
一种改进聚类算法的时间序列异常检测方法
2024-03-27 16:21蔡文铤
现代计算机 2024年1期
钱 宇,蔡文铤
(中国民用航空飞行学院飞行技术学院,广汉 618307)
0 引言
伴随着大数据时代的到来,航空领域产生了大量具有明显时间顺序性的数据。尤其是传感器的普及和生产的信息化,使越来越多的数据被记录下来形成时间序列数据,例如飞机、无人机飞行数据等。在时间序列数据中,异常数据往往携带着大量有用信息,比如通过检测飞机快速存取记录器收集的数据可以有效识别飞机飞行过程中的异常行为、设备故障以及其他潜在风险。
国内外学者在时间序列异常检测方面进行了大量研究,文献[1]提出了一种使用卷积半分自编码器来提取多参数数据特征的方法,并结合长短期记忆神经网络对这些学习到的特征进行异常点预测,通过这种方法能够识别出在数据中具有异常行为的点。文献[2]采用神经网络来辨别参数之间的隐藏状态,并通过交互学习捕捉时间序列数据之间的依赖关系。基于计算得出的异常分数,能够对时间序列的变化趋势进行预测,并根据异常情况做出判断。文献[3]针对飞行过程中不同飞行阶段和机动动作将其截取成多个数据向量,并利用高斯混合模型对样本数据进行聚类以找出可能存在异常情况的飞行阶段。文献[4]使用局部离群概率算法分析航空公司航班的历史飞行数据,成功地检测到以往未被识别的飞机运行异常现象。还可以训练时间序列预测模型,根据模型的预测值与真实值的残差进行异常判定,文献[5-8]利用神经网络建立时间序列预测模型;文献[9]使用改进的ARIMA 模型预测时间序列值;文献[10]使用GAN 模型拟合多元时序数据分布并重构时序误差,相比于使用样本数据训练模型半监督学习方法可以更好地利用无标签数据;文献[11]使用平均距离改进局部离群因子算法,实现电力市场的异常行为检测;文献[12]在VAE 编码器和解码器中引入LSTM 网络学习时间序列的时空关系。多元时间序列间通常存在着时空关系,因此也可以根据多变量间的时空关系判断序列异常。文献[13]利用图神经网络进行多变量时间序列异常检测。文献[14]利用图遍历和马尔可夫链进行相似矩阵转换来检测多元时序数据的异常,但因其需要异常状态的先验知识及各种状态变化概率,长期预测涉及对更远未来进行推断和估计。文献[15]采用自编码器进行对抗训练来放大异常的重建误差。
聚类算法作为机器学习算法的一个重要分支,不需要给数据打标签,不需要标记实例,成为最适合处理时间序列数据的方法之一,针对时间序列异常检测领域,研究人员广泛探索和应用各种算法。文献[16]提出的方法中,采用了分段线性表示来对电力时间序列数据进行降维处理。该方法首先根据预定规则将原始数据进行分段,并利用线性模型对每个子段进行表示。通过这种方式,可以显著减少数据的维度。文献[17]将QAR 数据转化为高维向量,使用DBSCAN 聚类算法将高密度区域划分为簇,不属于簇的点判定为异常航班。在相关文献中,有几项研究采用了不同的聚类算法和特征提取技术,以分析和检测异常情况。首先,文献[18]运用聚类算法来选择与飞行风险高度密切相关的参数。使用聚类方法对数据进行处理,从中筛选出与飞行安全性最相关的参数。其次,在文献[19]中,作者针对排队检测数据进行了特征提取,并使用K-shape 聚类方法对提取后的数据进行聚类分析。通过这种方式,得到了时间序列集合的平均特征序列作为异常序列判断依据。此外,文献[20]利用历史数据来预测当前时刻的区域用电量。
现有的聚类算法中通常采用欧氏距离对时间序列数据进行划分,缺少时间序列对齐的灵活性,无法对时间序列数据很好地聚类。基于以上问题,研究将QAR 数据和参数监控标准数据匹配,得到异常标签;使用时间动态规整距离度量方法替换聚类算法的欧氏距离度量方法,对QAR 参数航段数据进行聚类得到聚类结果,最后分析改进聚类算法异常检测的性能。
1 QAR数据与飞行品质监控
快速存取记录器(quick access recorder,QAR),指在日常运行过程中用于监控、采集与飞行相关的参数以及数据的机载飞行数据存储记录设备。QAR 记录了航空器的运行数据,用于监控航空器的一系列参数,其中包含航空器的姿态、高度、速度以及航空器驾驶员的操作动作等。
飞行品质监控(flight operations quality assurance,FOQA)是国际上公认的保证飞行安全的重要手段之一,已得到世界民航业的普遍认可。目前,飞行品质监控主要是利用快速存储记录器采集的数据进行安全监控[21]。
由于传感器记录过程中可能存在飞机飞行环境变化、引入噪声等因素导致数据存在异常[22-23],给后续的数据挖掘、模型训练和分析带来很大的困扰。通过分析QAR 数据可以对飞机的飞行安全进行监控,及时发现和解决潜在的故障和问题,提前采取维修措施,确保飞机的安全性和可靠性。因此,对QAR 数据进行异常检测以及深入挖掘异常数据背后所隐藏的信息是非常重要的,这是实现飞机飞行品质监控和保证飞行安全的重要手段。
2 时间序列异常检测方法及实现
2.1 K-Medoids聚类算法
K-Medoids 聚类算法是一种用于将数据集分成k个簇的算法,它能够通过迭代簇中心点来优化聚类效果,每个簇包含一个代表点和一组与该代表点最相似的数据点。在K-Medoids 算法中,通过使用欧几里得距离作为聚类准则函数来衡量聚类结果的质量,使用式(1)进行计算:
其中,p表示样本集中的样本点,oi代表簇Ci的中心点,E表示聚类准则函数值。
K-Medoids算法基本步骤如下:
(1)初始化:从样本集中随机选择k个数据对象作为初始聚类中心。
(2)计算距离:对于每个数据对象,计算它与所选聚类中心之间的距离。常用的距离度量方法包括欧氏距离、曼哈顿距离等。
(3)对于每个聚类簇计算其所有数据点到其他点的距离之和,选择其中距离之和最小的点作为新的聚类中心。
(4)重复执行步骤(2)、(3)的过程,直到聚类中心不再发生改变或达到设定的最大迭代次数为止。
2.2 动态时间规整算法
动态时间规整算法(dynamic time warping,DTW)是一种用于测量两个时间序列之间相似度的算法,该算法通过对时间轴进行弯曲、拉伸或收缩来计算两个时间序列间相似性[24]。动态时间规整算法创建一个二维矩阵来存储两个时间序列之间每个数据点之间的局部距离值,并根据一定规则进行累积距离计算。然后,根据累积距离矩阵找到最优路径,该路径代表了将一个时间序列映射到另一个时间序列的最佳匹配方式。在路径查找过程中,可以使用不同的约束条件来控制时间轴弯曲、拉伸或压缩的程度,从而灵活地调整对齐结果。最后,通过计算最优路径上各个点之间的累积距离值,得到两个时间序列之间的DTW 距离。DTW 算法是一种强大的工具,在比较和分析时间序列数据时发挥着重要作用。它能够克服长度不等以及形态变化等问题,并提供更准确的相似性度量结果[25]。DTW距离的对齐方式相比于欧氏距离,可以更加准确地匹配时间序列,更能体现时间序列对应特征点间的关系以及序列间的相似性。
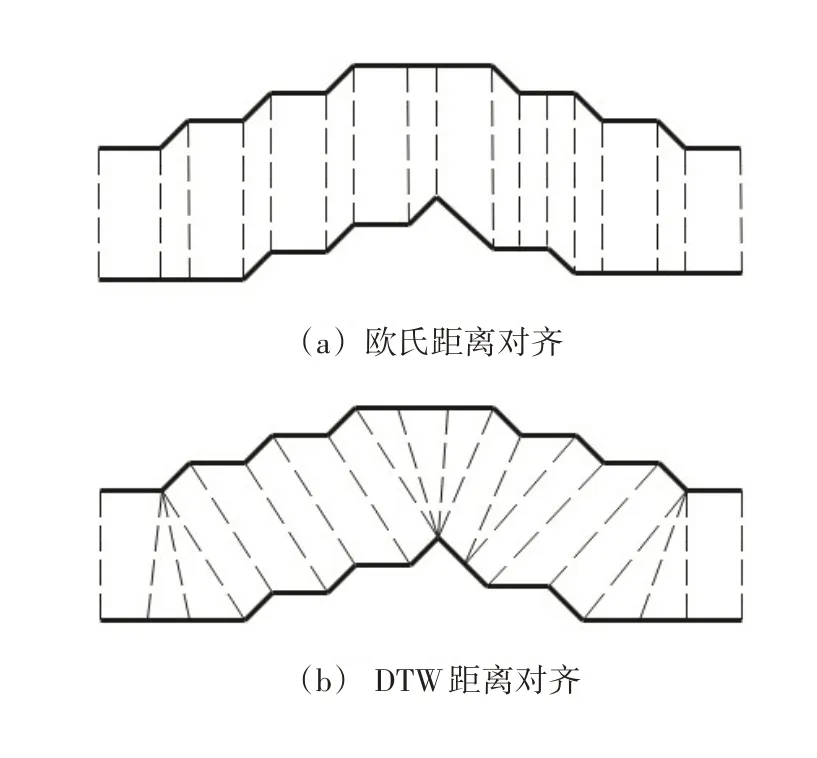
图1 欧氏距离和DTW距离的对齐模式
动态时间规整算法步骤如下:对于两个长度为m和n的时间序列。首先定义一个m×n的矩阵D,用于存储DTW 距离的计算结果;在计算DTW 距离时,首先需要初始化矩阵D,其中D[0][0]为0,D[i][0]和D[0][j]均设为正无穷大。这里的i取值范围是从1到m,而j取值范围是从1 到n。接下来使用动态规划的方法,逐个计算矩阵中的元素D[i][j]。具体计算方式如下:对于每个位置(i,j),将其定义为时间序列X中第i个元素与时间序列Y中第j个元素之间的距离,加上其左边、上边和左上方三个元素中的最小值。可以表示为式(2):
其中,d(X[i],Y[j] )表示X中第i个元素和Y中第j个元素的距离。
2.3 改进聚类算法
本研究根据实际时间序列数据异常检测情况将K-Medoids 算法进行了改进,由于异常数据在数据集里占比很小且数据集中只有正常与异常两种时间序列类别,因此在算法中只存在一个聚类簇。在时间序列距离度量方面,如图2所示,将欧氏距离度量方法替换为DTW 距离度量方法。航班在实际运行中相同飞行阶段飞机飞行状态变化趋势相似,对时间序列形态的相似性判断非常重要。DTW 算法为聚类簇划分提供样本序列,与聚类簇的相似性更加贴合聚类中心[26],因此在分析时间序列样本差异度时采用DTW算法进行计算。

图2 改进聚类算法流程
2.4 异常检测方法
基于改进聚类算法,构建对QAR 参数数据的异常检测方法,方法流程如图3所示。首先对数据进行预处理,将QAR 数据和参数监控标准数据匹配,得到异常标签;利用改进聚类算法对时间序列数据进行聚类得到聚类结果,在进行时间序列异常检测时采用1%的异常检出率,即算法输出距离样本集中心序列最远的百分之一的序列;最后结合算法输出序列与序列异常标签分析改进聚类算法异常检测的性能。
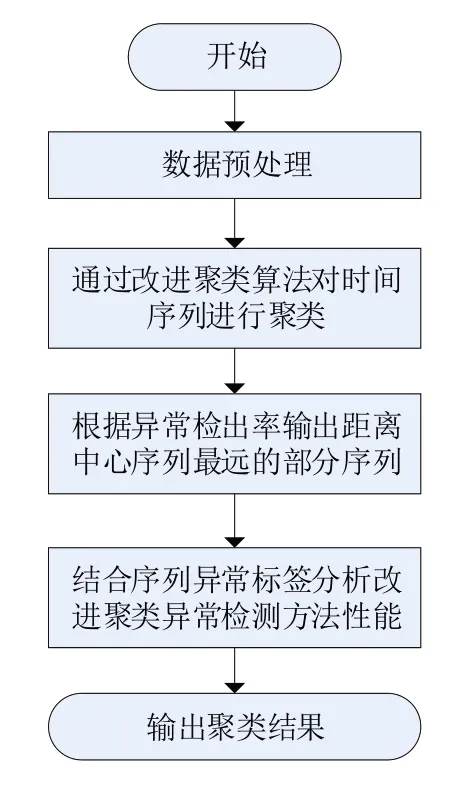
图3 时间序列异常检测方法流程
3 实验过程与结果分析
3.1 实验过程
3.1.1 异常数据筛选
本研究选用无极端天气状况下在成都双流机场降落的A320 机型QAR 数据作为实验数据,总共500 个航班。根据QAR 数据和超限事件参数标准判断QAR 参数数据是否为异常数据并得到异常标签,超限事件参数标准是根据民航法规设定的参数阈值得到的航班超限异常,部分超限参数阈值见表1。

表1 部分参数阈值及触发条件
3.1.2 航段选取
为了选取不同航班处于同一飞行阶段的时间序列数据,对每个航班的数据样本进行重抽样。对于每个航班f来说,样本数据可以表示为式(3):
对每个航班按相同的规则进行航段选取,飞机在主轮着地时飞机的空地开关会由AIR 转化为GROUND,将飞机空地开关转换的点设为着陆点,每个航班取着陆点前34 点,着陆后取5 点。每个航班总计40 个时间戳,取值的范围涵盖了飞机在500英尺至滑行跑道上的高度。
3.1.3 评估指标
为了验证时间序列异常检测方法的性能,研究采用准确率(Accuracy,Acc)和F1分数来评估模型的性能。
其中,TP表示真正例数,FP表示假正例数,TN表示真反例数,FN表示假反例数。
3.2 结果分析
为了评估改进聚类算法异常检测的性能,在选定实验数据集上,通过对飞行数据进行异常检测评估各聚类算法性能。
分别采用K-Means、K-Medoids 和改进聚类异常检测算法识别在落地前34 s 至落地后5 s 这一时间段内各QAR参数中带有异常标签的时间序列,各种算法的异常检测性能指标如图4、图5所示。
从准确率指标来看,改进K-Medoids 的平均准确率最高,约为99.86%,比K-Medoids 约高0.4%,比K-Means 约高0.67%。三种算法中改进K-Medoids 的F1 分数最高,比K-Medoids 约高0.21%,比K-Means约高0.74%。
三种算法在垂直载荷(VRTG)和俯仰角(PITCH)数据集上的异常检测准确率较高,在航向道偏差(GLIDE_DEVC)数据集上准确率有所下降,其中K-Means 下降最多约为0.4%,改进K-Medoids 下降最少约为0.14%。这是由于航向道数据集中的序列数据以0为基准上下波动且波动较多,改进K-Medoids 算法在计算序列数据差异时会匹配“波峰”“波谷”,实现“一对多”的数据对应,而使用欧氏距离计算序列差异的K-Means 和K-Medoids 算法在数据匹配时为“一对一”匹配,因此使用欧氏距离计算的聚类算法在序列数据有较多波动的数据集中表现较差。

图4 准确率对比图
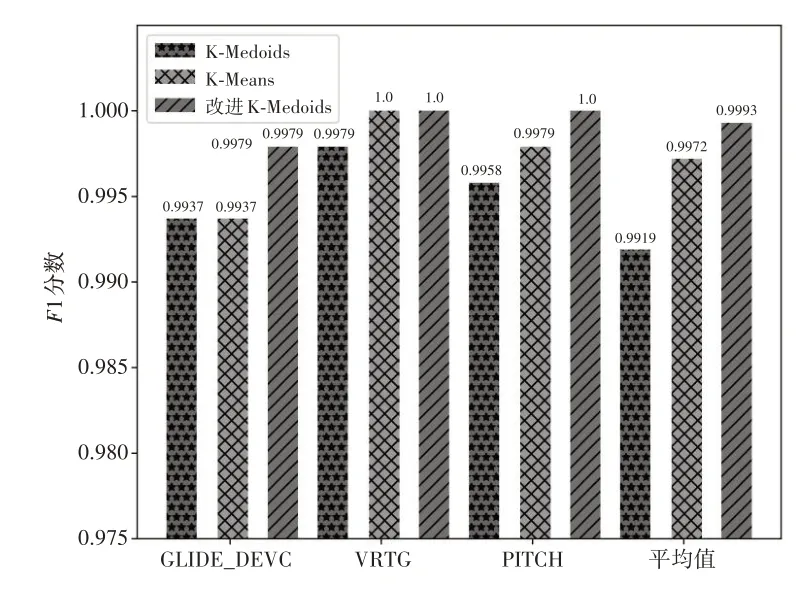
图5 F1分数对比图
4 结语
通过对现有时序数据异常检测方法的分析和研究,提出了一种改进的聚类算法,为时间序列数据异常检测提供了一种有效且可行的解决方法。以具有时间序列特性的飞机QAR 参数数据作为实验对象,通过对时间序列数据进行异常检测,体现改进聚类算法异常检测的性能,并将K-Means 算法、传统K-Medoids 算法作为参照进行实验对比,得出以下结论:
(1)动态时间规整度量时间序列间的距离相较于欧氏距离缩小了形状相似的序列数据间的距离,聚类算法结合动态时间规整可以对形态特点相似的时间序列更好地聚类。
(2)研究提出的改进K-Medoids 聚类算法在时间序列异常检测方面尤其是在处理具有相似形态特点的时间序列数据时更具优势,该算法可以有效识别存在异常波动和异常值的时间序列。
(3)后续研究可将该方法应用于飞机运行的其他阶段及参数,检测与分析其中所包含的潜在异常。
猜你喜欢
速读·下旬(2021年11期)2021-10-12
大东方(2019年12期)2019-10-20
小学生导刊(2018年34期)2018-12-18
电子测试(2017年15期)2017-12-18
科学与财富(2017年22期)2017-09-10
雷达学报(2017年6期)2017-03-26
商情(2017年1期)2017-03-22
山东青年(2016年3期)2016-02-28
母子健康(2015年1期)2015-02-28
电子设计工程(2015年6期)2015-02-27
