
基于特征选择和违约鉴别的我国上市公司债券违约预警模型研究
2024-03-04 02:31白钰铭姜昱汐
工程数学学报 2024年1期
白钰铭, 姜昱汐
(大连交通大学经济管理学院,大连 116028)
0 引言
近年来,我国债券市场飞速发展,中国人民银行金融市场司发布的《2021 年金融市场运行情况》[1]中指出,2021 年全年我国债券市场共发行各类债券61.9 万亿,同比增长8.0%,截至2021 年末,我国债券市场托管余额133.5 万亿元,同比增长16.5 万亿元,已成为全球第二大债券市场。债券市场快速发展的同时也出现了债券违约频发。2014 年“11 超日债”违约是我国第一次发生实质性债券违约,根据中央结算公司发布的《2021 年我国债券市场违约回顾与展望》[2],截至2021 年末,我国债券市场累计有243 家发行人发生违约,共涉及到期违约债券685 期,到期违约金额合计约6 184.17 亿元。找出影响债券违约的关键因素,并建立违约鉴别精度高且具备实用性的债券违约预警模型,对投资者和中国债券市场的健康稳定发展都具有重要意义。
当前关于债券违约预警的相关研究,主要可分为三个方面。
一是债券违约影响因素研究。蒋敏等[3]发现,过度负债和经济下行会导致高绩效企业债券违约,资金周转不足和经济下行会导致低绩效企业债券违约;肖艳丽和向有涛[4]发现,剩余期限(年)、票面利率、流动比率、长期负债占比和应收账款周转率等五个指标特征是引起债券违约风险的主要因素,影响贡献度占到80%,有形资产比率和长期负债占比超过相应阈值时,会分别产生拉低和拉高债券违约的风险;Li 等[5]指出,债券违约率与发债公司能源消耗成正相关,与发债公司的社会责任感、公司治理能力以及财务表现呈负相关;罗朝阳等[6]研究了金融周期和全要素生产率与债券违约的关系,研究发现金融周期顶部发生债券违约的概率较大,全要素生产率与债券违约呈负相关。
二是债券信用评级指标体系研究。陈学彬等[7]从债券发行公司的财务指标、债券市场指标、债券评级指标、宏观经济环境指标、行业景气指标、地区经济景气指标等六个方面构建指标体系;Ma 等[8]从债券基本信息、债券发行主体基本信息、债券信用评级情况、债券发行主体财务信息以及宏观因素等五个方面构建指标体系;Giesecke 等[9]从股票收益率、股票收益波动率、无风险利率、信用利差、消费增长、知识产权增长、通货膨胀率、GDP 增长等八个方面构建指标体系;姚潇等[10]从债券发行人基本信息和财务指标中选取8 个因素构建指标体系。
三是债券违约预警方法研究。按照债券违约预警方法的发展阶段,可将其分为三类,分别是以因子评分和Z-score 为代表的财务指标类分析法[11–14]、以Credit Metirics、Credit Portfolio View、CreditRisk+、KMV 等为代表的量化指标信用风险分析方法[15–19]和以逻辑回归、神经网络、支持向量机、随机森林等单模型和集成模型为代表的机器学习算法[10,20–22]。
从现有研究来看,当前关于债券违约预警的相关研究已经取得了很多成果,但还存在一定的不足。
债券违约影响因素方面,已有文献主要集中在发债主体的个别财务情况、企业经营情况、企业属性、所在地区宏观环境以及债券基本信息等,而这些影响因素只是说明了哪些指标会影响到债券违约,但不能对债券违约进行预警。
债券信用评级指标体系方面,已有文献的指标体系主要从部分债券基本信息、债券发行公司财务指标、债券发行公司非财务指标以及宏观情况等方面构成债券信用评级指标体系。但都是只考虑某一方面的指标,并没有从上述多个维度全面反映债券违约风险特征。
债券违约预警方法方面,财务指标分析方法通常只关注某一方面的指标而忽视掉其余的影响因素。因此,这种分析方法只能确定影响因素,却无法进行违约预测;对基于量化指标信用风险分析方法的系列模型,Credit Metirics、Credit Portfolio View 和CreditRisk+等是基于大量违约统计信息,适用于相关数据完整度高的研究对象,而KMV 模型考虑的指标不仅较少,还假定了资产收益等固定不变,与债券实际情况不符;基于机器学习的违约预警方法主要分为传统机器学习算法和深度学习算法。很多传统机器学习算法存在降维效果差、精度不高或计算速度慢等各类问题,深度学习方法则因为模型复杂的网络结构导致计算结果的可解释性不强,这对需要考虑经济意义可解释性的债券违约预警问题并不适合,且采用深度学习模型要想获得比较高的一个精度,需要较大的样本数据和计算时间。
此外,以上三个方面的实证研究中,关于债券违约预警影响指标的数据时间窗包括t、t −1 和t −2(即债券违约发生在t期,违约预警指标数据为同期、滞后一期和两期),但是现有研究通常是主观选取一个时间窗,对选择哪一个时间窗更合理并没有依据,且没有考虑债券违约预测中,违约和非违约样本数量差距大会导致的样本非均衡问题,这也影响了预测结果的精度。
根据上述分析,本文从以上几个方面进行改进。第一,本文从发债主体内部财务指标、发债主体内部非财务指标和发债主体外部指标三个方面出发,对已有文献的指标进行归类整理,其中已有文献中的“债券发行公司财务指标”对应本文的“发债主体内部财务指标”、“债券发行公司非财务指标”对应本文的“发债主体内部非财务指标”,“债券基本信息”和“宏观情况”合并为本文的“发债主体外部指标”,最终以19 个维度,615 个指标构建初始指标池,弥补现有研究中指标体系结构不清晰信息不充分的不足。第二,采用SMOTE 方法对样本进行均衡化处理,消除样本类别不均衡对预测精度的影响。第三,通过XGBoost 方法构建违约预警模型,选取不同时间窗数据进行计算,并根据计算结果反推最优违约预警特征指标组合和最优预测时间窗,保证了以较精简的指标体系达到较高预测精度的目标,并改变了现有研究主观选取违约预警时间窗的弊端。通过本文模型与其他常用违约预测模型的结果对比分析,本文模型具有降维效果好、计算速度快、稳定性好和可解释性强的优势。
1 基于特征选择和违约鉴别的我国上市公司债券违约预警模型构建
1.1 样本数据的处理
1.1.1 缺失值处理
缺失值是指不能获取的指标值,对于缺失值处理的整体思路是用最差值填补缺失值。按照指标的性质,可将指标分为定量指标和定性指标。指标的性质不同,填补缺失值的方法也不同。
1) 定量指标填补缺失值方法
定量指标是指可以用具体数值表示的指标,从指标对预测结果的影响又可将定量指标细分为正向指标、负向指标和区间指标。
正向指标是指指标值越大,越不容易违约,例如流动比率、速动比率等指标;负向指标是指标值越小,越不容易违约,例如有形资产负债率、长期资本负债率等指标;而区间指标是指当指标值处于某一特定区间时越不容易违约,指标值与这一特定区间的距离越远越容易违约,例如管理层平均年龄等指标。
设i为第i个指标,j为第j支债券,v′ij为用于填补的指标值,vij为原始指标值,m为债券总数,qi1为区间指标的区间最小值,qi2为区间指标的区间最大值,(qi1+qi2)/2 为区间指标的区间的中间值。
正向指标对于用来填补缺失值的数值的计算公式为
若按照公式(1)的计算结果偏离了该指标的合理范围,则用已知指标值中的最小值填补,计算公式为
例如流动比率这一指标,永远不可能小于0,若公式(1)的计算结果小于0,则用公式(2)计算[23]。
负向指标对于用来填补缺失值的数值的计算公式为
同样,若公式(3)的计算结果偏离了该指标的合理范围,则用已知指标中的最大值填补公式,具体如下[23]
区间指标对于用来填补缺失值的数值的计算思路是计算与最优指标区间距离最远的那个已知指标值,并用那个指标值填补,区间指标的填补值的计算公式如下[23]
2) 定性指标填补缺失值方法
定性指标是指不能直接将指标值代入数学模型进行计算的指标,如产权性质等指标。对定性指标,填补缺失值的思路是将定性指标的指标值按类别分成不同的等级,然后用最差的等级填补缺失值。
1.1.2 指标数据标准化
未经过标准化的数据经常存在三个问题,即定性指标的非结构化数据处理及标准化、数据存在异常值、不同指标数据之间的量级及单位不同等,本文采用下面的方法进行处理,将其转换为标准化数据。
1) 定性指标数据标准化
定性指标的非结构化数据需要将其转化为结构化数据,并将指标值按等级划分好的各个档次进行赋值。本文在赋值时,根据现有研究的常用处理办法,按照对结果的影响程度等距赋予[0,1]之间的值[24–25]。
2) 异常值处理
异常值处理的整体思路是将异常值进行缩尾处理,即整个数据集的前后1%的数据视为异常值,然后将前后1%的异常值分别用最临界的非异常值替换。
3) 指标数据归一化
指标数据的归一化是将所有指标数据转化为[0,1]之间的数值[26–27],不同性质的指标数据的归一化方法不同,按照缺失值中指标的分类,三类指标的具体归一化公式如下:
令i对应指标,j对应债券,xij是第j支债券第i个指标的标准化数据,vij为原始指标数据值,m为债券总数。正向指标数据归一化的公式如式(6)所示,负向指标数据归一化的公式如式(7)所示[28–29]。
令qi1为区间指标i的下界,qi2为区间指标i的上界,区间指标数据归一化公式如式(8)所示[30–31]。
1.1.3 基于SMOTE 的非均衡样本处理
虽然我国债券违约的数量在逐年增多,但我国债券市场上非违约债券的数量仍远大于违约债券。因此,债券数据是非均衡样本,而采用非均衡样本进行分类预测,模型的预测结果会偏向于样本数量多的那一类,将其应用于债券违约预测,容易导致对违约债券识别精度降低,而违约是债券违约鉴别中更关注的问题,即为金融领域重点关注的第二类错误(type II error,即将违约样本预测为非违约样本占总违约样本的比例)。因此,为提高模型的预测精度和实用性,需要用有效方法解决样本非均衡问题。
本文采用SMOTE 过采样方法解决样本非均衡问题,相比随机过采样等方法通过复制样本来增加少数类样本,SMOTE 过采样通过少数类样本的邻近样本合成新的少数类样本,最后使得少数类样本与多数类样本的样本数量相同,该方法得到的数据在满足样本数量增大的同时提高了样本质量。
用SMOTE 方法合成违约债券的步骤如下。

每个债券有n个指标,每个指标数据可以通过公式(9)生成。对于每个指标重复上述过程,得到m0−m1个新的违约债券样本数据。
1.2 基于特征选择的债券违约预警指标体系构建
1.2.1 债券违约预警指标体系构建思路
本文构建债券违约预警指标体系的思路是在尽可能保证模型预测精度的基础上,选取更精简且具备经济意义完备性的指标体系,保证模型预测的可靠性和实用性,包括指标海选、指标筛选和指标体系确定等几个步骤。
1.2.2 指标海选
依据全面反映债券违约风险特征的指标体系建立条件,根据债券违约风险的影响因素,参考惠誉、标普、穆迪、中诚信等国内外专业评级机构的评级指标体系,梳理国内外经典、高质量文献中的指标体系以及债券违约影响因素,从多个维度进行指标海选。
1.2.3 基于数据可获性的第一次指标筛选
为保证数据的完整性以及实证部分的可行性,删除不可获得和极少数债券才有数据的指标,以此来确保最后保留的指标其数据具备可获得性。
1.2.4 基于特征选择和违约鉴别的第二次指标筛选
特征选择是指在不损失特征信息的前提下,从选取的高维特征指标中删除信息重复和对违约鉴别影响低的指标,选择反映预测精度好和指标体系规模小的特征指标集,从而降低模型复杂度,提高模型预测精度。
本文采用XGBoost 方法的指标筛选是一种嵌入式特征选择方法,该方法将特征选择过程与学习器训练过程融为一体,二者在同一优化过程中完成,相比其他两类常用降维方法(过滤式和封装式),该方法计算效率高、降维效果好且计算简便。
1.2.5 根据计算结果反推最优特征指标集和预警时间窗
依据指标体系需要同时满足指标体系精简且预测精度高的指标体系构建条件,对采用上述方法用不同期数据计算得到的结果进行对比分析,从违约鉴别精度和模型精简性两个方面,确定包含最优特征的指标体系,并确定违约预测最优时间窗。
1.3 基于XGBoost 的债券违约预警模型构建与评估
1.3.1 XGBoost 算法
本研究是根据债券违约的特征因素来对其违约状态进行预测,选取的研究对象是我国上市公司债券,而我国债券市场缺少足够的违约统计信息,因此,CreditRisk+、KMV 等基于大量违约统计信息的模型不适合本文的研究问题,而根据违约特征预测违约状态的问题是机器学习中常见的有监督的分类问题,通过对现有监督问题的算法进行分析,最终采用稳定性好、预测准确率高、解释性强的XGBoost 算法[32],其属于集成学习算法,是通过多个学习器来完成学习任务。相比单一学习器构建的预警模型,集成学习将多个学习器结合起来,泛化性能更好,其中XGBoost 算法不仅计算速度快、精度高,而且在目标函数中加入了正则项实现降维。因此,适用于债券违约预测模型的特征筛选和违约预警模型构建。
XGBoost 的预测结果为每棵树的预测结果之和,具体为
其中fk是每棵树的预测结果,xi是第i个特征样本的特征向量值。
XGBoost 算法的目标函数为
其中l(·)代表损失函数,用来度量预测值ˆyi和实际值yi的差别,Ω是正则项,具体为

其中gi和hi分别代表一阶和二阶导数。
考虑优化计算中常数项不起作用,因此删除常数项,得到目标函数
将公式(12)代入公式(15)后,得到目标函数
令Gj=∑gi,Hj=∑hi,当ωj=−Gj/(Hj+λ)时,目标函数的最小值为
XGBoost 的模型寻优是通过给定参数下进行树分裂实现,树分裂点的计算公式为
其中Gain 代表结构评分,其值越大,表明切分后的目标函数值越低,GL、HL、GR和HR分别对应节点分裂后左右两边的子树。
1.3.2 模型评估
为验证模型的有效性,需要对模型进行预测精度检验,综合已有的关于违约鉴别的文献[26,28,33–34],本文共引用了7 个判别精度标准对模型进行检验,分别为精确率(precision)、样本总体预测精度(accuracy)、f1分数(f1-score)、AUC(Area Under the ROC Curve)、第一类错误(type I error)、第二类错误(type II error)、几何平均值(g-mean),选取的这7 个判别精度标准不仅包含了对整体预测精度衡量,还包含对违约和非违约两个类别预测精度的衡量。因此,可以更全面地度量模型预测精度,各项精度判别指标的计算公式中涉及到的参数如表1 所示。
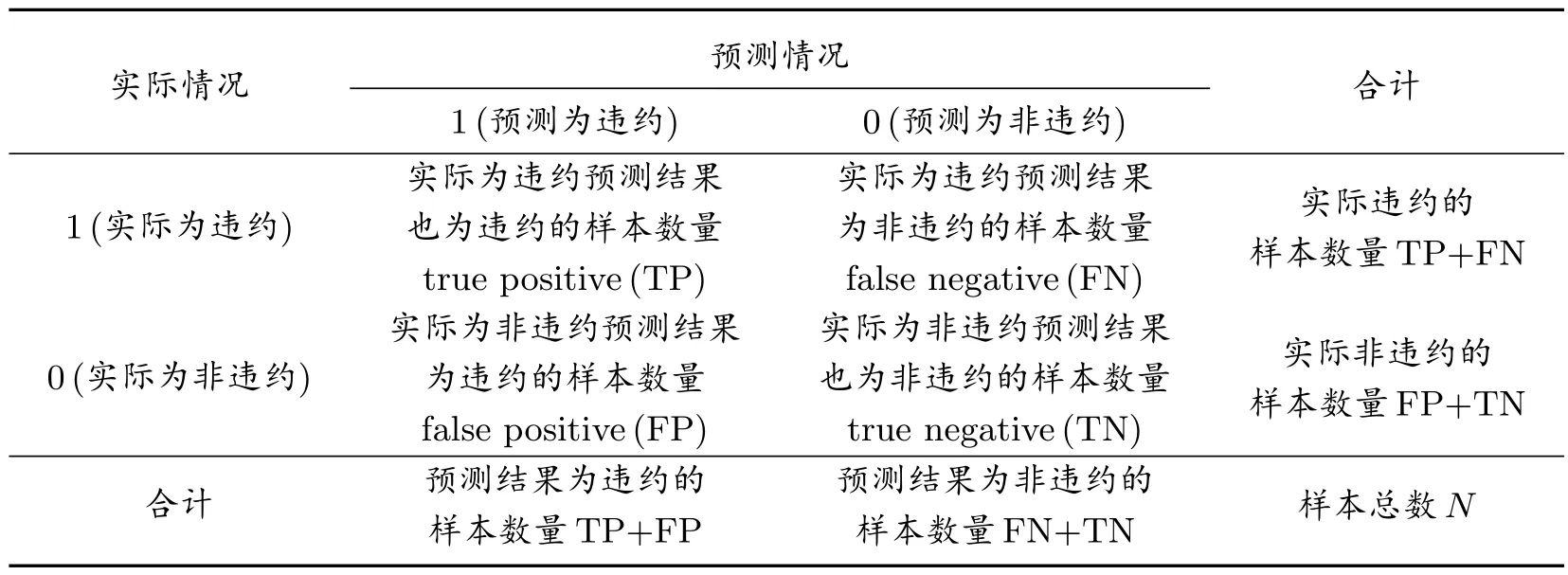
表1 指标参数
精确率的计算公式
precision 的值越大表示模型判别违约的效果越好。样本总体预测精度的计算公式
accuracy 的值越大,表示模型的预测性能越好。f1分数的计算公式
f1-score 是精确率与召回率的调和平均,f1-score 的值越大,表示模型的预测性能越好。AUC 是ROC 曲线与X轴围成的面积。AUC 的值越接近1,模型的判别能力越好,当AUC 值小于0.5 时,认为模型无效[35]。第一类错误的计算公式

g-mean 的值越大表明模型的预测效果越好。
2 基于特征选择和违约鉴别的我国上市公司债券违约预警实证研究
2.1 样本数据选取及来源
2.1.1 样本数据的选取
现有研究通常采用3 组违约预测时间窗,即t −m(m= 0,1,2),m代表指标体系中各指标数据滞后期,即用第t −m年的指标数据,预测债券第t年的违约状态。
债券违约预警的目的是根据影响债券违约的特征指标数据,采用预警模型预测其未来的违约状态,而m= 0 的时间窗口无法实现提前预警目的。因此,本文采用滞后1 期和2 期的时间窗作为备选预警时间窗口,并通过预测结果来确定最优时间窗。
因为中国债券市场在2014 年才出现发生实质性违约的债券,因此,本文所选取的债券样本为2012~2020 年上市公司发行的在市债券,包括公司债和金融债。
2.1.2 样本数据的来源
本文从国泰安数据库获取2012 年1 月至2020 年12 月的中国债券基本信息数据以及发债主体的财务数据和发债主体的非财务数据,从锐思数据库获取债券违约数据,从中国经济社会大数据研究平台获取宏观环境数据。初始指标池共提取615 个指标,其中包含发债主体财务指标375 个,发债主体非财务指标178 个,债券基本信息指标58 个,宏观指标4 个,其中指标数据为2012~2020 年,违约状态为2013~2021 年。
2.2 样本的处理
2.2.1 构建t −m时间窗口样本
根据2.1.1 节的分析可知,本文选取的样本的违约预警时间窗分别为t −1 年和t −2 年,其中t −1 年包含45 878 支债券,t −2 年包含13 671 支债券。
2.2.2 原始数据预处理及标准化
将原始数据进行填补缺失值的预处理,然后将处理后的数据进行标准化(异常值处理和归一化)。在填补缺失值时,从控制风险的角度出发,用指标样本中的最差值填补缺失的指标值,采用公式(1)~(5)来进行缺失值填补。采用前后1%的缩尾来完成异常值处理。采用公式(6)~(8)来进行指标数据归一化。
2.2.3 基于SMOTE 方法的非均衡样本处理
根据1.1.3 介绍的SMOTE 方法,对于每个t −m(m=1,2)年时间窗口样本进行非平衡数据处理,保证样本中的违约样本总数与非违约样本总数达到1:1,即得到违约状态均衡的样本。本文采用Python 语言编程,实现非平衡样本处理过程,经过SMOTE 处理前后的样本数如表2 所示。

表2 经过SMOTE 处理前后的样本数
2.2.4 样本数据划分
本文将经过SMOTE 处理后的样本经过两次划分,划分为训练样本,验证样本和测试样本。第一次划分:划分初始训练样本与测试样本。将样本按照初始训练样本和测试样本为8 : 2 的比例进行随机划分,为了保证随机划分的样本保持类别均衡,在该过程采用分层随机抽样。为了避免随机抽样结果的不稳定,共进行5 次抽样,得到5 组初始训练样本与测试样本。第二次划分:将第一次划分得到的初始训练样本按照十折交叉验证的方法进行样本划分并应用于XGBoost 模型训练,即占总样本80%的初始训练样本划分为样本量为9 : 1 的新的训练样本与验证样本,而占总样本20%的测试样本不加入模型训练,只用于模型精度检验。
跟所有样本都参加十折交叉验证相比,本文的测试集没有影响模型训练。因此,测试精度更能反映预测模型的泛化能力。
2.3 债券违约预警模型指标体系的构建
2.3.1 基于数据可获性的第一次指标筛选
删除不可获得和极少数债券才有数据的指标。第一次指标筛选从初始的615 个指标中删除了358 个指标,保留了257 个指标。第一次指标筛选结果如表3 所示。

表3 第一次指标筛选结果
2.3.2 基于特征选择和违约鉴别的第二次指标筛选
在本部分,首先基于网格搜索法确定超参数,然后根据不同时间窗的预测精度和降维效果确定指标体系,完成指标第二次筛选。
1) 网格搜索法
网格搜索法[36]是指将指定的参数进行枚举,通过将评估函数中的参数进行交叉验证得到最优参数的算法。具体操作时,把需要优化的参数取值规定在一定范围内并划分成网格,这样之后遍历网格内所有的取值,然后依次将这些数据放入分类器中进行训练,并采用交叉验证法对参数的表现进行评估,在遍历了所有参数组合之后,比较训练集分类的准确率,找到分类效果最好的那组参数组合。
本文采用的是网格搜索与十折交叉验证相结合的方法寻找XGBoost 模型的最优超参数,得到的最优超参数具体见表4。

表4 XGBoost 参数说明
2) 指标体系确定
根据计算结果,分别对t −1 期和t −2 期的最优指标体系进行对比分析,其中t −1 期时间窗的预测结果最好,根据t −1 年时间窗数据得到第二次指标筛选结果如表5 所示。
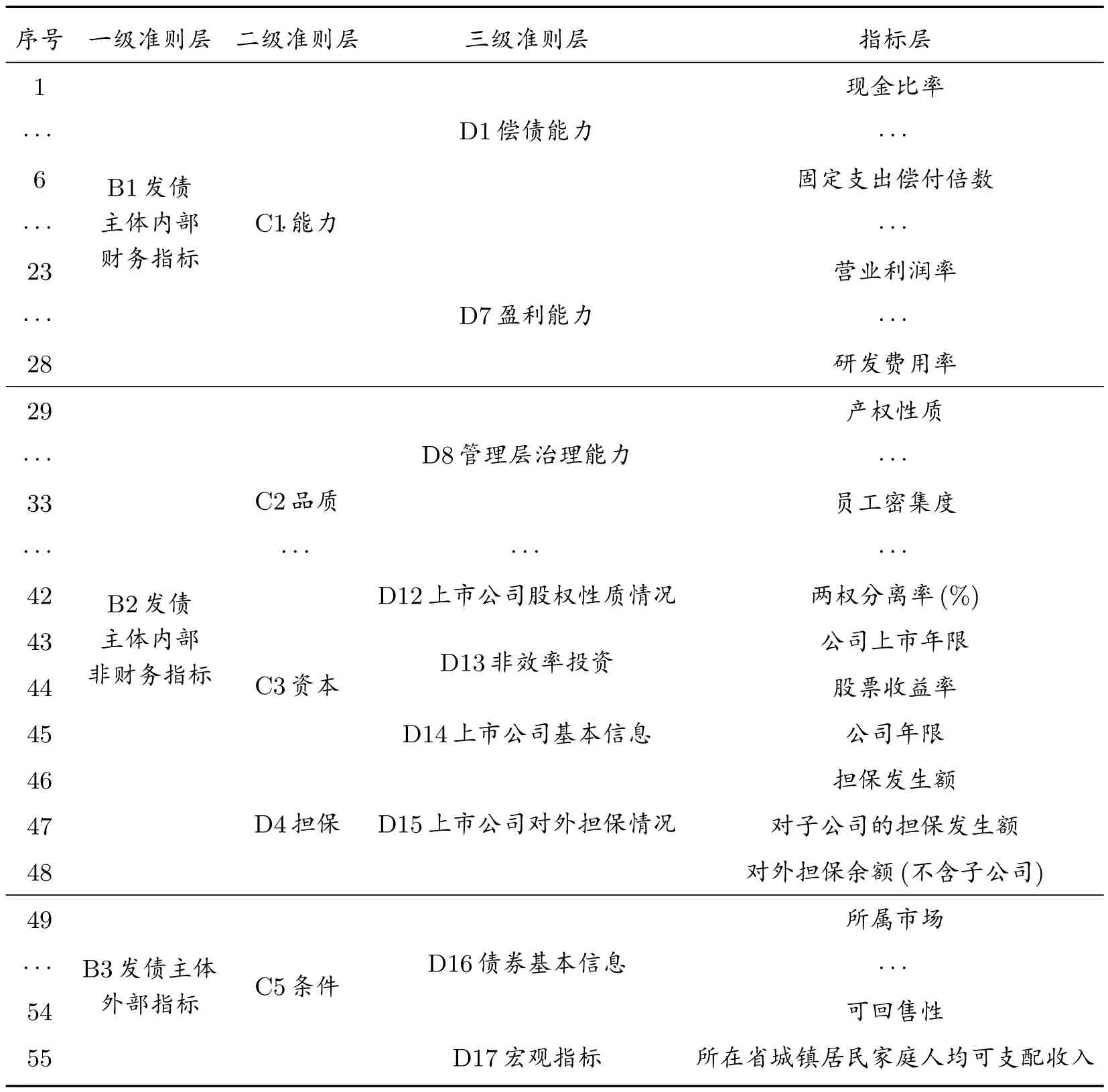
表5 t −1 年第二次指标筛选结果
从表5 可以看出,经过第二次筛选得到的评价指标对应金融界普遍认可的5C 原则,即品质、能力、资本、担保和环境,证明本文得到的指标体系在经济意义上符合业界共识,可为投资者和监管部门提供决策和监管参考,具有经济意义。
2.4 债券违约预警模型构建及精度测算
本部分首先计算混淆矩阵的相关指标,然后根据混淆矩阵计算其他7 个精度指标,根据预测结果得到的最优预测时间窗为t −1。因此,本部分只给出根据t −1 年指标得到的最优预测精度,对不同时间窗和不同模型的7 个精度指标对比见本文的2.5。
在t −1 年根据模型训练组(训练集和验证集)的预测情况,计算得到混淆矩阵如表6。根据表6 的混淆矩阵,采用公式(19)~(24),计算得到债券违约鉴别模型训练组的精度,其中precision = 97.24%, acc = 98.28%,f1-score = 98.30%, AUC = 99.69%, type I error=2.82%, type II error=0.63%,g-mean=98.27%。

表6 训练组混淆矩阵
显然,不论是模型总体的鉴别精度,还是对违约和非违约债券的鉴别精度,均在97.1%以上,说明模型对债券的违约鉴别能力较强。
根据训练得到的模型,采用t −1 年测试集数据进行预测,得到测试集混淆矩阵如表7 所示。

表7 测试集混淆矩阵
根据测试集混淆矩阵,采用公式(19)~(24),计算得到债券违约鉴别模型测试集的精度,其中precision=97.58%, acc=98.45%,f1-score=98.47%, AUC=99.75%, type I error=2.47%, type II error=0.62%,g-mean=98.45%。
综上可见,不论是模型总体的鉴别精度,还是对违约和非违约债券的鉴别精度,均在97.5%以上,说明本文构建的违约预警模型对债券的违约鉴别能力较强。
2.5 精度对比分析
下面从不同时间窗和不同模型的预测精度两个方面进行对比分析,确定最优债券违约预测模型和违约预警时间窗。
2.5.1 不同时间窗的对比分析
综合考虑预测精度和指标体系精简度,确定最优债券违约预测模型和最优预警时间窗。表8 和表9 给出了t−1 和t−2 时间窗分别对应的最优预测模型的计算结果,其中指标体系规模对比如表8 所示,测试样本精度如表9 所示。为方便计算平均精度,在表9 中将所有评估指标均转化为正向指标,即精度越高代表预测效果越好,即对表9 第6 行第3 列的type I error,在t −1 期的负向评估指标值2.47%,转换后变为97.53%,代表type I error 在t −1 期的正向评估指标值。

表8 各时间窗最优指标体系的指标个数

表9 各时间窗最优小组的测试集精度对比(%)
根据表8 可知,t −1 期的指标个数为55,t −2 期的指标个数为75,因此t −1 期的指标体系规模小于t −2 期,该指标体系更精简。
根据表9 可知,t −1 期所有评估指标的精度均优于t −2 期,因此t −1 期的预测精度要好于t −2 期。
综合表8 和表9 的计算结果可知,当时间窗口为t −1 期时,模型预测精度高且指标体系规模小,可以作为最优债券违约预警时间窗。
2.5.2 不同模型违约预测结果的对比分析
本部分选取7 个在违约鉴别领域常用的分类模型,从指标体系规模、预测精度和计算时间三个方面,进行模型预测对比分析。具体采用的模型为逻辑回归(Logistic Regression, LG)[37]、支持向量机(Support Vector Machine, SVM)[38]、Adaboost(Adaptive Boosting, Ada)[39]、随机森林(Random Forest, RF)[35]、线性判别模型(Linear Discriminate Analysis, LDA)[40]、朴素贝叶斯(Naive Bayes, NB)[41]、随机梯度下降(Stochastic Gradient Descent, SGD)[42]。
指标规模对比分析结果如表10 所示,表10 的指标体系规模排名是将指标体系规模由小及大排名的,即指标体系规模越小越靠前。

表10 各模型指标体系规模对比
从指标体系的规模进行对比分析。观察表10 可以发现,XGBoost 的指标个数为55,是所有对比模型中指标个数最少的,因此XGBoost 是降维效果最好的模型。
精度对比分析结果如表11 所示,表11 的每一个评估指标对应两行数据,第一行为模型精度指标,第二行为该精度指标在8 个模型中的排名,序号越小精度越好;type I error 和type II error 中分别包含了这两个指标的正向和负向精度及排名,type I error 和type II error 正向精度的计算方式同2.5.1。

表11 各模型精度对比(%)
从模型违约鉴别精度进行对比分析。观察表11 可以发现,XGBoost 的精度检验结果都较好,平均精度最高。
表12 为各模型的运行时间对比,第一行为计算时间,第二行为排序,当时间越短,排序越靠前。

表12 各模型计算时间对比
从模型运行时间的角度进行对比分析。观察表12 发现,XGBoost 的运行时间虽然比大部分非集成学习的单一算法要长,但是却比其他集成学习(Ada 和RF)的计算时间短。
综合表10~12 的计算结果可以看出,虽然XGBoost 的计算时间略高与NB、SVM 等单学习器模型,但是XGBoost 在指标体系规模和精度上要明显占优;且同集成学习的算法相比,无论是计算精度、降维效果还是计算时间,XGBoost 都优于RF 和Ada。因此,综合违约预警指标体系精简度、预测精度、计算时间三个方面,XGBoost 模型的综合表现最好,是实现债券违约预警的有效算法。
本文选取的对比模型中没有使用当前比较流行的深度学习网络结构(如ChatGPT 采用的Transformer),一是从模型的可解释性角度来讲,以Transformer 为代表的大模型依赖大量数据实现参数优化,训练过程为黑箱,导致了模型的可解释性较差,而金融领域中的债券违约预警,在考虑预警精度的同时,也要考虑模型的经济可解释性,只有具有可解释性的模型才能支持债券风险管控,从这个角度来说,基于XGBoost 构建的违约预警模型比基于Transformer 的深度学习大模型更具有优势;二是从模型的工作效率上来讲,基于Transformer 的大模型参数太多,存在对样本需求量太大、模型训练时间长、硬件成本高等弊端,对基于特征指标体系进行违约预警的问题并不适用,且本文基于XGBoost 训练得到模型已经达到较高的预测精度。因此,在有限样本条件下,本文构建预警模型的方法效率更高。
2.6 计算债券违约预警模型的特征权重
下面,本文根据得到的最优违约预警模型,计算该模型对应的特征指标权重,以确定各特征的重要性,特征指标的重要性程度计算结果如表13 所示。

表13 特征指标的重要性
由表13 可知,特征指标的权重是归一化的,可以直观地了解各个指标的重要程度,不仅证明了XGBoost 算法具有可解释性,还使本文所选取的指标体系经济意义更明确,这也是该方法得到的模型相比其他方法的模型(特别是深度学习模型)在债券投资和风险管理上的重要优势。
3 结论
本文所提出的基于t −1 期的债券违约预警时间窗符合预测精度高和指标体系精简的目标,相比现有研究人为设定预警时间窗更合理。本文以预测精度高且指标体系规模小为目标反推最优债券违约预警时间窗,经过多个时间窗的精度以及指标体系规模的对比发现,t −1 期的债券违约预警效果最好,即滞后一期是指标数据的最优预警时间窗。
本文所提出的指标体系相较于现有研究有较大改进,所涵盖的信息更完备,且符合金融界认可的5C 原则。本文所提出的指标体系不仅涵盖了发债主体内部财务指标、非财务指标,还包括外部宏观指标和债券基本信息。相比现有研究,本文选取的最优模型比现有的指标体系在财务指标上增加了“长期借款与总资产比”、“应收账款与收入比”等指标;在非财务指标上增加了“两权分离率”、“产权性质”等指标;在外部宏观指标上增加了“所在省城镇居民家庭人均可支配收入”;在债券基本信息上增加了“可回售性”等指标。筛选后建立的指标体系符合5C 原则,经济意义合理。
本文采用XGBoost 算法,在保证违约鉴别精度的同时对指标体系起到降维的效果,并给出关键因素重要性程度。经与7 个在违约鉴别领域较为常用的分类模型比较,本文的模型相较于其他模型具有降维效果好、计算速度快、稳定性好以及可解释性强的特点。
猜你喜欢
进出口经理人(2017年5期)2017-07-07
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
领导决策信息(2017年11期)2017-05-17
兵器装备工程学报(2017年4期)2017-04-28
地方财政研究(2014年12期)2014-03-19
装备学院学报(2014年1期)2014-01-19
植物营养与肥料学报(2011年4期)2011-10-26
中国土地科学(2011年2期)2011-03-20
