
基于改进AE-CM模型的未知应用层协议识别
2024-03-25 02:05马甜甜
计算机技术与发展 2024年3期
马甜甜,洪 征,陈 乾
(陆军工程大学 指挥控制工程学院,江苏 南京 210014)
0 引 言
未知协议识别是指在网络通信中识别出无法被预先确定的、类型未知的协议的过程。未知协议识别方法依据协议特征对网络流量进行分类,有助于发现异常的网络通信活动[1]。提高未知应用层协议的识别能力,有利于安全高效地提供网络服务[2]。
基于深度聚类的未知协议识别方法[3]通过神经网络模型对网络流量进行特征提取,并进行聚类分配。该方法适用于不同协议的特征和流量分布。
与此同时,基于深度聚类的未知协议识别方法[4]主要存在以下问题:
(1)特征提取和聚类分配是相互独立的过程,聚类结果不能指导特征提取,导致聚类性能不佳。
(2)未知协议的特征不确定,仅从时间或空间的单一维度提取特征会造成特征不充分。
(3)嵌入式聚类分配模块对不同特征的影响程度不同[5],但在分配初始权重时采用随机或相等的权重值,模型需要多次更新,收敛速度较慢。
AE-CM[6]在现有深度聚类模型的基础上设计了嵌入式聚类分配模块,克服了聚类分配模块对特征提取模块指导性不强的问题。该文以AE-CM为基础,提出了未知协议识别模型(DAEC-NM)。该文的主要研究工作如下:
(1)提出了一种新的未知协议识别模型,改进了AE-CM,并将改进模型应用于未知协议识别。
(2)在特征提取模块中插入重新设计的神经网络模块,增强了模型对协议时空特征的提取能力。经过特征提取模块获取的丰富特征能够被用于指导聚类簇的产生。
(3)使用Two-branch[7]中提出的邻居模型提高协议识别的准确性。使用邻居分支来捕获邻居样本的格式信息和关联特征,并根据邻居特征提高主分支中相关协议特征的权重。
(4)在聚类模块中引入了注意力评分机制。记录模型特征提取过程中的特征权重,并在样本聚类分配过程中为相关特征设置合理的初始权重,指导样本进入相应的聚类簇。
(5)实验结果表明,与现有的基于深度聚类的未知协议识别方法相比,DAEC-NM在ACC、ARI和NMI等指标上都有明显提升。
1 协议识别模型的设计
未知协议的识别主要包括协议数据预处理以及协议识别,如图1所示。数据预处理包括三个步骤。流量清理主要去除与协议识别无关的数据包,提高协议识别准确性。流重组和分割将网络流量转换为符合深度自编码器输入格式的数据,并将请求与响应组合在一起,便于分析协议内的关联关系。此后从网络流的开头截取固定长度的段,并根据需要执行截断和填充操作。最后,流量数据归一化对获得的固定长度的序列进行归一化操作,并将序列转换为固定格式的二维张量。通过数据预处理,可以提高输入数据的质量,减少数据噪声,保证模型训练的有效性和准确性。

图1 未知协议识别的流程
该文提出的DAEC-NM如图2所示,主要包含一个深度聚类分支(DAEC-branch)和一个邻居分支(NM-branch)。其中DAEC分支中包含协议特征的提取模块(feature extraction module)、聚类分配模块(clustering module)和协议重构模块(protocol reconstruction module)。各模块的具体工作将在后文详细论述。

图2 DAEC-NM结构
1.1 协议识别模型的特征提取
深度聚类模型DAEC的设计如图3所示,特征提取编码器根据其功能模块将输入的数据流张量转换为协议特征,聚类分配模块根据协议特征输出聚类簇分配结果,并根据协议簇分配结果重新调整协议特征权重,协议重构解码器根据协议特征重构协议样本。在设计未知协议识别模型中的特征提取编码器时,传统的堆栈自编码器处理非局部特征信息时不够灵活。DAEC模型采用了简单卷积模块、时序卷积模块和多层感知机模块来提取协议样本的特征。简单卷积模块采用高维卷积对协议样本进行空间特征提取,以增强对不同协议的区分能力。时序卷积模块是一种时间序列模型,通过残差链接块和膨胀因果卷积提取协议数据中的时间相关特征,以提高聚类分配的准确性。多层感知机模块采用全连接层对前两个模块提取的特征进行组合和抽象,增强对协议特征的区分能力。为了避免模型计算冗余参数的压力,该文向MLP中插入衰减层Dropout1,Dropout2,提高模型的泛化能力和稳健性。这些模块相互结合,可以挖掘协议数据的空间特征和时间特征,增强挖掘特征对不同协议的区分能力。

图3 DAEC自编码器模型结构
1.1.1 简单卷积模块
简单卷积模块由两个卷积层组成,用于提取协议样本的空间特征。协议特征在卷积层的输出值计算方法为:
y=ReLU(Wyx+by)
(1)
其中,y代表卷积操作后的输出,Wy代表卷积核权重,by表示偏置,ReLU表示激活函数。
1.1.2 时序卷积模块
TCN由多个残差模块(Residual Convolutional Block)构成,其处理函数为TCN(),它的正向传播计算过程如下:
ht=ReLU(max(Whxt+bh))
(2)
(3)
(4)
ft=Wfxt+bf
(5)
(6)

1.1.3 多层感知机模块
从TCN模块输出的特征输入MLP模块,MLP模块的正向传播计算公式如下:
z1=W1x+b1
(7)
(8)
x1=z1·d1
(9)
z2=W2x1+b2
(10)
(11)
x2=z2·d2
(12)
z3=W3x2+b3
(13)
其中,W1,W2和W3表示权重,b1,b2和b3表示偏置,p1和p2表示衰退层保留节点的概率。
1.2 邻居分支与补充特征
高维特征空间表示可能无法捕捉到协议数据的语义和局部联系。为了解决这些问题,该文采用了Two-branch方法设计邻居分支,采集邻居特征获得更丰富的协议信息,增强模型对协议的学习能力。邻居分支对邻居样本的二维张量进行特征提取,使用平均池化来得到一组邻居中心特征,从而获得一组通道特征和局部相关特征。这样,邻居分支可以帮助深度聚类模型更好地捕获协议数据的语义和局部联系,从而提高协议识别的准确性。
1.2.1 邻居编码器模块设计
模型的编码器可分为X编码器和邻居编码器,如图4所示。两个分支结构的网络模型相同且同步输入,X编码器分支输入样本x,邻居分支通过最近邻方法[8]将前次聚类结果中x的k个最近邻样本作为输入。假设一个输入邻居样本为z,它的前向传播过程如下:

图4 编码器模型邻居分支结构
简单卷积模块的处理:
yz=ReLU(Wyz+by)
(14)
时序卷积模块的处理:
rz=TCN(yz)
(15)
多层感知机模块的处理,简写为:
mz=Wmz+bm
(16)
其中,Wm表示权重,bm表示偏置,需要通过多层感知机训练学习得到。
1.2.2 邻居编码器权重加强设计
样本邻居的特征可以为协议分析提供更全面的信息,同时可以发现其他样本的特征模式,进而深入了解数据的总体特征。
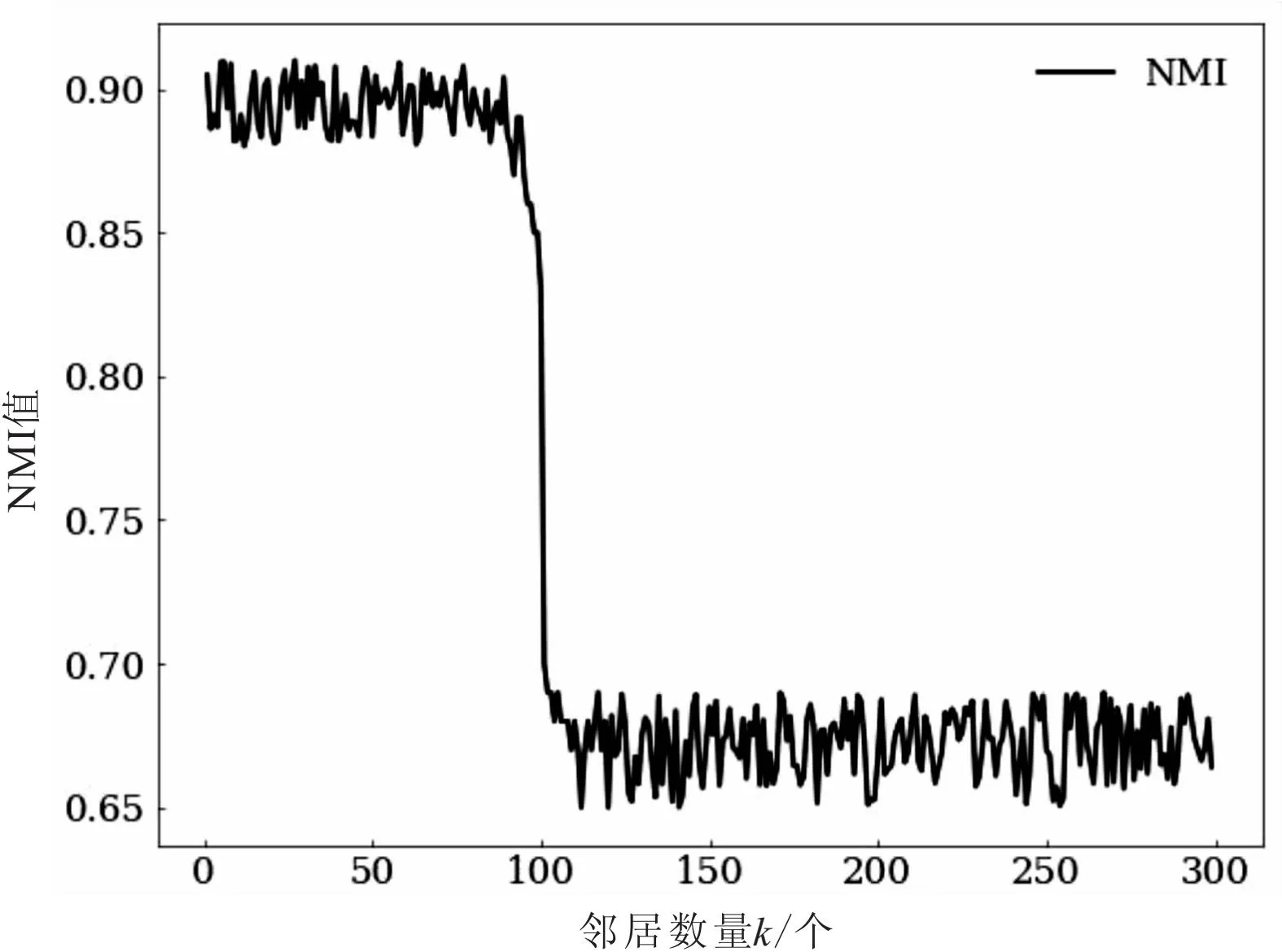
X分支和邻居分支获得整体样本特征表示z=[z1,ze,z3,…,ze]和邻居特征表示m=[mz1,me,…,mzk,0,0,0,…](k (17) 其中,θ表示增强参数,一般小于0.5,防止邻居特征中的冗余特征过强,影响原样本特征。 将加强后的特征输入聚类层之前的隐藏层,筛选权重较强的特征,其前向传播计算为: (18) 在AE-CM中使用RMABs[9]映射方法,设计嵌入式聚类模块,它将原始特征空间映射到低维的嵌入空间,并在嵌入空间中进行聚类。 在RMABs映射方法中,将EM算法迭代过程封装为一个小型自编码器表示的聚类模块,映射过程如下: F-step:Rd→RK,F(x)=〈p(z=k|x)〉{1≤k≤K}= γ~softmax(XWenc+Benc)=Γ (19) (20) AE-CM中聚类模块的gamma层的初始权重矩阵采用随机数进行设置,需要多轮训练来找到合适的特征权重初始值,降低了模型的识别效率,增加了训练开销。为解决这一问题,该文使用加性注意力评分机制[10]生成初始权重矩阵。该评分机制捕获特征关联性和重要性评分,得到特征权重评分矩阵,并使用该评分矩阵作为初始化的gamma层权重矩阵,从而使gamma层在几次迭代后快速收敛。这种方法可以降低训练次数,减少训练开销,提高模型的识别效率,同时保持聚类模块的对称性。 聚类模块总体设计如图5所示,gamma层对于上层网络提取的每一个协议特征,通过注意力评分函数获得注意力评分,用来表示该特征的重要性。在此基础上,对注意力评分进行加权平均f,得到最终的初始注意力评分矩阵Wh,通过gamma层将该样本特征表示输入相应簇中。相较于公式19,加入注意力评分机制的gamma层前向传播计算方法为: 图5 基于注意力评分机制的聚类模块 (21) h=Wha+bh (22) (23) 其中,Wv,Wq和Wk表示权重,bh表示偏置,a为注意力评分后加权平均层,h为隐藏层,g为gamma聚类层输出。 公式20中原mu layer是一个逆线性变化层ΓWdec+Bdec,为了抵消加性注意力机制的影响,聚类模块中G-step设计为一个多级权重衰减[11]的逆线性变化过程,mu layer前向传播计算为: mu=Γ•Dropout(Wh)+b (24) 其中,Wh是gamma层提供的注意力权重。 该文提出的未知协议识别模型,通过四个步骤(特征提取、聚类分配、协议重构、模型优化)进行协议识别。特征提取模块采用两个分支的设计,嵌入式聚类分配模块使用gamma层进行聚类分配,使用mu层调整未知协议特征的影响权重,最后使用重构误差和聚类损失来联合优化模型。模型不需要标记标签就能够自动识别未知协议的分布情况。 基于Tensoflow2.0构建了未知协议识别原型系统。为评价模型的性能,主要考虑了以下标准: (1)评价邻居数量以及邻居分支对协议识别性能的影响。 (2)评价改进聚类模块对协议识别性能的影响。 (3)与其他协议识别模型进行比较,并对协议识别模型的整体性能进行了评价。 选择数据集IDS2017[12]进行实验。数据集包含的是网络流量数据,以pcap的格式提供。提取了四种应用层协议(HTTP,FTP,DNS和SMB)进行测试。根据预处理方法对协议数据进行预处理后,得到了45 514条有序的网络流。在实验中,协议的标签被删除,从而使所有的协议都可以被视为未知的协议。为了评估所提出的协议识别模型的有效性,选择了精确度(ACC)、归一化互信息(NMI)和调整兰德指数(ARI)作为评估指标。 2.2.1 邻居的影响 该文通过邻居分支提取样本邻居的特征作为补充特征。在邻居分支的设计过程中,通过近似算法选取k个样本邻居。需要设置实验分析邻居数量对协议识别效果是否有影响。此外,需要设置实验探究邻居分支对协议识别模型识别精度的提升效果。 (1)邻居数量的影响。 探究邻居数量对协议识别模型效果影响,设计k邻居数量范围为1~300,实验通过NMI值随k值变化,探究邻居数量的影响。 从图6分析可得,邻居数量小于90时,NMI曲线波动小,邻居数量超过110时,NMI曲线恢复平稳波动;而邻居数量在100左右时,NMI曲线急剧下降。NMI值在邻居数量小于100时较高(约0.9),在邻居数量超过100时较低(约0.66)。 图6 NMI值随k的变化 从实验结果可以看出,较远处的邻居与原样本相差较大,从而导致原样本的特征被邻居样本的补充特征干扰。因此,该文选择较小数量的k值,能够呈现较好的协议识别效果。 (2)邻居分支的影响。 为探究邻居分支对协议识别模型的效果影响,通过实验比较带邻居分支的模型和不带分支的模型的识别效果。实验中分别获得协议识别模型(DAEC)带邻居分支(NM)和不带邻居分支(NA)情况下,模型的精确度(ACC)、调整兰德指数(ARI)和归一化互信息(NMI)。 从表1中得出以下结论:带邻居分支的深度聚类模型协议识别表现优于不带邻居的模型。 表1 有无邻居状态下协议识别模型表现 % 表2 有无注意力评分机制的聚类模块对协议识别模型表现的影响 % 2.2.2 注意力评分机制在聚类模块中的影响 探究注意力评分机制在聚类模块中对协议识别模型的效果影响,通过实验比较聚类模块(CM)包含和不包含注意力评分机制对协议识别模型的效果。实验结果显示,相较于不包含注意力评分机制的聚类模块,包含注意力评分机制的聚类模块的协议识别模型表现更优。精确度提升了4.23百分点,ARI指数提升了11.63百分点,NMI指数提升了10.78百分点。其原因在于,注意力评分机制侧重于提高协议识别模型对于重要特征的关注度,有利于提高聚类效果。具体来说,注意力评分机制可以通过动态给不同的特征分配不同的权重,使得那些更具有代表性和区分度的特征能够更好地被聚类模块所利用。 2.2.3 与其他模型的横向比较 为了验证所提出的未知协议识别模型的性能,将该模型与DEC[13],CAE[14],AE+K-Means[15],K-Means和GMM进行横向比较。 其中,K-Means和GMM是传统的聚类算法,常用于协议识别模型中。根据本研究实验结果设置它们的参数,K-Means聚类簇数为4,GMM的成份数为4。深度聚类的方法包含DEC,CAE,AE+K-Means,AECM以及DAEC-NM(ours),其中除该文设计的网络外,其他方法的自编码器均为对称的堆栈多层感知机。 不同协议识别模型的协议识别结果如表3所示。在表3所示的协议识别模型中,K-Means和GMM表示基于机器学习的协议识别模型,其余为基于深度聚类的未知协议识别模型。实验结果表明,提出的深度聚类协议识别模型优于传统聚类模型,在此基础上,基于高斯混和聚类的模型优于基于K-Means聚类的模型。同时,嵌入式模型优于异步训练的模型,因为嵌入式模型能够更好地将聚类表现融入到编码器的训练中。此外,增加卷积模块的自编码器模型也优于原堆栈编码器模型,能够增强模型的时间、空间特征的提取能力,从而提高识别精度。总体而言,提出的协议识别模型比DEC模型在ACC,ARI和NMI评判标准上分别提高了12.03百分点,25.52百分点和17.78百分点。 表3 各种方法下协议识别模型表现 % 该文提出了一种未知应用层协议识别模型(DAEC-NM)。该模型的特征提取模块包含两个分支,主分支采用时空卷积网络来提取协议数据的时空特征,邻居分支捕获邻居样本间的局部关联特征作为补充。模型的聚类模块通过增加注意力评分机制的方法进一步优化识别模型,并实现聚类簇分配。实验结果表明,该模型在识别性能上优于其他协议识别模型。在未来的工作中,考虑把该模型应用于协议逆向分析、入侵检测等领域,为网络安全提供有效的保障。1.3 基于注意力评分机制的聚类模块的设计

1.4 协议识别过程
2 实验分析
2.1 数据集与评价标准
2.2 实验结果分析



3 结束语
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
学生天地(2019年28期)2019-08-25
电子制作(2019年11期)2019-07-04
成都信息工程大学学报(2018年3期)2018-08-29
北京航空航天大学学报(2018年1期)2018-04-20
数学物理学报(2018年1期)2018-03-26
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
电视技术(2014年19期)2014-03-11
