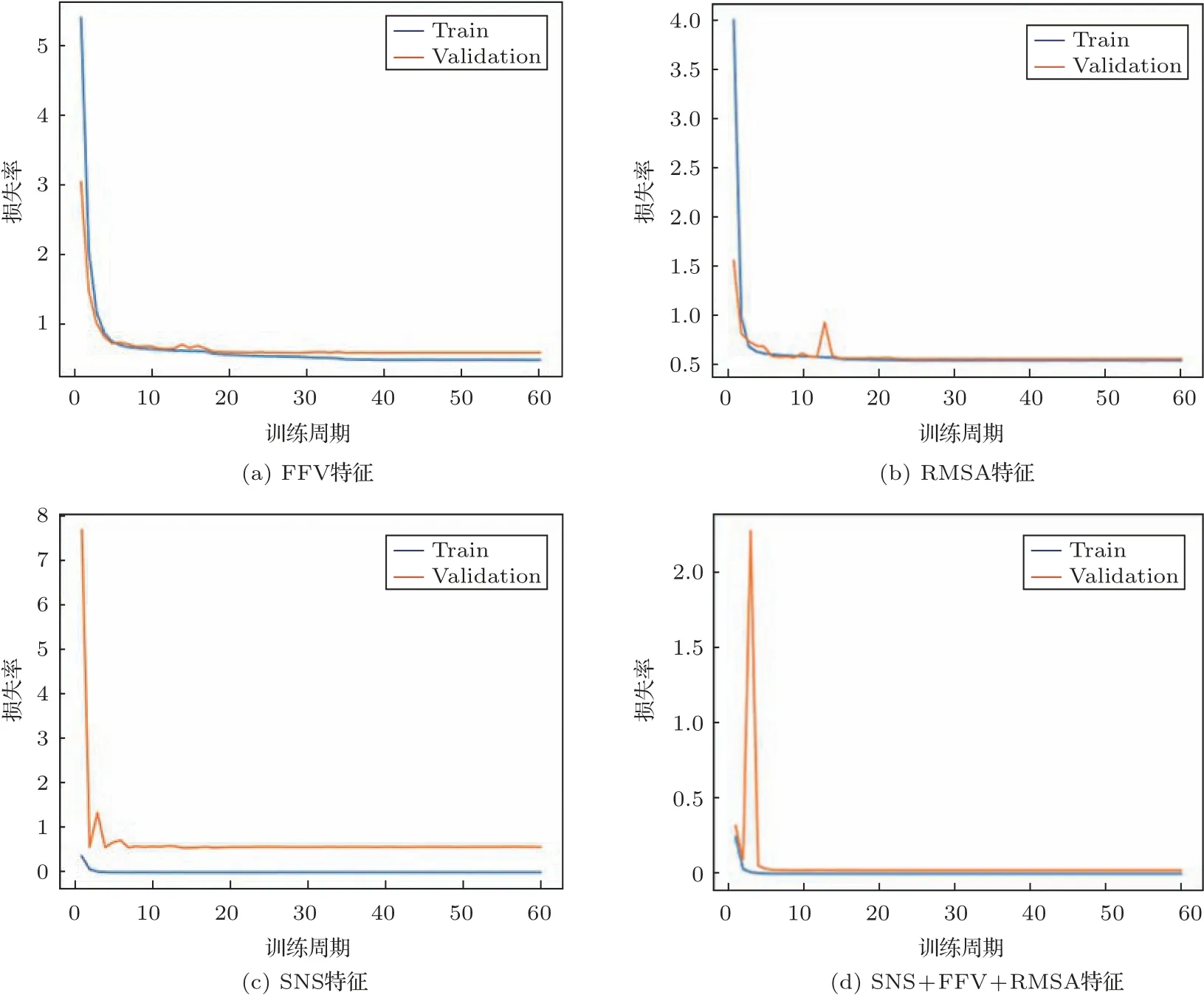
图7 单个特征和融合特征的损失曲线对比Fig.7 Comparison of loss curves of single features and fused features
通过分析以上的损失曲线观察结果可以发现:当将RMSA 特征、FFV 特征和SNS 特征融合输入至模型中时,模型的训练损失曲线和验证损失曲线下降速度进一步提高,起伏减少,稳定收敛所需周期进一步减小,反映出融合特征性能最佳。这是因为这3 种特征之间信息重复度较低,经过组合后能够较好地将合成语声与真实语声区分开来。进一步证实特征在本质上所反映出的是语声声学特性的不同方面,且均有利于合成语声的识别,也进一步反映出频谱声学特性对于合成语声识别精度的提高是极其重要的。
3.3.5 融合特征与已有研究成果对比实验
通过比对表4 可以发现:每组特征在不同的后端神经网络模型中的性能各不一样。其中在SERes-Net50 的模型下,本文提出的融合特征效果最佳;在SEResNet34 模型下,AFF 特征的效果最佳。除此之外,所提融合特征相比其他特征在不同模型下的表现差异更小,性能更为稳定。这是由于所提融合特征的构成是来自于频谱、基频、声强3 个不同方面,不同特征之间相互补足,所以面对不同模型均能保持良好性能。融合特征在没有SE 模块的ResNet+DNN 模型下的表现依次优于SERes-Net34/SEResNet50+DNN 模型,是因为SE 注意力模块并不能有效聚焦本文所提融合特征中的关键数据信息,导致,实验EER的提高。
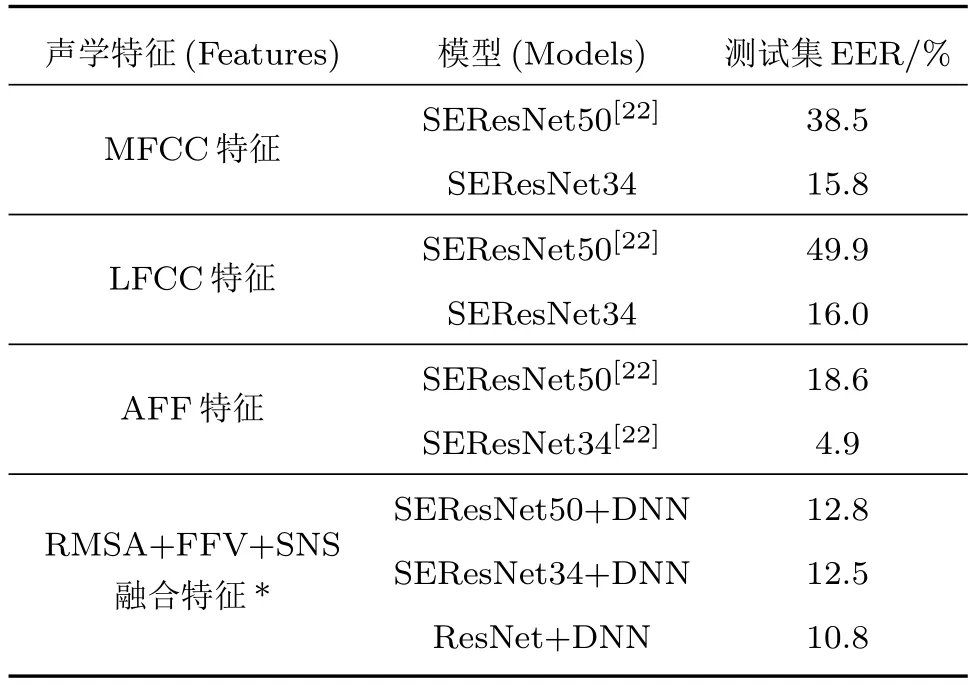
表4 RMSA、FFV、SNS 融合特征和已有研究的实验结果Table 4 Experimental results of RMSA,FFV,and SNS fusion features and existing studies
由此可见,不同的后端分类模型对特征的性能影响较大。这是因为不同的模型对不同数据类型特征的学习程度不同,好的模型将能更为充分高效学习到关键信息。因此,接下来将开发适用所提融合特征的深度神经网络模型,提高特征利用率,进一步强化识别合成语声的性能。
综合上述实验可见,基于声强和基频的变化程度和语声频谱特性数据特征化得到的RMSA、FFV、SNS 特征皆可适用于合成语声识别任务。对比3 种特征性能,在面对已知算法的数据时,三者都拥有较好的性能,能较好地实现合成语声的识别。而面对训练集中没有的新算法干扰时,SNS 特征的泛化性能最优,RMSA特征其次,FFV特征最差,三者通过融合后的性能最佳。
4 结论
为实现利用声学特性实现合成语声识别的目标,本文着重论述了基于声学特性的声学特征的提取和设计算法,开展了深度学习实验验证所提特征的有效性。实验结果表明,基于声强、基频变化程度和频谱特性数据特征化的RMSA 特征、FFV 特征、SNS 特征模型以及三者的深度融合特征在使用深度学习方法进行合成语声识别任务中,达到了较好的分类效果,实现了合成语声与真实语声的辨别。对于目前合成语声识别领域大量使用频域特征进行识别的现状,从声学角度进行对语声差异进行分析描述,拓宽了研究思路,形成了较为完备的特征研究过程,为合成语声识别领域提供了不同的特征设计方法,为深度学习方法提供了前提条件和实验基础。
在后续深化研究的过程中,将设计和使用更优的深度神经网络模型,改进深度学习方法,针对所提声学特征设计优化识别模型结构,提高声学特征的使用效率,更大程度地发挥声学特征效能。进一步拓展研究深度,将能使得合成语声的识别更加准确。
猜你喜欢
机械科学与技术(2024年2期)2024-03-21
振动与冲击(2022年17期)2022-09-23
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27
山东交通科技(2020年2期)2020-08-13
家庭影院技术(2020年6期)2020-07-27
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
电子制作(2017年20期)2017-04-26
