用于组织病理图像分类的双层多实例学习模型
2024-03-20 10:32陆浩陈金令陈杰陈百合唐卓葳
中国图象图形学报 2024年3期
陆浩,陈金令*,陈杰,陈百合,唐卓葳
1.西南石油大学电气信息学院,成都 610500;2.绵阳市中心医院,绵阳 621000
0 引言
根据全球癌症数据统计2020 年版,女性乳腺癌已经成为确诊率最高的癌症类型,其致死率也在所有癌症类型中高居第五,严重威胁女性的生命健康。研究表明,通过早期诊断和及时干预,大约有28%—37%的乳腺癌可以治愈(Sung等,2021)。Wang等人(2022a)认为分析组织病理学图像是癌症诊断的黄金标准。然而,由于全玻片图像(whole slide images,WSIs)巨大的尺寸,对WSIs 进行病理学分析是一个耗时且烦琐的过程,并且对病理医生的专业水平要求极高。面对日益剧增的乳腺癌病例数量,大众对于效率更高的计算机辅助诊断工具的需求愈发强烈。
随着深度学习的高速发展,学界不断地涌现出各种用于WSIs的计算机辅助诊断方法。如Tellez等人(2021)提出两阶段的病理全切片图像分类算法,首先压缩千兆像素的病理图像,然后在压缩后的图像上训练一个卷积神经网络(convolutional neural network,CNN)用于预测图像级标签。Zhang 等人(2021)认为引入数据预处理方法,如染色归一化、颜色增强可有效提升模型的泛化能力。拥有千兆像素的WSIs 在目前的计算机硬件条件下是不可能直接处理的,通常是在处理前将其分解为更小的图像块(Srinidhi 等,2021)。对于计算机辅助诊断系统,如何从大量实例中高效地识别出触发类别预测的关键实例,如何将成千上万个图像块的分析结果汇总成能够代表该WSIs 的包级表示是两个长期挑战。由于WSIs通常缺乏像素级标注,训练阶段无法获得图像块级的标签,因此,弱监督多实例学习成为分析WSIs 的主流方法(Campanella 等,2019)。弱监督多实例学习方法中,WSIs 通常定义为一个包,更小的图像块则定义为包中的实例。
然而,WSIs 领域中现有的弱监督多实例学习方法仍然存在着以下不足:1)由于病变区域仅占整个组织区域的一小部分,导致一个包中阳性实例和阴性实例的数量严重不平衡(Li等,2021)。因此,精确引导模型从大量实例中识别出区分性实例是模型成功的关键。2)目前,多数方法都是基于独立同分布假设的,没有考虑来自同一个包的实例间的相关性(Shao等,2021)。实际上,不同组织区域的相关性是病理医生进行诊断的关键信息。3)以前的弱监督多实例学习方法忽略了特征编码的重要性,往往都依赖于使用由公用数据集ImageNet预训练的特征编码器(Li等,2023)。但是,这种由域外数据集预训练的特征编码器对病理图像特征的表达能力是有限的。
为了解决上述问题,本文提出一种新的双层多实例学习模型(double-tier multiple instance learning,DT-MIL),而传统方法都采用单层的多实例学习模型进行推理。图1 展示了传统单层多实例学习模型的结构和本文提出的双层多实例学习模型的结构对比。
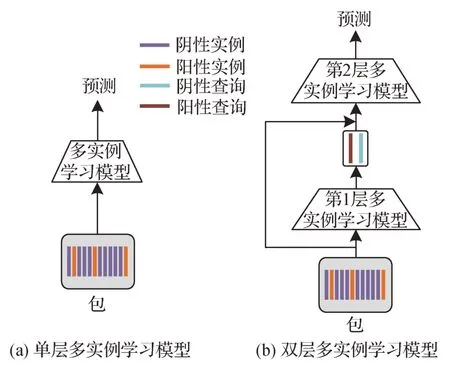
图1 传统多实例学习模型与本文提出的双层多实例学习模型结构对比Fig.1 Comparison of the structures of the traditional MIL model and the proposed double-tier MIL model((a)single-tier MIL model;(b)double-tier MIL model )
DT-MIL 的总体结构如图2所示,包括3个部分:数据处理、特征提取和特征聚合。首先,将WSIs 剪裁为固定大小的图像块,并过滤掉无效的背景区域,只保留包含病理组织的图像块;其次,在特征提取部分采用自监督对比学习框架SimCLR(a simple framework for contrastive learning of visual representations)预训练的特征编码器提取图像块特征;最后,在特征聚合部分部署提出的双层多实例学习模型。具体地,第1 层的自适应特征挖掘器首先结合门控注意力和Grad-CAM(gradient-weighted class activation mapping)(Selvaraju 等,2017)来推断实例的概率分布,然后检索并聚合每个子类的区分性特征以生成对应的内部查询。重要的是,自适应特征挖掘器通过灵活地选择、聚合K个区分性特征可以有效地降低肿瘤异质性对模型性能的影响,同时避免引入错误的特征信息。此外,自适应特征挖掘器还同时为每个子类都生成内部查询以防止模型对某类实例产生偏见。第2层由一个深度非线性模块和一个双路交叉检测模块组成,其目标是通过建模内部查询和实例间的关系为后续的分类器生成更准确的包级表示。
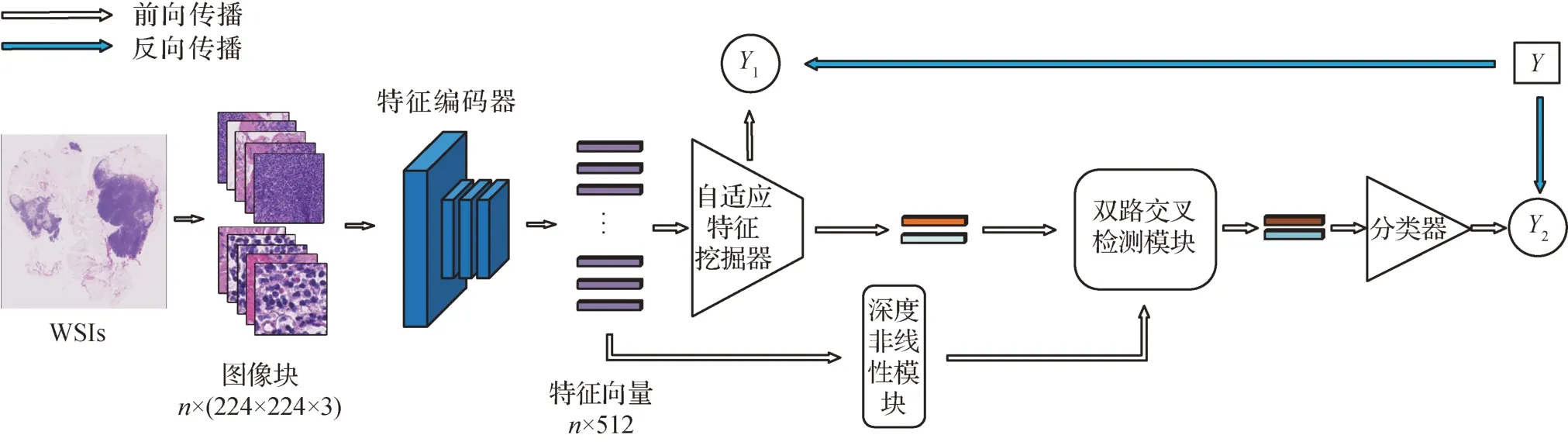
图2 DT-MIL的总体结构图Fig.2 Overview structure of the DT-MIL
本文在CAMELYON-16 和TCGA(the cancer genome atlas)数据集上评估提出的模型,大量实验结果显示本文模型优于其他较先进的对比方法,证明了所提模型的有效性。
1 基于深度学习的多实例学习模型和注意力机制
1.1 WSIs分析中的多实例学习模型
由于WSIs巨大的分辨率,在处理时必须将其分解为更小的图像块,然后总结每个图像块的分析结果生成最终的包级表示,这一特点恰好符合多实例学习的概念。多实例学习可分为两类,实例级算法(Campanella 等,2019;Feng 和Zhou,2017;Kanavati等,2020;Xu 等,2019)和嵌入级算法(Shao 等,2021;Lu 等,2021;Sharma 等,2021;Wang 等,2018;Zhu 等,2017)。对于前者,它在训练阶段将包的标签分配给所有实例作为伪标签,然后选择Top-K实例生成最终的包级表示。然而,实例级算法需要大量的WSIs数据支持,否则容易出现过拟合和收敛性差的问题。相比之下,嵌入级算法通过池化操作(如平均池化、最大池化)聚合所有实例生成更准确的包级表示。Wang等人(2018)研究表明,嵌入级算法的性能优于实例级算法。
1.2 深度学习中的注意力机制
注意力机制的本质是模仿人类的感知行为,将人类的注意力行为部署到机器上,使其学会分析训练样本的重要性。注意力机制最初应用在自然语言处理(natural language processing,NLP)领域,随后注意力机制开始在计算机视觉任务中流行起来,包括图像分类(Li 等,2021;陈金令 等,2022;高红民 等,2023)、目标检测(Zhang 等,2018;Zhu 等,2021;贾可心 等,2022)和视频处理(Zeng 等,2020)。最近,不断涌现出基于注意力的多实例学习框架。注意力机制在大量嵌入级多实例学习算法中都起着举足轻重的作用,这些方法通过给所有实例分配适当的权重来突出有价值的实例,这可以极大地提高性能并减少计算开销。例如,WSIs 分析领域的经典论文ABMIL(attention based MIL)(Ilse 等,2018)使用门控注意力机制进行特征聚合,取得了巨大进展。
出自Transformer(Vaswani 等,2017)的自注意力机制逐渐开始流行。Gao 等人(2021)考虑到远程依赖关系的重要性,通过将卷积和自注意力机制结合提出一种新的自注意力算法。Trans-MIL(Transformer based MIL)(Shao 等,2021)第1 个将自注意力机制应用到WSIs分类任务中。然而,它的模型并没有充分利用来自病理图像的内部信息,并忽略了肿瘤异质性的影响。此外,由于硬件条件的限制,在面对包含大量图像块的WSIs时,自注意力机制的表现并不理想。本文提出的模型也用到了自注意力机制的思想,但针对不同的应用场景对其进行了优化,以弥补不足。
2 提出的方法
2.1 多实例学习
多实例学习是一种流行的弱监督学习框架。在多实例学习中,输入是一系列包含大量实例的包,其中实例的标签是未知的,只有包级标签是已知的(1代表阳性,0 代表阴性)。如果包中至少包含一个阳性实例,则包级标签为阳性,否则为阴性。对于WSIs 的阴阳性分类任务,包含N个包的输入可描述为I={B1,B2,⋅⋅⋅,BN},其 中Bi={xi,1,xi,2,⋅⋅⋅,xi,K}表示包含K个实例的第i个包,包中每个实例对应的隐藏标签为Li={yi,1,yi,2,⋅⋅⋅,yi,K}。包级标签是训练阶段唯一明确的信息,包级标签Yi与实例标签yi,j的关系定义为
多实例学习推断包级标签的过程可以表述为
式中,f(·)是特征编码器,g(·)表示一个聚合函数,代表预测结果。
2.2 特征编码器
将图像块转化为特征嵌入是WSIs 分析中重要的一环,特征嵌入的质量好坏直接影响后续的分析。由于缺乏图像块级的标签,端到端的训练一个域内数据的特征编码器是不可行的。因此,使用由域外数据集如ImageNet预训练的特征编码器成为主流实践。然而,Li 等人(2021)认为使用这种简单的方法很可能导致生成次优的特征嵌入,因为域外数据特征编码器对病理组织细胞的结构特征缺乏敏感性。自监督对比学习通过比较由辅助任务生成的正负样本间的差距来不断学习数据的特征表示。例如,SimCLR(Chen等,2020)通过最大化由同一图像经两种不同数据扩增得到的两个样本间的相似性来训练特征编码器,而MOCO(momentum contrast)(He 等,2020)则是通过最小化两个样本的相似性来更新、优化特征编码器。Dehaene 等人(2020)的研究已经证明,使用自监督预训练的特征编码器可以显著增强弱监督多实例学习在WSIs分析任务中表现,缩小与全监督学习方法的差距。因此,本文使用SimCLR对比学习框架对组织病理学图像进行预训练,获得用于病理图像分析的域内特征编码器。SimCLR 对比学习框架的结构如图3所示。
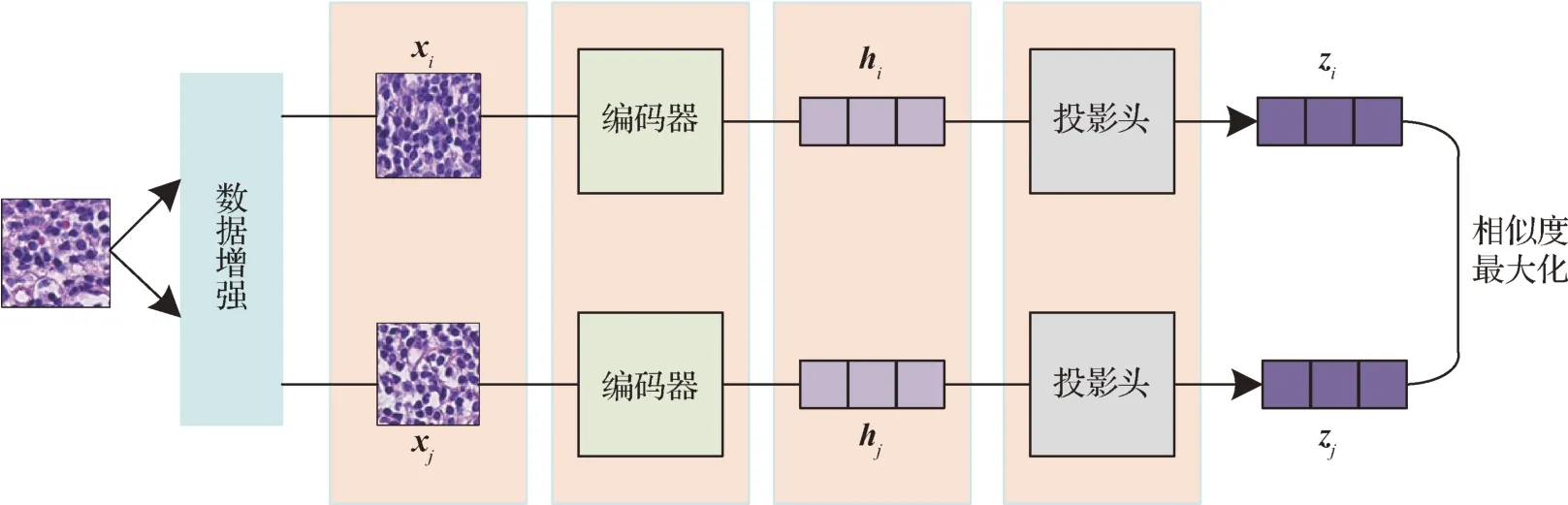
图3 SimCLR的结构图Fig.3 Overview structure of the SimCLR
2.3 自适应特征挖掘器
第1 层多实例学习模型即本文提出的自适应特征挖掘器,其核心任务是为后续的双路交叉检测模块提供高质量的内部查询,其结构如图4 所示。DSMIL(Li 等,2021)仅使用一个简单的线性层完成实例概率推断,并取出最大概率的实例作为查询向量。Trans-MIL(Transformer based MIL)(Shao 等,2021)使用一个外部随机初始化的可训练向量作为查询,从所有实例中收集有价值的特征信息。然而,以上方法都存在明显缺陷,DS-MIL(dual-stream MIL)这种简单的方式推断出实例概率不够可靠,而Trans-MIL的查询向量来自外部,没有充分利用组织病理学图像的内部信息。另外,这两种方法在设计时都忽略了肿瘤异质性对模型性能的影响(Wang等,2022b)。平均Top-K实例作为内部查询是缓解以上问题的一种常见方法。但是,面对不同的WSIs都采用默认值K生成的内部查询是次优的,缺乏灵活性。因为这种方法要么没有充分挖掘内部信息,要么会引入错误的特征信息。因此,本文设计了一种新的内部查询生成策略来解决这一问题。
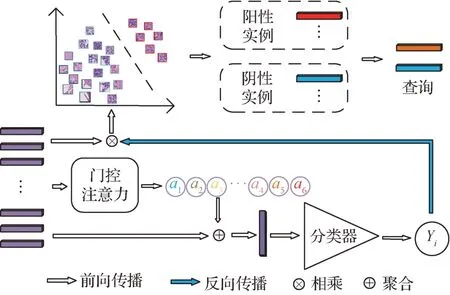
图4 自适应特征挖掘器的结构图Fig.4 Overview structure of the adaptive feature miner
Zhang 等人(2022)认为在经典的AB-MIL 框架下推导实例的概率分布是不可行的,因此,本文结合门控注意力机制和Grad-CAM 来推断每个单独实例的预测概率,实现对所有实例重要性的重校准。首先,所有实例都基于门控注意力进行聚合,并使用线性层进行预测。然后对类别C的预测结果进行反向传播,获得回传至实例特征的梯度信息,该梯度信息反映了实例特征中每个元素对类别C的重要性,将梯度信息与实例特征加权求和获得包中各实例对类别C的重要性。最后,使用Softmax 推导出各实例相应的概率分布。B={x1,x2,⋅⋅⋅,xN}表示包含N个实例的包,包中每个实例xi都被特征编码器f(·)映射为特征嵌入hi=f(xi) ∈RD×1,则第i个实例被预测为类别C的概率可表示为
式中,D表示特征嵌入的维度,sc表示分类器对类别C的预测输出是的第d个元素定义为
式中,ai表示第i个实例的注意力权重,sigm 表示sigmoid 函数。然后基于这些权重聚合所有提炼出的实例特征,并使用分类器T1推断出第1 层的伪标签Y1,具体为
完成实例概率推导之后,自适应特征挖掘器会检索出K个区分性特征。重要的是,这里的K不是一个固定的数字,它可以在面对不同的包时自适应地调整。具体来说,本文首先选择预测概率最高的实例作为目标样本。目标样本即为该包中概率最大的阳性实例,以该实例为基准,建模与其余实例的距离即可分析出其余实例的阳性概率,进而划分出阴阳性实例。然后,分析目标样本和其余样本之间的距离D(hm,hi),具体为
自适应特征挖掘器通过平均前K个区分性实例生成最终的内部查询。具体地,如果伪标签Y1是阴性,则K等于超参数α与包中实例数N的乘积。如果伪标签是阳性,则将距离向量进行排序并聚合满足以下条件的前K个实例,具体为
式中,D'K满足以下条件,具体为
式中,D'表示将D按降序排列获得的距离向量。当伪标签Y1为阳性时,自适应特征挖掘器首先根据实例与目标样本的距离将所有实例按降序排列,然后计算相邻实例之间的距离差,将出现最大距离差的位置作为阴性和阳性实例的分界线,最后聚合每个子类的实例生成相应的内部查询。自适应特征挖掘器通过灵活地聚合K个区分性实例生成更可靠的内部查询,在充分挖掘典型特征的同时避免了引入错误的阴性信息,减轻肿瘤异质性对模型性能的影响,为后续处理奠定了坚实的基础。
2.4 双路交叉检测模块
第2 层多实例学习模型即所提的双路交叉检测模块,其作用是聚合所有实例的特征信息,获得最终的包级表示,其结构如图5 所示。在双路交叉检测模块之前,本文应用一个深度非线性模块映射实例特征。对于WSIs的阴阳性分类任务,不像以前的方法仅使用单个查询进行实例聚合,本文提出的双路交叉检测模块同时建模阳性查询、阴性查询与包中其余实例的关系。双路交叉检测模块有3 个输入:来自自适应特征挖掘器的阳性查询Qp和阴性查询Qn,由深度非线性模块映射获得的特征矩阵H′=
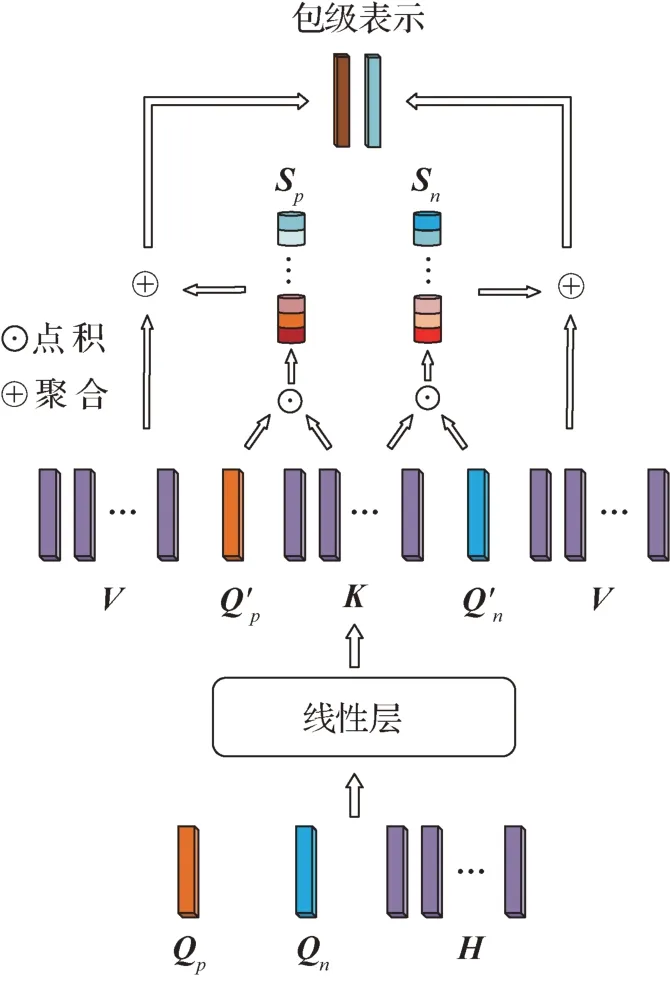
图5 双路交叉检测模块的结构图Fig.5 Overview structure of the dual-path cross-detection module
首先,将所有输入使用线性层进行映射,该过程可描述为
式中,W1,W2,W3和W4表示权重矩阵。基于和分别建模与各实例的相关性,获得实例的注意力分数,该过程可表示为
式中,i和j分别表示Q(query)和K(key)的横坐标。实例的注意力分数是由query 和key 之间的相关性决定的。送入最终分类器的包级表示描述为
双路交叉检测模块的最终产物是Z∈RC×d,其中C表示子类的类别数,d表示包级表示的维度。最后,使用分类器T2推断出最终的预测标签Y2,具体为
通过同时建模阳性查询、阴性查询与各实例之间的关系,聚合包中所有实例,不仅可以补充特征信息,还可以使模型同时对阳性和阴性实例都保持灵敏,防止模型对某类实例产生偏见,提高模型的鲁棒性。
3 实 验
3.1 数据集及预处理
本文在两个主流WSIs 数据集上评估提出的模型,分别是CAMELYON-16 数据集和TCGA 肺癌数据集。CAMELYON-16 包含由两个独立医疗机构收集的400 幅苏木精和伊红(hematoxylin and eosin stains,H&E)染色的乳腺癌筛查全视野数字病理切片(270幅训练图像和130幅测试图像)。TCGA肺癌数据集包含肺腺癌和肺鳞癌两个亚型,总共包含1 054 幅数字病理切片。CAMELYON-16 和TCGA 中的所有WSIs都存储在一个多分辨率的金字塔中,每个WSIs都提供了像素级的标注。但是,本文在实验过程中没有考虑像素级标注,整个实验中只使用到了包级标签。
预处理时,每个WSIs 被裁剪成224 × 224 像素不重叠的图像块,并过滤掉只包含背景的无效图像块。预处理后,CAMELYON-16 平均每个包包含约8 000 个有效图像块,TCGA 肺癌数据集平均每个包包含约5 000 个有效图像块。对于CAMELYON-16数据集,本文将官方训练集中的270 个WSIs 按9∶1的比例随机划分为训练集和验证集,并使用官方测试集中收集到的129 个WSIs 进行测试。对于TCGA肺癌数据集,按7∶1∶2 的比例将数据集随机划分为训练集、验证集和测试集。
3.2 实验环境及评价指标
所有实验都是基于PyTorch 库,都使用由Sim-CLR 预训练的ResNet18(He 等,2016)作为特征编码器。批大小为1,使用Adam优化器对第1层和第2层中的相关组件迭代更新200轮,学习率为2E-4,权重衰减为5E-3,操作系统为Windows10,GPU 为NVIDIA GeForce 3080Ti GPU。
在所有的实验中,本文报告了按类平均的准确率(accuracy)、精确度(precision)和召回率(recall),以评估所提出的模型在WSIs分类任务中的表现。
3.3 与其他最先进方法的对比
表1 和表2 分别展示了本文模型与其他最先进方法在CAMELYON-16 数据集和TCGA 数据集上的实验结果,对比的模型包括Attention-MIL(attention based MIL)(Ilse 等,2018)、Gated Attention-MIL(gated attention based MIL)(Ilse 等,2018)、CLAM-SB(clustering constrained attention multiple instance learningsingle attention branch)(Lu 等,2021)、CLAM-MB(clustering constrained attention multiple instance learning-multi attention branch)(Lu 等,2021)、Trans-MIL(Shao等,2021)和DS-MIL(Li等,2021)。
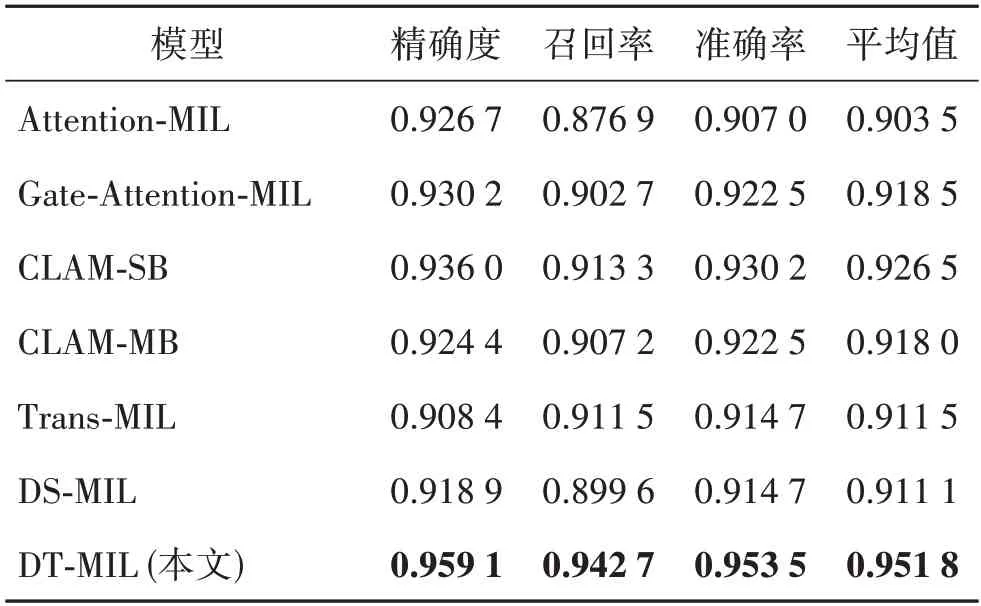
表1 不同模型在CAMELYON-16数据集的分类结果对比Table 1 Comparison of the classification results of different models on the CAMELYON-16 dataset
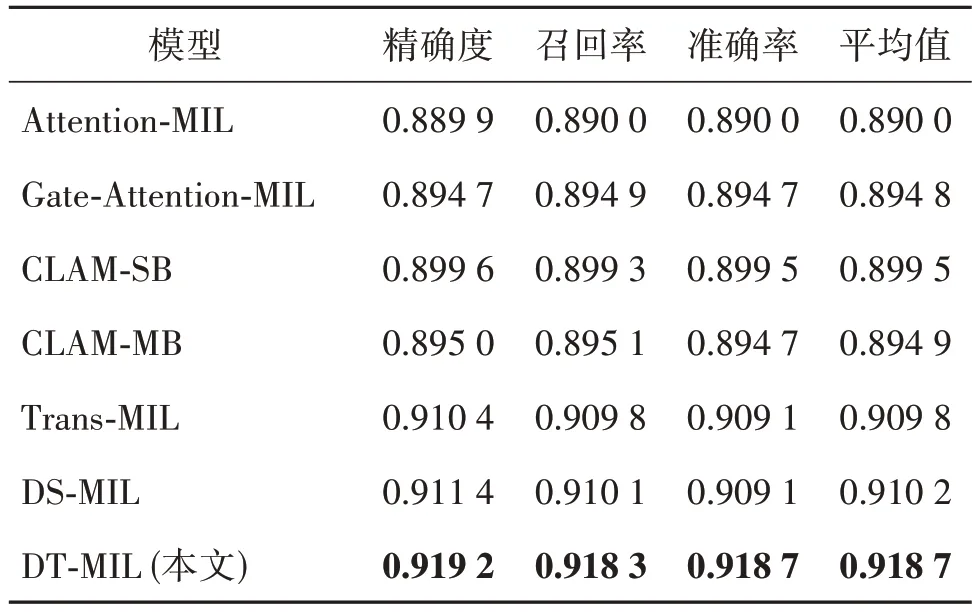
表2 不同模型在TCGA肺癌数据集的分类结果对比Table 2 Comparison of the classification results of different models on the TCGA lung cancer dataset
Attention-MIL 和Gated Attention-MIL 来自Ilse 等人(2018)提出的经典多实例学习模型AB-MIL。二者都是基于注意力机制对实例关系建模,从而获得包级表示,不同的是由于tanh(⋅)在注意力模块中的低效,Gated Attention-MIL 增加了门控机制,以强化模型建模实例关系的能力。CLAM 由包级分支和实例分支组成,前者采用基于注意力池化的方式获得包级表示,实例级分支选择每个子类中Top-K实例作为关键实例,并生成对应的类别标签以进行实例级分类。CLAM 也提供了两种模型,分别是单注意力分支的CLAM-SB 和多注意力分支的CLAM-MB。Trans-MIL 通过多头自注意力机制来捕获长距离依赖关系,并采用一个随机初始化的class token 作为查询聚合实例的特征信息。DS-MIL 从包中检索出概率最高的实例作为内部查询,然后通过计算内部查询和其他实例之间的相似性为实例分配权重,最后聚合所有实例获得最终的包级表示。
本文在原论文作者公布的开源代码基础上复现了上述所有方法。为了保证实验的公平性,所有的实验都采用了相同的CNN 骨干网络,并使用相同的比例来划分训练集、验证集和测试集。
从表1—2 中可以看出,本文方法在准确率、精确率和召回率等评价指标上明显优于其他对比模型。Attention-MIL、Gate-Attention-MIL、CLAM-SB、CLAM-MB都是基于独立同分布(i.i.d.)假设下设计的MIL 模型,它们在WSIs 分类任务中的表现都很有限。虽然Trans-MIL也能捕捉到实例的相关性,但其在建模实例相关性时使用的是外部查询,并不能充分地捕获病理图像的特征信息。DS-MIL 使用了来自包内部的实例作为查询聚合特征信息,同时考虑到实例间的相关性。然而,由于只使用了一个简单的线性分类层来获得粗略的内部查询,其与本文方法仍有很大差距,这也验证了本文方法强大的特征挖掘能力。
3.4 消融实验
3.4.1 模块的有效性
为了验证本文模型中主要模块的有效性,分别对特征提取器、自适应特征挖掘器和双路交叉检测模块在CAMELYON-16 数据集进行消融实验。除了3 个模块外,所有实验的其余设置都保持一致,以便进行公平比较,实验结果如表3所示。

表3 消融实验结果Table 3 Results of ablation experiment
模型1 使用ImageNet 预训练的ResNet-18 作为特征编码器,采用一个线性层生成内部查询,最后使用来自DS-MIL 的多实例聚合器生成最终的包级表示。设计模型1 的目的是将其与替换本文提出的各种模块后的模型形成对比,验证各模块的有效性。
从表3 中可以看出,模型2 较模型1 在准确率、精确率和召回率上有着明显的差距,说明合适的特征编码器在多实例学习模型中起着至关重要的作用,这也证明了自监督对比学习方法SimCLR 可以获得良好的特征嵌入。观察模型3 和模型2 的实验数据可知,使用本文提出的自适应特征挖掘器取代模型2 中的线性层可以极大地提高模型性能,说明自适应特征挖掘器可以生成更高质量的内部查询。观察模型4和模型3的实验数据可知,使用本文提出的双路交叉检测模块建模实例相关性能够使模型的准确率获得较大提升。综上所述,本文提出的3 个模块均能有效地提升模型性能。
3.4.2 自适应特征挖掘器的影响
本文设计的自适应特征挖掘器由两部分组成:实例概率推导和关键实例检索。关键实例检索的目的是通过检索阴阳性实例的边界,充分挖掘包中的代表性特征,并且整个过程是自适应的。
为了验证自适应特征挖掘器的有效性,本文将其与几种常见的方法进行比较,包括K-means 聚类和聚合Top-K实例。这里K取3 个不同的值,即10、100 和1 000。由图6 可知,本文方法具有明显的优势。K-means 聚类可以用来对所有实例进行自适应聚类,但实验结果表明,K-means 聚类的效果不如本文的自适应特征挖掘器,这可能是因为病理图像类间差异小,K-means 聚类在划分子集时容易出现误分。另一种常见的方法是聚合Top-K实例,但这种方法缺乏灵活性,往往会产生次优的内部查询。如果默认值K太小,则部分典型特征可能会被忽略;如果K值过大,则可能会引入错误的特征信息。本文方法在面对不同的WSIs 时可以及时调整K值,在充分挖掘典型特征的同时有效避免引入错误的特征信息。
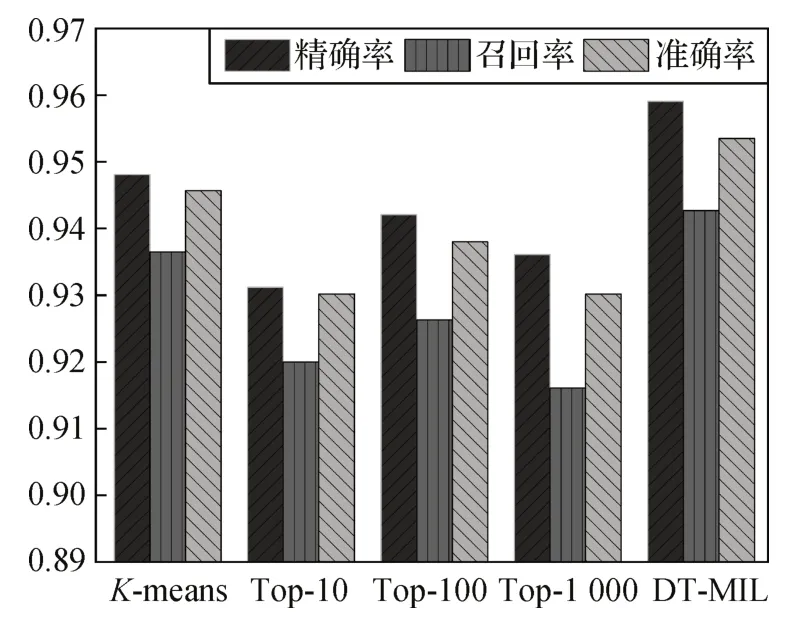
图6 不同内部查询生成方法的性能对比Fig.6 Performance comparison of different internal query generation methods
3.4.3 超参数α的影响
α是自适应特征挖掘器的一个关键参数。自适应特征挖掘器首先对WSIs 进行粗略分类以获得伪标签,然后根据不同的伪标签选择不同的处理方法。当伪标签为阴性时,α用来控制特征聚合的范围。
图7展示了本文方法在不同α值下的准确率、精确率和召回率。从图7 中可以看出,当α=1 时,可以得到最佳的效果,这也符合本文的假设。本文认为,考虑包中所有阴性实例,汇总包中所有阴性实例的信息有利于产生更稳健的阴性查询并防止额外的偏差。
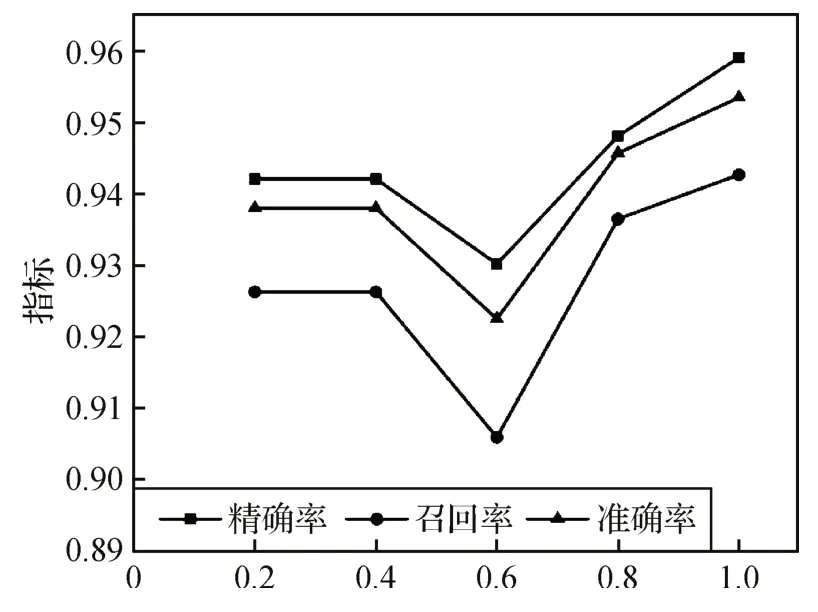
图7 超参数α对模型性能的影响Fig.7 The influence of hyperparameter α on model performance
3.5 WSIs的病变区域可视化
为了进一步展示本文方法的临床意义,本文对原始WSIs 上的病变区域进行可视化。病变区域的可视化被认为是人工智能辅助医生进行临床诊断的重要工具。在图8 中,本文根据WSIs 中各实例在双路交叉检测模块中的输出概率,将WSIs中的关键实例可视化。图8(a)展示了CAMELYON-16 的原始WSIs,绿色曲线是由病理医生勾勒出的真实病变区域。图8(b)(c)展示了本模型的可视化结果,分别以斑块和曲线两种形式来描述病变区域。图8(d)展示了该WSIs 中的几个高分实例。显然,从图8 中可以发现,尽管从未使用像素级标注来帮助模型训练,本文方法也可以很好地划定WSIs中的真实病变区域。这表明本文方法具有很好的注意力可视化能力和可解释性。

图8 病变区域可视化结果Fig.8 Visualisation of lesion area((a)original WSIs;(b)model in this article(patch form);(c)model in this article(curve form);(d)instances of high scores in WSIs)
4 结论
本文提出了一个新的双层多实例学习模型用于组织病理学图像分类任务。实验结果表明,本文方法得益于3 个部分:首先,本文算法将自监督对比学习整合到MIL 中,以获得更准确的特征表示;接下来,第1 层的自适应特征挖掘器检索每个子类的区分性特征,生成相应的内部查询;最后,部署在第2层中的双路交叉检测模块建模预先计算的内部查询与实例间的关系,生成最终的包级表示。在CAMELYON-16和TCGA 数据集上的实验结果表明,本文模型在所有评价指标上都明显优于其他对比的全切片分类模型,表明本文模型比其他先进的模型更有优势。本文方法考虑了组织病理学图像的远程依赖关系,充分挖掘内部特征信息,有效缓解肿瘤异质性的影响,提高病理学诊断的效率,同时还可以精确的定位病变区域,具有良好的可解释性。
猜你喜欢
成都信息工程大学学报(2018年3期)2018-08-29
通信电源技术(2018年3期)2018-06-26
铁道通信信号(2018年1期)2018-06-06
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
电源技术(2015年9期)2015-06-05
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电测与仪表(2014年13期)2014-04-04
电子世界(2004年5期)2004-07-26