
遗传算法优化BP 神经网络在水质评价中的应用
2024-03-14 08:48宋洁,冯青
甘肃科技 2024年1期
宋 洁,冯 青
(黄河水利委员会上游水文水资源局,甘肃 兰州 730030)
水环境质量评价是合理开发利用及保护优化配置水资源,提高水资源承载力的前提,水体中影响水环境质量的因素有很多,水质的评价等级和监测指标之间的关系异常复杂,存在不稳定性特征、非线性特征以及水质的模糊性等问题,所以早期的生物学评定法和专家评价法逐步被取代。目前常见的水质评价方法有:单项指数法、综合指数法、灰色关联分析法、模糊综合评价法、人工神经网络法等,其中绝大部分水质评价方法都是线性模型,相对简单快捷,但评价结果会有失偏颇,而人工神经网络法在处理非线性问题时有着绝对的优势,是比较前沿且应用较为广泛的水质评价方法。人工神经网络是20世纪50年代之后发展起来的适应性很强的交叉学科,它模拟了人脑的思维方式,目前用于水环境质量评价的人工神经网络多为BP 神经网络,它是一种前馈型网络[1]。
Rumelhart 和McCella 科学小组在1986 年提出的BP神经网络是一种反向传播(Back-Propagation)算法训练,它具有良好的自学习和自适应能力,免去权重的设计,从一定程度上减轻了水质评价工作量,评价结果不仅可以进行纵向比较且通用性很强。但随着研究的深入,网络收敛速度慢,初始权值、阈值确定难以及运算过程易陷入局部极值等都作为BP 神经网络的缺点显现出来了。本文用遗传算法对BP神经网络进行优化,解决了易陷入局部极值导致无法获得最优连接权系数和阈值的难题,并用MATLAB 软件进行训练,结合黄河上游部分断面的实际水体情况构建了水质评价模型,与常规的BP神经网络方法进行比较,对完善黄河流域水环境质量评价有着实际的应用价值。
1 BP神经网络
1.1 BP神经网络原理和模型结构
BP 神经网络主要是利用梯度下降算法让误差函数最小,过程分为信号的正向传播和误差的反向传播[2]。拓扑结构包括:输入层、一个或多个隐含层和输出层[3],如图1 所示,每一层都是由多个神经元构成,且相邻两层之间的神经元相互连接,但是同一层的神经元两两之间是没有任何连接的[4]。
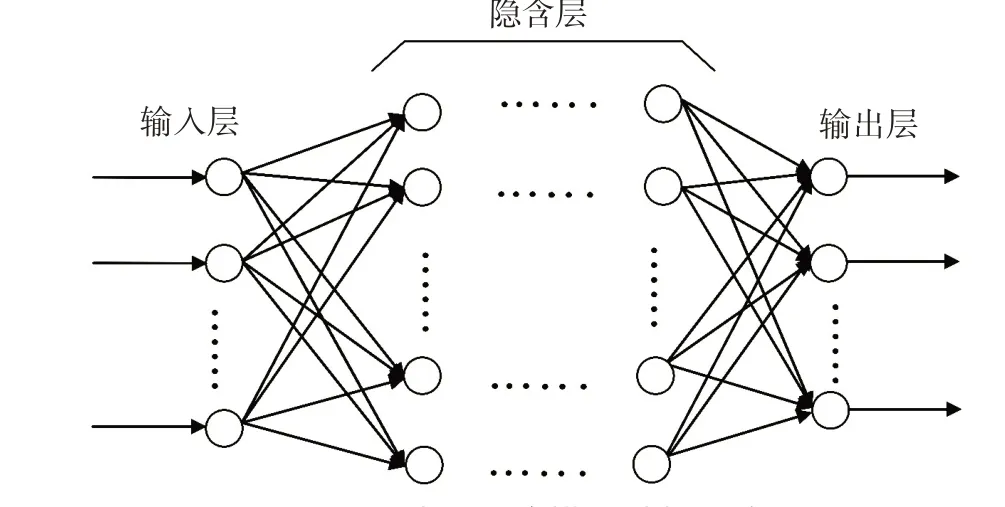
图1 BP 神经网络模型结构示意图
1998 年Robert Hecht-Nielson 证明了对任何在闭合区间内的连续函数,都可用只含有一个隐含层数的三层BP神经网络逼近[5]。
1.2 BP神经网络算法的弊端
作为一种有坚实理论依据和严谨推算过程的网络模型,它有着诸多显著的优点,如处理非线性复杂问题的能力很强,数据间采用并行处理方式,应用也较为广泛,但是在使用过程中,其自身也存在不足之处[6],主要有以下3点。
(1)BP 神经网络收敛速度慢:采用梯度下降算法,训练次数可能会达到几百至几千次迭代;
(2)易陷入局部极值:算法采用局部寻优,若初始点靠近局部最优点,则算法收敛并陷入局部最小值,导致网络训练失败;
(3)隐含层节点个数难确定:隐含层节点个数的确定通常都是靠经验和反复试验来确定,在一定程度上存在冗余性,影响其逼近能力。
这些自身缺陷使得传统的BP 神经网络在应用过程中受到诸多限制,严重制约着BP神经网络的研究和发展。
1.3 BP神经网络算法的改进
遗传算法GA(Genetic Algorithms)模仿自然界“适者生存,优胜劣汰”的进化机制[7-8],具有其他算法没有的鲁棒性、自适应性及全局最优性等特点。
本文用遗传算法对BP 神经网络的连接权进行优化,获得理想的权值分布。即先确定阈值和权值大概的范围,且在范围内随机产生多组数值并用实数进行编码,然后用选择、变异、交叉对遗传算子进化操作,产生新一代的父代,以个体适应度作为依据,再次进行选择、变异、交叉产生新的子代,如此反复直到满足最终条件,充分体现出遗传算法的全局搜索能力,获得最优阈值和权值。
1.4 遗传算法优化BP神经网络的工作原理
将遗传算法和BP神经网络相结合,对权值和阈值进行优化,其流程如图2所示。

图2 遗传算法优化BP 神经网络模型流程图
2 研究区域概况及数据来源
2.1 水域概况
黄河是中国第二大河,全长约5 464 km,流域总面积79.5 万km2(含内流区面积4.2 万km2),发源于青藏高原巴颜喀拉山北麓的约古宗列盆地,自西向东分别流经青海、四川、甘肃、宁夏、内蒙古、山西、陕西、河南及山东9 个省(自治区)[9],西界巴颜喀拉山,北抵阴山,南至秦岭,东注渤海。流域内地势西高东低,高差悬殊,形成自西而东、由高及低三级阶梯。黄河流域水资源的地区分布很不均匀,由南向北呈递减趋势。
黄河河源至内蒙古自治区托克托县的河口镇为黄河上游,河段长约3 472 km,流域面积38.6万km2,水多沙少是黄河上游的典型特征。黄河源头至兴海县的唐乃亥属于河源区,是重要的水源涵养地,湖泊较多,最大湖泊是鄂陵湖和扎陵湖,黄河河源段河谷开阔,冰川广布,水系发达,湖泊、沼泽众多,水资源丰富,长期未被开发利用,且人口稀少,主要以农牧业为主,水质较清,水流稳定,产水量大。唐乃亥以上至河源长度为1 552.4 km,集水面积121 972 km2,左岸有东科曲、切木曲,右岸有卡日曲、热曲、吉迈河、白河、黑河等,是黄河的天然水池。龙羊峡至刘家峡区间主要有洮河和大夏河,刘家峡至兰州区间主要有湟水和大通河。
为准确高效地监测出研究区域的水环境特征,要尽可能选择水流平稳,水面宽阔且顺直的位置,综合考虑选取黄河上游监测断面兰州、玛曲、小川、新城桥、民和断面,具体地理位置信息见表1。

表1 黄河流域各监测断面地理位置信息表
2.2 数据来源
为了尽可能完整地了解黄河上游区域的水质实际情况,取得最具有时效性和代表性的数据,设定一个季度一次的采样频率。结合近五年的整汇编资料以及黄河流域上游段的主要超标因子共选取化学需氧量、氨氮、总磷、高锰酸盐指数、五日生化需氧量、氟化物和溶解氧7 项指标。2021 年共采集了52个点的水样,其中兰州、玛曲、小川和新城桥断面均取左中右3 点,民和断面只取中点,共获得364组水质监测数据。研究时段内各断面各类水质指标的含量如图3所示。


图3 2021年各监测断面各指标含量
化学需氧量、氨氮、总磷、高锰酸盐指数、五日生化需氧量和氟化物指标均为浓度越大污染越严重指标,而溶解氧为浓度越小污染越严重指标。根据图3 可知:监测流域内化学需氧量含量在1 月份民和断面出现最大值;氨氮指标含量相对较小,绝大部分在0~0.40 mg/L 之间,仅在1月份民和断面出现最大值;总磷指标含量在7 月民和断面出现最大值;高锰酸盐指数指标含量在7 月玛曲断面出现最大值;五日生化需氧量指标含量在7 月玛曲断面出现最大值;氟化物指标含量在4 月民和断面出现最大值;溶解氧指标含量在7 月民和断面出现最大值。本文选取2021 年黄河流域各监测断面7 项指标的年平均数据为研究对象,具体数值见表2。

表2 2021年部分监测断面年平均数据 (单位:mg/L)
2.3 标准训练样本的生成
水质评价的本质是模式识别,也就是把评价指标实际检测结果和地表水标准限值进行比较,最为接近标准数值所对应的地表水环境质量等级即为BP 网络模型的识别结果。参照《中华人民共和国地表水环境质量标准》(GB 3838—2002)[10],仅能提供6组训练样本,很显然网络训练样本太少不具有说服力,不能真实反映出水体内部之间蕴含的规律,会导致模型识别精度低、泛化能力差,没有实用价值。所以本文选用随机插值的方法扩充了训练样本,生成规则见表3。

表3 训练样本生成规则
取0~0.2,0.2~0.4,0.4~0.6,0.6~0.8,0.8~1.0和1.0~1.5分别作为Ⅰ~劣Ⅴ类这6类水质的期望输出,每类标准分别生成30个样本,共生成样本数180个,构成模型需要的地表水环境质量标准训练样本。
由于各指标的量纲不同,指标之间具有不可公度性,所以,扩充后的训练样本不能直接进行比较,要进行标准化处理[11],扩充后的部分训练样本见表4。

表4 扩充后的部分训练样本
3 遗传算法优化BP 神经网络的水质评价建模
3.1 结构设计
结构的确定是建立网络模型的重点,神经网络结构是否合理直接影响着水环境质量评价结果的合理性和准确性。BP神经网络结构包括网络层数、输入层节点数、隐含层层数、隐含层节点数和输出层节点数这5个方面。
BP 神经网络输入层的节点数与训练样本的维数是密切相关的,如果训练样本维数过高,则会导致BP神经网络中数据训练的计算量过大,训练时间长且整个训练过程效率太低。所以在标准样本训练前要尽可能筛选出可靠、真实的数据来做BP神经网络的输入项。
选择了7项水质指标,因此,本次建立的遗传算法优化的BP神经网络模型的输入层包含7个节点,分别代表7项水质指标的年平均浓度值。
3.2 黄金分割算法确定隐含层节点数
隐含层节点数确定难是BP 神经网络的缺陷之一,目前,隐含层节点数大部分都是通过经验和多次试算选取的[12-13],在参阅相关文献的基础上,采用了黄金分割算法,通过在既定区间下寻找最优节点的方法,优化确定BP神经网络的隐含层节点数。假定BP 神经网络输入层的节点数是I,输出层的节点数是J,那么隐含层的节点数L取值范围是:
网络模型训练的精度是黄金分割算法判断BP神经网络优劣的依据,均方误差mse 值越小网络结构越优。同时,训练BP神经网络是为了确保训练好的网络模型对非训练样本具有好的泛化能力[14-15],所以,将总样本分成2个部分,即训练样本和测试样本。
采用MATLAB R2019b 构建网络结构,输入层到隐含层是非线性函数,隐含层到输出层则是线性函数。网络结构中设定学习速率参数是0.001,学习速率增加比例是10,期望值误差参数是0.000 01,BP神经网络最大训练次数是300。
在BP神经网络中即使网络结构相同,每次训练的次数和均方误差mse值都会不同,这是BP神经网络独有的特点,是由于网络模型每次开始训练时的阈值和权值不一样造成的,所以将BP神经网络多次训练取最好的一次结果记录即可。
依据输入层节点数7和输出层节点数1,确定隐含层最优节点数的大致范围是[a,b]=[4,18]。
第一个试验点位置确定:g1=0.618*(b-a)+a=12.652,取整为13,网络拓扑结构为7-13-1,记为模型BP1;
第二个试验点位置确定:g2=0.382*(b-a)+a=9.348,取整为9,网络拓扑结构为7-9-1,记为模型BP2;
将表3标准化后的180组数据作为BP神经网络模型的网络输入,分别对模型进行训练、迭代并达到稳定。比较试验结果E(g1)和E(g2),以此类推,拓扑结构不同时的网络模型性能见表5。

表5 拓扑结构不同时的网络模型性能对比
从表5中看出网络模型BP6在循环9次后收敛,均方误差mse值最小,即为遗传算法优化的BP神经网络的最优模型,拓扑结构是7-12-1,所以本文建立的水质评价模型中的隐含层节点数确定为12。
通过以上试验得出结论:运用黄金分割算法确定最优隐含层节点数时,只需要做6次试验,比试算法计算量小,比依据经验得到的网络结构更具有说服力。
3.3 参数设置和遗传操作
采用三层BP 神经网络结构,设定S1 是输入层节点个数、S2 是隐含层节点个数、S3 是输出层节点个数,那么网络模型中的编码长度S=S1*S2+S2*S3+S2+S3,根据确定的网络拓扑结构7-12-1,则编码长度S为109,权值为96,阈值为13。染色体编码方式用实数编码方法,取值范围(-1,1),选用算术方式进行交叉操作。设置初始种群取值30,遗传代数取值100,遗传操作选用最简单的适应度比例法,变异操作用非一致变异方法,调用MATLAB 软件的GAOT工具箱实现遗传操作如图4所示。

图4 遗传操作程序
3.4 优化网络阈值、权值
BP神经网络水质评价模型用遗传算法优化时,可以同时对阈值和权值一起进行优化。用MATLAB R2019b 软件,把前期的训练样本数据值作为输入,采用前面得到的最优网络拓扑结构7-12-1,同时用误差平方和的倒数作为标准优化阈值和权值,核心代码如图5所示。

图5 阈值和权值的优化程序
4 实例仿真
4.1 实际输出和期望输出的吻合度比较
本文中遗传算法优化BP 神经网络的拓扑结构为此前BP 神经网络的拓扑结构7-12-1,各参数设置均不变,将神经网络模型进行多次训练,保存均方误差值最小的网络,同时为了更加清楚地展现出优化后的网络模型训练结果,将样本数据的80%用于网络训练,剩余的用于网络测试。遗传算法优化后BP神经网络的误差平方和曲线图如图6所示,适应度曲线如图7 所示,图中的2 条线分别代表训练样本和测试样本。

图6 误差平方和曲线
从图6、图7 中看出:在遗传算法优化后建立的BP 神经网络模型中测试样本的实际输出与期望输出的吻合程度都是非常高的。
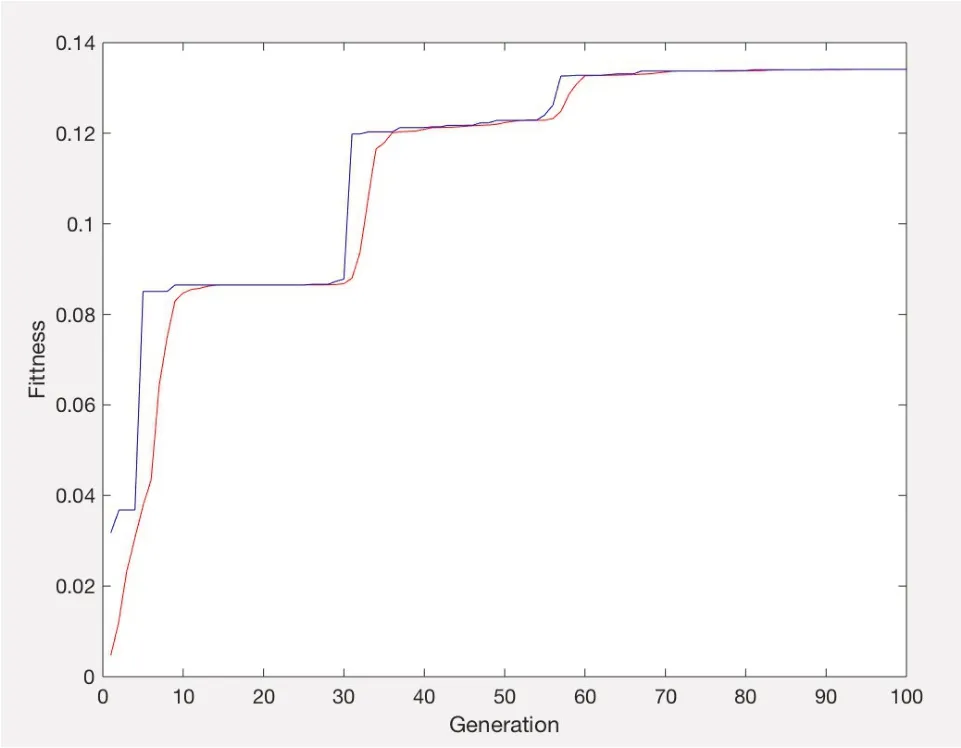
图7 适应度曲线
4.2 仿真结果及评价
应用所建立的遗传算法优化后的BP 神经网络模型对黄河上游5 个断面的水质情况进行评价,实例仿真测试性能如图8所示。

图8 水质评价仿真测试性能图
仿真测试得出:实例仿真模型经过106次循环后网络收敛,最终的均方误差为mse=0.000 009 85。模型试算后的仿真结果和水质评价类别见表6。

表6 遗传算法优化BP 神经网络模型的水质评价结果
遗传算法优化BP 神经网络模型对黄河流域上游段5个地表水监测断面的水质评价结果表明,这5个断面均未超过水域功能区3 类水标准,其中小川断面水质状况最优,水质评价类别达到Ⅰ类水标准;玛曲、兰州和新城桥断面水质状况次之,水质评价类别均为Ⅱ类水;民和断面水质状况最差,水质评价类别为Ⅲ类水。
4.3 与常规BP神经网络评价方法的比对分析
不同的网络模型根据网络训练过程中的步数作为依据来判断网络的收敛速度,它们在达到相同训练目标时,步数少的则网络收敛速度快,反之亦然。实例仿真中,遗传算法优化的BP神经网络模型和常规的BP神经网络模型训练误差曲线如图9所示。

图9 不同的网络模型训练误差曲线图
从图9对比后得出结论:遗传算法优化后BP神经网络模型的收敛步数为106,而常规BP神经网络模型的收敛步数为198,也就是说,当常规的BP 神经网络模型训练次数为198时才达到网络训练误差目标0.000 01,而遗传算法优化的BP神经网络模型只需训练106次就可以达到和常规BP神经网络模型一样的训练目标,网络模型的收敛速度得到了非常明显的提高。2种模型的水质评价结果见表7。

表7 2种模型的水质评价结果比对
依据表7得出以下2点结论:
(1)各断面各指标全年中实际监测数据变化波动不大时,遗传算法优化的BP神经网络模型仿真结果和常规BP 神经网络模型仿真结果一致,如兰州、玛曲、小川和新城桥断面;
(2)各断面各指标全年中实际监测数据变化波动较大时,遗传算法优化的BP神经网络模型仿真结果优于常规BP神经网络模型仿真结果,特别是全年监测结果中极值突出时,如民和断面,常规BP 神经网络模型仿真结果输出为0.623 6,评价类别为Ⅳ类水,而遗传算法优化的BP神经网络模型仿真结果输出为0.537 2,评价类别为Ⅲ类水,该断面的主要污染因子是化学需氧量和氨氮指标,且仅1月出现极大值。
出现这种情况的原因主要是:常规BP神经网络模型学习训练时收敛速度较慢,在目标函数复杂的情况下,会存在麻痹现象,出现一些平坦区,在这些区域内,权值误差改变很小,训练过程几乎停顿,即不能保证收敛到最低点,易陷入局部极值。综上所述,遗传算法优化的BP神经网络水质评价模型仿真结果更符合断面水体的实际情况。
5 结论
常规BP 神经网络模型虽然具有很好的非线性映射和学习能力,但存在确定模型结构过程繁琐,网络收敛慢和初始权值、阈值确定难,易陷入局部极值等问题,而遗传算法恰好拥有很好的优化搜索能力,所以,经对BP 神经网络和遗传算法深入研究后,提出将二者结合起来,取长补短,建立了遗传算法优化后BP 神经网络的水质评价模型,并借助MATLAB 软件编程实现网络权值和阈值的优化,对模型进行训练,应用于黄河流域上游部分断面的水环境质量评价中,验证了模型的实用性和精确性。研究结果表明,遗传算法优化后BP神经网络具有可行性和有效性,能科学、客观、准确地反映出研究水域的实际水体情况,在一定程度上改善了传统评价方法的片面性和主观性,对现有的水环境质量评价方法的改进起到了积极作用,为黄河流域水环境保护工作提供了一定的数据依据和技术支撑。
猜你喜欢
科技创新与应用(2020年6期)2020-02-29
环境保护与循环经济(2017年7期)2018-01-22
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
北京理工大学学报(2016年6期)2016-11-22
西藏大学学报(自然科学版)(2016年1期)2016-11-15
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
水利科技与经济(2016年9期)2016-04-22
