
基于知识图谱嵌入与深度学习的药物不良反应预测
2024-03-04 06:05吴菊华李俊锋
广东工业大学学报 2024年1期
吴菊华,李俊锋,陶 雷
(广东工业大学 管理学院, 广东 广州 510520)
药物不良反应(Adverse Drug Reaction, ADR)是全球重要的公共卫生问题,是导致死亡的重大原因之一[1]。全球范围内因ADR导致的伤残或死亡患者每年近80万例,占所有入院患者的3.6%[2]。在美国,每年约200余万名住院患者发生严重ADR,造成5 284亿美元经济损失,约占当年医疗总支出的16%[3]。我国每年也有超过250万人因ADR入院, 其中死亡人数高达19.2万人[4];2018年中国药品不良反应监测网络收到149.9万份药品不良反应/事件报告[5],且数量呈逐年增长趋势。尽管药物在被批准上市之前,经过严格试验,但由于样本数量及试验时间限制,许多严重ADR直到药物上市后才出现[6]。此外,高达50%与ADR相关的住院,可以通过避免不适当的处方来预防[7]。因此,如何有效识别和预测药物潜在的不良反应,预防ADR发生以及降低经济损失,提高临床用药的合理性和安全性,是当前智慧健康医疗领域的一个研究重点[8-9]。基于此,本文开发一种基于知识图谱嵌入和深度学习的ADR预测模型,并与多种常用基准模型及已有研究结果进行对比分析,同时检验本文预测模型的有效性和稳定性。本文的贡献可以概括如下。
(1) 本文结合知识图谱嵌入和深度学习开发了一种稳定且高效的ADR预测模型,将所有类型ADR进行统一预测,减少过往研究需要为每种ADR单独开发预测模型的冗余工作量,提高预测效率和精度。
(2) 本文通过对比评估不同嵌入策略对ADR分类模型的影响,选择最佳嵌入策略,所开发的ADR预测模型能够有效预测药物潜在的不良反应,为医生在用药时提供建议,提高患者的用药安全。
1 相关研究
根据世界卫生组织的定义,药物不良反应是指在使用正常剂量的药物用于预防、诊断、治疗疾病或调节生理机能过程中,出现有害和非预期的且与用药目的无关的反应[10];且ADR可能是药物化学物质与蛋白质反应的结果[11]。早期对于ADR的研究,主要基于自发报告系统(Spontaneous Reporting Systems,SRSs) 的临床案例数据[7,12],使用比例失衡分析[13]等方法评估药物与ADR之间的关联性和因果性,以挖掘相关药物不良反应信号。但SRSs的数据往往是不完整或不准确的,可能会导致研究结果有所偏差;此外加之数据量有限,缺乏对数据的深度挖掘,使得早期基于简单统计方法的研究结论缺乏说服力[14]。随着人工智能技术日趋成熟和生物医学数据量不断增长,一方面,研究人员基于文献、ADR报告等文本数据,结合自然语言处理技术挖掘药物潜在的不良反应[15-17];另一方面,基于药物的化学、生物学以及表型特征,使用机器学习或深度学习方法进行ADR预测研究[18-21]。基于文本挖掘的研究常用于识别和监测相关ADR,其假定相关ADR已出现,但无法预测药物潜在的ADR;而基于药物特征和机器学习的ADR预测研究,有助于探索药物未知的ADR,这也是本文的研究主题。
机器学习相关方法能够提升ADR预测效果,但这些研究仍存在可改进的关键点:(1) 未考虑药物之间关联关系,可能导致有用信息丢失;(2) 使用大量独热编码的特征数据,而高维稀疏特征矩阵降维难度大,模型计算效率低;(3) 绝大多数需要为每种ADR单独构建分类器。而知识图谱(Knowledge Graph, KG)这种由节点和关系构成的特殊网络结构及其嵌入技术,通过将实体嵌入连续低维的特征空间,捕获特征实体之间非结构化语义关系,在不同类型信息之间实现融合和计算,能有效缓解高维稀疏特征数据带来的计算低效问题,提高分类器预测性能[22-24]。
近年来,知识图谱及其嵌入技术逐渐被应用于药物研究领域的知识发现和知识库构建,这些研究通过获取药物特征数据,构建含有不同类型节点的知识图谱,通过知识图谱嵌入技术结合分类模型进行相关研究主题的目标预测。基于 KG的ADR预测,相关典型研究如表1所示。通过文献综述,当前研究仍存在以下有待改进的要点:(1) 使用KG中未出现的“drug-ADR”组合作为ADR预测模型的负样本,但KG中不存在的“drug-ADR”组合可能只是目前尚未被发现[21];(2) 使用简单的机器学习模型;(3) 所覆盖的药物数量较少,特征局限于药物靶点和适应症,诸如酶和载体蛋白之类的重要信息尚未在先前的研究中使用。

表1 相关典型研究Table 1 Relevant typical studies
基于此,本文采用知识图谱嵌入与深度学习相结合的方法实现ADR预测,除靶点和适应症之外,还整合了酶和载体蛋白信息构建知识图谱;并开发一个强大的深度神经网络,提高ADR的预测性能。
2 数据与方法
在本文提出的方法中,参考文献[25]和[26],将药物的副作用(Side Effect) 视为ADR。鉴于结合药物的生物学特征和表型特征能够提升ADR预测模型性能[18,25],从DrugBank(v5.18)[30]和SIDER(v4.1)[31]数据库分别选择靶点(Target) 、载体(Transporter) 、酶(Enzyme) 等生物学特征和适应症(Indication) 和不良反应(ADR) 等表型特征,以及药物(drug) 作为知识图谱实体节点。然后,为规避为每种ADR构建单独分类器所增加的沉重工作量,将ADR预测视作一个统一的二分类问题,并使用“drug-ADR”组合和“drug-Indication”组合分别作为分类模型的正样本和负样本,样本标签分别记作“1”和“0”。由此开发一个基于知识图谱嵌入和深度学习的ADR预测模型,通过5次重复实验,检验卷积神经网络(Convolutional Neural Networks, CNN)模型稳定性。最后,以药物性肾功能损伤为例进行预测,并通过真实世界数据验证模型预测的有效性。具体研究思路如图1所示。

图1 ADR预测研究框架Fig.1 Research framework of ADR prediction
2.1 数据来源与知识图谱构建
DrugBank数据库涵盖丰富的生物和化学信息学资源,SIDER数据库收录了1 430种药物,6 000余种副作用。通过下载DrugBank中xml数据文件和SIDER中tsv文件,使用Python程序解析并获得药物的相关特征数据。根据药物解剖治疗化学代码(Anatomical Therapeutic Chemical, ATC) 整合2个数据库的相关数据,并筛选至少具有1种药物特征的药物记录。最终构建5类三元组:<drug, hasTransporter, Transporter>、<drug, hasADR, ADR>、<drug, hasEmzyme,Emzyme>、<drug, hasTarget, Target>、<drug,hasIndication, Indication>;将三元组储存至Neo4j图数据库,获得可视化知识图谱,如图2所示。该图谱共包含了7 916种drug、5 454种ADR以及158 121个三元组,具体如表2所示。

图2 ADR知识图谱中的部分实体和关系Fig.2 Local entities and relationships in the knowledge graph

表2 ADR知识图谱包含的实体、关系及其数量Table 2 Entities, relationships and quantities included in the ADR knowledge graph
2.2 知识图谱嵌入模型
知识图谱嵌入技术逐渐被应用于预测研究[22],其中基于张量分解的DistMult[32]模型和HolE[33]模型应用最为广泛。DistMult模型通过实体之间的双线性变换来描述实体之间的语义相关性,其中头实体和尾实体分别由向量h和t表示,关系由向量r表示;关系矩阵Mr=diag(r)对潜在因子之间的成对相互作用进行建模,使用fr(h,t)=hTMrt作为评分函数。HolE模型以DistMult模型为基础,在实体之间引入循环相关运算,以捕获成对实体的组成表示,使用fr(h,t)=rT(h*t) 作为评分函数,式中* 为循环相关运算。上述2种嵌入模型均以最小化评分函数作为目标,以获得实体和关系的有效嵌入向量。
2.3 CNN分类模型
研究设计了一个具有2个卷积层,4个全连接层的CNN模型,如图3所示。由于ReLU激活函数计算效率和收敛速度等特性远高于sigmoid、Tanh等函数;因此,卷积层和全连接层均使用ReLU激活函数。同时,为使得每一层神经网络的输入保持相同分布和提高网络优化效率,卷积层均使用批归一化处理(Batch Normalization) ,模型具体参数如表3所示。本文使用式(1) 所示的二元交叉熵作为模型训练的损失函数,式中:n为训练样本总数,yi为 样本i的真实标签,^yi为样本i被预测为类别 “1” 的概率值;通过模型训练,获取参数W和b的最优值。

图3 用于ADR预测的CNN模型结构图Fig.3 CNN model structure diagram for ADR prediction

表3 CNN模型参数Table 3 Parameters of CNN model
采用逻辑回归(Logistic Regression, LR) 、K近邻(k-Nearest Neighbor, KNN) 、决策树(Decision Tree,DT) 、随机森林(Random Forest, RF) 、朴素贝叶斯(Naive Bayes, NB) 、梯度提升决策树(Gradient Boosting Decision Tree, GBDT) 等6种基准模型进行对比分析,上述模型被广泛应用于ADR预测[8]。
3 实验与结果分析
3.1 模型评价指标
本文采用混淆矩阵计算召回率(Recall) 、准确率(Accuracy, ACC) 、精确率(Precision,P) 、F1值(F1-Score,F1) 和曲线下面积(Areas Under the Curve,AUC) 作为模型的评价指标。
3.2 知识图谱嵌入及样本向量表示
嵌入操作基于Python语言,调用AmpliGraph工具库实现。在嵌入操作前,需要确定ADR预测模型的训练集和测试集;训练集被用于知识图谱嵌入操作和ADR预测模型训练,测试集被用于评估ADR预测模型的预测性能。
知识图谱中正样本为119 233个,负样本为12 498个(见表4) 。由于正负样本数量相差1个数量级,故以负样本的总数为基础,按照9:1的比例,将负样本随机划分为11 249个训练样本和1 249个测试样本,并随机从正样本中取1 249个作为测试样本;则测试集包含正负样本各1 249个;训练集包括117 984个正样本和11 249个负样本。为解决训练集样本不平衡问题,采用过采样(Oversampling) 将负样本复制10倍。样本划分结果如表4所示。

表4 用于知识图谱嵌入以及ADR分类器训练和测试的数据Table 4 Data used for KG embedding and ADR classifier training and testing
本文在知识图谱嵌入过程中,采用不同的嵌入策略获得嵌入向量。并分别使用hD、tA、tI表示实体drug、ADR和Indication的嵌入向量,通过头实体向量减去尾实体向量,构造出ADR分类器正负样本的表示向量,如表5所示。分别使用Xp、Xn表示正样本和负样本,其中Xp对 应“d rug-ADR ”组合,Xn对应“drug-Indication”组合,Xp和Xn共同构成分类器的实验数据集。

表5 ADR分类器部分样本的表示向量(DistMult, dim=20)Table 5 Representation vector of partial samples of ADR classifier(DistMult, dim=20)
3.3 嵌入维度对比分析
本文通过组合不同嵌入模型和不同嵌入维度(10至800) ,探索不同嵌入策略对基准ADR分类模型在测试集上预测性能的影响。如图4所示,在不同嵌入模型下,随着嵌入维度增大,各基准模型在测试集上的AUC值也逐渐增大;并且ACC、F1指标值也存在不同程度的波动增大;Recall值没有明显增大,相对稳定。然而,当嵌入维度大于400时,各基准模型的AUC、ACC、F1指标值趋于稳定。通过综合分析,适当增大嵌入维度,能够在一定程度上提升ADR分类模型的预测性能。同时,为避免分类器出现过拟合和实验硬件设备资源浪费,本文选择400维为最佳嵌入维度,并结合CNN模型进行ADR预测。

图4 不同嵌入维度下各基准ADR分类模型在测试集上的性能表现Fig.4 The performance of each baseline ADR classification model on the test set with different embedding dimensions
3.4 分类模型对比分析
基于Python语言,使用scikit-learn和深度学习框架Tensorflow2.0开发ADR分类模型,6种基准模型将使用默认参数。固定嵌入维度为400维,通过嵌入模型获得样本的表示向量,并将其输入到ADR分类模型进行训练和预测,各分类模型在测试集上的预测结果如表6所示。综合分析发现,在DistMult嵌入模型下,CNN分类模型在测试集上的AUC值为0.942,优于所有基准模型。
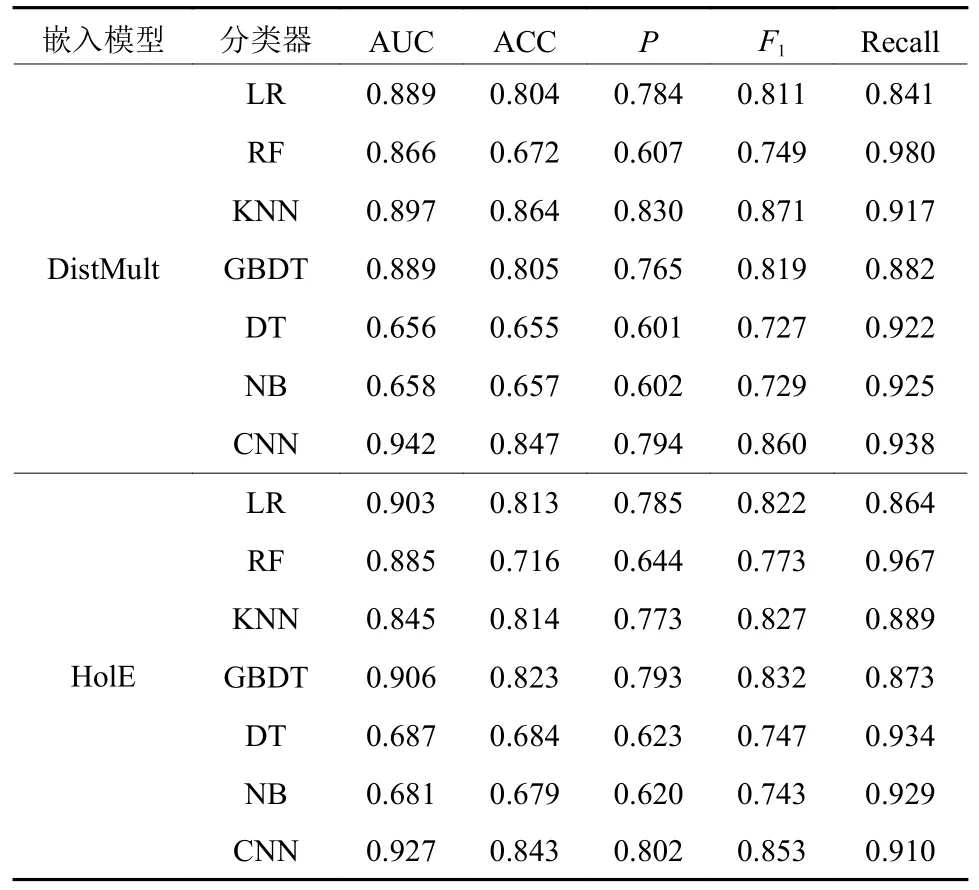
表6 嵌入维度为400时各ADR预测模型比较Table 6 Comparison of ADR prediction models when the embedding dimension is 400
3.5 模型稳定性评估
研究采用5次重复实验,评估CNN模型的稳定性。具体步骤:(1) 设定随机种子,构建训练集和测试集;(2) 采用“DistMult模型+400维”组合策略进行嵌入操作;(3) 将所得样本表示向量用于CNN分类模型训练和预测。结果如表7所示,本文CNN模型的AUC平均值为0.957,比Zhang等[26]的研究(平均AUC=0.863)高出0.094,提升了10.89%;F1均值为0.890,Recall均值为0.913,各指标值波动较小。同时,ROC曲线(见图5)表现也非常稳定,表明本文所开发的CNN模型具有较高稳定性。

图5 CNN模型5次重复实验在测试集上的ROC曲线Fig.5 ROC curve of five repeated experiments of CNN model
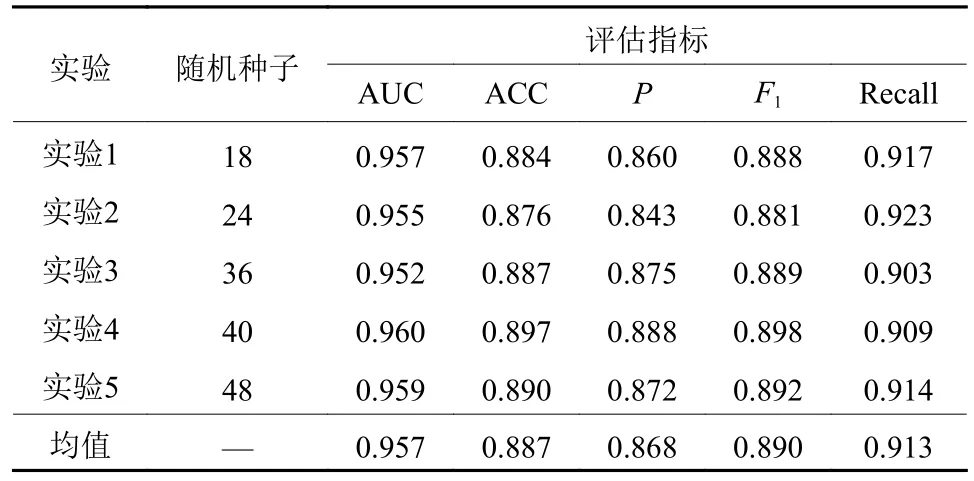
表7 5次重复实验CNN模型在测试集上的表现Table 7 The performance of the CNN model on the test set for five repeated experiments
3.6 预测模型验证
本文通过现实世界数据,对 CNN模型的有效性进行检验。以“肾损伤”或“kidney injury”为关键词,在中国知网、PubMed等文献数据库中随机检索相关的ADR研究,获得5个未被SIDER数据库收录的“ d rug-ADR”组合;将其作为输入,使用CNN模型进行预测。结果显示(见表8),真实样本被预测为“阳性”的概率平均值为0.972,表明本文的CNN模型能够有效预测实验样本集之外的样本。

表8 使用CNN模型对文献中的drug-ADR组合的预测结果Table 8 Prediction results of drug-ADR pairs in literature through CNN model
3.7 与先进研究对比分析
由于目前缺乏用于检验ADR预测模型性能的标准数据集,本文将从所覆盖的药物、ADR种类数量,以及预测模型的AUC值等方面,与相关典型研究进行对比(见表9)。通过对比分析,本文开发的CNN模型的AUC高于相关研究所提供的结果,预测性能更好。同时,本文的实验数据集包含7 916种药物和5 454种ADR,所覆盖的药物信息多于绝大多数同类研究。此外,以往的研究大多需要针对每个ADR单独构建预测模型,增加了ADR预测任务的工作量;相比之下,本文通过构建药物知识图谱,使用知识图谱嵌入技术将药物、ADR等实体编码成特征向量;最终使用一个统一的CNN模型对各“ d rug-ADR”组合进行预测,以评估该组合存在“hasADR”关系的概率,这极大减少了模型数量。Zhang等[26]的研究使用了类似的方法进行ADR预测,然而其所覆盖的药物仅有3 632种,并且所表现出的AUC值相对较低;Joshi等[25]的研究在文献[26]的基础上增加了药物通路(Pathways)和基因(Gene) 特征,但其ADR预测模型的平均AUC仅为0.912,仍存在提升的空间。本文通过选择更具代表性的药物特征,从而开发出更高性能的ADR预测模型。

表9 与现有典型研究对比Table 9 Comparison with advanced ADR prediction models
4 结语
针对既往ADR预测模型研究的预测精度低、需要为每种ADR单独构建分类器导致工作量繁重等问题,本文将不同类型ADR预测简化为一个二分类问题,并开发一个基于知识图谱嵌入和深度学习的CNN预测模型。本文的预测模型比已有研究的预测精度更高,此外通过真实世界数据验证模型预测结果的有效性和可行性,有望在临床安全用药中发挥重要的辅助作用。下一步研究将考虑使用类似的方法,对中成药潜在的不良反应进行研究;或以患者为中心,评估导致临床患者发生ADR的潜在风险因素,并预测患者在具体用药情况下出现特定ADR的风险程度;或探究不同场景下的ADR预测模型。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
电子测试(2018年1期)2018-04-18
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
领导科学论坛(2016年9期)2016-06-05
