
基于深度学习的浮选回收率预测建模研究
2024-03-02 13:01赵红宇何桂春江长松吴为波
金属矿山 2024年1期
赵红宇 何桂春 石 岩 江长松 吴为波
(1.江西省矿业工程重点实验室,江西 赣州 341000;2.江西理工大学资源与环境工程学院,江西 赣州 341000)
浮选是将有用矿物与脉石矿物分离的重要方法,但浮选过程非常复杂,对浮选指标的干扰因素众多,如何根据矿石性质等因素前瞻性地预测浮选精矿指标,进而采用自动控制系统及时进行工艺技术参数调整,以实现矿山企业经济效益的最大化具有重要意义。
在保证精矿品质的情况下,尽可能提高目标矿物的回收率,既是矿山企业追求经济效益的要求,更是矿产资源高效综合利用的要求,因此,对浮选回收率进行有效预测具有重要意义。
随着计算机技术的飞速发展,选矿行业的智能化发展备受关注[1-2],但由于传统机器学习方法[3-5]通常采用相对规模较小的数据进行预测建模[6],对于复杂问题和大规模数据,存在数据滞后、泛化性差及准确性低等问题[7],难以满足智能化浮选的要求。因此,研究动态实时的浮选回收率预测技术成为智能化选矿建设的重要一环。 深度学习是一种模仿神经网络的学习算法,用于复杂数据模式识别与预测,已在机械刀具损耗预测[8]、电力系统电网频率预测[9]、采矿岩爆烈度分级预测[10]以及隧道掘进机净掘进速率预测[11]等方面取得显著进展。 在浮选领域,已有学者采用深度学习中卷积神经网络使浮选泡沫图像分类的准确率得到提升[12-14]、采用前馈神经网络使浮选药剂用量的预测精准度得到提升[15]、采用长短记忆网络实现对精矿品位的有效预测[16]。
目前,已有不少关于传统机器学习预测浮选回收率方面的研究成果,但是利用深度学习预测浮选回收率的相关性研究较少,尤其是大量实际工况数据下的浮选回收率预测建模。 因此,本研究以某铜矿实际工况数据为基础,通过箱图与滤波算法对数据进行预处理,采用传统机器学习算法(DT、RF、SVR)、深度学习算法(DNN、CNN)构建相应浮选回收率预测模型,并通过实际生产数据对预测模型的预测精度加以验证,得到最优预测模型,为浮选回收率实时预测及浮选过程协同优化提供技术支持。
1 模型算法与评估方法
1.1 传统机器学习算法模型
DT 基于熵最小原理建模,是一种基于树结构来进行决策的方法。 在训练数据集的输入空间中,递归地将每个区域划分为2 个子区域,并决定每个子区域上的输出值,流程如图1(a)所示。 采用平方误差(MSE)作为特征选择的准则,通过计算MSE,选择最小MSE 为最优特征与切分点[17]。 RF 由决策树组成。 在处理回归预测问题时,取多棵决策树预测值的平均值作为RF 预测结果,流程如图1(b)所示。 SVR是一种支持向量机算法的变体,与传统的线性回归方法不同,SVR 专注于处理非线性回归问题,并具有一定的鲁棒性和泛化能力,流程如图1(c)所示。 SVR将输入数据映射到高维空间,尝试构建一个能够将所有训练样本投影到高维空间中的超平面,使得该超平面上离最接近的训练样本点的距离最大化,同时保证间隔边界内的样本点尽可能满足预测结果。 RF 模型结构如图2 所示。
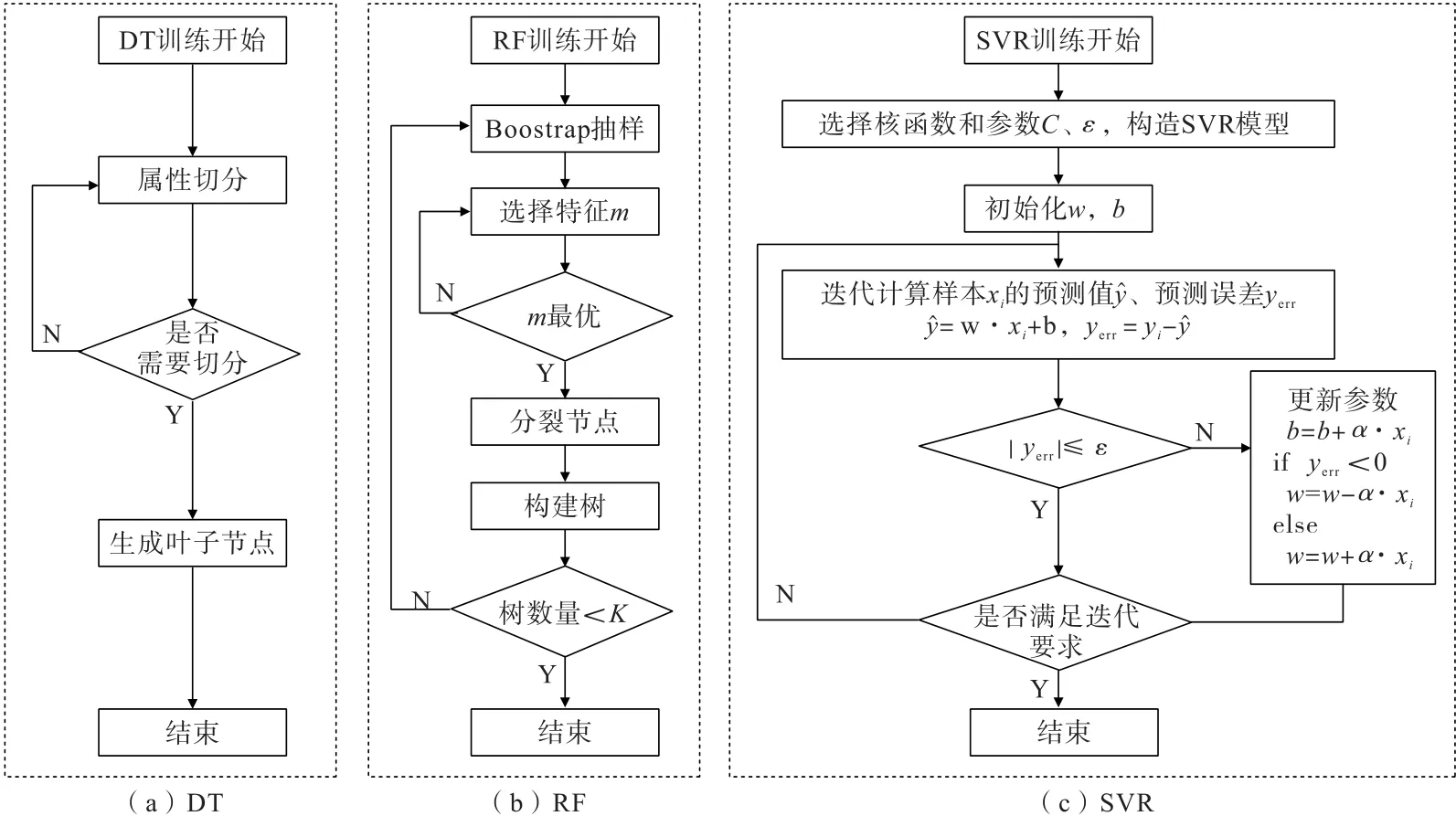
图1 DT、RF 和SVR 算法流程Fig.1 Flow of DT,RF and SVR algorithm

图2 RF 模型结构Fig.2 RF model structure
1.2 深度学习算法模型
1.2.1 DNN 算法模型
在DNN 模型中,输入层和输出层的大小由输入输出的维度决定。 DNN 模型神经元分层排列,网络结构分为输入层、隐藏层、输出层,如图3 所示。 其中隐藏层的深度体现网络深度,每个神经元仅与前一层神经元相连。 神经元输出计算方式如图4 所示,计算公式见式(1)。
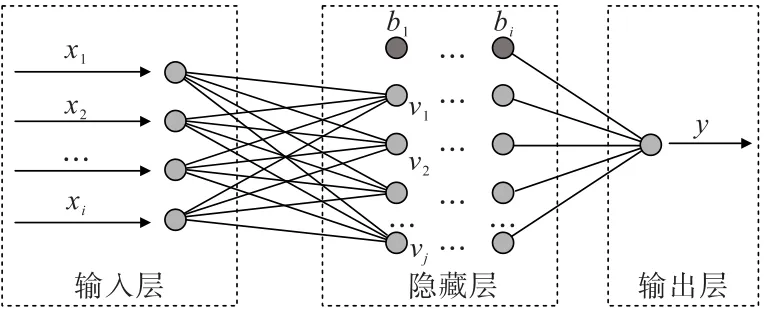
图3 DNN 网络结构Fig.3 DNN network structure

图4 神经元计算方式Fig.4 Neuron computing method
DNN 模型训练分为两阶段。 其一是前向传播阶段,数据信息从输入层传递至网络各层,经神经元变换逐级传递至输出层;另一个阶段为反向传播阶段,将向前传播所得的预测值与实际值的Loss函数(式(2)),Loss通过梯度下降进行反向传播(式(3)、(4)),逐层更新神经网络各个层的可训练参数(权值W和偏置b)。 学习速率参数(α)用于控制损失函数反向传播的强度。
1.2.2 CNN 算法模型
CNN 是一种具有深度结构和卷积运算的前馈神经网络,是深度学习代表算法之一,具有非线性数据特征的提取能力。 CNN 主要由卷积层、池化层、全连接层组成,如图5 所示。

图5 CNN 结构典型模型Fig.5 Typical model of CNN structure
卷积层[18]是CNN 的核心部分,具有特征提取、特征映射、局部连接、权值共享、非线性激活的特点。通过不同卷积核,按照步幅和填充,在特征平面上取与之相应位置的内积,提取输入数据中局部特征,即为卷积运算。 不同的局部特征反映了输入数据中不同特征的存在位置。 同时,因卷积核参数在不同位置具有共享性,从而减少了模型的参数数量,降低了数据的空间维度,增加了模型的表达能力。
池化层[18]是一种常用的操作层,用于对输入数据进行下采样[19](降维)和特征提取。 通过对输入数据进行空间上的降采样,有助于减少数据的空间维度;通过降低特征图的维度和尺寸,有助于减少后续层的计算量;通过在每个池化窗口中选择最显著的特征值来提取主要特征,有助于增强数据的鲁棒性。 同时,池化层具有平移不变性的特性,对输入的平移或位置变化不敏感。 以上特征使得模型能够在不同位置或尺度的特征上获得相似的响应,增强了模型的位置不变性和对局部特征的抽象能力。 本研究采用一维卷积神经网络(1D-CNN),网络结构如图6 所示。

图6 1D-CNN 回收率预测模型Fig.6 1D-CNN prediction model for recovery rate
1.3 模型评估方法
采用平均绝对误差(MAE)、均方根误差(RMSE)、拟合优度(R2)、相对误差(RE)对模型性能进行评估,检验预测模型的优劣[20-21],计算公式见式(5)~(8)。
其中,n为样本数量,Σ 表示求和运算,分别为真实值、预测值、平均值。MAE、RMSE和RE值越小,表示模型的预测结果越接近真实值;R2越接近于1,表明模型的预测结果越贴近实际值。
2 结果与讨论
2.1 数据来源与预处理
2.1.1 数据来源
本研究的数据采自江西某铜选矿厂,为160 m3浮选机选矿系列粗选工段实际生产数据,工艺流程如图7 所示。 所收集数据时间跨度为2022 年1 月1 日到2022 年7 月1 日,共182 d,每组数据为记录时刻前1 h 内的平均值,共4 368 组,定义的各输入变量如表1 所示。
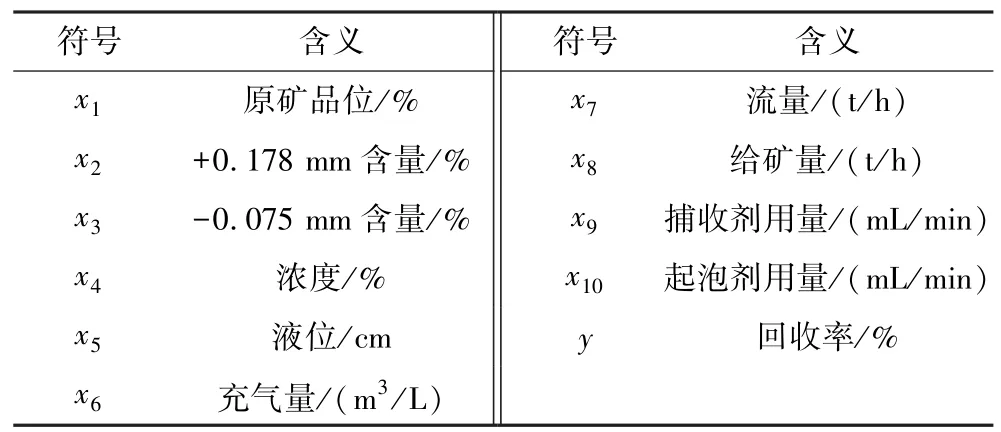
表1 输入变量Table 1 Input variables

图7 160 m3 系列粗选工段工艺流程Fig.7 Process flow of 160 m3series rough selection section
2.1.2 数据预处理
使用describe()方法对工况数据进行描述性统计分析[22],结果如表2 所示。 由于构建预测模型所收集的工况数据浮动变化较大,存在缺失值、异常值,需要将源数据进行预处理。
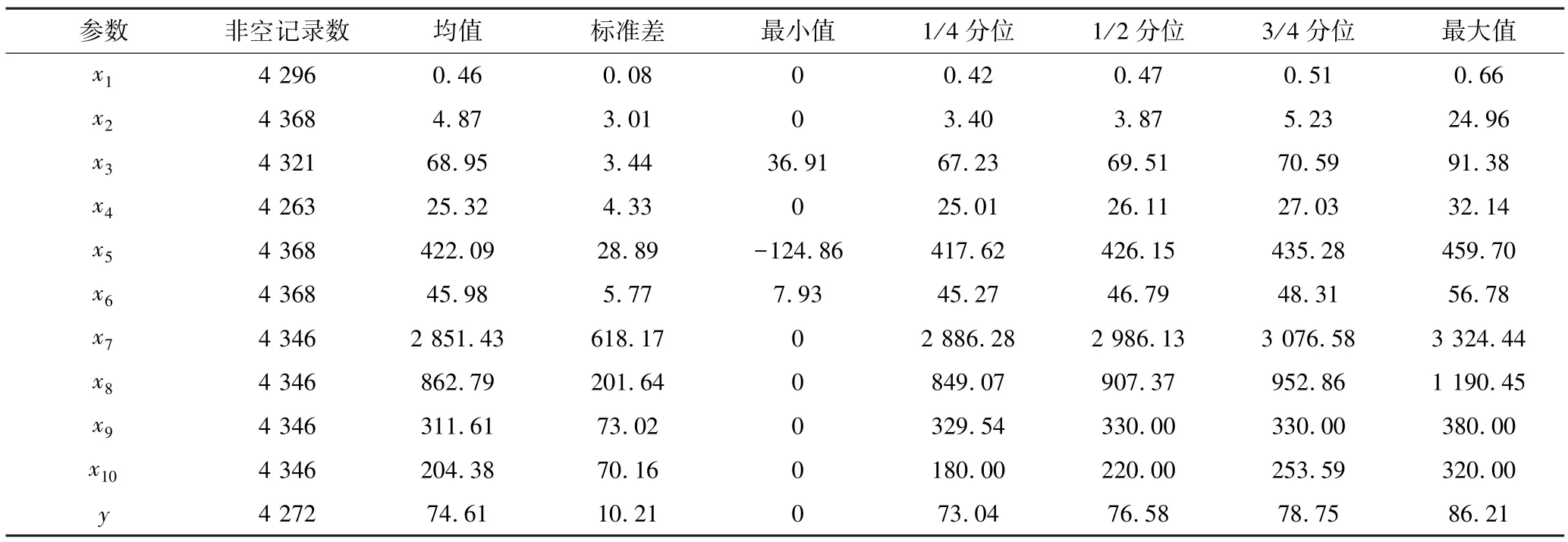
表2 统计分析Table 2 Statistical analysis
由表2 可知,y的count 数值数量低于4 368,可知样本数据存在缺失值。 其中x4缺失105 个记录。对缺省值进行剔除,此外,由表2 及四分位数的大小可对数据集各工况参数的异常值情况进行估计,11组参数中均存在异常值,需要进行异常值处理,其中x7、x8偏差最为严重,分别达标618.17、201.64,数据离散较为严重。
在对数据进行处理之前,为避免不同的浮选工况特征量之间存在量纲上的差异,对数据处理、模型训练与优化造成困难,需将训练数据集进行归一化[23]。
针对异常值问题,使用箱图和滤波处理的方法对原始数据进行处理。 首先,使用箱图检测异常值,找到数据集中的低密度区域,采用截断剔除的方式处理;其次,将处理后数据进行滤波处理,可去除噪声、平滑数据和提取数据特征。 这种联合使用的方法可以提高数据的可靠性、可视化和分析能力,为后续的工况分析、建模提供更好的基础。
工况数据经缺失值与异常值的剔除,数据集由4 368 条记录变为3 344 条记录。 根据滤波算法对输入数据进行处理,去除异常波动值,使数据更加可靠、稳定、平滑,减少噪声对数据分析处理的影响,有助于提取数据特征。
2.2 浮选预测的传统算法模型比较分析
基于DT、RF 和SVR 算法,结合工况数据,构建了DT、RF 和SVR 回收率预测模型。 对模型进行多次迭代运算,探究了DT、RF 和SVR 预测模型的最优参数,如表3 所示。 通过训练集对模型进行训练,采用测试集对模型进行验证。 各回收率预测模型评估指标如表4 所示,预测效果如图8 所示。
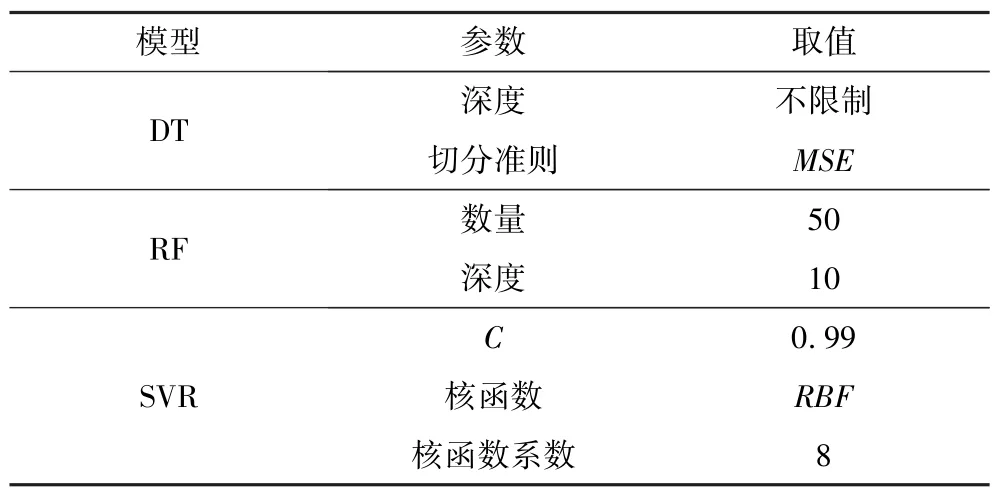
表3 DT、RF 和SVR 回收率预测模型参数设定Table 3 Parameter settings for DT、RF and SVR prediction model parameter setting

表4 基于传统机器学习算法的回收率预测模型评价指标Table 4 Evaluation metrics for a recycling rate prediction models based on traditional machine learning algorithms
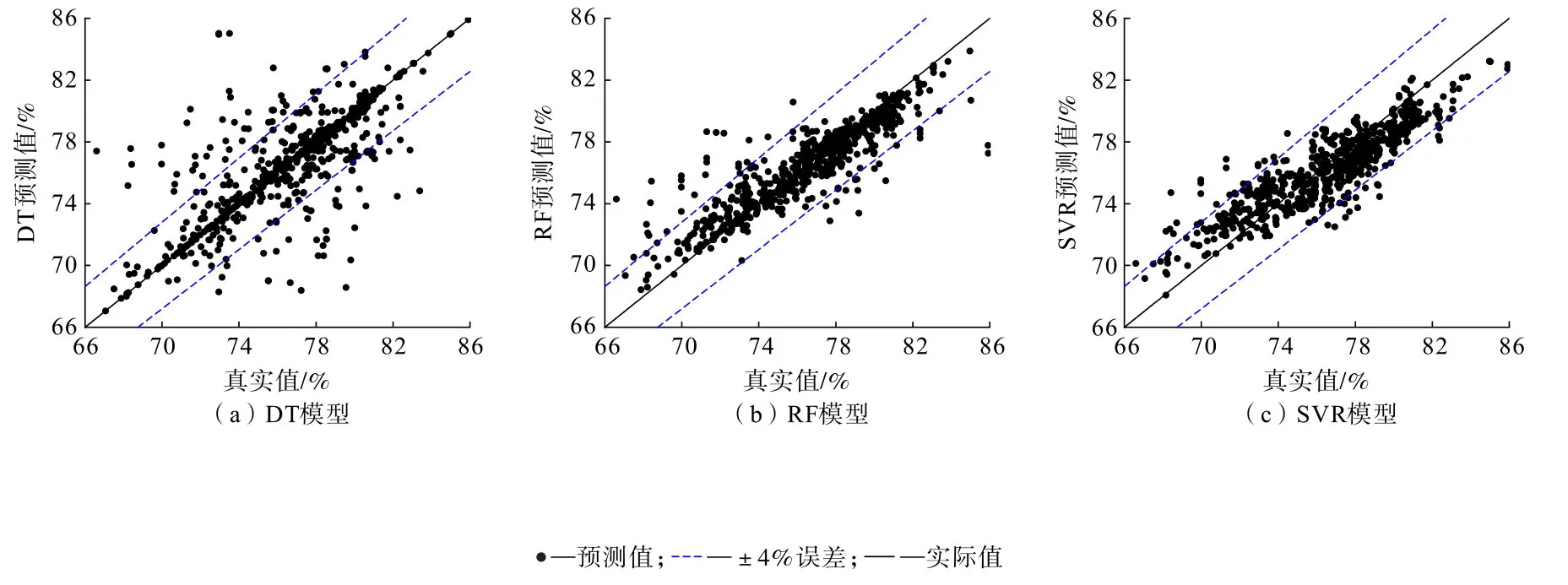
图8 基于传统机器学习算法的回收率预测模型预测值分布Fig.8 Prediction value distribution of recycling rate prediction model based on traditional machine learning
分析表4、图8 可知,基于传统机器学习算法的回收率预测模型中,DT、RF 和SVR 回收率预测模型的R2分别为0.501、0.782 和0.759,其中DT 预测模型的R2最小。 结合图8(a)可知,DT 模型回收率预测值分布较离散,与真实值的线性关系不显著,拟合效果较差,其原因为DT 模型过于简单,单颗决策树无法对多维数据进行有效划分。 RF 预测模型和SVR预测模型的R2均大于0.7,预测效果较好。 但二者MAE指数大于1、RMSE指数大于1.5,结合图8(b)和图8(c)可知,RF、SVR 模型的回收率预测值分布较集中,与真实值具有显著的线性关系,误差基本分布于±4%范围内。 可见,RF、SVR 模型的预测效果较好,但个别预测值仍存在较大预测误差。
2.3 浮选预测的深度学习算法模型比较分析
由基于传统机器学习算法的回收率预测模型结果可知,DT、RF 和SVR 模型的效果并不理想,采用深度学习算法中的DNN 和CNN 算法,构建DNN 和CNN 回收率预测模型。 经模型的迭代训练,探索最优的预测模型参数,各参数如表5 所示。 基于深度学习算法的回收率预测模型的评估指标如表6 所示,预测效果如图9 所示。

表5 DNN、CNN 预测模型参数设定Table 5 DNN、CNN prediction model parameter setting

表6 基于深度学习算法的回收率预测模型评价指标Table 6 Evaluation indicators of recycling rate prediction model based on deep learning algorithms

图9 基于深度学习算法的回收率预测模型预测值分布Fig.9 Prediction value distribution of recycling rate prediction model based on deep learning algorithms
由表6 和图9 可知,DNN 和CNN 模型的R2分别为0.854、0.907,均大于0.85,拟合效果较好。 DNN和CNN 回收率预测模型的预测值分布在实际回收率的两侧,分布在±4%误差范围外数据点较少,与传统机器学习的回收率预测模型相比,DNN 和CNN 模型回收率预测值更接近实际值。 其中,与RF 模型相比,DNN 模型的评价指标R2、MAE和RMSE分别提升了9.2%、23.6%和18.1%;CNN 模型的评价指标R2、MAE和RMSE分别提升了16. 1%、42. 3%和35.0%。说明基于深度学习算法的DNN 和CNN 回收率预测模型均能取得较好预测效果。
相较于DNN 模型,CNN 模型回收率预测值分布更为集中,DNN 模型的MAE为0.797,RMSE为1.322,CNN 模型的MAE为0. 601,RMSE为1. 049。 在MAE、RMSE和R2上CNN 模型均优于DNN 模型,说明在回收率预测效果上,CNN 模型优于DNN 模型。
2.4 各算法模型比较分析
为了进一步验证各预测模型的预测效果,分别对各回收率预测模型进行预测误差和误差准确率对比分析,结果如表7、表8 所示。
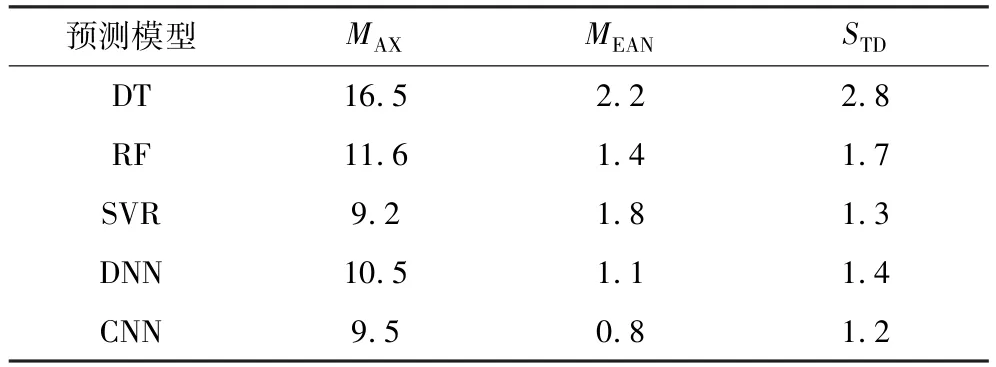
表7 各回收率预测模型预测误差统计分析Table 7 Statistical analysis of prediction errors in various recovery rate prediction models %
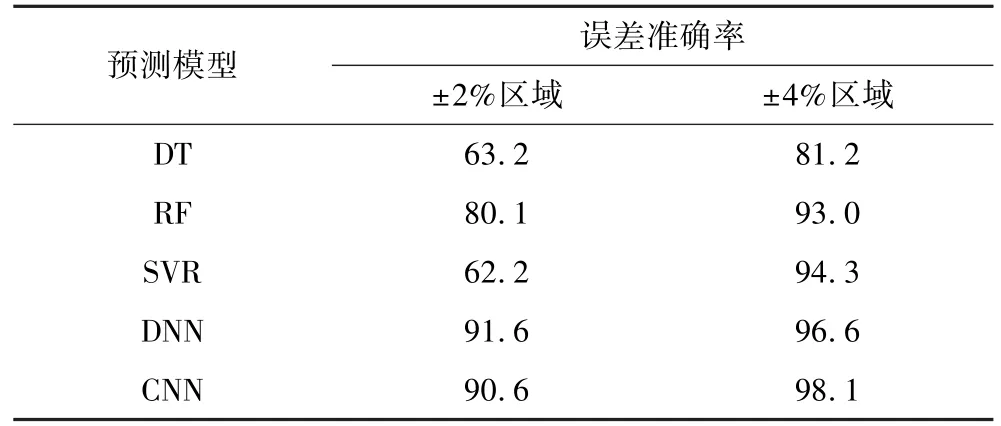
表8 各回收率预测模型预测命中率Table 8 Each recycling rate prediction model predicts the hit rate %
由表7 可知,在基于传统机器学习算法的回收率预测模型中,SVR 模型的MAX、STD最低,优于DT、RF模型,说明SVR 模型较为稳定,但MEAN并非最优。同时,结合表8 可知,SVR 模型的±2%误差命中率最低,±4%误差命中率最优,可知SVR 模型在±4%误差范围内模型比较稳定,而在±2%误差范围内精度欠佳。 相较于SVR 模型,RF 模型在MAX和STD上效果欠佳,但两模型相差较小,而在MEAN上RF 模型优于SVR 模型。 RF 模型在±2%误差范围精度最佳,±4%误差范围RF 模型与SVR 模型相差仅1.3 个百分点,表明RF 模型较为稳定,精度较高,但RF 模型的MAX为11.6%,说明该模型存在偏差较大的预测值。 其原因是RF 模型和SVR 模型对数据的特征敏感程度不同,RF 模型为复杂的模型,易受训练数据中噪声和细节的影响。 综上所述,认为在基于传统机器学习算法回收率预测模型中,RF 预测模型预测精度最佳。
基于深度学习算法的回收率预测模型拟合效果优于基于传统机器学习算法的回收率预测模型。 由表7 可知,DNN 模型和CNN 模型的MEAN分别为1.1%、0.8%,预测误差较小,均优于传统机器学习算法模型。 CNN 模型的STD数值最小,而DNN 模型的STD略高于SVR 模型的。 DNN 模型和CNN 模型的MAX分 别 为10. 5%、 9. 5%, 均 高 于 SVR 模 型(9.2%),说明对于MAX指标,DNN、CNN 模型均非最优。 结合表8 可知,DNN 模型和CNN 模型在±2%误差命中率分别为91.6%、90.6%,±4%命中率分别为96.6%、98.1%,均优于传统机器学习算法模型。 综合MEAN、MAX、STD指标,DNN 模型与SVR 模型虽在STD指标上相差不大,但在MEAN上,DNN 明显优于SVR 模型,表明DNN 模型预测更为稳定,但存在少数预测偏差较大的预测值。
基于深度学习算法的回收率预测模型中,CNN模型在预测效果上优于DNN 模型。 由表7 可知,CNN 模型的MEAN、MAX、STD指标均略优于DNN 模型。同时,由表8 可知,DNN 与CNN 模型在±2%误差分别为91. 6%、90. 6%,± 4% 误差分别为96. 6%,98.1%。 说明DNN 模型预测精度上略优于CNN 模型,而CNN 预测具有更好的稳定性。
模型的构建时间也是评价模型的重要指标,但往往因计算机硬件软件的差异有所变化,本模拟所使用的计算机配置如下: CPU i7-6500U; 主板戴尔0K64R6;内存16.00 GB(1 600 MHz 三星);硬盘240 GB(希捷);显卡AMD Radeon(TM) R5 M335;系统Windows 10(64 位);Python 3. 8(32-bit);Pycharm Community Edition 2021。 训练集与测试集运行时间如表9 所示。

表9 各回收率预测模型训练集与测试集运行时间对比Table 9 Comparison of running time between training and testing sets of various recovery rate prediction models
由表9 可知,训练集所需运行时间随着模型复杂程度的增加而增加,各模型测试集所需运行时间均小于1 s。 在浮选回收率的预测中,测试集的数据为当前时刻5 s/10 s/30 s/60 s 内的工况信息,数据量较小。 模型在小数据集下,均为秒级响应。
在现实工况下,浮选流程必然产生海量数据,随着数据量的增加,对模型的训练时间必然增加,现将训练集与测试集扩大100 倍,训练集267 500 条,测试集66 900 条,代入DNN、CNN 模型中,所需运行时间如图10 所示。

图10 百倍数据集下各回收率预测模型耗时Fig.10 Time consumption of various recovery rate prediction models on a hundred fold dataset
由图10 可知,CNN 模型训练时间约为DNN 模型的5 倍,而两模型测试集耗时相差约为1 s,表明DNN 模型后期维护成本优于CNN 模型。 同时,随着数据集的增加,DNN 模型的预测效果有所提升,最优模型下,DNN 模型的R2为0.891,与CNN 模型的R2(0.907)仅相差0.016,表明在大数据集下两模型回收率预测效果相差并不显著。
3 结 论
(1)从浮选工况数据的特征出发,首先对工况数据采用了箱图和滤波结合的处理方法,其次分别采用DT、SVR 和RF 这3 种传统机器学习算法,对浮选回收率进行预测建模,构建多种算法预测模型。 结果表明,传统机器学习算法模型中RF 预测精度最佳,±2%误差区域80.1%,±4%误差区域为93.0%。
(2)基于深度学习算法的回收率预测模型拥有更好的准确度。 DNN 和CNN 预测模型的R2分别为0.854、0.907,±2%误差区域命中率分别为91. 6%、90.6%,±4%误差区域命中率分别为96.6%、98.1%。深度学习模型预测效果均优于传统机器学习算法模型,采用深度学习算法建立铜矿的浮选回收率模型能够获得较好的预测精度。
(3)针对深度学习算法的回收率预测模型首选DNN 模型。 单从预测效果来看,CNN 模型略优于DNN 模型;从模型运行耗时来看,由于CNN 算法复杂度较大,训练耗时较长,而两者测试耗时均为秒级响应;通过将数据集扩大,发现DNN 模型的R2与CNN 模型的仅相差0. 016,CNN 模型预测效果并不显著,且以±2%误差区域命中率为依据,则DNN 模型预测精度略优于CNN 模型。
猜你喜欢
今日农业(2021年19期)2022-01-12
中国土壤与肥料(2021年5期)2021-12-02
环境保护与循环经济(2021年7期)2021-11-02
今日农业(2020年22期)2020-12-14
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
国外核新闻(2020年8期)2020-03-14
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
电力需求侧管理(2014年4期)2014-03-20
