
跨尺度结构智能优化方法与快速设计
2024-03-21 05:54霍树林江和昕宋贤海周恩临何智成
机械科学与技术 2024年2期
霍树林,江和昕,宋贤海,周恩临,何智成
(1.湖南大学 汽车车身先进设计制造国家重点实验室,长沙,410082;2.南昌航空大学 材料科学与工程学院,南昌,330036)
拓扑优化技术是一种在有限的设计领域中寻找最优材料布局的强大的结构设计工具,被广泛的应用于汽车[1-2]及航空航天[3-4]等领域。拓扑设计通过寻找结构的最优材料分布来获得结构的最优性能。然而,若仅在结构宏观尺度进行优化设计,则难以发挥结构的最佳性能及进一步提升结构的轻量化效果,而同时考虑结构的微观拓扑构型和宏观材料分布能够有效释放设计潜力。因此,对结构进行跨尺度优化设计,即同时生成宏微观结构是进一步提升拓扑构型性能和轻量化效果的关键方法。
目前,拓扑优化算法有固体各向同性材料惩罚法[5](Solid isotropic material with penalization, SIMP)、进 化 结 构 法[6](Evolutionary structural optimization method, ESO)/双向渐进结构优化算法[7](Bi-directional evolutionary structural optimization method, BESO)
和水平集法[8]。Huang 等[9]基于BESO 实现了最大体积或最大剪切模量的多孔材料微观结构的优化设计。Gao 等[10]结合水平集法和数值均质化法对多孔复合材料的宏观结构和多个代表性微观结构进行了优化。付君健等[11]为实现二维和三维的多层级结构拓扑优化并避免其中的连接性问题,提出了一种基于子结构法的多层级结构拓扑优化方法。Li 等[12]基于水平集法提出了一种用于在一定激励频率范围内并发设计多相复合结构的多尺度拓扑优化方法并通过2D 和3D 数值算例验证了其有效性。尽管拓扑优化在结构优化设计中带来了极大的便利,然而,由于拓扑优化问题中存在大量的设计变量,并且在得到最优设计变量之前需要进行多次优化迭代,因此拓扑优化问题的计算成本非常高。而多层级拓扑优化相对于传统的单尺度拓扑优化增加了许多参数,计算成本更高,计算效率更为低下。
在过去的几年中,随着高性能计算技术的快速发展,深度学习算法也得到了快速的发展。深度学习作为一种数据驱动的方法,不仅是传统实验或模拟方法的有效替代模型,也是从各种数据中提取材料相关信息的革命性方法。许多学者已经把深度学习应用到了拓扑优化领域。Yu 等[13]提出了一种深度学习模型,该模型能够在不使用迭代方案的情况下预测给定边界条件和优化设置的优化结构。White 等[14]利用神经网络代理模型开发了弹性结构的多尺度拓扑优化框架。叶红玲等[15]采用生成式对抗神经网络实现了对跨分辨率拓扑构型的快速预测。Cheng 等[16]结合卷积神经网络和长短期记忆神经网络实现了在各种载荷条件和体积分数限制下,以最小柔度自动生成结构拓扑构型。深度学习在拓扑优化领域得到了很好的运用,然而,目前基于深度学习的拓扑优化研究大多集中在传统的单尺度拓扑优化上,关于多层级拓扑优化的研究少之又少。
本文提出了一种基于耦合深度学习的跨尺度拓扑优化方法来快速生成基于各种边界条件下最优微观和宏观拓扑结构。首先,利用BESO 算法产生数据,建立神经网络的数据库;然后,结合Resnet、U-net架构及SEnet 中的注意力机制建立用于快速生成跨尺度拓扑结构的深度学习模型。研究结果表明该模型在快速生成跨尺度拓扑结构的同时,也能保证93%以上的准确度。
1 并行拓扑优化设计
基于均匀化方法与BESO 优化策略,建立双尺度拓扑优化模型及其分析方法,通过分别在宏观尺度与微观尺度上进行灵敏度分析,获得各尺度最优的材料分布,为后续神经网络的输入提供数据支持。
1.1 双尺度优化系统
结构双尺度优化即同时对宏观构型与微观单胞进行优化设计。图1)所示为双尺度优化系统示意图,其中图1a)灰色区域为均匀多孔材料;图1c)黑色区域为优化得到的实体单元,白色区域为空洞单元。在优化中对各尺度进行结构离散,宏观单元设计变量定义为 αj(j=1,2,···,M),微观单元设计变量定义为 βj(j=1,2,···,N)。

图1 双尺度优化系统示意图Fig.1 Schematic diagram of a dual scale optimization system
为了获得清晰的拓扑,将材料插值方案应用于宏观和微观两个尺度上。在微观尺度上,采用人工材料插值模型得到的单元弹性矩阵DM可以表示为
式中D0为微观实体单元弹性矩阵。采用同样的插值方法,宏观单元弹性矩阵DMA可描述为
式中DH为等效弹性矩阵。等效弹性矩阵数值表达式可以用均匀化方法通过微观尺度分析来计算,计算式为
式中: |Y|为 材料单元细胞的面积;I为一个 3×3的单位矩阵;b为应变-位移矩阵;u为微观结构节点位移场。
1.2 并行设计拓扑优化模型
双尺度拓扑优化的目的是宏观上找到最优材料分布,在微观上优化周期单胞。两个尺度上的优化过程通过均匀化理论集成到一个系统中,分别在宏观尺度和微观尺度上进行计算。宏观尺度上的设计变量是离散宏观结构的单元相对密度,微观尺度的设计变量是离散微观结构的单元相对密度。本文以宏观结构柔度为优化目标,以体积为设计约束,建立双尺度拓扑优化数学表达式:
式中:C为平均柔度; αi为宏观结构第i号设计变量;βi为微观结构第j号设计变量;M和N分别表示在宏观层级和微观层级的有限元单元总数;Vi和Vj分别表示宏观结构第i号单元体积和单元细胞第j号单元体积;V和Vc分别为宏观结构体积和单元细胞体积大小;WMA和WMI分别表示宏观和微观上定义的体积分数;xmin为单元最小相对密度。
采用伴随方法,C目标函数关于宏观设计变量αi的灵敏度可表示为
其中
同理,目标函数C关于微观设计变量 βi的灵敏度可表示为
其中
由式(5)和式(7)可知,目标函数在宏观和微观层面的敏感性是相互关联的。宏观结构的位移场是评价微观结构设计变量的重要指标,而微观结构的设计变量将改变宏观结构的材料有效弹性张量。
2 数据的获取和处理
本文中用于训练神经网络模型的数据集主要由多对最优微观和宏观构型及其相应的边界条件、载荷和体积约束组成。数据集由常用的BESO 算法生成,设计域的大小为80 ×40,对拓扑优化的体积约束、负载和边界条件设置如下:1)体积分数从0.5到0.8 之间的均匀分布中采样得到,间隔为0.05;2)固定设计域的左边缘作为边界约束,力的施加位置从设计域右侧的节点集合中选择,力F= 1 kN,所施力的角度 θ ∈[0,175◦],每隔5°取一个测试点。根据上述参数设置,通过BESO 算法进行相应的计算,计算得到的最优微观拓扑构型和最优宏观拓扑构型分别保存在两个文件夹中。把生成的数据中有错误的数据剔除,最终产生了10200 个数据对用于神经网络模型的训练。其中的一个负载和边界条件及生成的多层级结构如图2 所示。
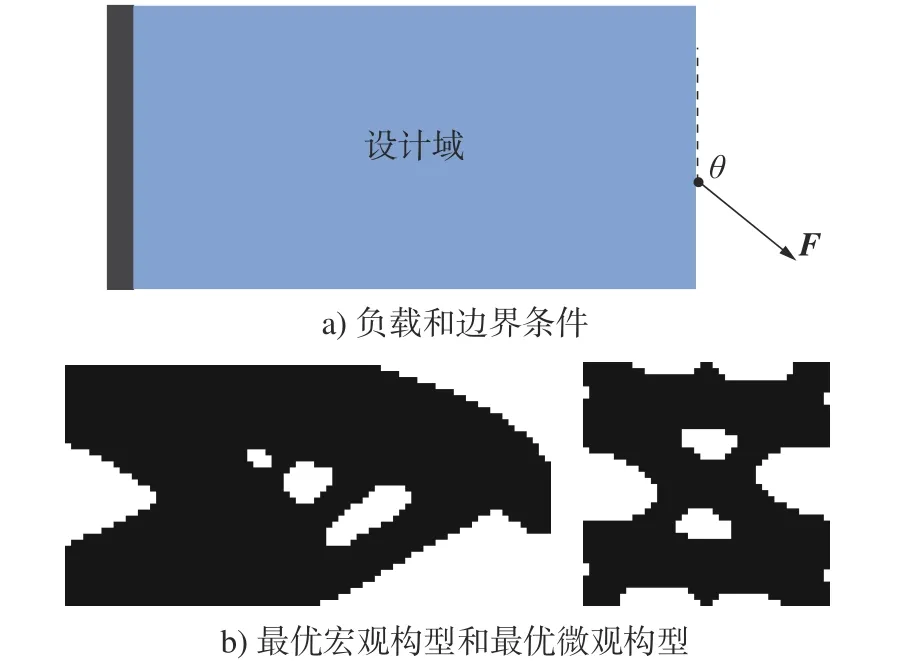
图2 边界约束及相应的多层级结构Fig.2 Boundary constraints and corresponding multi-layer structures
由于本文使用了卷积神经网络,因此需要把输入信息转化成适合卷积神经网络的数据形式。由于本文使用的拓扑优化的设计域为80 ×40,因此总共由81 ×41 个节点。体积约束、负载和边界条件通过图片表示如图3 所示。如图3 所示,体积约束、边界条件和负载都用含81 ×41 个像素点的图片表示。这样,对于边界条件和负载,使用两个数据矩阵表示X方向力和Y方向力的加载位置及约束位置,其中约束位置标记为“1”,加载位置分别标记为“Fx=Fsinθ ”, “Fy=Fcosθ”,其余位置则都标记为“0”,如图3a)和图3b)所示。对于体积约束,使用像素值全为体积分数值的图片表示,如图3c)所示。

图3 X 方向力及边界条件,Y 方向力及边界条件, 体积约束Fig.3 X-direction force and boundary conditions, Y-direction force and boundary conditions, volume constraints
3 耦合神经网络模型
本文主要目标是提出一个耦合深层神经网络模型来加速跨尺度拓扑优化结构的生成。该耦合神经网络模型结合了Resnet、U-net 架构和SEnet 中的注意力机制。由Resnet 模块组成的U-net 是本文的主体网络,而SEnet 中的注意力机制则加入到Resnet模块中以提高网络的精度。
3.1 Resnet、U-net 和SEnet 介绍
卷积神经网络是一种特殊架构的前馈网络,它的生物启发类似于动物视觉皮层的组织,其中每个单独的皮层神经元仅对受限视觉区域中的外部刺激做出反应。类似地,卷积神经网络内部的卷积层包括多个卷积滤波器。每个过滤器都与来自上一层的输入进行卷积,并生成特征图作为下一层的输入。卷积神经网络主要由若干卷积层和池化层组成,在图像处理方面有着十分出色的表现。然而,随着卷积神经网络深度的增加,其泛化能力没有提升,反而下降。而Resnet 的出现解决了这一问题。Resnet中的残差块如图4 所示。
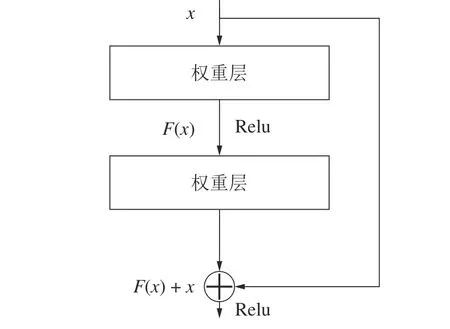
图4 Resnet 中的残差块示意图Fig.4 Schematic diagram of residual blocks in Resnet
由图4 可知,输入经过非线性变换后,又加上了原来的输入,这样子就保证了输入经过非线性层之后的结果不会比原来的结果差。因此,本文选取Resnet 作为主干网络。
U-net 是一种全卷积的网络结构,最初是为了解决图像分割问题而被发现的。U-net 以其特殊的模型架构命名。U-net 包括一个下采样过程和一个上采样过程。下采样过程和传统的卷积神经网络一样,使用池化层将少图片的维度,并随着网络的深入,逐渐提取全局图像特征。而上采样过程则分两步进行:一是扩展特征图大小的反卷积算子;二是concatenate 层,它结合了不同层次的特征,这样子可以通过下采样和上采样获得全局和局部特征。同时,输出可以调整为原始图像大小。因此,本文采用U-net 架构来生成跨尺度拓扑结构。
SEnet 是一种全新的图像识别结构,它可以通过对通道的相关性进行建模来强化重要的特征而提高模型的准确性。SEnet 中一个模块如图5 所示。

图5 SE 模块示意图Fig.5 Schematic diagram of SE module
SEnet 的计算过程主要分为3 步:
采用SPSS 23.0统计软件进行数据分析。定量资料以均数±标准差(x±s)表示,先进行正态性分析;正态分布资料采用两独立样本t检验、非正态分布资料采用两独立样本Mann-Whitney U检验,定性资料用百分数(%)表示、采用卡方检验进行组间比较。当P<0.05时表示差异具有统计学意义。
1)输入X经过一次卷积操作Ftr后,特征通道数由c1变成了c2,得到U。
2)U经过全局池化Fsq降维,然后经过两个全连接层Fscale为每个特征通道生成权重。
3)将第二步生成的通道权重逐通道相乘到U上。
通过这3 个步骤就可以自动获取每个通道的重要程度,然后依据这个重要程度来增强有用的特征而抑制对当前任务无用的特征,从而实现通道的自适应校准,提高网络的准确度。
3.2 耦合神经网络模型的建立
耦合神经网络模型架构和 Resnet-SE 模块如图图6 所示。
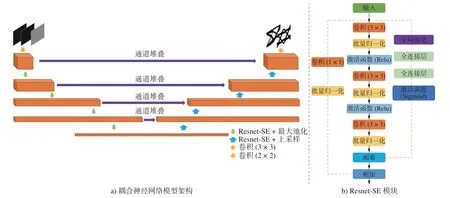
图6 耦合神经网络模型架构 和 Resnet-SE 模块Fig.6 Coupled neural network model architecture and resnet-SE module
建立如图6a)所示耦合神经网络模型,模型的输入包含3 张图片,分别是X方向力及边界条件,Y方向力及边界条件和体积约束,大小都为41 × 81。模型的输出包含两张图片,分别为最优的宏观构型和最优的微观构型。如图6a)所示,主体网络模型的左边部分由Resnet-SE 模块和池化层组成,主要提取输入图片的特征信息和对图片降维;网络的右边部分由上采样和Resnet-SE 模块组成,用来恢复被池化计算减少的数据维数,并采用通道堆叠操作分别将左边对应层的输出连接到当前层。通过采用这种特殊的U 形架构,可捕获输入的全局和局部信息,可以训练模型以预测最优的多层级结构的演变。图6b)表示了主体神经网络中使用的Resnet-SE 模块,它由批量归一化处理、整流线性单元(ReLU) 、卷积层、全连接层和‘Sigmoid’激活函数组成。图中右边的通道表示SEnet 在Resnet-SE 模块的实现,中间和左边的连个通道则为Resnet 的实现。
4 结果分析
在建立了适合用于生成跨尺度拓扑结构的耦合神经网络模型后,利用生成的数据样本对模型进行训练。共有102000 对数据作为训练、验证及测试数据。图7 和图8 展示了模型损失函数和准确率的收敛历史。随着训练次数的增加,损失函数值逐渐降低,准确度逐渐增大,训练和验证过程的损失函数值和准确度的趋势都一致且相差很小,训练模型的总体质量较好,过拟合度在可接受的范围内。
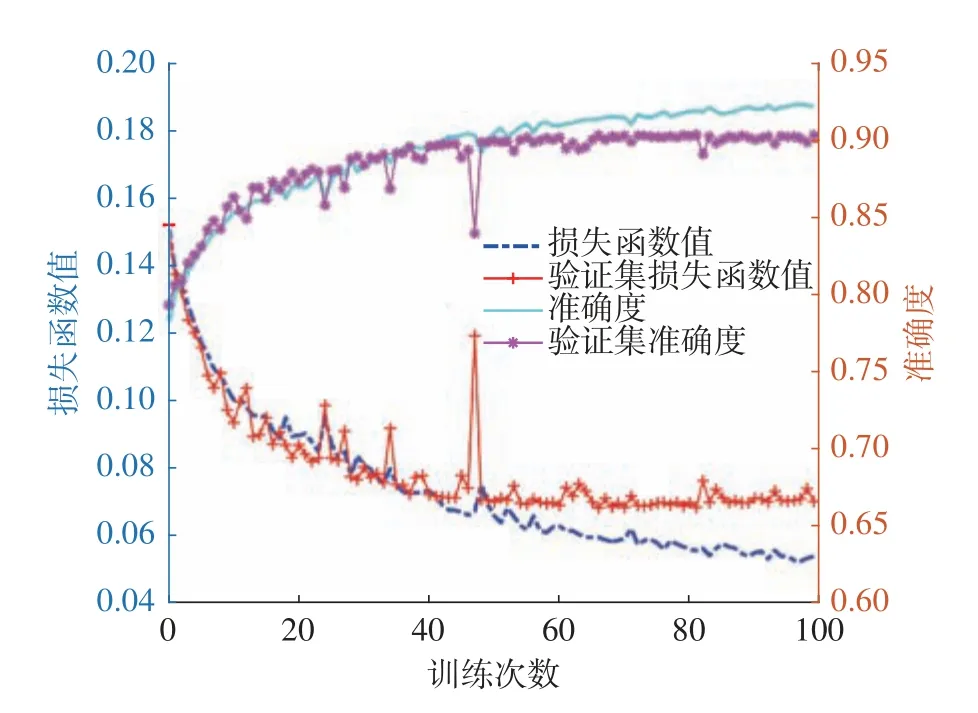
图7 针对宏观构型的训练历史参数的变化Fig.7 Changes in training history parameters for macroscopic configurations

图8 针对微观构型的训练历史参数的变化Fig.8 Changes in training history parameters for micro configurations
训练过程完成后,通过使用与训练数据集和验证数据集不同的测试数据集来对模型进行最终评估。同时,Dice 系数也被计算来定量评价模型的性能,Dice 的定义表达式为
式(9)用来计算两张图片 [y,](y表示真实的图片,表示预测的图片)的相似度。最后,通过从测试数据集中随机挑选的最优跨尺度拓扑结构来与真实的最优跨尺度拓扑结构进行比较来进行定性评估。
表1 表示一些BESO 生成的跨尺度结构和耦合深度学习模型生成的跨尺度结构的比较及计算得到的Dice 系数(表中的例子为从测试集中随机选取的10 个样本)。结果表明,耦合深度学习模型生成的跨尺度结构与BESO 的结果几乎一样,深度学习模型在模拟BESO 的优化过程中有着很好的性能。计算深度学习模型生成的跨尺度结构和BESO 的结果的Dice 系数,无论是宏观结构还是微观结构,Dice 系数均在0.93 以上,其平均Dice 系数分别为0.954 和0.946。Dice 系数表明提出的深度学习模型生成的多层级结构与BESO 的结果的相似性在93%以上,耦合深度学习模型生成的最优多层级结构是非常可靠的。

表1 深度学习模型和BESO 方法生成的二维多层级拓扑优化结构的比较(从测试集中随机选取的10 个样本)Tab.1 Comparison of 2D multi-level topology optimization structures generated by deep learning models and BESO methods(10 samples randomly selected from the test set)
表2 对耦合深度学习模型生成最优跨尺度拓扑结构的计算时间和基于有限元的BESO 方法生成最优跨尺度拓扑结构的计算时间进行了对比(表中数据为表1 中的10 个样本对应的计算时间)。
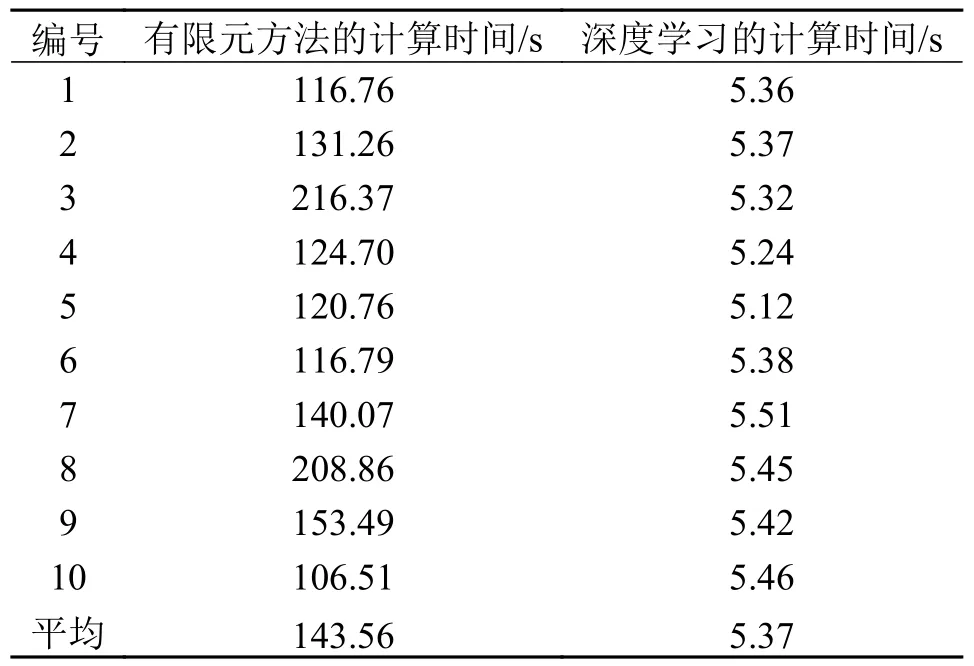
表2 有限元方法与耦合深度学习方法计算时间的比较Tab.2 Comparison of computational time between finite element method and coupled deep learning method
由表2 可知,对于有限元方法,生成一个最优跨尺度拓扑结构的平均时间为143.56 s,而对于深度学习方法而言,从读取数据、生成结构、计算Dice 系数及保存数据,平均时间为5.37 s,相对于有限元方法节约了96%的时间,本文提出的耦合深度学习方法在效率上远远优于传统的有限元方法。综上所述,本文提出的耦合深度学习方法能在保证结果的高准确性的情况下,高效的生成最优跨尺度拓扑结构。
5 结论
本文提出了一种能快速生成基于各种边界条件下最优微观和宏观拓扑结构的耦合深度学习方法。作为一种数据驱动的方法,该耦合深度学习模型由BESO 生成的数据样本进行训练,以获得用于生成跨尺度拓扑结构的神经网络结构。与传统的基于有限元方法的结果相比,该耦合深度学习模型生成的结果的准确性在93%以上,深度学习模型生成的结构与BESO 生成的结构几乎一样。与此同时,深度学习生成跨尺度拓扑结构的时间比基于有限元的BESO 方法节约了96%以上,大幅提高了跨尺度拓扑优化的效率。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
制造技术与机床(2017年5期)2018-01-19
中国机电工业(2016年5期)2016-12-01
太空探索(2016年5期)2016-07-12
河南电力(2016年5期)2016-02-06
诗选刊(2015年6期)2015-10-26
中国机电工业(2015年5期)2015-02-28
时代英语·高三(2014年5期)2014-08-26
浙江人大(2014年8期)2014-03-20
浙江人大(2014年6期)2014-03-20
