
基于深度强化学习算法的双边装配线第一类平衡
2024-03-13 05:45张亚辉曹先锋金增志胡小锋
计算机集成制造系统 2024年2期
程 玮,张亚辉,曹先锋,金增志,胡小锋+
(1.上海交通大学 机械与动力工程学院,上海 200240;2.上海交通大学 海洋装备研究院,上海 200240;3.中国重汽集团 工艺研究院,山东 济南 250100)
0 引言
装配线是车间流水生产的一种常见方式,常用于汽车、家电等大批量生产[1]。双边装配线相对于传统单边作业的装配线,拥有长度短、设备利用率高、物料搬运成本低等一系列优点,在装载机、卡车、汽车等较大型机械产品装配车间得到了广泛应用[1]。
装配线平衡问题即在满足一定约束条件下(生产工艺约束和节拍时间约束等),将一组装配任务尽可能均匀地分配到各个工位上,其追求一个或多个目标优化,属于NP hard组合优化问题,同样双边装配线平衡问题也属于NP hard组合优化问题[1]。通常,根据优化目标的不同,双边装配线平衡问题分为两类,第一类问题为给定节拍,最小化工作站数量,第二类问题为给定工作站数量,最小化节拍[2]。
自BARTHOLD[3]首次提出双边装配线平衡问题以来,众多研究人员对该问题展开了深入研究。针对第一类问题,KIM等[4]提出一种基于“工位”编码方式的遗传算法;LEE等[5]提出一种基于最大集规则的任务归组分配法,提高了装配任务之间的操作连续性;BAYKASOGLU等[6]设计了一种蚁群算法求解考虑区域约束的第一类问题;ÖZCAN等[7]采用禁忌搜索算法求解,同时考虑装配线效率和平滑度两个优化目标,并通过非线性组合将其转换为易于求解的单目标问题;KHORASANIAN等[8]采用模拟退火算法求解,得到了较好的解;YUAN等[9]设计了一种延迟接受爬山算法,考虑双边装配线问题额外约束,并与常见算法进行比较,验证其有效性;李大双等[10]将殖民竞争算法与延迟接受爬山算法结合,提出一种新型混合殖民竞争算法,通过多个算例测试验证了算法的合理性;LI等[11]基于改进的NEH(Nawaz-Enscore-Ham)启发式规则获得高质量的初始解,设计了一种改进的迭代贪婪算法,并与多种元启发式算法比较证明其优越性;LI等[12]提出一种分支界定记忆算法,将通过改进霍夫曼启发式规则获得高质量的初始解作为上界,并在标准案列上测试其有效性。
综上所述,第一类平衡问题的求解算法主要有启发式算法、精确算法和元启发式算法三大类。启发式算法虽然求解速度快、简洁高效,但是求解结果不能达到全局最优;精确算法能够得到最优解,但是求解速度慢;元启发式算法的迭代搜索过程通常比较耗时,每个问题案例需要重新迭代求解。这些传统优化算法很少利用历史信息来调整行为,不能有效利用历史求解经验进行学习,许多算法在大规模问题上仍有很大提升空间。
目前,利用深度强化学习算法求解组合优化问题已有一些初步的成果,包括旅行商问题、凸包问题、最大割问题、点集匹配、车间调度问题等[13],这些研究通常将求解组合优化问题转化为马尔科夫决策过程(Markov Decision Process,MDP),状态s描述问题状态,强化学习智能体(Agent)观察状态s,并做出决策a,环境采用决策a更新状态,并再将奖励r反馈给智能体,通过与环境交互获取决策经验来更新模型,在最大化奖励的同时最优化决策策略。
本文提出一种基于近端策略优化(Proximal Policy Optimization,PPO)的深度强化学习算法求解双边装配线第一类平衡问题,该算法充分利用深度强化学习从历史求解经验中进行学习,不断更新任务分配策略的特性,训练得到的模型可以直接用于求解其他具有相似组合优化结构的问题。PPO算法[14]是OpenAI在2017年提出的一种基于策略的深度强化学习算法,其独有的损失函数裁剪机制使得该算法学习稳定性更强,在交通、机器人、车间调度等智能控制领域得到应用,且明显优于策略梯度(Policy Gradient,PG)[15]、信任区域策略优化(Trust Region Policy Optimization,TRPO)[16]、优势动作评论(Advantage Actor Critic,A2C)[17]等深度强化学习算法。同时,考虑到双边装配线第一类平衡问题求解过程中状态的复杂性和多变性,采用独热编码将其转换为状态矩阵并引入卷积神经网络(Convolutional Neural Networks, CNN),构建了高效的CNN-PPO(proximal policy optimization with convolutional neural networks)算法求解双边装配线第一类平衡问题。
1 问题描述与建模
1.1 问题描述
双边装配线的构造如图1所示,其具有左右两条装配线,能在两侧并行完成同一产品的不同工艺,装配线每个工作站又分为左右两个相互独立的工作区,即左右两个工位,例如图中工作站2包括工位3和工位4,这两个左右对称的工位称作伴随工位,又称作配对工位[9]。

双边装配线的任务操作方位有左边(L)、右边(R)和双边(E)3种。图2a所示为P16问题的任务先序图,图中圆圈内的数字表示任务的序列号,括号中的数字表示该任务的作业时间,字母表示该任务的操作方位,箭头表示任务之间的执行顺序关系。

双边装配线任务分配需要考虑如下约束:
(1)先序约束 任务分配必须遵守任务之间的执行顺序关系。
(2)节拍约束 一个工位内所有任务的作业时间之和应该小于等于该工位的节拍时间。
(3)操作方位约束 任务只能分配到对应的操作边。
(4)序列相关约束 双边装配线上的任务可以同时串行、并行作业,导致任务在分配过程中除了考虑在其所分配工位上前一个任务的影响,还要考虑分配在伴随工位上的先、后序任务的影响。
图2b中,工作站1~工作站3表示该方案共开启3个工作站,L和R分别表示左工位和右工位;矩形内的数字表示任务的序列号,数字的先后顺序表示任务在该工位的执行顺序;矩形上的数字表示任务在该工位的开始和结束作业时间,数字的最大值表示该工位的作业完工时间;矩形内的黑色区域表示无任务分配。例如,工作站1的左工位分配任务为1,3,4,任务1的开始作业时间为0,结束作业时间为6,任务4的开始作业时间为6,结束作业时间为15,任务3的开始作业时间为15,结束作业时间为17,满足先序约束,而且该工位作业完工时间为17,小于节拍18,满足节拍约束。根据图2a,任务7可以分配在左工位或右工位,任务9只能分配在右工位,且执行顺序位于任务7之后;图2b中,任务7分配在工作站2左工位,任务9分配在工作站2右工位,满足操作方位约束,而且任务9的开始作业时间等于任务7的结束作业时间,同时满足先序约束和序列相关约束。
1.2 数学模型
本文涉及的参数说明如下:
(1)基本参数
Ns为双边装配线工作站数量;
I为任务集,I={1,2,…,i,…,m};
J为工作站集,J={1,2,…,j,…,n};
(j,k)表示工作站j上方位指示为k的工位,k=1表示工作站的左工位,k=2表示工作站的右工位;
AL为只能在左工位执行的任务集,AL⊂I;
AR为只能在右工位执行的任务集,AR⊂I;
AE表示在左或右工位均可执行的任务集,AE⊂I;
P(i)为任务i的紧邻先序任务集;
Pa(i)为任务i的先序任务集;
S(i)为任务i的紧邻后续任务集;
Sa(i)为任务i的后序任务集;
Pc为没有紧邻先序约束关系的任务集;



ct表示节拍;
μ为一个较大的常数。
C(i)为与任务i操作方位相反的任务集,其中C(i)=AL,i∈AR,C(i)=AR,i∈AL,C(i)=Φ,i∈AE;
K(i)为任务i操作方位指示符号集,其中K(i)={1},i∈AL,K(i)={2},i∈AR,K(i)={1,2},i∈AE。
(2)决策变量
xijk={0,1},如果任务i分配到工作站(j,k),则xijk=1,否则xijk=0。
(3)指示变量
zip={0,1},在同工作站上,如果任务i在任务p前,则zip=1,否则zip=0。
本文研究双边装配线第一类平衡问题,参考张亚辉[2]、李大双[10]等的研究成果,数学模型如下:
minns。
(1)
(2)
(3)
tf≥ti,∀i∈I;
(4)
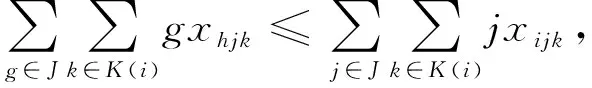
(5)

(6)
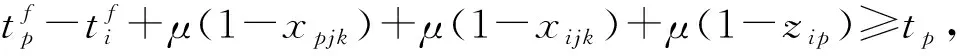
(7)
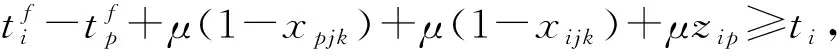
(8)
xij1={0,1},i∈AL,j∈J;
(9)
xij2={0,1},i∈AR,j∈J;
(10)
xijk={0,1},i∈AE,j∈J;
(11)
zip=0或1,∀i∈I,
p∈{r|r∈I-(Pa(i)∪Sa(i)∪C(i)),ir}。
(12)
其中:式(1)表示优化目标,即最小化工作站数量;式(2)表示每一个任务只能分配到一个工位;式(3)和式(4)表示每个任务的完工时间必须小于节拍,确保节拍约束;式(5)对应先序约束;式(6)~式(8)表示序列相关约束;式(9)~式(12)定义各个变量。
2 CNN-PPO算法求解双边装配线第一类平衡问题
CNN-PPO算法求解双边装配线第一类平衡问题的过程如图3所示。CNN-PPO强化学习智能体观察双边装配线环境状态st,采取任务分配决策at,环境完成任务at分配,并将奖励rt反馈给智能体,智能体通过与环境不断交互求解第一类平衡问题,同时获取任务分配求解经验,以数据驱动的方法学习经验,更新模型,通过反复试错获取更高的奖励值,在最大化累积奖励的同时最优化任务分配策略。

2.1 CNN-PPO强化学习智能体
CNN-PPO强化学习智能体采用类似PPO的执行—评价(Actor-Critic)结构类型。其中Actor策略网络根据双边装配线环境状态st做出任务分配决策at,Critic评价网络对任务分配决策at的优劣进行评价。
Actor策略网络用参数为θ的CNN逼近最优的任务分配策略pθ(at|st),网络结构如图4所示,包括两层卷积网络、三层全连接网络。图中,维度M×N的状态矩阵是网络在时刻t的输入,对应双边装配线环境状态st,M为状态特征数量,N为任务数量;pθ(at|st)为时刻tActor策略网络的输出,指Actor策略网络在双边装配线环境状态st下输出任务分配决策at的概率。
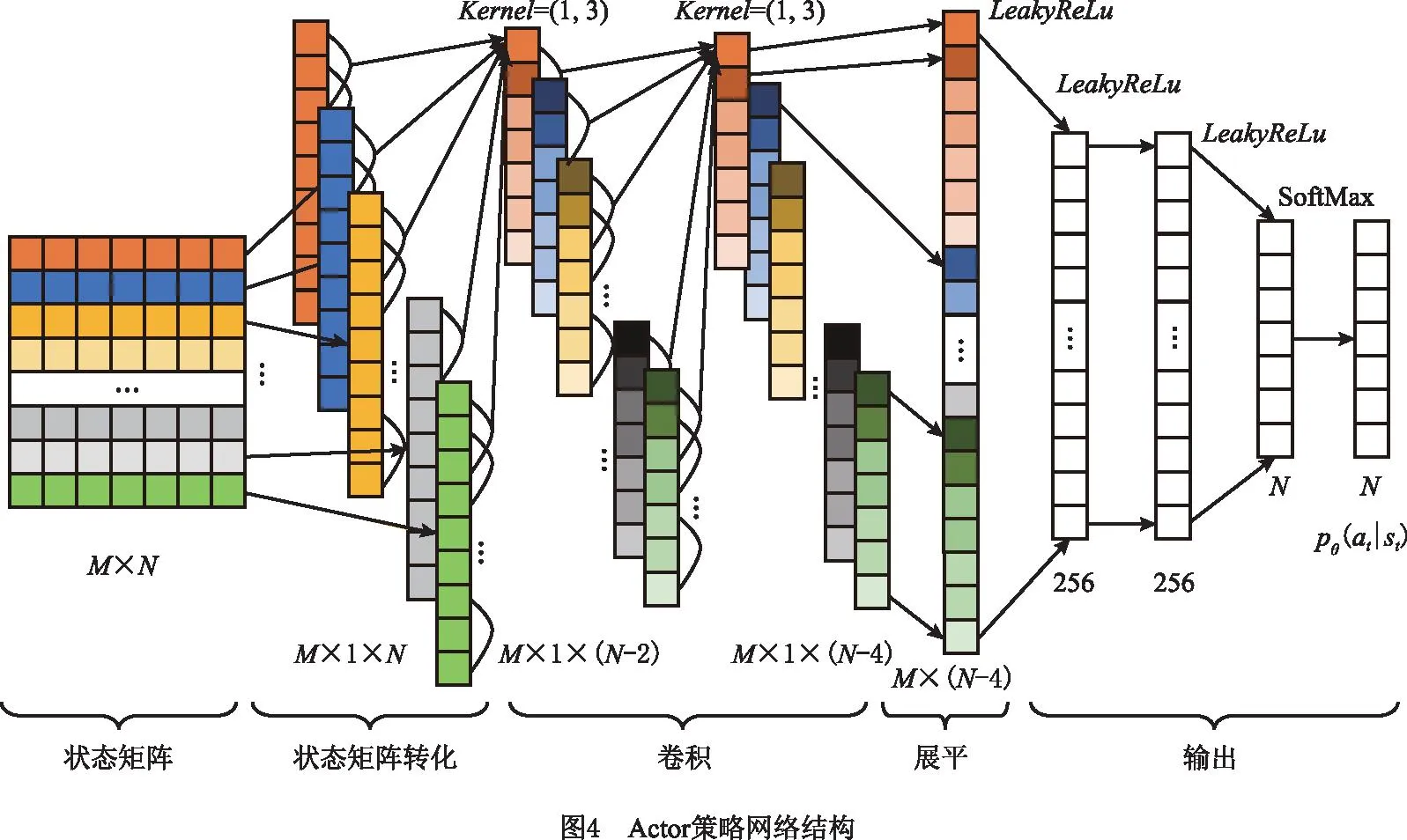
Critic评价网络用参数为ψ的CNN逼近最优的策略评价值vψ(st|at)。本文Critic策略网络结构前几层和Actor网络结构相同,只是最后一层为线性回归层,即vψ(st|at)=f(h(t);ψ)=ω×h(t)+b替代Actor网络中的SoftMax层,其中vψ(st|at)为t时刻Critic评价网络输出的策略评价值,h(t)为上一层的输出,ψ为网络内部单元节点的参数,包括权重ω和偏置项b。
2.2 双边装配线状态
状态的定义应与双边装配线平衡问题特征紧密相关。2016年,张智聪等[18]对强化学习在调度问题的状态选择提出以下准则:
(1)调度环境的主要特点和变化能够通过状态特征描述,包括调度系统的全局特征和局部特征。
(2)可以通过一个通用特征集表示所有问题的所有状态。
(3)状态特征可以用来表示和概括各种不同调度问题的状态。
(4)状态特征是调度问题状态变量的数值表征。
(5)状态特征应易于计算。
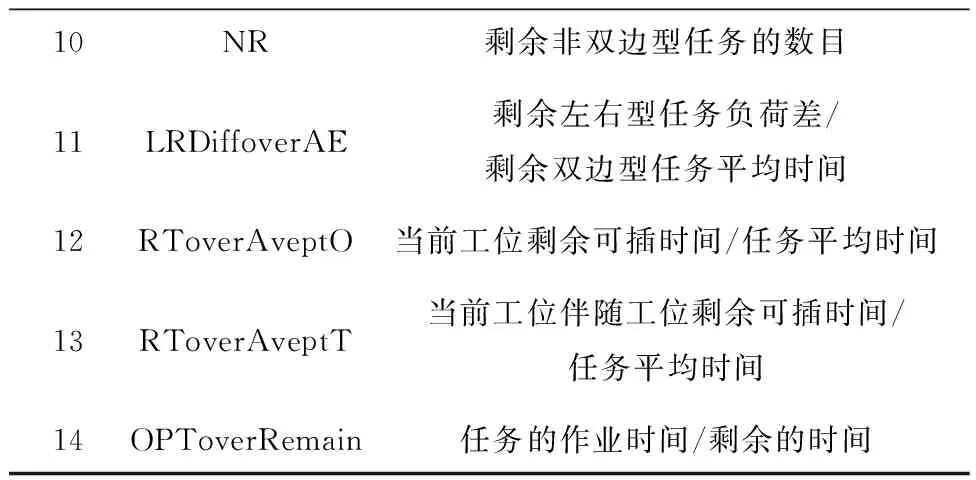
结合肖鹏飞对非置换流水车间调度问题提出的状态特征[19],本文针对双边装配线平衡问题提出双边装配线状态特征,如表1所示。

表1 双边装配线状态特征
续表1
其中,状态特征1~5的特征值为相应的任务序列号,状态特征6~14反映双边装配线的整体特征,特别地,对状态特征11~14进行取整处理。假设,某双边装配线任务数量为N,对表1中的状态特征进行独热编码处理,得到该双边装配线环境状态矩阵st,其维度为14×N。若序号为i的状态特征的特征值j≠0,则矩阵st第i行第j列的值为1,第i行其他列的值均为0;若状态特征i的特征值j大于矩阵列数,则取j的值为矩阵列数。
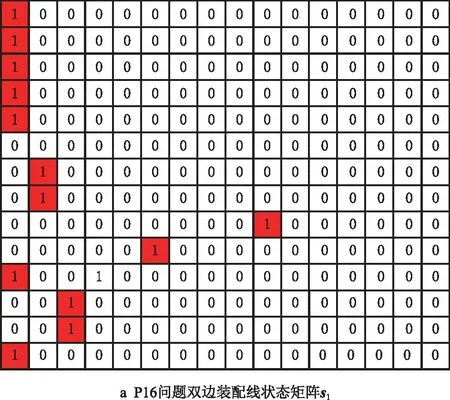
以P16问题为例,由图2a可知,在求解初始,装配线开启左工位,可分配的无先序任务集合为{1,2},对应的作业时间为{6,5},因此表1中,第1个状态特征PTime的特征值为1,其他状态特征可同理依次求得,如表2第3列所示,经过独热编码处理得到的状态矩阵s1如图5a所示。随后,CNN-PPO强化学习智能体观察状态矩阵s1,做出任务分配决策,若输出待分配任务1,并按下文装配线环境任务分配逻辑分配任务1(详见2.4节任务分配),则装配线开启右工位。考虑操作方位约束和序列相关约束,可分配的无先序任务集合变为{2},对应的作业时间为{5},因此PTime的状态特征值变为2,其他状态特征的参数相应发生变化,如表2第4列所示,经过独热编码处理得到状态矩阵s2如图5b的状态矩阵所示。

表2 P16问题状态特征值变化

2.3 任务决策
CNN-PPO强化学习智能体根据双边装配线状态矩阵st输出pθ(at|st),并按概率分布采样,获得待分配任务at。然而,因为双边装配线第一类平衡问题具有先序、操作方位、序列相关等约束,如果直接按概率分布采样,获得待分配任务at,则会出现算法难以收敛、陷入局部最优等问题,所以本文引入标记层(mask)来保证满足先序、操作方位、序列相关约束的任务能被采取,以充分利用智能体从经验中进行学习的能力。
以P16问题为例,Actor策略网络参数θ采用正交初始化,在双边装配线环境初始状态矩阵s1下,输出的pθ(a1|s1)如图6上所示,若按概率分布采样,则获得待分配任务a1为3,不满足先序约束。经mask层标记后如图6下所示,只能在满足约束的任务1和任务2中选择,若按概率分布采样,则获得待分配任务a1为1。

2.4 任务分配
双边装配线环境任务分配流程如图7所示。

2.5 奖励函数
CNN-PPO强化学习智能体通过最大化累积奖励rsum,实现最优的任务分配策略pθ(at|st),继而实现优化目标最优化。本文采用稀疏奖励,即智能体与环境交互过程中奖励r1,r2,…,rn-1均为0,当环境分配完所有N个任务后,给智能体反馈奖励rn,则累积奖励rsum=rn。若直接定义累积奖励为优化目标的负值,即rsum=rn=-ns,则环境给智能体反馈的信息太少,不利于智能体学习,因此本文累积奖励不仅包括优化目标,还包括该问题其他能辅助优化目标优化的子目标。
对于双边装配线第一类平衡问题,优化目标是工作站数量ns,通常优化工位数量nw能够帮助优化工作站数量ns,而且双边装配线效率LE、平滑系数SI、完工时间平滑度CSI[2]能够反映任务分配方案的优劣,也能辅助优化工作站数量,计算公式分别为:
(13)
(14)
(15)
式中:STi为工位i上所有任务作业时间的总和,STmax=max(STi)为其最大值;Ct(j,k)为工位(j,k)的作业完工时间,Ctmax=max(Ct(j,k))为其最大值。
考虑优化目标ns和子优化目标nw,LE,SI,CSI间的关系,本文首先采用线性规划法进行目标转化,以便高效获得较优的任务分配方案。参考文献[20],合并转化的函数方程式为
(16)
式中:wns和wnw为工作站数量ns和工位数量nw对应的参数,在双边装配线中,一个工作站包括两个工位,因此设置wns=1,wnw=2[14],le=100,而si的设置针对双边装配线问题规模的不同略有调整,即si为1(P24),25(P65),40(P148),300(P205),P9,P12,P16的si同样取1,csi取值同si。
因此,取rsum=rn=-f。
2.6 模型更新
CNN-PPO强化学习智能体通过与双边装配线环境不断交互完成第一类平衡问题求解,当双边装配线所有N个任务均完成分配时,定义τ={s1,a1,r1,s2,a2,r2,…,st,at,rt,…,sn,an,rn}为智能体与环境的交互轨迹,即智能体求解过程获取的经验。智能体与环境继续交互获取大量求解经验,并将其储存在经验池,当经验池的储存数量达到容量上限时,交互过程暂停,将经验池中的历史求解经验作为智能体Actor-Critic网络的训练数据,采用梯度下降法对网络参数进行更新,通过不断迭代对智能体任务分配策略进行优化。其中,Actor网络和Critic网络的损失函数同PPO[14]。
算法1基于CNN-PPO的双边装配线第一类平衡算法。
1:初始化Actor-Critic网络参数θ,φ,初始化迭代最大回合数episode、经验池容量buffersize、经验池最大容量max buffer size、批量样本大小batchsize
2:for each episode do:
3: t=1
4: 初始化双边装配线环境,生成状态st,清空经验池
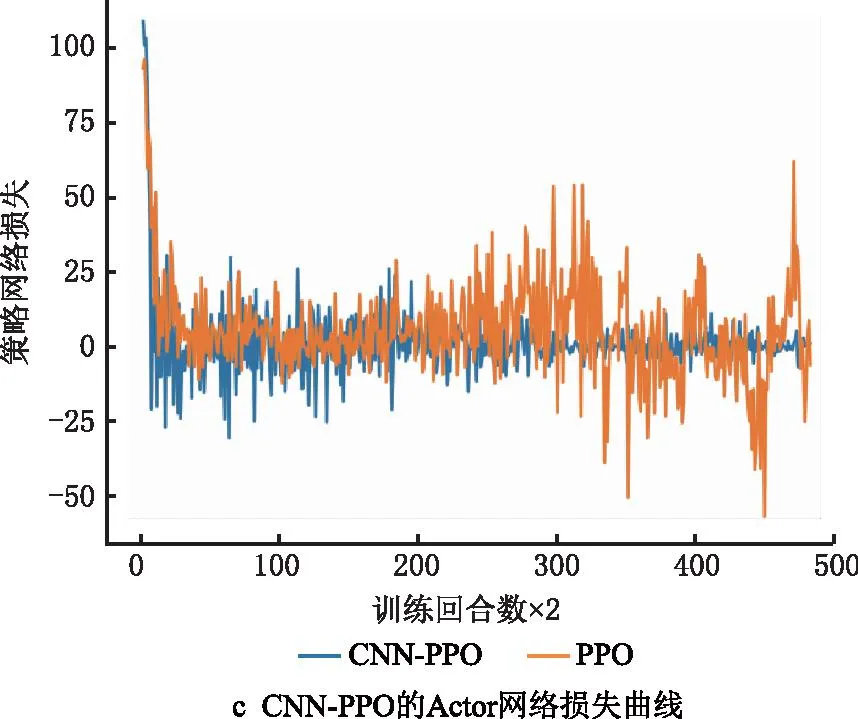
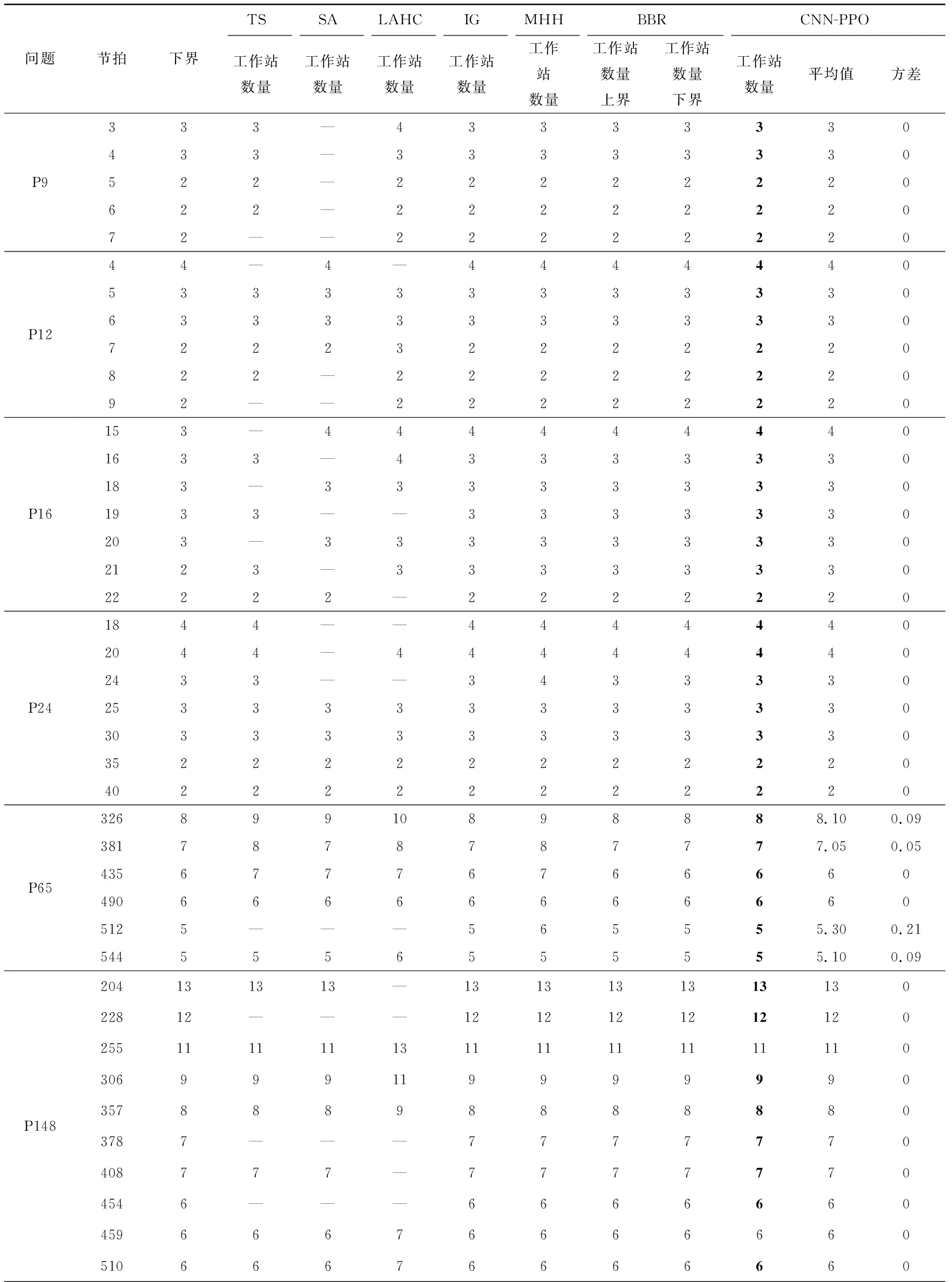
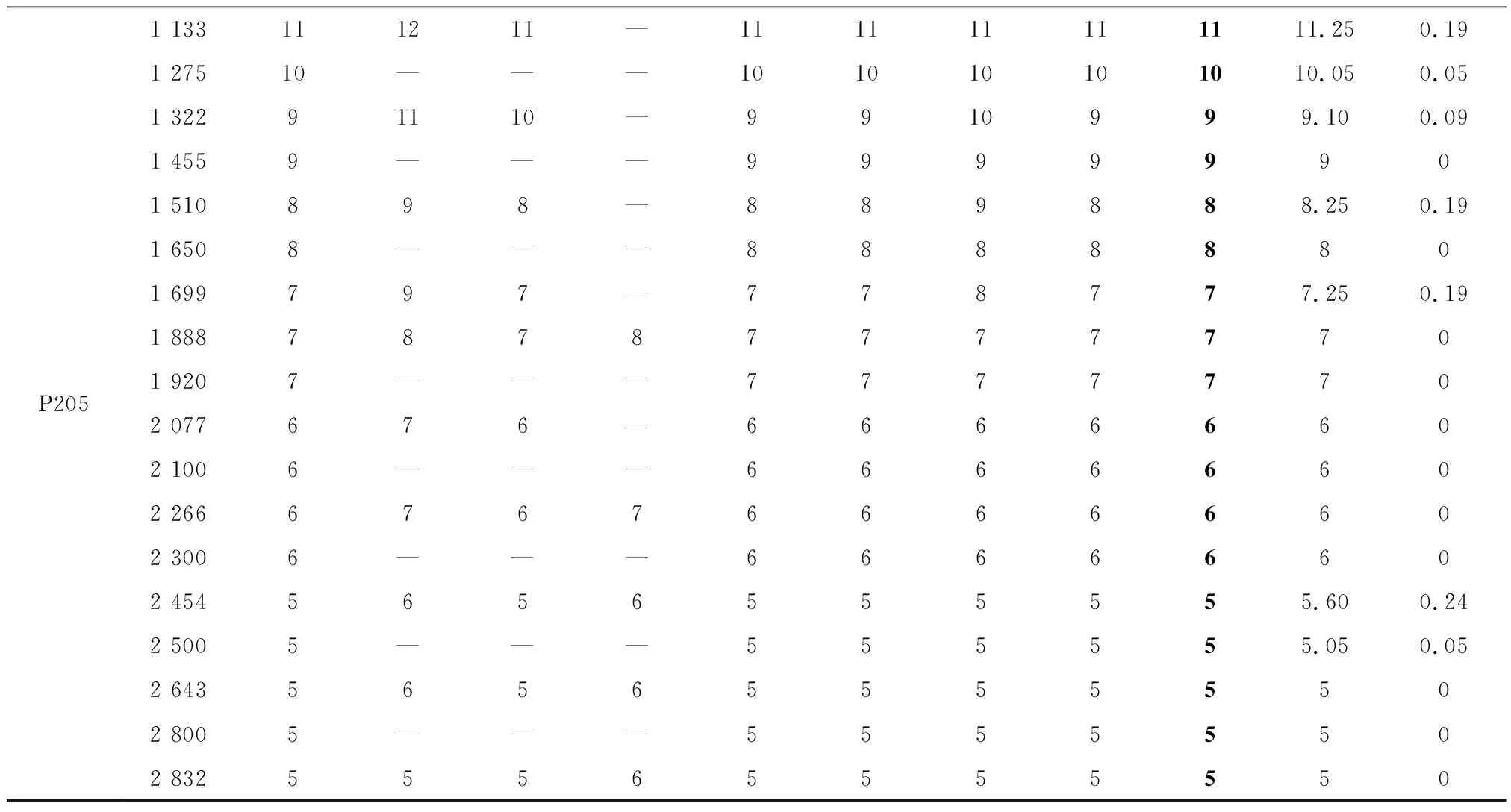
5: While buffer size 6: while双边装配线所有任务没有被分配完do: 7: 智能体观察环境状态st,根据策略pθ(at|st)决定待分配任务at 8: 环境分配任务at,反馈奖励rt 9: t=t+1 10: 更新环境状态st 11: end while 12: 智能体将交互轨迹τ(求解经验)存入经验池 13: end while 14: for epochin{1,2,…,buffer size/batch size} do: 15: 计算Actor策略网络损失函数actor loss,Critic评价网络损失函数critic loss 16: 更新Actor策略网络pθ(at|st) 17: 更新Critic评价网络vΨ(st|at) 18: end for 19: θold,φold←θ,Ψ 20:end for 采用Python语言编程,环境为Python 3.6,在操作系统为Ubuntu 20.04 LTS、CPU频率为2.90 GHz、内存为16 G的计算机上运行。以面向对象的形式搭建了双边装配线环境类,包括状态更新、任务分配、奖励生成,并用Pytorch框架和Python编程语言搭建了CNN-PPO强化学习智能体。 本文用基准问题进行算法测试,包括P9,P12,P16,P24,P65,P148,P205共7个问题,59个案例,问题数据同文献[6]。 在模型训练开始之前,本文算法的参数主要根据经验值和智能体交互过程的实际数据设置,具体如表3所示。 表3 算法参数 完成算法参数设定后开始训练,在迭代过程中记录智能体获得的累积奖励、Actor策略网络损失函数、Critic评价网络损失函数的变化情况,并与PPO算法对比。PPO算法为5层全连接网络,其输入为14×1的一维向量,14为状态特征个数,其输出和CNN-PPO一样都有mask层处理。 图8所示为改进前后的算法在P65、节拍CT=381案例上迭代训练过程的对比。 对比图8a和图8b可见,随着训练回合数的增加,增加CNN的CNN-PPO算法的累积奖励逐渐上升,而PPO算法一直在振荡,收敛困难,CNN-PPO算法的优化过程明显好于PPO算法,其收敛过程更稳定,优化结果更好。说明CNN的数据表征学习能力能够有效提取双边装配线状态矩阵的数据特征,并能更快更好地完成任务分配。图8c中PPO算法的Actor网络损失曲线振荡很厉害,收敛困难,而CNN-PPO算法的Actor网络损失曲线随着迭代次数的增加趋于收敛,策略趋于稳定。图8d中PPO算法的Critic网络损失曲线始终变化不大,即策略评价变化不大,表明Actor策略网络没有收敛,策略变化不大,而CNN-PPO算法的Critic网络损失曲线收敛过程更稳定,效果更好,说明CNN-PPO算法的优化过程更好。 综上所述,训练过程整体表明,相对于PPO算法,CNN-PPO算法的训练过程稳定,求解能力更强,更能满足双边装配线第一类平衡问题求解的需求,验证了算法改进的有效性。 保存训练后的CNN-PPO模型,在P9,P12,P16,P24,P65,P148,P205问题上求解,并将求解结果和现有5种较好的算法进行对比,对比算法为禁忌搜索(Tabu Search ,TS)算法[7]、模拟退火(Simulated Annealing, SA)算法[8]、延迟接受爬山(Late Acceptance Hill-Climbing,LAHC)算法[9]、迭代贪婪(Iterated Greedy,IG)算法[11]、改进霍夫曼(Modified Hoffman Heuristic,MHH)算法[12]、分支定界记忆(Branch,Bound and Remember,BBR)算法[12]。其中,TS,SA,LAHC,IG为元启发式算法,MHH为启发式算法,BBR为精确算法。因为文献[11]中,IG算法设定的优化目标为工位数量而非工作站数量,所以此处IG算法的求解结果取自文献[12],而文献[12]的IG算法同文献[11],文献[12]中已做说明。本文算法在每个问题案例上运行20次,记录最好的求解结果,对比算法的求解结果取自相应文献。求解结果对比如表4所示,各个算法求解问题所能得到的下界个数对比如表5所示。 表4 求解结果对比 P2051 133111211—111111111111.250.191 27510———101010101010.050.051 32291110—9910999.100.091 4559———99999901 510898—889888.250.191 6508———88888801 699797—778777.250.191 888787877777701 9207———77777702 077676—66666602 1006———66666602 266676766666602 3006———66666602 4545656555555.600.242 5005———555555.050.052 643565655555502 8005———55555502 83255565555550 表5 求解结果达到下界的个数对比 由于本文算法采用Pytorch框架和Python编写,IG和BBR算法采用C++编程语言,考虑编程语言以及个人计算机性能的差异,此处没有比较CNN-PPO和IG,BBR算法的求解速度,但从求解结果上看,CNN-PPO算法求解性能优异,能有效求解双边装配线第一类平衡问题。 由表5可知,CNN-PPO算法在全部59个测试案例中,有57个可以达到下界,在对比算法中只有IG和BBR能够达到这一目标。而且从表4可知,CNN-PPO算法有12个求解结果优于TS算法,有3个求解结果优于SA算法,有15个求解结果优于LAHC算法,有4个求解结果优于MHH算法,可见CNN-PPO算法的求解结果同IG和BBR算法,优于SA,TS,LAHC,MHH算法,是目前最好的算法。对于P9,P12,P16,P24,P148问题,CNN-PPO算法在20次求解中均能得到当前最优解,方差为0。对于P65和P205问题,CNN-PPO算法也可为其所有案例求得当前最优解,只是求解结果稍有波动:6个P65问题案例中,2个案例20次求解方差为0,其余4个案例虽有方差,但是仅CT=512案例的20次求解方差稍大,为0.21(均值为5.30,14次得到结果为5,6次得到结果为6),剩下3个案例的20次求解方差均小于0.1;18个P205问题案例中,11个案例20次求解方差为0;其余7个案例方差均较小,最大仅为0.24(案例CT=2 454,20次求解均值为5.60,8次得到结果为5,12次得到结果为6)。以上结果充分说明了本文所提CNN-PPO算法求解的稳定性。 本文针对双边装配线第一类平衡问题,提出一种CNN-PPO深度强化学习算法,在原有PPO算法基础上引入CNN提升了智能体的数据特征提取能力。同时,根据双边装配线问题特征定义状态特征,采用独热编码将其转换为状态矩阵来描述双边装配线问题,引入标记层辅助智能体进行任务决策,并根据问题优化目标设计了奖励函数。 为测试本文算法的有效性,用其求解所有规模的标准案例,并将结果与现有6种优化算法进行对比。结果表明,在所有案列中,CNN-PPO算法能够获得当前最优解,而且相对于传统的启发式算法、元启发式算法、精确算法,本文所提基于深度强化学习方法的算法能够从历史求解经验中进行学习,更新任务分配策略的特性,发展潜力较大,在计算能力不断提升、大规模并行计算的背景下有很好的发展前景。另外,为了验证算法的稳定性,本文计算了所有问题20次求解结果的均值和方差,结果显示,在59个案例中,绝大多数(48个)案例的方差为0,剩下11个案例虽有方差,但均较小,6个案例的方差小于0.1,大于0.1的5个案例中,方差最大的仅为0.24,说明本文所提算法求解的结果波动较小,具有较高的稳定性。 本文所提方法目前只能求解双边装配线第一类平衡问题,未来可以考虑将其应用于解决双边装配线第二类平衡问题、再平衡问题等更加切合生产实际的问题。3 实验验证
3.1 模型训练



3.2 模型验证

4 结束语
猜你喜欢
中国新闻周刊(2023年42期)2023-12-03
汽车工艺师(2021年7期)2021-07-30
物流技术与应用(2020年5期)2020-06-25
意林(2020年10期)2020-06-01
制造技术与机床(2019年12期)2020-01-06
中国资源综合利用(2017年4期)2018-01-22
浙江大学学报(工学版)(2016年9期)2016-06-05
杭州(2015年9期)2015-12-21
焊接(2015年5期)2015-07-18
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
