
基于大数据的分拣设备智能分析系统的设计与研究
2024-04-03 03:09龚亚彬
电脑知识与技术 2024年1期
龚亚彬
关键词:自动分拣;数据采集;大数据;HBase/Hive;智能分析
0 引言
随着物流行业的发展和物联网的普及,全国现代物流中心为了提高物流效率和服务质量,已逐步实现了信息化,对高性能物流分拣设备的需求在日益增长, 相应的各类智能自动化分拣设备也在不断地涌现。在众多的分拣设备中,小件交叉带分拣设备、大件摆臂摆轮分拣设备、模组带分拣机转换机和AGV等产品得到了业界广泛的应用与认可。
包裹分拣模式由传统的人工分拣逐步演变为自动化分拣,实现了对分拣全过程、全环节的信息跟踪与监控,提升了作业自动化水平,使得物流行业的整体运营效率大幅提升,运营成本大大降低。
由于包裹的多样性、供件人员操作不规范、设备元器件精密度要求高和分拣环境复杂等因素,给设备的稳定性和分拣的准确性造成了诸多困扰。分拣过程记录、设备PLC通信和光电信号传感器产生了海量数据,尤其在“618”“双11”“双12”“节假日”等高峰期间呈指数级增长。面对其庞大、多源、异构等特点,如何保证数据的快速接收与存储,并将分析结果反馈给相关业务部门,如何进一步确保设备运行的高稳定性和分拣结果的99.99%高准确率成为一大难题。
本文以Ginfon交叉带分拣设备为例,在分析分拣过程数据的特点和大数据技术的基础上,基于HBase 大数据库、Hive数据仓库和Spark计算模型进行整体架构设计和针对性分析,最终实现了对海量多源、异构和分布式分拣大数据的高效快速处理。对各项指标进行建模,可对分拣过程和设备元器件进行全方位智能诊断和智能决策,通过模型计算与评估挖掘潜在问题与规律,有效改善设备的分拣流程,促进设备工艺的优化,从而提升产品的市场竞争力。
1 相关技术简介
1.1 交叉带分拣设备的特点
交叉带分拣机由主驱动带式输送机和众多载有小型带式输送机的台车组成。环线小车与主驱动带式输送机连接在一起,包裹经供件台扫码后由PLC预约小车和装载。小车采用伺服直流驱动技术,毫秒级瞬时启动,确保货物能上正确的小车且位置居中。在控制系统的控制下,包裹随小车与主驱动带式输送机一起运行。当运行到目标位置时,小车皮带启动,将待分拣物品推送至分拣格口,完成包裹的分拣任务[1]。
1.2 HBase/Hive
HBase建立在HDFS之上,提供了高可靠性的列存储和实时读写的大数据库系统,介于关系型数据库和NoSql之间,通过主键和主键的Range来检索数据,支持单行事务,主要用来存储非结构化和半结构化的松散数据。
Hive是基于Hadoop的数据仓库工具,可以将结构化数据文件映射为数据库表,是一种类SQL的引擎,可以将SQL转化为MapReduce任务运行,十分适合数据仓库的统计分析[2]。
1.3 Spark
Apache Spark 是为大规模数据处理而设计的快速通用计算引擎,任务中间输出结果保存在内存中,由于不需要读写HDFS,Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark 启用了内存分布数据集,除了能够提供交互式查询外,还可以优化迭代工作负载。在内存计算模式下,Spark比Hadoop快100倍以上。Spark提供了大量的库,开发者可以在同一个应用程序中无缝组合使用这些库[3]。
2 系统架构设计
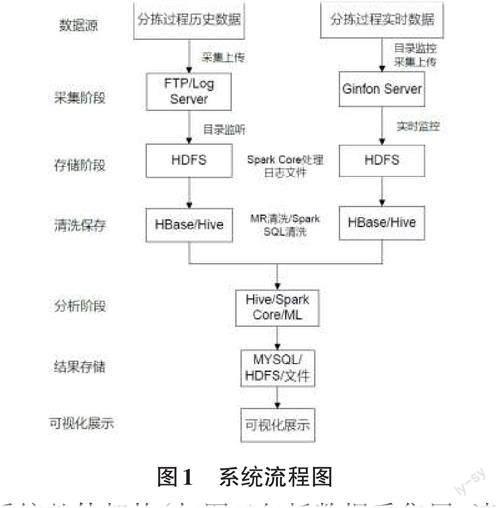
智能数据分析系统(Intelligence Data Analysis Sys?tem,IAS) 采用客户端分布式采集,云端集中处理模式。云端服務器与全国各个分拣中心交叉带分拣设备WCS实时连接,接收PLC控制器的指令。通过对分拣机WCS系统的日志目录监控,定时和实时采集正常日志、错误日志和系统信息,从各个分拣客户端传输至系统云端。服务端接收日志数据后保存至相关目录,通过Hadoop任务调度对相应的日志内容进行数据清洗、格式转换及规范处理,实现了包裹信息检索、分拣过程分析、设备元器件分析、错分分析、设备状况感知与分析、运营与监管、模型预警与预判、设备画像,同时给出分析报告。系统整体流程如图1所示。
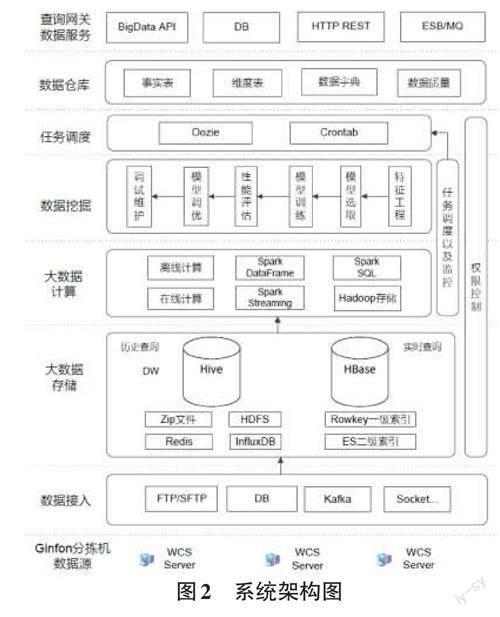
系统整体架构(如图2)包括数据采集层、清洗与存储层、数据计算、数据挖掘、任务调度、数据仓库和网关服务等。
2.1 数据采集层
数据源由设备参数数据和WCS分拣日志记录构成。设备参数数据包含交叉带的层数、小车数、供件台数、格口数、灰度仪数、小车组/格口组/急停按钮数和分拣方案数据等。分拣日志记录以文本文件格式保存,具体包括:分拣流程记录、PLC通信报文数据和光电传感器信号数据。数据采集层通过异步Socket 由客户端发给服务器,服务端接收后进行处理,处理完毕后返回给客户端相应指令。服务端将接收到的日志文件根据设备名称保存在相应的目录中,数据存储在HBase 和MySQL。服务端大数据环境Hadoop+Spark采用1主2从模式,可支持横向扩容[4]。
2.2 数据清洗与存储层
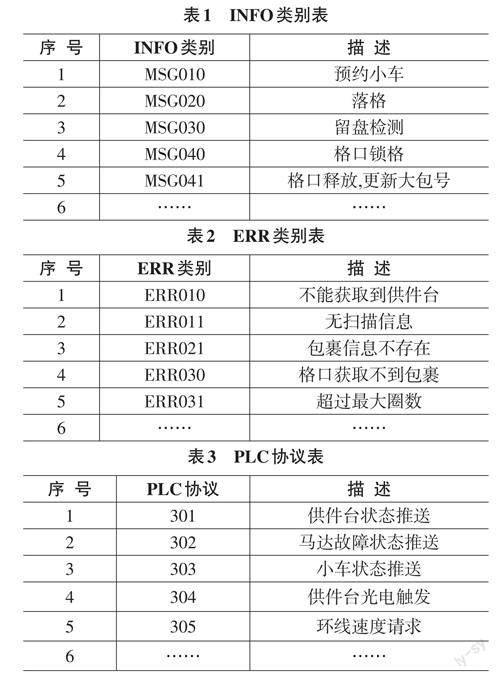
由于客户多样,不同的WCS客户端分拣记录日志格式存在差异、数据的不完整和未统一标准化,服务端将采集到的日志文件进行清洗处理形成规范,清洗的内容有:字段格式转换、缺失值、重复值、错误值和异常值等。分拣过程需要按不同阶段设定不同的INFO 类别(如表1),不同阶段的异常设定不同的ERR类别(如表2),控制设备元器件的PLC报文按协议编号进行区分(如表3)。
清洗后的INFO类别、ERR类别和PLC报文数据存储在大数据库HBase表中,通过数据仓库Hive统一调用。
2.3 数据分析
系统通过采集交叉带设备的分拣日志,做针对性分析,集设备分拣效率评估、分拣流程追溯、供包台供件效率、小车落格率分析、集包效率、可疑流程诊断、设备元器件分析和错分分析等于一体,挖掘规律,控制各项指标在有效的阈值内,同时实现预警。
3 功能模块设计与实现
系统主要包括分拣统计、集包效率分析、分拣过程追溯、相邻小车落格分析、错分分析和重量体积比分析等功能,具体功能模块如图3所示。
3.1 分拣统计与集包效率分析
通过Spark Core读取清洗后的标准日志文件,针对不同场地可进行如下分析:
1) 供件台分拣统计:根据各个供件台分拣量评判供件效率情况。
2) 小车分拣统计:根据小车分拣量评判可疑小车情况。
3) 集包效率分析:根据人员锁格、解锁时间差评估集包操作人员的熟练度。
4) 根据设备元器件运行过程的关键评判指标提供相关预警、提高主动式维修响应速度。具体包括:迷路预警、灰度仪及光电的故障预警、环线碳刷寿命预警、48V电源报警和小车故障检测等。提供的预警阈值分为供件台供件量阈值、小车分拣量阈值和集包时长阈值等。
3.2 分拣过程追溯
根据不同设备进行不同条件的组合查询,如条码、格口/小车/供件台号、报文类型和日志消息类型等,供分拣分析使用。
1) 分拣过程追溯:通过JDBC调用Hive Sql详细跟踪包裹分拣过程中供件台、小车、格口的状态详情及系统错误信息,并可关联查询供件台上一个包裹、下一个包裹,相邻小车上一个包裹、下一个包裹分拣情况。
2) 分拣调查:根据条码、错分格口、异常口针对性分析错分原因,并实现关联查询分析。
3) 针对分拣的流程,统计分析迷路占比及趋势,可直观地评判纠偏仪、灰度仪的工作运行正确率及稳定性。
3.3 相邻小车落格分析
环线小車通用截距60cm,格口宽度75cm,在2m/s的速度运行时,每5个小车在时间分配上为一组连贯性控制。当出现相邻小车落相邻格口时,可评估采用动态变换格口挡板角度来增加包裹的落格准确性。此时需要统计分析交叉带项目场地1s内、500ms内相邻小车落相邻格口情况,结果供设计部门对滑槽工艺改进及相关决策。相邻小车落相邻格口模型如图4所示。
由表4可得出,小车间隔越大,相邻格口落格比例逐渐降低,各场地占比情况整体类似。货物相邻、货物间隔1个小车、货物间隔2个小车落相邻格口导致格口变换的占比约为1.23%。而通过摆臂动作测试,只有货物相邻、货物间隔1个小车才可能导致摆臂来不及动作,占比为0.85%,此种情况,完全可以通过程序禁止第二件货物在此区域落格,而去另外一个区域落格,却对整体分拣没有影响。
3.4 错分分析
根据条码、错分格口和回流口可进行批量错分原因分析与错分关联查询。
包裹是否落入正确格口,和上车的位置、纠偏的位置、环线速度、包裹外观、材质重量等诸多因素有关联,通过大数据相关性分析得出包裹的重量和体积是直接的可量化指标。通过分析得出整体包裹的重量体积比分布情况,步骤如下:
1) 使用Spark SQL读取错分条码的重量(kg)、长宽高(cm)数据。
2) 通过Stream.groupBy()按包裹密度(重量/体积)级别分类,计算其占比[5]。
由图5所示:包裹密度主要分布在0.02~0.8kg/立方分米以内,总占比95.18%。根据上述包裹密度结果,在确定落格时PLC可精确实现对小车的毫秒级控制,减少错分机会。
4 结束语
智能数据分析系统作为一个物流分拣的大数据分析平台,是智能分拣设备、物联网和大数据相结合的典型应用,支持和兼容各类分拣设备的高并发场景,易于扩展,满足了快速、高效处理和专项分析有效数据的硬性要求。实现了数据来源于设备,分析结果逆向促进对分拣设备的有效智能管理,为提高设备的稳定性、准确性和产品的进一步的迭代奠定了真实的应用基础,大大提升了产品的市场竞争力。
猜你喜欢
农业与技术(2016年15期)2016-11-09
科技视界(2016年18期)2016-11-03
软件工程(2016年8期)2016-10-25
软件工程(2016年8期)2016-10-25
中国新通信(2016年16期)2016-10-18
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
