
基于要素关联图的汉越跨语言事件检索方法
2024-04-02 03:42赵周颖余正涛黄于欣陈瑞清朱恩昌
现代电子技术 2024年7期
赵周颖,余正涛,黄于欣,陈瑞清,朱恩昌
(1.昆明理工大学信息工程与自动化学院,云南昆明 650500;2.昆明理工大学云南省人工智能重点实验室,云南昆明 650500)
0 引 言
汉越跨语言事件检索旨在根据输入的中文事件查询短语,检索出相关的越南语新闻事件文档[1]是跨语言舆情事件检测、跨语言新闻推荐以及跨语言事件追踪等后续任务的基础。
跨语言事件检索是一种特殊的跨语言信息检索任务。近年来,在传统的跨语言信息检索方面已经取得了较好的进展,主流方法包括以下三种:基于机器翻译的方法、基于跨语言/多语言词嵌入的方法以及基于多语言预训练语言模型(诸如mBERT[2]、XML-R[3]等)的方法。其中,基于机器翻译的方法利用神经机器翻译将查询和文档映射到同一语义空间,然后进行单语检索。基于机器翻译的方法在一定程度上解决了不同语言的语义鸿沟问题,但是基于机器翻译的方法严重依赖于神经机器翻译的准确性,容易引起词不匹配和翻译歧义问题,特别是对于差异较大的低资源语言(如中文和越南语),机器翻译误差直接影响检索结果。为了解决这些问题,研究者提出了基于预训练跨语言词向量的跨语言信息检索方法[4],其核心思想是利用跨语言词向量将不同语言的语义映射到同一语义空间中,从而解决跨语言检索问题。然而,基于跨语言词向量的方法由于忽略了词序和上下文信息,导致查询或待检索文本的语义表示不准确,并且在不同语种间的语义表示空间映射过程中容易引起误差传播,从而影响检索模型的性能。随着多语言预训练语言模型如mBERT[2]和XML-R[3]的出现,基于多语言预训练语言模型的方法[5-6]成为了目前跨语言信息检索的主要方式。
现阶段,在跨语言事件检索方面的相关研究还较少。文献[7]提出了一种基于词向量的越汉跨语言事件检索方法,该方法首先利用词向量构建事件关键词的汉语语义特征向量,然后计算越语的事件关键词的特征翻译向量,最后通过计算语义特征向量之间的相似度完成跨语言关键词对齐,从而实现查询关键词的自动翻译,实现跨语言事件检索。文献[1]提出一种融入事件实体知识的汉越跨语言新闻事件检索模型。综上所述,目前跨语言事件检索仍然面临着以下两个方面的挑战:
1)跨语言事件检索的核心是计算事件查询短语与查询文档中描述的核心事件之间的匹配度。然而事件短语和查询文档中往往包含大量的实体,目前汉越实体翻译效果还不理想,基于翻译的跨语言事件检索会带来较大的误差级联。
2)目标语言(越南语)的新闻文本较长,中文事件查询短语与越南语的查询文档长度不一,表达差异较大,且查询文档中往往会包含大量与其描述的核心事件无关的噪声文本,现有的模型不能很好地捕捉事件匹配特征,难以对其进行准确匹配。
为了解决上述两个问题,本文提出了基于要素关联图的汉越跨语言事件检索方法。该方法首先预训练一个汉越双语词嵌入来解决跨语言语义鸿沟问题;然后,抽取查询文档中的关键信息(关键词和实体)并构建文档要素关联图;最后,通过引入一个图编码器对构建的要素图进行编码,生成结构化的事件信息来增强传统的事件检索模型。在自建数据集上的实验证明,本文提出的方法优于传统的基线方法,有效验证了本文所提方法的有效性。
1 汉越双语词嵌入预训练
本节主要介绍汉越双语词嵌入的预训练方法。汉越跨语言词向量预训练的目标是学习汉语词嵌入矩阵X和越南语词嵌入矩阵Y之间的映射,首先在汉语和越南语语料中训练词嵌入矩阵X和Y,将种子词典表示为二进制矩阵D;接下来找到最优双语映射矩阵W*,使映射的汉语词嵌入矩阵Xi*W和越南语词嵌入矩阵Yj*之间的欧氏距离平方和最小化。
式中:Xi*表示第i个汉语词嵌入;Yj*表示第j个越南语词嵌入。如果第i个汉语词与第j个越南语词对齐,则Dij= 1。
接下来对词嵌入矩阵X和Y进行归一化和中心化预处理操作,将W构建为正交矩阵(WWT=WTW=I)以防止单语性能下降,同时能提供更好的双语映射。最小化欧氏距离平方等价于最大化点积,优化后的公式为:
式中:Tr(·)表示主对角线所有元素之和;W*=UVT为最优正交解;XTDY=UΣVT为XTDY的奇异值分解。
最后使用映射源语言嵌入和目标语言嵌入之间的点积作为相似度度量,最终词嵌入映射以一种自我学习的方式迭代,直至收敛,完成汉越双语词嵌入映射。
2 要素关联图增强的汉越跨语言事件检索模型
本节主要介绍提出的基于要素关联图的汉越跨语言事件检索模型,模型结构如图1 所示。模型主要分为三个部分:首先根据文档构建要素关联图,每一个节点代表一个关键短语;然后将查询-节点匹配特征输入图神经网络并根据查询结果计算文档相关性分数;最后采用加权策略融入双语文档相似度,实现汉越跨语言事件检索。
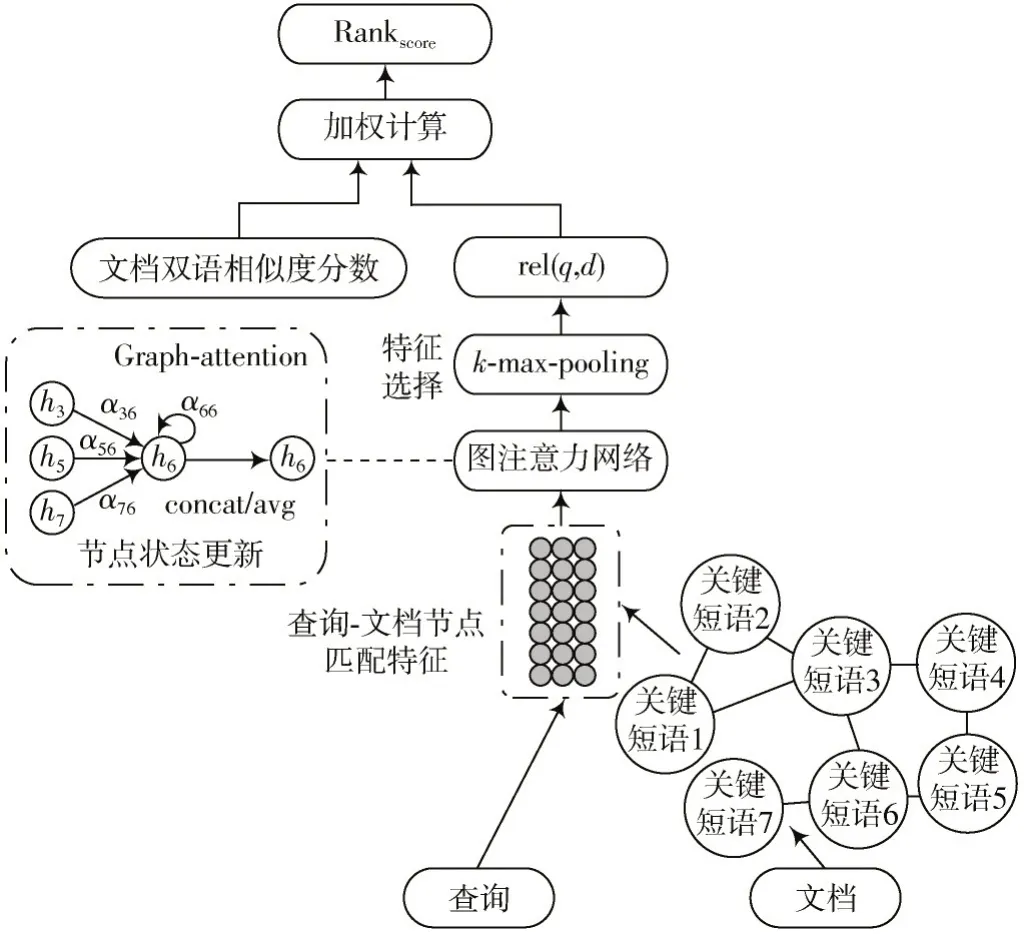
图1 基于要素关联图的汉越跨语言事件检索模型结构图
2.1 构建要素关联图
本节主要介绍如何基于输入越南语文档构造要素关联图。首先从原文档中抽取实体、关键词等重要要素作为图的节点来构建要素关联图。要素关联图可以有效表征整个文档的关键核心信息。对于每个查询q=[w(q)1,…,w(q)i,…,w(q)M],w(q)i为查询中第i个词,M表示查询长度,从文档D中抽取实体、关键词作为要素关联图的节点,所有的节点集合可表示为{w(d)1,w(d)2,…,w(d)n},n为节点个数。每个节点特征为其词嵌入与查询词嵌入之间的交互信号,使用余弦相似度矩阵S作为交互矩阵,定义如下:
式中:e(d)i为查询词向量;e(q)j为节点词向量;cos 为余弦计算。
通过节点之间的语义相似度和包含关系来确定要素关联图的边。为了缓解梯度爆炸或梯度消失的问题,将邻接矩阵归一化为=D-12AD-12,D为对角矩阵并且Dij=Σj Aij。
2.2 基于图的文本匹配特征提取
本文采用图注意力网络来获得关键词图的表征,其具体的操作步骤如下:
1)状态更新
用查询-文档交互矩阵初始化节点状态:
式中:j表示短语图中第j个节点;S:j表示交互矩阵S的第j列。
以图2 为例,对于节点“中英贸易”,它的邻接节点只有节点“英国脱欧”和节点“经济发展”,但不代表这两个节点对该节点具有一样的重要性。
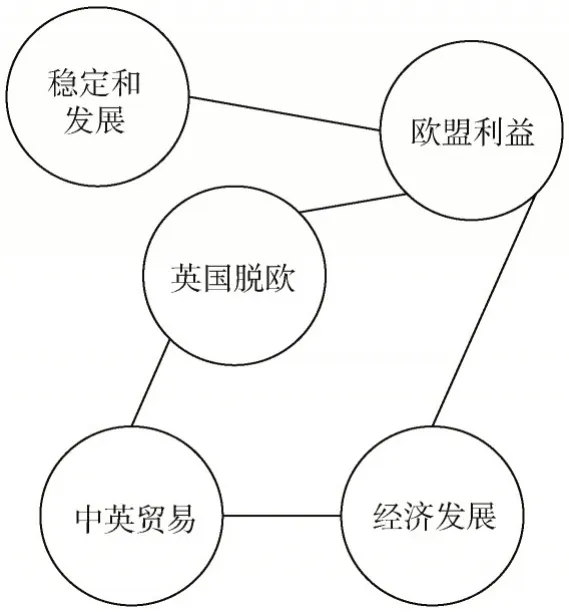
图2 要素关联图
因此,在进行邻居特征聚合时,通过图注意力层计算每个节点相对于其相邻节点的相互重要性程度,从而更新节点状态。节点的输入特征h={h1,h2,…,hn},n表示节点个数。为了获得足够的表达能力,将节点特征经过线性变换以得到更高层次的特征。具体策略为:将权重矩阵W应用于每个节点,并对每个节点执行自注意力机制,然后通过注意力系数计算节点k对节点j的重要程度,计算公式如下:
式中:αjk为节点k到节点j的注意力系数;“;”表示向量拼接;σ代表激活函数;注意力机制是一个单层的前馈神经网络,由权重向量aT进行参数化。
归一化的注意力系数用于计算与它们相对应的特征,得到每个节点的最终输出特征h={h1,h2,…,hn},计算公式如下:
式中:hj表示节点j的输出特征;Ni表示节点i的邻接节点;αjk为注意力系数。
2)特征选择
直观上看,相似度越高,关联可能性越大。因此,在查询维度上执行k-max-pooling 策略,并为每个查询项选择前k个信号,避免模型受到文档长度的影响。计算公式如下:
式中:i∈[1,M],表示查询中第i个词;H:,i表示特征矩阵H第i列。
2.3 匹配度计算
获得信息匹配特征xi后,需要将其转化为实际的相关得分进行训练。考虑到不同的查询词可能具有不同的重要性,在查询词级别采用注意力网络对查询词的重要性进行建模,它为每个查询词生成一个权重,控制该查询词的相关性得分,最终得到更合理的相关性分数。通过词嵌入学习查询中的词权重,使用查询词向量作为门控函数的输入,计算公式如下:
式中:gi表示词权重;eqi为第i个查询词向量;wg表示术语门控网络的权重向量。
最后利用权重共享的多层感知机对每个查询词进行评分。
式中:Wx、bx为可训练参数。
选择双铰链损失函数对模型参数进行优化:
式中:q为查询;d+为相关样本;d-为不相关样本。
最后在源语言文档匹配分数基础上与双语相似度进行加权求和,得到目标语言每篇文档的相关性得分:
式中:rel源语言为源语言相关性得分;Sim 为源语言和目标语言相似度分数;“*”表示乘法;α为超参数,设置为0.6。根据相关性分数进行降序排列,从而得到查询的双语文档排序列表。
3 实验数据与结果分析
3.1 数据集
本文实验数据为从互联网爬取的汉越热点新闻事件文档,包含政治、经济、社会、科技、文化等五类新闻事件,其中包含汉语和越南语文档各6 500 篇,训练集4 500 篇,测试集和验证集各1 000 篇。每篇文档包括标题和正文两部分,根据事件内容构建了相同数量汉语查询和越南语查询,采用查询和文档的相关性分数进行排序,查询和文档的相关性由人工标注,其中1 代表查询与文档相关,0 代表查询与文档不相关。查询与候选文档数统计信息如表1 所示。为了进行评估,将语料按照8∶1∶1 的比例随机分成训练集、开发集和测试集,分别用于模型的训练、超参数的调优和模型的评估。
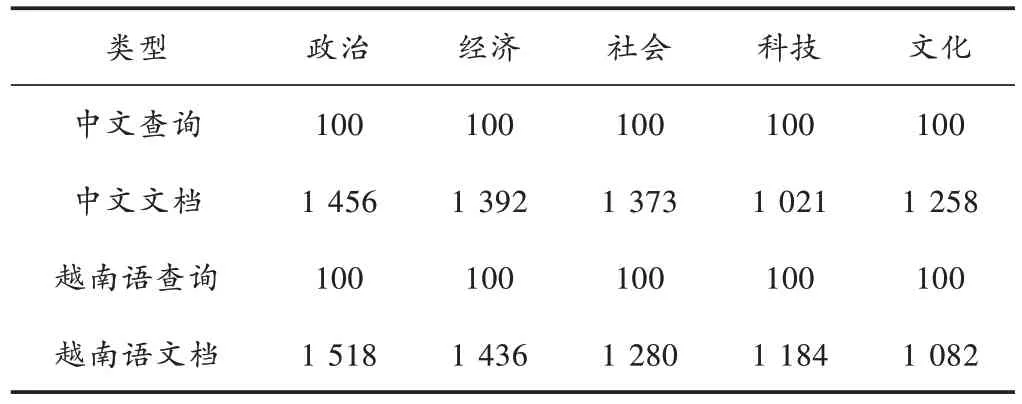
表1 实验数据统计
3.2 评估指标
本文采用NDCG[8]和mAP[9]作为实验的评价指标,具体的计算公式如下:
式中:k表示前k个排序文档集合;rel(i)表示排序列表中第i个查询与文档的相关度;IDCG@k由IDCG@k根据相关度对文档降序排序后得到。
式中:N表示相关文档总数;position(i)表示第i个相关文档在检索结果列表中的位置。mAP 表示多个返回结果的平均准确率。
3.3 实验设置
实验环境及参数设置详情如表2 所示。其中,词嵌入维度设置为200,图注意网络的层数设置为3,k-maxpooling 中k值设置为40,滑动窗口大小为7,训练批次大小为64,学习率为0.001,采用Adam 优化器进行优化。
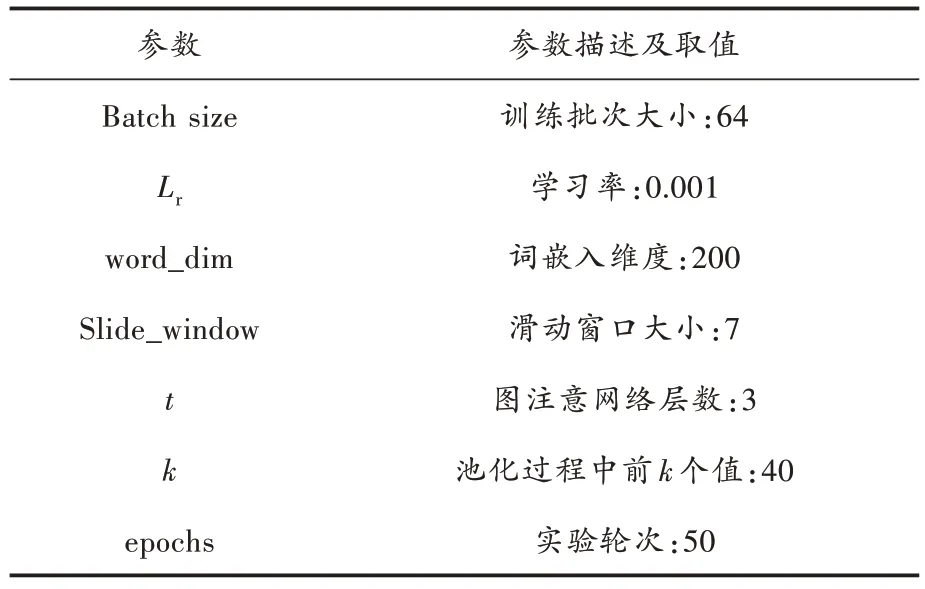
表2 实验环境及参数设置
3.4 实验结果分析
为了验证所提出模型的有效性,选取以下多个基线模型进行对比,实验结果如表3 所示。
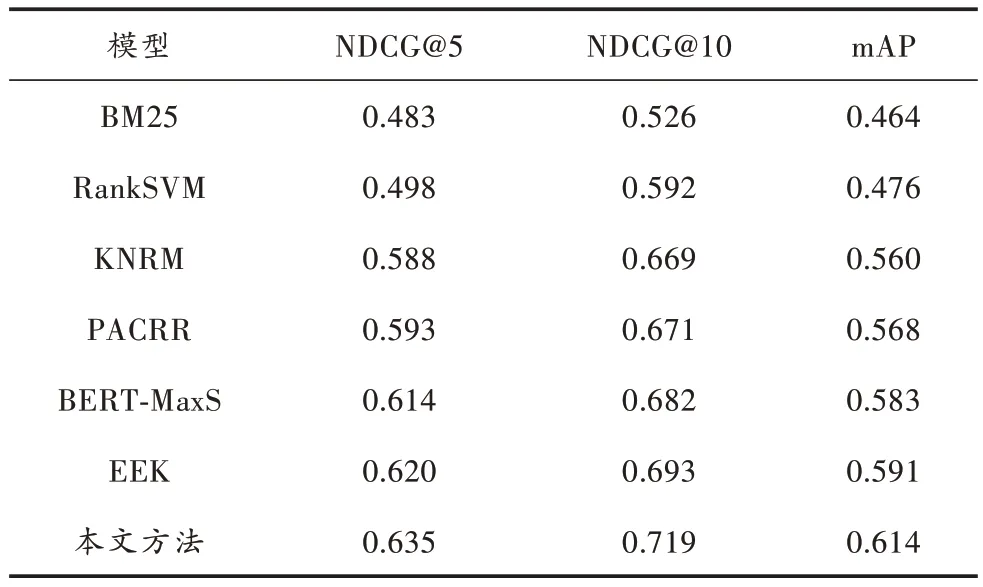
表3 与基线模型的对比实验结果
BM25:BM25 算法是在融合TF-IDF 特征的基础上计算查询句与文档相关性的一种算法,首先计算每个查询词与文档的相关度,再对得到的所有的词与文档的相关度进行加权求和,最后计算出最终的查询句与文档之间的相关度值。
RankSVM[10]:RankSVM 模型把文档检索问题进行转化,变成了pairwise 的分类问题,然后针对此分类问题利用SVM 模型进行求解。
KNRM[11]:KNRM 模型首先利用查询句向量和文档向量构建交互矩阵M,然后引入K个核函数,通过核函数池化的方式计算查询句与文档的相似程度。
PACRR[12]:DRMM 方法忽略文本位置信息,PACRR使用卷积网络提取词项的依赖关系,通过RNN 整合特征,能较好地保留文本位置信息。
BERT-MaxS[13]:使用BM25 模型计算查询句与文档的相关度值,并将文档切分为句子集合分别与查询句进行拼接,使用基于BERT 的检索模型计算查询句与每个文档句的相关度值。
EEK[1]:该方法通过查询翻译,将跨语言事件检索问题转化为单语事件检索问题,并提出融入事件实体知识来提升跨语言事件检索性能。
由表3 的实验结果可以看出:本文模型比其他基线模型性能更好,与传统模型BM25 相比,基于神经网络的模型在NDCG@5、NDCG@10、mAP 评价指标均有显著提升;在基于交互的神经排序模型中,与KNRM 模型相比,PACRR 模型在NDCG@10、mAP 指标比KNRM 提升了0.3%和1.4%,提升效果不大,而PACRR 引入了词位置信息,采用卷积操作来捕捉局部词序关系,说明位置信息和运算操作并不能很好地提升事件查询-文本匹配效果。新闻事件排序是针对事件粒度信息的文本匹配,本文所提模型从事件粒度进行文本匹配,效果优于基于局部交互的模型,NDCG@10、mAP 指标比PACRR 分别提高了7.2%、8.1%,由此证明了通过融入事件要素关联图可以有效建模查询文本的全局语义信息。
3.5 消融实验
3.5.1 不同GCN 层数下实验性能对比
为了研究图神经网络层数下模型的表现效果,设置了不同的卷积层数进行对比实验,实验结果如图3所示。
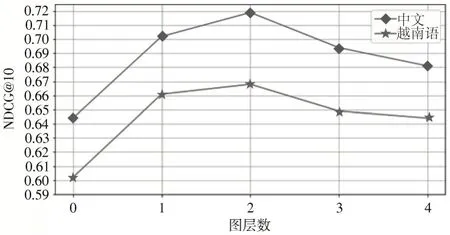
图3 不同图层数对模型性能的影响
由图3 可以看出,与0 层的模型相比,仅通过1 层网络就显著地提高了模型的性能,说明在图中传播关键短语信息有助于理解查询交互和文档级词关系,查询文档匹配信号可能会受到文档内的词关系影响。2 层网络比1 层网络模型性能有小幅度提升,但当叠加层数进一步增加时,模型的性能略有下降。原因可能是节点从邻居节点接收到更多的噪声,增加了参数训练的负担,过多的传播也可能导致过度平滑的问题。总的来说,使用上下文信息和不使用上下文信息之间存在巨大的差距,汉越新闻事件数据集上,图层数在2 层时达到峰值。实验结果也证明考虑关键短语级交互和文档级词汇关系对于汉越双语新闻事件排序很有必要。
3.5.2 不同k值下实验性能对比
为了研究k-max-pooling 中k的取值对模型性能的影响,对k取值为10、20、30、40、50 时的实验结果进行对比,如图4 所示。
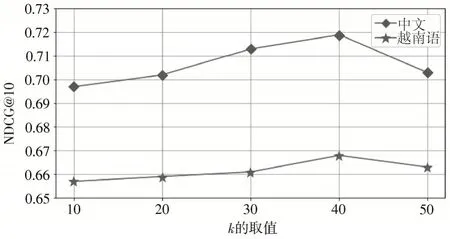
图4 不同k 值对模型性能的影响
通过图4 可以得到,当k取值从10 取到40,模型性能稳定增长。通过增大k值,可以将匹配信号多的相关项与匹配信号少的无关项进行区分。当k继续增大,呈现下降的趋势,说明较大的特征维数会带来负面影响。k值越大,可能对文档长度有偏置,文档越长,匹配信号越多。总体来看,图中没有明显的急剧升降,说明模型对k值的选取不是很敏感。同时,选取不同k值取得的性能均超过基线模型,这表明匹配信号是在特征选择前一个阶段基于图的交互过程中获得的。
3.5.3 不同α值在匹配度加权计算上的性能对比
为了探究模型中超参数α的不同值对模型性能的影响,本文设置了不同α值在本文模型上进行实验,实验结果如表4 所示。

表4 阈值α 对中文查询实验性能的影响
从表4 的实验结果可以看出:虽然当阈值低于0.6时,在三个指标上的性能都有明显降低,但在阈值从0.1提升到0.5 过程中,实验性能逐渐提升,在一定程度上验证了融入事件要素关联图可以有效捕获查询文档中的核心事件信息;当阈值大于0.6 时,模型性能开始出现下降,可能原因是当增加源语言关键短语的文档相关性得分时,使排序过于依赖单语的相似性,弱化了双语之间相似度,反而在最终的排序结果上并不理想。
4 结 语
为了实现汉越跨语言事件检索,本文提出了一种基于要素关联图的汉越跨语言事件检索方法。对于一对查询-文档,将文档转换为事件关联图的形式,通过节点中词与查询词的交互分配节点匹配特征;然后通过图神经网络传播匹配信号;接下来对查询进行k-max-pooling策略选择,将其特征输入神经网络层中以估计相关分数;最后在单语相关分数的基础上加权计算双语文档相似度分数,得到最终双语文档检索排序结果。实验结果表明,本文的双语模型达到了单语模型的准确率,在汉越新闻事件排序中取得了很好的效果。
猜你喜欢
客联(2022年3期)2022-05-31
新世纪智能(数学备考)(2021年9期)2021-11-24
中国新闻周刊(2021年26期)2021-07-27
当代陕西(2019年15期)2019-09-02
意林图解作文(小学版)(2019年6期)2019-07-16
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
信息安全研究(2016年4期)2016-12-01
专利代理(2016年1期)2016-05-17
