
配电网中任务卸载决策与边缘资源分配优化方法
2024-03-12 08:58朵春红齐国梁梅华威李保罡李永倩
计算机工程与应用 2024年5期
朵春红,匡 竹,齐国梁,梅华威,李保罡,李永倩
1.华北电力大学河北省能源电力知识计算重点实验室,河北 保定 071003
2.华北电力大学计算机系,河北 保定 071003
3.华北电力大学电子与通信工程系,河北 保定 071003
随着配电网的建设推进及规模扩大,其运行形态和技术特征面临重大变革[1]。一方面,体量庞大且分布广泛的配电设备、量测终端产生了海量异构数据,如果这些数据都迁移到云计算中心进行处理,将给云中心及通信信道带来巨大的负载压力[2]。另一方面,多元利益主体产生了差异化的业务需求,如计算密集型任务和时延敏感型任务;大多数终端设备电池容量有限,需要控制其任务通信和计算过程中产生的能耗。计算能力、时延及能耗等各方面约束限制了系统性能和用户体验。
作为云计算的延伸和补充,移动边缘计算(mobile edge computing,MEC)可以减少端到端时延,减轻回程链路负担,提高用户服务质量。随着现代信息技术与电力系统的深度融合,边缘计算成为提升配电网稳定运行、实时分析及控制能力的有效手段。如何高效利用配电网边缘有限的通信及计算资源,降低时延及能耗成本,提升系统计算性能和吞吐量,是保证配电物联网高效运作的关键问题。
边缘计算中的任务卸载与资源分配问题相互耦合,现有研究通常将两者协同优化。文献[3]提出一种基于李雅普诺夫优化的联合计算卸载和无线资源分配算法。文献[4]考虑车联网中移动车辆和固定基础设施的任务协作,设计了一种启发式算法——容错粒子群优化算法,以最大化延迟约束下的可靠性性能。传统优化方法计算复杂度高,耗时长,基于启发式的方法可以降低计算复杂度,但通常需要大量的迭代才能达到满意的解决方案。与上述优化方法相比,深度强化学习(deep reinforcement learning,DRL)算法具有强大的学习能力,可以在没有先验知识的情况下快速地做出自适应决策,因此被广泛用于解决大规模动态优化及复杂的协作、博弈问题。使用DRL算法处理资源分配问题时,将问题建模为马尔可夫决策过程(Markov decision process,MDP)。随着用户数量的增加,MDP模型的规模呈指数增长,出现维度诅咒。文献[5]采用深度确定性策略梯度(deep deterministic policy gradient,DDPG)来处理动作空间和状态空间的高维连续性,减少任务的长期处理延迟。文献[6]结合DDPG,长短期记忆网络和注意力机制提出A-DDPG,制定了任务卸载问题以最小化所有任务完成时延和能量消耗的总成本。文献[7]设计一种改进的深度Q网络(deep Q network,DQN)算法求解物联网边缘计算系统中的资源协同优化问题,用多个重放存储器来降低样本之间的相关性,在Q网络的末端添加滤波层来过滤无效动作的状态动作值。文献[8]研究多用户MEC 系统中卸载决策和资源分配的联合优化问题,提出一种基于双深度Q 网络(double deep Q network,DDQN)方法,最大化用户的计算效率。
近年来,配电网等工业物联网场景下的计算卸载与资源分配引起了广泛关注。配电网中未知的动态环境和巨大的状态和动作空间,与深度强化学习的优势高度契合。文献[9]分别针对静态和动态信道环境,制定多任务计算卸载、NOMA 传输和计算资源分配的联合优化方案,在满足每个任务的延迟约束下,实现物联网设备的总能耗最小化。文献[10]考虑到工业物联网环境的高度分布性及动态性,提出基于DQN 的资源分配方案以最大化系统的带宽利用率及能源效率。智能电网中有大量具有不同延迟要求的服务,文献[11]结合神经网络和基于DRL的轮询方法,解决了其中的联合通信、计算和缓存资源分配问题。文献[12]采用异步优势动作评价算法处理微电网能量交易中的区块链计算任务卸载问题,减少任务处理的时延并提高系统吞吐量。
相较于对时延[5]、能耗[8]等的单一优化,多目标优化更适合高度复杂的物联网环境。较为普遍的是对时延、能耗等多因素进行权衡,如考虑最小化用户设备执行能耗与计算时间的加权和[13]、在最小化任务能耗和延迟加权和的同时实现系统的负载平衡和通信负载优化[14]。文献[8]、文献[15]提出计算能效这一性能指标,将其定义为计算比特数与能耗的比值,并研究其最大化问题。这一指标旨在实现系统计算能力和能量消耗的同步优化[16]。
上述研究考量了用户需求和系统性能,忽视了边缘节点的利润。实际上,配电网中利益主体在请求资源时往往呈现出自私性,即追求自身利益的最大化而忽略整体利益。同时,随着用户数量的增加,资源有限的边缘节点无法完成所有计算任务,必须选择性地为卸载任务分配资源。因此,有必要设计一种机制来激励边缘节点为用户提供通信及计算服务,并且维持资源的公平竞争。拍卖是一种兼具公平性和高效率的分配机制,然而由于资源的地理分散性及资源请求的多样性,传统拍卖模型并不直接适用于边缘计算场景。针对边缘计算中基于拍卖的资源分配问题,文献[17]将移动边缘计算中的资源管理建模为双边拍卖,同时优化服务器的收益和物联网设备的效用。文献[18]设计了一种促进边缘云与移动设备之间资源交易的多轮拍卖机制。
综上所述,现有文献更多关注MEC 中的任务卸载及资源分配问题,但对具体场景的考虑并不充分,较少考虑边缘服务器的资源限制问题和多个用户之间的资源竞争关系。基于现有研究工作,本文针对配电网场景中边缘计算卸载和资源分配的联合优化问题,提出一种基于DRL 的任务卸载算法与基于拍卖的资源分配机制。所提卸载方法能在异构任务需求和时变信道的条件下,同时考量边缘节点负载平衡及任务排队时延等因素,使用户在动态环境下自适应地迁移任务,并选定最优的离散化资源请求策略。所提拍卖方案适用于配电网边缘计算系统,且能提高边缘节点的利润及资源利用率。本文的主要贡献包括:
(1)考虑配电网中多边缘节点、多用户设备的复杂场景。具体而言,资源有限且计算能力不均衡的边缘节点以分布式方式部署;用户任务随机到达,这些任务具有不同数据大小、计算量、资源需求和时延要求,竞争有限的资源。将边缘通信和计算资源的分配问题建模为双目标长期优化问题,即最大化系统计算能效和边缘节点效益。
(2)提出一种基于DRL的在线任务卸载算法,在算法中同时考虑边缘节点负载平衡及任务排队时延等因素,让用户任务在动态环境下自适应地调整迁移策略,以实现时延约束下系统计算能效的最大化。
(3)提出一种基于补偿策略的多轮迭代拍卖算法解决边缘节点的资源分配问题,通过用户竞价及动态的价格调整提高边缘节点的收益。
1 系统模型
1.1 网络模型
本文构建了一个配电网中的云-边-端三层边缘计算卸载及资源分配模型。
如图1 所示,云层拥有丰富的通信资源与计算资源[19]。云层中的服务器,如配电网调控中心,负责任务卸载模型的训练及更新。同时它可以作为拍卖商,从用户设备收集资源需求和边缘服务器的资源使用情况,通过专用的控制通道进行资源分配决策。

图1 配电网边缘计算系统模型Fig.1 Edge computing system model of distribution network
边缘层由J个边缘节点组成,定义为j∈{1,2,…,J},每个边缘节点包括一个小基站和一个边缘服务器。边缘节点具有一定的通信、并行计算能力,边缘服务器的计算能力用CPU 速率表征,即CPU 每秒可运转的最大周期数。
用户层由K个用户设备(user equipment,UE)组成,定义为k∈{}1,2,…,K,如配电终端、传感器等。用户k可以生成多个计算任务i∈{}1,2,…,I并接收返回的计算结果。用户k的第k个计算任务定义为ik=为任务数据大小;cik为任务的计算量,即任务计算所需的CPU 周期次数;为任务的最大容忍时延。任务随机到达,任务的特征参数均匀分布在一定范围内。用户利用云端下发的训练模型,生成迁移决策,进行局部数据的传输和计算。
定义一个离散的时隙模型t∈{1,2,…,T},每个时隙t的持续时间为τ。用户可以在本地计算任务,也可以将任务迁移到边缘节点。将用户本地和边缘节点表示为可选择的集合m∈{0,1,2,…,J},任务卸载决策变量xikm∈{0,1}, xikm=0,m=0 表示任务在本地执行任务,xikm=1,m≥1 表示任务卸载至边缘节点。本文假设用户的计算任务是不可分割的,即只能在一个节点上执行。
整个任务卸载及资源分配过程可以分成5个步骤。
(1)用户用训练好的最优迁移策略选择将任务本地执行或卸载至边缘节点进行处理。如果选择边缘卸载,则加入对应节点的拍卖备选队列。
(2)根据边缘节点的资源容量、用户的资源需求情况和报价来选择拍卖获胜的用户,拍卖成功的任务准备卸载,拍卖失败的任务对出价进行调整并重新进入第一步。
(3)基站为用户任务分配相应的带宽资源,任务通过无线接入网络或者蜂窝移动网络上传至边缘节点,等待边缘服务器计算资源空闲时进行执行。
(4)边缘服务器分配相应的计算资源用于处理任务。
(5)任务执行完成,用户按定价规则支付费用,边缘节点将执行结果返回给用户,释放任务占用的资源。
上述步骤主要解决两个问题:
(1)用户侧的卸载决策阶段:结合任务在本地运行和计算卸载的时间消耗和能量消耗来共同决策该任务是否需要卸载执行以及倾向于卸载到哪个边缘节点。
(2)边缘侧的资源分配阶段:当任务需要卸载执行时,通过改进拍卖算法对任务进行调度,在合适的边缘节点上执行任务,以实现边缘节点的利益最大化。
在MEC 系统中,计算卸载包括将该计算任务传输到该网络边缘的通信过程和执行该任务的计算过程。为了完成计算任务,用户同时需要通信资源和计算资源。当终端所需的两种资源都得到满足时,用户和边缘节点之间可以成功地达成一次拍卖交易。
1.2 通信模型
用户选择将任务卸载至边缘服务器时,需要考虑任务数据上传带来的传输时延。假设多用户干扰已通过正交频分复用技术消除。每个用户迁移到不同的边缘节点有不同的上下行链路速率,任务ik迁移到边缘节点的上行链路速率如下所示:
其中,Bj表示边缘节点j的基站带宽;pk表示用户k上传数据的传输功率;gk表示用户k在无线信道中的信道增益;N0表示高斯白噪声功率谱密度;λik j表示边缘节点j分配给用户k的任务ik的带宽占比。
则在迁移计算中用户上传计算任务ik到边缘节点j的传输延迟可表示为:
根据传输延迟,得到相应的传输能耗:
由于计算结果的大小远小于输入任务的大小,因此忽略下行链路传输延迟和能耗[19]。
1.3 计算模型
(1)本地执行
任务采用本地计算执行时,本地执行延迟与本地CPU的处理能力有关。因此任务的本地计算延迟为:
其中,βik表示本地用户分配给任务ik的CPU 资源占比;f l k表示用户的本地计算能力。则任务ik在本地计算时产生的能耗为:
其中,表示本地用户k的计算功率。
(2)边缘节点执行
如果用户选择将任务卸载至边缘节点,当数据传输到边缘节点后,利用边缘服务器分配的CPU 资源来进行计算,可以得到用户任务ik在边缘节点j上的计算时间为:
其中,βik j表示边缘节点j分配给用户任务ik的计算资源占比,fej表示边缘节点j的计算能力。
另外,任务时延还包括队列等待时延,定义为。包括任务等待传输的时延和等待执行的时延,由动态变化的信道和计算资源情况决定。在本文中,使用SimPy模拟任务的处理流程和队列模型,根据任务生成时间和结束时间计算出等待时延。
结合式(2)和(6),可以得到用户任务ik迁移到边缘节点j的执行过程总延迟为:
基于此得到任务ik迁移到边缘节点ik过程中,用户k本地的等待能耗为:
其中,为用户k在等待状态过程中设备的闲置功率。结合式(3)和(8),可以得到,任务ik迁移至边缘节点j过程中用户端消耗的总能耗为:
1.4 优化问题描述
通过联合设计卸载决策、资源拍卖机制、带宽和计算资源分配策略,最大化系统的计算能效,同时优化边缘节点的效益。优化过程分为两部分,在卸载决策阶段,优化目标是选择最优策略以最大化总计算比特数与能量消耗的比值;在拍卖阶段,优化目标是最大化边缘节点拍卖资源所得效益。本部分将给出系统计算能效和边缘节点效益的具体量化,并建立优化问题。
(1)系统计算能效
计算能效是评估资源分配方案的一种性能指标,定义为计算比特数与能量消耗的比值[16]。假设系统持续时间内用户k在本地完成的任务列表为,在边缘服务器j完成的任务列表为,系统中完成的总计算比特数为:
系统中用户总能耗为:
系统计算能效为:
(2)边缘节点效益
为了量化边缘节点的收益,本节引入拍卖理论将系统模型构建为一个多轮拍卖问题[20]。拍卖机制有四要素,包括买家、卖家、拍卖商及商品。拍卖商由所有买家和卖家共同信任的第三方担任,决定资源分配规则和支付规则,以保障拍卖的公平进行。在本文中,云层作为拍卖商,从用户设备收集资源需求和边缘服务器的资源使用情况,通过专用的控制通道进行资源分配决策。
在拍卖机制中,出价是一个用户对任务所请求资源的估值,是愿意支付的最高价格,意味着对资源的偏好程度。常见的用户出价策略包括根据终端的性能改进、用户任务在边缘节点执行得到的收益来估计资源价值。具体的评价指标包括减少的能耗值、降低的响应时延、提升的服务质量等。边缘节点对单位资源的要价与其持有资源决定。要价代表边缘节点执行计算任务所要求的最低报酬。要价不能低于运行成本,运行成本包括单位计算成本、单位通信成本和额外成本等。本文假设用户任务的原始出价和边缘节点的要价均匀分布在一定数值范围内。
在拍卖阶段,用户作为买家向第三方拍卖商提供出价,边缘节点作为卖家给出要价,由拍卖商来确定获胜的用户任务和最终的交易价格。拍卖商代理被部署在拥有大量计算能力的云计算中心上,可以快速促成买卖双方之间的交易[21]。
用户为其产生的任务向边缘节点请求不同数目的CPU计算资源和通信资源,且用户对紧迫程度不同的任务有不同的出价策略。用户提交真实需求及出价,任务请求的资源数即边缘节点分配的资源数,任务的传输与执行时延由获取的资源数确定。将用户任务ik的出价与请求向量表示为,其中表示单位通信资源的出价,表示单位计算资源的出价,表示任务ik单位时隙请求的带宽资源,表示任务ik单位时隙请求的计算资源量。出价是用户对任务所请求资源的估值,是愿意支付的最高价格。
边缘节点根据自身资源数量、成本等因素制定价格策略。用pj来表示边缘节点j的基础要价,即边缘节点可接受的最低价格。其中表示边缘节点的单位带宽资源要价,表示边缘节点的单位计算资源要价。
用拍卖补偿策略不断调整任务出价,具体设计在下文中详述。定义用户任务ik与边缘节点j最终成交的价格为uik j,uik j=0 时表示两者之间未产生交易。当任务执行完成时,用户向边缘节点支付最终成交价格,用户效益可表示为:
边缘节点的总效益Uj定义为通过拍卖机制获得的总收入与相应资源所需的基础要价之差:
本文只考虑最大化边缘节点的效益。对用户效益,仅保证其非负性,使拍卖能满足个体理性。
(3)优化问题建立
具体优化问题构建如下:
上述优化问题中,目标函数即为最大化系统计算能效Us和边缘节点拍卖效益Uj。式(16)表示无论任务选择本地计算还是边缘节点计算,其时延不能大于任务最大容忍时延。式(17)表示在某个时隙中,边缘节点分配给各任务的计算资源βik j的总和不能超过其计算能力。式(18)表示时隙中,边缘节点分配给各任务的带宽资源λik j的总和不能超过其带宽资源。式(19)表示任务卸载决策变量xikm的取值只能为0或为1。式(20)表示每个任务只能选择一个边缘节点进行处理。式(21)表示用户效益Uk需满足非负性,即用户的最终成交价格不能高于用户的出价。
2 任务卸载与资源分配方案设计
本文将任务处理过程分为计算卸载和资源拍卖两个阶段。在计算卸载决策阶段,将问题建模为MDP 模型,详细定义模型中的元素,并设计一种基于DRL的在线卸载决策算法,及时做出最优决策。在拍卖阶段,设计了一种资源分配与定价机制,用于处理用户的异构资源请求,激励边缘节点提供服务。
2.1 任务卸载算法设计
任务到达后,用户将根据边缘节点信道负载情况、等待传输队列、等待执行队列以及任务需求,选择节点开始迁移,其目标是最大化系统总计算比特数与总能耗的比值。深度强化学习可以充分拟合最优策略、适应复杂环境,是一种解决高维问题的有效方法。基于此,本文采用DQN 及它的两种改进Double DQN 和Dueling DQN来训练策略。
(1)马尔可夫模型
本部分将公式化的问题转化为一个有限时间范围内的马尔可夫决策过程。MDP由一个五元组(S,A,P,R,γ)组成,其中S表示状态空间,A表示动作空间,P表示状态转移概率,R表示奖励函数,γ是折扣因子,γ∈[0,1]用于调整短期和长期奖励对智能体的影响。具体描述如下:
在每个时隙t开始时,部署在用户端的智能体将收集当前局部环境的信息。状态空间包括系统中每个边缘节点的信道资源占用率信道中正在传输的任务数量及剩余传输时间,计算资源占用率正在计算的任务数量及剩余执行时间,任务的特征信息。状态空间定义为:
根据观察到的环境状态,智能体根据策略π 做出任务卸载决策。用一个长度为J+1的序列{xik0,xik1,…,xik J}表示卸载决策。动作空间定义为:
一旦根据观察到的状态s(t)采取了动作a(t),智能体即可获得奖励r(t)并进入下一个状态s(t+1)。在训练阶段,智能体根据获得的奖励迭代策略π,直到收敛。奖励函数通常与优化目标相关,因此,将奖励函数定义为此任务比特数与能耗的比值:
考虑到任务的时延要求,当任务耗时超过其最大容忍时延时,视为任务失败,用户将获得惩罚。惩罚定义为当前奖励绝对值的负值:
(2)基于DQN的任务卸载算法设计
深度强化学习的核心思想是通过基于系统状态观察的奖励来指导智能体行动。DQN将智能体在环境中的动作、观测、奖励作为一个序列。在每个时间间隔,智能体从动作空间中选择一个可用动作。该动作会使得环境发生改变,从而根据环境的变化来获得奖惩。DQN研究动作和观测序列,并通过该序列学习某种策略。
DQN 用神经网络Q(s,a,ω)来近似动作价值函数,其中,ω表示神经网络的参数。某时刻t,智能体观察到环境状态s(t),根据策略选择一种动作a(t)进行执行。本文使用Epsilon-Greedy 算法作为动作选择的策略,即确定一个正数ε(ε <1)作为随机选择动作的概率,剩下1-ε的概率选择Q(s,a,ω)中得到的价值最大的动作。
在环境中执行动作a(t),获得新的状态s(t+1)、奖励r(t) 。如果将观察到的状态转移序列{s(t),a(t),r(t),s(t+1)}按照时间顺序输入神经网络,则训练结果会受到邻近的序列的影响,这种相似性导致神经网络收敛到一个局部最优解。采用经验回放方法解决这一问题,将这些序列存储在经验池中,每次训练随机抽取一小批(W个)样本,计算目标价值为:
其中,γ的取值范围为(0,1],用于调节未来奖励对当前状态的影响。γ越大,智能体做决策时会考虑得越长远,但训练难度也越高。
使用L2 均方误差损失函数来计算Q(s,a;ω)与yt之间的差距,损失函数定义为:
用梯度下降法更新神经网络参数,降低损失函数值,提高神经网络拟合动作价值函数的精度。参数更新速度由学习率α控制。算法的具体流程如算法1所示。
算法1基于DQN的任务卸载算法

(3)Double DQN
在DQN 中,训练是为了使神经网络Q(s,a;ω)尽可能地接近目标价值yt,而在yt中使用到了神经网络在t+1 时刻的估计值,用估算来更新同类的估算会导致自举。同时,在yt中计算最大动作价值会导致对动作真实Q 值的高估,自举会将这一高估回传给神经网络,使得高估越来越严重。不同状态下动作出现的概率是不均匀的,神经网络对概率高的动作会进行更频繁的估值更新,产生失衡的高估并影响正确决策。
Double DQN 通过将选择动作和评估动作分割开来避免过高估计的问题。具体而言,增加一个target 网络用于估计动作的价值,用原来的神经网络选择最优动作,即yt变为:
(4)Dueling DQN
Dueling DQN 算法从网络结构上改进了DQN。其前半部分与原始DQN一致,在输出处,Dueling DQN将输出映射到两个全连接层值函数V(s;ωv) 和势函数A(s,a;ωA),分别用于评估状态价值和动作优势,其中ωV和ωA是两个全连接层网络的参数。最后,Dueling DQN 通过合并两个全连接层得到最终的Q值输出,如式所示:
状态价值函数V(s;ωv)等于在该状态下所有可能动作所对应的动作值乘以采取该动作的概率的和。优势函数A(s,a;ωA)是当前动作价值相对于平均价值的优势大小,如果优势大于零,则说明该动作比平均动作好,比平均动作好的动作将会有更大的输出,从而加速网络收敛过程。
直接使用式计算Q值会出现可识别性问题,即给定一个Q值,无法得到唯一的V和A,使得模型的性能变差。因此,Dueling DQN强制优势函数估计量在选定的动作处没有任何优势,得到式(30):
使用优势函数的平均值代替上述的最大化操作,可以提升网络稳定性,最终得到式(31):
2.2 资源拍卖方案设计
拍卖算法本质上是各个拍卖参与者根据自身利益,依次对商品进行报价,通过多个轮次的竞标,最终得到相对满意的商品。基于拍卖的算法机制,将任务分配过程定义为动态拍卖过程。通过用户任务与边缘节点的动态拍卖过程,实现用户任务的合理化分配。
本节设计了一种基于补偿策略的多轮迭代拍卖机制(compensation strategy-based multi-round iterative auction,CSMRⅠA),限定最大拍卖轮数为10,每一轮包含获胜者确定和定价两个步骤。在获胜者确定阶段,用户提交其任务的资源需求和出价,拍卖机制根据边缘节点要价、用户任务的资源需求情况和出价来确定获胜的用户,使边缘节点与用户任务形成匹配。在定价阶段,确定获胜用户最终应为其任务支付的价格。
实现拍卖方案,需要先分别设计用户的出价策略和边缘节点的要价策略。
(1)用户出价策略
假设用户任务的原始出价均匀分布在一定数值范围内。考虑到时延敏感的任务在单位时隙内占有的通信资源与计算资源量更多,需要提交更高的单位资源价格来赢得拍卖并优先执行;同时为防止用户请求不真实的资源,本文将任务原始出价与用户资源占有量、的乘积作为首轮拍卖的出价、。
如果用户任务在某一轮拍卖中失败,用户将采用补偿因子调整当前出价[22],本文将补偿因子定义为η=Sum指的是系统允许的最大拍卖总轮数,Numik是任务在此次报价之前拍卖失败的次数。随着任务失败次数的增加,补偿因子增大,任务会以更快的速度提高出价。
(2)边缘节点报价策略
边缘节点对单位带宽资源和单位计算资源的要价与其持有资源决定。持有更多资源的边缘节点适当降低报价以提升在拍卖中的竞争力,获得更多的任务,提高自身资源利用率。
(3)具体流程
基于出价及报价策略,参考文献[23],设计一种多轮迭代拍卖算法。
经过计算卸载决策阶段,拍卖商按照用户的决策,将任务加入其所选边缘节点j的拍卖备选队列Qj,j∈{1,2,…,J}。在每一轮拍卖中,用户向拍卖商提交任务的资源需求及出价向量,边缘节点向拍卖商提交基础要价pj。本文的拍卖涉及两种资源,将每个卖/买家看作是两个虚拟卖/买家,而每个虚拟卖/买家提供/请求单一的通信或者计算资源[24]。以通信资源的拍卖为例,在获胜者确定阶段,拍卖商将边缘节点的拍卖队列中的任务按其出价降序排序,将降序出价队列表示为。拍卖商执行一种贪婪策略,即每轮拍卖遍历,比较任务出价和边缘节点要价,如果用户任务ik对于通信资源的出价高于边缘节点ik对应资源的要价,同时边缘节点的剩余资源大于任务请求的单位时隙通信资源,视为任务请求节点的通信资源成功,加入获胜队列,反之视为两者拍卖失败。如果在某一轮拍卖中,任务与所选边缘节点匹配失败,用户将调整任务的出价并重新进入卸载决策阶段。在定价阶段,任务的最终出价应独立于其自身出价。用户任务在降序出价队列中的序号用l表示,根据第二价格密封拍卖规则,假设任务在边缘节点j某轮拍卖中获胜,则其最终应支付给边缘节点的单位通信资源价格,是位于其后的任务出价和节点要价之间的较高值,即。边缘节点对通信资源的获胜用户进行计算资源的拍卖,过程与通信资源类似。两种资源都拍卖成功视为用户与节点匹配成功,最终成交价格。以通信资源的拍卖为例,算法的具体流程如算法2所示。
算法2基于补偿策略的多轮迭代资源拍卖算法
输入:边缘节点拍卖备选列表Oj,用户任务的资源需求及出价向量bik,i∈{1,2,…,I},k∈{1,2,…,K},边缘节点的基础要价pj,j∈{1,2,…,J}
输出:用户任务与边缘节点j最终单位资源价格

3 仿真分析
3.1 实验设置
本节通过仿真测试来评估所提出的任务卸载与资源分配算法的性能。系统包括1 个云服务器、4 个边缘节点和K个配电网终端,用户随机分布在200 m×200 m的区域内。系统时间步长τ设置为10 ms,每一次仿真持续3 000 个时间步长。在不同用户数量的情况下,通过调整系统任务到达率,使每个用户在系统持续时间中生成100 个左右的任务。实验中设定资源占有量超过0.9 时为负载过重,不再执行新需求。实验中的主要参数设置见表1。

表1 实验参数Table 1 Experimental parameters
本文的神经网络由一个输入层、一个输出层和两个隐藏层组成。隐藏层的神经元数量为20。采用ReLU作为激活函数,使用Adam 进行优化,优化学习率为0.001。经验池大小为2 000,每次训练批处理大小为32,网络参数每200次迭代进行一次替换。折扣因子设为0.9,探索概率设为0.1。
为了验证本文基于DQN的卸载算法结合CSMRⅠA拍卖的DQN-CSMRⅠA 方案效果,与以下三种方案进行对比实验:(1)随机卸载(random,RAN)-固定补偿因子η的多轮迭代拍卖(fixed compensation factor multiround iterative auction,FCFMRⅠA),即RAN-FCFMRⅠA方案;(2)RAN-CSMRⅠA 方案;(3)DQN-FCFMRⅠA 方案。图2~图5主要验证所提算法的在计算卸载方面的性能,图6~图8主要验证所提算法在资源分配方面的性能。
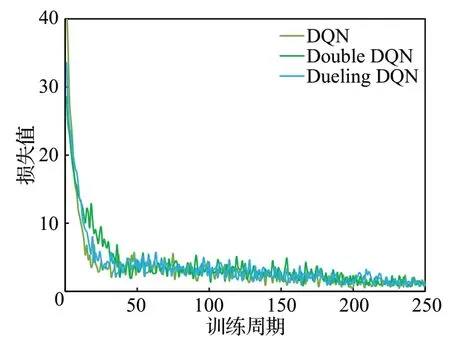
图2 DQN卸载算法的收敛性Fig.2 Convergence of DQN offloading algorithm
3.2 仿真结果
图2 显示了基于DQN、Double DQN、Dueling DQN的三种任务卸载算法的收敛性能。三种算法在40轮左右的迭代之后,收敛到一个相对稳定的值,说明智能体学习到了最优策略。
图3显示了用户数量不同的情况下,使用随机卸载方案和基于DQN、Double DQN、Dueling DQN 的任务卸载算法时的系统平均计算能效。可以发现,随机卸载方案下的系统能效一直保持较低的水平,而基于DQN及其改进算法能大幅提高系统能效,其中基于Dueling DQN的卸载算法效果最佳。在用户数为30时,Dueling DQN、Double DQN 和DQN 算法下的系统计算能效分别比随机方案下的系统计算能效高出88.6%、80.2%、80.1%。这是因为智能体通过观测当前时隙各节点的负载情况和任务需求,能做出更优越的决策,实现节点之间的负载平衡,减少队列拥塞,减少任务的排队等待时延和能耗,保证任务的成功率,从而提高系统的计算能效。随着用户数量增多,几种卸载方案下的系统计算能效均出现下降。这种下降趋势是因为任务数量持续增多时,资源竞争情况变得激烈,边缘节点的通信和计算能力到达了瓶颈,计算性能变差。

图3 不同用户数量下的系统计算能效Fig.3 System computing energy efficiency with different number of users
图4 显示了用户数为50,任务数据大小分布不同、其他特征参数分布情况一致的情况下,四种卸载方案的系统计算能效的变化。一开始,随着任务数据大小增加,各节点在相同的时间步长中计算比特数更多,虽然通信时延和能耗也随之增加,但是任务总能耗的其他部分变化较小,因此总的计算能效仍有一定幅度的提高。随着数据大小进一步增大到4 Mbit及以上,计算能效出现回落。这是因为系统的信道资源开始紧缺,任务需要等待较长时间才能分配到资源,甚至会因为超时导致任务失败。另外,基于DQN 及其改进算法的卸载方案下的计算能效总是优于随机卸载方案下的计算能效,其中基于Dueling DQN 算法的卸载算法在大部分情况下略优于其他两种深度强化学习算法。任务数据大小均匀分布在3 Mbit 时,Dueling DQN、Double DQN 和DQN算法下的系统计算能效分别比随机方案下的系统计算能效高出36.2%、35.3%、34.0%。

图4 不同数据大小下的计算能效Fig.4 System computing energy efficiency with different data sizes
图5 显示了系统在不同用户数量及不同卸载方案下的任务失败率。当用户数量小于30 时,四种方案的任务失败率都较低。在这一阶段,边缘节点的资源充足,可以满足用户任务的时延需求。随着用户数量持续增加,任务请求的资源超过了边缘节点的通信、计算能力,四种方案的任务失败率都有所增长。在边缘资源紧张时,相较于随机卸载,基于DQN及其改进算法的三种卸载方案失败率增长较为迅速,这是因为用户决策对彼此产生了干扰。

图5 不同用户数量下的任务失败率Fig.5 Task failure rate under different number of users
图6显示了本文所提DQN-CSMRⅠA方案与三种对比方案在不同用户数量情况下的效益。从图中可以看出,无论是结合基于DQN的卸载还是随机卸载,本文所提的CSMRⅠA 方案的节点收益均优于FCFMRⅠA 方案。当用户数小于45时,随着用户数量增加,边缘节点能服务于更多任务,四种方案的效益都随之增长。用户数等于45 时,DQN-CSMRⅠA 比RAN-FCFMRⅠA 方案的效益高出13.7%,RAN-CSMRⅠA 比RAN-FCFMRⅠA 方案的效益高出7.0%。而当用户数超过45,边缘节点资源有限,能服务的任务数已经趋于饱和,采用CSMRⅠA方案的节点效益增长趋于平缓,而采用FCFMRⅠA 方案的节点效益开始减少。这是因为大量用户抢占资源导致任务失败率变高,FCFMRⅠA 不能克服资源竞争带来的负面影响,而CSMRⅠA中用户通过动态调整出价提升竞争力,以优先获取任务所需的资源,能有效增加边缘节点的效益。

图6 不同用户数量下的卸载-拍卖方案效益对比Fig.6 Benefit comparison of offloading-auction schemes with different numbers of users
图7、图8分别显示了本文所提DQN-CSMRⅠA方案与三种对比方案在不同用户数量情况下的通信、计算资源利用率对比。两种多轮迭代拍卖方案的资源利用率总体较为接近;基于DQN的方案与随机卸载相比,能使资源得到更高效的利用。除此之外,在CSMRⅠA 方案中,用户会为时延更敏感的任务支付更高的价格来抢占资源、避免过长的等待延迟,这种出价策略能增加这类高时延要求的任务的优先级,提高用户的满意度。

图7 通信资源利用率Fig.7 Communication resource utilization rate

图8 计算资源利用率Fig.8 Computing resource utilization rate
4 结束语
本文针对配电网中任务卸载决策和边缘计算资源、带宽资源分配的联合优化问题,在任务卸载方面,提出基于DQN及两种改进Double DQN和Dueling DQN方法的任务卸载算法,评估节点资源利用和负载情况,在动态变化的环境中快速得到最优卸载决策,以实现系统计算能效的最大化;在资源分配方面,提出一种基于多轮迭代拍卖的资源分配算法,使资源受限的边缘节点选择性地为用户提供服务,获取最大利益。通过仿真验证了任务卸载算法的收敛性,并从系统计算能效、任务失败率、边缘节点效益、通信资源/计算资源利用率的多个评价指标,将DQN-CSMRⅠA 卸载-拍卖方案与RANCSMRⅠA、Dueling DQN-CSMRⅠA、Double DQN-CSMRⅠA三种方案作对比,证实了所提算法可有效提高计算能效和边缘节点效益。在未来的研究工作中,将考虑用户的数据敏感性和隐私保护的问题,研究更具安全性的资源分配方案。
猜你喜欢
科学技术创新(2021年18期)2021-06-23
英语文摘(2020年10期)2020-11-26
印刷工业(2020年5期)2020-03-29
微型电脑应用(2019年10期)2019-10-23
测控技术(2018年7期)2018-12-09
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
流程工业(2017年4期)2017-06-21
计算机应用(2016年10期)2017-05-12
自动化博览(2014年6期)2014-02-28
