
长向量处理器高效RNN推理方法
2024-04-08 11:38苏华友陈抗抗杨乾明
国防科技大学学报 2024年1期
苏华友,陈抗抗,杨乾明
(1. 国防科技大学 计算机学院, 湖南 长沙 410073; 2. 国防科技大学 并行与分布计算全国重点实验室, 湖南 长沙 410073)
传统的卷积神经网络(convolutional neural networks,CNN)在视觉领域取得了巨大的成功,例如图像分类、目标检测等。但是对于语言类时序数据任务,某些时刻前面的输入和后面的输入是有关系的,CNN这种只能处理独立输入的模型就无法获得较好的效果。循环神经网络(recurrent neural network, RNN)是面向时序数据处理的一类重要的深度神经网络,它以序列数据为输入,并对每一个时刻的输入结合当前模型的状态给出一个输出。目前,以RNN、长短记忆网络[1](long short term memory networks, LSTM)、门控循环单元[2](gate recurrent unit, GRU)为代表的时序数据处理类循环神经网络已广泛应用于文件分类[3]、语音识别[4-5]和机器翻译[6]等自然语言相关的任务处理中。随着自然语言处理任务的复杂度增加,计算量更大的Transformer结构和BERT模型得到广泛的应用,对计算资源的需求和计算效率的提升都提出很大的挑战。
随着模型规模的扩大和模型层次的增加,类循环神经网络的训练和推理过程对目标平台的执行效率提出了极大的挑战。如果沿用通用深度学习框架,诸如PyTorch[7]、TensorFlow[8]等直接按照类循环神经网络的计算过程进行碎片式、拼接化执行,硬件的利用率得不到保障。例如,在图形处理器(graphics processing unit, GPU)上直接调用各个算子函数进行端到端的拼接执行,LSTM的执行效率还不能达到峰值性能的10%。当前有很多的工作针对RNN在GPU上的执行过程进行了优化,例如cuDNN[9]深度学习库。该工作通过算子级的优化、层级融合等多种技术手段,大大提高了RNN计算在GPU上的效率。随着物联网技术的发展,越来越多的设备接入网络中,例如中央处理器(central processing unit, CPU)和数字信号处理器(digital signal processor,DSP)等,这类处理器的数量远远多于GPU,并且离数据源更近。然而,当前针对CPU或者以长向量为重点计算单元的DSP的类循环神经网络计算优化工作相对较少,只能借助于基础的矩阵乘等算子进行功能实现,以LSTM等为代表的类循环神经网络在DSP等长向量处理器上的性能优化空间还很大,难度也很高。
首先,RNN处理对象的序列长度可变性导致计算不均衡。对于RNN处理的序列数据而言,不同语句的长度往往不一致,会导致描述语句的输入向量长度不一致。在大batch_size主导的推理应用模式下,所有的时序都会以当前batch中序列长度最大的样本为参照,进行样本数据的填充以保证输入的底层计算规模相同,从而不会影响循环的深度,同时使得分批处理执行变得简单,但是这种填充的方法会造成大量的额外的计算需求。其次,序列长度的可变性导致内存管理的不确定性。序列长度的不同会使得内存的分配和片上存储分配动态变化,否则,所有序列都需要按照最长序列的需求进行存储分配。另外,由于基于长向量处理器的智能算子库的缺失,需要重新构建完整的算子,需要对矩阵向量乘和矩阵乘进行优化,同时RNN及其变种还存在大量的边缘算子,这些算子的性能也会影响整体的效率,并且随着参数的增大,RNN等模型中核心矩阵规模增大,矩阵计算效率的提高会放大边缘算子计算的耗时占比。
针对上述问题,本文面向国产自主长向量处理器FT-M7032,研究如何高效实现RNN等类循环神经网络推理任务的并行优化实现。首先,为了克服序列长度可变的问题,提出了一种行优先的矩阵向量乘方法,通过改变原有的计算顺序,有效地利用长向量处理器的计算单元和开发数据的局域性,最大化提高计算效率。然后,建立了一个手工汇编实现的高效的RNN算子库,对矩阵向量乘算子的底层实现进行了深度优化,包括单核内的指令排布、多核任务划分以及片上存储空间的替换策略等。最后,高效实现了RNN等类循环神经网络模型的边缘算子,并且基于有效利用片上存储的原则对边缘算子和矩阵向量乘算子进行了融合。通过上述工作,可以有效地利用自主长向量处理器对循环神经网络算法进行加速。
1 背景介绍
1.1 RNN介绍
1.1.1 模型结构介绍
RNN常用于解决输入样本为连续序列且序列的长短不一的问题,单层RNN神经网络的结构如图 1所示。

图1 单层RNN神经网络的结构Fig.1 Structure of a single-layer RNN neural network
RNN每读取一个新的输入xt,就会生成状态向量ht作为当前时刻的输出和下一时刻的输入,将T个输入x0~xt依次输入RNN,相应地会产生T个输出,其中S表示神经元。
1.1.2 计算原理
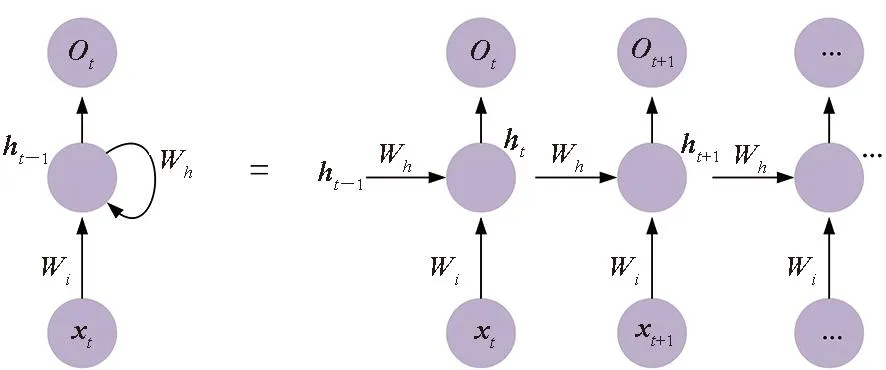
图2 RNN神经网络的计算原理Fig.2 Calculation principle of RNN neural network
典型的RNN神经网络的计算原理如图 2所示,主要由两条单向流动的信息流处理组成。一条信息流从输入单元到达隐藏单元,另一条信息流从隐藏单元到达输出单元。假设x为输入层,一般为向量;O为输出层,h为隐含层,而t指计算次数;Wi、Wh为权重,一般为矩阵。其中计算第t次的输出结果如式(1)所示。
Ot=f(xt×Wi+ht-1×Wh)
(1)
从式(1)可以看出,循环神经网络的主要计算模式是矩阵向量乘,当以batch模式执行的时候则是矩阵乘。除此之外,还涉及tanh、sigmoid等边缘计算过程。诸如LSTM和GRU等RNN变种模型的计算模式也主要以矩阵计算为主,区别在于LSTM相对于标准的RNN网络涉及的信息流更多,即矩阵计算模块更多。
1.2 FT-M7032长向量处理器
FT-M7032是一款国防科技大学自主研制的长向量处理器,采用异构结构,集成了1个16核ARMv8 CPU和4个通用数字信号处理器(general purpose digital signal processor, GPDSP )。多核CPU主要负责线程管理和通信,其单精度浮点峰值性能为281.6 GFLOPS。每个GPDSP集群包括8个DSP核心,它们共享6 MB片上全局共享内存(global shared memory, GSM)。每个计算簇中的8个DSP核和GSM通过片上网络进行通信,通信带宽可达300 Gbit/s。GSM是软件可管理的片上存储器,需要由开发人员维护GSM和DSP之间的数据一致性。CPU和每个GPDSP计算簇以共享内存的方式进行数据交互。CPU可以访问整个内存空间,但每个GPDSP计算簇只能访问其对于内存通道的存储空间,理论访存带宽为42.6 Gbit/s。
GPDSP中的每个DSP核心基于超长指令字(very long instruction word, VLIW)架构,包括指令调度单元(instruction fetch unit, IFU)、标量处理单元(scale processing unit, SPU)、向量处理单元(vector processing unit, VPU)和直接内存访问(direct memory access, DMA)引擎,如图3所示。IFU被设计为每个周期最多启动11条指令,其中包含5条标量指令和6条向量指令。SPU用于指令流控制和标量计算,主要由标量处理元素(scale processing element, SPE)和64 KB标量内存(scale memory, SM)组成,它们匹配5条标量指令。VPU是长向量处理单位,为每个DSP核心提供主要计算性能,包括768 KB阵列存储器(array memory, AM)和以单指令多数据(single instruction multiple datastream, SIMD)方式工作的16个矢量处理元件(vector processing element, VPE)。每个VPE有64个64位寄存器和3个融合乘加(float multiply accumulate, FMAC)单元,1个FMAC每周期可以处理2个FP32或者4个FP16的乘加计算。当工作在1.8 GHz时,每个DSP核可以提供的单精度浮点峰值性能为345.6 GFLOPS,半精度浮点峰值性能为691.2 GFLOPS。AM可以通过2个向量load/store单元,在每个周期向寄存器传输512个字节。SPU和VPU之间通过广播指令和共享寄存器传输数据。DMA引擎用于在不同级别的存储器(即主存储器、GSM和SM/AM)之间进行块数据传输。

图3 FT-M7032长向量处理器体系结构Fig.3 FT-M7032 long-vector processor architecture
1.3 相关研究
当前,已有一些面向循环神经网络推理的优化研究,比如:TensorFlow使用cuDNN对底层进行优化,但是其核心采用矩阵乘算法并不能匹配序列长度的可变性,导致不能最大化地利用计算资源。Holmes等提出了GRNN[10]引擎,该引擎最小化全局内存访问和同步开销,并通过新的数据重组、线程映射和性能建模技术来平衡芯片上资源的使用;Zhang等[11]提出了DeepCPU,创建了专用缓存感知分区,通过形式分析优化共享L3缓存到私有L2缓存之间的数据移动。DeepCPU和GRNN存在类似的问题,主要优化的是底层算子,没有考虑序列可变带来的问题。Gao等[12]和Silfa等[13]都试图通过批处理相关技术进行性能优化,但是没有针对底层算子进行进一步的提升。除此之外,还有很多针对GPU平台对LSTM[14]、GRU[15]和Transformer[16]的性能优化工作,其目的都是提升在复杂模型情况下序列任务的执行效率。
除了批处理优化和内核优化,还有一些其他方式的相关工作:Kumar等[17]提出了一个名为Shiftry自动编译器,将浮点深度学习模型编译成8位和16位定点模型,显著降低内存需求,并且使用了RAM管理机制,可在物流网设备上获得更低的延迟和更高的准确性;Thakker等[18-21]提出了多种RNN压缩方法,探索了一种新的压缩RNN单元实现,最终实现了比剪枝更快的推理运行时间和比矩阵分解更好的精度的效果。然而,上述工作都是在牺牲精度的情况下进行RNN推理优化,存在一定的局限性。此外,还有一些基于现场可编程门阵列[22-23](field programmable gate array, FPGA)的RNN高效实现研究。
2 面向FT-M7032处理器的RNN推理并 行优化
包括RNN、LSTM在内的类循环神经网络计算过程主要分为矩阵向量乘和激活函数等边缘算子。本节对两类算子均进行了优化。其中,重点对计算耗时较大的矩阵计算进行了优化,提出并实现了面向长向量体系结构的行优先通用矩阵向量乘(general matrix vector multiplication, GEMV)算法,有效提升计算效率。为了减少对片外存储空间的访问,还将边缘算子和部分矩阵算子进行了融合。
2.1 面向长向量处理器的行优先矩阵向量方法
常见的矩阵向量乘有两种格式,第一种为y=xA,第二种为y=Ax,RNN模型更加接近于第一种,其中x代表输入序列向量,A代表权重矩阵。假定矩阵A的大小为k×n,向量x的大小为1×k,向量y的大小为1×n,且
(2)
式中,j=0,1,2,…,n-1。传统的实现方式是取向量x中的第i个元素与矩阵A的每一行的第i个元素进行对应的计算。然而,对于超长向量体系结构来说,这种实现方式难以有效利用长向量处理单元:一是矩阵A需要转置,增加大量的数据访问,对于存储带宽本就较低的处理器而言,会导致性能急剧下降;二是需要对最后结果进行规约,FT-M7032处理器结构对于规约计算并不友好。
针对这一问题,提出按行计算的GEMV算法,该向量化方法的基本思想是每次计算矩阵A的一行元素,计算向量y的第j个值由k次向量累加完成。首先将向量x分成p组,假定k能被p整除,每组包含q个元素,然后取矩阵A的q行,与向量x对应的q个元素进行乘加运算,之后分别从矩阵A以及向量x取下一组元素进行对应的计算,并且与上一组的结果进行相加,最后在p组内部进行对应相加运算。图 4表示其中组内的矩阵向量乘实现。
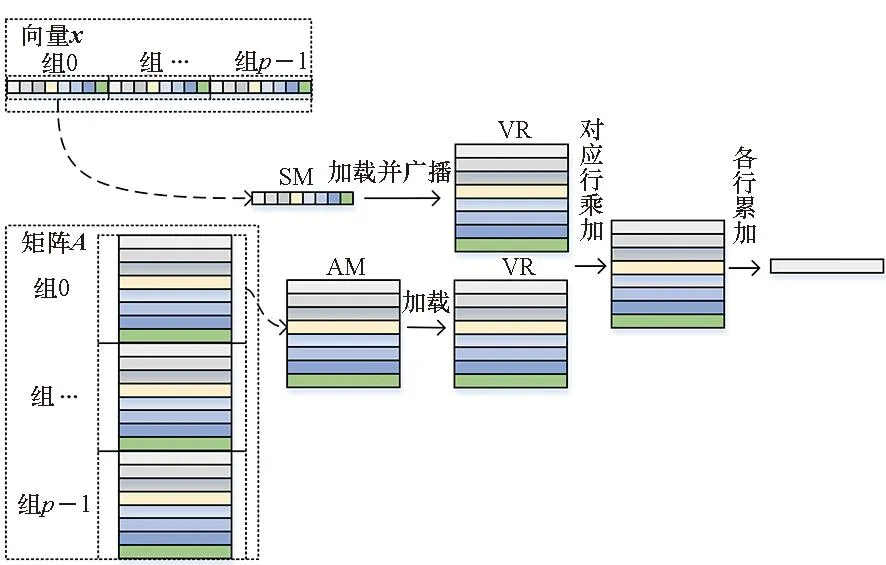
图4 组内的矩阵向量乘实现Fig.4 Matrix vector multiplication implementation within a group
基于上述原理,为减少循环开销,本文通过手动编排汇编代码,让VPE的v个FMAC指令同时并行执行,并根据FMAC指令延迟槽进行循环展开,以获得较好的流水排布和最佳的性能。以q=8为例,核心汇编循环如图 5所示。SLDH指令表示将输入数据从SM中按照半字大小格式加载到标量寄存器中,这时标量寄存器中低位数据为传输的半字大小的数据,高位数据为0,但是因为标量寄存器可以存储单字大小的数据,所以使用SFEXTS32L指令将标量寄存器中的低位数据扩展到高位上,使得高低位的数据都为传输进来的单字大小的数据,继而使用SVBCAST指令将数据从标量寄存器广播到向量寄存器VR,使用VLDW/VLDDW指令将数据以单字/双字大小从AM加载到另外的向量寄存器VR,并使用VFMULAS32指令对不同的VR寄存器中的数据进行乘加计算,其中的SBR指令为条件跳转语句,用于算法的循环,SUB指令用于控制循环变量的自减。

图5 矩阵向量乘的核心循环Fig.5 Core loop of GEMV
本文提出的矩阵向量乘的汇编代码的计算单元利用率很高,当k=1 024时,最高利用率为99.3%;当k=512时,最高利用率为98.6%;当k=256时,最高利用率为97.3%。
2.2 向量拼接
如式(3)所示,循环神经网络计算包括大量的矩阵向量乘。
x×Wi+Bi+h×Wh+Bh
(3)
式中,x和h为向量,Wi和Wh为权重,Bi和Bh为偏置。如果按照式(3)进行计算和长向量内核调用,需要调用2次矩阵向量乘,且每次调用的计算量较小,对于计算能力较强的处理器,会导致硬件利用率较低。此外,对于计算单元足够多的处理器,这种直接碎片式的调用也导致大量碎片式存储空间的搬运过程。如式(3)所示,完成RNN的一次操作,需要11次数据传输(每个原始数据需要1次,一共6次;每次运算出的中间结果需要一次输出数据的传输,一共5次)。基于上述问题,可以通过数据拼接,将多个小规模计算拼接成较大规模数据的计算,以利用长向量处理单元的强大计算能力和DMA的大块数据传输效率。
具体而言,将x和h以及Wi和Wh分别进行拼接,并将Bi和Bh进行累加,将式(3)转换成:
x×Wi+Bi+h×Wh+Bh=x_h×Wih+Bih
(4)
按照上述公式,1次RNN样本的运算只需要进行1次加法以及1次乘法,以及5次数据传输(每个原始数据需要1次,共3次;每次运算出的中间结果需要一次输出数据的传输,共2次)。这样做的好处在于,虽然整体的计算量不变,但是通过减少碎片化数据的传输,提高了带宽利用率。合并方式如图6所示。对于有多个时间步的计算,输入x_hitj按照如图 6方式在双倍速率同步动态随机存储(double data rate synchronous dynamic random access memory, DDR)中排列。其中x_hitj表示第i个batch的第j个时间步输入数据。
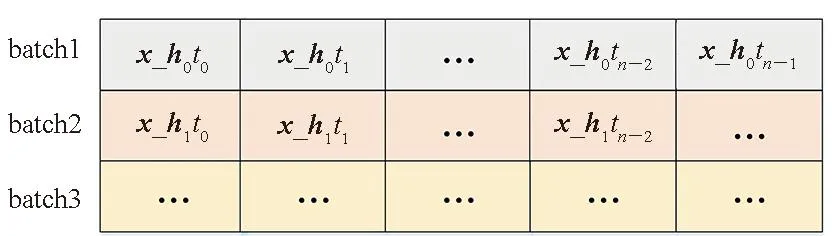
图6 向量拼接后输入数据结构Fig.6 Input data structure after vector concatenation
2.3 边缘算子融合
RNN模型的边缘算子一般为tanh和sigmoid,公式分别如式(5)和式(6)所示。
(5)
(6)
这两个算子都和ex相关,所以问题转换为高效求解ex。本文通过泰勒展开的方式构造ex的近似值,如式(7)所示。
(7)
为了更快收敛,采用以下步骤进行优化(需要注意的是,该方法需要上下界约束):
步骤1:预先计算ln2。
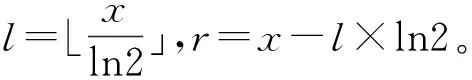
步骤3:ex=er+l×ln2=erel×ln2=er·2l。
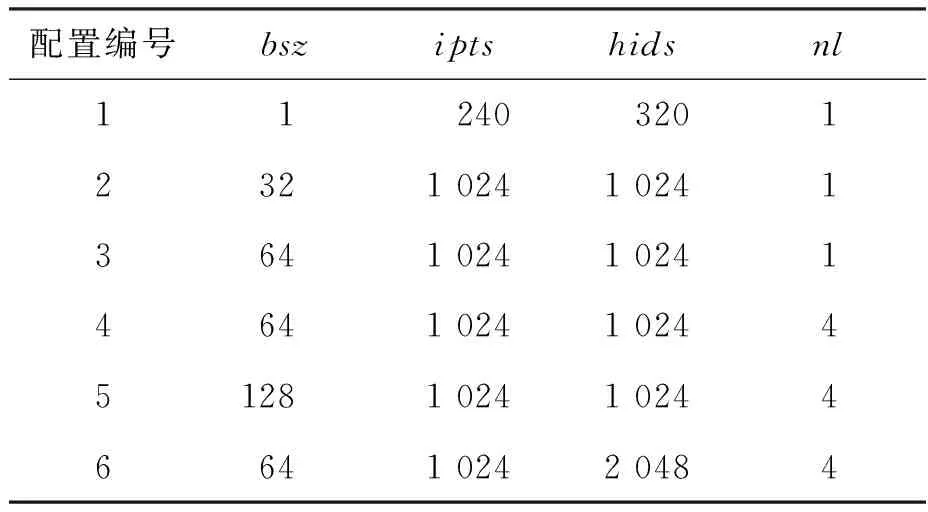
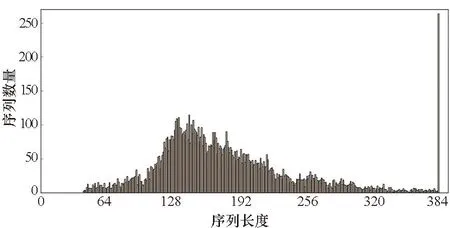
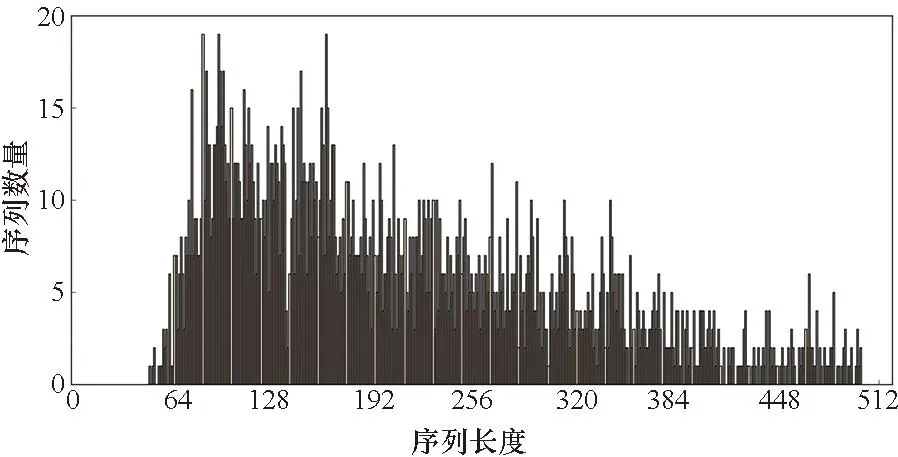
因为0≤r 算法1 基于DSP的ex汇编核心算法 当使用训练框架时,如TensorFlow或PyTorch来推理RNN模型时,大量的函数调用和中间临时结果传输导致大量的时间花费在一些非计算密集型的边缘算子上。可通过内核融合的方法减少内存访问的数量,利用片上存储提高数据的局域性。同时也可以减少内核启动开销以减少额外开销。本文主要实现了两个级别的内核融合策略:对于tanh、sigmoid等逐元素计算的算子,利用寄存器进行计算单元的融合;而对于向量加、点乘等需要两个输入的算子,利用核内空间AM的大容量进行算子融合。 FT-M7032处理器采用共享GSM和DDR的存储结构,且拥有最多8个计算核心。如何利用更多的计算核心对批量数据进行处理以提高计算效率,以及如何进行任务划分以提高片上存储利用率成为多核优化的关键所在。 FT-M7032异构处理器通过DMA完成核内外空间的数据传输,例如从DDR到GSM或者AM等片上存储空间,常用的传输方式包括点对点和广播两种方式。 通常来说,GSM的带宽是DDR带宽的10倍以上,为了更好地提高存储带宽利用率,可将数据尽可能地存放在GSM上,但是由于GSM的空间有限,所以有些数据也会溢出到DDR中。为了尽可能地减少对DDR的访问,本文设计了数据敏感的数据划分方式,根据输入数据的大小采用不同的数据存储模式和传输方式。 当向量长度较大时,即n较大的情况下,在n方向分核。将Wih和Bih存储在DDR上,通过点对点传输到核内空间AM;x存储在GSM中,通过点对点传输到核内空间SM;O存储在AM中,通过点对点传输到DDR中,如图 7所示,图中nc表示计算核的数量。此外,还根据权重的大小对数据存储生命周期进行了优化,如果满足式(8),将会让Wih常驻在AM中,极大地减少数据在AM和DDR之间的传输。 n-nc×z<0 (8) 式中,z表示FMAC能处理的向量长度。 在这种实现模式下,每个核上的x是一样的,而每个核上的Wih和Bih是不一样的。因为在GSM上使用点对点和广播方式的传输效率近似,所以采用点对点传输。 然而,当n较小时,根据向量长度在n方向分核会导致部分核长时间无法利用。而推理应用通常会采用高吞吐模式,将大批量数据捆绑输入,也就是说有很多条序列同时输入,使得batch_size(bsz)很大。针对这种情况,本文设计了序列维度的任务划分方式,如图8所示。 当输入序列数量较多时,采用bsz方向并行的模式。将Wih和Bih放在DDR上,通过广播方式传输;x放在GSM上,通过点对点传输。 在这种实现方式中,每个核上的x不一样,而Wih和Bih是一样的。考虑到在DDR上使用点对点和广播方式的传输效率差异大,而广播方式效率更高,因此采用广播传输。 图7 基于向量长度并行的多核分配方案Fig.7 Multi-core distribution scheme based on vector length parallelism 注:Wihnp表示Wih的列数除以nc并且向上取整。 对提出的面向长向量处理器的RNN并行优化实现在自主FT-M7032处理器上进行了测试,并与基于FT-2000+(16核)以及Intel Gold 6242R(20核)的实现结果进行了对比和分析。首先,基于SQuAD-1.1[24]以及OpenSLR LibriSpeech Corpus[25]两个数据集,分别在FT-M7032处理器和其他平台上对RNN和LSTM模型进行了性能测试以及比较;然后,对提出的各种优化方法的效果进行了细化评估;接着对循环神经网络中主要的计算模式矩阵向量乘进行了测试;最后与传统方法进行了对比。 测试中向量x的大小为1×k,矩阵A的大小为k×n,得到的向量y的大小为中1×n。为了测试的多样性,对RNN以及LSTM模型常用的4个参数进行了6组配置,如表1所示。其中batch_size(bsz)、input_size(ipts)、hidden_size(hids)、num_layers(nl)分别代表批次大小、输入大小、隐藏层大小、网络层数。 表1 RNN测试参数 采用矩阵向量乘的方法适应序列的可变性,并将边缘算子与矩阵乘算子进行了融合以获得在长向量处理器上的良好性能。以上述两个数据集为输入,分别在FT-M7032、FT-2000+(16核)以及Intel Gold 6242R(20核)上对RNN和LSTM的性能进行了测试,对同一数据集在不同平台下的吞吐量进行了对比。其中后面两个CPU平台的实现是基于PyTorch框架,后端是标准的深度神经网络库。测试结果分别如图9和图10所示。 从图9中可以看出,在各组参数下,提出的方法在两个数据集上的性能都能大幅超过对应循环神经网络模型在FT-2000+上的性能。从多组参数配置的加速效果可以看出,当参数配置较大时,加速效果更加明显,主要是因为:参数小时的计算量也较小,可并行度较低,计算占比较低;而当参数量增大时,可并行度增加,计算占比增加,加速比有明显提升,最大可高达62.68。 图9 基于长向量处理器的RNN和LSTM模型推理相比于FT-2000+的性能加速比Fig.9 Performance acceleration ratio of RNN and LSTM model inference based on long vector processor compared to FT-2000+ 从图10中可以看出,除了小参数的情况,提出的方法在两个数据集上的性能都能超过对应模型在Intel CPU上的性能,RNN模型加速比最大能达到3.51,LSTM模型最大加速比为3.12。而FT-M7032的峰值计算能力与Intel CPU相当,说明提出的实现方法针对硬件结构进行了有效的优化。 图10 基于长向量处理器的RNN和LSTM模型推理相比于Intel Gold 6242R的性能加速比Fig.10 Performance acceleration ratio of RNN and LSTM model inference based on long vector processor compared to Intel Gold 6242R 本文采取矩阵向量乘的方法而不是矩阵乘的方法进行RNN及其变种LSTM的处理,主要原因是batch中的序列长度不一致导致计算量不一致,如果使用矩阵乘实现,将引入很多的无效计算。分析了两个数据集的序列长度分布,如图11、图12所示。从图中可以看出,序列长度非常不均匀,如果对序列长度进行补齐的话,将存在大量的无效计算,可能导致性能的下降。 图11 SQuAD-1.1数据集序列长度分布Fig.11 Sequence length distribution of SQuAD-1.1 dataset 图12 OpenSLR LibriSpeech Corpus数据集序列长度分布Fig.12 Sequence length distribution of OpenSLR LibriSpeech Corpus dataset 在不同的参数下,为了适应可变序列,采用矩阵向量乘的方法,并且根据数据集的特点,将SQuAD-1.1的最大序列长度设置为384,将OpenSLR LibriSpeech Corpus数据集的最大序列长度设置为500,将适应可变序列的方法与固定最大序列长度的方法进行对比,其中RNN模型的对比结果如图13所示。 图13 使用RNN模型时,可变序列长度相比于固定序列长度的性能加速比Fig.13 Performance acceleration ratio of variable sequence length compared to fixed sequence length when using RNN model 从图13中可以看出,当bsz、ipts以及hids较小时,提出的实现方式收益较小,因为在此情况下,主要的时间消耗在数据搬运上,提高计算效率的影响不大。但是随着各个参数的增大,数据搬运的耗时占比慢慢减小,因此,通过针对算子等进行的极致优化效果变得明显,最高能产生1.79的加速比。 本文实现了高效的矩阵向量乘算子库,通过手动编排汇编的方式提高计算效率,对优化实现后的矩阵向量乘和基于PyTorch框架下矩阵向量乘在FT-2000+CPU的执行时间进行对比,不同规模下的加速比如图14所示。 从图14中可以看出,所有参数下,提出的矩阵向量乘的效率都高于FT-2000+,而当矩阵向量维度比较大的时候,性能提升更加明显,性能提升可达6倍以上。同时,本文注意到矩阵向量乘的加速效果不如RNN以及LSTM模型整体效果明显,其原因有两点:第一点是矩阵向量乘本质上不受可变序列长度的影响;第二点是使用RNN以及LSTM模型时,可以采用大批次,能更好地复用权重。 图14 基于长向量处理器的矩阵向量乘相比于 FT-2000+的性能加速比Fig.14 Performance acceleration ratio of matrix vector multiplication based on long vector processor compared to FT-2000+ 通用的框架,如PyTorch,使用矩阵乘实现RNN模型的推理,其主要考虑的问题是可以批量执行。因此,矩阵乘算法需要首先对序列进行预处理,将所有的带处理的序列进行对齐,然后进行并行处理。这种模式需要更大的内存空间,同时会引入很多额外的计算。本文对比了在长向量处理器上使用矩阵乘以及矩阵向量乘对RNN模型进行推理的吞吐量性能,如图 15所示,提出的基于矩阵向量乘的方法在RNN模型推理上的加速比最大可达1.82。 图15 基于矩阵向量乘优化方法相对于矩阵乘实现方法的RNN模型推理加速Fig.15 Performance acceleration ratio of matrix-vector multiplication for RNN model inference compared to matrix multiplication 本文面向FT-M7032长向量处理器对RNN模型推理进行了优化。首先,对RNN神经网络结构进行剖析,将其分为了矩阵向量乘算子和边缘算子,并根据处理器的体系结构,针对矩阵向量乘算子,提出了基于按行计算的矩阵向量乘算法,在多核层面采用了内核选择等优化方法;而针对边缘算子,提出了两个级别的内核融合优化方法,并且使用手写汇编对单核的两种算子进行了优化,旨在挖掘FT-M7032处理器的最佳性能。实验表明,提出的面向长向量处理器的RNN实现效果较好,相较于FT-2000+以及Intel Gold 6242R,LSTM模型最多分别获得了62.68倍以及3.12倍的性能加速。
2.4 数据敏感的多核并行优化方法


3 实验结果和分析
3.1 整体性能评测

3.2 基于可变序列的RNN以及LSTM性能加速效果
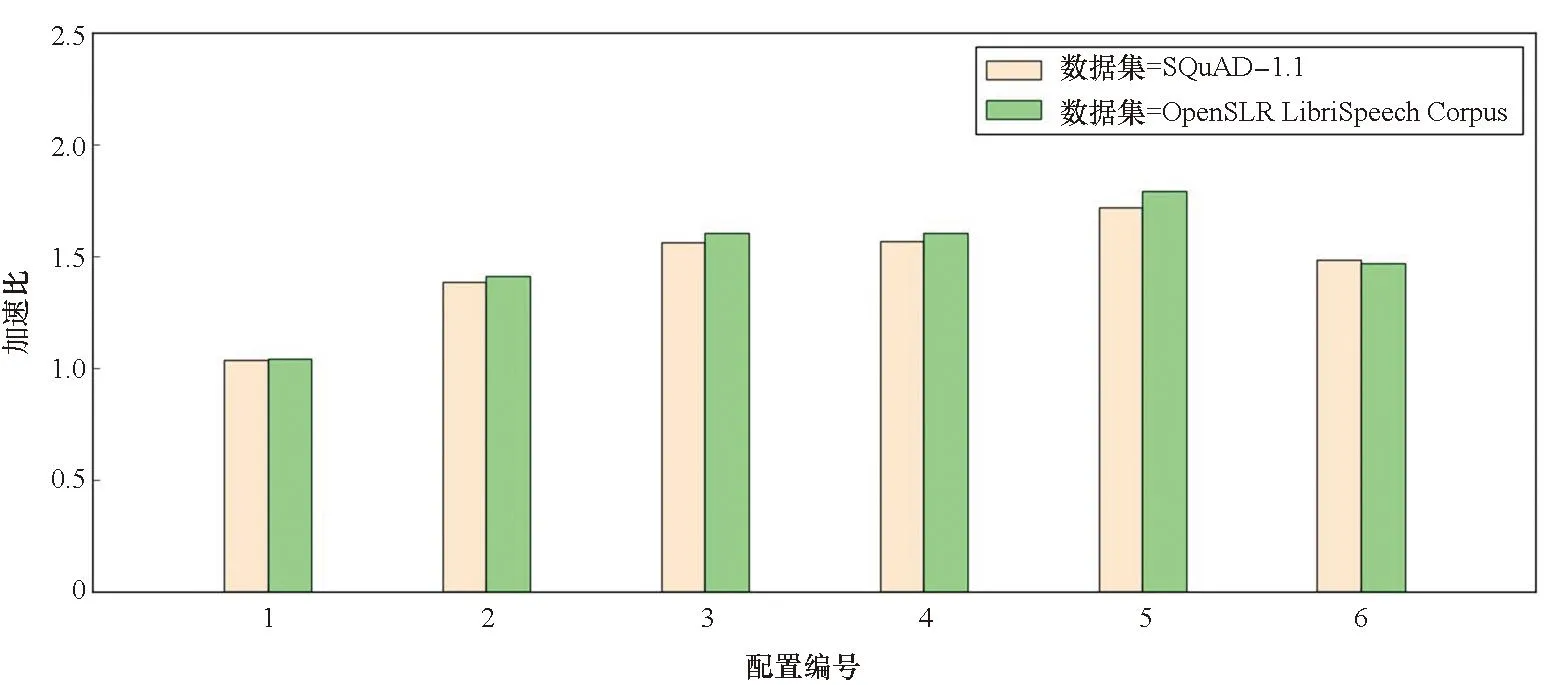
3.3 矩阵向量乘性能

3.4 不同RNN推理方法对比测试
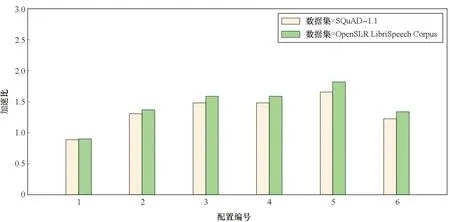
4 结论
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学物理学报(2021年2期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
数学物理学报(2016年3期)2016-12-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
