
基于模型聚合的去中心化拜占庭鲁棒算法
2024-03-12 12:48卢朕李建业董云泉
浙江大学学报(工学版) 2024年3期
卢朕,李建业,董云泉
(南京信息工程大学 电子与信息工程学院,江苏 南京 210044)
近年来,随着5G网络的高速发展以及物联网技术的广泛应用,移动设备的便携化和智能化已经是大势所趋,使用机器学习对移动设备的用户数据进行处理可提高应用程序的智能化,方便人们的日常工作与生活.然而,传统的机器学习算法需要中央服务器对用户数据进行集中处理,不仅会耗费大量通信资源,而且存在数据泄露风险,使用户隐私安全产生隐患.联邦学习(federated learning,FL)作为旨在提高通信效率和隐私性的新兴机器学习范式,可以让资源受限和地理分散的设备,利用本地数据合作训练全局模型,同时避免直接交换用户数据.其中最经典的算法是联邦平均(FedAvg)算法[1],在中央服务器上重复聚合用户的本地训练模型来生成性能优秀的全局模型.在联邦学习中,用户数据的处理和分析只在设备终端进行,终端用户传递的信息(本地梯度或者本地迭代值)使得窃听方即使获得传递的信息也不可能立刻推断出用户数据,以保护用户隐私.
传统的集中式联邦学习[1-2]虽然提高了数据隐私和通信效率,但存在扩展性差、带宽高、单点故障等问题.此外,新一代通信网络采用去中心化的无基础设施通信方案和设备到设备的多跳链接技术以提高通信能力[3].为了解决上述困境,去中心化的联邦学习[4-7]被提出,然而由于联邦学习数据存储的特殊性以及对通信效率的考虑,许多分布式机器学习方法并不适用于去中心化联邦学习.同时,联邦学习由于其分布式机器学习的本质,在面对对手攻击时更加脆弱.拜占庭攻击[8]是联邦学习面临的一种最常见的威胁,亟须设计一种“可证”为安全的拜占庭鲁棒算法.在传统联邦学习中,通常假设所有参与联邦训练的终端都是“诚实”的,即所有传递给中央服务器的消息都是真实可靠的.然而,在实际情况中上述假设并不成立,某些终端可能因为网络环境或者被恶意程序操控而发送错误信息.
在集中式联邦学习领域中,有关拜占庭鲁棒的分布式优化研究,已经取得了一系列成果[9].拜占庭节点传递给中央服务器的恶意信息通常“远离”真实信息,因此中央服务器可以借助安全聚合机制来聚合真实的信息,减少错误信息对联邦学习的影响.利用安全聚合机制,诞生了许多拜占庭容错梯度聚合算法[10-14],但这些算法都需要中央服务器对候选节点上传的梯度统计信息进行处理且计算复杂度较高,难以取得实际应用.Tahmasebian等[15]结合真值推理方法和历史统计数据来估计每个客户端的可靠性,提出基于客户端可靠性的鲁棒聚合算法.Xie等[16]提出的完全异步算法借助验证数据集,利用中央服务器对候选梯度进行打分,挑选诚实梯度.然而,在去中心化联邦学习中,无法使用中央服务器来过滤恶意信息并聚合真实信息.So等[17]提出BREA联邦学习框架,集成随机量化、可验证的异常值检测和安全模型聚合方法,保证框架的拜占庭弹性、隐私和收敛性.Wang等[18]提出点对点算法P2PKSMOTE,共享参与FL的不同客户端的合成数据样本,并用于训练异构场景下的异常检测机器学习模型.受Kang等[19]的基于声誉和区块链的可靠用户选择方案启发,Gholami等[20]提出基于Trust度量的数学架构来衡量代理用户的信任度,提高去中心化联邦学习的安全性.同样,Zhao等[21]使用区块链代替中央服务器聚合局部模型更新,并利用区块链上的记录不可篡改和可以追溯的优势,保障用户隐私安全.Lu等[22]将本地模型存储在用户子集,实现了物联网场景下的去中心化异步联邦学习,并采用深度强化学习(deep reinforcement learning,DRL)进行节点选择,以提高效率.然而,法律法规和能源消耗及其他因素限制了区块链技术的实际应用.
针对以上问题,本研究探讨在去中心化联邦学习中如何应对拜占庭用户的问题.在一个去中心化网络中,拜占庭用户数量未知,攻击方式不明,通过先发送后验证的策略和SCORE函数,来评估未知属性用户的属性.同时,利用得分函数的结果来进行阈值划分以降低用户属性分类的错误率,提高计算资源的利用率.
1 系统模型
1.1 网络模型
考虑在N个代理用户(节点)组成的网络上执行联邦学习任务,其中恶意节点数量未知.在此去中心网络中,无中央服务器且每个用户i只能与它们的通信范围内的多个邻居节点逐次相互通信.所有用户可被编号以记为一个集合V,V={1,···,N}.这个网络可以被建模为有向图G(V,E),其中V为网络中节点的集合,E为网络中边的集合,E⊆{(i,r)∈V×V|i≠r}.同时,每个代理用户i拥有自身 的数据 集Di,|Di| 表示用户数据集的大 小.训练所用数据样本总数为其中第d个样本为为输入模型的样本数据而为对应于输入样本的标签.假设由代理用户i采集的数据样本点的索引集为pi,基于上述条件,可以利用本地采样数据集zi={(xd,yd),d∈pi} 训练由θi参数化 的代理用户i的本地模型Mi,如图1所示.

图1 去中心化网络模型Fig.1 Decentralized network model
1.2 联邦学习模型
在集中式联邦学习中,通过在中央服务器上优化目标函数,寻找解决推断问题的全局模型,这个模型把输入的样本数据向量x映射到输出为输出结果维数.在去中心化联邦学习中,每个用户不仅拥有各自的数据集,而且还共享一个由 θ 参数化的有着固定架构的机器学习全局模型.这个全局模型的目标是解决如下经验风险最小化问题:
式中:fi(θ) 为用户i的本地经验风险函数,l(θ;zi) 为参数 θ 在数据样本zi上的经验损失.
1.3 拜占庭攻击模型
对于固定用户网络上的去中心化联邦学习,它的模型聚合路线是既定的.未经身份认证的恶意节点可能发起拜占庭攻击,它试图在未训练模型的情况下发送本地模型,从而改变模型聚合路线,影响用户对模型聚合路线的共识,最终导致全局模型的实际训练过程偏离正确方向,进而影响全局模型的评估能力[23].在一个固定用户网络上的去中心化网络中,在无拜占庭节点时,拟定一条联邦学习模型训练和传输的路线:1→2→3→···→20,如图2所示,每个节点利用私有数据集对接收到的模型参数进行本地训练,并将模型参数发送给下一个节点来协作完成联邦学习任务.所使用的环状聚合路线,不仅拥有低能耗、延迟低、简单易实现等优点,而且相较于广播形式,此种方式能够降低诚实用户“暴露”给恶意用户的风险.
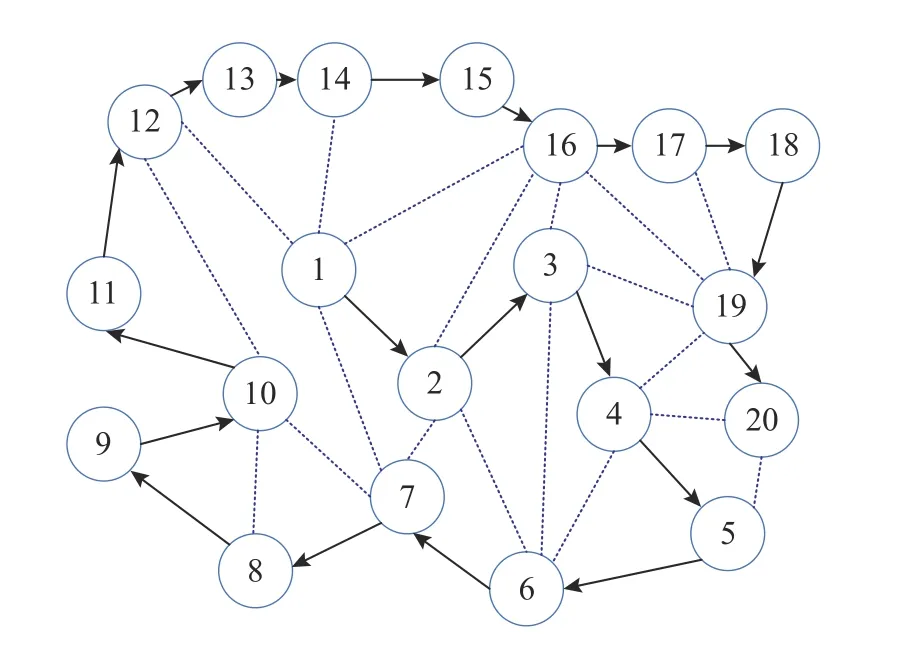
图2 去中心化联邦学习中的模型聚合路线Fig.2 Model aggregation route in decentralized federated learning
当此去中心化网络中存在拜占庭节点时,如图3所示,假设节点7为恶意节点执行拜占庭攻击,节点2并未对节点7的属性进行验证,恶意节点7接收到节点2发送的模型信息后,发送任意模型信息给节点10,同时谎称发送的聚合模型来源于诚实节点9.对于节点10,同样缺乏对节点属性的验证手段,无法判断源于节点7的信息是否符合模型聚合的要求.恶意节点7的拜占庭攻击不仅会改变模型聚合路线,忽略节点3~6的本地训练模型,而且其发送的任意信息,会使全局模型的训练受到恶劣影响.在更严重的情形下,模型更新的聚合路线陷入一个死循环,如图3中的1→2→7→1,模型将只会在这些局部节点训练,使得全局模型发散或者收敛到局部最优处,导致联邦学习失败.

图3 拜占庭攻击下的模型聚合路线Fig.3 Model aggregation route under Byzantine attack
1.4 拜占庭攻击方式
代理用户使用随机梯度下降(stochastic gradient descent,SGD)和先发送后验证的方法在用户的数据集上优化损失函数以训练本地模型.在第t轮全局训练时,用户i将本地模型参数m(t,i)传递给它们的下一跳邻居用户i+1.如果用户i为诚实用户,其传递的模型参数是真实的,即m(t,i)=θ(t,i).然而,恶意用户传递的信息并不是在其本地数据集上运行SGD计算所得到的结果而是任意信息g(t,i).根据文献[8]中的定义,其表达式如下:
下一跳的用户在收到上一跳用户发来的信息后,在本地数据集上执行SGD,并重复以上过程寻找最优全局模型参数 θ*=argminθF(θ).
考虑符号翻转(sign-flipping attack)攻击、常数向量攻击(same-value attack)、高斯噪声攻击(Gaussian-noise attack)和标签反转攻击(labelflipping attack).在符号翻转攻击中,拜占庭节点翻转发送给其他节点的信息(本地梯度或者本地迭代值)的正负号,并且增大其幅度,即g(t,i)=σ×其中σ 为负数.其目的是使得变量往正梯度方向变化,从而使得目标函数增大,破坏训练过程[24].在常数向量攻击中,拜占庭节点发送给其他节点的信息是由常数向量构成的,即g(t,i)=c×1,其中1 ∈Rd为每一维都为1的向量,c为常数.其目标是发送相同的虚假消息来误导其他节点,让它们做出错误的决策.在高斯噪声攻击中,拜占庭节点发送给其他节点的信息被高斯噪声“污染”,即其中n为服从某种高斯分布的随机扰动.在标签反转攻击中,拜占庭节点并未对发送给其他节点的信息进行修改,而仅对本地训练数据的特定类别的标签进行修改,然后再进行训练.尽管这种攻击方式只对数据进行投毒,攻击性较弱,但是它通用性较强,并且攻击方式简单,仅须对特定的数据标签进行改变.
2 方法介绍
由于去中心化的联邦学习没有中央服务器的协助,并且普通的代理用户受限于计算、网络资源而无法处理大量信息,单个代理用户接收的受限信息无法相互比较、聚合.此时,基于集中式联邦学习的安全聚合算法无法适用于去中心化的情况.本研究所提出的可验证的去中心化FL算法利用SCORE函数来对未知节点的属性进行评判.
2.1 SCORE函数
在传统机器学习中,为了验证一个用户诚实与否,一个朴素的想法是:在此用户数据集上执行学习任务并通过任务的表现来判定该节点的属性.然而受制于联邦学习中的隐私设置,用户的个人数据是无法共享的.由Zeno++算法[16]启发,在由未知数量的拜占庭用户和诚实用户所构成的去中心化网络中进行联邦学习任务时,诚实用户可借助验证数据集和得分函数对下一未知属性用户传递给它的梯度信息进行“打分”,借此来实现分辨和排除拜占庭用户的目的.对于任意候选梯度g,利用模型参数 θ、学习率 γ 和常量 ρ (ρ>0),可以对SCORE函数进行定义:
式中:fd(θ) 为验证数据集上的经验风险函数,此得分函数可被定义为2部分.fd(θ)-fd(θ-γg) 为预估损失函数的梯度下降值,它在某种程度上反映了待验证节点的属性信息;-ρ‖g‖2为SCORE函数的惩罚项,它约束了模型参数的变化量.一个更大的损失函数的梯度下降值会导致更大的SCORE得分,也就意味着此节点更有可能是一个诚实节点;相反,当此节点为拜占庭节点时,会阻碍学习任务的进行,相应的SCORE得分较低.这为SCORE函数分辨拜占庭节点与诚实节点提供了理论支撑.
式 (3)会给部分节点带来较大的计算负担,在实际情况中,可以对式(3)中的fd(θ)-fd(θ-γg) 进行一阶泰勒公式展开和近似计算来减少计算开销,改进后的SCORE函数如下:
2.2 可验证的去中心化FL算法
所提出的基于模型聚合的去中心化拜占庭鲁棒算法的总体流程如下.此方法预置条件是去中心化网络起始必须是2个诚实节点,来初始化全局模型参数.
1)在第t轮全局迭代中,第i-2 和第i-1 节点均已是诚实节点且拥有验证数据集,算法目的是分辨第i节点是否为诚实节点.为此,第i-1 节点发送第i-2 节点的本地模型参数θ(t,i-2)给第i节点.然后,第i节点利用本地数据集和θ(t,i-2)来执行SGD,并将此过程中得到的梯度信息g回传给第i-1节点.
2)当第i-1 节点接收 到第i节点回传 的梯度信息g后,其将利用g在验证数据集上运行SGD,同时结合SCORE函数给出分数.如果存在常数ε使得SCORE函数的 结果满 足 SCOREγ,ρ(g,θ)≥-γε,则认为第i节点是诚实节点.
3)如果步骤2)判定第i节点是诚实节点,那么第i-1 节点将传递自己的本地模型参数θ(t,i-1)给第i节点,第i节点利用 θ(t,i-1)和本地数据集来执行SGD.
重复以上过程,直到最后得到的模型满足精度要求.
对于伪装成诚实节点的拜占庭节点,有如下考虑:如果一个待验证属性的用户做出诚实的回答,需要正确的数据集和准确、及时的模型参数.受制于去中心化联邦学习的设置,不可能对待验证属性的用户的本地数据集进行审查,同时各个参与联邦学习的用户是不可能同时获得模型参数信息并进行同步训练的,因此只有逐步向待验证属性的用户传递不准确和不及时的模型参数来进行学习.一个简单的方法就是向待验证属性的用户传递过时的模型参数来阻止拜占庭用户直接回传诚实的梯度进而伪装自身,这样做有2个优点:一是操作方便简单,不需要太过复杂的加密传递方式;二是增加了隐私性,即使拜占庭用户获得诚实的模型参数,其也不能取得与其直接通信的用户的相关隐私信息.此方法的缺点是需要节点耗费额外的内存和通信资源来储存和传递这些“过时”的模型参数信息.因此,本研究选择储存和传递上一个诚实用户的模型参数信息来降低存储、通信资源的代价.
在传统的机器学习中,通常用准确率和风险经验函数损失值来衡量模型的性能,但在本实验中仅仅通过这2个指标来评价模型是不充分的,因为在实际场景可能须对用户的诚实或恶意属性进行统计分析从而来激励或惩罚用户,因此需要其他的标准来评价模型.为此,本研究采用假阳(false positive,FP)和假阴(false negative,FN)分别表示被采用的信息是错误信息、被抛弃的信息是正确信息的概率.但是,在算法步骤2)中单独使用得分函数不足以分辨出恶意节点,因而有必要对得分函数中的预估损失函数的梯度下降值以及惩罚函数值进行阈值比较,以更加精准地分辨出恶意节点与诚实节点.修改后的算法流程如下.
输入:初始模型参数 θ、用户数据集、验证数据集、λt1,λt2,λt3,ρ,γ,ε 等超参数
3 收敛分析
对所提的可验证的去中心化FL算法分析其误差界限.首先,需要以下定义与假设.
定义1 光滑性.如果存在常数L>0 使本地目标函数f(x) 满足 L 光滑,那么 ∀v,w∈Rd,有
定义2 PL不等式.如果存在常数 µ>0 使得可微函数f(x) 满足Polyak-Lojasiewicz (PL)不等式[25],那么 ∀x∈Rd,有
式中:f*:=f(x*),x*=argminf(x).
假设1在整个学习过程中,F(x) 和fd(x) 的梯度均具有上限B1,并假设fd(x) 的梯度具有下限B2,即同时0 <B2≤B1.此外,假设训练数据集与验证数据集的损失函数的梯度的差值是受限的,即E[‖∇F(x)-
借由上述定义与假设,讨论本算法的收敛情况.
理论1假设经验损失函数F(x) 和验证数据集上的经验损失函数fd(x) 均是光滑函数且满足PL不等式,同时满足假设1.如果有常量 β>0,使得在经过T轮次的全局迭代后,有以下的误差界限:
证明如果第i用户回传的梯度信息g满足第i-1用户上的SCORE函数,即
SCORE(γ,ρ)≥-γε.根据SCORE函数的定义,此结果可以改写为
对fd(·) 进行泰勒公式展开和近似运算,可以得到
利用二范数性质、梯度受限假设和训练数据集与验证数据集的相似假设,可以得到
将式(10)结合光滑性和PL不等式,可以得到
通过迭代和计算整体期望,在经过T轮全局训练后,可以得到理论1.通过文献[26]中对正则化经验风险最小化优化算法的收敛速度的比较方法,本算法的第T轮全局迭代输出的模型 θ(T,N)与最优模型 θ*的对应的正则化经验风险的差值趋于0,所以本算法是收敛的.同时,在有界梯度假设下,本算法具有线性收敛速率,这与FedAvg算法[1]以及部分去中心化联邦学习优化算法[4-7]的收敛速率一致.误差界限中的超参数 ρ 在收敛速率和用户梯度取舍之间做出均衡,如果增大 ρ,可以加快算法收敛速度,但可能会抛弃更多的诚实梯度(用户).
4 数值验证
通过实验仿真对所提去中心化联邦学习算法的性能进行评估.在本实验中,假设去中心化网络中节点与节点之间的通信是理想且无损的.
4.1 实验设置
在本次实验中,总数据集为CIFAR-10[27]和MNIST[28],前者包含了60 000张3 2×32 像素的10个类别的自然彩色图片;后者包含了70 000张28×28像素的0~9数字的手写灰度图像.将总数据集中的样本按照类别和数量随机平均分配给所有的用户,即每个用户数据集都有10个类别的图片,且每类别的图片数量相等.同时,采用对所有的用户数据集样本进行随机采样的方式来构成一个适用于SCORE函数的验证数据集(在实际场景下,任务发布者无法接触到用户的个人数据,为此,可以通过社会实践、大数据调查以及一些不触犯用户隐私的方式来获取先验知识,或者直接从受信任的用户收集信息并添加噪声来构造验证数据集).
在一台装备了NVIDIA GeForce GTX 1 660 SUPER显卡的主机上,基于Mxnet[29]平台,利用卷积神经网络(convolutional neural networks,CNN)对算法进行实验仿真.此卷积神经网络包含4个卷积层和4个全连接层,并在卷积层之间嵌入Batch Norm层和Dropout层来防止神经网络的过拟合.在实验过程中,利用测试数据集上的准确率作为衡量模型性能的标准.同时,采用假阳率、假阴率来表示被采用的信息是错误信息、被抛弃的信息是正确信息的概率.
4.2 仿真结果
利用实验仿真来探究拜占庭用户的数量、拜占庭用户的攻击方式以及阈值划分方式对于可验证去中心化联邦学习算法性能的影响.
4.2.1 拜占庭用户的影响 比较在同样超参数设置和CIFAR-10数据集下,不同类型的拜占庭攻击方式和不同数量的拜占庭节点对于算法性能的影响.采用环形网络下的联邦学习作为对照算法,该算法不受拜占庭攻击的影响,记为“理想的去中心化FL”.
首先模拟一个拥有20个节点,其中5个节点执行符号反转攻击的去中心化网络,比较无恶意用户的情况、存在恶意用户但执行可验证的去中心化FL算法的情况和无任何拜占庭容错算法但存在恶意用户的情况下的性能.如图4所示为不同情况下,去中心化联邦学习在测试集上的准确率.图中,A为准确率,t为轮次.实验结果表明,去中心化网络在面对符号反转攻击时十分脆弱,去中心化联邦学习无法进行收敛,而利用所提出的拜占庭容错算法后,训练出的模型甚至可以媲美无攻击时环形网络上训练出的模型.

图4 25%的用户执行符号反转攻击时不同算法的准确率Fig.4 Accuracy of different algorithms for 25% of users performing sign-flipping attack
为了探究不同数量的拜占庭节点对可验证的去中心化FL算法的影响,将去中心化网络中恶意节点数量提高一倍,即有10个拜占庭节点,占节点总数的50%.比较图4、5,可以发现所提出的算法对于不同数量的拜占庭节点具有鲁棒性,尽管恶意节点的数量增加了,但经此算法训练出的全局模型还能保持良好的性能.
为了探究拜占庭节点的不同攻击方式对可验证的去中心化FL算法的影响,将去中心化网络中恶意节点实施的符号反转攻击更改为标签反转攻击,比较图5、6,发现此方法也可以针对不同类型的攻击方式进行防御.同时,根据图5、6中的无任何拜占庭容错算法但存在恶意用户的情况下的模型性能的比较,可以发现模型污染攻击(符号反转)比数据污染攻击(标签反转)更加直接且高效.
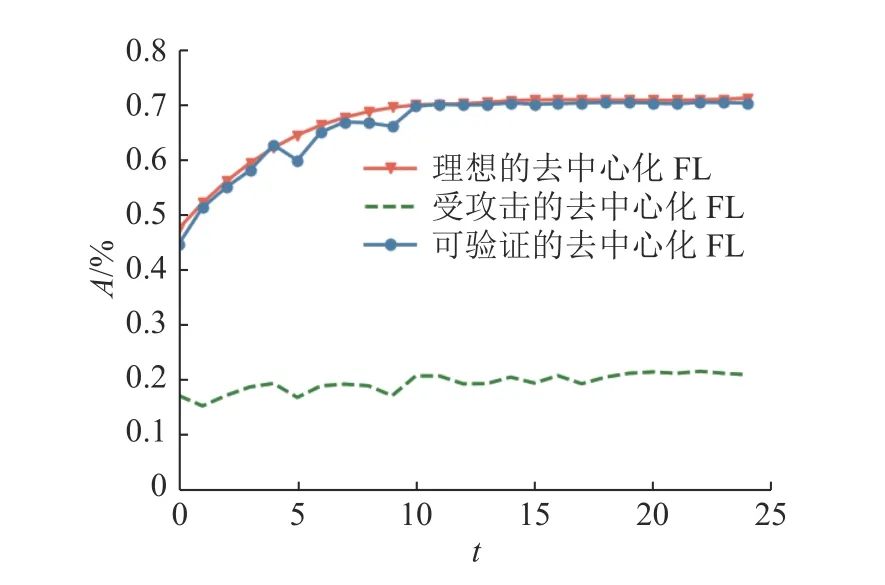
图5 50%的用户执行符号反转攻击时不同算法的准确率Fig.5 Accuracy of different algorithms for 50% of users performing sign-flipping attack

图6 50%的用户执行标签反转攻击时不同算法的准确率Fig.6 Accuracy of different algorithms for 50% of users performing label-flipping attack
4.2.2 阈值划分的影响 如图7所示为阈值划分对FP和FN的影响.可以看出,在相同的数据集和超参数设置下,带有阈值重划分的本研究算法在面对符号反转攻击和常数向量攻击时,可以有效降低无阈值重划分算法训练出的模型中的假阳和假阴概率.然而,由于阈值重划分针对的是SCORE函数中的预估梯度的下降值和梯度信息的惩罚值,无法对标签反转这类定向攻击的阈值进行精准划分,只能小幅减少标签反转的模型性能的假阳和假阴概率.

图7 阈值划分对假阳率和假阴率的影响Fig.7 Effect of threshold division on false positive and false negative
在相同的CNN、30%的恶意用户比例和同样的超参数设置下,将可验证的去中心化FL算法与一些经典或先进的鲁棒FL算法进行比较.如表1所示,展示了这些算法分别在CIFAR_10数据集和MNIST数据集上,面对高斯噪声攻击和标签反转攻击下的准确率.本研究提出的可验证的去中心化FL算法相较于现有的拜占庭容错FL算法,不仅对于不同的拜占庭攻击方式表现了更一致和更好的鲁棒性,并且更加贴近良性环境下的训练性能.

表1 CIFAR_10(MNIST)数据集上不同鲁棒算法的准确率Tab.1 Accuracy of different robust algorithms on CIFAR_10(MNIST) dataset
5 结语
针对抵抗拜占庭攻击的去中心化联邦学习,基于随机梯度下降算法(SGD)提出鲁棒梯度聚合方法.通过结合验证数据集和SCORE函数,有效提高了算法对于拜占庭攻击的鲁棒性.从理论上证明了所提算法的收敛性质,大量数值实验也说明可验证的去中心化FL算法能够确保:在存在未知数量和攻击方式的拜占庭用户的去中心化场景下,所训练的全局模型能够保持良好性能,并可以更准确地区分诚实节点与拜占庭节点.在未来的工作中,将进一步研究如何把去中心化联邦学习与无线传输相结合,以提高联邦学习的通信效率和隐私性.
猜你喜欢
数学物理学报(2021年6期)2021-12-21
家庭影院技术(2020年10期)2020-12-14
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03
应用数学(2020年2期)2020-06-24
家庭影院技术(2019年7期)2019-08-27
数学年刊A辑(中文版)(2018年2期)2019-01-08
中学历史教学(2018年1期)2018-04-04
古代文明(2016年1期)2016-10-21
凤凰生活(2016年2期)2016-02-01
河南科技(2014年3期)2014-02-27
