
融合对抗网络和维纳滤波的无人机图像去模糊方法研究
2024-03-05 07:35张文政吴长悦满卫东刘明月
无线电工程 2024年3期
张文政,吴长悦,赵 文,满卫东,2,3,4,5,刘明月,2,3,4,5
(1.华北理工大学 矿业工程学院,河北 唐山 063210;2.唐山市资源与环境遥感重点实验室,河北 唐山 063210;3.河北省矿区生态修复产业技术研究院,河北 唐山 063210;4.矿产资源绿色开发与生态修复协同创新中心,河北 唐山 063210;5.河北省矿业开发与安全技术重点实验室,河北 唐山 063210)
0 引言
随着无人机(UAV)技术的不断发展和应用的深入,UAV测量作为一种新兴的测量手段,已经在测绘领域得到了普遍的应用。相比于传统的测绘方法,UAV航拍测量具有多项特点,包括高视角、细节捕捉、高分辨率和时间序列观测等,特别是在大规模测绘和难以到达的地形区域测量方面具有独特的优势[1-2]。
在实际作业中,UAV在拍摄时可能存在3种类型的相对运动:平移、旋转和运动畸变,这些运动引起了图像中的像素位置变化,导致图像失去清晰度和细节,从而产生模糊现象。然而,UAV航拍测量的精度很大程度上依靠机载相机对地物高分辨的细节捕捉。因此,去除图像模糊、恢复图像特征对于提高测量精度和效率具有重要意义。
针对模糊图像的处理方法主要分为传统方法和基于深度学习的方法[3-6]。传统方法通常包括图像滤波、去模糊算法等,如高斯滤波、维纳滤波(Wiener Filter)和盲源分离等。这些方法具有简单、直接、易于实现等优点,但是在处理复杂的模糊图像时存在一定的局限性。近年来,随着深度学习技术的进一步发展,基于卷积神经网络(CNN)[7]的图像去模糊方法成为了研究热点。Shao等[8]首先将CNN引入到图像去模糊领域中,提出了DeBlurNet方法,但其对于高速运动模糊的处理效果不佳。Goodfellow等提出的生成对抗网络(Generative Adversarial Network,GAN)通过学习真实图像分布,可以生成高质量、较真实的图像,因此被广泛应用于图像增强和图像复原任务[9]。基于GAN的DeblurGAN和DeblurGANv2方法也应运而生,成为当前比较流行的端到端学习方法的去模糊网络[10],其中DeblurGANv2[11]相对于其前身DeblurGAN表现更加突出,且在GoPro数据集上的SSIM-FLOPS权衡图上也明显优于尺度循环网络(Scale-Recurrent Network,SRN)[12]以及其他运动模糊模型。这些方法的引入和不断优化,为图像去模糊任务带来了巨大的进步和突破。
然而,在UAV测量领域中,由于图像中存在一定程度的运动模糊和透视变换等问题,传统方法和基于深度学习的方法在处理UAV测量图像时存在一定的不适用性。因此,针对UAV测量中的模糊图像问题,需要进一步深入探究相应的图像处理方法。
本文工作主要包括三方面:① 将DeblurGANv2网络引入到UAV测量模糊图像的恢复任务中,并设计一种自适应指数移动平均损失函数(Adaptive Exponential Moving Average Loss Function,AEMALF);
② 将维纳滤波后的图像存在振铃效应进行高频抑制并通过色彩映射等方法恢复原图像部分细节;③ 建立了模拟仿真的UAV测量运动过程模糊图像数据集。
1 去模糊算法
1.1 维纳滤波
维纳滤波是一种线性滤波器,常用于信号处理和图像处理领域,是一种基于最小均方误差准则的滤波器,能够提高信号质量并处理具有固有模糊的图像和信号。该滤波器通过估计信号和噪声的功率谱密度,将信号在频域中加以滤波,以达到降噪和去除模糊的目的[13]。其原理可以概括为:通过对一个待处理信号进行加权平均的方式,抑制噪声,同时增强信号。其核心思想是先通过对信号和噪声的功率谱密度的估计,来提高信号的质量。将信号和噪声的功率谱密度作为输入,对信号进行线性滤波处理,从而抑制噪声并增强信号的特征[14]。其具体组成部分如图1所示。
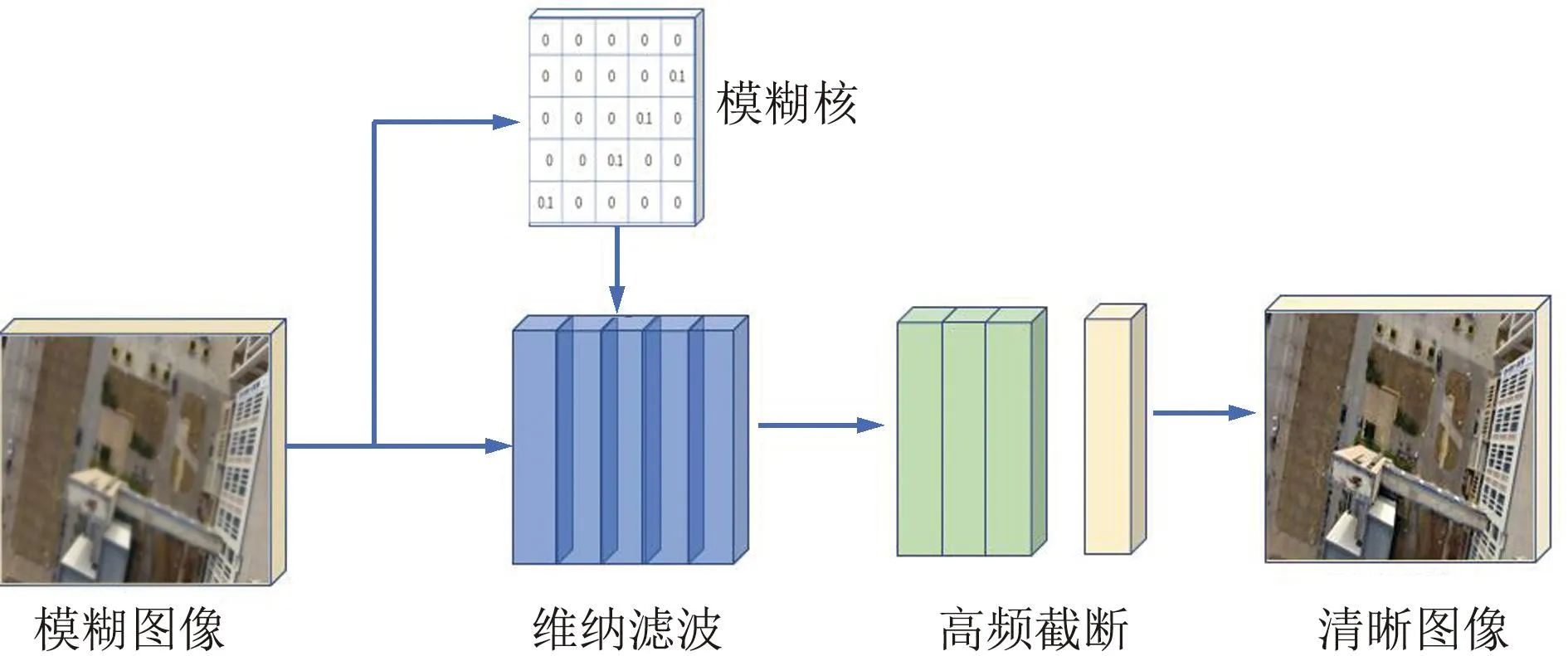
图1 去振铃效应维纳滤波组成部分Fig.1 De-ringing effect Wiener filtering components
在离散时间信号的情况下,维纳滤波的数学公式为:
(1)
式中:H(u,v)为维纳滤波器的频率响应,Sf(u,v)为输入图像的傅里叶变换,K为一个正常数,它代表了噪声和信号功率谱之间的比率。在实际应用中,K的值通常需要根据具体情况来确定。
维纳滤波的具体流程如下。
① 对原始图像进行傅里叶变换,得到频域图像G(u,v):
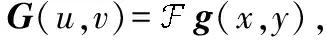
(2)
② 计算模糊函数H(u,v)的傅里叶变换:
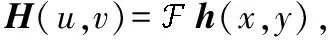
(3)
式中:h(x,y)为模糊函数。
③ 分别计算Sη(u,v)和Sf(u,v)的功率谱:
(4)
式中:η(x,y)为噪声图像,f(x,y)为未经模糊和噪声处理的原始图像。
④ 根据维纳滤波公式计算每个频率分量的加权系数,得到加权后的频域图像F(u,v):
(5)
式中:K为一个常数,用于控制噪声的强度。
⑤ 对加权后的频域图像进行傅里叶反变换,得到去模糊后的图像fdeblur(x,y):
fdeblur(x,y)=-1F(u,v)G(u,v),
(6)
将维纳滤波引入到UAV图像恢复中,用于对模糊图像进行预处理。然而维纳滤波对于模糊核的估计要求较高以及输出图像存在一定的振铃效应,因此采用如图1所示的以高截断方式补偿这一缺陷的方法。
1.2 改进对抗网络
DeblurGANv2是一种图像去模糊方法,是DeblurGAN的改进版,其流水线架构如图2所示。GAN是一种基于博弈论的机器学习技术,由生成器和判别器2个网络构成。生成器网络接受输入的模糊图像并尝试生成清晰的图像,判别器网络则尝试区分生成器生成的图像是否真实。生成器和判别器通过不断地对抗学习来提高性能。GAN能够从大量的数据中学习到真实图像的分布特征,从而生成具有相似特征的图像,因此在图像去模糊任务中,使用GAN可以获得更好的效果。其推出了特征金字塔网络(Feature Pyramid Network,FPN)放入到去模糊任务中,作为GANv2生成器的核心构建块,可以灵活地与广泛的骨干网络合作,在性能和效率之间取得平衡,例如使用轻量级主干(MobileNet[15]及其变体)。GANv2网络中的带有梯度惩罚的沃瑟斯坦距离生成式对抗网络(Wasserstein GAN with Gradient Penalty,WGAN-GP)[16]是一种用于判别器的损失函数,它是基于沃瑟斯坦距离的对抗网络(Wasserstein GAN,WGAN)的一个改进版本,可以解决WGAN的梯度爆炸和消失问题。WGAN-GP使用梯度惩罚技术,迫使生成器生成的图像更加逼真,并且在训练过程中可以自适应地调整惩罚系数。WGAN-GP的公式为:
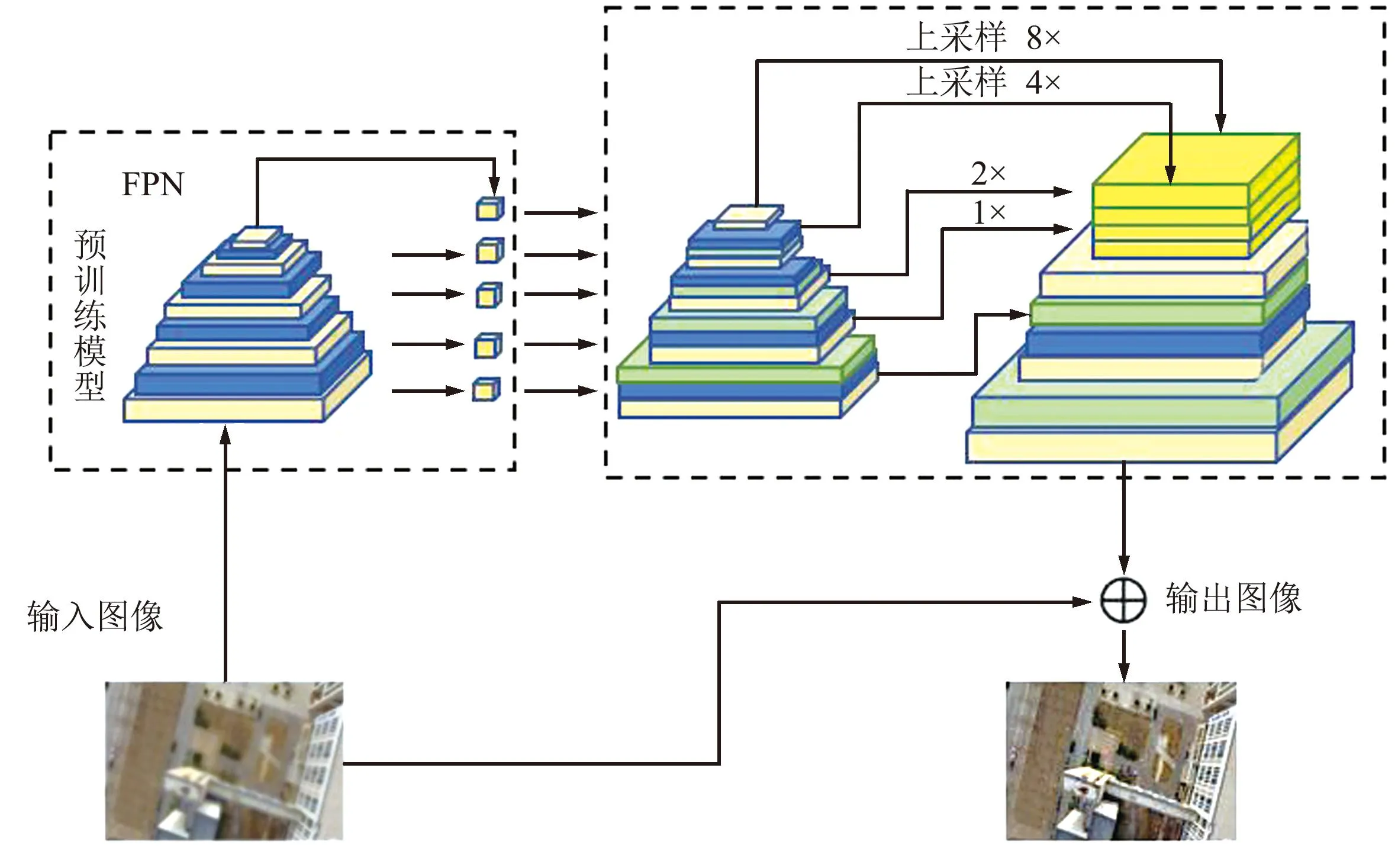
图2 DeblurGANv2流水线架构Fig.2 DeblurGANv2 pipeline architecture
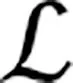
(7)
式中:D(G(z))为判别器对生成器生成图像的输出,D(x)为判别器对真实图像的输出,λ为惩罚系数,GP为梯度惩罚项,用于防止梯度消失或爆炸。
(8)
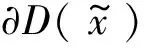
λ是一个很重要的超参数,主要用于控制生成器和判别器之间的平衡,使GAN网络的训练更加稳定和高效。为确保判别器的梯度具有连续性。在WGAN-GP中,λ的值通常设置为10,以确保梯度惩罚在损失函数中的权重得到平衡。值一直为10的情况可能会导致GAN模型中生成器和判别器之间的平衡失调。如果判别器表现不佳,无法准确地区分真实和生成的样本,将影响生成器的训练效果,导致生成器无法生成真实的样本。如果判别器表现很好,生成器将生成接近真实样本的样本,但此时如果值一直为10,则损失函数会过于强调对生成样本的误差,可能导致生成的样本过于保守或缺乏多样性。因此,为了得到更好的训练效果,通常需要根据模型效果时刻调整λ值,使其适应当前训练的状态,达到一个更好的平衡。
2 改进的自适应损失函数模型
为了解决UAV高速飞行时拍摄的图像产生运动模糊的问题,提出了一种基于维纳滤波模块的自适应DeblurGANv2网络。基于指数移动平均值(Exponential Moving Average,EMA)[17-18]对GANv2网络中损失函数的超参数λ(惩罚系数)进行改进,设计一种AEMALF。图3为损失函数中ASEMA调节过程。
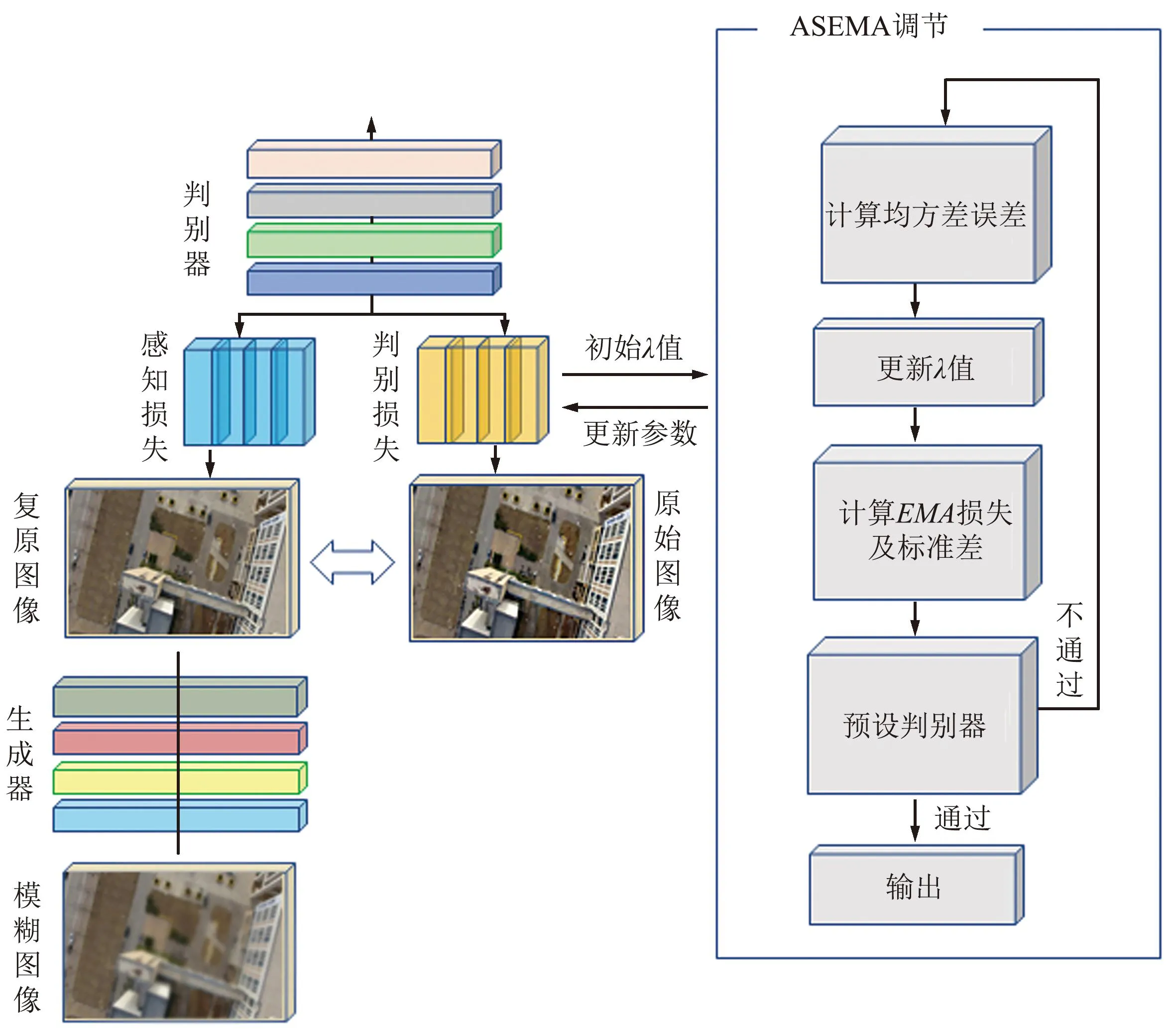
图3 损失函数中AEMALF调节过程Fig.3 Conditioning process of AEMALF in the loss function
其中,对损失函数中λ超参数引入ASEMA算法。
一组模糊图像和清晰图像对,其中模糊图像为x,清晰图像为y。AEMA算法流程如下。
① 对每个模糊图像x,使用模型f生成一个估计的清晰图像y′。
② 计算当前模糊图像x和生成的估计清晰图像y′之间的均方误差损失L(x,y′)。
MSE(x,y′)表示输入图像x和生成图像y′之间的均方误差:
(9)
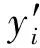
③ 对所有模糊图像x的损失进行指数移动平均,得到EMA损失LEMA:
LEMA=α*L(x,y′)+(1-α)*LEMAprevious,
(10)
式中:LEMA为EMA损失,L(x,y′)为当前批次的均方差损失,α为EMA系数,LEMAprevious为上一次迭代的EMA损失。
④ 计算EMA损失的标准差Lstd:
(11)
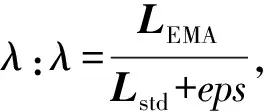
式(11)的意义是在每次模型迭代时,将当前的MSE损失函数与上一次的EMA损失函数进行加权平均,以得到更加平滑、稳定的损失函数值。具体地,根据式(10),LEMA在每次迭代中以一定的权重(1-α)保留上一次的值,同时以另一个权重(α)考虑当前的MSE损失函数。这样,EMA损失函数值不仅包含了当前迭代步的信息,还包含了之前迭代步的信息,使得该函数更加平稳、更能够反映模型的整体性能。
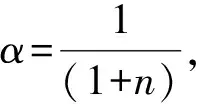
首先,提出先用维纳滤波模块对模糊图像进行预处理并傅里叶变换后将高频信息截断能有效的抑制振铃效应的产生;然后,对Mobilenetv2轻量网络增加提取特征深度和宽度以此作为DeblurGANv2的主干网络,并且对判别器损失函数中的超参数自适应化;最后,本文对模糊图像进行2次恢复,使恢复的图像更加清晰。
3 实验测试与结果分析
3.1 数据集
用大疆精灵4RTK版UAV进行航线规划飞行,飞行过程中将快门速度降低以及拍摄照片中存在一些快速移动的物体用来模拟常规拍摄中可能存在的模糊现象,并且采用了一种基于物理模型的方法来生成训练样本。该模型采用高斯过程模拟运动轨迹,在这个模型中运动轨迹上的每一点都与上一点的位置和速度有关。对运动轨迹进行子像素插值,得到对应的模糊核。
采集1 000对无人机图像,并按照5∶1的比例将其划分为训练集和测试集。图4展示了部分训练数据,其中图4(a)为清晰图,图4(b)为清晰图的局部细节图,图4(c)为模糊图,图4(d)为模糊图的局部细节放大图。此外,为了提高模型的鲁棒性、泛化能力和多样性,在采集过程中尽可能涵盖不同场景、不同光照等情况;另外为使模型更好地适应常规作业中不同程度的模糊图像,在训练集中放入多种模糊度的图像。

图4 部分训练数据Fig.4 Partial training data
3.2 图像相似度评估
使用2种图像相似度评估算法对生成图像和标准图像进行比较,分别是峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似度(Structural Similarity,SSIM)评估算法[19-21]。
PSNR是一种用于表示信号最大可能功率和表示精度之间比值的工程术语,通常用对数(单位dB)表示,由于许多信号具有非常宽的动态范围,因此PSNR具有广泛的应用。
(12)
式中:MAX是表示像素点颜色的最大数值,8 b表示的图像中MAX为255。信噪比数值越大,代表图像越清晰失真越少。
SSIM是一种用于比较2幅图像相似程度的指标,当一幅图像为无失真图像,另一幅图像为失真后的图像时,2幅图像之间的SSIM值可以作为失真图像的图像品质衡量指标。相较于传统的图像品质衡量指标,SSIM更能符合人眼对图像品质的判断,因为它不仅考虑了图像的亮度信息,还考虑了图像的结构信息。给定2个图像x和y,SSIM指标通过比较2幅图像的亮度、对比度和结构信息来衡量它们的相似性,二者的SSIM定义为:
SSIM=[l(x,y)]α[c(x,y)]β[s(x,y)]γ,
(13)
式中:l(x,y)表示图像的亮度,c(x,y)表示图像的对比度,s(x,y)表示图像的结构信息,α、β、γ用于调整这些因素的相对重要性。当SSIM指标的值越大时,表示2幅图像的相似度越高。
3.3 实验结果分析
本文通过实验设计了3种模型,并与DeblurGANv2模型进行对比。这3种模型分别为去振铃效应维纳滤波(Ring Artifact-free Wiener Filter, RLW)、基于自适应指数移动平均函数的对抗网络(DeblurGANv2-AEMALF)以及融合对抗网络和去振铃效应的维纳滤波网络(RLW-DeblurGANv2-AEMALF, RLW-DG-AEMALF)。对比结果如表1所示,其中DeblurGANv2模型为消融实验对照组。

表1 评估结果
图5为去模糊效果对比。可以看出,RLW方法虽然相较模糊图像有一定程度上的改善,但仍然存在少量的振铃效应,而DeblurGANv2生成的图像较为平滑且没有振铃效应,但在局部细节上仍然存在模糊现象。基于RLW的自适应损失函数所生成的图像纹理信息更加丰富,更加贴近于清晰图像。

图5 去模糊效果对比Fig.5 Contrast of deblurring effects
根据表1的评估结果,本文所提出的RLW-DG-AEMALF模型相比于DeblurGANv2模型,在训练过程中需要更多的时间,但是预测单张照片的平均处理时间差距不大。此外RLW-DG-AEMALF模型在去除图像模糊方面表现更优,展现出更好的去模糊效果。尽管RLW模型仍存在一定的振铃效应,但后续的深度学习网络可以弥补这一缺陷。
实验结果表明,相对于原始的DeblurGANv2和维纳滤波模型,RLW-DG-AEMALF模型在图像平均PSNR分别提高了1.56、1.99 dB,SSIM分别提高了6%、9%
3.4 GoPro数据集实验结果分析
GoPro数据集是目前为数不多的公开运动模糊图像数据集之一。该数据集使用GOPRO4 HERO Black相机拍摄街景视频,每秒拍摄240帧,并对连续的7~13帧进行平均以获得不同程度的模糊图像。数据集中将中间位置的一帧定义为对应的清晰图像,共包含3 214对图像,其中2 103对用于训练,1 111对用于测试,图像分辨率为1 280 pixel×720 pixel。由于去模糊任务是将模糊图像恢复为清晰图像,因此在训练集中添加少量经过维纳滤波的图像可以更好地帮助模型学习图像之间的对应关系,并提高模型的泛化能力。但需要注意的是,添加维纳滤波后的图像时需要控制数量,以避免过多的维纳滤波后图像影响模型的多样性,从而导致模型过拟合。GoPro数据集实验的评估结果如表2所示。
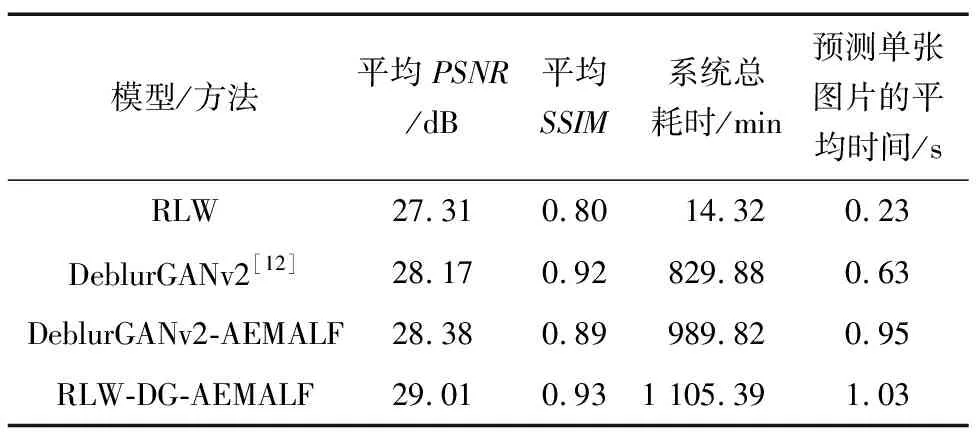
表2 GoPro数据集评估结果
针对复杂的街景环境下的运动模糊,本文使用GoPro数据集进行实验,结果如图6所示。可以看出,仅使用RLW或DeblurGANv2-AEMALF方法的效果并不明显,且使用RLW方法恢复的图像中振铃效应更加明显,对于一张图像中存在多种模糊图像的恢复效果更差。具体原因在于,RLW方法是一种用于运动模糊去除的方法,需要对模糊核进行准确的估计。但在复杂场景下,模糊核可能会因为运动模糊和其他因素的影响而变得复杂,导致精度更高的估计变得更加困难。因此,即使使用RLW方法,也可能无法获得足够好的恢复效果。然而,RLW-DG-AEMALF模型结合了自适应损失函数和DeblurGANv2的优点,能够通过多次复原对模糊图像进行有效地恢复,因此仍然可以获得较高的PSNR值。

图6 GoPro数据集去模糊效果Fig.6 GoPro dataset deblurring effects
实验结果表明,与DeblurGANv2相比,本文构建的RLW-DG-AEMALF模型在GoPro数据集中展现了一些显著的优势。虽然该模型的训练时间相对较长,但是预测单张图片方面与DeblurGANv2几乎相同,而且对运动模糊的图像显示出了很高的复原能力。相较于同类算法DeblurGANv2和维纳滤波,RLW-DG-AEMALF模型恢复后的图像平均PSNR分别提高了0.84、1.7 dB,SSIM分别提高了1%、12%。
4 结束语
针对UAV航拍测量中产生的图像运动模糊这一场景,并为了充分捕捉图像中地物的细节,提出了一种新的模型,将AEMALF与DeblurGANv2模型相结合,设计了DeblurGANv2-AEMALF模型,用于UAV模糊图像恢复任务。又由于DeblurGANv2模型在不同尺度上学习图像细节和轮廓特征的能力,将高频信息截断后的维纳滤波与DeblurGANv2-AEMALF网络相结合,首次提出了RLW-DG-AEMALF网络模型。实验表明,该模型通过对模糊图像进行2次复原,使图像的恢复更加清晰,同时能够有效抑制维纳滤波后出现的振铃效应。在消融实验中,RLW-DG-AEMALF网络模型在构建的UAV数据集和GoPro数据集上表现出比原始DeblurGANv2网络模型更好的模糊图像复原效果。相较于同类算法DeblurGANv2和维纳滤波,此算法恢复的图像平均PSNR和SSIM均有显著提高。然而,本文算法并没有针对UAV航拍测量中可能出现的图像雾化问题进行处理,为了改进算法,后续考虑在相应的模块中引入大气散射模型进行处理。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
实用心电学杂志(2021年3期)2021-07-02
舰船电子对抗(2019年4期)2019-09-10
太原科技大学学报(2019年3期)2019-08-05
今日农业(2019年15期)2019-01-03
常州信息职业技术学院学报(2017年5期)2017-10-23
计算机应用与软件(2017年3期)2017-04-14
洛阳师范学院学报(2017年2期)2017-03-12
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
