
基于GHM可视化和深度学习的恶意代码检测与分类
2024-03-12 09:21张淑慧胡长栋王连海徐淑奖
信息安全研究 2024年3期
张淑慧 胡长栋 王连海 徐淑奖 邵 蔚 兰 田
1(齐鲁工业大学(山东省科学院)山东省计算中心(国家超级计算济南中心) 济南 250014)
2(算力互联网与信息安全教育部重点实验室(齐鲁工业大学(山东省科学院)) 济南 250014)
3(山东省计算机网络重点实验室(山东省计算中心(国家超级计算济南中心)) 济南 250014)
4(山东省基础科学研究中心(计算机科学)齐鲁工业大学(山东省科学院)) 济南 250014)
随着互联网的广泛应用,恶意代码的数量和种类增长迅速[1],AV-TEST研究所每天捕获到超过45万个新的恶意程序样本和潜在的未知应用程序[2].恶意代码指的是在受害者的计算机或网络上执行未经授权和有害操作的软件,包括病毒、蠕虫、木马和僵尸程序,导致数据泄露、系统破坏和网络瘫痪[3].研究者们对恶意代码检测技术展开了研究,包括基于签名的检测、基于行为的检测和基于机器学习的检测方法.
近年来,基于图像处理的检测方法[4]用于可视化和恶意软件分类已经变得越来越受欢迎.由于缺乏有效的预处理,其检测精度和稳定性并不高.本文构建了一种VLMal神经网络模型,以训练和分类预处理的数据.大多数PE文件都是加密和混淆的.然而,运行在内存中的PE文件是已解密和解包的原始数据.为了评估模型的有效性,本文收集了PE文件样本并在沙盒环境中执行PE文件.然后,使用内存取证技术从内存中提取出PE文件,构建小型内存PE文件数据集.本文的主要工作和贡献如下:
1) 提出了基于GHM(Gray,HOG,Markov)的PE二进制文件可视化方法,利用图像转换、增强和马尔科夫矩阵等多种技术生成3个灰度图像,并将这些图像构建3通道的彩色图像,保留了PE文件更加详细的数据特征.
2) 构建了基于CNN(卷积神经网络)和LSTM(长短期记忆模型)的VLMal分类模型,实现对可视化的图像进行恶意软件检测分类.
3) 构建了1个小型样本的内存PE文件数据集,以评估本文提出方法的检测效果,弥补了目前没有公开内存PE文件数据集的不足.
1 相关工作
在计算机安全领域,恶意软件的检测和分类变得越来越重要.为了解决这一问题,研究者们提出静态分析、动态分析和内存取证分析等多种分析技术.
1.1 静态分析
Schultz等人[5]提出一种用于识别恶意代码的初始数据挖掘方法,利用恶意软件二进制文件的字符串序列、字节序列和PE文件头部3个不同的静态特征进行识别.Iwamoto等人[6]使用n-gram技术从Windows二进制文件中提取字节,并使用1对多的分类方法训练了多个分类器.Zhang等人[7]提出一种基于操作码序列的勒索软件分类方法,该方法将勒索软件样本的操作码序列转换为n-gram序列,然后使用n-gram特征的词频值构建特征向量,采用5种机器学习方法对勒索软件进行分类.Soni等人[8]提出一种利用API调用和操作码序列信息进行恶意软件分类的方法,该方法首先提取这些特征,然后使用朴素贝叶斯(NB)、逻辑回归、随机森林(RF)和支持向量机(SVM)4种机器学习算法对恶意软件进行分类.
1.2 动态分析
静态分析侧重于在不执行程序代码的情况下分析程序代码,而动态分析是运行软件并在其执行过程中监视其行为.Anderson等人[9]提出一种基于动态指令跟踪图的恶意软件检测算法.该方法从收集的数据中构建了马尔科夫图,使用SVM(支持向量机)进行分类.Nair等人[10]提出一种基于API调用的动态分析方法检测恶意软件,对所有恶意软件家族生成签名,并发现同一家族的大多数变异病毒共享相同的基本特征.Bayer等人[11]提出一种可扩展的聚类方法,用于基于相似行为识别和分组的恶意软件聚类.
1.3 内存取证分析
恶意软件内存取证是一种分析计算机内存中的恶意软件行为的技术.Bozkir等人[12]利用内存数据通过计算机视觉和机器学习技术对恶意软件进行分类.Otsuki等人[13]提出从64位Windows系统内存镜像中提取堆栈痕迹的方法.Uroz等人[14]提出从注册表ASEP(auto-start extensibility point)中寻找未知和罕见程序的方法.针对通过内存转储获取的Windows进程和系统库文件,Martín-Pérez等人[15]提出以文件对象为导向和线性搜索的方法,清除重定位,实现转储文件的相似性计算.
相较于之前的恶意软件分类研究,本文构建了1个3通道彩色图像.在构建彩色图像时,本文根据数据集中的稀疏性对每个通道的图像生成算法进行了改进.
2 方案设计
本节将详细解释本文方案整体工作流程(如图1所示).
2.1 数据集x
本文使用Kaggle公共恶意软件检测数据集[16]作为第1个数据集.此外,收集了最新的恶意的和常用的良性PE文件,在沙箱中运行,并在内存中提取PE文件,确保了PE文件是真实的、未加密的数据,并将收集到的样本构建了小样本数据集作为本文的第2个数据集.
2.1.1 数据集A
Kaggle发布的微软恶意软件分类挑战数据集包含10868条带标签的训练数据和未标记的测试数据,分为9类.本文提出的检测方法是一种监督学习方法,因此只使用微软恶意软件分类挑战数据集的训练集作为本文的数据集.以8∶2的比例将其划分为新的训练集和测试集.
2.1.2 数据集B
本文从VirusShare收集样本作为恶意样本,并将Windows系统中常用软件作为良性样本.通过使用VirusTotal平台检测收集的样本,发现每个反病毒平台给出的标签不一致,因此本文将收集到的样本分为良性和恶意2个类别.之前的研究已经通过在沙箱中运行并以其他格式发布了预处理样本.文献[17]给出了1个API数据集,在杜鹃沙盒中执行PE文件,生成报告,提取API调用.然而,没有在相关文献中找到提供原始内存PE文件的数据集,只有将内存PE文件转换为API或图像格式的数据集.因此,本文在沙盒中运行收集到的静态样本,并每隔10min转储1次内存镜像,重复该过程10次,尽可能多地捕获恶意行为.本文使用volatility[18]和团队开发的内存取证工具[19]分析这些转储的内存镜像,从而提取exe和dll文件.
2.2 GHM可视化
2.2.1 灰度图转化
为了可视化PE文件,需要将它们转换为向量矩阵从而可视化为灰度图.然而,由于每个PE文件的数据大小差异较大,将它们转换成具有相同宽度的2维矩阵会导致较小的文件在放大时其结构遭受损失.因此,在将其转换为2维向量矩阵时根据文件的大小确定矩阵向量的宽度,如表1所示:

表1 图像宽度设定表
数据集中每个样本的大小不均匀,由于训练神经网络需要创建大小一致的灰度图像,本文将不同大小的灰度图像调整为224×224px.
2.2.2 HOG图像
为了增强灰度图像的对比度,采用方向梯度直方图(HOG)特征提取方法[20],通过提取有用信息并丢弃无关信息构造第2通道的灰度图像.
HOG中计算梯度g和方向θ的公式如式(1)所示:
(1)
其中
gx=(hx+1,y-hx-1,y+hx+1,y-hx-1,y)/2,
(2)
gy=(hx,y+1-hx,y-1+hx,y+1-hx,y-1)/2.
(3)
本文注意到内存PE文件中数据的稀疏性,并调整梯度g以更清晰地反映数据梯度.具体来说,在计算梯度g和方向θ时,本文使用式(2)(3)计算水平和垂直梯度,然后使用式(1)计算梯度g和方向θ.将梯度g按比例分成9个角度块,构建初步的梯度方向直方图.然后,利用L2范数对梯度方向直方图进行归一化处理,以减少训练时的计算量,防止因计算量大而导致数据溢出.
2.2.3 马尔科夫图像
本文选择的PE文件为二进制数据,即字节流数据.取值范围为0x00~0xff.为了构建字节频率表,本文创建1个256×256矩阵,并将矩阵中的每个坐标点初始化为0.将PE文件作为序列读取之后,将滑动窗口大小设置为2,即每2B表示矩阵中的1个坐标点.例如,如果窗口中的2B是0x00和0x01,表示第1行和第2列中的1个坐标点,而这个坐标点的值加1.滑动窗口继续移动,直到遍历完整个数据序列,从而构建PE文件的字节频率表.通过字节频率表可以计算出字节概率表.具体来说,每个矩阵坐标点的频率除以每行样本总数就是该坐标点的概率.
(4)
BFTij表示第i行第j列的频率分布,Si表示第i行总的频率.通过遍历字节频率表构建了字节概率表.
分析过程中发现,字节频率分布不均匀,难以充分体现低概率字节的特征.因此,使用对数变换公式构造马尔科夫图像:
(5)
其中GIij表示将概率表中的元素转换为灰度值后得到的像素,p(i,j)表示概率表中的元素值,c表示1个取值为0.1的参数,L表示灰度级的个数.通过遍历字节频率表和字节概率表,构建马尔科夫图像,得到马尔科夫图像的特征信息.
2.2.4 GHM彩色图像构建
最后,将3种类型的灰度图像(Gray,HOG,Markov)填充到彩色图像的3个通道中,以构建样本数据的最终可视化彩色图像.此过程的目的是将不同的图像特征合并到RGB图像中,使得本文的神经网络模型能够更好地理解图像的特征和内容,如图2所示.通过使用这些样本数据,构建和训练能够准确分类和识别恶意软件的神经网络模型.
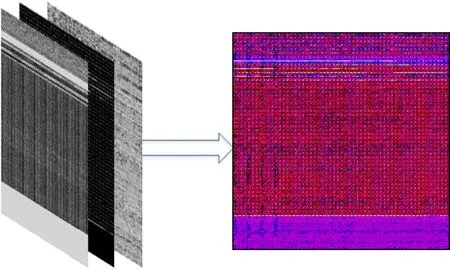
图2 马尔科夫图像构建
2.3 VLMal模型
本文对几个成熟的基于CNN的网络模型(包括GoogLeNet,ResNet,ResNet)进行了实验,发现VGG16在选择的数据集上评估指标最好.考虑到二进制PE文件表现出文本序列的特征,本文在VGG16特征提取后结合LSTM模型进一步突出序列特征.
通过将原始VGG16的1000个类别修改为数据集的9个类别来改进VGG16的分类器.由于本文使用迁移学习加载预训练模型,在导入预训练参数时,将参数strict设置为false.在VGG16特征提取后,使用Flatten将数据转换成1维序列,然后使用LSTM进一步训练数据,以获得更好的分类性能.
在数据分析过程中,本文发现数据集的不平衡性.文献[20]由于不平衡而选择删除样本数量少的类别.针对此问题,本文使用了Focal Loss函数FL(·)平衡权重并将模型的注意力更多地集中在难以分类的类别上.
CE(pt)=-lg(pt),
(6)
FL(pt)=-(1-pt)γlg(pt).
(7)

FL(x)通过增加γ的值,提高了少量样本类别的分类性能.随着γ的增加,FL(x)对错误分类样本的惩罚更大,从而强调了少数样本的重要性.当γ=0时,FL(x)降为标准的交叉熵损失函数CE(x).在模型训练过程中,样本的预测概率记为pt.此外,在权重分配过程中,为样本较少的类别分配更高的权重.
2.4 评估指标
为了检测恶意代码类别,本文使用分类的4个评价指标:Accuracy,Precision,F1_score,Recall.F1_score表示可以同时反映准确率和召回率的指标.
(8)
(9)
(10)
(11)
TP表示被模型正确预测为恶意样本数量;而FP表示被错误预测为恶意的样本数量;TN表示被正确预测为良性样本数量;FN表示被错误预测为良性的样本数量.
3 恶意软件分类实验评估
3.1 环境设置
本文实验中使用的CPU为Intel®CoreTMi7-11800H处理器,配备2个8GB内存模块和1个NVIDIA GeForce RTX 3050显卡.软件环境包括64位的Windows 10操作系统和VMWare,其中包含Windows 7和Windows XP虚拟机,用于执行恶意样本.深度学习框架使用Python 3.7,Anaconda conda 4.11.0,PyTorch torch1.10.1构建和执行的.模型学习率设置为0.001,批处理大小为8,epoch为25,使用SGD优化器.
3.2 数据集A
在构建的模型中对3种特征提取方法(Gray,HOG,Markov)和GHM的3通道彩色图像进行实验.对不同通道的图像进行了10折交叉验证实验.图3示出采用不同特征提取方法的Accuracy,Precision,F1_score,Recall指标:
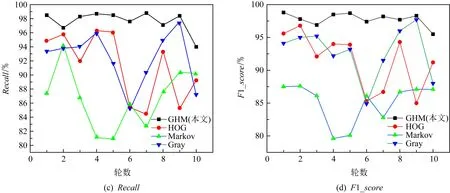
图3 不同通道图像实验结果对比
3.3 数据集B
为了探索本文方法在内存数据上的分类性能,在数据集B上训练和测试本文的模型.表2给出了GHM的3通道彩色图像和单通道灰度图像的实验结果对比:

表2 数据集B实验结果对比
4 结 语
本文提出了一种基于GHM-VLMal的恶意代码检测与分类方法,并对该方法进行了全面的实验,取得了良好的效果.
该方法在静态数据集上表现良好,但在内存数据集上检测性能下降.通过观察内存数据,发现其数据是高度稀疏的,这是导致检测性能下降的原因.
未来,计划对稀疏内存数据进行进一步的研究,提高检测性能.还将对跨平台的恶意软件检测和分类进行研究.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
销售与市场(营销版)(2021年10期)2021-11-21
高技术通讯(2021年5期)2021-07-16
高技术通讯(2021年3期)2021-06-09
当代陕西(2019年13期)2019-08-20
销售与市场(营销版)(2019年6期)2019-06-21
网络安全技术与应用(2017年9期)2017-09-20
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年1期)2016-11-07
测绘科学与工程(2014年5期)2014-02-27
