
以对比学习与时序递推提升摘要泛化性的方法
2024-03-19 11:47汤文亮陈帝佑桂玉杰刘杰明徐军亮
重庆理工大学学报(自然科学) 2024年2期
汤文亮,陈帝佑,桂玉杰,刘杰明,徐军亮
(华东交通大学信息工程学院,南昌 330013)
0 引言
生成式文本摘要领域如今已有很多大型的Se-q2Seq模型,从最初循环神经网络的提出标志着生成式摘要模型雏形的诞生[1],到LSTM[2]和GRU[3]等模型的出现,缓解了数据时序性对于文本长度的依赖问题。后来有指针网络(PN)[4]和指针生成网络(PGN)[5]的提出,有效解决了OOV(out-of-vocabul-ary)问题,又随着基于注意力机制的Transformer[6]问世,模型对于文本特征提取达到了一个前所未有的高度,使得自然语言处理领域的模型进入了一个新纪元。随后对于通用的自然语言任务场景的特征提取诞生了不少大参数量的模型,如基于Transformer编码器结构的BERT[7]能够充分获取文本的上下文信息,也对文本生成任务提供了巨大帮助;X-LNet[8]在大量无标签数据中训练,从而能够有效避免训练过程中的偏差问题;基于Transformer解码器结构的GPT模型[9],其解码器的特点使得GPT能够在文本生成类任务上有着极佳的表现。
以上提到的诸多模型都是基于传统神经网络模型构建和训练的,通过模型的输出结果与标签以极大似然估计的方式来构建损失函数。同时,对于传统深度神经网络模型的改进方法都已十分成熟,因此想从优化模型本身结构的方式入手来优化文本信息的特征提取不是一件容易的事情。
但传统训练方式往往会导致模型的泛化性无法达到最佳,SimCLS[10]和BRIO[11]通过构建多个候选摘要的方式,将候选摘要按照某种分数排序[12],利用候选摘要的句间信息构建对比损失函数[13],使得模型的泛化性得到提升,从而在测试集上取得更好的效果。
通过候选摘要间对比损失的训练方式(每一个候选摘要都会以分数高于自身的摘要为正样本,分数较低的作为负样本)虽然能让模型的泛化性得到提升,但当分数较高的正样本与参考摘要内容差距较大或者与负样本内容差距较小时就会“误导”模型在文本生成中g(ci|D;θ)→ci+1的能力,从而导致生成的文本准确性降低,其中g表示模型,D表示原文档,θ表示模型的参数,ci表示任意一个候选摘要的第i个词元。
为了缓解上述训练方式的“误导”问题,提出了3种解决方式使得模型在提高泛化性的同时,能够提升解码器输出的候选摘要与其对应候选标签的文本相似度。
方法1:通过构建反语意文本,替换候选集中的原文本来增大正样本与负样本间的距离,将分数越低的样本以更大概率“反语意”化,达到负样本“更负”的效果。
方法2:从候选集句间的关系层面控制准确度,在Seq2Seq模型输出的概率分布中,不仅是选取候选集中每一个句子对应的标签概率来计算句子之间的对比损失值,还以贪心搜索的方式计算每一句摘要输出的最大概率值的词元来计算对比损失值,从而进一步提升泛化性。
方法3:从每一候选摘要句内词元层面细粒度控制准确度,使每一个候选摘要的时序概率最大化。与传统极大似然估计不同的是,该方法通过构建递推关系式xi=f(xi-1),降低对当前词元本身概率值的关心度,更在意对于任意摘要的第i个词元,在前i-1个词元推理正确的情况下,使第i个词元的分数最大化,从而保证在推理过程中每一个时间步的准确性。
1 基线模型与训练方式
无论是基于Transformer结构的模型、图神经网络模型[14]或者文本卷积模型[15],其核心应用都是以不同的方式提取文本特征[16]。
从基础模型的角度来说,基于Transformer的大模型结构在文本生成任务中的效果远远优于现有的图结构和卷积网络结构。因此,本文选择的2个基础模型正是基于Transformer结构的较大体量的模型。
1.1 基线模型
选取以双向自回归方式训练的BART[17]和以掩盖式语言建模MLM(mask languagemodel)训练的PEGASUS模型[18]作为基础模型。
其中,BART是FaceBook在CNN/DailyMail数据上微调的BART-LARGE(406.29 M参数量)和Google在Xsum数据上微调的PEGASUS(569.75 M参数量),并且以Rouge[19]分数作为主要评价指标。
表1所示的是多种结合Transformer结构的模型分别在CNN/DailyMail(CNNDM)和Xsum数据集上的Rouge分数,其中R-1、R-2、R-L分别表示Rouge-1、Rouge-2、Rouge-Lsum。
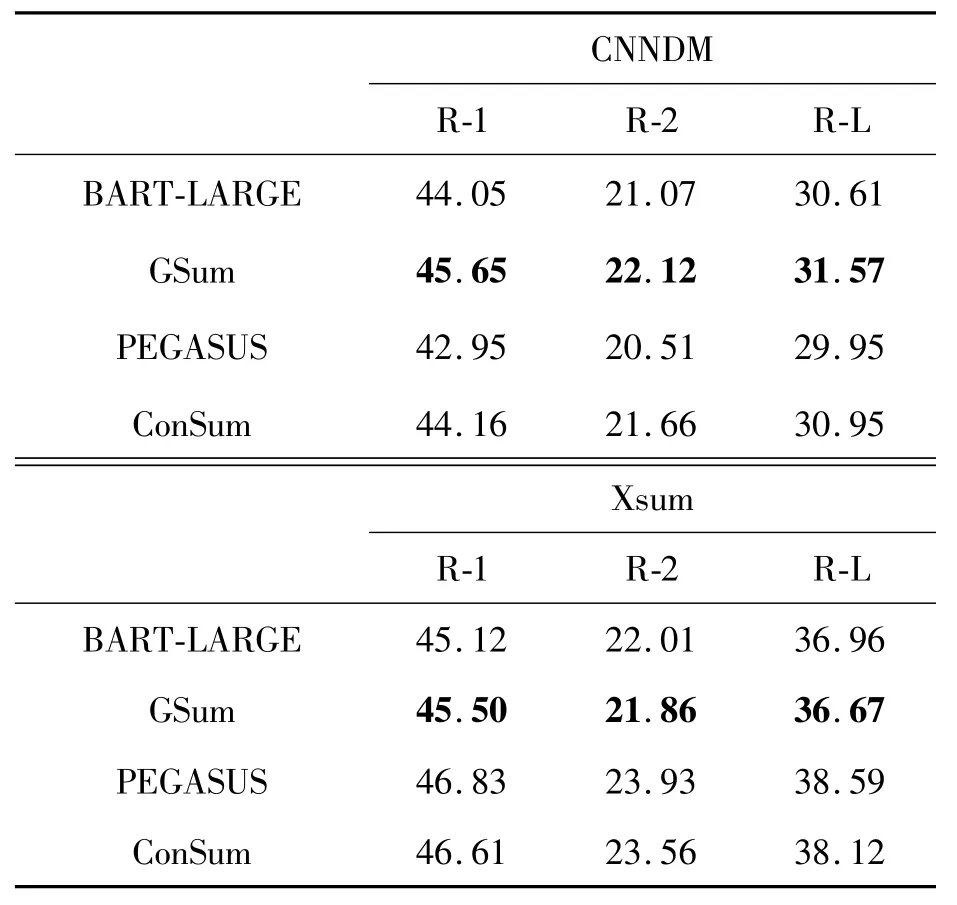
表1 基线模型的Rouge分数(采用F1分数作为指标)
1.2 训练方式
1.2.1 训练流程
如图1所示的是本次实验的整体训练流程①本次实验的源代码、模型和实验结果提供在https://github.com/cq-cdy/ecjtu-brio-improved。,首先将CNNDM和Xsum数据集分别经过基础模型BART-LARGE和PEGASUS,以beamwidth=N和随机采样等方式生成候选摘要,并且与参考摘要一同并为候选集标签,即整个候选集的摘要数目为1+N。
将候选集输入解码器得到整个候选集的概率分布,图1中wi表示每一个词元级别的概率分数值,pi表示每一句摘要的评估分数,将在后文从每一个候选摘要输出的概率分数入手,对整个候选集的输出进行约束。
1.2.2 数据增强
此前,Gao等[20]在SimCSE中提出了一种仅对原文档做Dropout的数据增强方式来构建对比学习的正负样本,但此方法对于增大正负样本的距离有一定的局限性。
由于本文在与基线模型相同的数据集上微调,因此在进行训练时需要对数据加入噪声,尽量增大负样本与正样本的距离。将候选集从解码器输入时,都会在给定原文档D的情况下,输入标签词元ci来预测下一个标签词元。
当候选集数量足够多时,那么候选集间的词元在随机采样和beamseach的驱使下就有着足够的相异性,但所有候选摘要的语意方向却趋于一致,因此采用前文所提到的方法1以反语意替换的方式进行数据增强,使得文本生成存在2种输出方式:
其中,c*表示反语意样本,且按照候选摘要与参考摘要的某种分数对整个候选集进行排序的情况下,排序越靠后的摘要与参考摘要的分数差距越大。
将分数排名越靠后的候选摘要以更大的概率进行反语意文本替换(如图2所示),从而更加体现出分数较低的候选摘要作为负样本出现的作用。且图中的n表示该摘要的排名,N表示候选集总数,p(n)表示第n个摘要进行反语意替换的概率。
2 损失函数设计
大多数Seq2Seq模型都使用模型预测的词元和标签词元来构建基于最大似然估计的损失函数。然而,传统的训练方法仍然存在过拟合问题,为了提高模型的泛化性,可以通过生成更广泛概率分布的候选集来扩展词元空间。
图3所示的是整个候选集输出的概率分布图,其中红色轮廓代表某一个时间步的概率值最大的词元,绿色填充表示该摘要的候选标签对应的概率值,纵向实线表示损失函数,纵向虚线表示损失函数(将在后文对和进行介绍)。
将两两相异但语意相近的摘要作为标签输入模型进行训练,同时将候选集按照Rouge分数降序排序,建立摘要间的对比损失函数来提高模型的泛化性,并建立对于候选摘要的时序信息的递推损失函数来保证整个候选集输出的准确性。
对于某一句文本长度为l的候选摘要C(c1,c2,…,cl),其中ci(0<i≤l)是模型中每一个词元在全连接层输出的词典大小的对应标签概率值,且对每一个候选摘要的词元取得概率分数:
2.1 对比损失函数
在候选集中,取Rouge分数较大的作为正样本,较小的作为负样本构建对比损失,第i和j个摘要的概率分布中所对应的候选标签概率分数均表示为β(α1,α2,…,αl),于是两句摘要的对比损失函数为[21]:
式中:表示第j个候选摘要中所对应的候选标签概率分数,λij=(j-i)*ε,ε为超参数。式(2)中仅仅考虑了每一个候选摘要的标签概率分数,但在原有的模型输出中,并非所有的预测词元概率分布和标签一致。预测的最大概率分数和标签分布不一致的词元,在对比损失函数中计算正负样本的距离会有所偏差,因此以方法2的方式在模型预测的概率分数上也加以约束,即对于候选集C,有γi=argmax(Ci),1≤i≤N,对于每一个候选摘要γ(α1,α2,…,αl)的概率分数构建损失函数为
则取得整体候选集的对比损失函数:
其中,对于每一个摘要的概率评分函数有:
式中:q是对摘要长度进行奖惩的超参数;|C|是摘要长度。需要注意的是:在计算摘要间的对比损失时,更在意的是候选摘要间的整体分数关系,而没有在意生成词元的时序关系,并对每一个长短不一的候选摘要都给予了固定的惩罚参数。
2.2 词元时序递推函数
在对候选摘要进行细粒度控制的同时,仍需要将原始参考摘要作为重点,因此保留对于原始参考摘要的基于传统极大似然估计的损失函数[22]:
其中:
式中:R(C)表示候选摘要的Rouge分数;η是固定的常数值,且0<η<1,BRIO中采用的损失函数为
仅采用式(8)损失函数面对的问题,在计算候选摘要间损失函数时以式(5)作为评分函数,单个摘要的分数仅为每个词元的概率分数之和,这样的计算方式在句内缺失时序信息的同时,若相邻或相近的候选摘要词元差别过大,则会导致候选摘要之间的错误引导而降低模型生成文本的准确性。
在N个已排序摘要中,以1号和2号候选摘要为例,有ROUGE(C1,Cref)>ROUGE(C2,Cref),希望的是在计算排序相近或相邻摘要的对比损失时,同时满足和
但h(C)函数并没有计算各自候选摘要句内的时序信息,在不同摘要间计算对比损失的同时,可能会导致出现不同候选摘要间标签的错位引导,尤其是当C1和C2文本内容差异较大时。
为了解决此问题,前文中所提到的方法3设计出应用于每个候选摘要句内的递推关系式,使得每一时间步t的概率分数都来自于前t-1时刻的所有概率分数的递推数值:
式中:f(x)为单调函数,且,同时为了保证t时刻的递推数值[1,t-1]时间段的适度影响,应满足,保证f(x)在x>0时为单调递增的凸函数。
通过beamsearch和随机采样所生成的候选集文本长度不一,并且在推理过程中时序递推函数并不在意当前词元本身概率分数的大小,因此在以mini-batch形式对整个摘要进行时序递推时,不适合如式(5)那种直接加入长度奖惩的超参数q,而应该在t时刻的预测正确的情况下,鼓励后续时刻的正确的递推数值。
因此,在句子长为l的摘要中,当不加入长度惩罚项时整体的递推值,即对于f(x)满足x >0时,对于每一个时间步t,当时,会对每一个独立摘要t+1时刻的词元生成做出鼓励;当时,会对每一个独立摘要t+1时刻的词元生成做出惩罚。
如图4所示,有区域S={Ⅰ,Ⅱ,Ⅲ,Ⅳ,K},f1(x)和f2(x)表示不同递推函数,从图像面积与时序t的关系来看,以的值来控制每一时刻的长度奖惩效果。
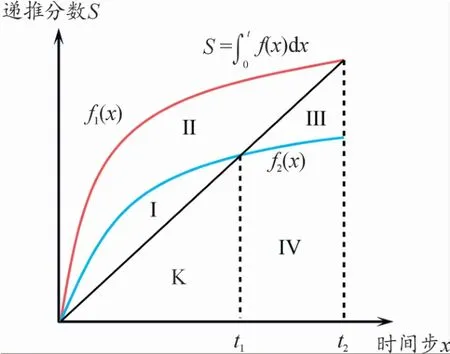
图4 候选集在时序递推函数损失L lp对生成文本的长度奖惩变化示意图
例如,F(K∪Ⅲ∪Ⅳ,t2)表示无长度奖惩的递推值;F(Ⅰ∪Ⅱ,t1)表示在当前时刻会对下一时刻的词元生成带来奖励效果;F(K∪Ⅳ,t2)会对下一时刻的词元生成带来惩罚效果。
在本次实验中,对于不同抽象程度的数据集应用了2种不同的词元损失函数形式,其中对于格式较为规整的数据集采用:
对于文本内容较为抽象的数据集则采用:
算法1对候选集的正负样本进行循环计算。
输入:[原文档D,候选集C(C1,C2…CN),候选集对应标签在字典中的索引index,基础模型g,超参数margin:ε]。
输出:对比损失与时序递推函数数值。
符号说明:

3 实验细节
本次实验采用的显卡为NVIDIA Tesla A40,且BART-LARGE与PEGASUS的预训练模型均来自transformers库。
3.1 数据集处理
CNNDM和Xsum都是来自datasets库的公共英文新闻数据集,且Xsum更偏向于抽象的文本极限压缩摘要。
通过BART-LARGE和PEGASUS模型分别对CNNDM 和Xsum 的训练集生成候选摘要,以beamwidth=16生成的候选集预存入文本中,数据集的数量如表2所示。
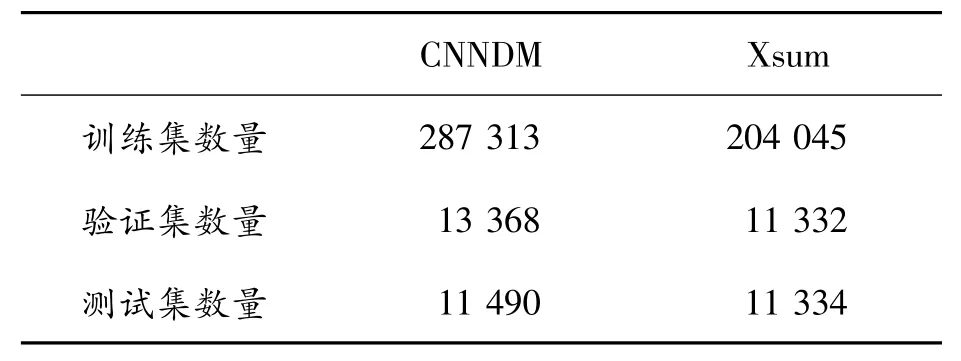
表2 数据集详细数量
3.2 参数设置
由于CNNDM和Xsum数据集及各自基础模型的参数量不同,因此提供如表3中不同的参数来达到本次实验的效果。
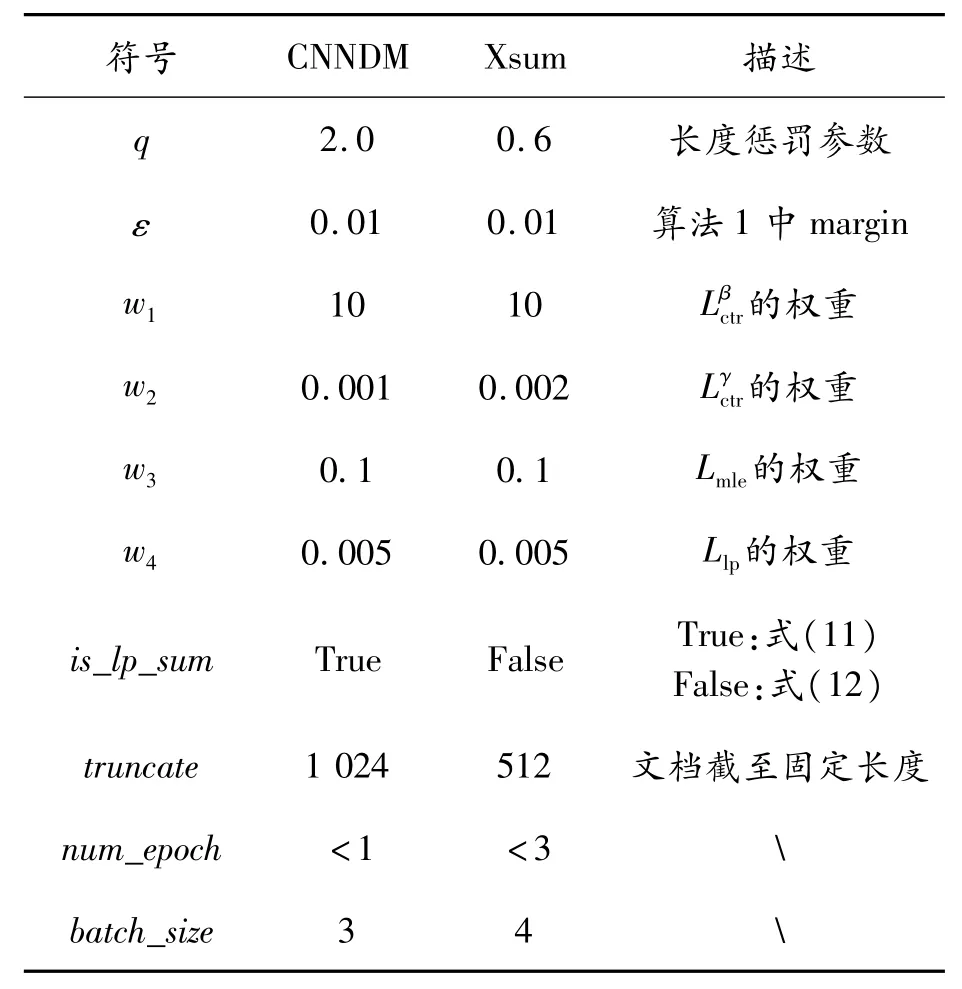
表3 实验中的各项参数设置
3.3 实验结果
将本文的训练方式Lctr+Lmle+Llp与BRIO的训练方式+Lmle进行对比,并从 Rouge、BertScore、余弦相似度3个指标进行评估。
3.3.1 Rouge分数评估
如表4所示,式(13)的训练方式在式(8)的基础上有了明显提升,同时为了更加体现出模型泛化性能的提升,如表5所示,本文通过不同的beam width在测试集上对生成的文本Rouge分数进行评估。
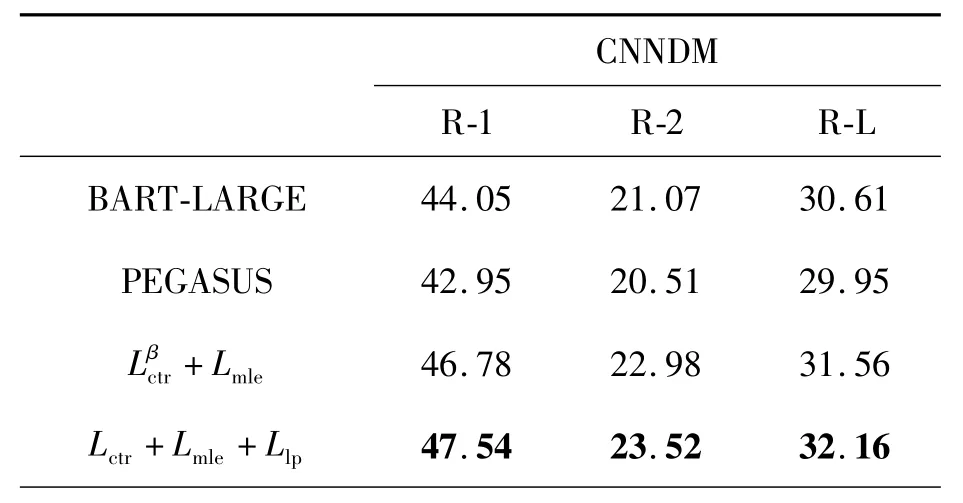
表4 式(13)训练方式在不同模型与数据集上的Rouge分数
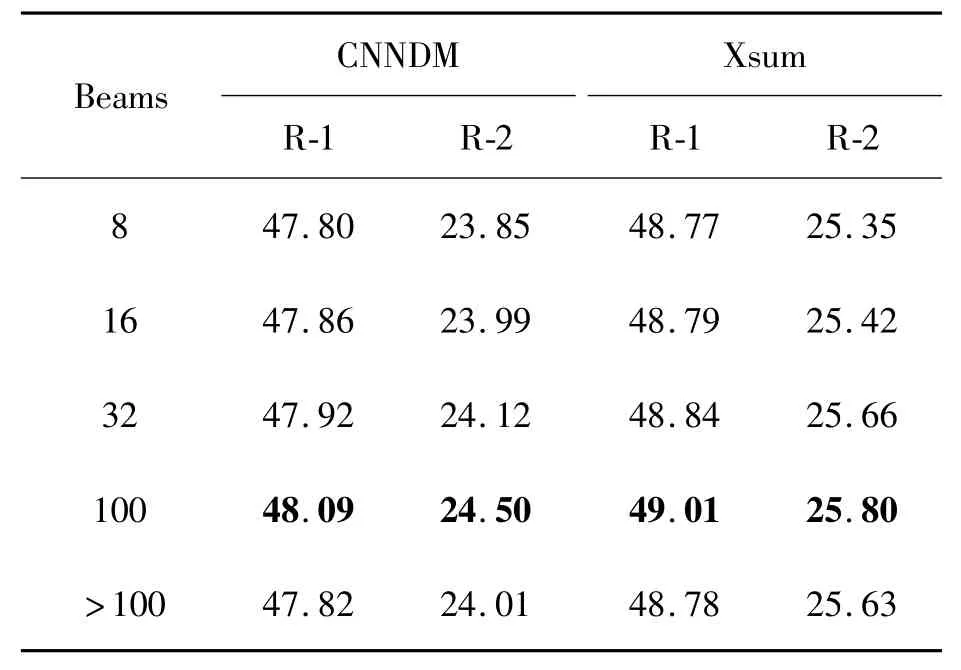
表5 式(13)训练的模型以不同beamwidth在测试集上的表现
3.3.2 BertScore与余弦相似度
Rouge分数并不是评价文本生成质量的唯一标准,Rouge更在意的是生成的文本与参考文本n-gram的重合度,使用Rouge分数评价生成文本质量的同时,引入BertScore[21]和余弦相似度来评估文本的语意分数和文本相似度,文本余弦相似度的计算方法为
式中:hyp表示训练后的模型生成的摘要;Cref表示参考摘要;l表示摘要长度。
如表6所示,体现本文提供的训练方法不仅仅是在意每一个词元及其时序上的准确性(COSSIM),还要能在提升泛化性的同时,保证语意的完整性(BertScore)。
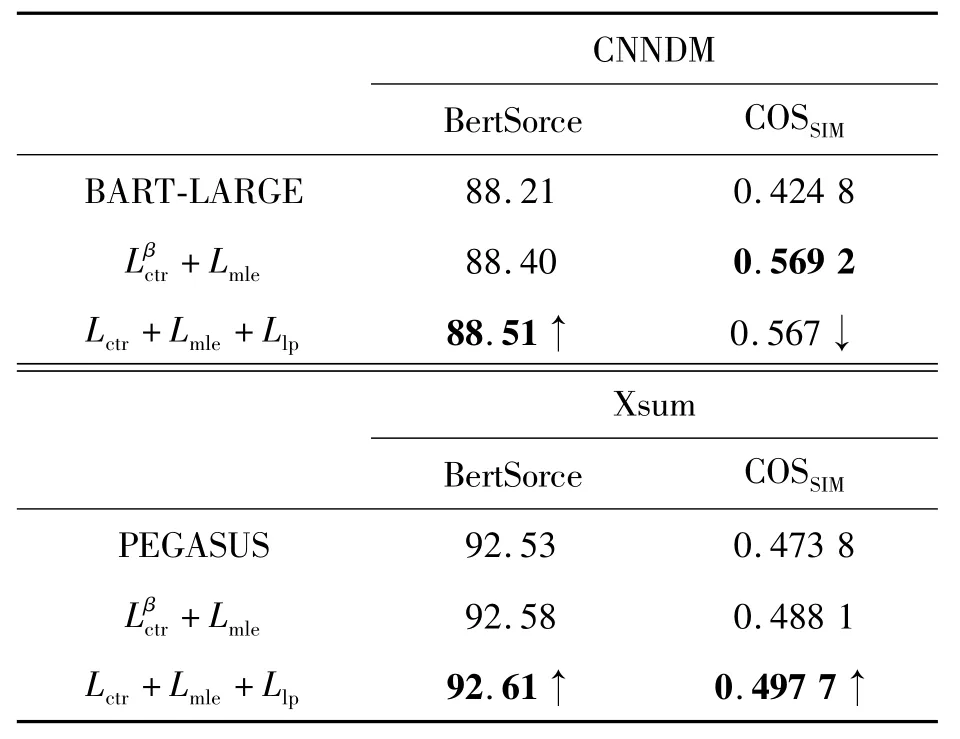
表6 采用BertScore和余弦相似度(COSSIM)对生成文本进行语意和文本相似度的评估
针对式(13)和式(8)的训练方法,在图5中给出生成文本与参考摘要之间的余弦相似度[22]和Rouge分数之间的对比,COS表示文本余弦相似度,OURS表示以式(13)训练后的模型,对于模型生成的文本T有:当ROUGE(TOURS<TBRIO)在y=x轴的上方时,其TCOS值变化较为平缓,且部分COS(TOURS>TBRIO);当ROUGE(TOURS>TBRIO)在y=x轴的下方时,其TCOS值变化较为明显,且有不少样本跨越了1~2个虚线跨度。即本文的训练方式使得模型在提升泛化性的同时是按照标签词元准确性和标签的时序准确性方向提升Rouge分数的,且在抽象数据集中的摘要关键字提取效果更佳。式(8)和式(13)训练出的模型生成的文本各1 000条,横轴和纵轴分别表示从式(13)和式(8)生成的文本Rouge和余弦相似度数值(数值范围均∈(0,1))。
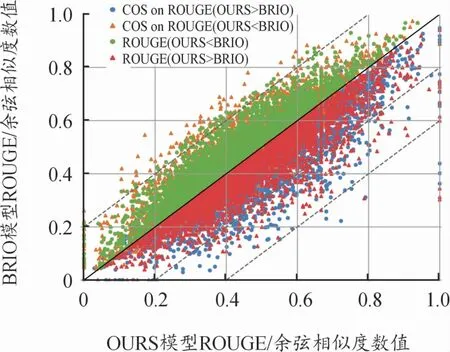
图5 Rouge和余弦相似度值示意图
3.4 损失函数变化分析
本文的主要方法是构建不同的对比损失函数,通过对整个候选集的概率分布的约束提高模型的泛化性,因此在式(8)和式(13)的训练过程中,其损失函数的变化趋势能够反映出模型在训练前后泛化性上的差异。
图6是在CNNDM数据集采用Lctr+Lmle+Llp情况下训练过程的损失函数变化曲线,且训练的规模在1个epoch以内,由于该数据集的文本格式相对长且规整,因此Llp采用式(11)的形式,可以看出相较于抽象的Xsum数据集,整体候选摘要的Llp损失函数有明显下降的趋势。

图6 CNNDM损失函数曲线
图7是Xsum采用Lctr+Lmle+Llp情况下训练损失函数变化曲线,训练规模在3个epoch以内,因为在Xsum数据集中的文本具有较高的抽象程度,因此在选择Llp损失函数的形式时选择式(12)的形式。
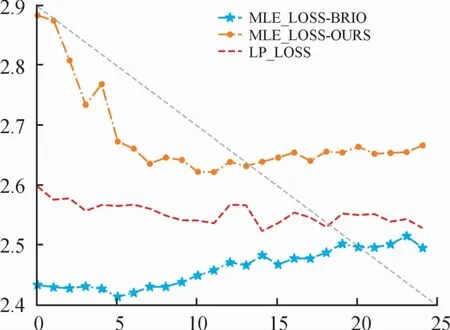
图7 Xsum损失函数曲线
在以式(13)的训练过程中,对比采用式(8)训练过程中参考摘要的Lmle损失,加入、Llp损失之后,参考摘要的Lmle损失在整个训练阶段明显增高,但整体候选集的Llp时序损失值下降,即降低模型在训练过程中对于参考摘要的依赖性,更在意整个候选集的时序准确性,使得模型的泛化能力提升的同时保持与候选标签之间的相似度。
如表7所示的是以本文训练方式的模型在部分测试集上所生成的摘要对比,可以看出,加入Llp进行训练后,有效缓解了文本生成过程中曝光偏差问题。
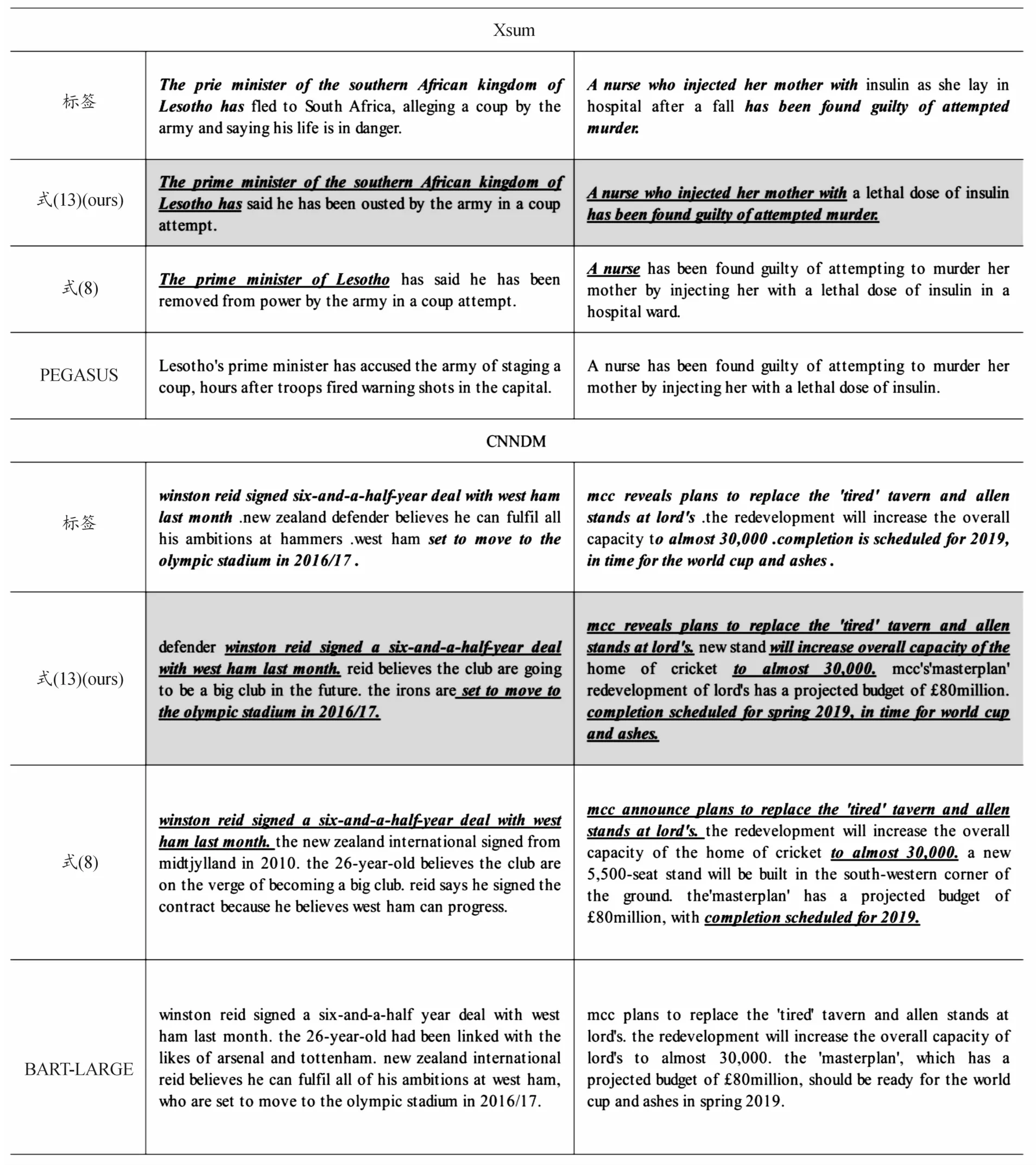
表7 式(8)和式(13)训练的模型与BART-LARGE/PEGASUS在CNNDM和Xsum测试集上生成的文本效果对比
4 结论
提出了一种新颖的训练方法,基本思想是通过构建候选集来扩展神经网络输出的词元概率分布。针对每个候选摘要,计算其概率分数,充分利用整个候选集语义空间中的概率分布构建摘要的正负样本,并采用对比学习的方式,使模型在相似的语义空间中能够更好地拟合不同的文本序列,从而提高模型的泛化性能。同时,本文中提出的时序递推函数确保候选集在推理过程中每个时间步的预测准确性。
从Rouge、BertScore等多个评估角度进行验证,证明了该方法在提升模型的泛化性能和准确性方面的有效性,并在对摘要内容和标签准确度要求较高的应用场景中有着积极作用。也为大模型时代的研究者提供了一种有效且可靠的模型训练方法。
对于此课题后续的研究,可以选择非Transformer结构的模型(如GNN和文本卷积网络等)作为基础模型,采用本文中的方法进行训练,并与结果进行比较。此外,本文中对于候选集的生成方式相对单一,可以尝试使用不同的模型(如T5、RoBERTa模型等)来生成候选摘要;候选集排序方式也可以不仅仅依赖于Rouge分数,还可以根据不同的应用场景和数据集,尝试设计不同形式的时序递推函数,控制整个候选集在推理过程中概率分数的变化趋势。
猜你喜欢
中国农业信息(2023年3期)2023-03-18
中国农业信息(2021年3期)2021-11-22
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
电子制作(2016年15期)2017-01-15
公民与法治(2016年10期)2016-05-17
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
计算机工程(2015年8期)2015-07-03
