
唯密文场景下的分组密码算法识别方法*
2024-03-20 01:16张运理石元兵苏攀西
通信技术 2024年2期
张运理,石元兵,明 爽,籍 帅,苏攀西
(1.中电科网络安全科技股份有限公司,四川 成都 610095;2.可信云计算与大数据四川省重点实验室,四川 成都 610095)
0 引言
在当今这个信息爆炸的时代,数据安全和隐私保护已经成为人们关注的焦点。随着网络技术的发展,加密技术在信息安全领域的应用越来越广泛。分组密码算法作为加密技术的一种重要手段,以其高效、简单、易实现的特点,被广泛应用于各种场景中。然而,分组密码算法的安全性也受到了挑战,特别是受到唯密文攻击的场景。唯密文攻击是指攻击者仅知道加密后的密文,而不知道明文和密钥的情况下进行的攻击。在这种场景下,如何有效地识别出所使用的分组密码算法是一个重要的问题。
唯密文场景下的密码算法识别研究方向主要分为两种:一种是早期基于统计学的密码算法识别方法,另一种是基于机器学习算法的密码算法识别方法。Maheshwari 等人[1]首次使用统计学方法,以自然语言频数作为比较阈值,对密文中字母的出现频率进行统计,对代换密码、置换密码和维吉尼亚密码等几种古典密码算法进行了分类,并重点研究了数据加密标准(Data Encryption Standard,DES)和国际数据加密算法(International Data Encryption Algorithm,IDEA)两种密码算法的区分。随着密码学的不断发展,现代密码算法所生成密文的随机性复杂程度得到了极大的提升,基于统计学的识别方法已不再适用。研究人员尝试将机器学习算法应用到密文分析领域。Rivest[2]详细研究了密码学与机器学习两大领域结合应用的理论。Matthews[3]使用遗传算法分析传统置换密码。Ramzan 等人[4]提出可以使用神经网络进行加密算法识别。国内学者李继中等人[5]以汇编级密码算法特征分析为基础,首次提出了汇编级密码算法特征度量元的概念,并建立基于Bayes 决策的密码算法识别模型,该模型能高效地定位密码算法。文献[6]基于唯密文条件,对密码算法识别过程中的特征提取、分类器训练、特征选择和算法识别等关键技术进行了详细研究,分析了不同机器学习算法及特征选择方法对识别准确率的影响。文献[7]对密文特征选择方法进行了改进与创新,选择BP 神经网络、卷积神经网络与循环神经网络3 种深度学习算法分别对8 种密码算法进行识别,相较于基于随机森林的识别方法,准确率有巨大提升。
本文针对唯密文场景下的分组密码算法识别问题进行了深入研究,提出一种基于集成学习的唯密文场景下分组密码算法识别方法。该方法通过使用集成学习算法学习密文的随机性统计特征,如扑克检测、随机游走状态频数检测等,来识别密文所使用的分组密码算法。为了验证所提方法的有效性,本文进行了多组实验,并与现有的识别方法进行了比较。实验结果表明,本文所提方法在识别准确率和鲁棒性方面均优于现有方法。此外,本文还讨论了唯密文场景下分组密码算法识别的挑战和局限。
1 集成学习模型
基于集成学习思想,本文设计了一种基于混合梯度上升决策树和逻辑回归模型的唯密文场景下的对称密码算法识别方法。该集成学习模型是2014 年由Facebook 提出的[8],使用混合梯度上升决策树(Gradient Boosting Decision Tree,GBDT)模型[9]在训练过程中对特征进行自动组合和离散化,得到的离散向量与训练数据原特征组合作为逻辑回归模型(Logistic Regression,LR)的输入数据,最终输出分类预测结果。结合梯度提升决策树和逻辑回归算法,构建混合模型,利用梯度提升决策树在处理非线性问题上的优势及逻辑回归算法在处理二分类问题上的优势,提高模型的整体识别性能。模型结构如图1 所示。
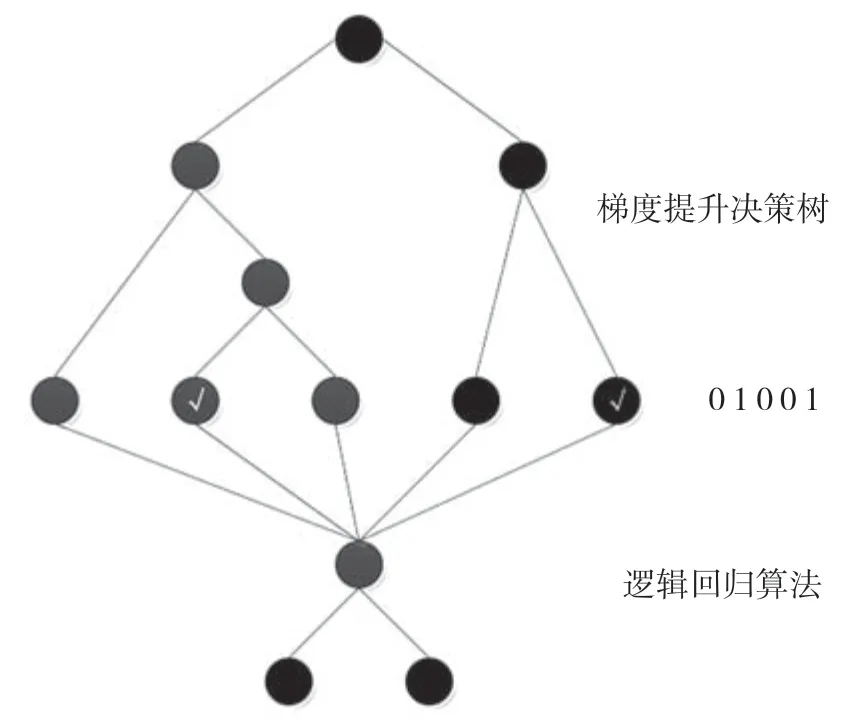
图1 GBDT+LR 集成学习模型
1.1 GBDT 模型原理及应用
GBDT 模型是一种迭代的决策树算法模型,它通过结合多个弱分类器来提高整体模型的性能。GBDT 的核心思想是每一棵树都是对之前所有树预测结果的残差进行拟合,即每个新加入的决策树都是为了修正前面所有决策树的预测误差。
具体来说,GBDT 的工作流程如下。
步骤1:初始化训练数据,将所有样本的预测值设为0。
步骤2:对于每一个训练样本,计算其残差。
步骤3:用当前的残差拟合一个新的决策树。
步骤4:更新样本的预测值。
步骤5:重复步骤2~4,直到满足预设的停止条件,如树的数量达到设定的最大值或残差小于某个阈值。
在实际应用中,GBDT 模型具有很好的可解释性和广泛的应用效果。它在数据挖掘、计算广告、推荐系统等领域都得到了广泛应用。此外,GBDT与LR 的结合也是一个重要的应用场景,用以解决LR 模型无法处理非线性数据的问题。
1.2 LR 模型原理及应用
逻辑回归模型是一种用于处理因变量为分类变量的回归模型,常见的是二分类或二项分布问题,也可以处理多分类问题。虽然名称中含有“回归”两个字,但实际上逻辑回归是一种分类方法。逻辑回归的原理为:首先通过伯努利分布和逻辑函数建立回归分析模型,其次通过最大似然估计法来求解模型中的参数。逻辑回归模型预测函数可以表示为:
式中:p为某个事件发生的概率,z为线性组合的特征值与偏置项之和。
在实际应用中,逻辑回归具有广泛的适用性。例如,它可以用于信用评分,预测客户是否会违约;也可以用于医学诊断,如预测患者是否患有某种疾病。此外,逻辑回归还可以应用于垃圾邮件过滤、推荐系统等领域。
1.3 GBDT+LR 模型的构建过程和集成策略
GBDT+LR 集成学习模型是一种两阶段的集成模型,它通过GBDT 模型自动提取特征,并将提取的特征输入到逻辑回归模型中进行分类预测。这种模型化的特征工程方法能够有效提升模型的预测性能,并减少人工特征工程的工作量,具体的构建过程如下文所述。
步骤1:利用GBDT 模型训练原始样本数据,得到一个二分类器。这一步通常涉及模型的训练和参数的调整。GBDT 是一种基于boosting 集成学习思想的加法模型,训练时采用前向分布算法进行贪婪学习,每次迭代都学习1 棵CART 树来拟合之前t-1 棵树的预测结果与训练样本真实值的残差。
步骤2:使用训练好的GBDT 模型做预测,例如,一个原始样本数据经过GBDT 后,可以得到一些新的特征,并对新特征进行One-hot 编码处理,这些新的特征可以看作原始特征的非线性变换或者组合。
步骤3:将GBDT 构造出的组合特征再与原始数据特征组合,输入到逻辑回归模型中进行训练。这一步通常也涉及模型的训练和参数的调整。
1.4 分组密码算法识别模型
基于GBDT+LR 集成学习模型构造唯密文场景下的分组密码算法识别模型框架,如图2 所示。
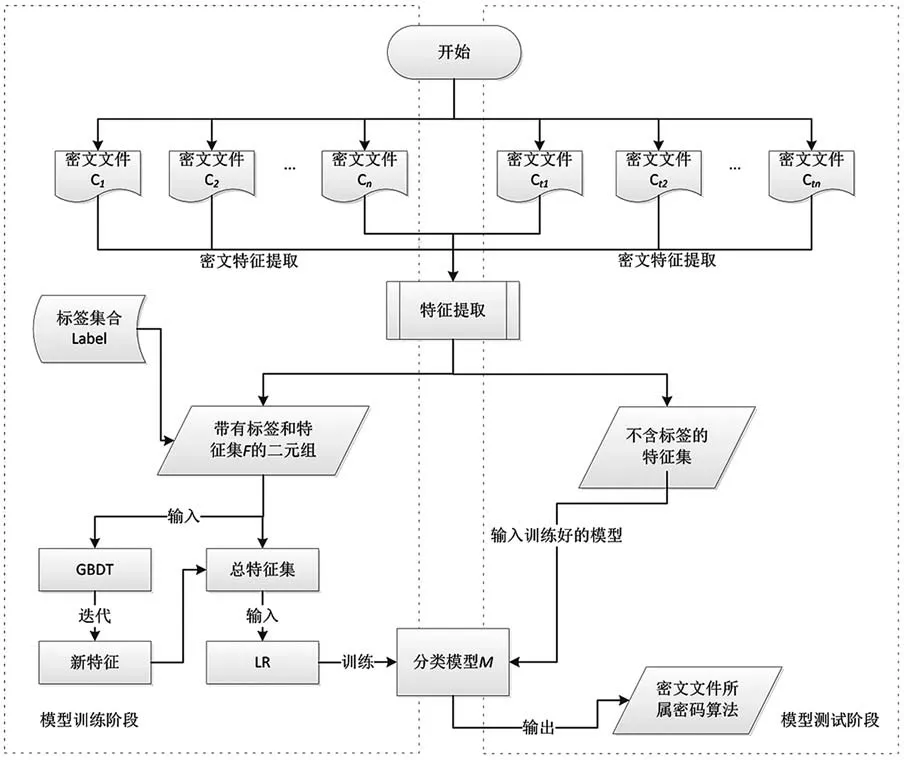
图2 分组密码算法识别模型
1.4.1 训练阶段
该模型从各类分组密码算法密文文件C={C1,C2,…,Cn}按2.2 节中的方法进行提取,并处理得到密文特征集F={F1,F2,…,Fn}与标签集合Label={L1,L2,…,Ln}。将得到的特征集作为GBDT 模型输入,对GBDT 模型N次迭代后得到的预测结果进行One-hot 编码,与原特征集组合得到新特征集Fnew={P1,P2,…,Pn}。将新的特征集作为LR 模型输入,对特征进行分类训练,输出训练好的集成学习分类器模型M。
1.4.2 测试阶段
对待识别的密文文件进行特征提取得到不含标签的密文特征FnoLabel,将提取到的特征输入训练好的分类器M中,输出即为识别结果。
2 数据集及特征提取
2.1 密文数据集构建
分组密码算法是对称密码算法的一种,其加密和解密过程中使用相同密钥的密码算法,并将明文分成固定长度的组,对每个组进行加密处理,最后得到密文。训练模型使用到的密文数据集由AES、SM4 和3DES 这3 种分组密码算法加密明文数据得到,分别包含10 万条数据。明文数据集使用THUCNews dataset 和AclImdb_v1 dataset,其 中THUCNews 是清华大学自然语言处理实验室根据新浪新闻RSS 订阅频道2005—2011 年间的历史数据筛选过滤生成的,AclImdb_v1 dataset 是用于二进制情绪分类的大型电影评论数据集。将明文划分为1 KB、2 KB、4 KB、8 KB、16 KB、32 KB、64 KB、128 KB、256 KB 和512 KB,使 用Crypto 及Gmssl库对明文进行随机密钥加密,加密模式为ECB、CBC 和GCM 这3 种,得到混合不同文件长度的密文数据集。
2.2 特征提取
分组密码算法设计安全性[10]中要求分组密码算法应遵循混淆原则和扩散原则,因此明文信息在经过加密算法编码后得到的二进制序列具有良好的随机性。现有研究中,美国国家标准与技术研究所(National Institute of Standards and Technology,NIST)制定的SP 800-22 标准[11]被广泛应用于随机序列随机性特征提取方法中,该标准包含15 个检测项,每项分为一级检测和二级检测,检测结果以P_Value呈现,如表1 所示。文献[12]中指出SP 800-22 的正态分布型检测项目二级检测存在不完备的情况,即通过这种检测的随机序列仍有可能在所检测的统计特性上存在缺陷,因此提出了Q_Value 的均匀性检测作为正态分布型检测项目的二级检测,这种新的检测方法能降低误检率提高可靠性。新的检测方法在行业规范《GMT 0005-2021 随机数检测规范》[13]中被使用,并提出了不同于NIST 标准的4 项随机数检测项,分别为扑克检测、游程分布检测、二元推导检测和自相关检测。本文采用随机数检测规范中的检测项对密文进行检测得到P_Value和Q_Value,并将其作为密文特征项(F_P1,F_P2,…,F_Pn;F_Q1,F_Q2,…,F_Qn),这些特征将用于描述密码的结构、频率等特性,为后续的模型识别提供依据。
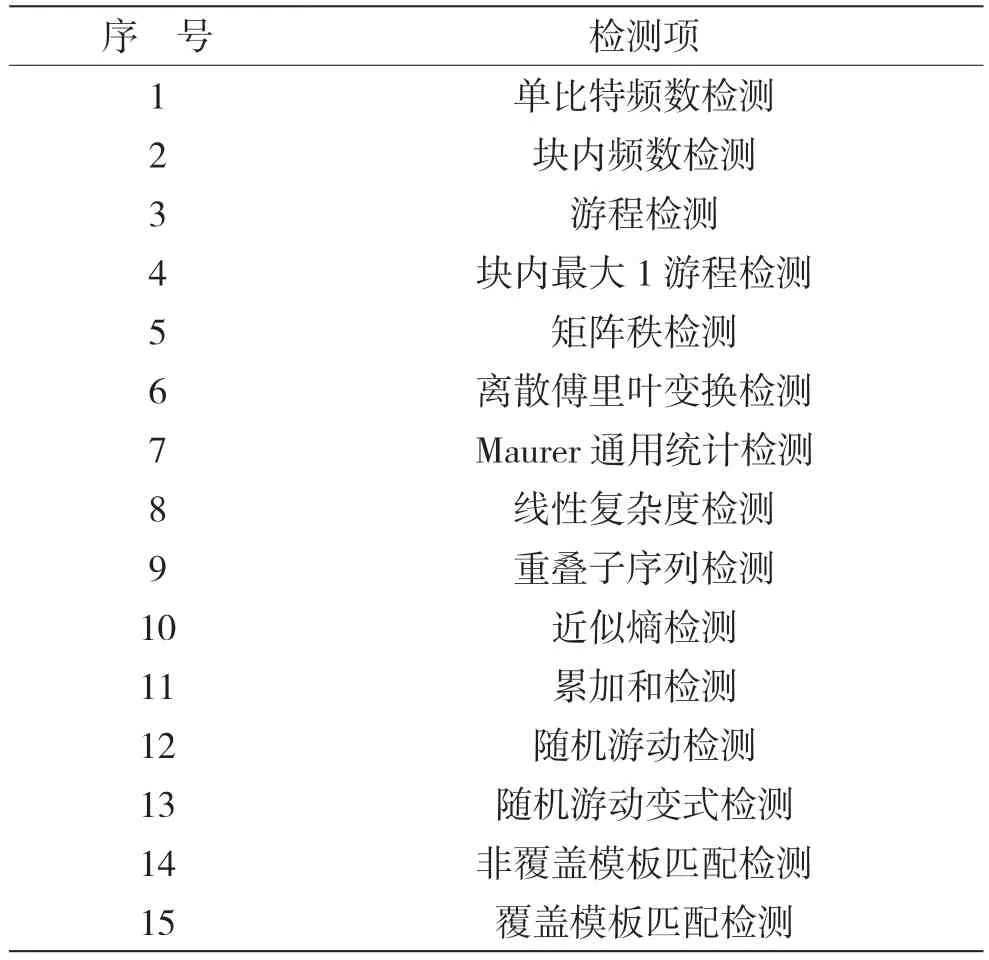
表1 NIST 随机数检测项
提取到的特征值不能直接作为模型训练数据,需要进行如下处理工作:
(1)将基于随机数检测项提取到的特征整理到一个CSV 文件中,并根据生成密文的算法进行标注;
(2)对数据集中存在异常值的特征样本进行清洗,这些值会影响模型训练效果,因此需要提前进行清洗。
3 实验结果及分析
3.1 评价指标
本文采用准确率Accuracy、F1 值作为模型性能好坏的评价指标,它们的计算式为:
3.2 结果与分析
本文使用十折交叉验证的方法对集成学习模型、梯度提升决策树模型和逻辑回归模型3 种分组密码二分类识别方案进行对比实验验证,结果如表2所示。从表中可以看出,在相同实验数据条件下,集成学习模型对密文所使用的加密算法的识别准确率明显高于单一模型20%左右,说明集成学习模型对分组密码算法的识别效果良好。同时,F1 值也与准确率呈现相同的规律,说明模型稳定性良好。
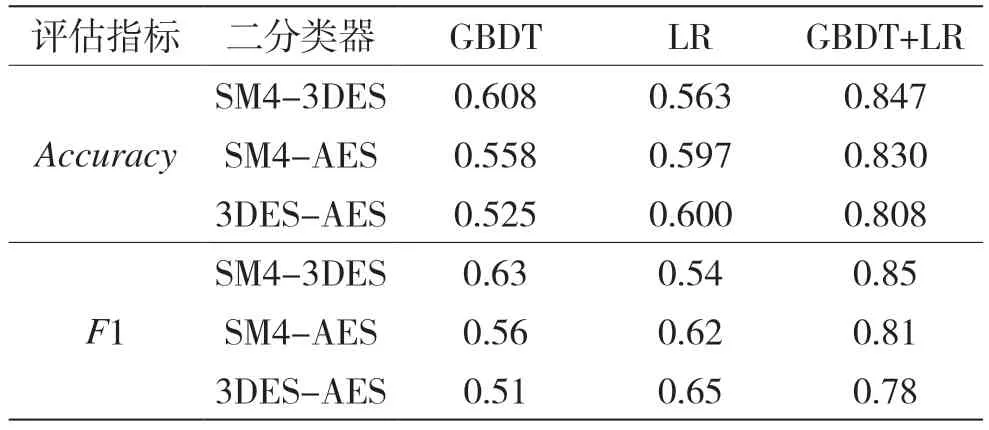
表2 分组密码算法二分类识别准确率及F1 值
4 结语
本文提出了一种唯密文场景下的分组密码算法集成学习识别模型,基于Q_value 二级随机数检测项提取密文特征。实验结果表明,集成学习模型识别效果优于单一识别模型,且在不同长度混合的数据集上具有良好的稳定性。后续研究工作中将进行特征优化以提高识别方法的鲁棒性和泛化能力,同时研究如何利用深度学习模型在唯密文场景下对分组密码算法进行识别。
猜你喜欢
电子与信息学报(2023年9期)2023-10-17
保健医苑(2022年4期)2022-05-05
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
成都信息工程大学学报(2019年3期)2019-09-25
学与玩(2018年5期)2019-01-21
电子制作(2018年16期)2018-09-26
语文世界(小学版)(2016年9期)2016-09-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
微型小说选刊(2015年5期)2015-06-05
