
改进的目标检测算法在司机室场景的应用
2024-04-01 06:41屈波
电视技术 2024年1期
屈 波
(国能包神铁路集团信息技术服务分公司,内蒙古 鄂尔多斯 017000)
0 引言
现有轨道交通综合分析室中,大部分还是依靠人工分析司机室的视频,判断司机是否有无违规行为。机车运行中常发生的违规项行为有离开座椅、打盹、玩手机等,会对行车安全产生巨大隐患。本文针对司机室智能分析系统中的智能检测模块进行优化改进,提升检测算法在复杂的场景下的准确率,提出了一种YOLOv8-DR(YOLOv8-Driver)方法。该方法在原有的YOLOv8 基础上引入了坐标注意力机制(Coordinate Attention,CA)[1],抑制无关特征干扰,增强高关联区信息特征提取能力,增加了一个大尺度检测头分支,更好地捕捉玩手机等小目标的细节信息,减少检测模型在分析模糊和遮挡图像时的误判,以期为机车司机室场景的检测提供有效解决方案。
1 司机室智能分析系统
人工分析视频速度慢,每日无法完成约两千个小时的视频文件分析。司机室智能分析系统由计算机分析视频,可大大提升分析效率,减少人力资源消耗,节约成本,可实现当天视频文件全覆盖分析。该系统部署于多显卡服务器上,24 h 不间断全自动分析,输出异常或违章行为,最终由相关工作人员核查司机行车过程中否有违规[2]。如图1 所示,司机室智能分析系统使用服务器和客户端模式的整体架构。其中,服务器上的智能检测模块是整个分析系统的核心部分,检测算法的准确率是整个系统准确性的关键因素之一。通过不断优化和改进模型,可以提高模型的准确性和可靠性,从而提升整个系统的性能。
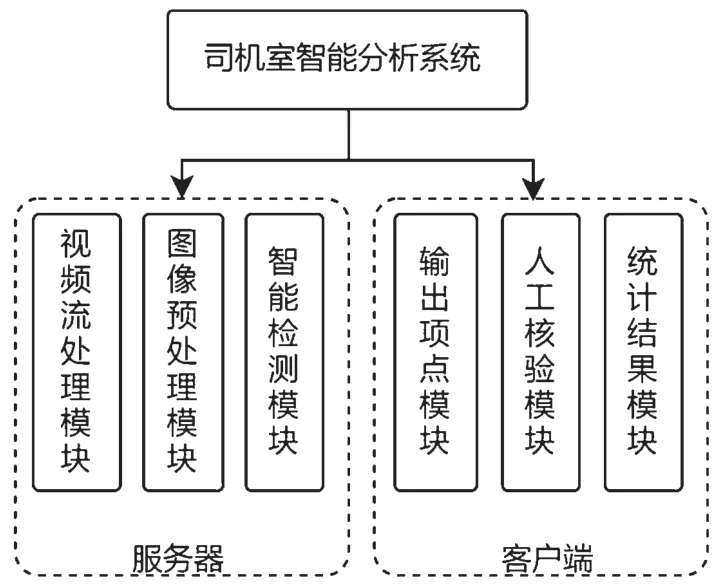
图1 司机室智能分析系统框架图
2 目标检测算法的改进
原有的智能检测模块采用YOLOv8 网络检测目标。虽然该网络检测效果好,但在司机室复杂场景下表现不佳,特别是对小目标的检测准确率低。本文提出的方法如图2 所示。

图2 YOLOv8-DR 网络结构
2.1 小目标检测头的增加
YOLOv8 的骨干(backbone)网络主要用于提取图像特征,通过C2f 获取图像汇总的信息特征;头部网络一般由颈部和检测头组成,用于特征融合和目标推理预测。本文在头部网络中增加了小目标检测分支[3](图2 中虚线部分),增加的特征图大小为160×160,用来解决模型对小目标检测准确率不佳的问题[4]。小目标检测头结构增加了CA 模块,C2f模块可以使得梯度流信息更加丰富,在其后面接一个CA 模块,更有助于特征信息定位[5]。
2.2 CA 注意力机制模块
机车司机室的环境复杂多变,为了提高模型对目标的有效检出能力,本文在YOLOv8 的颈部网络中增加了注意力机制,目的是增强目标的特征表达。注意力机制从大量数据信息中挑选出一少部分特征信息,过滤不重要的信息,关注提取的部分信息。注意力机制有空间注意力机制,有通道注意力机制,也有两者结合的。传统的注意力机制如SE 的缺点是不能提取特征图上位置信息。另一种注意力机制CBAM,通过在通道上进行全局池化来引入位置信息,但这种方式只能捕获局部的信息,对长范围依赖的特征获取显得力不从心[6]。CA 模块是一种新颖、高效的注意力机制,通过在通道注意力中嵌入位置信息,使网络获得更有效的信息,避免更多计算开销的增加。CA 模块使用起来非常方便灵活,可以插入网络的多个位置,且不会造成过多的参数量和计算量。其结构如图3 所示,通过平均池化,再对空间信息变换进行编码,最后在通道上以加权的方式将空间信息进行整合。

图3 CA 注意力机制模块
对于给定的输出数据x,经过残差模块之后,先使用(H,1)和(1,W)的池化核,分别在X方向和Y方向对通道进行池化计算,计算公式为
式中:h表示为高度,c表示特征通道数。另一个方向可表示为
式中:w表示为宽度。式(1)和式(2)是相互垂直的两个空间方向汇聚特征信息,最终得到的是一对方向感知的特征图。两个公式合起来的编码公式为
式(3)中的zc不仅将目标全局空间信息压缩到通道描述符中,而且保存了目标特征的位置信息。
获得全局感受野并编码精确的位置信息后,需要充分利用上述信息,将两个方向的权重gh和gw合并成权重矩阵,CA 模块的最终输出y可以表示为
CA 模块的每个权重都包含了通道间信息、横向空间信息和纵向空间信息,能够帮助网络更准确地定位目标信息,增强识别能力。
2.3 YOLOv8-DR 部署应用
改进后的检测算法重新进行训练,训练后进行模型转换部署,最后进行模型推理。如图4 所示,智能检测模块主要包括训练、部署及推理3 个子模块。训练子模块根据系统提供的数据集对网络参数学习更新;部署子模块可以在保证准确率不降低的前提下提升模型的推理速度;推理子模块是对图像数据提取特征,并预测分类和坐标位置。检测项点的结果会上传至客户端输出项点模块,经过人工的核验,最终统计成为报表形式呈现于客户端上。

图4 智能检测模块流程
3 实验设计与分析
3.1 环境与评价指标
本文使用的数据集为司机室场景数据集,数据集的划分按照7 ∶2 ∶1 的比例,其中训练集大约6 万张。试验所用的系统为Windows10,中央处理器(Central Processing Unit,CPU)型号为Intel i5-8500 CPU @ 3.00 GHz,图形处理器(Graphics Processing Unit,GPU)型号为RTX3060,显存12 GB,使用PyTorch 版的深度学习框架,GPU 加速框架库为TensorRT。
评价指标主要包括:精确度(Precision)用P表示,召回率(Recall)用R表示,平均精度均值用mAP50,计算公式分别为
式中:NTP表示模型预测为正样本且实际是正样本的检测框数量,NFP表示模型预测为正样本但实际是负样本的检测框数量,NFN表示模型未能检测到的实际样本数量,N是样本类别总数,mAP50表示交并比(Intersection over Union,IoU)阈值设置成0.5的平均精度均值。
3.2 消融实验
本文设计了消融实验,用来验证网络改进的可行性和有效性。试验方案是将未进行任何改动的YOLOv8 网络作为基准,将小目标检测头分支添加到网络中,命名为YOLOv8-MinHead,将CA 模块加入到网络模型中,命名为YOLOv8-CA,与同时增加两个模块的YOLOv8-DR 网络模型进行比较分析。对比结果如表1 所示。由于向网络模型中新增加了模块层,这会导致整个模型的参数量增大,从而影响模型的检测速度,YOLOv8-MinHead 和YOLOv8-CA 的检测速度都比YOLOv8-DR 的速度快。YOLOv8-DR 虽然增加了计算量,但提高了目标检测的准确性,相比YOLOv8 模型,准确率、召回率和平均精度均值分别提升了4.6%、3.8%、3.4%。

表1 增加小目标检测头与CA 模块对模型性能的影响
3.3 对比实验
为验证YOLOv8-DR 模型对司机室场景的检测效果,选择目前检测准确率较高的YOLO 系列模型进行改进对比试验,比对模型有YOLOv5-DR(YOLOv5 中同时增加检测头和CA 模块)、YOLOv7-DR(YOLOv7 中同时增加检测头和CA 模块)两个检测模型。试验结果如表2 所示,YOLOv8-DR 虽然推理速度最慢,但效果是最好的。在速度满足实时性要求的情况下,YOLOv8-DR 提升了模型对目标空间位置信息的感知能力,提高了检测的准确性。

表2 不同模型在测试集上的性能对比
3.4 实际应用分析
在实际现场用YOLOv8-DR方法进行部署测试。使用相同的司机室视频数据,采用不同的智能检测模块(模型不同),进行智能分析系统对视频的分析。图5 所示为司机室智能分析系统运行界面,对视频数据进行实时监测和分析。通过对视频数据的分析,系统可以对司机人员的行为进行智能识别和分类,如玩手机、待机打盹、姿态不端等不规范行为。

图5 司机室智能分析系统运行界面
统计一周的结果显示。以前旧模型的项点准确率为62.7%,YOLOv8-DR 模型的项点准确率为76.2%。
图6 是客户端显示的一周项点平均准确率统计结果。根据统计数据分析,YOLOv8-DR 模型相比旧模型在项点平均准确率上提高了13.5%,表明YOLOv8-DR模型在实际应用中具有更高的准确性。准确率的提高表明该方法在处理复杂场景和不同类型的数据时更加可靠准确,为进一步应用推广提供了有力的依据。

图6 统计准确率
4 结语
本文提出的改进目标检测算法检测精度高,满足实时性要求,对图像检测中目标的相互遮挡、特征点少等问题有所改善,是提高司机室场景中项点准确率的一个积极进展,不仅有助于提高驾驶操作的安全性,还能规范驾驶操作人员的习惯,对机车安全运行具有重大的意义。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
文萃报·周二版(2021年51期)2021-01-02
杂文月刊(2019年19期)2019-12-04
小天使·一年级语数英综合(2019年11期)2019-01-13
文苑(2018年23期)2018-12-14
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
