
基于改进条件生成对抗网络的字体风格迁移算法
2024-03-25 01:58王存睿战国栋
大连民族大学学报 2024年1期
赵 明,王存睿,战国栋
(大连民族大学a.计算机科学与工程学院b.设计学院;c.大连市汉字计算机字库设计技术创新中心,辽宁 大连 116650)
设计一套新的中文字体对于设计师来说需要耗费大量的时间,因此现在很多工作通过算法自动进行字体设计。然而不同于英文字母的风格迁移或者其他风格迁移任务,汉字结构复杂、笔画丰富而且不同字体都有自己独特的风格,因此汉字的风格迁移是一项很艰难的工作。
1 研究现状
1.1 字体风格迁移任务现状
现有的汉字风格迁移方法可以分为通过神经网络学习笔画的组合方式和基于端到端网络进行图像生成两大类。
第一类方法将汉字看作各种笔画的组合,通过神经网络学习汉字的各种结构信息,并通过生成目标字体的部件以组合的方式得到目标字体。Junbum等人[1]通过引入部件复用的概念,通过提出的一种具有类似存储器功能的部件分析模块,在训练的过程中学习不同部件的特征,在解码时从其中取出对应部件的特征组合成目标字体;Xie等人[2]提出很多字体的风格可以通过标准字体经过变换得到,因此他们提出引入可变形卷积对输入字的特征进行处理,通过对齐标准字和目标风格字的特征进行字体的风格迁移;Tang等人[3]的方法同样使用基于部件复用的方法进行目标风格字体的生成,通过引入交叉注意力机制使模型能够更好地匹配内容字和风格字的空间特征,使目标字体的部件能够准确地迁移到源字体的对应部位。
另一类方法基于端到端的神经网络,通常使用编码器-解码器的结构直接将输入的源字体图像转换为目标字体,这类方法通常使用生成对抗网络[4]的方式进行训练。Zi2Zi[5]是这类方法的代表,它基于Pix2Pix[6]的网络结构进行改进,训练U-Net结构的生成器使其能够输入一个标准汉字得到一个具有特定风格的汉字。Wen等人[7]引入了循环生成对抗网络[8]的模式,加入了一组额外的生成器和判别器,使生成的目标风格字体映射回原来的字体,通过循环一致性的方式约束目标风格字体的生成质量。
1.2 现有字体风格迁移方法的不足
现有的字体风格迁移方法很难收敛,例如将源字体图像经过编码器进行编码,再将其解码成目标字体图像。由于这个过程需要处理很多细节和复杂性,所以需要大量的数据和时间进行训练。
4、及时与学生家长沟通,共商良策。当深入了解情况,发现问题源地、中心人物以及迷信思想都来自于学生老家,一个人的出生地文化决定了我们的性格特征、行事风格和思维方式,我选择联系学生的母亲,利用长辈和亲情的力量去感召学生。
现有的字体风格迁移方法难以处理复杂的字体结构,例如带有特殊符号或复杂曲线的字体。这是因为传统的方法主要基于对图像的像素级别处理,难以准确捕捉字体的结构和形状。
1.3 本文主要研究内容
本文采用条件生成对抗网络的方式训练端到端的字体风格迁移网络,通过知识蒸馏技术[9]将经过预训练的目标风格字体图像重建网络的特征信息引入字体风格迁移网络,使网络更好地学习目标字体的特征解码方式。同时结合边缘平滑损失和感知损失[10]使生成的目标字体更加真实。
2 基于知识蒸馏的字体风格迁移算法
本文提出的字体风格迁移网络结构如图1。字体风格迁移网络使用与Zi2Zi相同的结构,通过条件生成对抗网络的方式训练生成器作为字体风格迁移网络。为了能够更好地将编码器提取的特征解码为目标风格字体,本文引入一个经过预训练的目标风格字体图像重建模型作为教师网络,以知识蒸馏中的特征蒸馏[11]方式使作为学生网络的字体风格迁移网络能够更好地将特征解码为目标风格字体。同时为了使生成的目标字体边缘更加平滑,本文使用边缘平滑损失使网络更加关注梯度变化较大位置的生成,并且引入了感知损失使生成的目标风格字体图像更加真实。
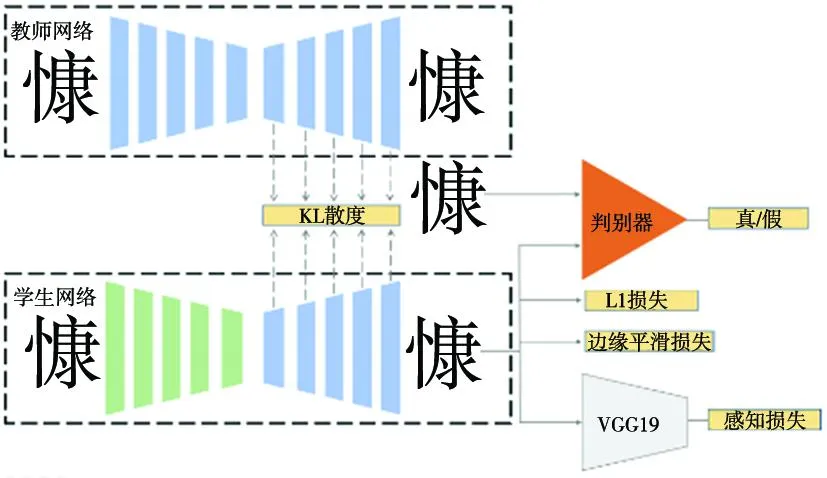
图1 基于知识蒸馏的字体风格迁移网络结构
2.1 生成对抗网络结构
本文的生成对抗网络结构属于条件生成对抗网络[12],以源风格字体图像作为生成器的输入来生成目标风格字体,使用PatchGAN结构[6]的判别器判断生成质量。
生成器的结构如图2。是一个编码器-解码器结构的U-Net[13]网络,网络的输入为单通道源字体图像,编码器将输入图像下采样到较低的特征空间,解码器再将其上采样回原始图像大小并输出为目标风格字体图像。具体来说,生成器的网络结构由8组跳跃连接模块组成,每组跳跃连接模块包括一个下采样卷积层、一个上采样卷积层以及相应的批归一化层。其中,下采样卷积层使用 LeakyReLU 作为激活函数,以2为步幅降低图像尺寸;上采样卷积层使用 ReLU 作为激活函数,以2为步幅还原图像尺寸。批归一化层的作用是在训练过程中加速收敛,并且有效避免过拟合等问题的发生。此外,编码器每一层都有一个跳跃连接,将编码器中同一层级的特征与解码器中对应位置的特征相连,这种跳跃连接能够帮助网络保留较低层的细节信息。

图2 生成器网络结构
本文的判别器如图3。它采用的PatchGAN结构是一种基于区域的判别器结构,它将输入的生成目标风格字体图像或者真实的目标风格字体图像分成N×N个区域,并对每个区域进行二分类真假判别。具体来说判别器的结构是一个全卷积网络,由卷积层、LeakyReLU 激活函数以及批归一化层堆叠而成,最后一个卷积层的输出通道数为 1,其中的值对应每个区域的真假判断。通过这种结构设计,PatchGAN结构的判别器可以为图片不同尺度的局部信息判断真假,具有更强的判别能力。

图3 PatchGAN判别器网络结构
2.2 知识蒸馏教师网络模块
教师网络采用与字体风格迁移网络中的生成器结构相同的U-Net结构,输入目标风格字体图像并通过均方误差损失约束使其能够重建为输入图像,在这个过程中模型能够很好地学习到将目标风格字体进行特征编码并解码为目标风格字体的能力。而字体风格迁移网络中的编码器学习如何将源字体编码为特征图,解码器学习如何将特征图解码为目标风格字体,其中解码器部分可以通过特征蒸馏的方式学习教师网络的解码器的特征解码方式,获得更好的目标风格字体生成能力。
2.3 损失函数设计
本文使用的损失函数主要包括GAN损失函数、L1损失函数、特征蒸馏损失函数以及感知损失函数。
其中GAN损失函数与条件生成对抗网络的损失函数相同,通过判别器将生成器生成的目标风格字体图像与真实的目标风格字体图像进行对比,以此来鼓励生成器生成逼真的目标风格字体图像,这一损失函数的公式如下:
LcGAN(G,D)=Ex,y[logD(x,y)+Ex,z[log(1-D(x,G(x,z)))]。
(1)
式中,x表示输入的源风格字体图像,y表示目标风格字体图像。生成器的目标是生成判别器认为真实的目标图像,判别器的目标则是准确判断输入的图像是真实的目标风格字体图像还是生成的目标风格字体图像。
然而生成器的目标不仅成功欺骗判别器,还需要使生成图像接近目标图像,因此同样需要加入其他的图像相似性损失函数,相对于L2损失,L1损失能够鼓励网络减少图像中的模糊区域,因此本文选择使用L1损失函数约束生成图像与目标图像的相似性,L1损失函数的公式如下:
(2)
GAN损失函数和L1损失函数的优化目标都是使最终的输出结果,特征蒸馏损失可以直接约束网络中间的特征层,使网络能够更加直接地学习教师网络的特征处理能力,能够更高效地训练网络,本文使用的特征蒸馏损失函数如下所示:
(3)
其中p和q分别表示教师和学生的特征图分布,本文选择的是对8层解码器上采用网络的特征进行约束。
现有的字体风格迁移方法如Zi2Zi的生成结果边缘处存在不平滑的情况,为了使生成的字体边缘更加真实,本文引入边缘平滑损失,通过对生成图像与真实目标图像的梯度进行加权,使网络对于高梯度处也就是边缘位置的生成更加谨慎,减少生成带来的噪声,使生成更加真实,边缘平滑损失的计算方式如下所示:
(4)
为了使图像生成得更加真实,本文还使用了基于VGG19[14]的感知损失,感知损失通过预训练的VGG19模型提取图像的高维特征表示,高维特征包含了丰富的图像结构与内容信息,可以很好地约束生成的目标风格字体图像与真实的目标风格字体图像之间的一致性。本文使用的VGG19感知损失函数如下所示:
(5)
式中:φ表示本文使用VGG19网络结构;表示网络的层数;φi(I)表示第i层网络输出的特征;λi表示对应的权重。
本文字体风格迁移网络的损失函数如下所示:
LT=α1LcGAN+α2LL1+α3Lf+α4Ls+α5Lp。
(6)
其中α1为15,α2为100,α3为100,α4为100,α5为1。
2.4 评价指标
为了更客观地评估本文方法的性能,除了将生成结果可视化的定性实验,本文还通过均方根误差(RMSE)和像素误差率(PDR)两个指标作为评估标准进行定量实验对本文方法进行实验评估。
3 实验与结果分析
为了评估本文方法的性能,本文构建了具有多种风格字体的数据集,其中包括印刷体如宋体、黑体以及手写体如楷体等,通过对生成结果进行可视化以及使用均方根误差和像素误差率两个定量指标对生成结果进行客观评价。
3.1 实验数据集与实验环境
使用宋体作为源风格字体,目标风格字体选择了黑体用以测试对印刷体的生成能力以及楷体测试针对手写体生成能力,随机选择了3 000个汉字生成了三种字体的相对应图像进行训练和测试,其中用于训练和测试的数据比例为9:1,汉字图像均为单通道的二值图。
本文使用Pytorch框架搭建字体风格迁移网络,选择Adam优化器对模型进行训练,初始学习率设置为0.001,每20轮训练衰减为原来的一半,共进行100轮训练,批大小设置为32。本次实验的运行环境为Ubuntu 16.04系统,Intel(R) Xeon(R) E5-2673 CPU,英伟达GeForce GTX 1080 Ti GPU。
3.2 实验结果与分析
对于源字体为宋体,目标字体分别为黑体和楷体的风格迁移实验结果分别如图4~5。可以看到Zi2Zi的生成结果在字体的边缘以及结构复杂、笔画紧凑的汉字(如“嬷”)位置处理地不够好,而本文的方法能够更好地生成边缘平滑、结构清晰且更加真实的目标风格字体。

图4 宋体转换成黑体的生成结果

图5 宋体转换成楷体的生成结果
根据主观判断,本文的字体风格迁移结果相比于Zi2Zi在细节处更加真实且文字的边缘更加清晰。
除了主观评价,本文还采用均方根误差(RMSE)和像素误差率(PDR)两个客观指标评估生成结果。RMSE通过生成图像的整体观感进行评价,PDR通过汉字图像的像素点位置的误差率评估生成效果,RMSE和PDR的计算方式如下所示:
(7)
(8)
式中:f和r分别表示生成图像(fake)和真实图像(real)的2维向量;两幅图像中对应位置的像素值分别用fi,j和ri,j表示;M和N代表图像在两个维度上的像素点总数。I{·}在fi,j=ri,j时值为1,否则为0。RMSE、PDR值越小说明模型的生成结果越接近真实图像。
本文方法和Zi2Zi的对比结果见表1。在两种类型的字体的风格迁移任务上都体现出了本文方法的有效性。
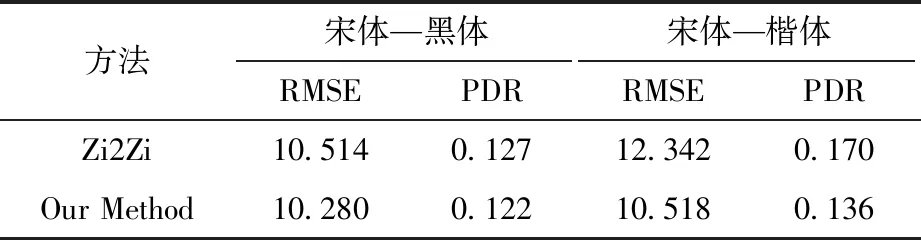
表1 定量分析
4 结 语
基于改进生成对抗网络的字体风格迁移的研究,通过对目标风格字体进行图像重建任务学习目标风格字体的解码过程,结合特征蒸馏技术提升了风格迁移网络中针对目标风格字体的解码能力,并通过引入边缘平滑损失和感知损失提高了字体风格迁移任务中目标风格字体的生成质量。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
数学小灵通·3-4年级(2021年5期)2021-07-16
娃娃乐园·综合智能(2020年2期)2020-03-12
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
今日农业(2019年15期)2019-01-03
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
小雪花·成长指南(2014年10期)2014-10-31
