
基于邻域粗集神经网络的大数据特征分类系统
2024-04-13 06:54朱磊凌嘉敏
电子设计工程 2024年7期
朱磊,凌嘉敏
(1.浙江理工大学,浙江 杭州 310000;2.浙江外国语学院,浙江 杭州 310000)
大数据特征分类是指在互联网手段的作用下,按照数据样本表现形式所建立的数据信息特征提取与类别划分过程[1]。一般来说,数据样本类型越多,特征分类原则也就越复杂。然而随着大数据样本的不断累积,主机元件对这些信息参量的准确分类能力明显下降,这不仅会导致数据误传,还会使主机运行速率受到影响。
常规的k-prototypes 聚类算法通过求解相异度系数来确定大数据的熵权分类标准,又利用经典kprototypes 算法分类处理大数据样本特征[2]。然而利用此方法所得大数据的单位召回率水平相对较低,主机元件难以实现对大数据的精准分类。
粗糙集可以在不应用集合外先验信息的同时,处理各项不完全、不确定、不精确的数据对象。粗糙集理论可以在保持网络系统对数据样本分类能力的同时,删除初始数据中的冗余信息,使得网络主机能够准确推断出初始分类规则[3]。邻域粗集神经网络是在粗糙集理论基础上发展而来的一种可以实现数据区分的结构。在特征参数难以被准确测量出来的情况下,邻域粗集神经网络会筛选待训练样本,以供其他设备元件的裁决与判定。由于整个处理过程中无需其他元件的配合,故而其分类准确性相对较高[4]。
随着电商领域的发展及其所应用技术的升级,电商大数据的累积量也在不断增大,导致在既定时间范围内,应用常规工作软件能捕捉到的电商大数据特征集合。为此,该文以邻域粗集神经网络为基础,设计了一种新的数据特征分类系统。
1 调制信息选取
在大数据特征分类系统中,调制信息的选取过程应建立在邻域粗集神经网络的基础上,对所选数据样本进行逼近处理。
1.1 邻域粗集原理
邻域粗集的定义包含邻域粒化处理、邻域粗糙集逼近两部分,具体研究方法如下。
1)邻域粒化处理。邻域粒化处理就是将已定义邻域节点聚合在一起,再通过突出优化的方式,使得原有粗糙集合对于数据样本的承载能力大幅提升,从而使得网络主机能够准确辨别出粒化节点所处的位置,从而增强大数据分类行为的执行准确性[5]。
假设en表示n个不重合的邻域节点定义参量,其求解过程如下:
其中,wn表示n个粗糙度向量,δn表示n个大数据样本取值系数。在式(1)的基础上,假设Δe表示邻域节点的单位变量,β表示邻域标记系数,αi表示粒化度条件,α0为其初始赋值,联立上述物理量,可将邻域粒化处理表达式定义为:
粒化度条件越小表示邻域节点的聚合能力越弱。在实施粒化处理时,所需消耗的邻域节点参量也就越少。
2)邻域粗糙集的逼近。邻域粗糙集逼近是在已知领域节点所处位置的基础上,通过逼近处理的方式,确保边缘节点与中心节点之间的距离始终处在可控范围之内,从而使得邻域粗集神经网络对于数据样本的承载能力得到提升。
一般情况下,粗糙度较高侧邻域节点的分布数量较多,而粗糙度较低侧邻域节点的分布数量较少[6-7]。在实施逼近处理时,将邻域节点划分在同一平面内,且规定粗糙度平均值能够描述该平面内邻域节点的具体分布状态。假设r表示逼近参量的初始赋值,χ表示邻域节点排列系数,ymax表示粗糙度指标的最大赋值结果,ymin表示粗糙度指标的最小赋值结果,yˉ表示系数ymax与系数ymin的平均值,φ表示边缘化逼近向量。在上述物理量的支持下,联立式(2),可将邻域粗糙集逼近原则定义为如下形式:
由于邻域节点划分平面不具备绝对性,所以邻域粗糙集逼近表达式的作用只具有参考价值,并不能直接影响邻域节点在神经网络模型内的排列与分布形式。
1.2 神经网络模型
神经网络模型是在邻域粗集原则基础上构建的网络结构,由输入节点、筛选节点、聚合节点、输出节点四部分组成。其中,输入节点直接接触数据,负责录入样本信息[8-9];筛选节点与输入节点按照邻域粗集原则,挑选处理待分类的大数据特征参量,再将这些信息样本反馈回系统数据库主机;聚合节点对已筛选出来的大数据特征参量再次聚合,使分类主机能够准确分类数据样本;输出节点只负责显示样本信息,不能改变数据的排列形式[10]。邻域粗集神经网络结构如图1 所示。

图1 神经网络模型结构
2 大数据特征分类系统设计
利用邻域粗集神经网络选取调制信息样本后,按照调制识别器设置、大数据特征导出、多标合并的处理流程,实现大数据特征分类系统的设计与应用。
2.1 调制识别器
调制识别器负责提取邻域粗集神经网络中存储的数据样本,利用传输信道将信息样本反馈至底层调制芯片与Map 识别元件中,并于其中生成长期文本记忆,以供系统分类主机的直接调取与利用[11-12]。调制识别器结构的连接简图如图2 所示。
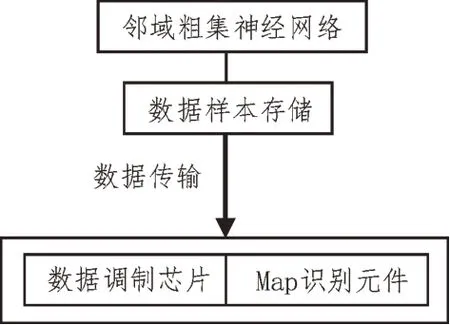
图2 调制识别器结构简图
邻域粗集神经网络输出的大数据样本保持并序排列的分布状态,随着网络覆盖区域的增大,其排布形式却并不会发生改变。作为调制识别器的核心处理设备,数据调制芯片、Map 识别元件对于数据样本的存储能力并无明显差别,但前者对于数据信息排列标准的要求相对较高,其内部存储对象必须保持为顺序排列状态,而后者对于数据信息的排列标准无严格要求[13]。
2.2 大数据特征导出
大数据特征导出过程就是将大数据样本由邻域粗集神经网络导出至分类系统运行主机的过程。由于调制识别器设备的存在,大数据样本的单位输出量并不会无限增大,故而在系统运行过程中,当已导出特征参量达到既定数值水平后,神经网络体系会自动判定系统网络主机已达到最大运行速率[14-15]。假设u表示基于邻域粗集神经网络的大数据分类指标,其求解表达式如下:
其中,γ表示邻域粗集神经网络中的数据样本识别权限,ε表示数据样本度量值,Iε表示基于系数ε的大数据查询条件。在此基础上,令ι、κ表示两个随机选取的大数据样本传输量,Aι表示基于ι的分类特征,Aκ表示基于κ的分类特征,φ表示大数据样本的分配权重值,联立上述物理量,可将大数据特征导出结果表示为:
若ι与κ的差值较小,则表示待分类的大数据特征指标相对较少;反之,则表示特征指标相对较多,邻域粗集神经网络所需承担的数据处理指令相对较为复杂。
2.3 多标合并
多标合并是设计大数据特征分类系统的关键处理环节,可以将已导出的大数据特征串联在一起,以供邻域粗集神经网络的自主选择[16]。由于邻域粗集神经网络中同时运行的大数据总量相对较多,所以在求解多标合并规则时,应确定当前情况下待分类大数据特征参量的具体数值水平。假设kn表示n个待运行的大数据样本,λn分别表示与n个大数据样本匹配的特征参量合并处理系数,h表示基于邻域粗集神经网络的大数据标定参量,且其取值恒大于自然数1。大数据特征分类系统多标合并原则的推导条件满足式(6):
按照多标合并原则,调节相关硬件设备的运行状态,实现基于邻域粗集神经网络的大数据特征分类系统的顺利应用。
3 实例分析
3.1 实验流程与数据处理
为验证上述分类系统的执行能力,设计对比实验,具体实验流程如下:
1)将基于邻域粗集神经网络的大数据特征分类系统作为实验组,控制主机元件,并记录相关指标参量的数值变化情况;
2)闭合相关控制按钮,使实验组系统进入自主运行状态后,关闭控制按钮,调节相关设备元件至初始状态;
3)将传统的k-prototypes 聚类算法作为对照组,控制主机元件,记录相关指标参量的数值变化情况;
4)闭合相关控制按钮,使对照组系统进入自主运行状态;
5)对比实验组、对照组记录数值,总结实验规律。
主机元件对大数据样本的分类准确性可以反映出所选系统对大数据的传输能力。主机元件对大数据样本的分类准确性越高,系统对大数据的传输能力就越强,即数据误传行为的出现可能性越小。该指标的计算过程为:
其中,η表示主机元件对大数据样本的分类准确性,ξ表示实验数据样本的单位召回率,ω表示收敛分类容差。根据式(7)可知,实验数据样本的单位召回率越高、收敛分类容差越大,表示主机元件对大数据样本的分类准确性越高。
3.2 结果与分析
图3 反映了实验组、对照组实验数据样本单位召回率指标的数值变化情况。
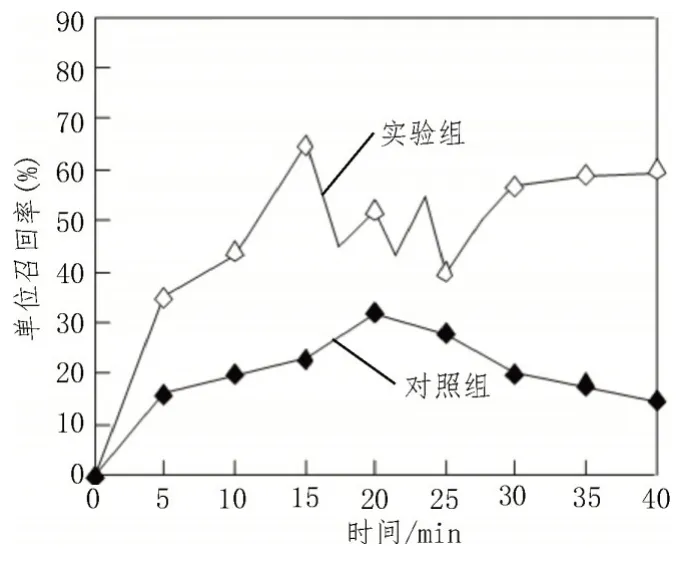
图3 实验数据样本单位召回率
分析图3 可知,实验组数据样本单位召回率指标保持先上升、再波动、最后基本趋于稳定的数值变化状态,在15 min时,单位召回率指标达到最大,数值为65%;对照组数据样本单位召回率指标则呈现出先上升、再下降的数值变化态势,在20 min时,单位召回率指标取得最大值32%,低于实验组最大数值。由此可知,实验组系统可将大数据的单位召回率提升至65%,明显优于对照组,说明实验组系统主机元件对大数据样本的分类准确性也更高。表1 统计了收敛分类容差的变化情况。

表1 收敛分类容差指标
由表1 可知,随着实验时间的增加,实验组、对照组的收敛分类容差指标均不断增大,但实验组容差指标均值略高于对照组。在整个实验过程中,实验组收敛分类容差指标最大值1.20,与对照组最大值1.10 相比,增大了0.10。
为确定系统对于大数据特征的最强分类能力,求解准确性指标。选取样本单位召回率指标、收敛分类容差指标的最大值,计算实验组、对照组分类准确性,具体计算过程如下:
其中,C、Cmax分别表示样本单位召回率指标及其最大值,D、Dmax分别表示收敛分类容差指标及其最大值,ω1、ω2分别表示召回率和分类容差的权重。经式(8)的计算,统计实验组、对照组的分类准确性,结果如表2 所示。

表2 分类准确性
分析表2 可知,实验组、对照组的分类准确性呈现上升态势,经多次测试后,实验组的分类准确性达到94.55%,明显高于对照组。
综上可知,应用传统系统后,实验数据样本单位召回率指标的数值水平相对较低,故而该系统并不能完全满足主机元件对大数据样本进行精准分类的需求;基于邻域粗集神经网络的系统能够有效提升数据样本的单位召回率水平,在解决大数据误传问题、提升主机元件对大数据分类准确性方面具有更强的实用性价值。
4 结束语
以邻域粗集神经网络为基础,大数据特征分类系统设置了调制识别器结构,又通过推导大数据特征导出条件的方式,定义多标合并表达式。与常规的k-prototypes 聚类算法相比,这种新型分类系统从提升主机元件对大数据分类准确性的角度着手,能够在解决数据误传问题的同时,联合相关应用设备,调整邻域粗集神经网络的实际覆盖面积,不仅实现了对相关特征分类节点的邻域粒化处理,也使得邻域粗糙集结果能够更加逼近实际约束标准。
猜你喜欢
吉林大学学报(理学版)(2020年3期)2020-05-29
电子制作(2019年19期)2019-11-23
自动化学报(2018年7期)2018-08-20
周口师范学院学报(2016年5期)2016-10-17
现代工业经济和信息化(2016年2期)2016-05-17
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
电子工业专用设备(2015年4期)2015-05-26
汽车维修与保养(2015年8期)2015-04-17
海军航空大学学报(2015年4期)2015-02-27
