
鹈鹕优化算法在岩体结构面分组中的应用
2024-04-13 06:03刘铁新董自岩郭怡宁
哈尔滨工业大学学报 2024年3期
刘铁新,董自岩,郭怡宁
(大连海事大学 交通运输工程学院,辽宁 大连 116600)
岩体由结构面和结构体两部分组成,直接控制着工程的稳定性[1]。结构面广泛分布岩体之中,由于结构面数量巨大,难以逐一分析,因此,实现岩体结构面的精准分组,是进行岩体工程稳定性分析和结构面三维网络计算机模拟的先决条件[2]。经历相同地质构造时期的结构面,产状、间距、粗糙度等属性上是相似的,可以划分为同一优势组别[3]。由于工程现场环境复杂,许多结构面指标难以测量。结构面产状可使用罗盘或者点云模型进行测量。依据产状数据,对结构面进行组别划分,是目前常用的分组方法[4]。
文献[5]将结构面的产状数据进行二维化显示,简化了结构面数据的处理方式,并对结构面的分组方法进行了研究。早期的结构面分组多采用极点图、等密度图、玫瑰图等方法[6]。此类方法虽然操作简单,分组结果直观,但无法给出稳定准确的结构面分组结果,且在产状极点边界不清晰时,需要根据工程人员的经验进行判断,最终的分组结果受到强烈的主观因素影响。为了避免人为因素的干扰,文献[7]提出了基于结构面产状数据的分组算法,此方法的局限性在于需要先给定小球半径,用来确定密度点的位置。在此基础上,结构面分组算法得到进一步发展。文献[8]将FCM算法引入结构面分组中;文献[9]采用闭包传递的方法,实现对结构面产状的模糊聚类;文献[10]将模糊等价聚类和模糊软划分聚类方法相结合,提出了综合模糊聚类分析方法;文献[11]将迭代思想引入结构面分组中;文献[12]建立了服从双正态分布的产状模型,并用迭代法对结构面进行分组。上述方法大部分为局部寻优方法,易陷入局部最优解,导致所得分组结果不稳定。考虑到FCM算法的不足,部分学者尝试将人工智能算法引入结构面分组中,以改善FCM算法的性能。部分研究[13-16]将差分进化优化算法、变尺度混沌优化算法、量子粒子群算法、变长字符串遗传算法等优化算法引入到结构面分组方法中,使获得的聚类中心更具有全局性,分组的结果更加准确。然而,上述算法往往实现过程繁琐且输入参数较多,分组效率较低,工程实用性有限。
鉴于传统结构面分组方法存在的不足,本文提出一种基于鹈鹕优化算法的结构面分组方法(PFCM算法),从鹈鹕优化算法出发,借助算法的强空间寻优能力,结合模糊聚类算法软划分的特点,获得精确可靠分组结果。该方法能够有效处理产状极点边界不清晰的数据,扩大了结构面分组方法的应用范围。最后,利用PFCM算法对大连某边坡的结构面进行了分组,对其工程实用性进行了验证。
1 基于POA的FCM聚类算法
1.1 PFCM算法
鹈鹕优化算法(pelican optimization algorithm,POA)是一种新型元启发式优化算法,灵感来自鹈鹕种群狩猎行为。通过模拟鹈鹕狩猎的全过程,建立数学模型,找到解决问题的最优解[17]。该方法具有输入参数少、收敛速度快、全局寻优与局部搜索相结合、算法运行流程简单等优点。
本文结合结构面分组特点,将鹈鹕种群成员位置设定为结构面产状聚心集(鹈鹕狩猎的过程即为寻找最优聚心集的过程),提出了基于鹈鹕优化算法的模糊聚类方法(PFCM)。该方法通过确定种群成员位置,迭代计算目标函数值F,获得全局理想解(最优聚心集)。具体算法流程如图1所示,基本步骤如下。

图1 算法流程图
步骤1设置迭代次数T、鹈鹕种群规模N及结构面分组数C。N和T越大,搜索精度越高,计算负担越大。通过多次试算,N设置为30,T设置为100。
步骤2根据倾向(0°<α<360°)和倾角(0°<β<90°)的范围,随机生成结构面产状聚心集。该过程重复N次,生成N个鹈鹕位置。
步骤3计算所有产状数据对鹈鹕种群成员位置的隶属度,由隶属度矩阵计算目标函数值F,将目标函数值最小的鹈鹕所在位置视为全局最优解。
步骤4随机寻找C条结构面产状数据,构成猎物位置。
步骤5根据POA算法优化原理,计算鹈鹕新位置,并计算更新后隶属度矩阵和目标函数值。
步骤6将所得目标函数值与猎物位置目标函数值比较,更新鹈鹕位置与全局最优解。
步骤7进行算法迭代,重复步骤4~6,确定每次迭代后目标函数最小值,鹈鹕对应位置为最佳位置。算法迭代过程中,所得的鹈鹕最佳位置为最优结构面产状聚心集。
步骤8以步骤7中所得聚心集为初始聚类中心,使用FCM算法进行最终分组。
1.2 模糊C均值聚类算法
利用模糊C均值聚类算法(FCM)进行聚类时,需要给定初始的聚类中心。获得初始聚类中心后,根据初始聚类中心计算所有样本数据对于聚类中心的隶属度[18]。在获得聚类中心和隶属度矩阵后,便可计算模糊目标函数。模糊目标函数值是评价聚类结果优劣的重要指标,模糊目标函数值越低,聚类结果越好[19]。依据模糊目标函数值重新选择聚类中心,再根据新的聚类中心更新隶属度矩阵,最后由更新后的隶属度矩阵计算出新的模糊目标函数。重复上述步骤,直到所得模糊目标函数值为最小值时,聚类中心和隶属度矩阵为最优。隶属度矩阵和模糊目标函数计算[20]如下。
给定N个结构面xj(j=1,2,3,…,N),划为K组,每组的聚类中心为vi(i=1,2,3,…,K)。定义uij为第j个结构面属于第i个聚类中心的隶属度,即
(1)
则模糊目标函数为
(2)

FCM算法依赖初始聚类中心,聚类结果不稳定,与实际情况有一定差异。针对上述不足,本文基于POA算法,对FCM算法进行了改进。
1.3 鹈鹕优化算法
在POA算法中,使用目标函数来评估候选解决方案的优劣情况,目标函数值越小,候选解决方案越优,候选解越逼近最优解。在对岩体结构面分组时,选取式(2)作为目标函数,目标函数值最小的聚心集即为结构面的优势产状集。POA算法中的目标函数为
F=Jm(U,C)
(3)
1.3.1 初始化阶段
假设m维空间中有n只鹈鹕,第i只鹈鹕在m维空间中的位置为Xi=[Xi1,Xi2,…,Xin],则n只鹈鹕在m维空间的位置X为
(4)
鹈鹕位置初始化为
xij=lj+α·(uj-lj),i=1,2,…,n;j=1,2,…,m
(5)
式中:xij为第i个鹈鹕在第j维的位置,n为鹈鹕的种群数量,m为求解问题的维度;α为[0,1]内的随机数,uj、lj分别是求解问题在第j维的上下边界。
1.3.2 移向猎物阶段
在这个阶段,鹈鹕识别猎物的位置,并向着猎物移动。猎物在搜索空间的随机分布特性增强了算法的全局寻优能力。每次迭代中,鹈鹕的新位置为
(6)

如果目标函数值在该位置得到改善,则其更新位置为
(7)
1.3.3 掠过水面阶段
鹈鹕到达水面后,它们在水面上展开翅膀,将猎物收集在喉袋中,该过程增强了算法的局部搜索能力。每次迭代中,鹈鹕的新位置为
(8)

如果目标函数值在该位置得到改善,则更新位置为

(9)

在结构面分组应用中,该方法相较一般仿生算法优势如下:1)能得到更优的聚心集。对产状极点边界不清晰结构面分组时,能有效降低了识别错误率,使分组结果更为合理;2)人为输入参数少。最大程度减少人为因素,对于结构面分组结果的影响;3)程序实现步骤简单,分组花费时间少,提高了分组效率。
1.4 聚类有效性检验
聚类有效性评价的关键在于:确定样本划分数目的合理性,以及如何定性分析划分结果的优劣性[23]。文献[24]以夹角余弦距离作为相似性度量,提出了简化的谢贝尼指数。该简化指标精度高、实用性强。计算公式如式(10)、(11)所示。
(10)
(11)
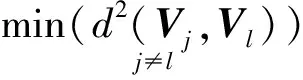
谢贝尼指数越小,聚类效果越好;反之,聚类效果越差。
2 算法精度验证和分析
2.1 算法精度对比
采用蒙特卡罗模拟技术,模拟生成符合Fisher分布的人工数据集[25],进行算法精度对比。具体模拟参数见表1。生成数据集共有4个优势产状组,每个组包含300个产状数据。下面分别使用PFCM算法和FCM算法[11]对模拟产状数据进行分组,通过比较模拟参数和本文所提算法的分组结果来验证算法的有效性,通过比较两种算法的分组结果来验证算法的准确性。

表1 结构面模拟参数
在对符合Fisher分布的产状数据进行分组时,通常用离散度(k)表征产状数据围绕均值的密集程度,离散度越大,数据围绕均值越紧密[25]。对不同离散度下生成的产状数据进行分组,检验不同产状极点边界情况的分组精度。
当离散度k>30时,数据紧密围绕在均值周围,聚类边界清晰,分组效果良好;当k<10时,数据高度分散,聚类边界较模糊,分组结果不具有代表性。因此,选取10到30区间的离散度进行分析。
根据表1的模拟参数,在k=10、k=20、k=30时,分别生成符合Fisher分布的人工数据集。模拟生成结构面产状极点图,如图2所示。FCM算法和PFCM算法聚类生成的结构面极点图,如图3所示。

图2 不同离散度下的结构面极点图(模拟)
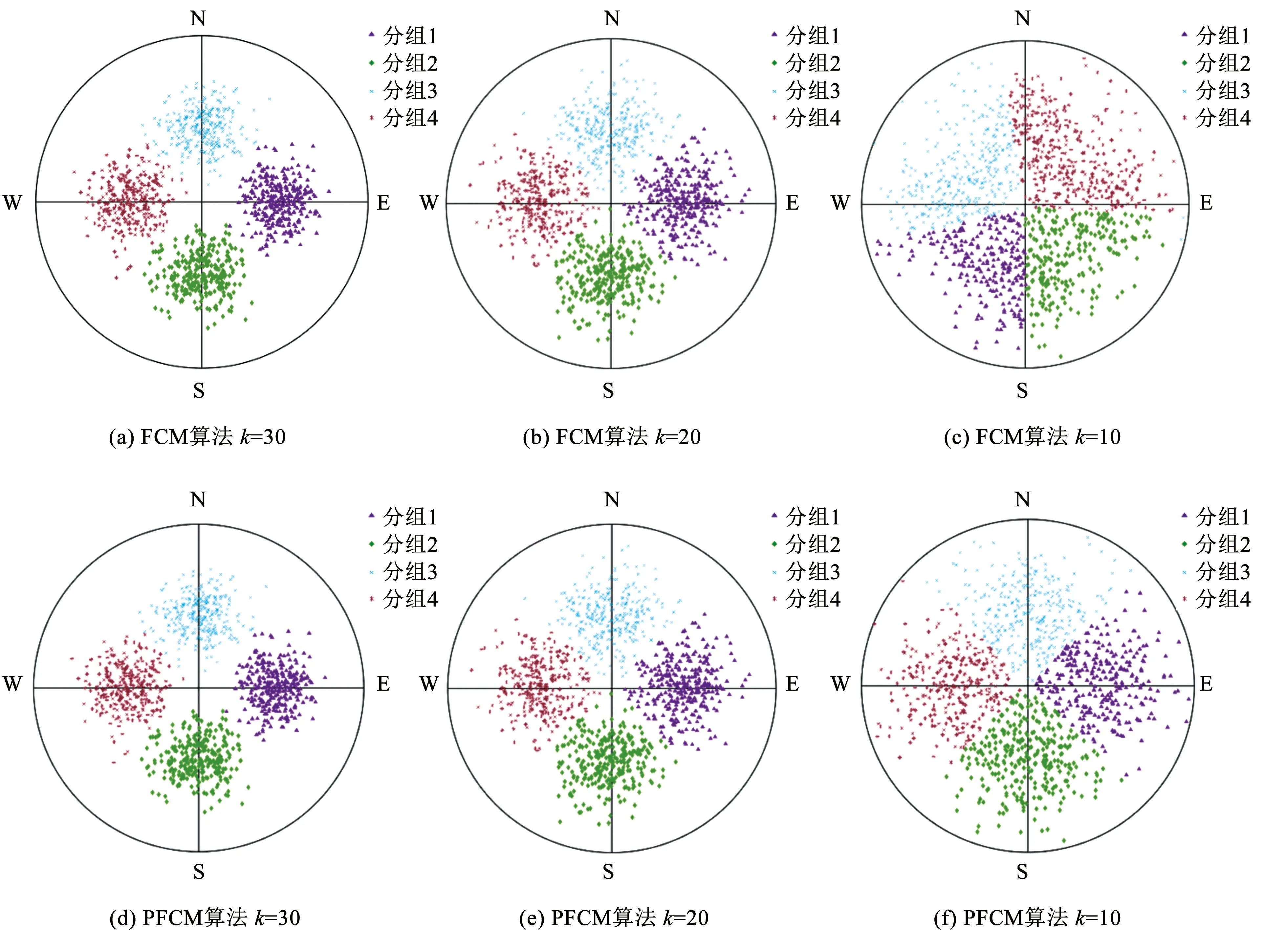
图3 不同离散度下的聚类效果对比图
由图2、3可知,FCM算法和PFCM算法在3次分组检验中,得到的分组数相同,与模拟的分组数一致。FCM算法和PFCM算法在结构面条数、倾向、倾角3个参数上,与模拟参数存在误差,具体分组对比结果见表2。

表2 模拟参数和聚类结果对比
由表2可知,在k=30和k=20两种情况下,FCM和PFCM算法的分组结果,与模拟分组结果相近,PFCM算法的分组结果更优,错误识别的结构面仅为FCM算法的一半。在k=10的情况下,PFCM算法分组效果依然良好,错误识别了9条结构面;FCM算法的分组效果较差,错误识别了103条结构面。PFCM算法分组所得的优势产状倾向和倾角,与模拟参数基本吻合;FCM算法所得倾向和倾角,与模拟参数存在较大差异。
识别错误率是指被错误分组的结构面的比率,常被作为评价结构面分组精度的指标。上述3种情况下,PFCM算法和FCM算法的识别错误率见表3。

表3 不同离散度下的识别错误率对比
由表3可见,k=30和k=20时,FCM算法和PFCM算法的识别错误率,处于较低水平,均小于1%;k=10时,PFCM算法的识别错误率依旧较低,为0.75%;FCM算法的识别错误率出现较大波动,增长至8.58%。为了清楚知道k在10~30之间取值时,PFCM和FCM算法的识别错误率变化情况,下面对两种算法的分组情况进一步研究,具体识别错误率对比结果如图4所示。
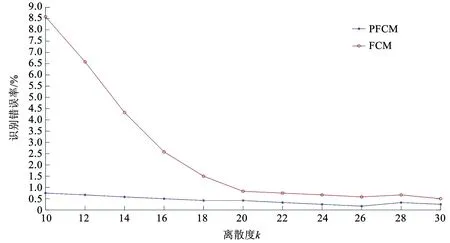
图4 不同离散度下识别错误率对比
由图4可以得到以下结论:1)PFCM算法的识别错误率随着离散度的下降呈现上升的趋势。2)FCM算法的识别错误率,在离散度由30到20时,呈现较为平稳的趋势;在离散度由20到10时,呈现指数上升的趋势。3)当离散度大于20时,两种算法的识别错误率差距较小,分组精度较高;当离散度小于20时,两种算法的识别错误率出现明显差异,FCM算法的分组可靠性不高。
FCM算法较为依赖初始聚类中心,聚类中心不合理,会导致较大的识别错误率。PFCM算法优化上述问题,给出全局最优的初始聚类中心,分组结果和模拟参数基本一致,且产状极点边界不清晰时,识别错误率仍然较低。
2.2 不同变量对算法精度的影响性分析
在算法验证的过程中发现,离散度、结构面条数、结构面组数(用结构面优势产状倾向来表示)、聚类中心(用结构面优势产状倾角来表示)等变量,对PFCM算法的识别精度有着较大影响。基于正交试验设计,用A、B、C、D表示上述4个变量,每个变量设置5个水平,以识别错误率为评定指标,研究PFCM算法的分组精度变化规律。试验采用L25(45)正交表,因素水平见表4。

表4 正交设计影响因素水平表
根据变量设定的水平数,生成结构面产状数据,计算每种情况下的识别错误率,结果见表5。对计算结果进行极差分析[26],确定4个变量对PFCM算法分组精度影响的显著性。
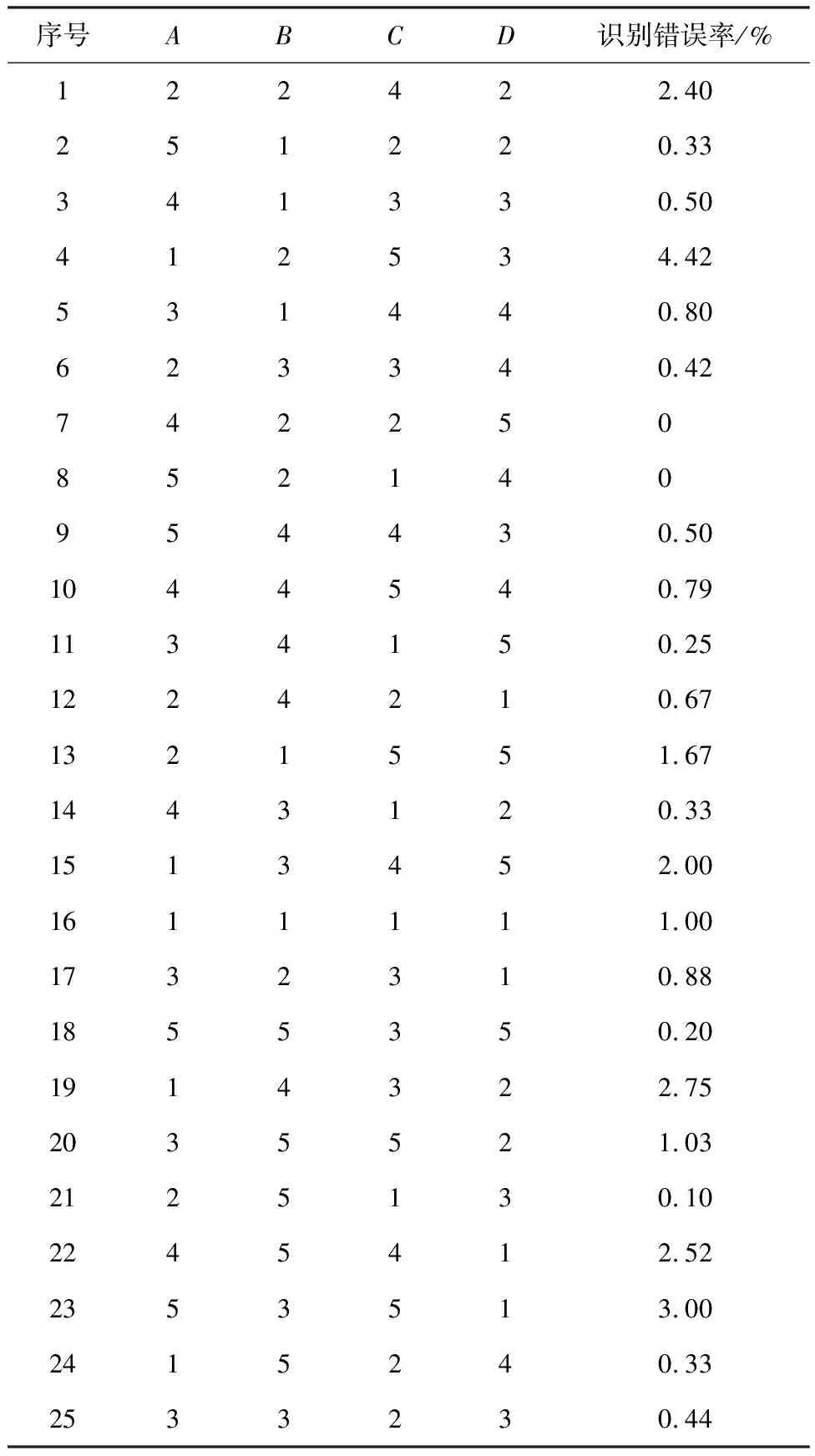
表5 正交设计数据表
表6为评定指标的极差分析结果表,其中:Ki(i=1,2,…,5)表示m(m=A,B,C,D)变量第i个水平的试验结果之和;ki(i=1,2,…,5)表示Ki的平均值[26]。通过表6可知,A,B,C,D4个变量的极差分别为1.78、0.88、2.31、1.43。由极差结果分析可得,变量对于PFCM算法分组精度影响的主次顺序:聚类中心→离散度→结构面组数→结构面数量。

表6 识别错误率极差分析结果
3 工程应用
大连龙王塘水库道路边坡,岩体多呈现块状结构,结构面发育明显。因边坡稳定性易受结构面影响,边坡结构面有效分组显得尤为重要。本次研究的结构面产状数据,是基于数字摄影测量技术计算所得。
拍摄水库边坡岩体图像,利用近距离数字摄影测量技术,建立边坡岩体三维点云模型。根据三维点云模型,提取迹线拐点坐标,拟合覆盖拐点坐标的三维平面。基于三维平面的法向量,计算出结构面的产状(倾向和倾角)数据[27]。经由上述方法,共测得结构面产状1 030个。文献[28]指出,只有当结构面数目超过200个时,才可以对结构面进行分组,显然,所测得的结构面数目符合分组要求。
鹈鹕优化算法参数设置如下:最大迭代次数T=100,初始种群规模N=30。根据工程实践经验,分组数通常在2~8之间。以简化的谢贝尼指数为分组效果评价指标,对比不同分组数下的分组结果,确定最佳分组数。分组数为2、3、4、5、6、7、8时,简化谢贝尼指数分别为525.69、327.95、398.36、400.52、441.28、451.49、480.70。
由所求简化谢贝尼指数可知,分组数为3时,简化谢贝尼指标最小,分组效果最佳。PFCM算法结构面分组结果见表7,结构面产状聚类效果如图5所示。

表7 结构面聚类参数(3组)
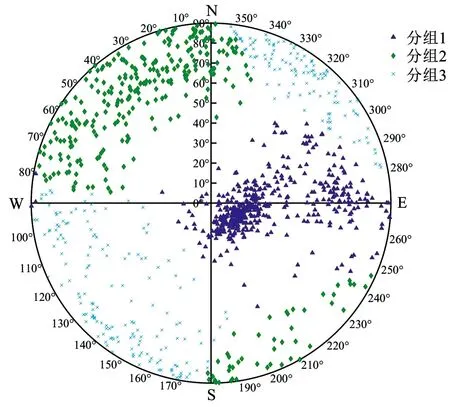
图5 结构面聚类极点图(3组)
确定分组数为3后,PFCM算法对1 030个结构面进行分组,每组的结构面数分别为456、306、268,这一分组结果和工程实际情况相一致,可为后续研究工作提供理论依据。
4 结 论
针对传统结构面分组方法的不足,将鹈鹕优化算法引入结构面分组当中,提出一种基于POA算法的岩体结构面分组方法。通过对该方法的研究和应用,得出以下主要结论:
1)利用鹈鹕优化算法,改进了FCM算法易受初始聚类中心的影响,难以实现全局优化的不足,分组结果更加高效、准确。
2)与未经优化FCM聚类算法相比,PFCM算法在对产状极点边界不清晰结构面分组时具有明显优势,分组结果更加稳定。
3)通过正交设计试验,得到4个变量对算法精度影响的显著性。聚类中心对算法精度影响最为显著;离散度次之。
4)应用PFCM算法对大连龙王塘水库边坡结构面分组,得到与工程实际情况相符的分组结果,可为结构面三维网络计算机模拟和岩体工程稳定性分析提供理论基础。
猜你喜欢
小哥白尼(野生动物)(2021年8期)2021-11-22
油气·石油与天然气科学(2021年7期)2021-09-10
矿产勘查(2020年6期)2020-12-25
大众科学·上旬(2020年4期)2020-10-21
福建质量管理(2019年9期)2019-04-29
新课程·上旬(2019年1期)2019-03-18
小哥白尼(野生动物)(2018年12期)2018-12-18
小哥白尼(野生动物)(2018年3期)2018-06-15
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
