
非完全信息下协作式入侵检测系统检测库配置研究①
2024-03-20 08:21石月楼杨旦杰冯宇李永强
高技术通讯 2024年2期
石月楼 杨旦杰 冯宇 李永强
(浙江工业大学信息工程学院 杭州 310023)
近年来,随着计算机网络和信息技术的不断发展,“黑客攻击”已成为威胁互联网安全的主要因素之一,如何有效地防御恶意入侵、保证网络安全受到了广泛的研究[1-3]。
入侵检测系统(intrusion detection system,IDS)是一种动态检测网络的安全防御机制,可以通过运行入侵检测算法来识别网络中的攻击,有效弥补安全防护技术中的不足[4]。常用的入侵检测算法有异常检测算法[5]、误用检测算法[6]和人工智能算法[7]。然而单一算法无法捕获所有的攻击,且由于能量的限制,单个入侵检测系统无法同时运行所有的算法,因此大量的研究工作投入到了入侵检测系统的检测库配置问题上。其中,博弈论[8-9]是分析该问题的有效工具。文献[10]将入侵检测系统与攻击者的交互过程建模为一个两人非零和随机博弈,通过求解效用最优化方程得到攻防双方的最优策略。文献[11]也用相同的博弈框架研究了类似的问题,并通过强化学习算法求得攻击者和入侵检测系统的最优策略。文献[12]通过两人零和随机博弈框架研究了入侵检测系统检测库配置的问题,提出一种基于强化学习的算法来得到最优检测库配置策略。在文献[13]中,作者使用零和贝叶斯信号博弈研究了入侵检测系统与未知类型的攻击者的交互过程,并证明博弈的纳什均衡策略就是一组最优攻防策略。为了可以运行更多的算法提升检测性能,越来越多的研究提出在多个入侵检测系统中引入协作机制。文献[14]验证了协作式入侵检测系统可以显著提升整体的检测性能,并提出分布式激励分配方法来解决检测库分配的矛盾。文献[15]也研究了类似的问题,并且还考虑了传输延迟和资源有限对检测库分配的影响。文献[16]在文献[15]的基础上还考虑了攻击者之间的协作性,提出了一种基于演化博弈的入侵检测系统检测资源分配模型。求解博弈均衡的方法有Sarsa 算法[17]、Q-learning 算法[18]、Monte Carlo 算法[19]等,这些都属于强化学习范畴[20]。强化学习的应用场景非常广泛,尤其适用于环境动力学无法建模的场景,智能体通过与环境的交互,将得到的奖励值作为反馈信号进行训练[21],且泛化性好,不需要进行大量调参。但传统的强化学习算法只能处理离散状态,而本文中的信念状态是连续的,因此本文提出后向递归算法来求解博弈问题。
与现有的大多数研究完全信息下单个入侵检测系统配置不同,本文考虑了一个非完全信息下协作式入侵检测系统检测库配置的问题。入侵检测系统可以监测到系统的状态,而攻击者无法获知,只能通过信念估计,因此通过非完全信息博弈模拟各入侵检测系统和对应攻击者的交互过程符合该情况。并且由于多个入侵检测系统共用一套检测库,因此在得到最优检测库配置方案后还要考虑同一检测库被重复加载的矛盾。本文主要工作总结如下:首先,为了解决信息不对称的情况,攻击者通过假想一个入侵检测系统建立基于信念的随机博弈框架来制定策略,通过后向递归算法求解,并证明了有限时间非完全信息博弈中稳态纳什均衡(stationary Nash equilibrium,SNE)的存在;然后,由于入侵检测系统可以观察到攻击者的策略,因此最优检测库配置方案可以通过求解一个混合Markov 决策过程得到;最后,提出了一种基于策略共享的集中式分配方法解决检测库被重复加载的矛盾。
1 问题定义
如图1 所示,入侵检测网络(intrusion detection network,IDN)由N个相互连接的入侵检测系统IDSi(i∈{1,2,…,N}) 组成,对应的攻击者用γi(i∈{1,2,…,N}) 表示。每个子系统的状态集合都是S={S1,…,Sq,…,SK},其中,Sq表示某种特定运行状态;例如,S1表示运行正常,S2表示正遭受恶意攻击,S3表示运行异常。每个攻击者的纯动作集合都是Aγ={1,…,h,…,H},攻击者γi发动h类型的攻击的能耗为cγi(h)>0。
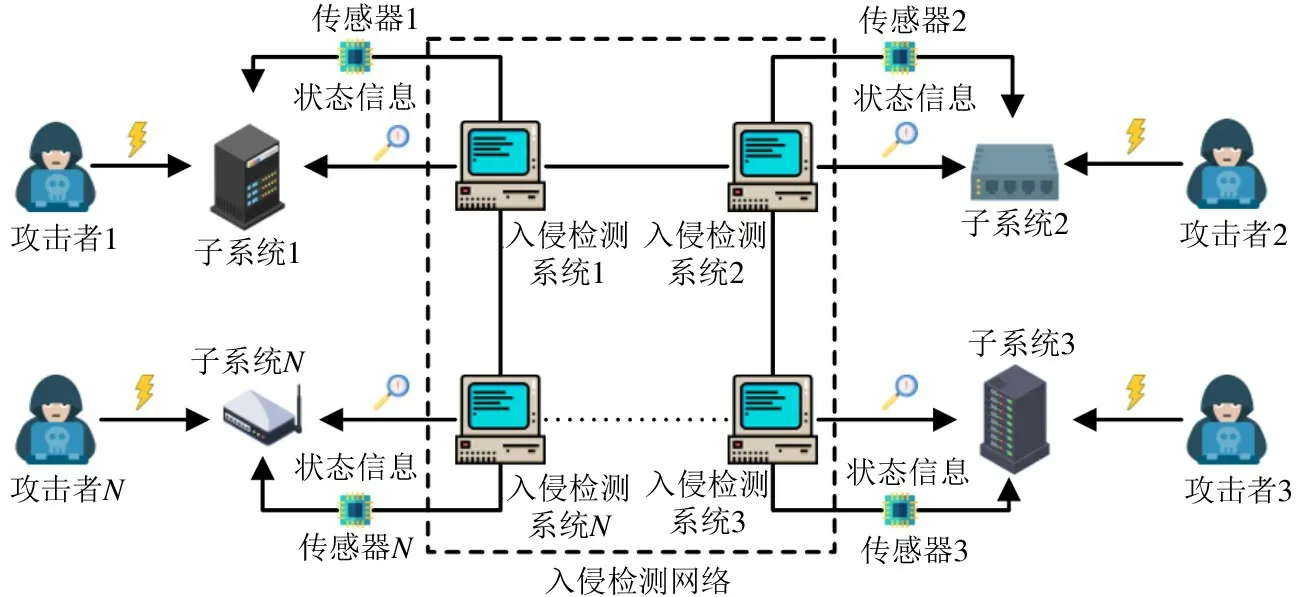
图1 协作式入侵检测系统模型图
协作式入侵检测系统共用的检测库集合为L={l1,…,lm,…,lH},检测库lm成功检测到h类型的攻击的概率是plm,h。当加载的检测库与攻击类型相匹配时,成功检测到的概率会大幅提升。入侵检测系统可以通过加载多个检测库来优化检测性能,但是相应的检测能耗也会变高,因此要考虑检测准确率和能耗之间的一个平衡。每个入侵检测系统每次可以同时加载n(n∈{1,2,…,H}) 个检测库,则检测库L的可能组合类型共有M=种,表示从H个检测库中挑出n个检测库的所有可能组合数,用Fj(j∈{1,2,…,M}) 表示,因此,各入侵检测系统的纯动作(检测库配置方案)集合都可以用AIDS={F1,F2,…,FM} 表示。令入侵检测系统IDSi加载检测库lm的能耗为>0,则入侵检测系统IDSi选择配置方案aIDSi∈AIDS的总能耗是
接下来,定义入侵检测系统IDSi选择动作aIDSi成功检测到攻击aγi的概率为
当子系统i状态为Sk时,如果攻击aγi没有被成功检测到,其损失为D(Sk,aγi),则部署在该子系统上的入侵检测系统IDSi的损失为
其中,δIDSi>0 表示与IDSi检测能耗相关的权重参数,δγi>0 表示与攻击能耗相关的权重参数。最后,定义每个子系统状态转移矩阵为
其中,TSe,Sf(aIDSi,aγi)(e,f∈{1,2,…,K}) 表示子系统i在联合纯动作{aIDSi,aγi} 下从当前状态Se转移到下一状态Sf的概率。
由于协作式入侵检测系统共用一套检测库,因此,任一检测库在每一时刻只能被分配给一个入侵检测系统,即各入侵检测系统的检测库配置方案{aIDS1,aIDS2,…,aIDSN} 需满足:
2 非完全信息入侵检测系统检测库配置
本文聚焦非完全信息下协作式入侵检测系统的检测库配置,接下来将分3 步研究这个问题。首先,构建一个基于信念的随机博弈来研究攻击者的策略制定问题;然后,通过混合Markov 决策过程得到入侵检测系统的检测库配置策略;最后,基于策略共享的检测库分配方法来解决加载检测库的矛盾。
2.1 攻击策略
每个入侵检测系统和对应攻击者的交互过程都可以描述为一个两人零和随机博弈,动作集、回报函数、子系统的状态集合以及状态转移概率都是相同的,因此在以下建立的基于信念的随机博弈框架中,只考虑其中一个入侵检测系统和其对应攻击者之间的交互,其余N-1 对的交互过程也是完全一样的。攻击者γi无法获得子系统的真实状态,通过信念估计,并假想一个同样使用信念的入侵检测系统来制定策略,建立一个由五元组<I,A,B,T,R>组成的基于信念的随机博弈框架。
(2)动作:令A=Δ(AIDS) ×Δ(Aγ) 表示纯动作集合AIDS×Aγ上的联合概率分布集合。
(3)信念:令B=Δ(S) 表示信念集合,Δ(S)表示在状态集S上的概率分布。记Bt(k) 表示t时刻子系统i状态为Sk(k∈{1,2,…,K}) 的概率。在t时刻末,攻击者γi根据观察到的动作用下式更新t+1 时刻的信念:
(4)信念转移概率:令t时刻信念为b∈B,联合概率动作为,则t+1 时刻信念转移到b′∈B的概率可以表示为T(b′|b,β)=Pr(Bt+1=b′ |Bt=b,At=β)。根据信念更新式(6),当时,有T(b′|b,β)=;否则,T(b′|b,β)=0。于是可以得到:
(5)收益:令rγi(Bt=b,At=β) 表示t时刻攻击者γi的收益,是根据信念b对所有状态下收益的加权和,具体表达式为
本文研究的是稳态策略,记为从信念空间B到动作空间A的映射,即πN:B→A。在给定信念b∈B,稳态策略是定义在纯动作集合AIDS×Aγ上的一个概率分布。因此,加权入侵检测系统和对应攻击者γi的累计收益函数分别为
其中,b0是初始信念。下面给出有限时间非完全信息博弈问题的定义。
问题1令GN:=(I,A,B,T,R) 表示一个有限时间非完全信息博弈,求解该博弈问题就等价于求解稳态纳什均衡策略满足:
2.2 入侵检测系统的检测库配置方案
由于真正的入侵检测系统在信息方面具有优势,因此在博弈的每个阶段,攻击者的策略制定过程对入侵检测系统而言是公开的,这使得入侵检测系统能够根据攻击者的策略来制定自己的策略。将该过程建立为一个混合Markov 决策过程,并用一个四元组来描述。
(2)状态:令U=S×B为混合状态空间,其中,S是子系统的状态空间,B是在基于信念的随机博弈中定义的信念空间。
(3)混合状态转移概率:令t时刻混合状态为u∈U,联合概率动作为则t+1时刻混合状态转移到u′∈U的概率为
(4)收益:入侵检测系统IDSi的收益函数为
其中,ω(s,aIDSi,aγi) 已在式(2)定义。
入侵检测系统IDSi的稳态策略用表示,是混合状态空间U到动作空间Δ(AIDS) 的映射,即:U→Δ(AIDS)。入侵检测系统IDSi的累计收益函数为
其中,u0是初始混合状态,是攻击者γi的稳态策略。在获知攻击者γi的稳态纳什均衡策略之后,入侵检测系统IDSi的目标是最大化累计收益函数,因此,入侵检测系统的最优配置策略可以通过求解以下最优问题来得到:
2.3 检测库分配
在检测库分配过程中,会有一个入侵检测系统充当中心管理者调度所有入侵检测系统加载检测库。在得到各入侵检测系统的最优配置策略以及对应攻击者的稳态纳什均衡策略后,将该信息报告给入侵检测网络管理者,管理者通过基于策略共享的检测库分配方法得到协作式入侵检测系统实际的检测库配置方案为{aIDS1,aIDS2,…,aIDSN},该分配方法将在下一节中详细介绍。此时入侵检测系统IDSi的期望收益为
其中,u={s,b} 表示当前时刻子系统i的状态以及攻击者γi的信念,是攻击者γi的稳态纳什均衡策略,ω(s,aIDSi,aγi) 已在式(2)定义。
此外,本文考虑的是入侵检测网络的收益,即所有入侵检测系统的收益之和,入侵检测网络的收益为
因此,中心管理者求得的检测库配置方案需满足:
3 入侵检测系统检测库配置方案计算
本节将给出具体求解基于信念的随机博弈、混合Markov 决策过程以及检测库分配的方法。
3.1 攻击策略
为了解决有限时间非完全信息博弈问题1,本文提出后向递归算法来构建攻击者γi的最优稳态策略。在该算法中,假定加权入侵检测系统已经使用稳态纳什均衡策略;并且证明该算法的解就是有限时间非完全信息博弈问题GN的稳态纳什均衡策略。
令GN中的SNE 策略为具体可以表示为根据式(10),在稳态纳什均衡策略下,攻击者γi从t时刻到N时刻的累计收益函数为
下面给出后向递归算法的具体步骤。
(1)初始化:对所有的信念b∈B,令t=N+1时攻击者γi的收益函数为
则t=N时刻攻击者γi的最优稳态策略为
相应地,t=N时攻击者γi的收益函数为
(2)递归:对于任意t=N-1,N-2,…,0;∀bt∈B,攻击者γi的最优稳态策略为
则相应地,攻击者γi的收益函数为
(3)构造攻击者γi的一个最优稳态策略为
在上述的后向递归算法中,理论上需要先将一方参与者的稳态纳什均衡策略固定下来,再求解另一方参与者的稳态纳什均衡策略,但是在实际的仿真案例中,由于GN是零和博弈,因此在求得收益矩阵以后可以通过效用等值[22]方法同时求解出双方的稳态纳什均衡策略。下面的定理1 给出了上述后向递归算法与有限时间非完全信息博弈GN中稳态纳什均衡存在的关系。
定理1由后向递归算法构造出的解是有限时间非完全信息博弈GN的一个稳态纳什均衡策略。
证明要证明是有限时间非完全信息博弈GN的一个稳态纳什均衡策略,根据问题1 中对稳态纳什均衡的定义,即等价于证明成立。由于在后向递归算法中假定加权入侵检测系统使用稳态纳什均衡策略显然是成立的。因此,下面只需要证明成立。
值得注意的是,在定义有限时间非完全信息博弈的收益函数时没有用到折扣因子(或者,等价于折扣因子ρ=1),如果在定义有限时间非完全信息博弈的收益函数时加上折扣因子,定理1 也依然适用于证明该博弈存在一个稳态纳什均衡,详见下面的推论1。
推论1当有限时间非完全信息博弈GN的收益函数定义为
其中,0<ρ<1 是折扣因子。在这样的情况下,GN依然存在一个稳态纳什均衡。
证明在定义式(19)中加入折扣因子ρ,后续证明过程和定理1 的证明过程相同。
3.2 检测库配置方案
在这一小节给出求解混合Markov 决策过程的方法。定理2 给出了入侵检测系统IDSi的最优纯动作贝尔曼方程。
定理2入侵检测系统IDSi的最优纯动作贝尔曼方程为
证明根据基于信念的随机博弈中求得的稳态纳什均衡策略∈B,入侵检测系统IDSi的累计收益函数满足最优贝尔曼方程[23]:
其中,第2 个等号成立的条件是因为状态s的转移与信念b的转移都是相互独立的;第3 个等号成立的条件是因为攻击者γi无法获知入侵检测系统IDSi的策略βIDSi,所以只能根据加权入侵检测系统的稳态纳什均衡策略来更新信念。因此,式(30)可以改写为
将式(31)中的概率动作换成纯动作,可得入侵检测系统IDSi的最优纯动作状态值函数为
其中,a={aIDSi,aγi}。
综上所述,入侵检测系统IDSi的最优纯动作贝尔曼方程式(27)和(28)得证。
通过最优纯动作贝尔曼方程式(27)和(28),入侵检测系统IDSi可以算得任意状态下所有联合动作即状态纯动作值表。又因为入侵检测系统在信息方面有优势,可以看到攻击者的策略制定过程,即在博弈的每一阶段,入侵检测系统都能获得攻击者的稳态纳什均衡策略。因此,入侵检测系统IDSi可以通过算法1求得最优检测库配置方案。

算法1 的步骤4 表示遍历入侵检测系统IDSi的检测库配置方案AIDS;步骤5 表示入侵检测系统IDSi每一个检测库配置方案对应的期望收益,表示攻击者选择z类型的攻击的概率;步骤7表示选出能使期望收益最大的检测库配置方案。
由该算法流程可以看出,入侵检测系统IDSi的最优检测库配置方案是在获得防守者γi的稳态纳什均衡策略以后,计算每一种检测库配置方案对应的期望收益,通过比较期望收益的大小,选择最大值对应的配置方案。因此,入侵检测系统IDSi的最优检测库配置方案实质上是一个纯策略。
3.3 检测库分配
由于协作式入侵检测系统共用一套检测库,因此可能会出现同一时刻多个入侵检测系统加载同一检测库的矛盾,本小节将介绍如何用基于策略共享的集中式分配方法解决该矛盾。
每一时刻,入侵检测系统通过与攻击者的交互得到最优检测库配置方案。由算法1 的分析可知,该最优检测库配置方案是纯策略,表示为{aIDS1,…,aIDSi,…,aIDSN},其中,aIDSi∈AIDS,i∈{1,2,…,N}。将该最优检测库配置方案报告给中心管理者,若满足式(4)和(5),则说明各入侵检测系统的检测库配置方案没有任何矛盾,即没有2 个或2 个以上的入侵检测系统同时加载同一个检测库,则中心管理者按该方案分配检测库。若不满足上述条件则说明有检测库被重复加载,则此时中心管理者先将没有矛盾的检测库分配掉;然后再通过一个优化机制将矛盾的检测库分配给合适的入侵检测系统。该优化机制具体描述如下。
(1)对任意入侵检测系统IDSi(i∈{1,2,…,N}),找出其与剩余所有入侵检测系统加载有矛盾的检测库的集合,表示为uij=aIDSi∩aIDSj(j={1,2,…i-1,i+1,…,N})。
(2)对∀lm∈uij,利用式(18)计算入侵检测系统IDSi加载lm、IDSj不加载lm后入侵检测网络的期望收益。注意,当从入侵检测系统IDSj的配置方案中去掉检测库lm以后,中心管理者会再从剩余的检测库中挑选满足以下条件的检测库分配给IDSj。
再用相同的方法计算入侵检测系统IDSj加载lm、IDSi不加载lm后入侵检测网络的期望收益
4 仿真分析
如图2 所示,考虑一个由2 个入侵检测系统相互连接的入侵检测网络展开有限次博弈,每个子系统i(i∈{1,2}) 都有3 个状态{S1,S2,S3}。攻击者的纯动作集合为Aγ={1,2},且不同类型的攻击的能耗分别为cγi(1)=0.8 和cγi(2)=1.2(i∈{1,2})。不同状态下各类型的攻击对子系统i造成的损失如表1 所示。
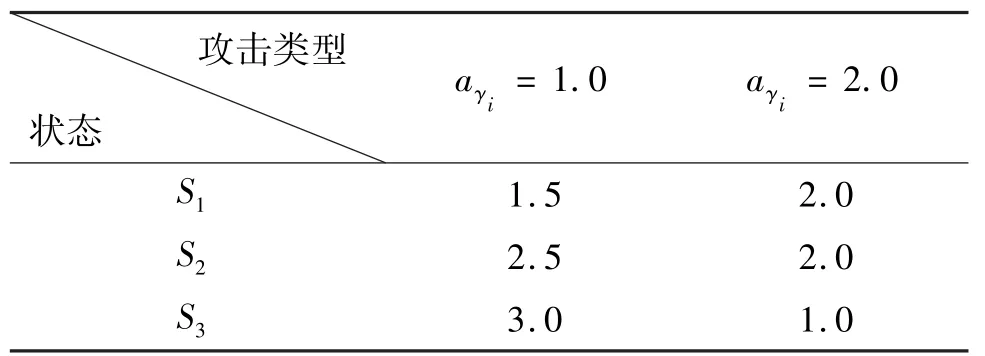
表1 不同状态下攻击对系统造成的损失
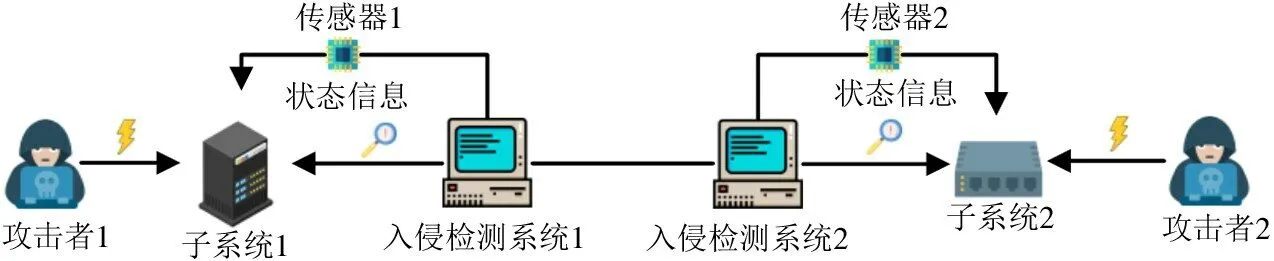
图2 二对二攻防博弈模型图
协作式入侵检测系统共用的检测库集合为L={l1,l2},每个入侵检测系统任意时刻只能加载一个检测库,则入侵检测系统的纯动作(检测库配置方案)集合为AIDS={{l1},{l2}},每个检测库被加载的能耗分别为IDSi(l1)=0.6,IDSi(l2)=1.0,i∈{1,2}。各检测库成功检测到攻击的概率分别为pl1,1=0.80,pl1,2=0.20,pl2,1=0.15,pl2,2=0.90。式(2)中的权重参数δIDSi=0.5 和δγi=0.4,i∈{1,2}。状态转移矩阵T(aIDSi,aγi) 可以按以下方式计算得到。假设当前子系统i的状态为S2,攻击者γi发动类型为1 的攻击,对应的IDSi加载检测库{l1},则相关的状态转移概率分别为
用相同的方法可以得到不同状态所有联合动作下的状态转移概率。令IDSi在状态Sk(k=1,2,3) 下的收益矩阵为ω(k,·,·),则ω(1,·,·)=
通过后向递归算法和算法1 可以求解有限时间非完全信息博弈的稳态纳什均衡策略和最优检测库配置策略。将博弈的长度设置为N=3。当t=3时,信念可以表示为b3=(b3(1),b3(2),b3(3)),b3(1) +b3(2) +b3(3)=1,且b3(1)>0,b3(2)>0,b3(3)>0。令分别表示博弈第3 阶段攻击者γi和加权入侵检测系统IDSi的稳态纳什均衡策略,aIDSi,3表示博弈第3 阶段入侵检测系统IDSi的最优检测库配置方案。根据后向递归算法,首先对∀b∈B,设置然后根据式(21)可以算得为
其中,∈=q1-q2-q3+q4,且qm(m∈{1,…,4})是第3 阶段博弈矩阵的元素,其具体表达式为
当η>0 时,入侵检测系统IDSi加载检测库l1;当η<0 时,入侵检测系统IDSi加载检测库l2;当η=0 时,任意加载检测库l1或者检测库l2。在得到最优检测库配置方案{aIDS1,aIDS2} 后,如果满足式(4)和(5),则直接为IDS1和IDS2分配检测库;否则按3.3 节中的分配方法为IDS1和IDS2分配检测库。
在博弈的t=2、1、0 阶段,信念bt可以用信念更新式(6)得到,真实状态通过状态转移矩阵得到,攻击者的稳态纳什均衡策略和入侵检测系统的最优配置方案可通过上述相同的步骤算得。
在这个仿真案例中,给定攻击者γ1的信念为b3=(0.5,0.3,0.2),子系统1 的真实状态为1;攻击者γ2的信念为b3=(0.4,0.4,0.2),子系统2 的真实状态为2,按上述步骤,攻击者γ1从博弈的第3 阶段到第0 阶段的稳态纳什均衡策略分别为
相对应地,入侵检测系统IDS1从博弈的第3 阶段到第0 阶段的最优检测库配置方案为aIDS1,3={l1},aIDS1,2={l2},aIDS1,1={l2} 和aIDS1,0={l2}。
用同样的方法可以得到攻击者γ2从第3 阶段到第0 阶段的稳态纳什均衡策略分别为
相对应地,入侵检测系统IDS2从博弈的第3 阶段到第0 阶段的最优检测库配置方案aIDS2,3={l1},aIDS2,2={l1},aIDS2,1={l2} 和aIDS2,0={l2}。
注意到在博弈的第3 阶段,入侵检测系统IDS1和IDS2都要加载检测库l1。当入侵检测系统IDS1加载检测库l1而IDS2加载检测库l2,入侵检测网络的收益;当入侵检测系统IDS2加载检测库l1而IDS1加载检测库l2,入侵检测网络的收益,因此把检测库l1分配给入侵检测系统IDS1。类似地在博弈的第1 阶段,入侵检测系统IDS1和IDS2都要加载检测库l2。当入侵检测系统IDS1加载检测库l2而IDS2加载检测库l1,入侵检测网络的收益r1IDN=0.740;当入侵检测系统IDS2加载检测库l2而IDS1加载检测库l1,入侵检测网络的收益,由于因此检测库l2可以分配给入侵检测系统IDS1或者IDS2。在博弈的第0 阶段,入侵检测系统IDS1和IDS2都要加载检测库l2。当入侵检测系统IDS1加载检测库l2而IDS2加载检测库l1,入侵检测网络的收益;当入侵检测系统IDS2加载检测库l2而IDS1加载检测库l1,入侵检测网络的收益=0.800,由于因此检测库l2被分配给入侵检测系统IDS1。
在相同模拟场景下比较了本文提出的基于策略共享的集中式分配方法和文献[14]提出的分布式激励分配方法解决检测库重复加载的矛盾后,所有入侵检测系统的收益总和。前者为10.360,后者为9.235,由此可以看出,本文提出的分配方法比分布式激励分配方法在收益值上提升了12.18%。此外,还研究了2 种分配方法完成分配的时间,基于策略共享的集中式分配方法运行时长为2.3 ms,分布式激励分配方法运行时长为1.4 ms,后者的运行时长相对减少了39.00%。因此当分配次数变多以及检测库数量变多后,分布式激励分配方法在运行时间上的优势会更明显。这是由于本文提出的分配方法为了能最优化整体入侵检测网络的检测性能,考虑了矛盾检测库分配的所有情况,因此当检测库的数量较多时耗时会较为严重。而分布式激励分配方法是各检测系统选择能使自己检测性能最优化的检测库,即通过一系列的局部最优来近似整体最优,这种分配方法能降低计算的复杂度,但是整个入侵检测系统的性能可能不会达到最优。
5 结论
本文给出了有限时间下非完全信息协作式入侵检测系统的最优检测库配置方法,该方法不仅解决了各入侵检测系统应对不同类型攻击时最优检测库的配置,而且解决了共用一套检测库引发的加载库的矛盾。攻击者无法获知系统状态的设定也更符合实际,可以通过构建一个基于信念的随机博弈来解决,并借助后向递归算法证明了博弈中SNE 的存在。真正的入侵检测系统利用一个欺骗机制获知攻击者的策略,并基于该策略算得每种检测库配置方案下的期望收益,通过比较期望收益的大小得到最优检测库配置方案。解决多个入侵检测系统加载同一检测库矛盾的分配方法实质上就是在分配完所有检测库的约束下最大化入侵检测网络的收益。仿真案例验证了上述方法的有效性,并给出了各入侵检测系统的最优检测库配置方案。
本文只考虑了入侵检测系统之间的协作性,而攻击者是相互独立的,不存在任何合作。未来工作可以考虑更加智能的协作式攻击者,能通过分享信息来实时更新攻击策略,以及当任意一个攻击者攻击失败时,其余的攻击者可以协助攻击。
猜你喜欢
大电机技术(2022年3期)2022-08-06
核科学与工程(2021年4期)2022-01-12
自动化学报(2021年8期)2021-09-28
锦绣·中旬刊(2021年3期)2021-07-14
煤气与热力(2021年4期)2021-06-09
锦绣·中旬刊(2021年8期)2021-03-15
中华戏曲(2020年1期)2020-02-12
爱你(2018年16期)2018-06-21
指挥与控制学报(2015年4期)2015-11-01
意林·作文素材(2015年14期)2015-08-26
