
基于多智能体深度强化学习的无人艇集群博弈对抗研究
2024-03-14 03:42于长东刘新阳刘殿勇
水下无人系统学报 2024年1期
于长东 ,刘新阳 ,陈 聪 ,刘殿勇 ,梁 霄 *
(1.大连海事大学 人工智能学院,辽宁 大连,116026;2.哈尔滨工程大学 智能海洋航行器技术全国重点实验室,黑龙江 哈尔滨,150001;3.大连海事大学 船舶与海洋工程学院,辽宁 大连,116026)
0 引言
在现代军事研究领域,随着高新技术的快速发展,催化了战场中作战思想、理论和模式等方面的迅速变革,战争形态逐渐趋于信息化和智能化[1-3]。人工智能和无人系统技术为未来战争中的决策分析、指挥控制和博弈对抗等应用提供了更多智能决策和自主作战能力,逐渐扮演着更加重要的角色。其中,无人艇作为一种全自动小型水面机器人,具有体型小、机动灵活以及活动范围广等优势,在情报侦查、海上巡逻以及环境检测等领域发挥着重要作用[4]。
强化学习作为人工智能技术的重要分支,目前在无人艇、无人机等多智能体博弈对抗问题中具有重要的应用价值[5-7]。李波等[8]将多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient,MADDPG)算法应用于多无人机的协同任务研究,可以解决简单的任务决策问题。刘菁等[9]提出了博弈理论与Q-Learning 相结合的无人机集群协同围捕方法,结果表明该方法可以完成对单目标的有效围捕。Zhan 等[10]提出了多智能体近端策略优化(multi-agent proximal policy optimization,MAPPO)算法,用于实现异构无人机的分布式决策和协作任务完成。赵伟等[11]对无人机智能决策的发展现状和未来挑战进行了讨论和分析。相比之下,目前国内外对于无人艇的博弈对抗研究工作相对较少,仍处于发展阶段。苏震等[12]开展了关于无人艇集群动态博弈对抗的研究,提出利用深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法来设计策略求解方法,训练得到的智能体可以较好地完成协同围捕任务。夏家伟等[13]则使用MAPPO 算法完成对单一无人艇的协同围捕任务,通过结合围捕任务背景,建立了伸缩性和排列不变性的状态空间,最后利用课程式学习训练技巧完成对围捕策略的训练,结果表明所提方法在围捕成功率上相较于其他算法具有一定优势。
无人艇集群博弈对抗的研究工作仍处于起步阶段,存在较大的提升空间: 目前的研究中,无人艇博弈对抗中的敌方通常采用传统算法躲避我方的拦截围捕,缺乏智能化决策能力;其次,海上目标行为动作较为复杂,双方博弈过程中的当前决策需要充分考虑前后阶段产生的影响结果;此外,除需要围捕的动态目标外,海上还存在岛礁等障碍物,在博弈对抗中还需要考虑躲避岛礁障碍物等问题。
受到以上启发,文中以无人艇集群对敌方入侵岛礁目标进行围捕拦截为背景,开展基于多智能体深度强化学习的无人艇集群协同围捕研究。首先基于现代式作战需求,合理设计作战假想,建模相应的围捕环境;其次,采用MADDPG 算法求解策略方法,根据不同的围捕任务设计网络结构、奖励函数和训练方法;最后通过仿真实验表明,训练得到的我方无人艇经过博弈后能够有效完成对敌方的围捕拦截任务。
1 任务场景描述
海上无人艇集群协同围捕任务是一种典型的集群作战模式,如图1 所示,文中主要针对海上岛礁防卫任务场景展开研究。不同于离散化任务环境的方案,文中从实际作战角度出发,设计了连续的海上作战地图作为无人艇集群博弈对抗问题中的任务环境,即采用连续的空间坐标位置来表示敌我双方的位置信息。若干敌方无人艇会随机出现在某海域位置,对目标岛礁进行入侵进攻。而我方无人艇集群在岛礁周围进行常态化巡逻,当发现入侵敌方后,会迅速调整状态去拦截围捕敌方。

图1 无人艇围捕场景示意图Fig.1 Round-up scene of unmanned surface vehicles
无人艇的简化运动模型定义为
式中,(,)和 (,)分别表示2 艘艇的坐标位置。此外,我方无人艇在围捕敌方的过程中,考虑到实际无人艇发生碰撞的可能性,当我方各无人艇距离敌方目标点距离l小于围捕半径r时,则视为完成围捕任务。
2 博弈算法与训练策略设计
文中考虑深度强化学习在无人艇集群的博弈对抗策略上的应用。强化学习下无人艇与战场环境的交互过程如图2 所示: 无人艇根据战场环境的即时状态St,执行可以获得最大回报的行为动作At,以使得奖励Rt达到最大值。在选择行为At后,环境会给予无人艇Rt的奖励,同时环境进行到下一状态St+1。然后无人艇根据下一状态St+1和奖励的反馈Rt+1,选择执行下一个行为动作,进入下一轮的动态交互。
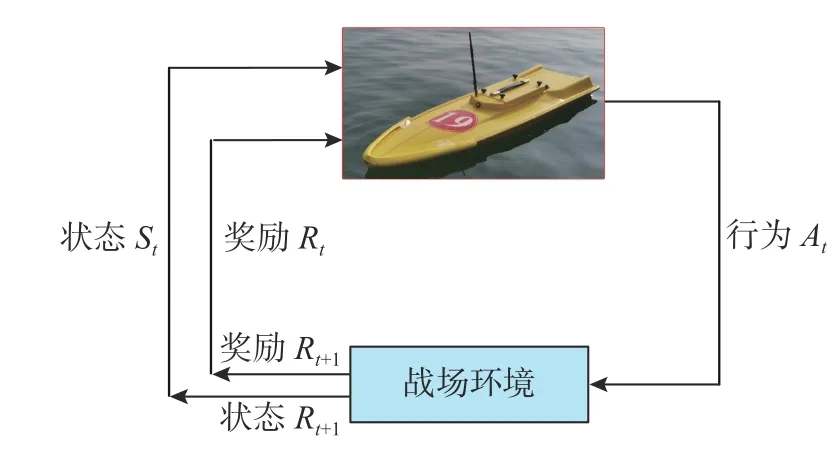
图2 无人艇与环境交互过程示意图Fig.2 Schematic diagram of the interaction process between the USV and environment
基于实际作战思想,在敌我双方的无人艇博弈对抗中,若一方的各无人艇处于协同合作关系,则对方的无人艇处于竞争博弈关系。针对该问题,文中选择了主流的群智能体强化学习算法——MADDPG 算法[14]。MADDPG 算法由DDPG 算法[15]发展而来,可有效缓解训练中的非平稳问题,提高学习效率。
2.1 DDPG 算法
DDPG 算法在网络结构上采用了基于“行动者-评论家” (actor-critic,AC)的框架形式[15],Actor网络基于当前智能体的状态信息,给出确定性动作策略,让智能体执行最优动作,同时通过策略梯度算法不断优化策略网络参数;而Critic 网络则对智能体基于当前状态的动作进行Q值评估,并根据智能体的实际收益,更新目标价值和网络参数,提高估计的准确性。
DDPG 算法的AC 网络受到深度Q学习的在线-目标双网络结构的启发,将在线训练方式转向离线训练方式,简化了许多复杂操作,同时也提高了数据的有效利用。AC 网络结构分别由2 个完全相同的深度神经网络组成,这2 个网络的作用是将输入的状态信息和输出的动作信息进行连续化处理,同时还能够将低维度的离散信息映射到高维度的连续信息空间中。图3 展示了 DDPG 算法的数据传递结构示意图[16],结构左侧为Actor 策略网络,通过策略梯度优化对网络参数进行优化,从而将状态信息映射到最优策略;然后网络根据策略输出确定性动作,并将其送入右侧的在线价值网络来预测状态-动作价值;在线价值网络则采用价值梯度来更新优化网络参数,将状态-动作组映射为价值函数;最后,采用滑动平均更新法对目标网络参数进行更新。

图3 DDPG 算法数据传递结构示意图Fig.3 Structure of data transfer of DDPG algorithm
2.2 MADDPG 算法
在多无人艇系统中,每个无人艇都是独立的智能体,由于各智能体同时受到环境和其他智能体的影响,使用单智能体强化学习算法无法有效处理复杂多变的多智能体环境,从而导致训练效果通常不理想。因此,文中采用了多智能体强化学习算法MADDPG 作为无人艇集群协同围捕方法。MADDPG 算法通过经验回放、目标网络和通信机制等方式来考虑前后阶段产生的影响问题,从而处理多智能体系统中的长时间依赖性和协作竞争问题。
MADDPG 在训练多智能体过程中使用了集中式训练和分布式执行方案,即训练中一方的所有智能体都共享全局信息,同时智能体可以并行地执行策略,从而加速学习过程。该方案可以使多智能体系统能够更好地协同学习和协调策略,提高训练效率和稳定性。MADDPG 网络中的数据传递如图4 所示,在更新网络的训练过程中,中心化的评价函数Critic 使用经验池中的联合经验数据来更新网络参数,而Actor 函数会依据 Critic 给出的Q值更新策略。当更新完成后,在实际执行阶段用更新后的 Actor 决策函数进行去中心化决策,即执行阶段仅使用自身的局部观察得到策略,这样能够有效减少复杂度和计算量。
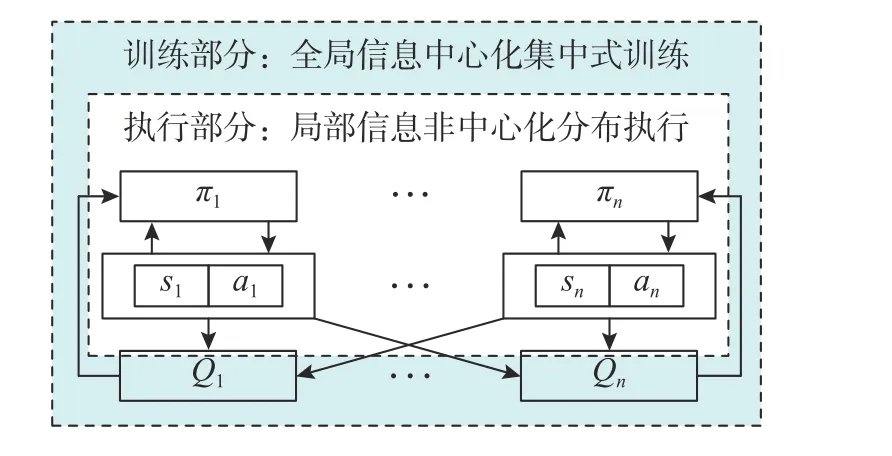
图4 MADDPG 算法数据传递结构示意图Fig.4 Structure of data transfer of MADDPG algorithm
MADDPG 算法的具体执行流程[16]如图5 所示。

图5 MADDPG 算法具体执行流程Fig.5 Execution process of MADDPG algorithm
2.3 任务决策与奖励函数设计
文中基于海上岛礁防卫任务展开研究。假设无人艇分别为USV1,USV2,…,USVk,每艘无人艇的自身状态空间Susv中不仅包括当前时刻的速度信息 (uk,vk),还包括在海洋环境中的坐标位置信息(xk,yk)。此外,环境状态Senv则包含了岛屿的坐标位置 (Dx,Dy),该岛屿位置既是我方保卫目标位置,也是敌方进攻目标位置。
文中的敌方艇也采用了智能化逃跑策略,因此文中敌我双方都采用了基于MADDPG 算法的博弈策略。在文中设计的 MADDPG 算法中,每艘无人艇的状态包括了环境状态、自身状态以及其他无人艇的状态。每艘无人艇在t时刻的状态定义为
此外,无人艇集群的友方之间可以获取角度信息 φi,该角度为我方2 个无人艇靠近敌方无人艇形成的夹角。无人艇的动作范围是二维的连续空间,采取确定性动作策略后,会在每一时刻输出瞬时速度 (ux,vy),无人艇经过 Δt时刻后的位置更新为,即
文中主要从以下2 方面来设计奖励函数。
敌方奖励函数设计如下:
敌方在运动过程中的奖励目标函数为Rr=其中di为第i艘敌方无人艇与目标的最近距离,距离越近奖励值越大;此外给与碰撞惩罚,当敌方碰撞到船只或岛屿时,惩罚为-5。
我方奖励函数设计如下:
3 实验结果与分析
3.1 模型参数设计
文中应用的MADDPG 算法模型使用了确定性动作策略,即a=πθ(s)。网络结构具体设计如下:当我方与敌方无人艇数量为3 对1 时,策略网络结构为[14;64;64;2]的全连接神经网络,价值网络结构为[14;64;64;1]的全连接神经网络,网络结构表示输入层、隐藏层和输出层对应的节点数;当无人艇数量为6 对2 时,策略网络结构为[26;64;64;2],价值网络的结构则为[26;64;64;1]。在训练时的最小批尺寸为512;训练3 对1 时最大回合数为5 000,训练6 对2 时最大回合数为10 000,价值网络的学习率为0.001,策略网络的学习率为0.001,2 个网络都采用了Adam 优化器进行训练网络,经验池的大小为5×105。
3.2 结果分析
文中分别进行了保卫岛屿场景下的无人艇3 对1 和6 对2 的博弈对抗实验。
1) 3 对1 实验
双方无人艇回报曲线如图6 所示。可以看出,双方回报值都呈现整体上升并增至最大值,然后趋于稳定。这说明双方处于一种互相竞争的状态,最终达到一种博弈平衡。从后期的回报曲线可以看出,我方无人艇的曲线分布一致且相对稳定,每艘无人艇均可完成围捕任务。
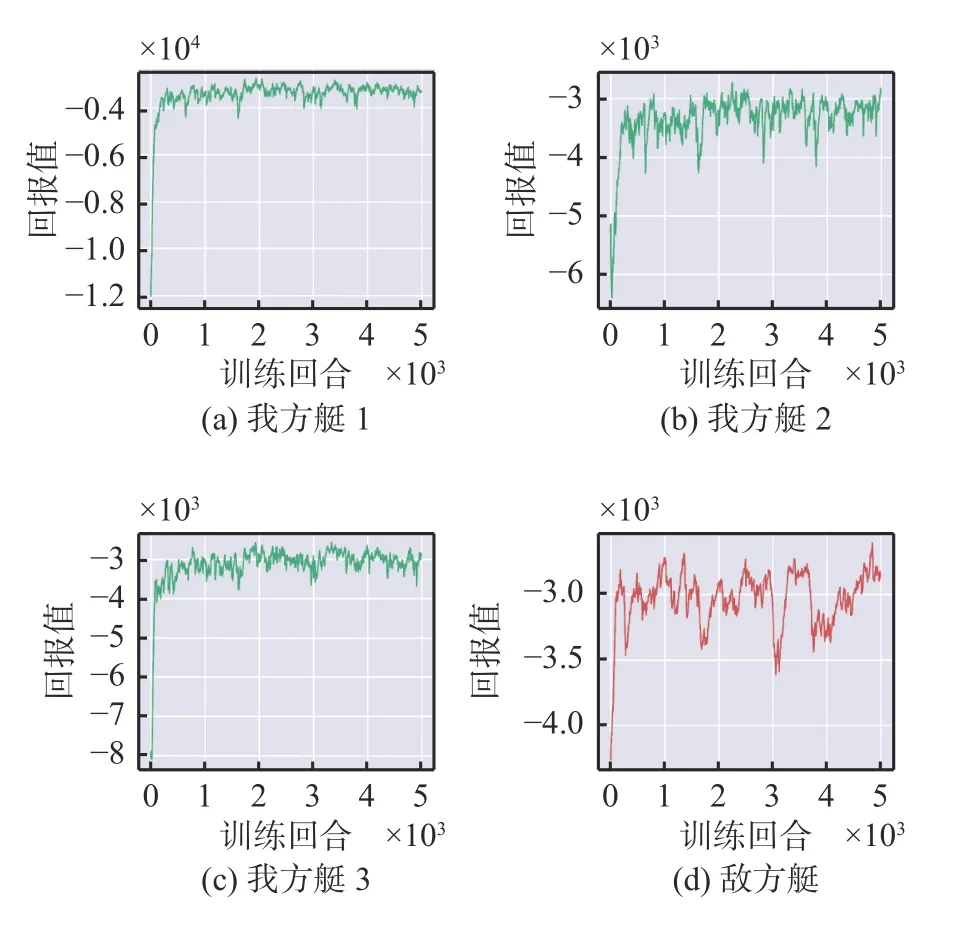
图6 3 对1 时各艇回报值Fig.6 Return values of the USVs at 3 vs 1
图7 展示了3 对1 时不同时刻的仿真结果。在初始时刻,我方无人艇围绕在岛屿周围进行巡逻,敌方无人艇随机出现在某一位置(见图7(a));随后,敌方无人艇对目标岛屿进行进攻,我方发现目标后,选择绕开岛屿障碍物,并对敌方进行围捕拦截(见图7(b)和(c));最后,我方无人艇对敌方无人艇进行包围,分散在其周围,并保持跟随,视为围捕成功(见图7(d))。
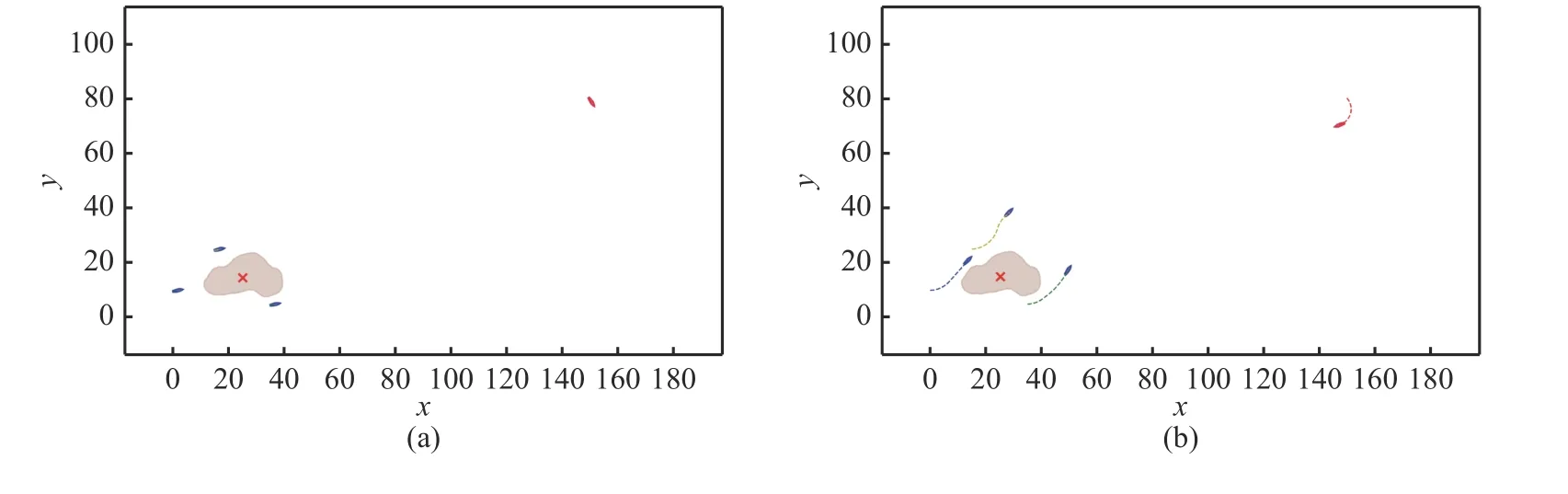
图7 3 对1 仿真结果示意图Fig.7 Simulation results of 3 vs 1
2) 6 对2 实验
我方6 艘无人艇所获得的回报曲线如图8 所示。可以看出,我方无人艇回报值均呈现上升趋势并最终趋于稳定状态。这说明无人艇集群在训练中得到了良好的收益,有效完成了任务目标。相比之下,敌方无人艇的回报曲线则先上升,之后出现了严重的波动,呈现不稳定现象,如图9所示。

图9 6 对2 时敌方各艇回报值Fig.9 Return values of enemy USVs at 6 vs 2
图10 展示了6 对2 时不同时刻的仿真结果。在初始时刻,我方6 艘无人艇分散在岛屿周围,敌方2 艘无人艇随机出现在不同区域(见图10(a));当发现敌方无人艇后,我方无人艇首先绕过岛屿,然后去围捕拦截敌方无人艇(见图10(b));敌方无人艇不断进行智能躲避,而我方充分考虑了敌方目前位置以及下一阶段的运动趋势,并在其周围展开围捕(见图10(c)~(e));最后,我方无人艇成功完成对敌方的围捕,以持续的围捕状态伴随在敌方周围(见图10(f))。

图10 6 对2 仿真结果示意图Fig.10 Simulation results of 6 vs 2
4 结束语
基于实际的海上作战背景,文中提出了基于多智能体深度强化学习方法MADDPG,用以解决无人艇群动态博弈对抗中的协同围捕决策问题。通过搭建模型,设计奖励函数和训练函数,完成实验。通过3 对1 和6 对2 的仿真实验,结果表明我方无人艇可以有效完成对敌方无人艇的围捕拦截,证明了所搭建模型系统的有效性,为未来实战的应用提供了技术支撑和理论参考。在未来的研究工作中,将会考虑采用更加高效的状态信息处理手段,例如文献[13]中的伸缩和排列不变性设计,以使同一个网络结构可以适用于不同数量无人艇的博弈对抗场景。
猜你喜欢
少林与太极(2022年6期)2022-09-14
趣味(数学)(2022年3期)2022-06-02
小哥白尼(军事科学)(2019年2期)2019-04-17
小哥白尼·趣味科学画报(2019年12期)2019-02-28
儿童时代·快乐苗苗(2018年7期)2018-09-03
无人机(2017年10期)2017-07-06
岷峨诗稿(2017年4期)2017-04-20
新高考(英语进阶)(2017年12期)2017-02-26
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
