
基于场景自适应的船舶吃水值计算方法
2024-03-05 07:35杜京义梁大明
无线电工程 2024年3期
付 豪,张 渤,杜京义,梁大明
(1.西安科技大学 通信与信息工程学院,陕西 西安 710054;2.西安科技大学 电气与控制工程学院,陕西 西安 710054)
0 引言
海运船舶通常采用水尺计重的方式获得货物质量[1],通过卸货前后的六面水尺读数获得吃水深度的变化来计算船舶载运货物的质量。获得六面水尺读数常见的方式为人工观测,这种传统的方式受主观性和环境的影响,容易造成较大的读数误差。除人工观测的方法外,还有通过传感器等辅助仪器测量的方法和图像处理的方法。盖志刚等[2]提出固定传感器激光测量到水面的距离的方法。吴俊等[3]提出声呐传感器获得轮廓线的方法。管利广等[4]提出压力传感器与陀螺仪结合获得载重量的方法。以上的外载辅助仪器容易受场景限制、海水腐蚀,因此更多的学者提出图像处理的方法。在传统的图像处理方法中,吴海[5]提出透明水体边缘检测,采用霍夫直线检测水线,浑浊水体分析颜色分量确定感兴趣区域(Region of Interest,ROI),边缘检测挑选合适分量,水平投影定位水线,彩色图像RGB分割字符,采用平方差和(Sum of Squared Differences,SSD)相似度计算获得匹配区域,然后仿射变换动态匹配视频。李锦峰[6]提出双向提取的字符区域采用背景色填充,利用K-means聚类算法分割图像,定位吃水线。但这些传统的方法在遇到水尺受损、水面有浪花等复杂环境时表现较差。在采用深度学习方法中,吴禹辰[7]提出采用Faster R-CNN算法固定大小锚框标定水尺位置,采用最小二乘法和3次样条插值拟合,设计了倾斜和非倾斜2种方法计算吃水线。此方法面对有浪花、船体斑驳等情况,对吃水线的定位精度会有所下降。张钢强[8]采用语义分割的方法,分割水体与船体定位吃水线,采用单一灰度图像最大稳定极值区域(Maximally Stable Extremal Regions,MSER)与CIElab的L通道的MSER提取候选区域合并,选取blob特征分析对字符裁剪进行识别。这种方法对吃水线的定位有显著提升,但针对水尺字符倾斜角度较大的情况表现较差,其性能和鲁棒性会较差。针对图像的矫正,薛银涛[9]提出手动旋转第一帧视频图像,之后的每一帧旋转同样的角度,但该方法自动化程度不高且只适用于固定位置拍摄的情况。安鸿波[10]提出对二值化图像进行形态学处理,通过获得字符与吃水线的走势计算斜率进而矫正图像。然而,在夜间和船体受损的情况下,该方法效果表现不佳。
针对船体表面弯曲程度不同、水尺拍摄时间段不一、水尺标志区域受损且存在倾斜等问题,本文提出一种基于场景自适应的船舶吃水精确检测方法,水尺计重会根据不同船型的弯曲程度有相应公式修正,因此重点解决后两点的场景问题,首先采用不同阈值的修正型伽马矫正,改善夜间拍摄图像的质量,接着采用语义分割定位字符和吃水线排除水尺标志区域受损的影响,再结合字符和吃水线的定位信息矫正图像,然后裁剪字符进行识别和精确定位,最后根据字符信息计算获得吃水深度。本文方法解决了夜间拍摄识别困难的问题,对不同场景的拍摄都有较好的矫正效果,排除了水尺标志区域受损的干扰,实现吃水深度的精确测量。
1 船舶吃水值计算方法流程
本文提出一种基于场景自适应的船舶吃水值计算方法,主要分为四部分。首先,进行图像预处理,利用亮度公式确定是否需要增强图像,并对需要增强的图像采用修正型伽马校正,以提升夜间拍摄图像的质量;其次,进行图像分割,利用改进的语义分割算法对水体、水尺字符和船体进行分割,定位吃水线和水尺字符;然后,进行图像矫正,结合水体分割图像信息和水尺字符图形信息,计算斜率并设计对应坐标,采用投影变换对水尺进行矫正;最后,进行吃水值计算,利用矫正后的字符分割图像的轮廓信息裁剪水尺字符,对大M字符二值化后进行字符识别获得数值信息,对小字符进行边缘检测,结合数值信息,利用吃水值的计算公式得到吃水值。吃水值计算流程如图1所示。

图1 吃水值计算流程Fig.1 Draft value calculation process
本文数据来源于海南某港口电厂,采集图像时通常为电厂人员乘坐小艇在全天任意时间段拍摄,如图2所示。在夜间采集时,通常为手电照射水尺区域,然后采集图像,采集到的图像如图2(a)所示,图像出现光照不均匀,且水尺标志出现高亮。此外,由于船只受海水腐蚀和靠岸侧船体刮擦,工作人员的拍摄角度也受到限制,因此拍摄的图像可能存在水尺区域缺失、白色字符脱色、水尺标志倾斜和水面有浪花等情况。这些因素都会对船舶吃水值的计算造成很大困难。拍摄图像时存在诸多不利因素,例如光线环境变化、水尺损伤和倾斜等,多数拍摄图像存在字符倾斜的情况,因此需要一种算法来自适应不同的场景。

(a)夜间拍摄
(b)船体锈蚀

(c)浪花干扰

(d)字符缺损
2 图像预处理及分割
受港口环境和拍摄方式的限制,采集到的水尺图像往往需要进行预处理。观察可知,夜间拍摄和白天拍摄的图像存在明显的亮度差异,字符区域不清晰。因此,本文采用亮度公式判定图像是否需要进行亮度增强。首先,计算图像RGB三通道的像素均值;然后,利用式(1)求得图像的亮度表达值。针对多张白天与夜间拍摄的图像分别进行计算并分析二者亮度表达值的分布情况,如图3所示。由于夜间拍摄也存在光照良好情况,所以设置亮度表达值的阈值为100,将小于此阈值的图形进行亮度增强,提高较暗区域的亮度,使得水体和字符能够更加突出。
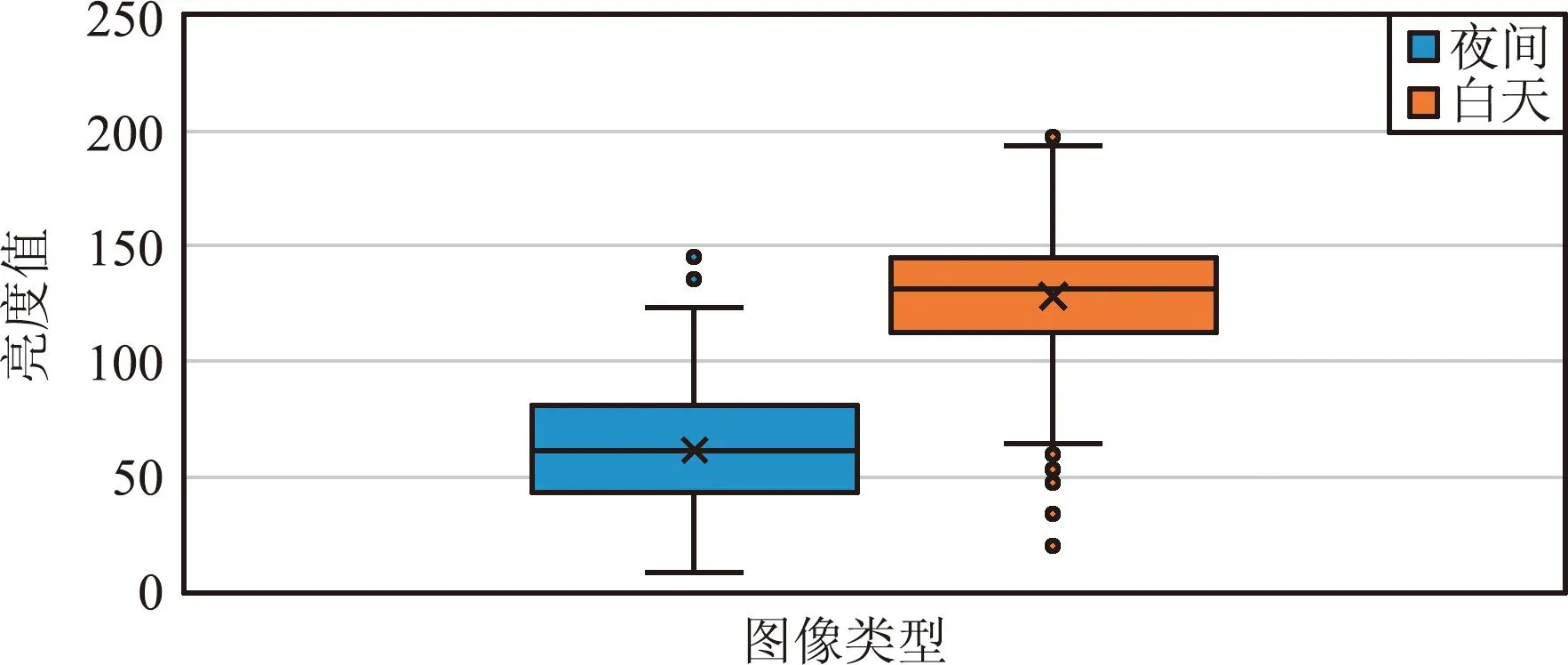
图3 夜间与白天拍摄图像的亮度分布Fig.3 Brightness distribution of images taken at night and during the day
亮度公式如下:
Y=0.299×R+0.587×G+0.114×B,
(1)
式中:R、G、B为图片的颜色分量,Y为求得的亮度表达值。
针对图像的亮度增强,常见的方式如下:
方式1是对图像的HSV颜色分量中的V分量进行直方图均衡化[11],压制图像高亮区域,提亮图像暗区域,这种方式对于亮度表达值较小的图像会出现严重的色彩失真,对后续的图像分割任务有重要影响。
方式2是对图像采用伽马校正,通过非线性变换,解决图像过暗和过亮问题。其中,伽马值为最重要的参数,当伽马值大于1时,用于校正较亮的图像;小于1时,用于校正较暗的图像。手动调节伽马值可以通过观测找到最佳校正的伽马值,但不适用于大批量的图像处理。文献[12]提出的自适应伽马校正,通过假设正常图像的像素均值为0.5,计算目标图像的平均亮度,并分别对其取对数相除,以获取伽马值,使得目标图像的直方图向中心靠近。这种方式对于不太暗的图像可以获得的较好校正效果,但是对于太暗的图像校正结果会出现偏色。
因此,提出了一种修正型的伽马校正,采用分段函数对小于0.5的伽马值进行上调,大于0.5的不进行修改,用上述RGB三通道得到的亮度表达值归一化后代替原公式中用图像灰度化求均值得到的平均亮度,使其计算值更准确。图像预处理结果如图4所示。经实验,修正后伽马值对整体图像校正效果更好,适应性增强。

(a)原图

(b)方式1

(c)方式2

(d)本文方法
本文采用的修正型伽马校正公式如下:
(2)
(3)
式中:Y/255为亮度表达值归一化,γ为未修正的伽马值,伽马为采用分段函数进行修正获得伽马值。
在水尺深度的测量中,图像的分割任务尤为重要。传统的分割方法会受图像场景变换的影响。没有风浪、船体无污染以及照充足时拍摄的图像,传统图像分割方法可以准确地定位吃水线以及字符,图像的矫正工作也会减轻,计算结果相对准确。但实地环境以及船体是多变的,复杂的背景难以取得良好的效果,并进而影响吃水深度的计算。因此,针对船舶水尺图像中船体和水尺标志损伤,采用传统的图像处理技术已经不能满足要求,对水线和字符的定位工作就难以进行。目前采用语义分割的方式已经在分割船体和水体取得了很好的结果。语义分割的模型众多,例如FCN[13]、DeepLab[14]、SegNet[15]和PSPNet[16]。本文选用常用于医学图像分割的UNet[17]网络,其采用编码(encoder)与解码(decoder)的U型结构,在医学中的CT扫描影像、显微图像等的分割任务中有着出色的表现。针对船舶水尺的水体与字体分割任务中,目标的特征较为单一,但其水尺标志区域受外界因素的影响会有不同程度的损伤,这对目标分割的精细化是一项挑战。因此,对原UNet进行改进,采用特征提取能力较好的VGG网络替换原主干网络。VGG每一层的卷积提取的特征并不一定是关键特征,因此在编码与解码的跳跃连接中增加混合注意力机制(Convolutional Block Attention Module,CBAM)以提高网络对字符与水体区域的关注,细化目标区域的特征提取。修改损失函数,采用Focal Loss作为损失函数,让网络更注重解决相对难分割的字符样本,提高分割的精度。改进后的UNet网络结构图如图5所示。

图5 改进后的UNet网络结构Fig.5 Diagram of the improved UNet network structure
CBAM为融合通道注意力(Channel Attention Model,CAM)和空间注意力(Spatial Attention Model,SAM)的混合注意力机制,CBAM结构如图6所示。在骨干网络VGG提取的特征层与对应上采样进行特征融合时,将中间的特征层输入CAM,获取其通道上的注意力权重,再将结果传到SAM获得特征图的空间注意力权重。经过CBAM注意力机制处理,网络更聚焦重要特征区域,抑制无关特征的影响。

图6 CBAM结构Fig.6 CBAM structure
流程公式如下:
(4)
(5)
式中:F为主干网络提取特征图,Mc为CAM特征图,Ms为SAM特征图,⊗表示元素级相乘。
替换原本的损失函数,选用Focal Loss作为本文的损失函数,目的是调整网络对易分割目标与难分割的权重分配,字符的分割相对于水体为难分割目标,因此选用Focal Loss解决字符的分割问题行之有效。
Focal Loss的公式如下所示,通过对交叉熵损失函数CE引入一个调节因子(1-p′)λ减小容易分类的样本权重,关注难分类样本。
(6)
(7)
(8)
式中:p为预测标签的置信度,λ为调节因子的调节参数。λ≥0,λ的值越大,易分类的loss越小,这就使模型关注难分类样本。
3 图像矫正及吃水值计算
由于拍摄角度受限,采集的图像会出现不同程度的倾斜,倾斜图像对于后期计算吃水值会有很大影响,若对倾斜图像进行计算,则需根据不同的倾斜情况设计不同的算法,且精度会有所偏差。所以,由上述得到的水体和字符的分割图像对原图像进行矫正可以大大减少后期吃水值的计算难度,并且精度有所提高[18]。通过水体和字符的分割图像可以计算吃水线和字符的斜率,利用斜率在原图像上寻找4对相对应的坐标点,采用投影变换对图像进行矫正。与矫正结果有着直接关系的是斜率的确定,因此针对两斜率的计算设计如下2个算法流程。
(1)针对水体分割图像
① 采用形态学处理,去除分割产生的杂点和填充细小的孔洞;
② 对①结果进行canny边缘检测,获得吃水线的边缘;
③ 对②结果采用轮廓检测得到吃水线的点集;
④ 对③结果采用最小二乘法拟合得到水线的斜率。
对于吃水线斜率算法设计,采用canny边缘检测[19]算法对二值图像的边缘查找要好于其他边缘检测算法,不会出现吃水线边缘未检测到和边缘存在大空洞的情况。没有对图像直接进行轮廓检测获取吃水线点集,是因为轮廓会包含图片的边框,需设计另外的算法对其进行去除,适应性差且图像处理速度变慢。
(2)针对字符分割图像
① 采用形态学处理,去除分割产生的杂点和填充细小的孔洞;
② 对①结果中字符的每个连通区域进行最小外接矩形拟合获得连通区域的中心坐标;
③ 对②中心坐标的集合进行外接矩形拟合,获得穿过中心坐标点最多的直线;
④ 计算②获得的所有中心坐标到③获得直线的距离,采用大于距离集合均值剔除的算法,去除离群点;
⑤ 采用最小二乘法拟合④的结果点集,获得字符的斜率。
对于字符的斜率算法设计,采用连通区域的外接矩形中心点再次进行外接矩形拟合,可以很好地获得所有中心点的大体走向,再利用距离信息剔除离群的点,最后采用最小二乘法拟合直线,可以得到更加精准的斜率,相对于直接对中心坐标进行最小二乘法拟合直线,效果要更好。算法的结果和比较如图7所示,其中图7(e)中的实线为剔除离群点的结果,虚线为直接拟合直线的结果。

(a)原图

(b)水体分割图

(c)字符分割图

(d)字符连通区域中心点拟合
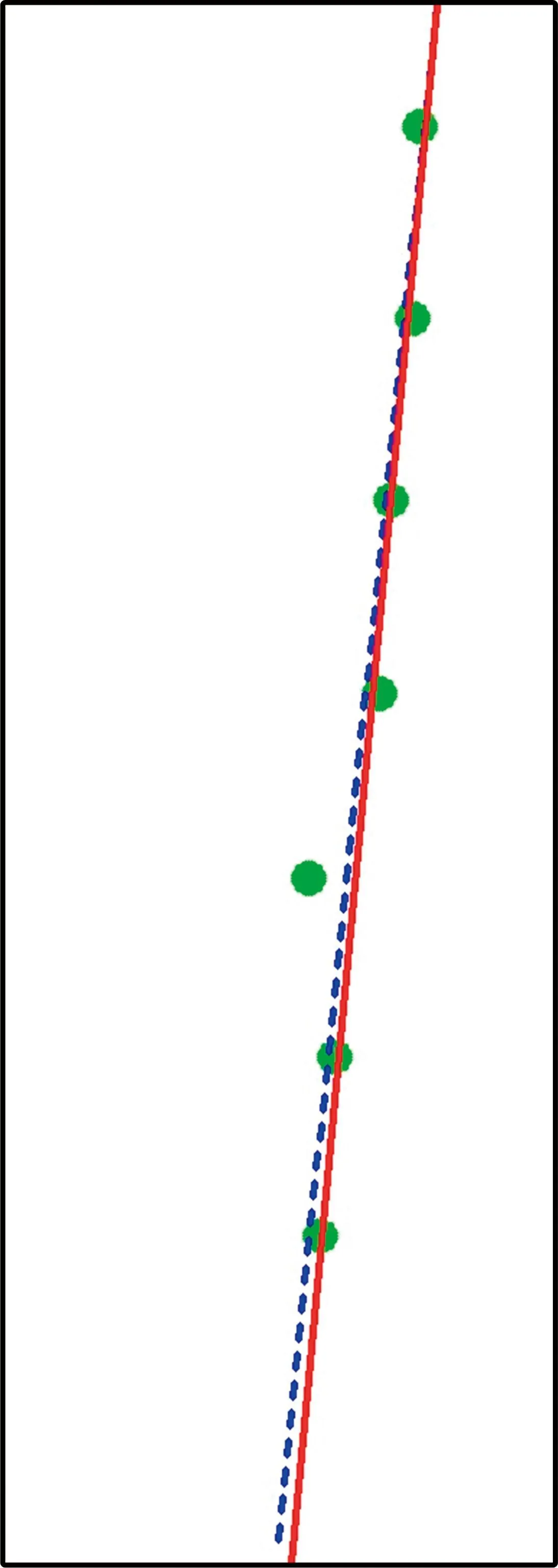
(e)字符2种拟合直线结果

(f) 最终拟合斜率
最小二乘法是一种数学优化技术,通过最小化误差的平方和寻找数据的最佳函数匹配。假设一组坐标样本为((x1,y1),(x2,y2),…,(xn,yn)),对样本进行直线拟合,直线公式设为y=kx+b。通过使损失函数值最小,求得k和b的值如下:
(9)
(10)
根据吃水线和字符的斜率,采用投影变换对图像进行矫正,投影变换是将图像投影到一个新的视平面,即正面拍摄水尺图像的效果。投影变换需要4组两两对应的坐标,通过计算得到变换矩阵[20],对原图进行矫正,由于矫正后的图像会出现图像缺失,因此为保证图像的字符较好地保留下来,对坐标的选定为图7(f)中白线与图片的边框的交点和以白线的交点为十字中心的正十字线与图片的边框的交点作为4组对应点。图像矫正结果如图8所示,矫正之后可以很好地保留图像的有效区域且结果较为准确,便于后续吃水值的计算。
图8 图像矫正结果Fig.8 Image correction results
投影变换算法公式如下:
(11)
(12)
式中:(x0,y0)为原图像中的坐标点,(X,Y,Z)为变换后的目标点,通过4组对应的坐标点即可求出矩阵中a11,a12,…,a33的值,其中a33=1。
吃水值的计算,需要大M字符的数值和字符与水线的位置。水线的位置信息在图像矫正的过程已经获得,因此只需获得字符的位置信息和靠近吃水线的大M字符的数值。
(1)大M字符数值的确定
在矫正原图的同时对字符的分割图像进行矫正,对字符的矫正结果进行轮廓检测,通过获得的轮廓信息裁剪原图中的大M字符,将裁剪的左侧大米数的字符进行大律法二值化,再对二值化图像进行字符识别,获得字符的数值。采用大律法可以更好地得到描述字符特征的二值图像,相对于原图,裁剪后的图像二值化效果更佳。
(2)字符位置的确定
对裁剪的右侧字符进行高斯滤波然后边缘检测,通过水平投影的方法获得顶部位置,由于光照会在字符的左、右下侧产生阴影,对字符的顶部没有影响。因此使用相邻字符顶部像素距离与实际距离的比值作为像素比例尺,最终计算底部字符到水线的距离通过计算公式得到吃水值。针对有波浪情况下采集的水尺视频,可对连续的读数结果进行周期化,之后取平均值,能有效降低波浪对读数精度的影响;针对字符白色漆料缺失等情况下,采用边缘检测可有效避免其造成像素比例无法正确计算和吃水值出现大误差的问题,算法的适应性更强。吃水值计算过程如图9所示。

(a)分割字符矫正
(b)大M字符裁剪与二值化

(c)小字符裁剪

(d)边缘检测

(e)水平投影
吃水值计算示意如图10所示,标准船只的小字符的高度为10 cm,假设字符6和8的顶部像素距离为S2,字符6与水线的像素距离为S1,大M字符的下方有2个字符,设吃水值为D,吃水值的计算公式为:
(13)
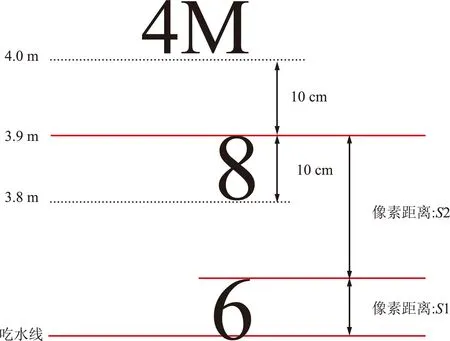
图10 吃水值计算示意Fig.10 Schematic diagram of draft value calculation
4 结果与分析
4.1 夜间图像增强结果
针对夜间图像的处理结果如图11所示,从左向右图像亮度依次降低,V分量直方图均衡化方法会使图像出现严重偏色,自适应伽马校正的方法在图像亮度较低时会出现过度校正,图像会偏白失真。与二者比较可以看出经过修正后伽马值校正效果更佳,在图像不失真的情况下最大可能凸显水尺标志与水体。



(a)场景1 (b)场景2 (c)场景3
4.2 图像分割结果
实验数据经过剔除无效图像后,包含1 035张白天采集图像和150张夜间采集图像。对夜间采集的图像经过修正型伽马校正后与白天采集的图像放在一起,采用百度飞桨提供的半自动打标签软件EIseg对所有的图像进行标注,标注类别为字符和水体。如标注图像的示意如图12所示,分为字符的标注区域、水体的标注区域和船体区域。
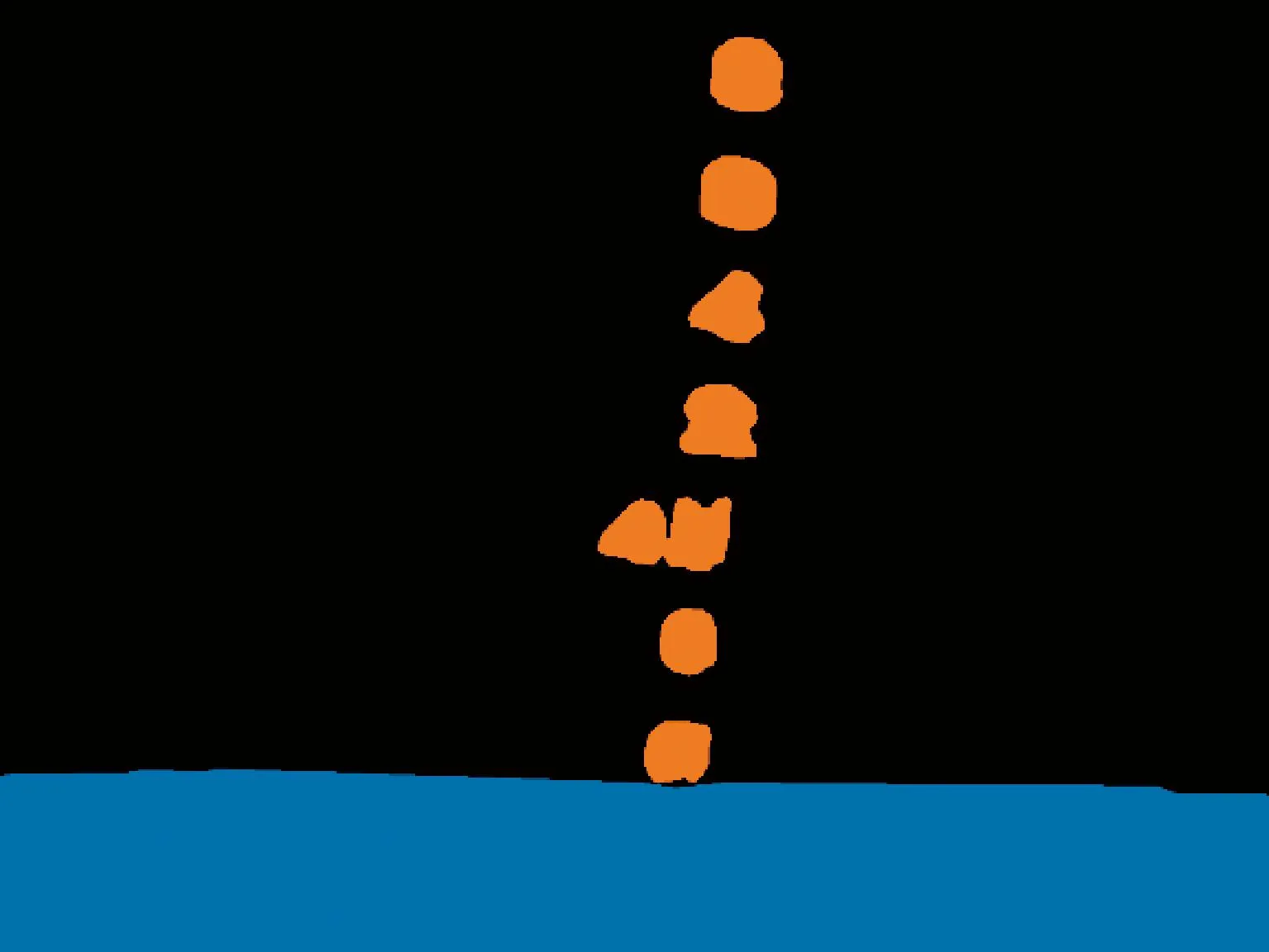
图12 图像标注示意Fig.12 Illustration of the image annotation
数据集中训练集与验证集的比例划分为4∶1,采用Windows 10操作系统实现,硬件环境如下:CPU为Intel(R) Xeon(R) CPU E5-2640 @2.40 GHz、GPU为NVIDIA Quadro P2200,后期可使用更高规格的GPU进一步提高检测速度。算法采取了冻结网络主干和解冻训练结合的方式进行训练,训练均采用迁移学习,以加快模型的收敛,特征提取网络权重均为数据集VOC2007训练权重,训练总轮次为300,50次冻结训练加250次解冻训练,基本学习率为0.001,下采样倍数为16,输入图像的尺寸为512 pixel×512 pixel,冻结训练和解冻训练的batch-size分别为8和4。训练300次后,训练集和验证集的损失值曲线如图13所示,可以看到模型的迭代已经收敛。
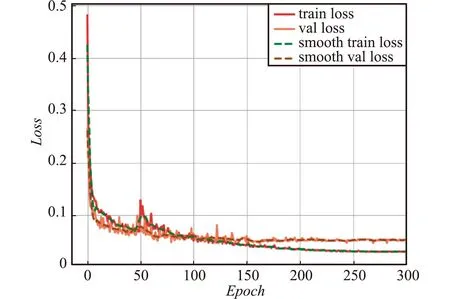
图13 训练集与验证集loss曲线Fig.13 Training loss curves versus validation loss curves
4.2.1 评价指标
采用单个类别的交并比(Intersection over Union,IoU)、召回率(Recall)和精确率(Precision)作为衡量指标,单类别分析更能分析其分割效果。IoU为预测结果与真实标签交集与并集的比值,示意如图14所示。
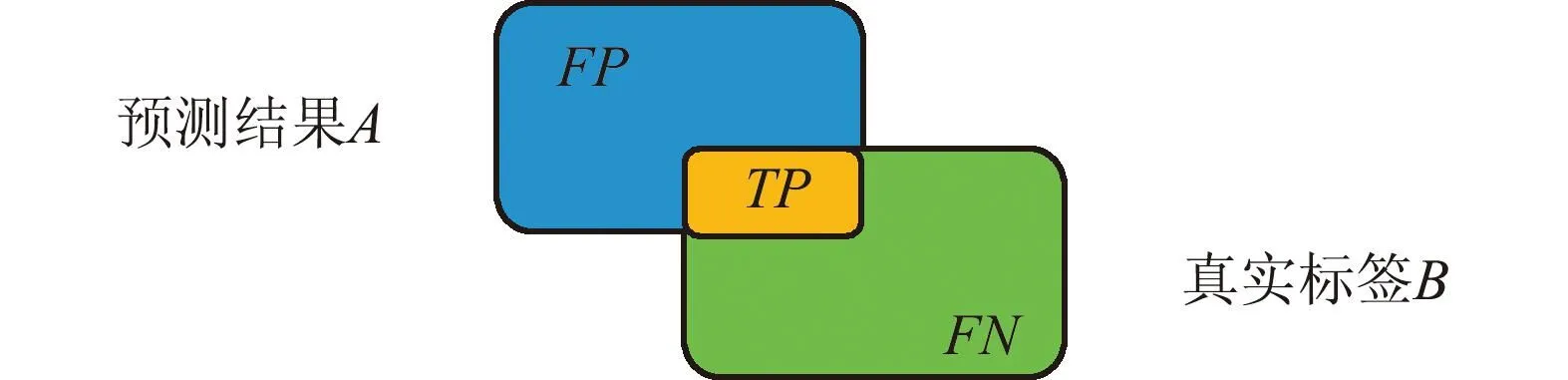
图14 IoU示意Fig.14 Diagram of IoU
(14)
(15)
(16)
式中:FP为预测为真样本,实际为假样本的部分;TP为预测为真样本,实际为真样本的部分;FN为预测为假样本,实际为真样本的部分。
4.2.2 不同算法对比
为验证本文改进UNet的优势,分别对比了几个主流网络在分割水体与字符的表现。不同模型分割结果的对比分析如表1所示,不同模型在水体的分割任务中的表现相差并不大,所以水体的分割不作为重点分析对象。不同模型分割结果如图15所示。对于字符的分割,改进的UNet对比几个主流的网络,分割效果最好,对比采用ResNet50为特征提取网络的UNet,IoU也提升了2.23%。

表1 不同模型分割结果对比Tab.1 Comparison of segmentation results of different models

(a)原图 (b)标签 (c)HrNet (d)BiSeNetv2 (e)ABCNet (f)UNet (g)本文算法
4.2.3 消融实验
为验证特征提取网络替换,以及添加注意力机制和修改损失函数的有效性,首先对不同的特征提取网络替换进行了评估,然后对增加注意力机制和修改损失函数进行了评估。消融实验结果如表2所示,水体的分割结果已满足检测需求,因此只列出字符分割的评价指标。
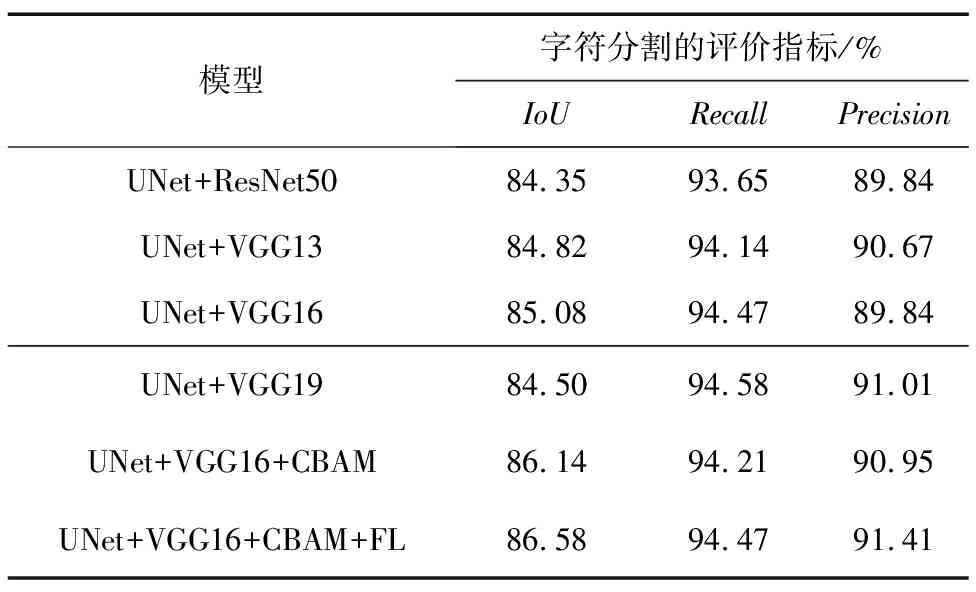
表2 消融实验Tab.2 Ablation experiment
观察表2可知,对于字符这种特征较为单一的目标,ResNet的表现并不如VGG,在选用不同深度的VGG特征提取网络中,VGG16的表现最佳,网络深度的提升可能会造成梯度消失,对特征的提取效果会降低。字符的分割效果会一定程度影响图像的校正效果,在添加了注意力机制与修改损失函数后,字符的IoU、Recall和Precision均有所提升,这对后续的图像校正有着重大的作用。消融实验证明对UNet所做改进的有效性。
4.3 图像校正结果
针对水尺标志图像的矫正的实验部分结果如图16所示,将不同场景下的水尺图像进行实验对比。传统方式中,文献[10]提出的经过mean-shift滤波再自适应阈值分割,针对图像质量较好的情况有着良好的表现,根据设定的条件可以获得字符和吃水线的斜率,图像的矫正效果较好,但对于复杂的环境变化,如水面反光、水尺标志区域受损以及光照条件差等情况,此方法不能取得稳定的表现。本文依靠语义分割,在各种复杂场景都能取得良好效果,通过对轮廓以及边缘信息的分析,矫正图像的效果都要优于传统方式。





(a)水面反光 (b)船体受损 (c)夜间拍摄
4.4 吃水值计算结果
吃水值计算结果如图17所示,从上往下第2条红色标注线到第3条红色标注线的距离为最下方字符到吃水线的像素距离1;第1条红色标注线到第2条红色标注线为计算的像素距离2,用来计算像素比例尺;左上角为计算的吃水值。本文算法对于多种场景都有着很好的识别效果,读数数据如表3所示,算法读数的准确以船方提供的标准读数为准,本文的算法识别为像素级别的比例换算,结果达到毫米级别。
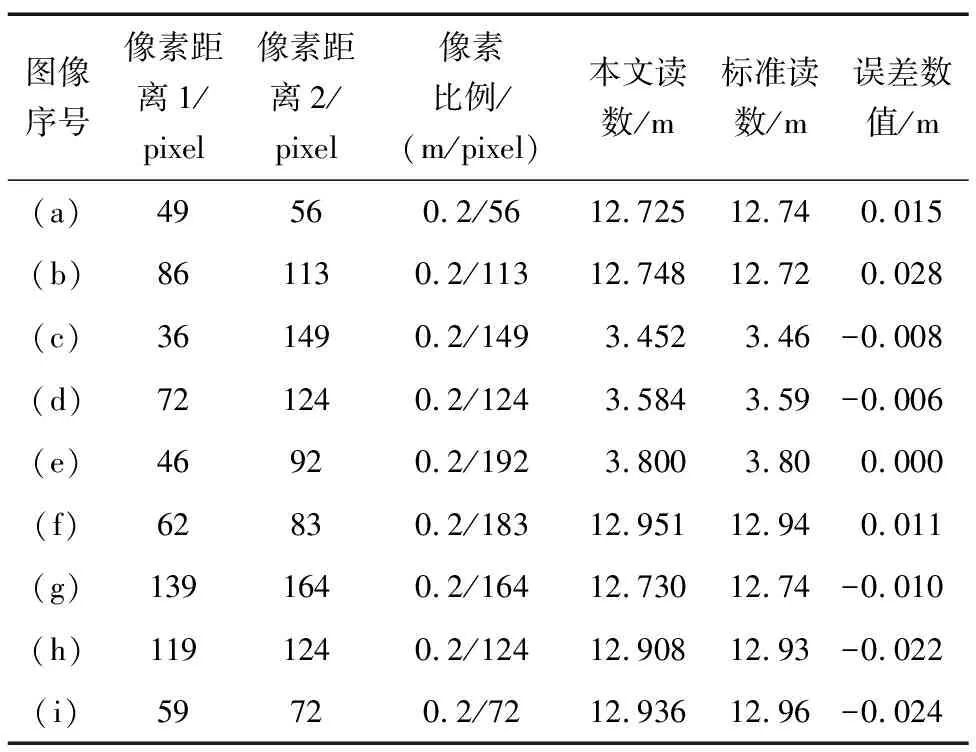
表3 读数数据Tab.3 Reading data



(a)场景1 (b)场景2 (c)场景3
与标准读数的误差保持在上下3 cm内,读数结果优于人眼的直接估算,本文算法与人工读数的误差分布图如图18所示,人工读数的稳定性和低误差性要差于本文算法。

图18 误差分布Fig.18 Error distribution
5 结束语
基于场景自适应的船舶吃水值的计算方法,针对采集后的图像数据,采用图像亮度增强有效地解决了夜间拍摄图像难识别的问题,利用深度学习分割图像,消除了船体有损伤造成的字符和吃水线难定位问题,对分割图像的后处理,有效地提高了船舶吃水值的计算准确度,这对后续的水尺计重提供了有力的保障。此外,考虑到语义分割对小目标的分割精度会弱一些,因此字符的分割只作为字符初步定位,后续会对字符的分割进一步研究,对算法的整个流程进行优化,使得算法的鲁棒性更强。
猜你喜欢
军事文摘(2024年4期)2024-03-19
军事文摘(2023年18期)2023-10-31
电脑爱好者(2022年15期)2022-05-30
珠江水运(2021年24期)2022-01-23
科技与创新(2019年22期)2019-12-07
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
广船科技(2019年2期)2019-10-16
少儿美术(快乐历史地理)(2018年7期)2018-11-16
家庭影院技术(2018年8期)2018-08-21
