
运营商大模型硬件基础设施创新及RDMA流量控制技术研究
2024-03-13 12:19车碧瑶张永航廖怡唐剑樊小平赵继壮陆钢
信息通信技术与政策 2024年2期
车碧瑶 张永航 廖怡 唐剑 樊小平 赵继壮 陆钢
(1.中国电信股份有限公司研究院,北京 102209;2.中国电信天翼云科技有限公司,北京 100007)
0 引言
“真正认真对待软件的人应该自己制造硬件”[1]。经过十几年的发展,云计算已经走到了硬件创新成为行业主要驱动力的阶段。随着2022年底大模型时代的开启,全球头部云服务商2023年除了推出自己的各种大模型,也坚定地在大模型硬件基础设施上进行了自主研发。本文首先对电信运营商在大模型硬件基础设施领域自主创新的路线选择进行了分析和研究,然后重点论述了基于中国电信云网融合大科创实验装置在远程直接内存访问(Remote Direct Memory Access,RDMA)拥塞控制方面的研究进展。
1 运营商大模型硬件基础设施创新路线图
大模型硬件基础设施创新主要包括以下3个层面。
一是研发人工智能(Artificial Intelligence,AI)算力芯片。2023年,AWS推出第二代AI芯片Trainium 2,微软推出Maia 100,谷歌推出TPUv5p,这些产品均选择走可对特定AI业务场景加速的专用集成电路(Application Specific Integrated Circuit,ASIC)芯片路线,而不是通用图形处理器(Graphics Processing Unit,GPU)路线。
二是研发数据处理单元(Data Processing Unit,DPU)。例如,AWS的Nitro、谷歌的IPU、阿里巴巴的CIPU、中国电信的紫金DPU等。DPU设备是云服务商的根本技术所在,云主机最重要的虚拟化、网络通信、存储、安全功能全部下沉到此设备中;与过去智能网卡只能提供部分软件卸载不同,现在整个基础架构软件堆栈都可以在DPU上实现,中央处理器(Central Processing Unit,CPU)释放后可给最终用户售卖更多核;头部云服务商自研DPU的产品路线上均选择对能够体现自身架构独特性的功能进行强化;因功能非常复杂且需要嵌入云服务商各自独特的功能,故产业界DPU标准化程度还不高。
三是研发运行在数据中心专用通信硬件上的实时处理逻辑。例如,嵌入高速网卡中的RDMA拥塞控制逻辑、网络负载均衡逻辑和交换机上的定制化协议处理逻辑等。
第一、二层面硬件自主研发的商业价值主要体现在:一方面,自研芯片可给云服务商加持其他公司难以复制的核心竞争力,如AWS的IPU Nitro;另一方面,大幅降低云服务商采购第三方先进芯片的投资额,可以预估一旦谷歌原生多模态大模型Gemini的领先效果被业界广泛认可,则训练Gemini的谷歌张量处理器(Tensor Processing Unit,TPU)会一改以前只是自用的局面,外部客户也会从通用GPU转向更便宜的谷歌自研芯片TPU,谷歌会大大降低外购GPU成本。
但第一、二层面的硬件研发需要巨大的投入和时间积累并且失败风险很高,目前的实现路径有以下几种模式。
一是与大型芯片公司联合研发,既可解决自身能力不足问题,又提高了项目的成功率。例如,微软组建数百人的独立团队,与AMD联合开发代号名为Athena的AI芯片,此项目预估已投入20 亿美元以上;谷歌TPU v1~v4均由博通共同设计,除了芯片设计之外,博通公司还为谷歌提供了关键的知识产权,并负责了制造、测试和封装新芯片等步骤,以供应谷歌的新数据中心,博通公司还与其他客户(如Facebook、微软和AT&T等公司)合作设计ASIC芯片。
二是收购半导体设计公司,走独立自主的芯片设计路线。例如,亚马逊多年前收购Annapurna Labs,设计出的AI推理/训练和网络芯片均已规模部署。
三是收购初创公司获得完整知识产权(Intellectual Property,IP)和人才,如微软收购DPU初创公司Fungible。
四是组建设计团队,直接购买第三方完整IP修改后定制出自己的芯片,但除了因符合云服务商定制化需求的IP供应商很少外,商务合作模式也受限于运营商标准化采购流程比较难以操作。
五是与已经成功流片的小体量的初创设备商合作进行上层功能定制,快速推出自己的芯片。
六是基于现场可编程门阵列(Field Programmable Gate Array,FPGA)开展核心IP完全自主可控的产品研发,逐步积累芯片研发经验,时机成熟启动流片,最后实现低成本芯片规模化部署;微软早在2010年就启动了以FPGA路线为主的硬件研发;由于FPGA在信息通信网络设备中广泛存在,运营商在云中选择同样的FPGA路线可实现IP的复用;针对高端云网设备(高速DPU+高速交换机)极难解耦的困境,运营商端侧的FPGA设备可以实现异构厂家交换机协议的兼容,保持运营商对网络的核心掌控力。
综上所述,结合运营商自身业务场景、实际需求和研发现状,对硬件基础设施创新3个层面分析如下:芯片研发耗时漫长,投资巨大,见效慢,且流片失败风险极高。选择上层功能定制合作模式的自研芯片见效快,但由于运营商研发人员没有真正深度参与IP设计,从长远看不利于核心竞争力的掌控。因此,在第三层面研发嵌入到特殊硬件中的硬件逻辑则相对周期较短,风险可控,实现独有技术架构的可能性较大。例如,随着业界100 G以上高速网卡在需求方引导下逐步开放可编程接口,研发面向大模型智算场景运行在高速网卡上的RDMA流量控制逻辑是一种性价比较高的选择。
RDMA流量控制技术是保证大模型训练网络性能的关键技术之一。RDMA流量控制技术主要包括RDMA拥塞控制与RDMA多路径负载均衡两种技术:RDMA拥塞控制技术用于调控各个计算端服务器向数据中心网络的发送数据的速度;RDMA多路径负载均衡技术的目标是让流入网络的报文公平且最大化地利用组网中所有物理链路,尽快完成流传递,避免出现一部分链路过载而另一部分链路利用率不高的情况。这两种技术现阶段都需要在符合特定规范的硬件中嵌入运营商自主研发的控制逻辑,才能在100 G、200 G、400 G甚至未来800 G的高速网卡和高速交换机中发挥作用。
2023年,中国电信股份有限公司研究院与中国电信天翼云科技有限公司紧密协同在RDMA拥塞控制方面持续发力,结合运营商智算网络规模大、可靠性要求高等特征确定研发目标:重点关注可部署性,尽可能破除对基于优先级的流量控制(Priority-Based Flow Control,PFC)的依赖,简化交换机配置,避免繁琐的显式拥塞通知(Explicit Congestion Notification,ECN)水线调优,得到高速、NO-PFC、NO-ECN、Zero Queuing的拥塞控制算法。基于大科创装置仿真实验平台和物理实验平台,通过方法创新不断挑战性能曲线,自主研发拥塞控制技术(Chinatelecom Congestion Control,CTCC),在Incast场景、全闪存储场景、混合专家(Mixed of Expert,MoE)大模型训练场景实测结果有明显对比优势。
2 RDMA流量控制技术业界研究现状
2.1 主流技术路线
随着大模型算力性能飞速提升,为实现更高的GPU计算加速比,云主机网络带宽从主流通用云计算的单端口25 G演进到单端口400 G,此时基于软件的网络堆栈已经无法发挥出网卡的全部性能。头部云服务商在高算力数据中心的各种业务中开始广泛采用RDMA技术,将网络堆栈卸载到网卡硬件中,实现数据直接传输。但RDMA网络在协调低延迟、高带宽利用率和高稳定性方面面临着挑战。由于网络丢包对业务(尤其是大模型训练业务)影响较大,避免网络拥塞并发挥网络全链路负载是保证算网协同场景性能的关键,云服务提供商都在此领域积极布局自主研发创新。
数据中心网络拥塞主要由Incast流量和流量调度不均导致,为应对这两类场景,提高RDMA网络的性能和可靠性,业界采用拥塞控制算法和流量路径负载均衡两种技术路线。前者致力于提出高效的拥塞控制协议,感知链路拥塞状态后进行流级别控速;后者调整进入网络的各种流量路径避免拥塞,特别是解决在大模型训练业务场景下复杂的组网架构、通信模式极易引起的局部链路过载等问题。
主流拥塞控制算法主要通过ECN、往返时延(Round-Trip Time,RTT)、带内网络遥测(In-band Network Telemetry,INT)等信号感知链路拥塞,并做出微秒级响应。当前业界最普遍采用的、基于ECN信号的代表性算法是微软和Mellanox联合研发的数据中心量化拥塞通知(Data Center Quantized Congestion Notification,DCQCN)算法[2],需要交换机在拥塞时标记数据包,并由接收侧反馈到发送侧网卡进行速率控制。基于RTT的方案依赖网卡硬件实现高精度的时延测试,不需要交换机参与,部署相对容易,谷歌提出的TIMELY和SWIFT算法[3-4]均采用该路线;基于INT信号的方案依赖链路中交换机记录的出口速率和队列深度等信息精确控制飞行流量,要求交换机支持特定格式的INT报文[5-6]。
在流量路径负载均衡控制方面,业界主流技术路线包括动态负载均衡和多路径传输两种。动态负载均衡感知链路故障或拥塞状态,修改数据包头中生成负载均衡哈希(Hash)算法Key值的相关字段,实现自适应路由,腾讯提出端网协同的快速故障自愈Hash DODGING方案[7]采用该路线,网卡和交换机上采用基于Hash偏移的网络路径控制方法,感知故障后终端修改数据包头的服务类型字段值实现重新选路;多路径传输路线的主要设计思路是包级别甚至信元(Cell)级别的负载均衡实现方案,以解决传统等价多路径(Equal Cost Multipath,ECMP)算法在长/短流混合场景负载分配不均导致长尾时延的问题。AWS的SRD协议[8]实现逐包转发的负载均衡技术,依赖自研芯片Nitro完成乱序重排。谷歌提出新型网络架构Aquila[9],定制TiN(ToR-in-NIC)芯片实现网卡和交换机硬件级的紧耦合改造,采用私有L2 Cell Based协议GNet提供Cell级交换能力。博通公司采用分布式分散式机箱(Distributed Disaggregated Chassis,DDC)组网方案[10],提出基于网卡的全网端到端Cell改造以及仅在叶脊网络(Leaf-Spine)之间进行Cell改造的实现方案。
目前,先进的负载均衡方案大多依赖端网协同,需要交换机和网卡提供各种定制化能力。由于尚未形成统一的标准,设备商基于各自独有技术提供能力支持,现阶段开放性不足,难以异厂家设备组网,在运营商现网环境中大规模应用存在阻碍。端到端拥塞控制算法可以在不进行业务软件、网络硬件设备更新的前提下优化网络拥塞和时延,是提升大规模集群网络通信性能最具成本效益的方法。结合现网环境和业务场景,运营商可先着手于短期内能落地、易部署的高效拥塞控制算法,在数据中心改造升级过程中结合实际情况探索端网协同的负载均衡策略,提出更完备的流量控制解决方案。
2.2 面临挑战与优化目标
DCQCN是标准网卡中默认的RDMA拥塞控制算法,只有当交换机队列累积至超过ECN水线才能感知拥塞,导致在大规模Incast场景拥塞缓解速度慢,收敛前持续触发PFC。此外,DCQCN算法超参数数量过多,性能与参数选择强相关,在实际部署中调参困难。此外,DCQCN算法完全依赖于路径中交换机标记ECN拥塞后对端返回给发送端的拥塞通知报文(Congestion Notification Packet,CNP)调速,此方案有如下优劣势。
在各个发送端,由于一台交换机下所有发送端收到的拥塞信号接近,很容易导致各个流以相同的计算公式在同等输入条件下得到的速度相近,吞吐波形图中体现为各条流曲线基本重合。通过大科创装置的物理实验平台,观测到DCQCN吞吐量接近链路带宽且各条流曲线公平性非常好。
ECN信号无法反馈准确的交换机队列长度,拥塞情况下极易导致队列累积触发PFC。如果一条链路上出现多种流量混跑,因为交换机每个端口的优先级队列只有8条,超过8个业务时必然存在多个业务共享一个交换机优先级队列的情况。各个业务的流量模型不同时,可能出现共享队列的流彼此影响,触发PFC时端口暂停导致受害者流的问题。
调速应同时考虑交换机链路和主机处理速度双重因素,但交换机的ECN信号无法反映对端主机上的业务处理速度。
综合考虑运营商现网设备现状与实际业务需求,从业务性能、网络可靠性、成本等方面出发,提出自主可控的CTCC拥塞控制算法2023年设计目标:一是降低业务延迟,满足RDMA网络高吞吐、低时延的需求。算法基于端到端的RTT信号监控网络拥塞状态,快速做出响应,控制交换机队列长度,减少数据包在网络中的排队延迟和抖动。二是支持NO-PFC。算法能够在NO-PFC配置下正常工作,避免持续丢包降低网络性能,保证网络可靠性。三是简化部署步骤。工业级网络实践中往往强调可部署性,新的拥塞控制方案应当不需要对网络设备进行任何修改,主要在网卡上实现和配置,降低部署的成本和复杂度。
3 中国电信自研RDMA拥塞控制算法
交换机队列长度是网络拥塞状态的直接反应,维持稳定的低交换机队列能够同时实现低延迟和高吞吐。排除软件侧时延抖动,RTT大小主要受数据包经过交换机的排队延迟影响,能够快速反应网络拥塞状态的变化。随着硬件性能的提升,网卡能够提供更高的时钟精度和更准确的时间戳功能。这使得通过网卡进行高精度延迟测量成为可能,为基于RTT信号的数据中心RDMA拥塞控制协议的设计与实现提供了前提条件。
针对DCQCN基于ECN信号调速导致队列累积、对网络拥塞反应滞后、PFC依赖程度较高等问题,考虑使用RTT信号进行更细粒度的调速,提出一种端到端的、基于速率(Rate-Based)的拥塞控制协议,可基于现有商用网卡或DPU的可编程拥塞控制(Programmable Congestion Control,PCC)功能实现。与现有算法相比主要有以下两点创新:依赖RTT信号进行Rate-Based调速,实现交换机免配置,能够有效维持交换机低队列,降低延迟;以支持NO-PFC配置为出发点,设置收到否定应答(Negative ACKnowledge,NACK)报文时快速降速,减少丢包带来的性能损失。
3.1 算法设计
如图1所示,CTCC算法使用RTT信号体现网络拥塞的变化趋势,设置目标RTT,当实测RTT高于目标RTT时表明网络发生拥塞,控制发送端网卡降速;实测RTT低于目标RTT时表明网络畅通,可试探性增速。此外,网卡收到NACK信号快速降速,避免持续丢包造成网络性能损失。
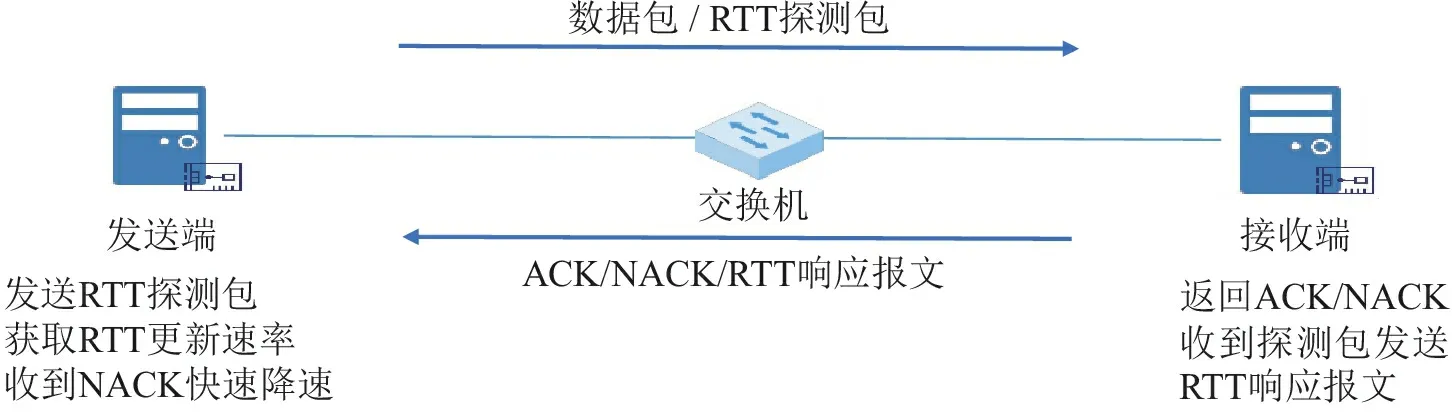
图1 CTCC拥塞控制算法实现框架
CTCC算法主要在网卡中实现,采用无需修改RDMA协议或软件协议栈的RTT探测方式,发送端网卡在拥塞控制算法请求RTT探测时主动发出探测包,收到RTT响应报文或NACK基于加性增乘性减(Additive Increase Multiplicative Decrease,AIMD)策略调速。接收端网卡负责返回应答(Acknowledgement,ACK)报文和NACK报文,收到RTT探测包时记录相关时间戳,生成RTT响应报文返回发送方。为避免反向链路拥塞增加RTT信号反馈延迟,设置RTT响应报文高优先级。该算法无需交换机参与,能够降低部署成本,更好地支持动态环境下的网络调整和扩/缩容操作。
CTCC算法难点描述:典型场景如7 000 个发送方往一个接收方打流,约束条件为7 000 个发送方彼此完全未知,每个发送方只能通过往接收方发送探测帧获得微秒级延迟后进行发送速率控制;目标为7 000个发送方要速率快速收敛达到一致以保证公平性,同时避免总发送速率超过接收方链路带宽,避免交换机队列太满产生PFC暂停帧,瓶颈链路吞吐要尽量逼近链路带宽。此外,在网络动态变化或复杂业务场景下,如打流期间对相同接收方动态新增1 000 个或动态减少1 000 个发送方、发送方物理链路混跑有多种业务流量、跨多个交换机、大小业务流混跑等场景,依然要满足上述目标。
3.2 算法优势分析
纯RTT方案无需交换机配合,基于现有商用网卡实现,减少替换和运维成本。CTCC算法仅基于RTT信号进行拥塞控制,无需交换机支持可编程等高级功能,且基于商用网卡提供的PCC框架实现,无需定制化硬件。
收到NACK快速降速,支持NO-PFC场景。算法设置网卡收到NACK后直接将速率减半,在关闭PFC的情况下也能应对大规模突发场景,快速降速大幅减少丢包数量,降低丢包带来的性能损失。
参数数量少,降低调优难度。算法不依赖PFC和ECN,免去配置交换机水线的繁琐步骤;且网卡实现简单,超参数数量少,极大地降低了算法调优难度,减少部署和运维工作量。
3.3 控制器设计
在算法研发测试过程中,随着测试环境节点数的增加,算法烧写、网卡和交换机配置等准备工作量剧增,且极易出现不同节点算法配置不一致等问题。为验证算法可商用需要进行覆盖多种基础场景的上千项测试,测试结果的统一记录和汇总是结果分析和算法优化的基础。为解决该问题,自主研发出CTCC集中控制器,提供图形化操作界面,实现多设备算法镜像一键烧写、动态超参数下发、算法类型切换、自动化测试、测试结果实时监控、试验结果跟踪等一系列功能,大大降低了研发测试的工作量和复杂性,保证测试结果可靠。
其中,超精度网络指标采集及监控是CTCC控制器的重要组成部分和一大技术难点。拥塞控制技术在研发过程中往往需要观测流量变化瞬间的网络性能的变化,对指标采集精度提出非常高的要求。CTCC控制器采用网络遥感技术,通过推模式(Push Mode)周期性地主动向采集器上送设备的接口流量统计、CPU或内存数据等信息,相对传统拉模式(Pull Mode)的一问一答式交互,可提供更实时、更高速的数据采集功能。之后,经过Protocol Buffer编码,实时上报给采集器进行接收和存储。通过上述方案,可实现亚秒级以上的监控精度。
3.4 算法性能评估
利用商用网卡可编程架构实现自研算法,基于大科创装置的物理实验台搭建8台服务器通过1台交换机连接的网络环境,通过性能测试(Perftest)命令进行打流测试验证自研算法优势。测试使用的网卡支持per-QP和per-IP两种调速模式,per-QP模式下为每个连接(QueuePair,QP)单独调速,per-IP模式为相同目的互联网协议(Internet Protocol,IP)地址的QP分配相同的速率。考虑到同一目的IP的流可能通过负载均衡分配到不同的链路上,拥塞状态会存在差异,设置相同发送速率并不合理。在测试中,采用per-QP模式对每个QP进行细粒度调速,根据链路实际拥塞情况调整速率。对于DCQCN算法,测试时开启PFC,相关参数使用网卡和交换机推荐的默认值。对于CTCC算法,测试时关闭网卡和交换机的PFC功能。
CTCC算法维持交换机低队列避免丢包:将7台服务器作为发送方,另外1台作为接收方,控制7个发送方同时起1 000 个QP向接收方打流,对比DCQCN和CTCC算法在大规模Incast拥塞场景的性能。测试结果显示DCQCN算法拥塞控制基本失效,始终维持10 MB以上的交换机队列,打流过程中持续触发PFC,易造成PFC风暴、死锁等问题,从而影响网络性能。CTCC算法最高交换机队列仅为1.22 MB,且在没有开启PFC的状态下无丢包。DCQCN算法Perftest测得的发送端总和带宽为97.98 Gbit/s,瓶颈链路带宽利用率为95.4%。CTCC算法测得的发送端总和带宽为90.70 Gbit/s,瓶颈链路带宽利用率为91.5%。
CTCC算法实现低时延:为验证自研算法在时延方面存在的优势,在上述测试场景中添加同方向的小流,测试小流完成的时延。由于DCQCN算法维持高队列,小流延迟达到1 154.77 μs,而CTCC算法能够有效维持低交换机队列,小流延迟平均值为20.31 μs,与DCQCN相比降低99%。
以上两项测试结果验证了CTCC能够在保证高吞吐的同时显著降低时延。与DCQCN相比,大规模Incast场景CTCC算法交换机平均队列和小流时延降低90%以上,在DCQCN持续触发PFC的情况下实现稳定状态无丢包。尽管控制交换机低队列易导致吞吐损失,且RTT探测包会占用少量带宽,CTCC仍保证了90%以上的带宽利用率,与DCQCN相比吞吐损失低于5%。
4 结束语
本文总结了业内RDMA拥塞控制算法研究趋势,结合运营商实际组网环境和业务场景需求提出研发目标,设计了一种交换机免配置的拥塞控制算法,基于大科创装置验证了其在物理环境中的性能优势。随着自主研发DPU、交换机技术的不断突破,产业各方会持续开展RDMA关键技术攻关,加强面向大模型训练场景数据中心网络极致负载分担、RDMA拥塞控制算法等核心技术研究,基于新的硬件设备设计结合多种信号的高效拥塞控制算法,并规划拥塞控制与负载均衡结合的全套解决方案,推动产业链的成熟与落地。
猜你喜欢
科技与创新(2023年17期)2023-09-17
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
网络安全和信息化(2019年1期)2019-02-15
军营文化天地(2018年2期)2018-12-15
制造技术与机床(2017年6期)2018-01-19
产品可靠性报告(2017年7期)2017-09-05
电脑爱好者(2015年15期)2015-09-10
电源技术(2015年9期)2015-06-05
计算机与网络(2014年5期)2014-04-15
